云上 OpenClaw(原 Clawdbot)数据持久存储指南
为什么需要持久存储数据
OpenClaw 运行过程会持续产生几大类数据:
- 记忆类数据:OpenClaw 记忆数据是其作为“永不遗忘的 AI 助手”的核心,它通过一套精巧的本地化、文件驱动的系统,实现了信息的持久化存储与智能检索。记忆数据主要包括每日记忆和长期记忆等信息。
- 结果类数据:用户通过 OpenClaw 获取公开信息并进行本地化处理后,可以将获取到的公开信息和处理结果存储在指定路径上,实现数据的持久化存储。
- 运行日志:系统运行过程中会持续产生日志记录服务运行状态、模型调用记录、工具执行记录、错误警告等信息,存储在系统临时文件目录下。
随着系统运行时间逐渐增加,这类数据规模会逐渐增长,此时使用轻量对象存储(Lighthouse 版)即可实现弹性、低成本地持久化存储数据的目的!
使用轻量对象存储(Lighthouse 版)存储数据
在该环节正式开始之前,请先完成了 OpenClaw 部署,可参考该文章快速搭建属于自己的OpenClaw >> OpenClaw 一键秒级部署指南。
完成搭建后,可以进入轻量服务器控制台,进入【对象存储】卡片页,点击挂载存储桶的选项:
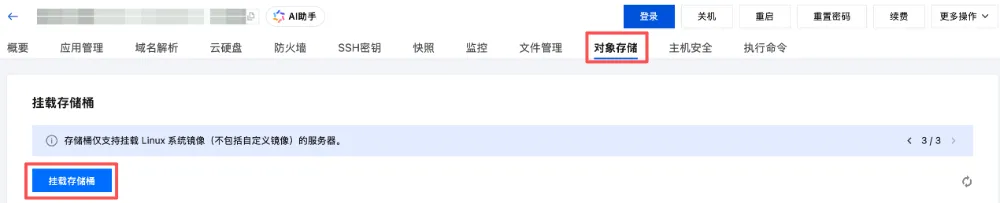
在弹出的窗口中,选择服务器对应地域的存储桶,并设置好相应的参数;如果存储桶未创建,可以点击创建存储桶按钮新建存储桶。
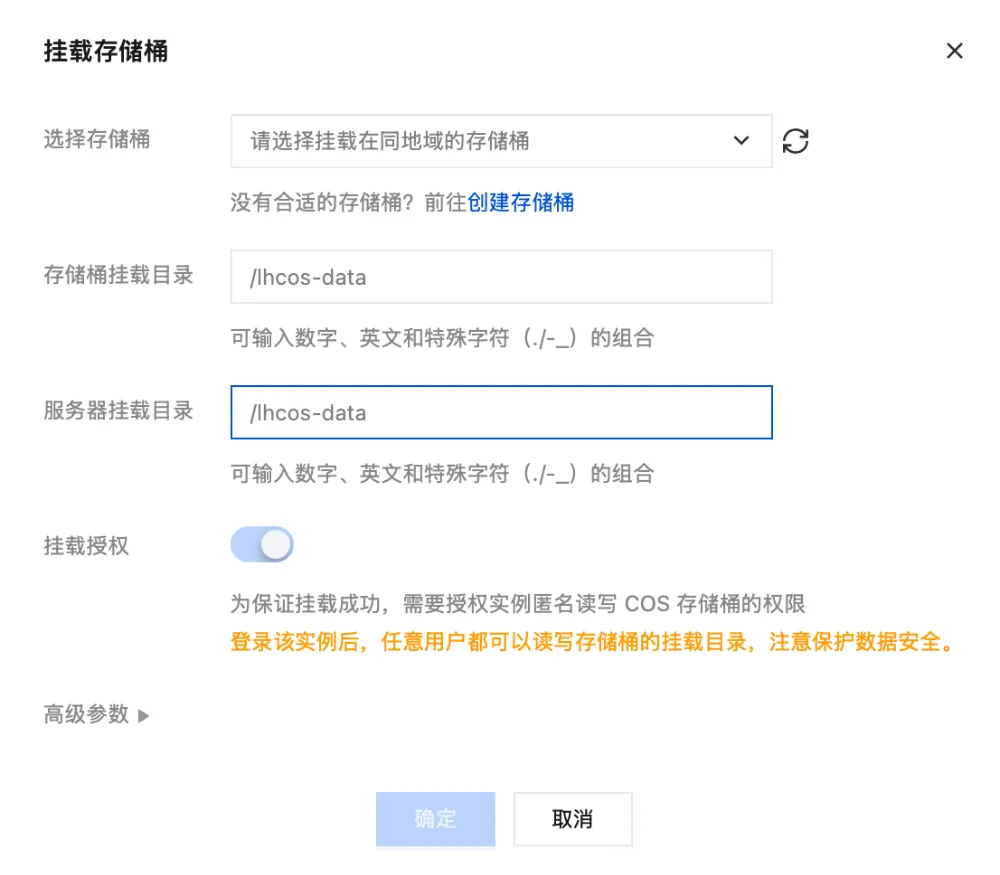
- 选择同地域 Lighthouse 服务器。
- 存储桶挂载目录:输入存储桶挂载目录,注意路径需要以/开,例如 /aaa。
- 服务器挂载目录:输入服务器本地目录,该目录会作为本地挂载目录(例如/home/lighthouse/lhcos-data)。该目录下不能存在文件,也可以输入一个不存在的本地目录。
- 确认挂载授权。创建挂载点之前,必须授权当前 Lighthouse 服务器匿名访问存储桶挂载目录的权限。详情可参见 挂载授权。
- 高级参数(可选)。
- 并发数:挂载传输的并发数,可根据服务器 CPU 核数适当调整。假如服务器 CPU 核数为N,默认推荐值为max(10,2*N)。
- 分块大小:挂载传输中,大文件会使用分块上传,分块大小默认为10MB。由于分块上传最多支持10000块,如果需要传输超出100GB的大文件,可适当调大该参数。
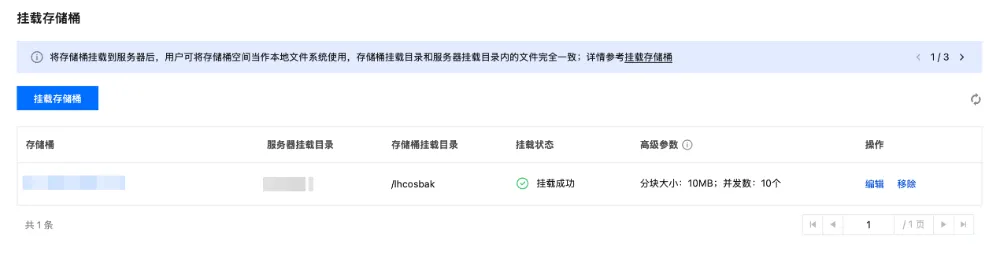
单击确定,开始挂载。通过挂载状态可以查看当前挂载任务的完成情况,单击右侧的刷新图标可以刷新状态。完成挂载后会显示挂载成功的状态。
在完成挂载动作后,即可和 OpenClaw 通过对话式的方式,将数据转存至轻量对象存储 (Lighthouse 版)上。比如如下命令将记忆类文件转存到了指定目录下。
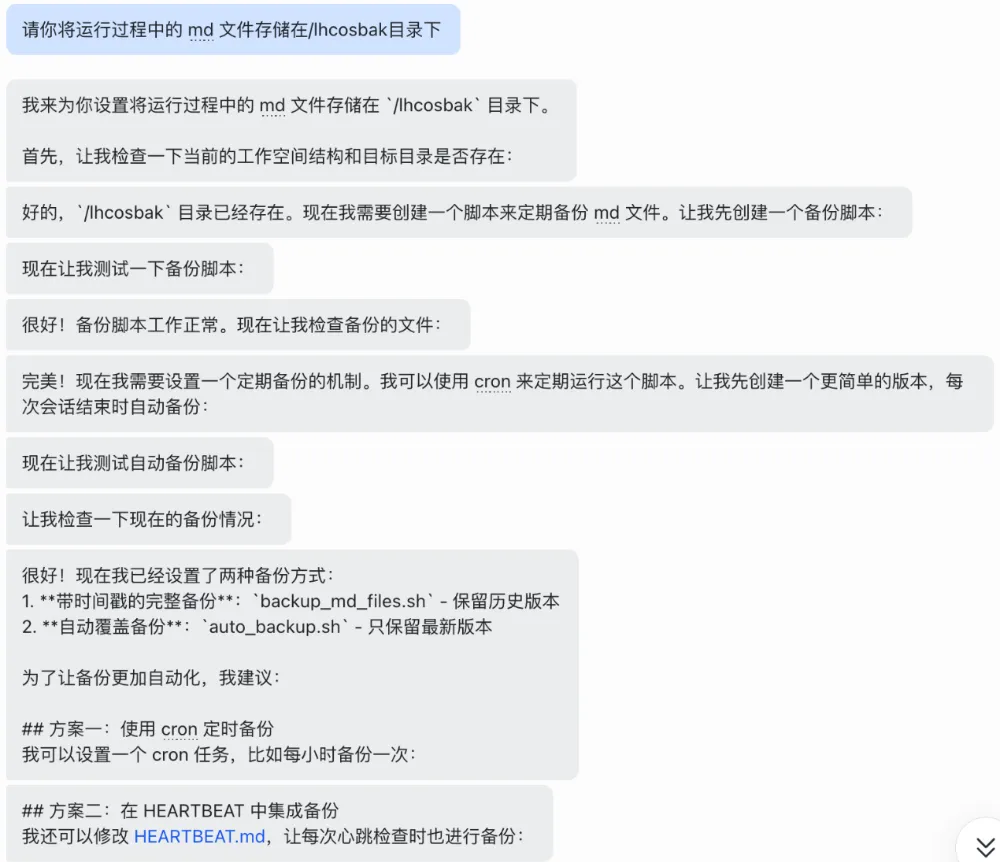
等待 OpenClawd 完成指令后,可以看到轻量对象存储中已经存储了上述文件。
下载 MEMORY.md 文件,可以查阅这位 AI 小助手今天的“工作纪要”:

将 OpenClaw 处理结果输出至轻量对象存储
除了存储记忆类数据,还可以通过命令将运行结果保存到挂载好的轻量对象存储中,以下提供一个 Arxiv 论文检索和存储到轻量对象存储的示意:
任务指令:ArXiv论文自动化抓取与摘要报告生成
角色设定
你是一个专业的学术研究助手,专注于自动化文献检索与处理。请使用集成化的ArXiv访问工具(如ArXiv MCP Server或arxiv Python包)与LLM能力,完成以下多步骤任务。
核心任务流程
1. 领域筛选与论文检索
• 针对以下四个领域,分别检索最多10篇高质量论文,优先选择顶会(如NeurIPS、ICML、OSDI)或高影响力期刊的近期成果,并聚焦热门方向:
◦ 云计算(arXiv分类:cs.DC, cs.SE, cs.Distributed)
◦ 存储(arXiv分类:cs.DS, cs.DB, cs.AR)
◦ AI(arXiv分类:cs.AI, cs.LG, cs.CV, cs.CL)
• 使用ArXiv API的高级检索功能,按lastUpdatedDate降序排列,确保获取最新内容。关键词组合示例:
◦ 云计算:"cloud computing" OR "edge computing" OR "serverless"
◦ 存储:"distributed storage" OR "database optimization" OR "SSD"
◦ AI:"large language model" OR "reinforcement learning" OR "computer vision"
2. 论文处理与摘要优化
• 下载每篇论文的PDF原文至临时目录。
• 提取摘要文本,调用LLM(如DeepSeek或SiliconFlow)执行以下操作:
◦ 逐句翻译:将英文摘要专业地翻译为中文。
◦ 摘要精简:压缩至100字以内,突出研究动机、核心方法创新、关键实验结果,避免冗余描述。
• 确保翻译准确且术语规范(例如,“transformer”译为“ Transformer架构”而非“变压器”)。
3. Markdown报告生成
• 按领域分组输出,每篇论文包含以下字段:
## 领域名称(如:云计算)
### 论文标题
- **精简摘要**:(100字内中文摘要)
- **PDF链接**:[arXiv直接下载链接](https://arxiv.org/pdf/XXXX.XXXXX.pdf)
• 文件整体结构需包含标题(如“ArXiv论文日报-YYYYMMDD”)及更新时间备注。
4. 备份与归档
• 将最终Markdown文件保存至主机目录/lhcosbak/arxivbak,并按领域建立子目录:
◦ cloud/(云计算)
◦ storage/(存储)
◦ ai/(AI)
• 文件名格式:YYYYMMDD_report.md(例如云计算领域2026年2月1日的文件为/lhcosbak/arxivbak/cloud/20260201_report.md)。若目录不存在,需自动创建。
工具与配置建议
• 使用ArXiv MCP Server进行论文搜索与下载,或通过arxiv Python包实现。
• 集成LLM API(如DeepSeek)时,设置系统Prompt为:
> “你是论文摘要专家,需将英文摘要翻译为简洁中文,保留创新点与问题解决方法,严格限100字内。”
• 为避免重复处理,启用去重机制(如记录已处理论文ID)。
验收标准
• 每个领域论文数≤10,且均为顶会或高引用工作。
• 摘要翻译精准、简洁,创新点明确。
• Markdown格式规范,链接有效。
• 文件按日期和领域正确归档。
在输出指令后,OpenClaw 就会自己干活并将结果输出到指定路径下:

如果运行过程中有报错也没关系,可以尝试让 OpenClaw 自行分析原因并处理报错,直到问题解决。以下最终输出的报告样例:

查询更多接入教程👉云上 OpenClaw(原 Clawdbot)最全实践指南合辑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号