[吴恩达机器学习笔记]16推荐系统3-4协同过滤算法
16.推荐系统 Recommender System
觉得有用的话,欢迎一起讨论相互学习~




参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广
16.3 协同过滤Collaborative filtering
- 推荐系统有一个很有意思的特性就是 特征学习 ,即 自行学习所要使用的特征。对于基于内容的推荐系统来说,需要有人事先对电影的x1爱情成分和x2动作片成分做出评价,来确定每部电影的特征成分,并使用电影的特征训练出了每一个用户的参数 。然而事先对电影做出客观的评价是十分耗时和浪费人力的
![]()
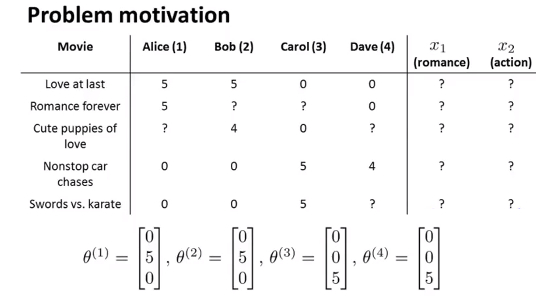
- 现在假设我们没有事先做出的对电影的客观的评价,包括影片的爱情元素和动作元素,只有 不同客户自身对于爱情电影和动作电影的喜爱程度 即用户的特征向量\(\theta\)和这个用户对此影片的评价,理论上我们能够通过用户对电影类型的喜好,和用户对此电影的评价来推断出电影的特征向量的
![]()
- 即对于上图中所示,对于Alice,Bob,Carol,Dave对《Love at last》的评价有
\[(\theta^{(1)})^{T}*x^{1}=5,即(\theta^{(1)})^T*\left[\begin{matrix}1\\x^1_1\\x^1_2\end{matrix}\right]=5 \]\[(\theta^{(2)})^{T}*x^{1}=5,即(\theta^{(2)})^T*\left[\begin{matrix}1\\x^1_1\\x^1_2\end{matrix}\right]=5 \]\[(\theta^{(3)})^{T}*x^{1}=0,即(\theta^{(3)})^T*\left[\begin{matrix}1\\x^1_1\\x^1_2\end{matrix}\right]=0 \]\[(\theta^{(4)})^{T}*x^{1}=0,即(\theta^{(4)})^T*\left[\begin{matrix}1\\x^1_1\\x^1_2\end{matrix}\right]=0 \]
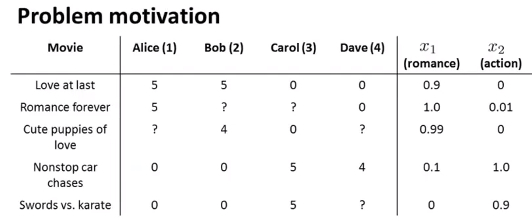
从一部电影中学得特征
- 假如用户给予了他自身的偏好特征\(\theta^{(1)},\theta^{(2)},\theta^{(3)}...\theta^{(m)}\),而我们需要根据这些信息求出电影的特征向量\(x^{(i)}\)
- 从让所有已经评价过电影的用户j的偏好特征和电影的特征相乘算法会预测出一个用户可能对当前电影的评价然后和实际用户对电影的评分相比较,通过优化参数,得到电影的特征。
![]()

从多部电影中学习特征
- 上面的代价函数只是针对一部电影的,为了学习所有电影的特征,我们将所有电影的代价函数求和
![]()

基本协同过滤算法
- 上一个教程中介绍的是通过 已知电影的特征x和用户对电影的评分学习用户的特征\(\sigma\) ,本教程介绍的是通过 已知用户的偏好特征\(\sigma\)和用户对电影的评分学习电影的特征x
- 我们可以先随机的初始化用户特征\(\theta\) ,然后学出不同电影的特征x,继而学习更好的\(\theta\),然后得到更好的特征...不断迭代重复进行不断得到更有效更合理的参数。
- Note 对于上述电影推荐系统的问题仅仅建立在每位用户都对数个电影进行了评价,并且每部电影都被数位用户评价过的情况下,这样才能重复这个迭代过程来估计出\(\theta和x\)
- 协同过滤算法 指的是当你执行算法时,要观察大量的用户的实际行为来协同地得到更佳的每个人对电影的评分值,因为如果每个用户都对一部分电影做出了评价,那么每个用户都在帮助算法学习出更合适的特征,然后学习出的特征又能预测其他用户的评分。
16.4 协同过滤算法 Collaborative filtering Algorithm
- 如果给你几个特征表示电影就可以用他们来学习用户的参数\(\theta\),如果给你用户的参数,就可以用其来学习电影的特征。把这两个特点结合起来就能得到真正的协同过滤算法。
- 如果你有电影的特征,你就可以解出以下的最小化问题,找到用户参数\(\theta\)
![]()
- 如果拥有电影的特征参数\(\theta\),你也可以使用此参数通过最小化以下特征,估计特征x
![]()
- 但是如果我们既没有用户的参数,也没有电影的特征,这两种方法都不可行了。协同过滤算法可以同时学习这两者。我们的优化目标便改为同时针对 x 和 θ 进行。
![]()
- 注意 ,此时x和\(\theta\)都是n维向量,即去掉了截距项\(x_0=1\) ,因为协同过滤算法可以自行选择和学习特征,所以不需要把\(x_0\)固定为1。
- 对 代价函数求偏导数 的结果如下:
![]()
- 协同过滤算法使用步骤:
- 初始 x(1),x(2),...,x(nm),θ(1),θ(2),...,θ(nu)为一些随机小值
- 使用梯度下降算法最小化代价函数
- 在训练完算法后,我们预测\((θ(j))^Tx(i)\)为用户 j 给电影 i 的评分
- 通过这个学习过程获得的特征矩阵包含了有关电影的重要数据,这些数据不总是人能读懂的,但是我们可以用这些数据作为给用户推荐电影的依据
- 例如,如果一位用户正在观看电影 \(x^(i)\),我们可以寻找另一部电影 \(x^(j)\),依据两部电影的特征向量之间的距离||x(i)-x(j)||的大小判断这两部电影的特征相似度,如果两者的特征相似度差距很小,则我们可以将其互作为推荐内容推荐给用户。
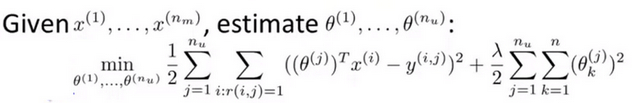
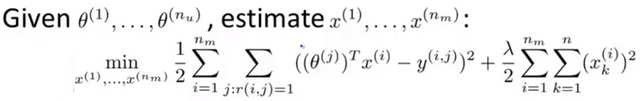

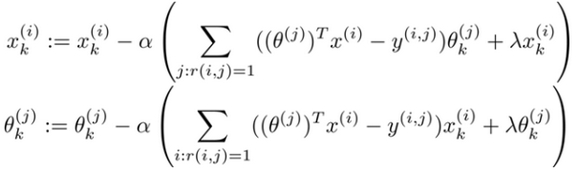

 浙公网安备 33010602011771号
浙公网安备 33010602011771号