Python——正则表达式 - 详解
类别 | 概念/符号 | 说明与示例 |
|---|---|---|
元字符与特殊序列 |
| 匹配除换行符外的任意单个字符 示例:a.b可匹配 "aab", "acb" 等
|
| 匹配字符串的开始。示例: | |
| 匹配字符串的结束。示例: | |
`` | 转义特殊字符,使其表示字符本身。例如 | |
| 或操作,匹配两侧的任意一个表达式。示例: | |
量词(重复次数) |
| 匹配前一个字符0次或多次。示例: |
| 匹配前一个字符1次或多次。示例: | |
| 匹配前一个字符0次或1次。示例: | |
| 匹配前一个字符至少m次,至多n次。示例: | |
字符集合与范围 |
| 匹配方括号内任意一个字符。示例: |
| 匹配指定范围内的任意一个字符。示例: | |
| 否定字符集合,匹配不在方括号内的任意一个字符 | |
| 匹配任意数字,等价于 | |
| 匹配任意非数字字符 | |
| 匹配字母、数字、下划线,等价于 | |
| 匹配非字母、数字、下划线的字符 | |
| 匹配任意空白字符(空格、制表符、换行符等) | |
| 匹配任意非空白字符 | |
边界匹配(位置) |
| 匹配一个单词的边界(开头或结尾)。示例: |
| 匹配非单词边界 | |
分组与捕获 |
| 捕获分组,将括号内的模式作为一个整体,并提取匹配的内容。示例: |
| 非捕获分组,只分组但不捕获内容,用于提高效率或逻辑分组 | |
| 命名分组,为分组起名,可通过名称引用。示例: | |
正则标志 |
| 忽略大小写进行匹配 |
| 多行模式,使 | |
| 使元字符 |
re模块
有了准备知识,我们就可以在Python中使用正则表达式了。Python提供re模块,包含所有正则表达式的功能。
先看看如何判断正则表达式是否匹配(此处忽略手残打错的代码):

切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:

这里并不能正常识别到连续的空格,用正则表达式试试

分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组(Group)。比如:
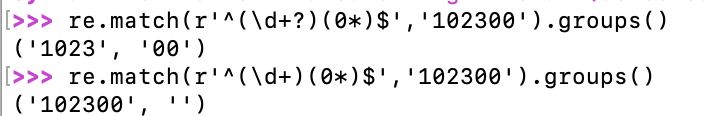
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是与整个正则表达式相匹配的字符串,group(1)、group(2)……表示第1、2、……个子串。

贪婪匹配
最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的0:
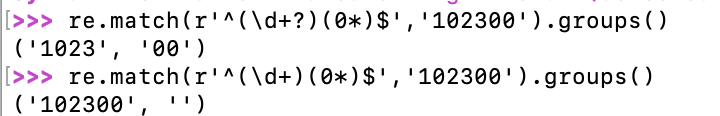
练习
请尝试写一个验证Email地址的正则表达式。版本一应该可以验证出类似的Email:
- someone@gmail.com
- bill.gates@microsoft.com
import re
def is_valid_email(addr):
return True
# 测试:
assert is_valid_email('someone@gmail.com')
assert is_valid_email('bill.gates@microsoft.com')
assert not is_valid_email('bob#example.com')
assert not is_valid_email('mr-bob@example.com')
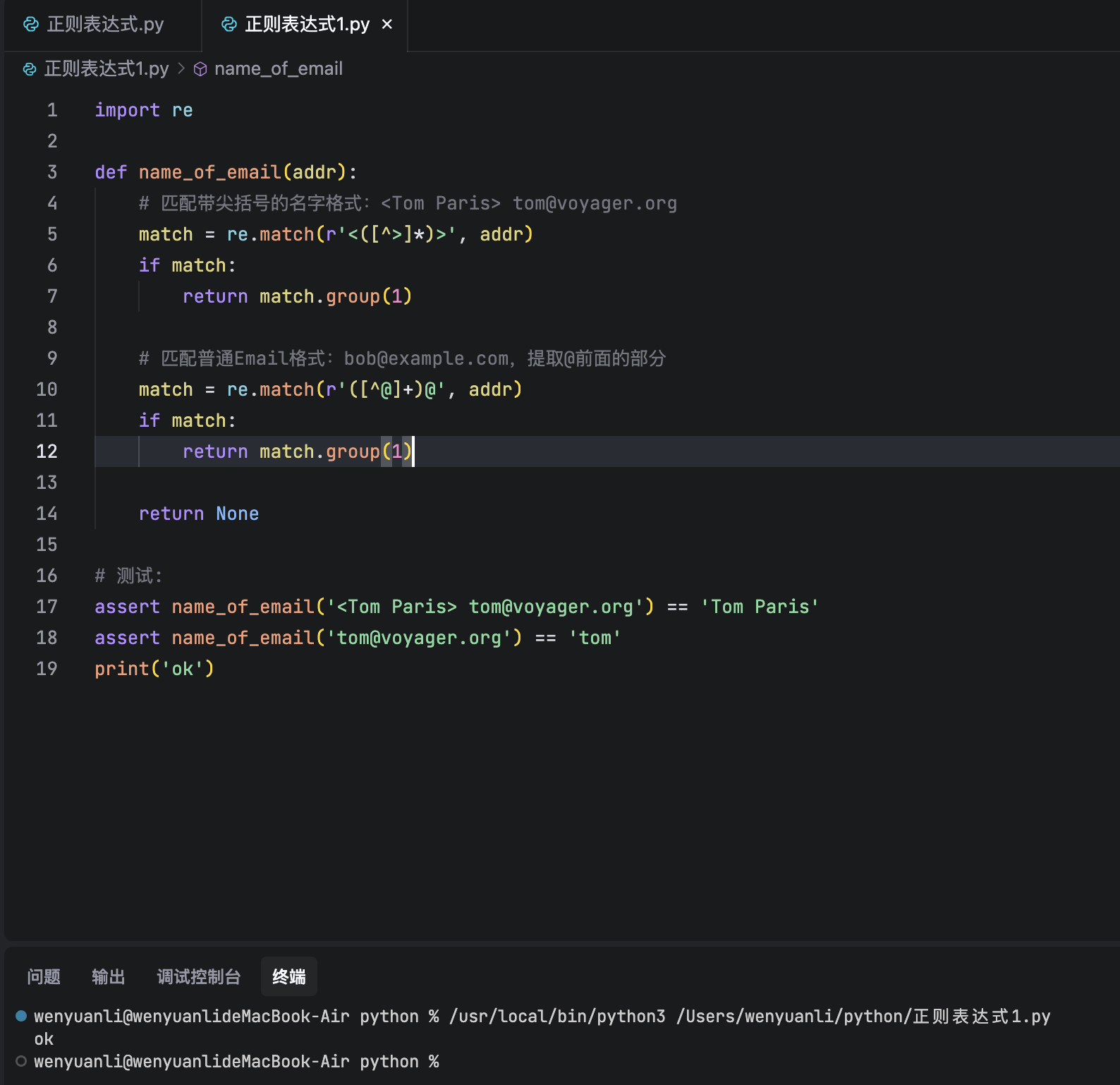
print('ok')版本二可以提取出带名字的Email地址:
- <Tom Paris> tom@voyager.org => Tom Paris
- bob@example.com => bob
import re
def name_of_email(addr):
return None
# 测试:
assert name_of_email(' tom@voyager.org') == 'Tom Paris'
assert name_of_email('tom@voyager.org') == 'tom'
print('ok') 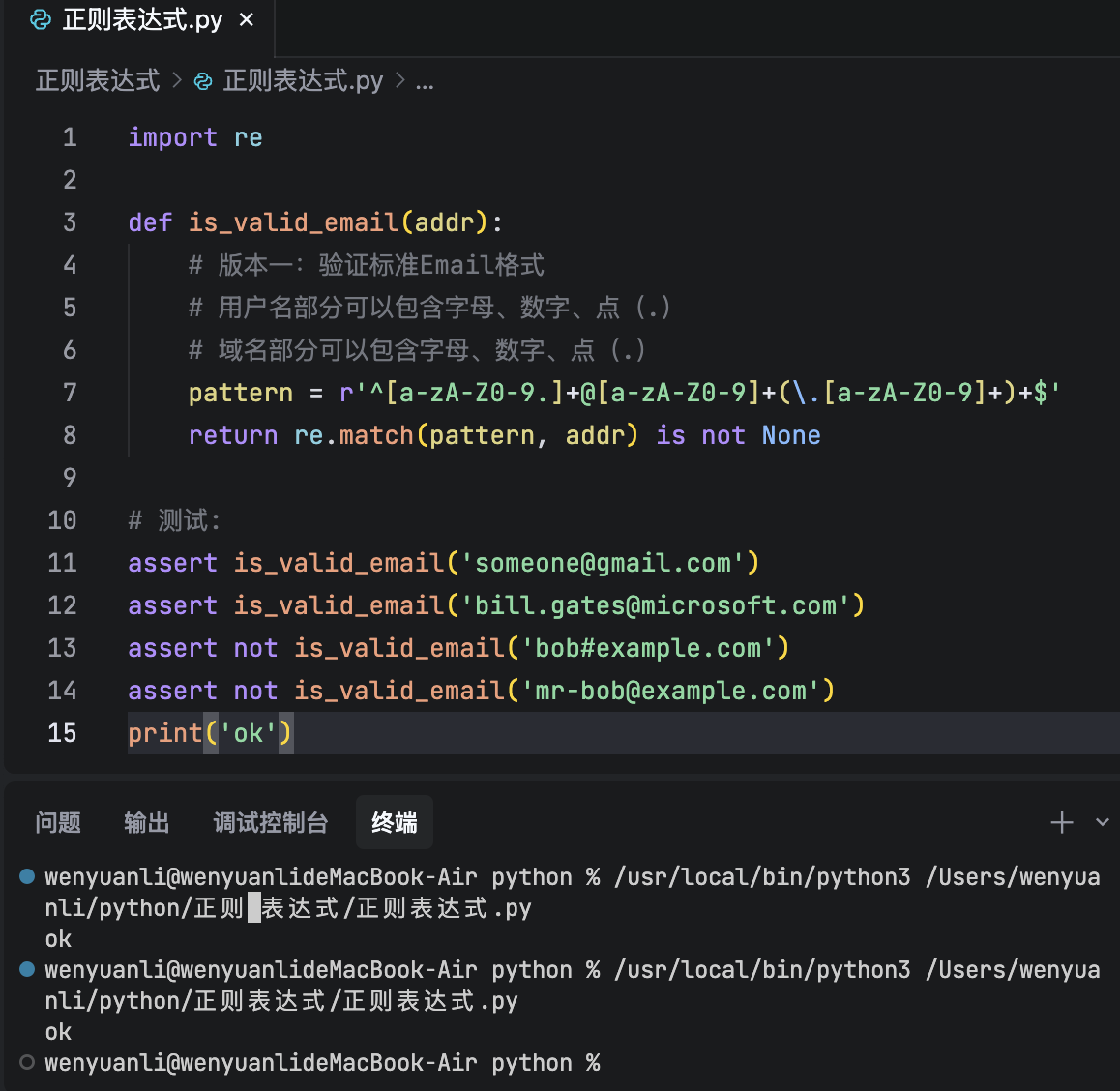

 浙公网安备 33010602011771号
浙公网安备 33010602011771号