
【消息中间件全解析】聚焦主流消息中间件(RocketMQ/Kafka/RabbitMQ)主流产品对比与业务场景精准选型 - 教程
前言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在微服务架构中,消息中间件是搭建“解耦、削峰、异步通信”的核心组件,从电商秒杀的流量缓冲到分布式系统的事务一致性保障,都离不开其支撑。本文聚焦主流消息中间件(RocketMQ/Kafka/RabbitMQ),通过多维度对比分析、业务场景适配指南与实战配置建议,帮你掌握“选对、用好”消息中间件的核心能力。
1. 消息中间件核心价值:为什么要求它?
在单体架构向微服务架构演进中,服务间耦合、流量波动、同步通信延迟等问题凸显,消息中间件通过“异步通信”模式,成为消除这些问题的关键工具。
1.1 三大核心作用
| 核心作用 | 解决的痛点 | 原理说明 | 示例场景 |
|---|---|---|---|
| 服务解耦 | 服务间直接依赖,一方改动导致全链路故障 | 服务通过消息中间件通信,不直接调用接口 | 订单服务→库存服务→物流服务,订单完成后发消息,库存/物流订阅消息处理 |
| 流量削峰 | 秒杀/促销场景瞬时流量冲垮下游服务 | 消息中间件缓冲请求,下游按能力消费 | 秒杀活动中,10万QPS请求先进入消息队列,支付服务按2万QPS消费 |
| 异步通信 | 同步调用链过长,响应时间累加 | 非核心流程异步处理,主流程快速返回 | 用户注册后,同步返回结果,异步发送短信/邮件通知 |
1.2 典型业务场景映射
消息中间件已渗透到后端业务的多个核心场景,不同场景对中间件的需求差异显著:
- 流量冲击场景:秒杀、促销、直播带货(需高吞吐量、低延迟);
- 异步通知场景:注册通知、订单状态变更(需可靠性、低延迟);
- 数据同步场景:日志收集、数据库binlog同步(需高吞吐、可回溯);
- 分布式事务场景:订单-支付-库存一致性(需事务消息、可靠性);
- 实时通信场景:IM聊天、实时数据推送(需低延迟、高并发)。
2. 主流消息中间件深度对比
目前工业界主流的消息中间件有三类:阿里开源的RocketMQ、Apache的Kafka、Pivotal的RabbitMQ,三者在架构设计、性能特性上差异显著,适配不同业务需求。
2.1 架构与核心特性对比
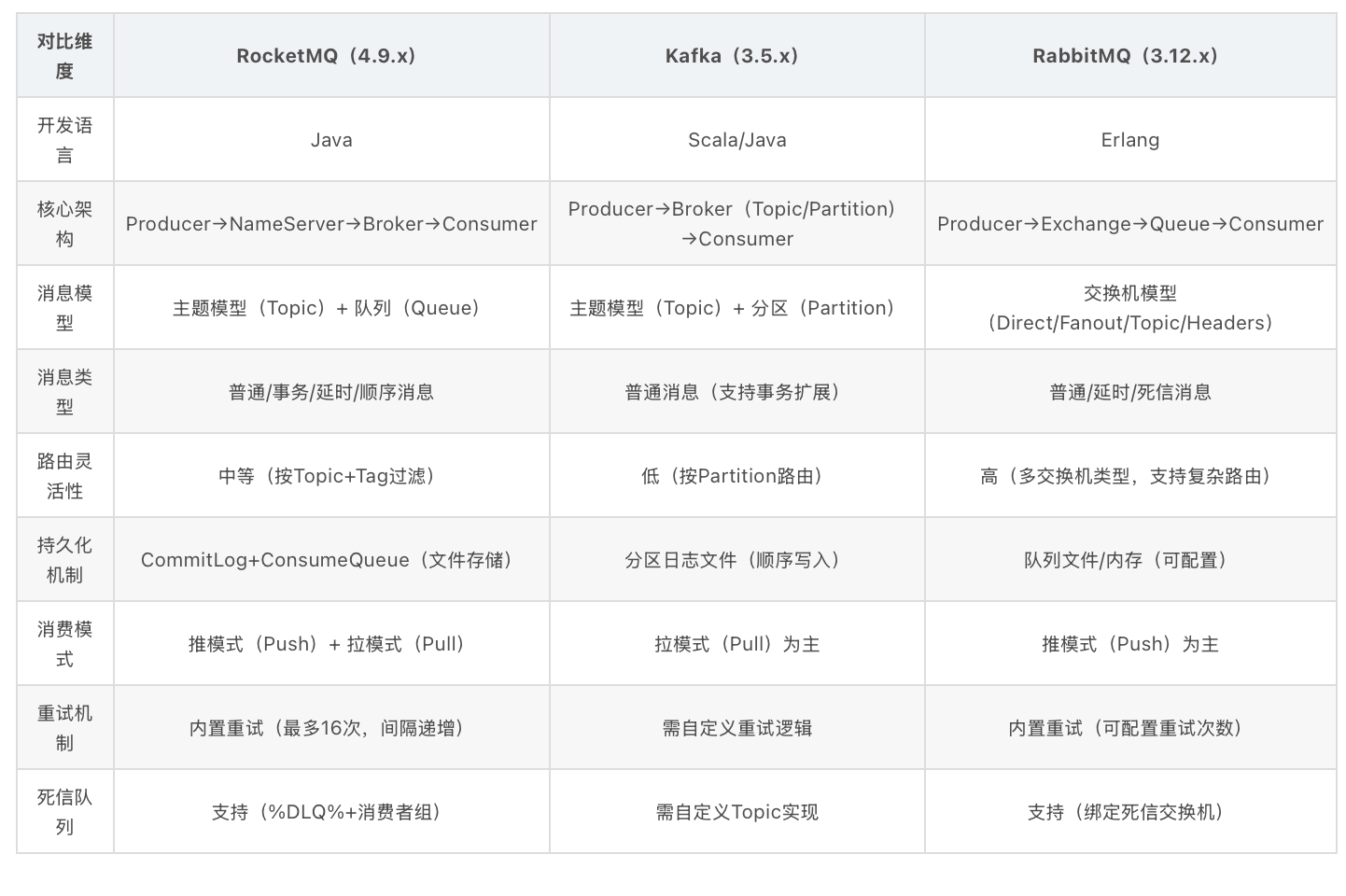
| 对比维度 | RocketMQ(4.9.x) | Kafka(3.5.x) | RabbitMQ(3.12.x) |
|---|---|---|---|
| 开发语言 | Java | Scala/Java | Erlang |
| 核心架构 | Producer→NameServer→Broker→Consumer | Producer→Broker(Topic/Partition)→Consumer | Producer→Exchange→Queue→Consumer |
| 消息模型 | 主题模型(Topic)+ 队列(Queue) | 主题模型(Topic)+ 分区(Partition) | 交换机模型(Direct/Fanout/Topic/Headers) |
| 消息类型 | 普通/事务/延时/顺序消息 | 普通消息(拥护事务扩展) | 普通/延时/死信消息 |
| 路由灵活性 | 中等(按Topic+Tag过滤) | 低(按Partition路由) | 高(多交换机类型,支持复杂路由) |
| 持久化机制 | CommitLog+ConsumeQueue(文件存储) | 分区日志文档(顺序写入) | 队列文件/内存(可配置) |
| 消费模式 | 推模式(Push)+ 拉模式(Pull) | 拉模式(Pull)为主 | 推模式(Push)为主 |
| 重试机制 | 内置重试(最多16次,间隔递增) | 需自定义重试逻辑 | 内置重试(可配置重试次数) |
| 死信队列 | 帮助(%DLQ%+消费者组) | 需自定义Topic实现 | 支持(绑定死信交换机) |
2.2 性能指标对比(实测信息,单机8核16GB)
| 性能指标 | RocketMQ | Kafka | RabbitMQ |
|---|---|---|---|
| 峰值吞吐量 | 10万+ TPS(普通消息,同步刷盘) | 100万+ TPS(批量消息,异步刷盘) | 万级 TPS(普通消息,默认部署) |
| 端到端延迟 | 1-10ms(普通消息) | 1-5ms(普通消息) | 0.1-1ms(轻量消息) |
| 消息堆积能力 | 亿级(支持磁盘扩容) | 亿级(分区日志存储) | 百万级(默认配置,需优化) |
| 单机最大队列数 | 万级(Topic+Queue) | 千级(Partition,过多影响性能) | 万级(Queue,需优化内存) |
| 最大消息大小 | 默认4MB(可配置至64MB) | 默认1MB(可配备至100MB) | 默认128MB(可配置) |
2.3 生态与运维成本对比
| 对比维度 | RocketMQ | Kafka | RabbitMQ |
|---|---|---|---|
| 社区活跃度 | 高(阿里维护,中文文档丰富) | 极高(Apache顶级项目,全球社区) | 高(开源社区成熟,插件丰富) |
| 监控工具 | RocketMQ Dashboard | Kafka Eagle/Grafana+Prometheus | RabbitMQ Management UI/ Prometheus |
| 运维复杂度 | 中(Java生态,配置项较少) | 高(需调优分区/副本/刷盘参数) | 中(Erlang语言门槛,插件化运维) |
| 云服务支持 | 阿里云RocketMQ(商业版) | 阿里云消息服务Kafka版/AWS MSK | 阿里云消息服务RabbitMQ版/AWS MQ |
| 客户端语言支持 | Java为主(C++/Go客户端较少) | 多语言(Java/Go/Python/Scala) | 多语言(全语言覆盖,客户端成熟) |
| 学习成本 | 低(Java开发者易上手,API简洁) | 中(需理解分区/副本机制) | 中(需理解交换机路由模型) |
3. 业务场景精准选型指南
选择消息中间件的核心逻辑是“业务需求匹配技术特性”,而非盲目追求“高性能”或“功能全”。以下针对四大典型业务场景给出选型建议。
3.1 电商核心场景选型
电商场景涵盖秒杀、订单、库存等关键链路,对“吞吐量、可靠性、延迟”均有较高要求:
| 电商子场景 | 核心需求 | 推荐中间件 | 不推荐原因 | 配置建议 |
|---|---|---|---|---|
| 秒杀/促销 | 高吞吐(10万+ TPS)、低延迟、防超卖 | Kafka/RocketMQ | RabbitMQ(吞吐量不足) | Kafka:分区数=CPU核心数×2,异步刷盘;RocketMQ:主从同步,批量发送 |
| 订单状态流转 | 可靠性(不丢消息)、顺序性(状态按序更新) | RocketMQ | Kafka(顺序消息需自定义) | 启用事务消息,单Queue保证顺序,同步刷盘 |
| 库存扣减通知 | 可靠性、重试机制(避免库存不一致) | RocketMQ/RabbitMQ | Kafka(重试需自定义) | RocketMQ:设置重试次数16次;RabbitMQ:绑定死信队列 |
| 物流/短信通知 | 低延迟、异步处理(不阻塞主流程) | 三者均可 | - | 异步发送,批量消费,非核心链路可降级 |
3.2 分布式事务场景选型
分布式事务需保证“最终一致性”,核心依赖“事务消息”机制:
| 事务场景 | 核心需求 | 推荐中间件 | 实现方案 | 注意事项 |
|---|---|---|---|---|
| 订单-支付-库存 | 两阶段提交、回查机制、不丢消息 | RocketMQ | RocketMQ事务消息:半事务消息→本地事务→提交/回滚 | 避免长事务,本地事务执行时间<300ms |
| 跨服务数据同步 | 最终一致性、重试幂等 | RocketMQ/Kafka | Kafka:基于事务API;RocketMQ:事务消息 | 消费端实现幂等(如唯一消息ID去重) |
| 数据导入(批量) | 高吞吐、可回溯(失败重试) | Kafka | RabbitMQ(批量处理能力弱) | 分区并行消费,批量提交offset,失败重试分区 |
3.3 日志/数据同步场景选型
此类场景以“高吞吐、可持久化”为核心,对延迟敏感度较低:
| 同步场景 | 核心需求 | 推荐中间件 | 优势体现 | 部署建议 |
|---|---|---|---|---|
| 应用日志收集 | 超高吞吐(百万级 TPS)、持久化、可回溯 | Kafka | 分区日志存储,承受日志压缩,成本低 | 多Broker集群,分区数=日志源数量,异步刷盘 |
| 数据库binlog同步 | 顺序性(binlog按序消费)、高吞吐 | Kafka/RocketMQ | RabbitMQ(顺序性需复杂安装) | Kafka:单分区保证binlog顺序;RocketMQ:单Queue消费 |
| 搜索引擎同步 | 低延迟(近实时同步)、批量消费 | Kafka/RocketMQ | - | 批量拉取(批量大小=100-1000),消费端异步写入ES |
3.4 实时通信场景选型
实时场景对“低延迟、高并发连接”要求苛刻:
| 实时场景 | 核心需求 | 推荐中间件 | 技术优势 | 限制说明 |
|---|---|---|---|---|
| IM聊天(单聊) | 低延迟(<100ms)、高并发连接 | RabbitMQ(Direct交换机) | 推模式低延迟,支持点对点通信 | 单节点连接数<10万,需集群扩展 |
| 实时数据推送(如股价) | 低延迟、广播能力(一对多) | Kafka(Pub/Sub) | 分区并行推送,延迟<5ms | 消费者组数量不宜过多(<100) |
| 物联网设备消息 | 高并发(百万级设备)、低功耗 | Kafka | 批量消息减少网络交互,适合设备低功耗场景 | 设备端批量发送(每100ms一批),异步刷盘 |
4. 实战安装:关键能力落地
选对中间件后,需通过合理配置实现“可靠性、高可用、高性能”,避免“选对产品用不对”的困难。
4.1 消息可靠性保障方案(全链路)
消息丢失可能发生在“生产端→中间件→消费端”任一环节,需针对性防护:
| 链路环节 | 丢失原因 | 保障方案 | RocketMQ配置示例 | Kafka配置示例 |
|---|---|---|---|---|
| 生产端 | 网络波动、发送超时、未确认 | 1. 同步发送+重试;2. 事务消息;3. 发送确认 | producer.setRetryTimesWhenSendFailed(3); | acks=all(等待所有副本确认) |
| 中间件 | 机器宕机、刷盘失败、副本同步延迟 | 1. 主从同步;2. 同步刷盘;3. 多副本 | brokerRole=SYNC_MASTER;flushDiskType=SYNC_FLUSH | replication.factor=3(3副本);min.insync.replicas=2 |
| 消费端 | 消费超时、异常未捕获、未提交offset | 1. 异常重试;2. 手动提交offset;3. 死信队列 | consumer.setMaxReconsumeTimes(16); | enable.auto.commit=false(手动提交) |
4.2 高可用部署架构对比
高可用的核心是“避免单点故障”,不同中间件的集群方案差异较大:
| 中间件 | 部署架构 | 故障转移机制 | 优势 | 适用规模 |
|---|---|---|---|---|
| RocketMQ | 多NameServer+主从Broker(1主2从) | 主Broker宕机,从Broker自动切换 | 切换快(<10s),配置简单 | 中小规模(1000-10000 TPS) |
| Kafka | 多Broker+分区多副本(3副本) | 分区Leader宕机,Follower选举为Leader | 横向扩展能力强,吞吐量无上限 | 大规模(10万+ TPS) |
| RabbitMQ | 主从集群+镜像队列(Mirrored Queues) | 主节点宕机,镜像节点接管 | 路由灵活,适合复杂业务 | 中小规模(1000-5000 TPS) |
生产环境最小部署建议:
- RocketMQ:3台NameServer + 2组主从Broker(共4台机器);
- Kafka:3台Broker(每台8核16GB),3副本,分区数根据业务调整;
- RabbitMQ:3节点集群,启用镜像队列,每节点4核8GB。
4.3 消息堆积与消费优化
消息堆积是高并发场景的常见问题,需从“生产限流、消费提速”双端优化:
| 优化方向 | 具体措施 | 适用场景 | 配置示例 |
|---|---|---|---|
| 生产端限流 | 1. 令牌桶限流;2. 降级非核心消息;3. 批量发送 | 秒杀/促销场景,避免中间件过载 | RocketMQ:producer.setSendMsgTimeout(1000);(超时降级);Kafka:批量发送大小batch.size=16384 |
| 消费端提速 | 1. 并行消费(增加消费线程/分区);2. 批量消费;3. 异步处理 | 消费能力不足,堆积持续增加 | RocketMQ:consumer.setConsumeThreadMin(20);;Kafka:增加Consumer实例数=分区数 |
| 中间件优化 | 1. 扩容Broker;2. 调整刷盘策略;3. 清理历史消息 | 长期堆积,磁盘空间不足 | Kafka:配置日志保留时间log.retention.hours=24;RocketMQ:开启文件清理deleteWhen=04 |
5. 常见问题与解决方案
即使配置合理,消息中间件仍可能出现异常,需掌握高频问题的排查思路。
5.1 消息丢失:全链路排查
| 丢失场景 | 排查步骤 | 解决方案 | 工具支撑 |
|---|---|---|---|
| 生产端发送无响应 | 1. 查生产端日志是否有发送失败;2. 查中间件是否收到消息;3. 查网络是否通 | 1. 增加重试次数;2. 启用发送确认;3. 更换网络链路 | RocketMQ:mqadmin sendMsgStatus;Kafka:kafka-console-producer |
| 中间件存储丢失 | 1. 查Broker日志是否有刷盘错误;2. 查副本同步状态;3. 查磁盘是否损坏 | 1. 切换主从;2. 恢复数据;3. 更换磁盘 | RocketMQ:mqadmin clusterList;Kafka:kafka-topics --describe |
| 消费端未消费 | 1. 查消费端是否在线;2. 查是否有消费异常日志;3. 查offset是否提交 | 1. 重启消费端;2. 修复消费逻辑;3. 重置offset | RocketMQ:Dashboard消费进度;Kafka:kafka-consumer-groups --describe |
5.2 消息重复消费:幂等性设计
重复消费的根本原因是“消费确认机制的不确定性”,需利用幂等性解决:
| 业务场景 | 幂等实现方案 | 优点 | 注意事项 |
|---|---|---|---|
| 订单创建 | 消息ID+Redis去重(SET NX,过期时间30分钟) | 实现简单,性能高 | 确保消息ID全局唯一 |
| 库存扣减 | 数据库唯一索引(订单ID+商品ID) | 可靠性高,避免超卖 | 需处理唯一索引冲突异常 |
| 数据同步 | 基于版本号(如ES文档版本) | 支持更新,避免覆盖最新数据 | 版本号需自增,消费端按版本号更新 |
5.3 死信队列:异常消息处理
死信队列用于存储“消费失败且重试耗尽”的消息,避免影响正常消息消费:
| 中间件 | 死信队列配置方式 | 处理流程 | 监控建议 |
|---|---|---|---|
| RocketMQ | 自动创建(%DLQ%+消费者组) | 1. 死信消息入队;2. 监控告警;3. 人工处理/重投 | Dashboard查看死信队列长度,配置告警阈值 |
| Kafka | 自定义死信Topic,消费失败时发送至此 | 1. 消费异常时手动发送;2. 定时重投 | 监控死信Topic的消息量,超过阈值告警 |
| RabbitMQ | 队列绑定死信交换机(x-dead-letter-exchange) | 1. 重试耗尽后路由至死信队列;2. 重投或人工处理 | Management UI查看死信队列,配置消费者重投 |
6. 总结与选型决策树
核心选型结论
- 优先选RocketMQ:电商核心业务(订单/库存/秒杀)、分布式事务场景,Java技术栈团队,追求“可靠性+易用性”;
- 优先选Kafka:日志收集、大信息同步、超高吞吐场景(10万+ TPS),多语言团队,能接受较高运维成本;
- 优先选RabbitMQ:复杂路由场景(如IM聊天、多系统通知)、低延迟轻量消息,能接受较低吞吐量。
选型决策树(快速判断)
graph TD
A[业务场景] --> B{核心需求}
B -->|高吞吐(>10万TPS)+ 持久化| C[选Kafka]
B -->|可靠性+事务消息+Java栈| D[选RocketMQ]
B -->|复杂路由+低延迟轻量消息| E[选RabbitMQ]
B -->|不确定?| F[看团队技术栈:Java→RocketMQ,多语言→Kafka/RabbitMQ]最好的。就是消息中间件的价值不仅是“传递消息”,更是“架构解耦的桥梁”与“流量治理的程序”。在实际落地中,需结合业务优先级(如“可靠性优先”还是“性能优先”)、团队工艺能力、运维成本综合决策,避免盲目追求“最先进”或“功能最全”的产品——适合业务的才

 浙公网安备 33010602011771号
浙公网安备 33010602011771号