
T2S:增加与优化(上) - 教程
之前在Text2SQL、ChatBI简介介绍过T2S的基本概念,基准测试、开源项目、工程实践;实际上,因LLM的火热,T2S在学术界也是非常热门的研究领域。
注:本文搜集网络资料,汇总成文,没有多少原创性。
综述
论文。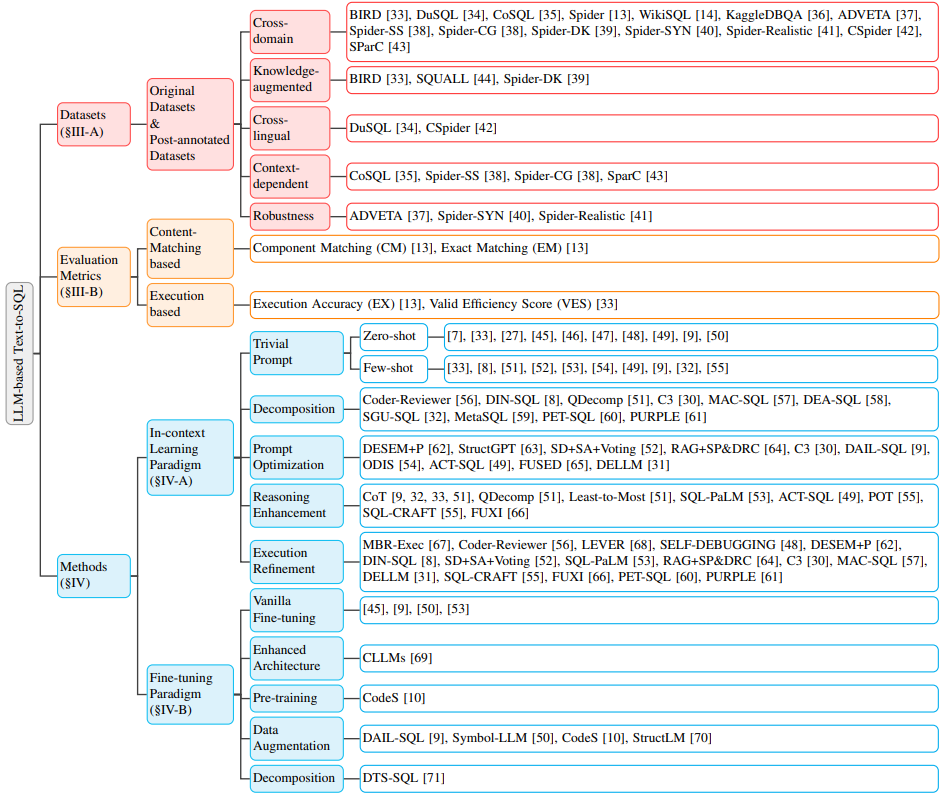
演进
- Rule:早期T2S系统主要依赖于规则和模板;
- DL:深度神经网络被引入T2S领域;
- PLM:PLM在大规模语料上进行预训练,积累丰富的语言知识和语义理解能力;
- LLM:LLM因其强大的文本生成能力备受关注。
挑战
- 语言复杂性和歧义性:自然语言的灵活性和多样性是T2S任务中的巨大挑战;
- Schema理解与表示:数据库Schema的复杂性和多样性要求T2S环境能够有效表示和编码Schema信息;
- 罕见和复杂的SQL执行:实际应用中SQL查询可能涉及不常见或复杂的操作和语法;
- 跨域泛化:不同领域的数据库在词汇使用、Schema结构和问题模式上存在显著差异。
数据集
- BIRD:跨域和知识增强特性
- KaggleDBQA:跨域场景研究
- DuSQL:跨域且跨语言的数据集
- SQUALL:提供更精细的监督信息
- CoSQL:探索上下文相关的SQL生成
- Spider:广泛应用的资料集,跨域T2S任务
- WikiSQL:早期跨域T2S研究
评估指标
- 基于内容匹配的指标:组件匹配(Component Match,CM)和精确匹配(Exact Match,EM)
- 基于执行结果的指标:执行准确性(Execution Accuracy,EX)和有效效率分数(Valid Efficiency Score,VES)
展望
- 鲁棒性:在实际应用场景中,需进一步提高鲁棒性;
- 计算效率:随着数据库复杂度的提高,基于LLM的T2S工艺在计算效率方面面临着严峻挑战;
- 数据隐私和可解释性:在基于LLM的T2S研究中,数据隐私和可解释性是两个重要但尚未得到充分应对的疑问;
- 扩展:T2S技术在与其他领域的交叉融合中具有巨大潜力,未来的研究应积极探索这些扩展方向;
方法
综述里汇总的方法包括:
- 上下文学习(In-Context Learning,下文统一检查ICL):一种无需对模型进行额外训练的方法,依赖于为LLM精心设计的提示词来激发其生成SQL查询的能力。核心在于,通过构造合适的上下文环境,使模型能够在没有显式训练信号的情况下结束困难任务。
- 简单提示(Trivial Prompt):研究者尝试通过直接或极少量的示例来引导模型理解任务要求,包括两种形式:
- 零样本学习(Zero-shot):在没有任何先前示例的情况下,模型需要直接根据输入的问题生成SQL查询。对模型的理解能力和泛化能力提出极高要求;
- 少样本学习(Few-shot):提供少量示例来帮助模型理解任务的上下文,并生成相应的SQL查询。试图通过有限示例来引导模型学习任务特定的模式。
- 分解(Decomposition):将复杂问题拆解为简单子问题,依据多个步骤或使用多个模型协同应对,使LLM能够更专注于问题的特定部分,从而提高SQL生成的准确性。
- DIN-SQL:通过模式链接、分类与分解、SQL生成和自我纠正四个模块来处理T2S任务,每个模块负责处理任务的不同方面,最终共同完成复杂的SQL生成任务;
- Coder-Reviewer:结合生成器(Coder)和评估器(Reviewer),通过生成器产生可能的SQL查询,然后评估器评估这些查询的准确性和可能性,从而提高SQL生成的准确性。
- DTS-SQL:提出一种两阶段分解的T2S微调框架,在最终SQL生成之前,设计模式链接预生成任务。通过先进行模式链接,帮助模型更好地理解数据库模式与用户问题之间的关系,为后续准确生成SQL奠定基础。
- 提示优化(Prompt Optimization):旨在通过改进输入提示的质量来提高LLM在T2S任务中的表现。这涉及到改进少样本组织的质量和数量、增强用户问题与少样本实例之间的相似性、整合外部知识或提示等。
- DESEM:这种提示工程框架通过去语义化和骨架检索来优化提示,它先去除用户问题中的语义标记,保留问题意图,再借助可调提示模块检索具有相同难题意图的少样本示例,并结合模式相关性过滤,引导LLM生成SQL。
- SD+SA+Voting:结合语义相似性、多样性和投票机制,通过语义相似性和k-Means聚类多样性进行少样本示例采样,然后借助模式知识增强提示,最后利用投票机制选择最终的SQL查询。
- 推理增强(Reasoning Enhancement):通过增强LLM推理能力来处理需要复杂逻辑的问题,专门适用于那些需要多步骤推理或深入理解的挑战。
- CoT(Chain of Thought):通过引导LLM进行全面推理过程,促使其准确推导,激发推理能力。CoT作为规则暗示,在提示构建中设置
让我们逐步思考等指令,帮助模型逐步构建解决方案。 - PoT(Program of Thoughts):作为CoT变体,通过要求模型同时生成Python代码和SQL查询,增强算术推理能力,在复杂信息集上的评估表明PoT可提升LLM的SQL生成能力,尤其是在需要麻烦推理的情况下。
- CoT(Chain of Thought):通过引导LLM进行全面推理过程,促使其准确推导,激发推理能力。CoT作为规则暗示,在提示构建中设置
- 执行细化(Execution Refinement):利用执行反馈来优化和修正生成的SQL查询,允许模型在生成初步SQL查询后,根据实际执行结果进行调整,以提高最终查询的准确性和有效性。
- MRC-EXEC:引入自然语言到代码(NL2Code)翻译框架并执行,执行每个采样的SQL查询,选择具有最小执行结果贝叶斯风险的示例,从而优化SQL查询。
- SELF-DEBUGGING:框架教LLM通过少样本演示调试预测SQL,模型通过检查执行结果并自然语言解释生成的SQL来纠正错误,无需人工干预,提高模型的自我修正能力。
- 微调(Fine-Tuning,FT):与ICL不同,微调范式依据对开源LLM进行针对性训练来优化模型性能,允许模型凭借学习特定的数据集来适应特定的任务或领域。
- 增强架构(Enhanced Architecture):在处理复杂的数据库查询时,传统的LLM可能面临速度慢和效率低的问题。增强架构的微调方法旨在通过改进模型架构来提高SQL生成的速度和效率。
- CLLMs:通过改进模型架构,如优化注意力机制、调整模型参数设置或采用更高效的计算策略等,减少生成SQL查询时的延迟,从而在保证准确性的同时,提高系统的整体效率。
- 数据增强(Data Augmentation):通过扩充和改进训练数据来提高模型的性能,特别适用于处理那些数据稀缺或材料质量不高的情况。
- DAIL-SQL:设计为ICL框架,通过采用特定采样策略选择更好的少样本实例,并将其纳入监督微调(Supervised Fine-tuning,SFT)过程,有效提高开源LLM在T2S任务中的性能。
- 预训练(Pre-training):微调过程的基础阶段,旨在通过在大规模数据上进行自回归训练,使模型获得强大的文本生成能力。
- CodeS:模型预训练阶段包括三个阶段的增量预训练,从基本的代码特定LLM开始,依次在包含SQL相关数据、NL-to-Code数据和NL相关数据的混合训练语料库上进行训练,显著提高模型对T2S任务的理解能力。
论文
下面的论文,按照初稿发表时间排序。
DIN-SQL
论文:https://arxiv.org/abs/2304.11015
提出一种基于少样本提示的方法,将T2S任务分解为多个子任务,并经过自校正机制提高生成SQL的准确性。由四个模块组成:
- Schema Linking:模式链接,基于提示,包括从Spider内容集训练集中随机选择的10个样本。提示遵循CoT模板。对于问题中提到的每个列名,模块会从给定的数据库模式中选择相应的列和表。模块还会从问题中提取可能的实体和单元格值。
- Query Classification and Decomposition:查询分类与分解,对于每个JOIN运行,模型有时无法正确检测到所需的表或JOIN条件。随着查询中JOIN数量的增加,至少有一个JOIN操作失败的概率也会增加。通过分类标签会设置不同的提示词来应对。此外,查询分类与分解模块还会检测非嵌套和嵌套查询中必须JOIN的表集合,以及嵌套查询中可能检测到的子查询。将查询分为三类:
- Easy(便捷):单表查询,无需JOIN或嵌套;
- Non-nested Complex(非嵌套复杂):需要JOIN但无需子查询;
- Nested Complex(嵌套复杂):可能涵盖JOIN、子查询和集合操作(如EXCEPT、UNION、INTERSECT)。
- SQL Generation:SQL生成,每个子模块的提示设计不同,以适应不同复杂度的查询,根据查询的复杂性分为三个子模块:
- Easy Class:对于简单查询,使用轻松的少样本提示即可;
- Non-nested Complex Class:对于需要JOIN的查询,采用中间表示(如NatSQL)来简化从自然语言到SQL的转换;
- Nested Complex Class:对于最复杂的查询,先解除子查询,然后使用这些子查询生成最终的SQL语句。
- Self-Correction:自校正,生成的SQL查询有时会缺少或有多余的关键字(如DESC、DISTINCT和聚合函数)。为了解决这个问题,提出一个自校正模块,模型会在零样本设置下被要求修正这些小错误。设计两种不同的提示:
- Generic Prompt:通用提示,假设SQL查询有错误,要求模型识别并修正错误;
- Gentle Prompt:温和提示,不假设SQL查询有错误,而是要求模型检查潜在难题并提供一些提示。
C3
论文:https://arxiv.org/abs/2307.07306
T2S问题的定义
T2S任务的目标是将自然语言问题转换为可执行的SQL查询。给定自然语言问题和数据库模式,任务是生成与问题对应的SQL查询。其中,数据库模式包含多个表、列和外键关系。
LLMs一个重要能力是ICL,即模型能够在给定的上下文中利用少量示例学习并完成繁琐任务。ICL能够有效提升LLMs在T2S任务中的表现。然而,包含额外示例会增加手动成本和使用OpenAI API的token成本。因此,论文中独特关注零样本提示设置。
提出基于ChatGPT的零样本T2S方法,称为C3:通过三个关键组件来提升零样本T2S性能:
- 清晰提示(Clear Prompting,CP):对应模型输入
- 提示校准(Calibration with Hints,CH):对应模型偏差
- 一致性输出(Consistency Output,CO):对应模型输出
CP,目标是为T2S解析供应管用提示,两部分组成:
- Clear Layout:清晰布局,可分为两类:
- Complicated Layout:复杂布局,直接将指令、问题和数据库模式(上下文)拼接在一起,看起来比较混乱;
- Clear Layout:清晰布局,通过使用分隔符(如
###)将指令、上下文和问题分开,使得提示更加清晰易懂。
- Clear Context:清晰上下文,在提示中包含整个数据库模式会导致两个问题:
- 引入过多的无关信息会增加ChatGPT在生成SQL时选择无关模式项的可能性;
- 使用完整的数据库模式会增加提示的长度,导致生成SQL时的效率降低。
为了应对这些难题,提出模式链接方法,借助以下两个步骤来精简提示中的上下文:
- 表召回(Table Recall):根据问题从数据库中召回最相关的表;对所有表进行排序,根据它们与问题的相关性从高到低排列。使用ChatGPT生成多个召回结果,并通过自一致性方式(Self-Consistency)选择最一致的结果。
- 列召回(Column Recall):在召回的表中进一步召回最相关的列。对每个表中的列进行排序,根据它们与疑问的相关性从高到低排列。同样使用自一致性方法生成多个召回结果,并选择最一致的结果。
通过这些步骤,提示中的上下文被精简为最相关的表和列,提高生成SQL的准确性和效率。
通过对生成SQL查询中的错误进行分析,发现ChatGPT在生成SQL时存在一些固有的偏差。ChatGPT倾向于:
- 选择不必要的列:即使某些列在难题中并不需要,ChatGPT仍然会选择它们;
- 错误使用SQL关键字:例如,ChatGPT倾向于使用
LEFT JOIN、IN和OR,但这些关键字的使用往往不正确,导致生成的SQL查询包含额外的执行结果。
为了校准这些偏差,提出CH策略,凭借在提示中加入历史对话和校准提示来引导ChatGPT生成更符合预期的SQL查询。
- 提示1:指导ChatGPT只选择必要的列。例如,如果
COUNT(*)仅用于排序目的,则不应将其包含在SELECT子句中; - 提示2:指导ChatGPT避免错误使用SQL关键字,如
LEFT JOIN、IN和OR,并建议使用JOIN、INTERSECT、DISTINCT或LIMIT来避免重复的执行结果。
通过这些校准提示,ChatGPT生成的SQL查询更加符合预期,减少不必要的列和错误的SQL关键字利用。
CO:尽管通过清晰提示和提示校准,ChatGPT能够生成高质量的SQL查询,但由于LLM固有随机性,生成的SQL查询仍然存在不稳定性。为提高输出稳定性,借鉴自一致性方式,提出执行一致性(Execution-based Self-Consistency)策略。
- 生成多个SQL查询:通过多次调用ChatGPT生成多个不同的SQL查询。
- 执行SQL查询:将这些SQL查询在数据库上执行,并收集执行结果。
- 选择最一致SQL:依据投票机制选择执行结果最一致的SQL作为最终输出。
依据利用多个生成路径的集体知识,提高生成SQL查询的可靠性和稳定性。
DAIL-SQL
论文:https://arxiv.org/abs/2308.15363
主要关注三个方面:问题表示(Question Representation)、ICL和监督微调(Supervised Fine-Tuning)。这三个方面是基于LLM的T2S任务的核心组成部分。
挑战表示:在零样本场景下,给定目标挑战q qq和数据库D \mathcal{D}D,T2S的目标是最大化LLM生成正确SQL(s ∗ s^*s∗)的概率:max q ∗ P M ( s ∗ ∣ σ ( q , D ) ) \max_{q^*} \mathbb{P}_{\mathcal{M}}(s^* \mid \sigma(q,\mathcal{D}))maxq∗PM(s∗∣σ(q,D))
其中,函数σ ( q , D ) \sigma(q,\mathcal{D})σ(q,D)决定目标挑战q qq的表示方式,并从数据库D \mathcal{D}D的Schema中提取有用信息。此外,σ ( q , D ) \sigma(q,\mathcal{D})σ(q,D)还可包括任务指令、规则推导和外键信息等。
在零样本场景下,常见表示方式:
- 基本提示(Basic Prompt,BP):最简单,仅包含表结构、自然语言问题和响应前缀
_A: SELECT_,用于提示LLM生成SQL; - 文本表示提示(Text Representation Prompt,TRP):将表结构和自然语言问题都表示为文本,并添加了任务指令;
- 开放AI演示提示(OpenAI Demonstration Prompt,ODP):在提示中添加
_with no explanation_的规则推导,要求LLM生成SQL时不要解释; - 代码表示提示(Code Representation Prompt,CRP):将数据库的完整信息(包括主键和外键)编码为SQL语句,并使用注释来表示自然语言问题;
- Alpaca SFT提示(Alpaca SFT Prompt,ASP):为监督微调设计的,包含任务指令和输入信息。
ICL:在少样本场景下,除问题表示外,还需要选择和组织示例,ICL关键在于示例选择和示例组织。
常用示例选择(Example Selection):
- 随机选择(Random):从候选示例中随机选择k kk个示例;
- 问题相似性选择(Question Similarity Selection,QSS):选择与目标问题最相似的k kk个示例;
- 掩码难题相似性选择(Masked Question Similarity Selection,MQSS):凭借掩码表名、列名和值来消除领域特定信息的影响,然后计算相似性;
- 查询相似性选择(Query Similarity Selection,QRS):选择与目标SQL查询最相似的k kk个示例。
这些策略主导关注问题或查询的相似性,但论文指出,在示例选择中同时考虑问题和查询的相似性可能会对T2S任务更有利。
示例组织(Example Organization)方式:
- 全信息组织(Full-Information Organization,FIO):将示例的完整信息(包括指令、schema、问题和SQL查询)组织到提示中。
- 仅SQL组织(SQL-Only Organization,SOO):仅将示例的SQL查询组织到提示中,以节省token长度。
FIO保证示例质量,SOO则更注重数量。希望找到一种在质量和数量之间取得更好平衡的示例组织策略。
为了解决示例选择和组织中的问题,提出DAIL-SQL:
- DAIL选择(DAIL Selection):结合MQSS和QRS思想,同时考虑问题和查询的相似性来选择示例;
- DAIL组织(DAIL Organization):在保留问题-SQL映射信息的同时,经过去除数据库schema来提高token效率。
DAIL-SQL采用CRP作为问题表示,选择示例时考虑问题和查询的相似性,并组织示例以保留问题-SQL映射信息。在Spider排行榜上,DAIL-SQL刷新最佳性能,达到86.2%的执行准确率。
监督微调(SFT for T2S):为了进一步增强LLM在零样本场景下的性能,应用监督微调,包括两个子任务:
- 使用监督数据微调给定的LLM,以获得最优的LLM
- 寻找最优的问题表示。
MAC-SQL
论文:https://arxiv.org/abs/2312.11242
提出MAC-SQL,一个基于LLM的多智能体协作框架,专门用于解除T2S问题。通过将LLM作为具有不同功能的智能体,有效地解析复杂的T2S任务。由三个主要智能体组成:
- Decomposer(分解器):负责将复杂问题,通过生成一系列中间步骤(即子问题和子SQL),分解为更简单的子问题,并通过CoT逐步解决这些难题;
- Selector(选择器):当数据库规模较大时,选择器会将大型数据库分解为较小子数据库(从完整的数据库模式中选择与用户疑问相关的最小子模式),以减少无关信息干扰;只在数据库模式的长度超过某个阈值时被激活,否则直接使用完整的数据库模式。
- Refiner(精炼器):负责检测和自动纠正生成的SQL查询中的错误,确保SQL语法的正确性和执行的可行性。通过外部SQL工具执行SQL查询,获取反馈并进行修正。
METASQL
论文:https://arxiv.org/abs/2402.17144,GitHub
MCS-SQL
论文:https://arxiv.org/abs/2405.07467
主要涉及三个步骤:
- 模式链接:目标是从数据库模式中提取与自然语言困难相关的表和列。分为两个子步骤:
- 表链接(Table Linking):获取与难题相关的表集合;
- 列链接(Column Linking):获取与困难相关的列集合。
- 多SQL生成:基于多个不同的提示生成多样化的候选SQL查询,有两种方法:
- 基于问题相似性选择:计算嵌入相似度,选择相似度最高的k kk个问题;
- 基于掩码障碍相似性选择:对问题进行掩码,计算掩码挑战嵌入相似度,同样也是选择相似度最高的k kk个问题。
- 选择:从生成的候选SQL查询中选择最准确的查询,分为两个子步骤:
- 候选过滤(Candidate Filtering),几个过程:
- 执行过滤:在数据库上执行所有候选SQL查询,移除导致语法错误或超时的查询;
- 置信度计算:对于每个查询,计算其置信度分数;
- 时间过滤:在具有相同执行结果的查询中,仅保留执行时间最短的查询;
- 置信度过滤:移除置信度分数低于阈值的查询。
- 多选选择(Multiple-Choice Selection,MCS):输出最终选择的SQL查询:
- 将上一步结果集,按置信度分数降序排列,生成多选问题;
- LLM从多选问题中选择最准确的查询,并经过多数投票确定最终结果。
- 候选过滤(Candidate Filtering),几个过程:
CHESS
论文:https://arxiv.org/abs/2405.16755。
Contextual Harnessing for Efficient SQL Synthesis简写,一个端到端的T2S系统,专门为困难的现实世界数据库设计。依据一个由三个主要组件组成的可扩展且高效的LLM管道来建立这一目标:实体和上下文检索、模式选择和SQL生成。
实体和上下文检索
作为管道第一步,识别输入中的相关信息,包括问题中提到的实体以及数据库模式中提供的上下文信息。分为三个步骤:
- 关键词提取:利用少样本示例提示模型,要求其识别和提取关键词、关键短语和命名实体。
- 实体检索:从问题中提取的关键词中,有些可能对应数据库中的实体。在这一步中,搜索数据库中与关键词相似的值,并返回每个关键词最相关的结果及其对应的列。为了处理关键词的变体或拼写错误,使用编辑距离相似度度量来衡量关键词和数据库值之间的语法相似性。此外,为了提高检索效率,提出一种基于局部敏感哈希(LSH) 的分层检索策略,结合语义(嵌入)相似性度量。
- 上下文检索:除了值之外,数据库目录(解释模式的元材料)也可能可用。例如,每个列可能有描述、扩展列名(在缩写情况下)和值描述。我们通过查询向量数据库,使用语义(嵌入)相似性度量来检索与提取的关键词最相似的描述。
模式选择
目标是缩小模式范围,只包括生成SQL查询所需的表和列。通过排除无关信息,实现高效模式许可提高SQL查询生成的性能。使用召回率和精确度指标来确定是否选择了正确的表和列,并以正确的SQL查询作为基准。
- 单列过滤:数据库可能涵盖数百个列,其中许多可能与问题语义无关。通过将每个列的相关性视为二分类任务,要求LLM判断该列是否可能与问题相关,从而过滤掉无关列。
- 表选择:在过滤掉无关列后,继续选择生成SQL查询所需的表。向模型提供前一步过滤后的模式,并要求其评估每个表的相关性,选择必要的表。
- 最终列选择:在模式选择的最后一步,旨在将模式缩小到生成SQL查询所需的最小列集。通过提示模型评估过滤后的表中每个列的必要性,并解释为什么得每个列。
查询生成
第一生成一个候选SQL查询,然后对其进行修订以修复潜在的语义和语法错误。
- 候选生成:在将模式缩小到最小的表和列集后,提示模型生成一个回答疑问的SQL查询。在提示中,献出了前几步中获得的最小模式,以及在管道第一步中检索到的相关值和描述。模型生成一个候选SQL查询。
- 修订:在管道的最后一步,旨在修复候选SQL查询中的潜在逻辑和语法错误。向模型提供数据库模式、问题、生成的候选SQL查询及其执行结果。模型被要求评估SQL查询的正确性,并在必要时进行修订。
预处理
为了在管道执行期间加速信息检索过程,在执行管道之前对数据库值和目录进行预处理。对于数据库值,经过创建LSH索引来执行语法搜索。对于数据库目录,运用向量数据库检索方法来衡量语义相似性。
- 数据库值的LSH索引:为了优化实体检索步骤,使用了一种能够高效搜索包含数百万行的数据库的方法。使用LSH来索引数据库中的唯一值,然后在实体检索步骤中查询此索引,快速找到与关键词最相似的值。
- 描述的向量数据库:为了从数据库目录中提取最语义相关的信息,预处理描述并将每个描述的嵌入向量存储在向量数据库中。在上下文检索步骤中,查询此向量数据库,找到与问题最相关的描述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号