
实用脚本公开!0成本实现GitOps中Kubernetes资源自动调优
原文发布于 CloudPilot AI
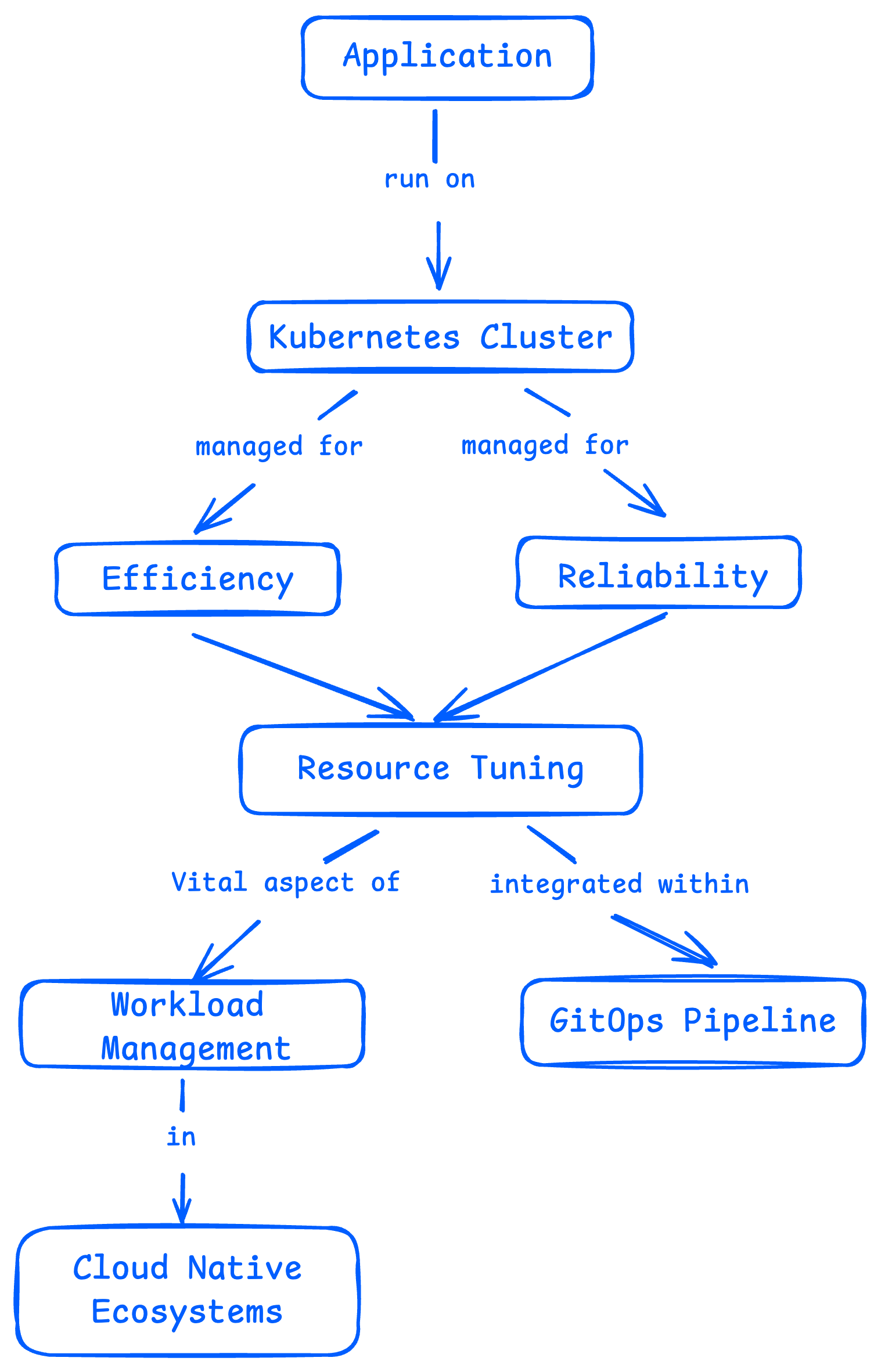
在云原生环境中,Kubernetes 资源配置是一项非常关键的工作,尤其是当你通过 GitOps 流程来管理集群时更是如此。
这篇文章会带你了解资源管理中常见的一些“坑”——比如资源预留太多,配额浪费严重,或者因为资源不足而无法部署新服务。同时我们也会介绍几种不花一分钱的方法,帮你更轻松地解决这些问题。
资源配置的核心逻辑和常见挑战
Kubernetes 的资源配置,其实主要围绕两个核心机制展开:资源配额(Resource Quotas) ,以及 Pod 的请求值和限制值(Requests & Limits) 。这两者共同作用,用来限制应用对资源的占用,确保整个集群既健康又高效地运行。
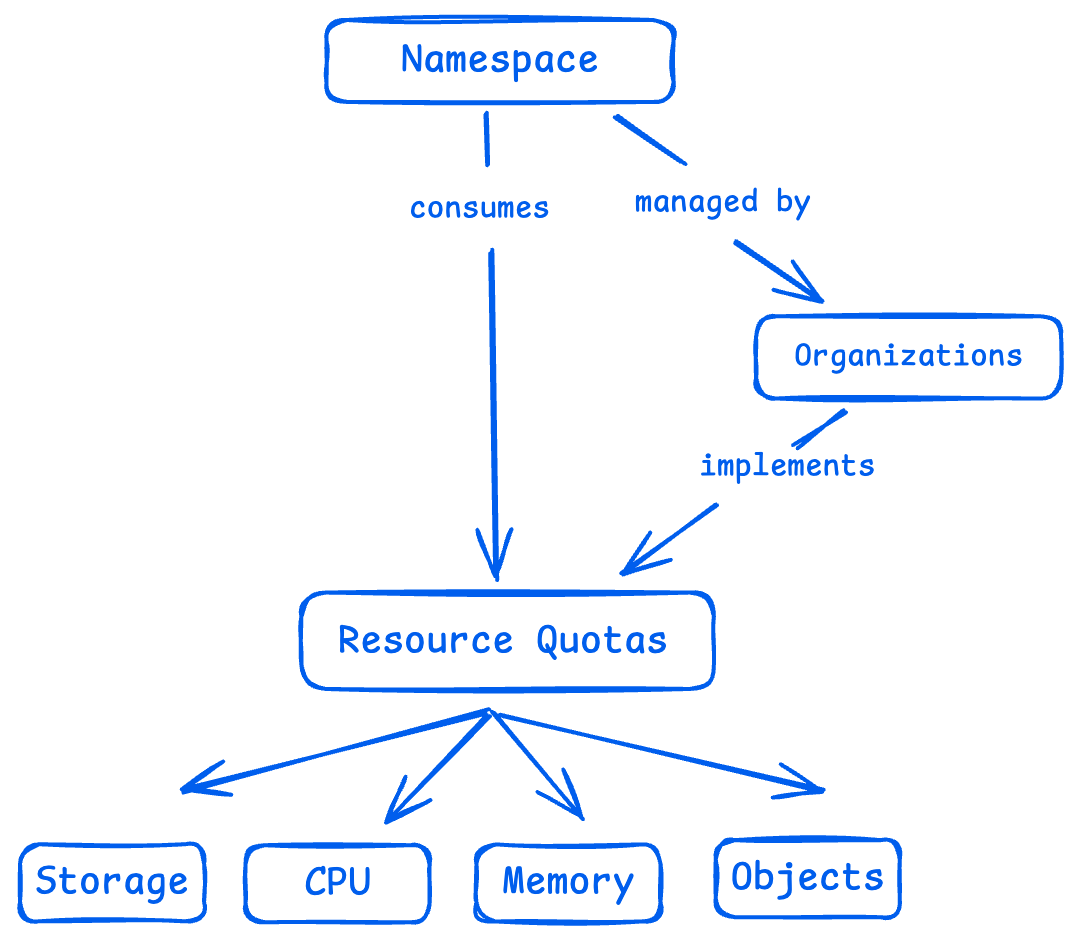
资源配额(Resource Quotas)
资源配额是 Kubernetes 提供的一种控制机制,用来限定某个命名空间(namespace)下能使用的资源总量。除了 CPU 和内存这种常见资源,它还能限制比如 Pod、Service、PersistentVolumeClaim(持久化存储申请)等对象的数量。
这么做的目的很简单:防止某个团队或者服务“独占资源”,影响到其他人的正常运行。通过资源配额,平台管理员可以实现资源的公平分配,避免“抢资源大战”,同时让整个集群的性能更加可控、可预期。
资源配额带来的挑战,开发和运维团队可能深有体会:
-
很难拿捏“刚刚好”的配额: 配得太少,服务跑不起来;配得太多,又容易浪费资源,甚至让其他服务“饿死”;
-
配额一旦超了,成本也跟着飙升: 过度预留资源不仅烧钱,还可能让整个平台的资源利用率大打折扣;
-
协调配额成了日常负担: 每次资源不够用,都要和平台、运维、开发多方来回沟通调整配额设置。稍微出点差错,就可能卡住部署流程,影响上线节奏。
简单来说,资源配额虽然是个好工具,但调不好反而成了团队协作和系统效率的“绊脚石”。
Pod 的 Requests 和 Limits
Pod 的 Requests 和 Limits 是用来规定容器在运行过程中可以使用的 CPU 和内存资源范围。
其中,Request 是“起步资金” ,确保容器有足够的资源顺利启动并稳定运行;而 Limit 则像“信用卡额度” ,防止某个容器过度占用资源,拖慢同一节点上的其他服务。

但在实际操作中,这部分配置常常让开发和运维团队头疼不已,主要问题包括:
-
设置得太低时,可能导致:
-
-
容器启动缓慢,或由于 CPU 不足出现响应延迟;
-
容器因为内存不足频繁崩溃。
-
-
设置得太高时,则容易:
-
- 浪费资源,甚至超出命名空间的 ResourceQuota 限制;
- 导致新 Pod 无法调度,因为节点上的资源已经被高请求值占满;
- 拖累其他应用,造成限速(throttling)或被 OOM Kill(内存溢出强制终止)。
换句话说,设置 Requests 和 Limits 并不是“越多越好”或“越省越稳”,而是需要不断调试和权衡,找到既满足性能又不过度浪费的平衡点。
关于 Kubernetes 服务启动时所需资源激增的问题,可以查看这篇文章寻找解决方案:KubeCon 演讲文字实录 | 从瓶颈到突破:征服 Kubernetes 中的应用程序启动高峰
解决部署延迟与资源分配难题
如何判断 ResourceQuota 是否阻碍了部署
在 Kubernetes 的部署过程中,有一个非常常见、但又让人头大的问题:Pod 因为触达了资源配额上限而无法部署。这种情况往往出现在关键更新或滚动发布时,对开发者来说影响极大,甚至会直接阻断上线流程。
要解决这个问题,首先得搞清楚 ResourceQuota 是如何影响部署策略的。有了这层理解,开发者就能提前预判风险,在部署前做好准备,避免临时踩坑,从而提升整个发布流程的流畅度。
举个例子,如果你设定了一个 Deployment 使用滚动更新(rolling update),但新版 Pod 一直没法跑起来,你可能会在事件日志中看到类似这样的提示信息:
# kubectl get events -n recipes
LAST SEEN TYPE REASON OBJECT MESSAGE
18s Warning FailedCreate replicaset/recipes-5cb59585d4 (combined from similar events): Error creating: pods "recipes-5cb59585d4-7r78l" is forbidden: exceeded quota: compute-resources, requested: requests.cpu=250m,requests.memory=128Mi, used: requests.cpu=375m,requests.memory=384Mi, limited: requests.cpu=375m,requests.memory=384Mi
# kubectl describe resourcequota -n recipes
Name: compute-resources
Namespace: recipes
Resource Used Hard
-------- ---- ----
limits.cpu 375m 2
limits.memory 384Mi 2Gi
requests.cpu 375m 375m
requests.memory 384Mi 384Mi
当你发现资源配额阻碍了部署,接下来的处理通常就比较“低效”了:团队必须手动排查当前配额使用情况,并和平台管理员协商资源调整。
这一来一回,不仅打断了工作节奏,还可能导致部署周期大幅延后。
别再靠猜来配置容器资源请求了
“我到底该设置多少资源才合适?”——这是开发过程中经常会遇到的问题,尤其是当应用还处于开发早期或者频繁变动时,更是无从下手。
大多数时候,初始的资源设置其实都是“靠感觉”,为了确保应用能跑起来,就先预留多一点,哪怕没有任何历史数据支撑。
比如说,一个 Deployment 在运行时并没有做资源监控。此时你用 kubectl top 查看,发现它只用了 5 millicores 的 CPU 和 15MB 的内存。
表面上看,一切正常。但这并不能说明它在实际压力下的表现,而这组数据也揭示了另一个问题——它现在的资源请求,可能比真实需求高出 25 倍之多。

这种“过度预留”不仅浪费资源,还可能占用了本来可以分配给其他服务的空间,导致整个集群效率下降。
# kubectl top pods -n recipes
NAME CPU(cores) MEMORY(bytes)
recipes-postgresql-0 5m 15Mi
# kubectl get pods -n recipes -o json | jq '.items[] | {name: .metadata.name, limits: .spec.containers[].resources.limits, requests: .spec.containers[].resources.requests}'
{
"name": "recipes-postgresql-0",
"limits": {
"cpu": "125m",
"memory": "256Mi"
},
"requests": {
"cpu": "125m",
"memory": "256Mi"
}
}
为了真正做到资源配置的“精细化”,通常需要让 Pod 在正常负载下运行一段时间,收集性能指标,再进行分析和调整,然后再把优化后的结果应用到 Pod 的配置中。
这个流程既耗时又复杂,难怪很多 Kubernetes 集群存在资源利用率偏低的问题——与其频繁调优,不如一开始就多申请点资源来得省事。
简化这个过程!
好消息是,有一些小工具和 Kubernetes 自带的能力,可以帮我们缓解这些烦恼。
脚本:检查命名空间中的 ResourceQuota 使用情况
下面这个脚本就非常实用,适合开发者或平台用户在遇到部署失败、怀疑资源配额相关问题时随时运行。
它会检查当前命名空间下所有的 ResourceQuota 使用情况,评估资源是否紧张,并根据使用率给出哪些资源项可能需要上调配额的建议。这样一来,不用等到部署挂了才发现问题,而是可以主动预警、及时处理。
# KUBERNETES_DISTRIBUTION_BINARY=kubectl NAMESPACE=recipes CONTEXT=gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster bash -c "$(curl -s https://raw.githubusercontent.com/runwhen-contrib/rw-cli-codecollection/main/codebundles/k8s-namespace-healthcheck/resource_quota_check.sh)" _
Resource Quota and Usage for Namespace: recipes in Context: gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster
===========================================
Quota: compute-resources
limits.cpu: OK ( 18 %)
limits.memory: OK ( 18 %)
requests.cpu: AT LIMIT ( 100 %) - Immediately increase the resource quota for requests.cpu in recipes
requests.memory: AT LIMIT ( 100 %) - Immediately increase the resource quota for requests.memory in recipes
-----------------------------------
Recommended Next Steps:
[
{
"remediation_type": "resourcequota_update",
"increase_percentage": "40",
"limit_type": "hard",
"current_value": "375",
"suggested_value": "525",
"quota_name": "compute-resources",
"resource": "requests.cpu",
"usage": "at or above 100%",
"severity": "1",
"next_step": "Increase the resource quota for requests.cpu in `recipes`"
},
{
"remediation_type": "resourcequota_update",
"increase_percentage": "40",
"limit_type": "hard",
"current_value": "384",
"suggested_value": "537",
"quota_name": "compute-resources",
"resource": "requests.memory",
"usage": "at or above 100%",
"severity": "1",
"next_step": "Increase the resource quota for requests.memory in `recipes`"
}
]
自动化生成 Pod 资源请求建议
要精准地设置 Pod 需要的资源量,确实需要一段时间的监控和分析,然后再做调整。
幸运的是,Kubernetes 自带了一个非常实用的工具——Vertical Pod Autoscaler(垂直 Pod 自动伸缩器,VPA),它可以帮你解决这个问题!
Kubernetes 目前有两种弹性伸缩方式:
- Horizontal Pod Autoscaler(水平 Pod 自动伸缩器),通过增加或减少 Pod 副本数来应对负载变化,不过这跟调整单个 Pod 的资源请求无关,没用在这里。
- Vertical Pod Autoscaler(垂直 Pod 自动伸缩器),专门监控单个 Pod 的资源使用情况,判断是应该“扩”资源还是“缩”资源。它可以自动调整,也可以只给出建议。
针对“我到底应该设置多少资源?”这个问题,Vertical Pod Autoscaler 就很合适。
虽然自动调整运行中的 Pod 在某些场景(比如 GitOps 流程)可能不太适用,但你完全可以让它运行在 “推荐模式” ,只给出调整建议。
借助 Kubernetes 内置的指标服务,或者配合 Prometheus,VPA 能帮你做出合理的资源配置建议,大大减少猜测的盲目性。
当然,市场上还有一些更高级的资源推荐算法和工具,比如 CloudPilot AI,能实时监控集群资源使用情况,对资源利用率的节点进行资源优化,减少浪费,适合有更高要求的团队。
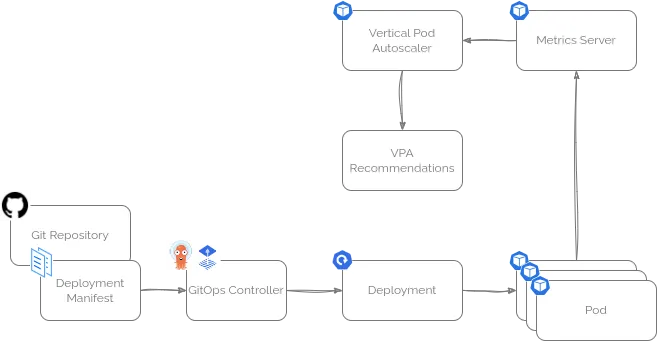
启用 VPA 的推荐模式
你可以很方便地按照官方文档,或者通过 Helm Chart,把 VPA 部署到正在运行的 Kubernetes 集群中。
使用 Helm Chart 的好处是灵活,可以轻松开启推荐器(recommender)功能,同时关闭自动更新(updater)和准入控制器(admissionController)这两个组件——如果你暂时不需要它们的话。
举个例子,下面是一个用于在沙箱集群中通过 FluxCD 部署 VPA 的 HelmRelease 配置示例:
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: vpa
namespace: vpa
spec:
releaseName: vpa
# (https://github.com/FairwindsOps/charts/blob/master/stable/vpa/values.yaml)
chart:
spec:
chart: vpa
sourceRef:
kind: HelmRepository
name: fairwinds-stable
namespace: flux-system
interval: 5m
values:
recommender:
enabled: true
updater:
enabled: false
admissionController:
enabled: false
配置 VPA 为指定 Deployment 提供资源推荐
在成功部署 VPA 后,你可以创建一个 VerticalPodAutoscaler 资源清单,指定它要监控哪个 Deployment,并且只生成资源配置的推荐,而不会自动修改 Pod。
比如,下面这个 VPA 配置示例就是针对某个特定 Deployment,只输出资源调整建议,避免自动变更 Pod。这对于使用 GitOps 管理的环境来说非常重要,能保证配置变更都在版本控制之下,避免自动更新带来的不确定性。
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: recipes-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: recipes
updatePolicy:
updateMode: "Off" #Set to off since the 'recipes' deployment manifest is managed with GitOps
脚本:自动获取命名空间内 Pod 的资源推荐
有了 VPA 之后,这个脚本可以帮助开发者自动查询当前命名空间中各个 Pod 的资源推荐情况。
需要注意的是,虽然 VPA 本身提供了接口可以直接查询推荐结果,但这些数据通常比较原始,需要进一步解读并转化为具体的调整方案。
这个脚本就是为了解决这个问题,它会整理出详细的推荐信息和配置变更建议,方便自动化处理和后续执行。
# KUBERNETES_DISTRIBUTION_BINARY=kubectl NAMESPACE=recipes CONTEXT=gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster LABELS= bash -c "$(curl -s https://raw.githubusercontent.com/runwhen-contrib/rw-cli-codecollection/main/codebundles/k8s-podresources-health/vpa_recommendations.sh)" _
VPA Recommendations for Namespace: recipes for Context: gke_runwhen-nonprod-sandbox_us-central1_sandbox-cluster-1-cluster
===========================================
Recommendation for recipes-nginx in Deployment recipes: Adjust CPU request from 125 to 20 millicores
Recommendation for recipes-nginx in Deployment recipes: Adjust Memory request from 64 to 50 Mi
Recommendation for recipes in Deployment recipes: Adjust CPU request from 125 to 20 millicores
Recommendation for recipes in Deployment recipes: Adjust Memory request from 64 to 50 Mi
Recommended Next Steps:
[
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "cpu",
"current_value": "125",
"suggested_value": "20",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes-nginx",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust CPU request from 125 to 20 millicores"
},
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "memory",
"current_value": "64",
"suggested_value": "50",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes-nginx",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust Memory request from 64 to 50 Mi"
},
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "cpu",
"current_value": "125",
"suggested_value": "20",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust CPU request from 125 to 20 millicores"
},
{
"remediation_type": "resource_request_update",
"vpa_name": "recipes-vpa",
"resource": "memory",
"current_value": "64",
"suggested_value": "50",
"object_type": "Deployment",
"object_name": "recipes",
"container": "recipes",
"severity": "4",
"next_step": "Adjust pod resources to match VPA recommendation in `recipes`\nAdjust Memory request from 64 to 50 Mi"
}
]
将资源调优融入GitOps流水线
前面提到的脚本帮你找出了哪些资源配置需要调整,以及具体该怎么改,最后一步就是把这些推荐结果整合进 GitOps 流水线里。
虽然不同团队的 GitOps 流程会有所差异,但一般来说,可以把脚本输出中“Recommended Next Steps”(推荐的后续操作)部分的 JSON 内容提取出来,传给一个自动化脚本。
这个脚本会根据推荐内容更新 GitOps 代码仓库,并通过既有的审批流程通知相关负责人,确保资源调整变更有序、安全地落地。这样一来,资源配置的优化就能无缝融入日常的开发和交付节奏。
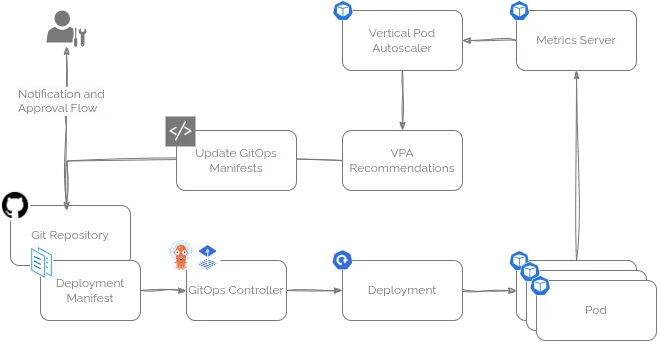
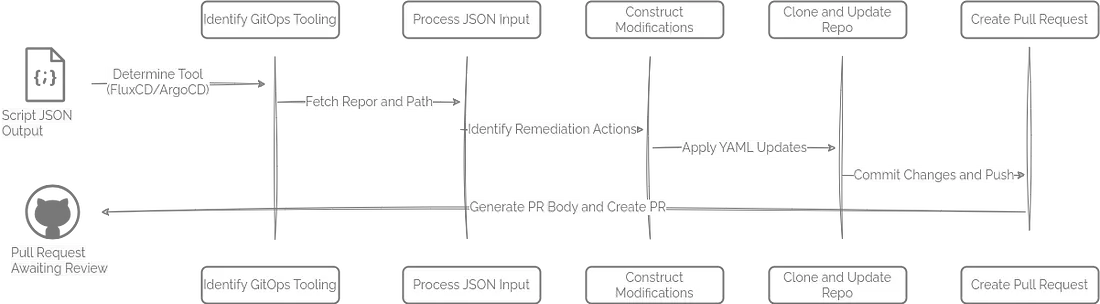
举个例子,这个脚本( https://github.com/runwhen-contrib/rw-cli-codecollection/blob/main/codebundles/k8s-gitops-gh-remediate/update_github_manifests.sh )适用于存放在 GitHub 上的 GitOps 仓库,兼容 ArgoCD 和 FluxCD 两种 GitOps 引擎。它的工作流程大致如下:
- 首先识别负责管理资源的 GitOps 控制器(FluxCD 或 ArgoCD);
- 获取对应的 Git 仓库地址以及存放 Kubernetes 清单(manifest)文件的路径;
- 解析输入的 JSON,识别需要修正的资源操作,并按类型分类,比如资源配额更新、资源请求建议、PVC 容量扩容等;
- 针对每个需要修正的操作,动态生成对应的 YAML 文件变更内容;
- 克隆目标 Git 仓库,创建一个新的分支,将修改后的 YAML 文件写入并提交;
- 自动生成一份详细的 Pull Request(PR)说明,阐述修改原因并附带相关信息链接,然后发起针对主分支的 PR;
- 最后输出 PR 链接,方便团队成员进行代码审查和审批。
这个流程让资源调优的变更能自动、有序地推进,减少人工干预和出错风险。
总 结
资源管理,特别是在性能和成本之间找到最佳平衡,对处于生产环境的平台来说确实是一项复杂的挑战。本文介绍了一些免费且实用的脚本和工具,适合作为平台或应用团队入门的参考。
目前市面上也有许多厂商投入大量资源,提供更深入的应用使用洞察和资源调优方案,比如 CloudPilot AI (我们即将推出一个全新的Dashboard,将带来更直观的成本监控体验,敬请期待!) ,这些方案尤其适合规模大、环境复杂的场景。
posted on 2025-07-21 10:35 CloudPilotAI 阅读(178) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号