
深入解析:Linux 进程深度解析(三):调度算法、优先级调整与进程资源回收(wait与waitpid)

在前两篇文章中,我们探索了进程的本质、生命周期中的各种状态,以及 fork 如何创造新生命。现在,我们来到了这个系列的终章,将解答三个终极问题:
- CPU 资源是如何在众多进程间分配的? (调度算法)
- 我们如何人为干预,让关键任务优先执行? (优先级调整)
- 父进程如何优雅地为子进程 “送终”,彻底杜绝僵尸? (wait/waitpid)
这篇文章将带你深入内核的资源管理核心,通过原理、命令与代码,让你不仅理解 Linux 的调度智慧,更能亲手掌控进程的优先级,编写出健壮、无资源泄漏的程序。
文章目录
一、进程调度:CPU 时间的艺术化分配
在一个多任务操作系统中,进程数量远多于 CPU 核心数。进程调度的本质,就是制定一套规则,决定在某个时刻,哪个进程有权使用 CPU,以及能使用多久。这套规则就是调度算法。
1.1 调度的目标:在公平与效率之间寻求平衡
调度器需要解决两个核心矛盾:
- 公平性 (Fairness):确保每个进程都能获得合理的 CPU 时间,防止低优先级进程 “饿死” (starvation)。
- 高效性 (Efficiency):最大化 CPU 的利用率,减少进程切换的开销,提升系统整体吞吐量。
1.2 Linux 的主流选择:CFS 完全公平调度器
Linux 的调度器从早期的 O(1) 调度器演进到了目前主流的 CFS (Completely Fair Scheduler)。CFS 的核心思想极其简洁:力求让每个进程享有的 CPU 时间绝对公平。
| 调度器 | 核心思想 | 优点 | 缺点 |
|---|---|---|---|
| O(1) 调度器 | 基于固定的优先级队列,高优先级先执行。 | 实时强劲,硬性保证高优先级任务。 | 公平性差,低优先级进程易 “饿死”。 |
| CFS 调度器 | 追求完全公平,通过权重调整实现优先级。 | 公平性极佳,响应流畅,无饥饿问题。 | 实时性略逊于 O(1),但对通用场景更优。 |
1.3 CFS 的实现智慧:虚拟运行时间 (vruntime)
CFS 如何做到 “公平”?它为每个进程维护一个 虚拟运行时间 (vruntime)。调度器总是选择 vruntime 最小的进程来执行。
可以这样理解:
- vruntime 就像一个 “已运行时间” 的账本。
- 一个进程运行得越久,它的 vruntime 就越大。
- 调度器每次都挑那个 “欠账” 最多的(vruntime 最小)进程来运行,以求 “追平” 大家的运行时间。
优先级如何体现?
优先级通过权重 (weight) 影响 vruntime 的增长速度。公式简化为:
vruntime 增长量 = 实际运行时间 × (NICE_0_LOAD / 进程权重)
NICE_0_LOAD是一个基准权重(对应 nice 值为 0)。- 优先级越高,权重越大,vruntime 增长得越慢。
- 因此,高优先级进程可以 “跑更久” 才会轮到别人,从而获得了更多的 CPU 时间。
为了高效地找到 vruntime 最小的进程,CFS 在内部使用红黑树来组织就绪队列,确保查找和更新操作都极为迅速。
二、进程优先级:让你的进程 “插队”
理解了调度,我们自然想知道如何影响它。Linux 提供了优先级 (Priority) 和 nice 值 (NI) 两个指标来调整进程的调度权重。
2.1 PRI 与 NI:谁决定了优先级?
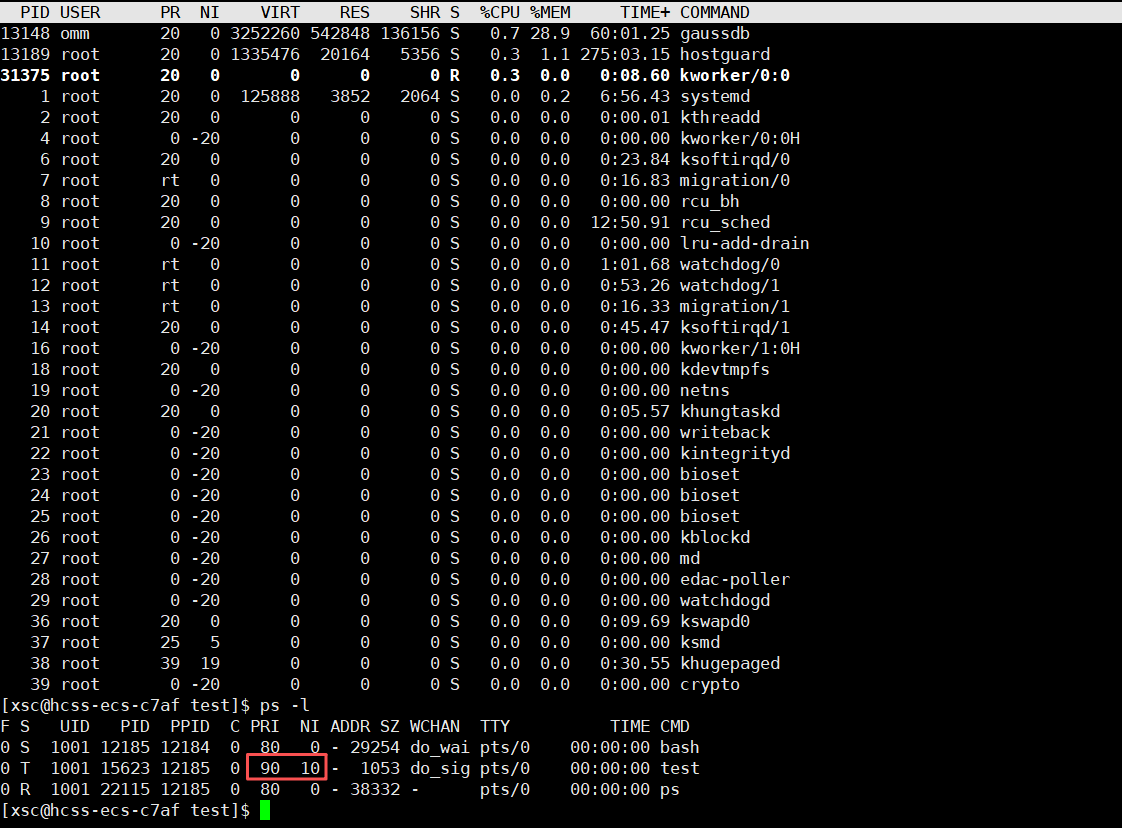
通过 ps -l 或 ps -la 命令,我们可以看到这两个关键值:

- PRI (Priority):内核内部使用的实际优先级,值越小,优先级越高。范围 0-139。
- NI (Nice Value):用户空间用于调整优先级的 “修正值”,值越小,优先级越高。范围 -20 到 19。
它们的关系是:PRI(new) = PRI(old) + NI。对于普通进程,通常 PRI(old) 是 80,所以:
PRI = 80 + NI
NI = -20(最高优先级):PRI = 60NI = 0(默认优先级):PRI = 80NI = 19(最低优先级):PRI = 99
2.2 调整优先级的 3 个命令
调整 NI 值是普通用户影响调度的唯一方式,但权限受限:
- 普通用户:只能调高 NI 值(降低自己进程的优先级),不能调低。
- root 用户:可以任意设置 NI 值。
| 命令 | 用途 | 示例 (需要 root 权限才能降低 NI 值) |
|---|---|---|
nice | 启动新进程时指定 NI 值 | sudo nice -n -10 ./my_app (以高优先级启动) |
renice | 修改已运行进程的 NI 值 | sudo renice -10 -p <PID> (提升已运行进程的优先级) |
top | 交互式修改已运行进程 | 在 top 中按 r,输入 PID 和新的 NI 值。 |
三、进程回收:wait 与 waitpid 的救赎
我们已经知道,僵尸进程的根源在于父进程没有回收子进程的退出信息。wait() 和 waitpid() 就是内核提供的 “收尸” 工具。
3.1 wait():阻塞式回收
wait() 会阻塞父进程,直到任意一个子进程结束,并返回该子进程的 PID。
函数原型:
#include <sys/wait.h>
pid_t wait(int *status);status:一个整型指针,用于接收子进程的退出状态。如果为NULL,则表示不关心。
代码示例 (解决僵尸问题):
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
printf("Child (PID: %d) is running...\n", getpid());
sleep(2);
exit(42); // 子进程以退出码 42 退出
} else {
int status;
printf("Parent waiting for child...\n");
pid_t child_pid = wait(&status); // 阻塞等待
if (WIFEXITED(status)) { // 检查是否正常退出
printf("Parent collected child %d, exit code: %d\n",
child_pid, WEXITSTATUS(status));
} else {
printf("Child %d terminated abnormally.\n", child_pid);
}
}
return 0;
}WIFEXITED(status):宏,如果子进程正常退出,则为真。WEXITSTATUS(status):宏,提取子进程的退出码。
3.2 waitpid():更灵活的精准回收 (推荐)
wait() 功能有限。waitpid() 提供了更精细的控制,是实际开发中的首选。
函数原型:
pid_t waitpid(pid_t pid, int *status, int options);参数详解:
pid(指定回收目标):> 0: 只等待 PID 为pid的那个子进程。-1: 等待任意子进程 (等同于wait())。0: 等待同一进程组的任意子进程。< -1: 等待指定进程组(其 GID 为pid的绝对值)的任意子进程。
status: 与wait()相同。options(控制等待方式):0: 阻塞等待。WNOHANG: 非阻塞等待。如果没有子进程退出,waitpid()会立即返回0,而不是阻塞父进程。
非阻塞回收示例:
父进程可以在执行自己的任务的同时,周期性地检查子进程是否退出。
// ... (fork a child process) ...
// Parent process loop
while (1) {
int status;
pid_t result = waitpid(child_pid, &status, WNOHANG);
if (result == 0) {
// Child is still running, parent can do other work
printf("Parent is working...\n");
sleep(1);
} else if (result > 0) {
// Child has exited, collect it
if (WIFEXITED(status)) {
printf("Parent collected child, exit code: %d\n", WEXITSTATUS(status));
}
break; // Exit loop
} else {
// Error
perror("waitpid");
break;
}
}waitpid 的非阻塞能力对于需要管理多个子进程的服务器程序至关重要。
四、进程切换:保存现场,恢复现场
当调度器决定从进程 A 切换到进程 B 时,内核必须执行一次上下文切换 (Context Switch),以确保进程能从它上次离开的地方无缝地继续执行。
4.1 什么是 “进程上下文”?
进程上下文是内核为描述进程运行状态而维护的所有数据的集合。最核心的部分是 CPU 寄存器的状态,包括:
- 通用寄存器:存储变量和计算结果。
- 程序计数器 (PC):指向下一条要执行的指令地址。
- 栈指针 (SP):指向当前函数调用的栈顶。
- 页表基址寄存器 (如 CR3):决定进程的内存视图。
这一部分暂且简单了解即可
4.2 上下文切换的步骤
- 保存旧进程上下文:内核将当前 CPU 中所有寄存器的值保存到进程 A 的 PCB (
task_struct) 中。 - 加载新进程上下文:内核从进程 B 的 PCB 中取出它上次保存的寄存器值,加载到 CPU 的寄存器中。
- 切换地址空间:更新 CPU 的页表基址寄存器,指向进程 B 的页表。这是最关键的一步,它改变了 CPU 的 “内存视野”。
切换完成后,CPU 的程序计数器指向了进程 B 的下一条指令,进程 B 开始执行,仿佛它从未被打断过。
4.3 切换的代价
上下文切换并非没有成本。它的开销主要来自:
- 直接开销:保存和恢复寄存器所需的时间。
- 间接开销:切换页表会导致 CPU 的 TLB (Translation Lookaside Buffer) 缓存失效,使得新进程在初期访问内存时速度变慢。此外,CPU 缓存中与旧进程相关的数据也可能失效。
过于频繁的切换会消耗大量 CPU 时间,降低系统整体性能,这也是调度算法设计时需要权衡的重要因素。
五、系列总结与展望
至此,我们完成了对 Linux 进程核心概念的深度探索:
- 进程的本质:是内核管理资源的实体,由 PCB + 代码与数据 构成。
- 进程的状态:
R(运行/就绪),S(睡眠),D(磁盘等待),T(停止),Z(僵尸),共同描绘了进程的生命周期。 - 进程的创建与管理:
fork通过写时复制高效创建子进程;孤儿进程被init收养,而僵尸进程则需要父进程通过wait或waitpid来回收。 - 进程的调度与资源:CFS 调度器通过
vruntime追求公平,而我们可以用nice和renice调整优先级来影响调度。上下文切换是实现多任务的基础,但伴随着性能开销。
掌握了这些,你不仅能从容应对面试,更能深入理解 Linux 系统的运行机制。
然而,进程的世界远不止于此。你是否想过,父进程是如何将自己的信息(例如,特定的路径配置)传递给子进程的? 这就引出了我们下一篇的主题——环境变量。它将揭示进程间信息传递的一种重要机制,并解释为什么你在任何地方都能执行 ls 这样的命令。敬请期待!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号