
SpiderBuf--爬虫练习网站手把手带练(最新独特版1-10) - 实践
网站:Python 爬虫实战练习案例 - Python 爬虫练习网站
这是一个爬虫练习网站 适合练习 查漏补缺
第一题:
Ctrl+U 查看页面源代码 然后 Ctrl+F 打开搜索框 搜索我们想要的内容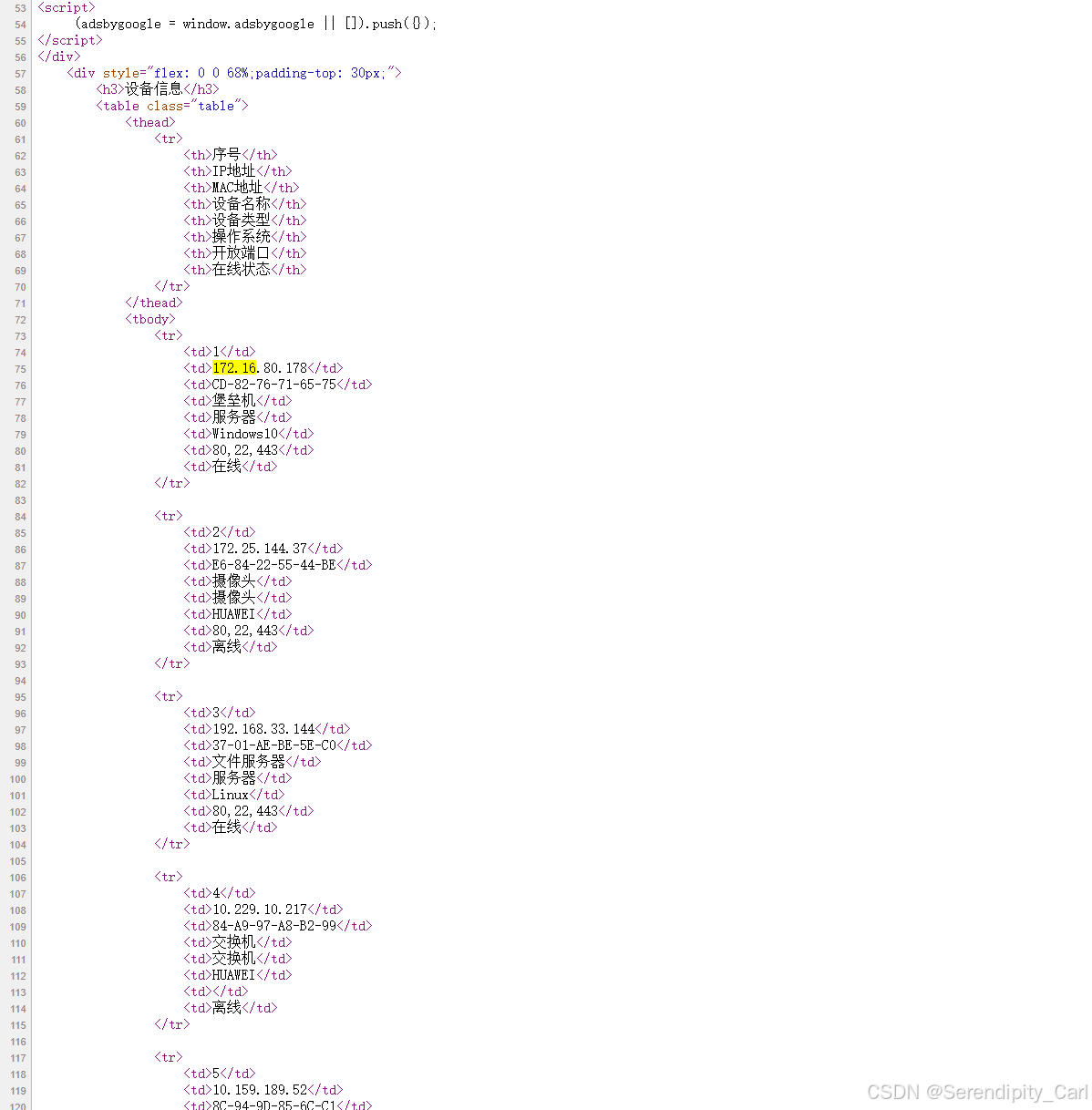
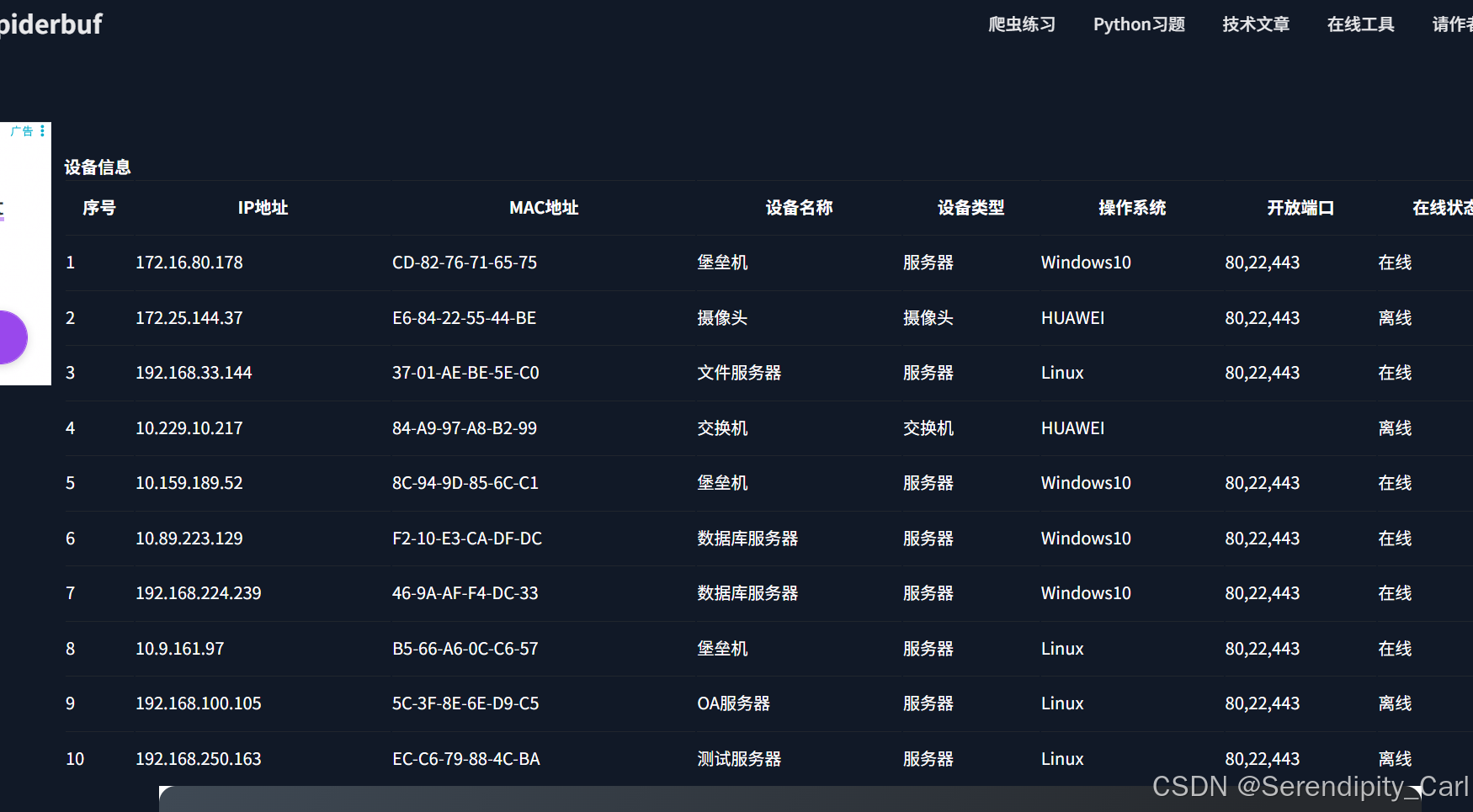
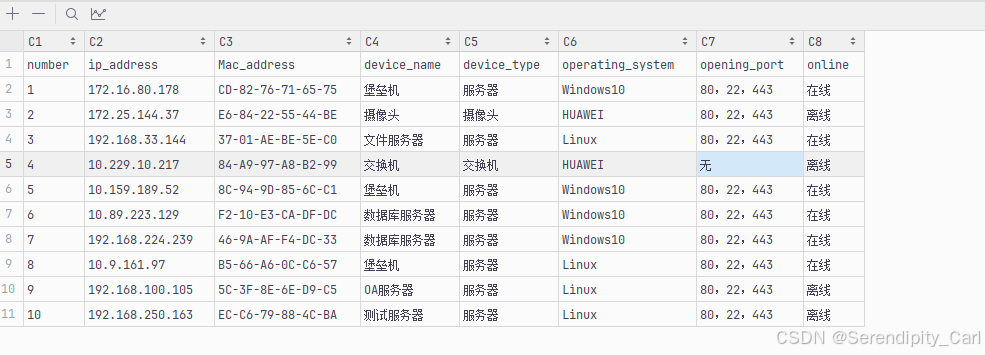
可以看到我们爬取的数据都在其中 至此 确定该网站为静态数据
接着我们F12 打开开发者工具 此时不需要Ctrl+R 刷新页面 因为我们获取的是静态数据
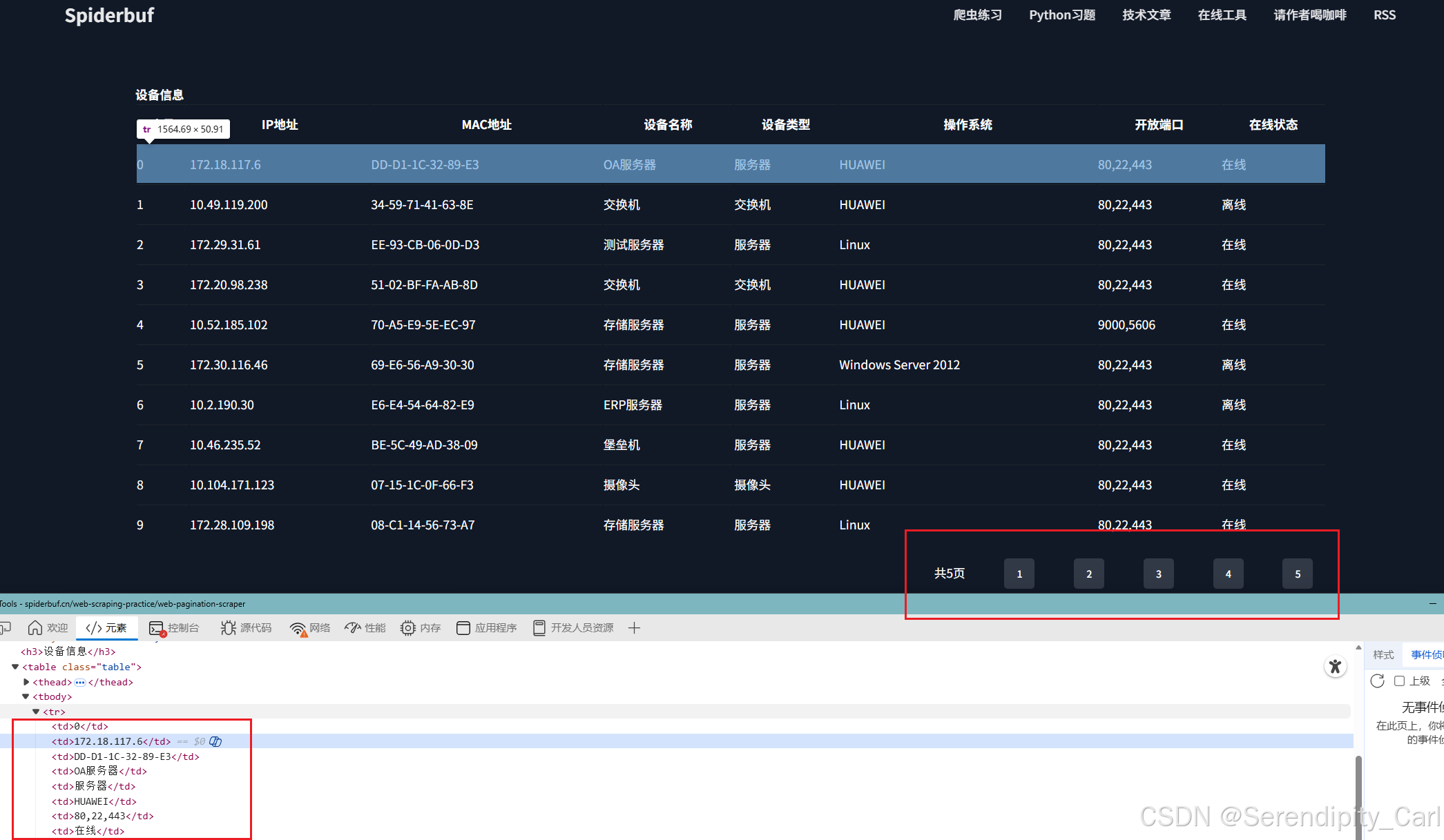
点击元素 左上角小箭头 选中我们想好爬取的数据 分析页面结构
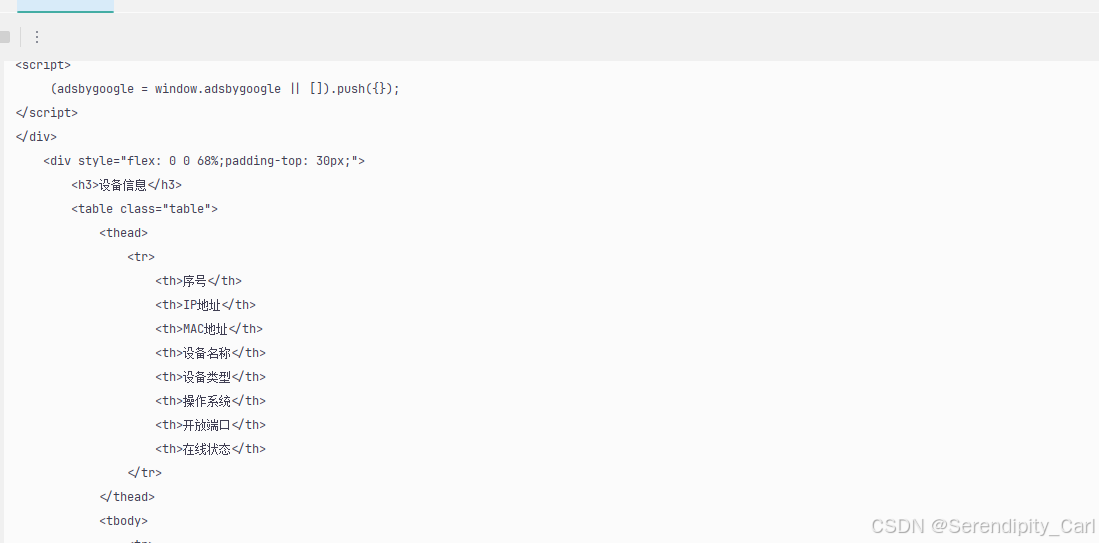
分析网页结构
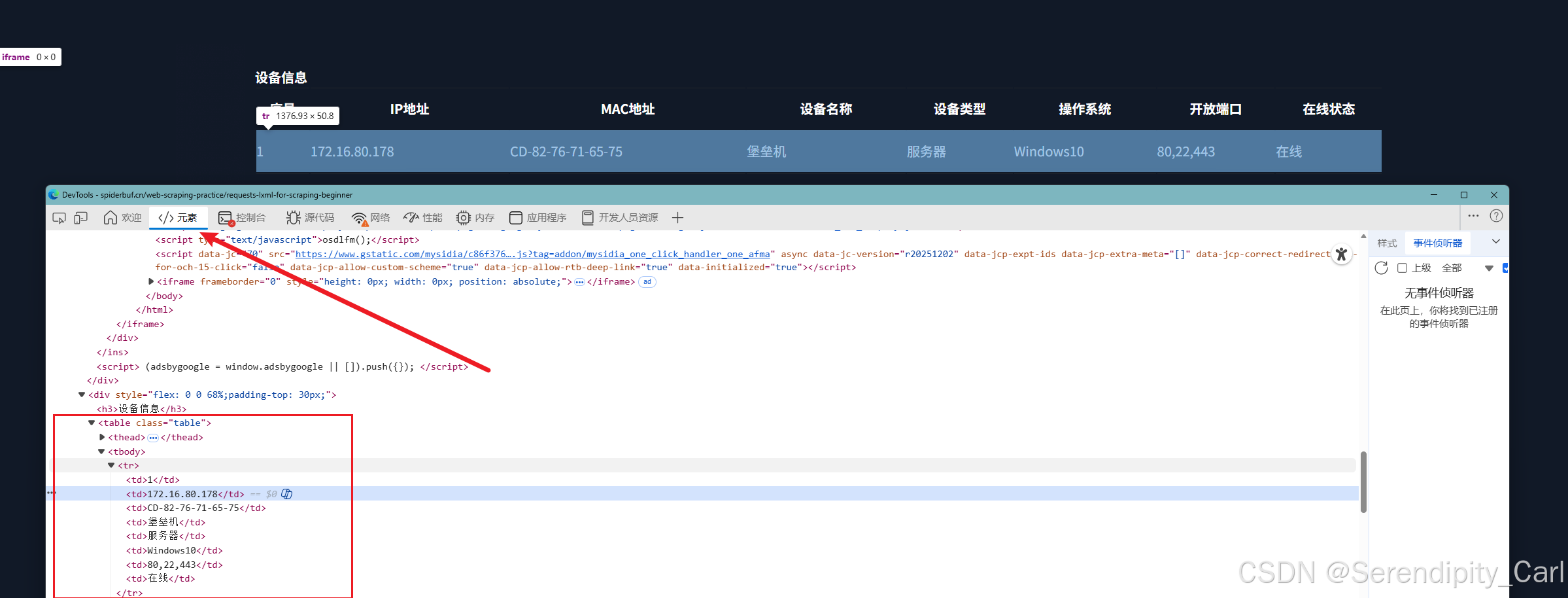
OK 此时我们如果直接定位到tbody的话 此页面有五个 不好定位 我们按照层级定位
定位: class属性为table的table标签下面的tbody 里面的tr 此时刚好为十条返回结构 符合我们爬取数据的条数
OK 页面的层级分析定位完毕 现在我们开始写代码
The first step is to build headers
点击网络(network) 一次性将所有的请求头复制下来 一锅端
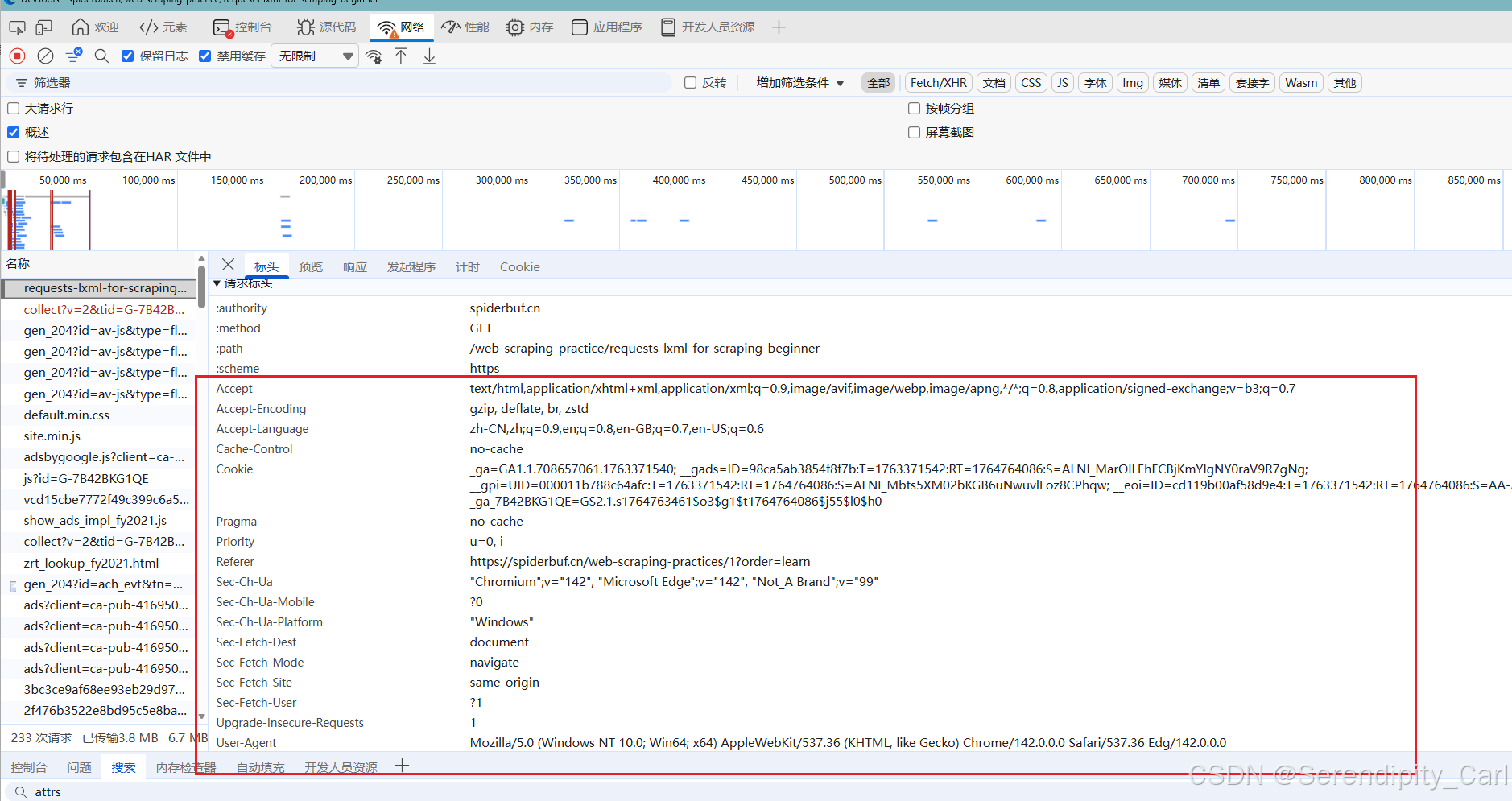
这里推荐一个插件 可以提高我们构建请求头的效率 在插件商城里面搜 headers 出来一个蜘蛛的图标 下载即可
使用方法: 复制请求头信息后 到Pycharm 里面右击复制 里面有个选项 Headers 复制为headers
目前代码如下 编写代码
# 导包
import requests
url = 'https://spiderbuf.cn/web-scraping-practice/requests-lxml-for-scraping-beginner'
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "_ga=GA1.1.708657061.1763371540; __gads=ID=98ca5ab3854f8f7b:T=1763371542:RT=1764764086:S=ALNI_MarOlLEhFCBjKmYlgNY0raV9R7gNg; __gpi=UID=000011b788c64afc:T=1763371542:RT=1764764086:S=ALNI_Mbts5XM02bKGB6uNwuvlFoz8CPhqw; __eoi=ID=cd119b00af58d9e4:T=1763371542:RT=1764764086:S=AA-AfjbIBrUY97XhQd5DGDYSZ-on; _ga_7B42BKG1QE=GS2.1.s1764763461$o3$g1$t1764764086$j55$l0$h0",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practices/1?order=learn",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
resp = requests.get(url, headers=headers)
print(resp.text)在终端查看返回的源代码
发现返回的是一串乱码 哦豁
这里有一个乱码的样式 总结 大家可以查看一下
第一反应就是 第二个 是吧 但是我们以UTF-8的方式 读取 依然没用
resp.encoding = 'utf-8'
解决方法 就是删掉请求头中的 accept-encoding 这个参数是指定客户端接受的压缩编码格值"gzip, deflate, br, zstd"表示客户端支持四种压缩算法:gzip、deflate、br(Brotli)和zstd,服务器可以根据这些选项选择合适的压缩方式来减少传输数据量。
直接删掉其它的留下gzip即可 或者把这行都删了 or 注释掉 默认为gzip压缩格式
有时候页面出现类似的代码 有可能是受br的影响 删掉即可
此时运行 即可看到页面的源代码 我们想要的数据也在其中
继续写代码 解析数据 导入用到的包
from lxml import etree
html = etree.HTML(resp.text)
lis = html.xpath('.//table[@class="table"]/tbody/tr')
lis = html.xpath('.//table[@class="table"]/tbody/tr')
# 遍历根节点
for li in lis:
number = ''.join(li.xpath('./td[1]/text()'))
ip_address = ''.join(li.xpath('./td[2]/text()'))
Mac_address = ''.join(li.xpath('./td[3]/text()'))
device_name = ''.join(li.xpath('./td[4]/text()'))
device_type = ''.join(li.xpath('./td[5]/text()'))
operating_system = ''.join(li.xpath('./td[6]/text()'))
opening_port = ''.join(li.xpath('./td[last()-1]/text()'))
if not opening_port:
opening_port = '无'
online = ''.join(li.xpath('./td[last()]/text()'))Explain:
正则提取出来的数据返回的是一个列表 此时我们想到可以将其取出来[0]
但是这样其实不好 假如要取的那个字段是空的 就会报错 索引超过列表长度
因为里面是空的 你还要进行取值 正确的处理方式是将其转化成字符串
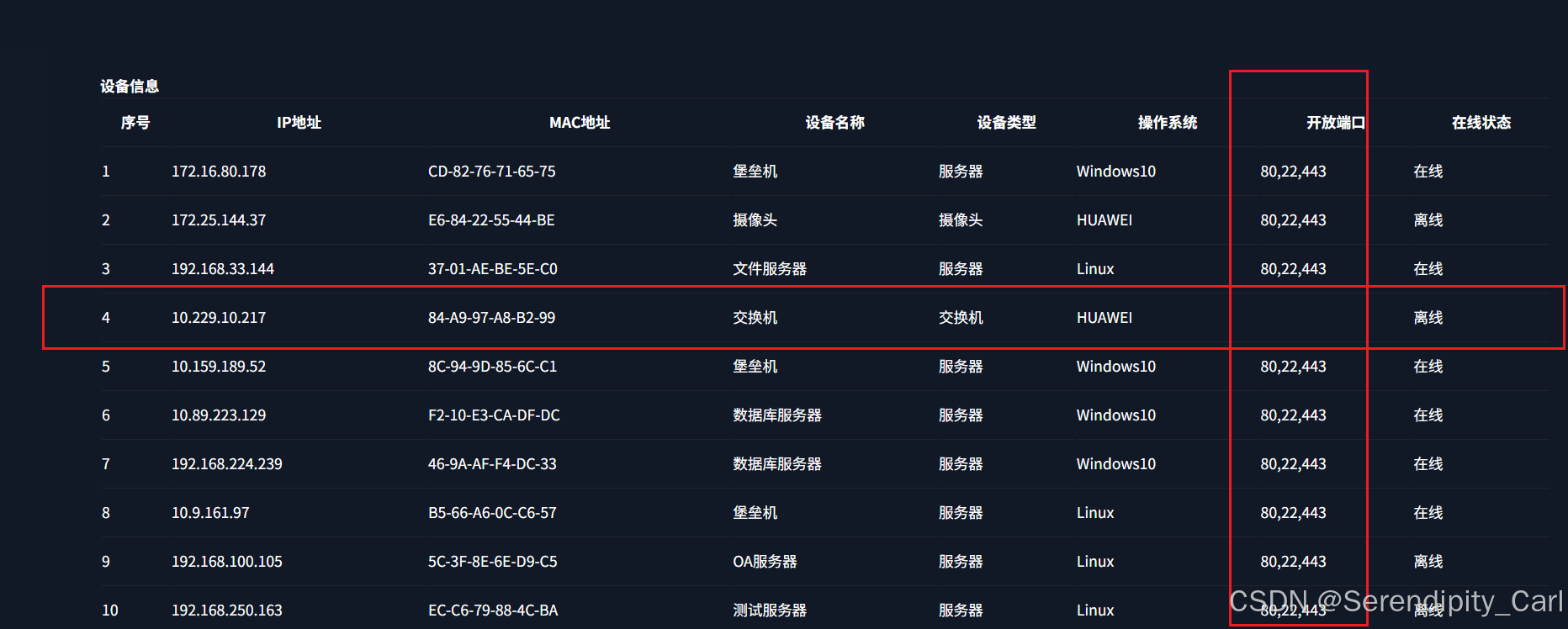
opening_port字段 我们通过网页可以发现是空的
如果不处理 那么得到的也是空数据 当然我们也可以进行处理
not 取反 意思是 如果这个字段为空 则返回 空字符串
至此 我们爬取的所有数据就搞定了 将所有的字段打印出来 检查符合格式要求 就可以进行数据的保存了
保存数据为csv 文件
# 创建一个名为'S_b_1.csv'的文件,以写入模式('w')打开,使用UTF-8-SIG编码格式,并设置newline=''来避免CSV文件中出现额外的空行
f = open('S_b_1.csv', 'w', encoding='utf-8-sig', newline='')
# 写入表头
f.write('number,ip_address,Mac_address,device_name,device_type,operating_system,opening_port,online\n')
# 使用格式化字符串 将我们的数据一行对应表头写入 以逗号隔开 csv文件的格式
all_data = f'{number},{ip_address},{Mac_address},{device_name},{device_type},{operating_system},{opening_port},{online}\n'
f.write(all_data)
# 关闭文件
f.close()编码格式为utf-8-sig 可以在excel里面打开 而不出现乱码
运行看到我们的数据 会发现开放端口那个字段 本身就有, 所以保存的数据有问题
我们可以将里面所有的英文逗号改成中文的 即可正常保存
# 如果字符串中存在英文逗号 就执行替换
if ',' in opening_port:
opening_port = opening_port.replace(',',',')以下是保存成功的数据 以及所有的代码 供大家参考学习
import requests
from lxml import etree
url = 'https://spiderbuf.cn/web-scraping-practice/requests-lxml-for-scraping-beginner'
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
# "accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "你的cookie",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practices/1?order=learn",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
resp = requests.get(url, headers=headers)
f = open('S_b_1.csv', 'w', encoding='utf-8-sig', newline='')
html = etree.HTML(resp.text)
lis = html.xpath('.//table[@class="table"]/tbody/tr')
f.write('number,ip_address,Mac_address,device_name,device_type,operating_system,opening_port,online\n')
for li in lis:
number = ''.join(li.xpath('./td[1]/text()'))
ip_address = ''.join(li.xpath('./td[2]/text()'))
Mac_address = ''.join(li.xpath('./td[3]/text()'))
device_name = ''.join(li.xpath('./td[4]/text()'))
device_type = ''.join(li.xpath('./td[5]/text()'))
operating_system = ''.join(li.xpath('./td[6]/text()'))
opening_port = ''.join(li.xpath('./td[7]/text()'))
if ',' in opening_port:
opening_port = opening_port.replace(',',',')
if not opening_port:
opening_port = '无'
online = ''.join(li.xpath('./td[last()]/text()'))
all_data = f'{number},{ip_address},{Mac_address},{device_name},{device_type},{operating_system},{opening_port},{online}\n'
f.write(all_data)
f.close()第二题:
这个考察点 我们在第一个题目的时候已经完成了 只需要把请求头构造完整即可
将请求地址修改即可
第三题:
前面基本的步骤我就不重复了
分析页面 页面的结构相比之前 有点改动 需要我们稍微调整一下代码 已经Url
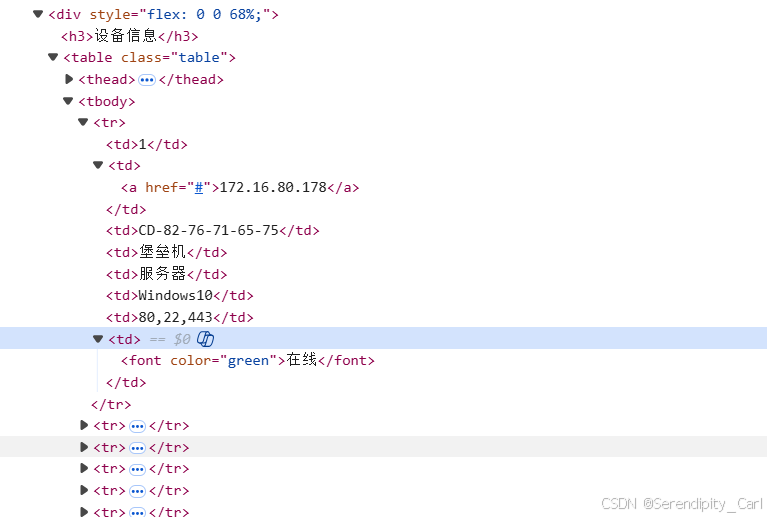
主要修改这两个:
- 第二个td 标签 下面的a标签 提取其中的文本
- 最后一个td标签 下面的font标签 提取其中的文本
ip_address = ''.join(li.xpath('./td[2]/a/text()'))
online = ''.join(li.xpath('./td[last()]/font/text()'))第四题:
依然F12打开开发者工具 分析页面的结构
发现和之前第二题的页面结构一样 直接把之前的代码拿过来运行 可得
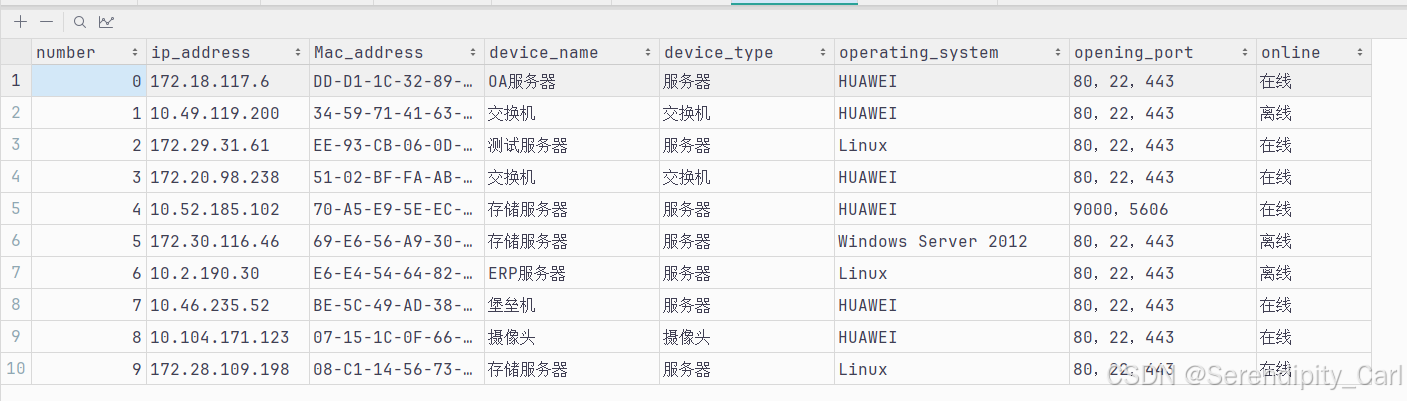
确认代码没有问题 可以拿到数据 接下来爬取五页的所有数据
点击页码 查看页码之间的关联
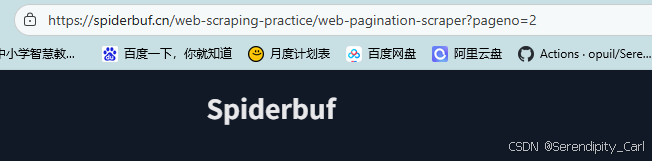
可以看到 Url地址中拼接了页码的参数 pageno=2
我们可以循环遍历 将每一页的数据保存下来 如果是将所有的数据保存到一个文件中 还需要调整一下代码的顺序
就是和文件打开 关闭 以及写入表头的代码
Explain: 因为我们保存到一个文件中就只需 打开一次 待所有的数据都写入后再关闭 表头都是一样的 所以就只要写入一次
还有一个小细节 就是number 序列 第一个字段 都是从0开始 我们可以在循环外面定义一个字段每循环一次加1
第四题的代码如下
import requests
from lxml import etree
f = open('S_b_4.csv', 'w', encoding='utf-8-sig', newline='')
f.write('number,ip_address,Mac_address,device_name,device_type,operating_system,opening_port,online\n')
count = 1
# range 函数 只写一个数字 默认代表的是从0开始 到数字-1结束 左闭右开
# 从1开始 到5 结束
for page in range(1, 6):
url = f'https://spiderbuf.cn/web-scraping-practice/web-pagination-scraper?pageno={page}'
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
# "accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "你的cookie",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practices/1?order=learn",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
lis = html.xpath('.//table[@class="table"]/tbody/tr')
for li in lis:
# number = ''.join(li.xpath('./td[1]/text()'))
number = count
ip_address = ''.join(li.xpath('./td[2]/text()'))
Mac_address = ''.join(li.xpath('./td[3]/text()'))
device_name = ''.join(li.xpath('./td[4]/text()'))
device_type = ''.join(li.xpath('./td[5]/text()'))
operating_system = ''.join(li.xpath('./td[6]/text()'))
opening_port = ''.join(li.xpath('./td[7]/text()'))
if ',' in opening_port:
opening_port = opening_port.replace(',', ',')
if not opening_port:
opening_port = '无'
online = ''.join(li.xpath('./td[last()]/text()'))
all_data = f'{number},{ip_address},{Mac_address},{device_name},{device_type},{operating_system},{opening_port},{online}\n'
f.write(all_data)
count+=1
f.close()这样的话就比较美观
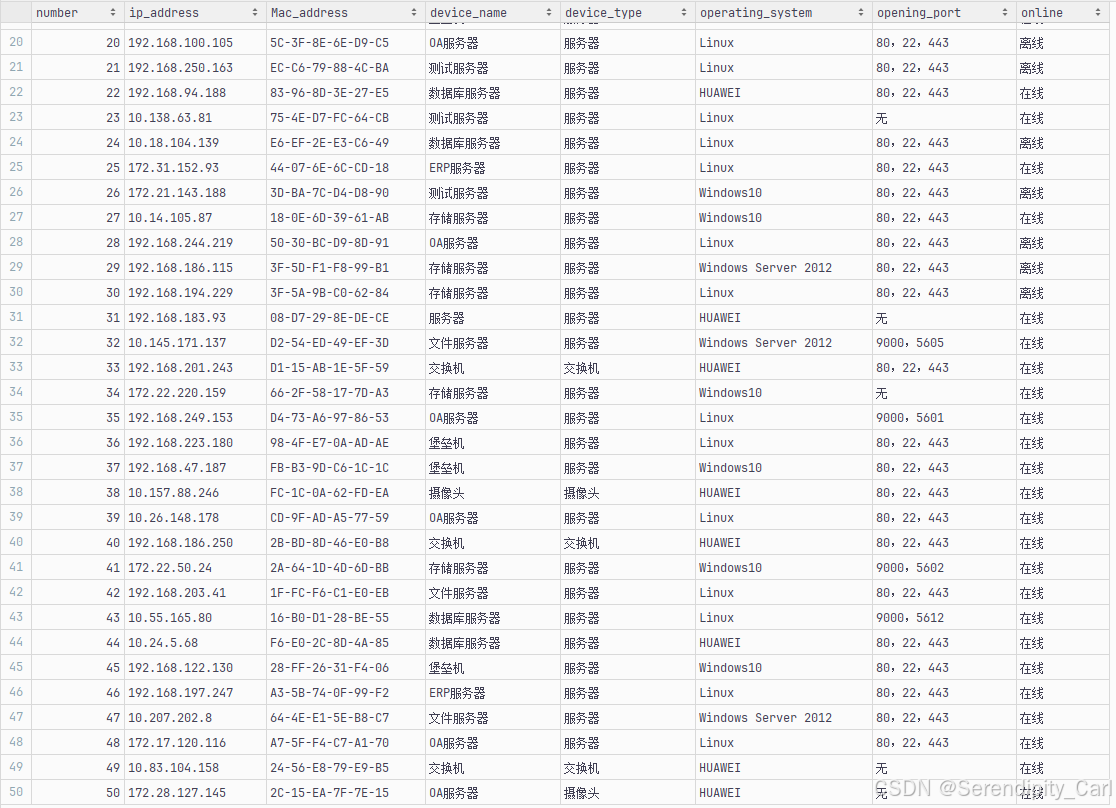
刚刚说了 如果你是想每一页保存为一个文件的话 就得做如下的调整 思路换一下
这样就不需要调写入文件相关的代码 只需将保存的文件名换成变量即可
这样就完成了分页保存
第五题:

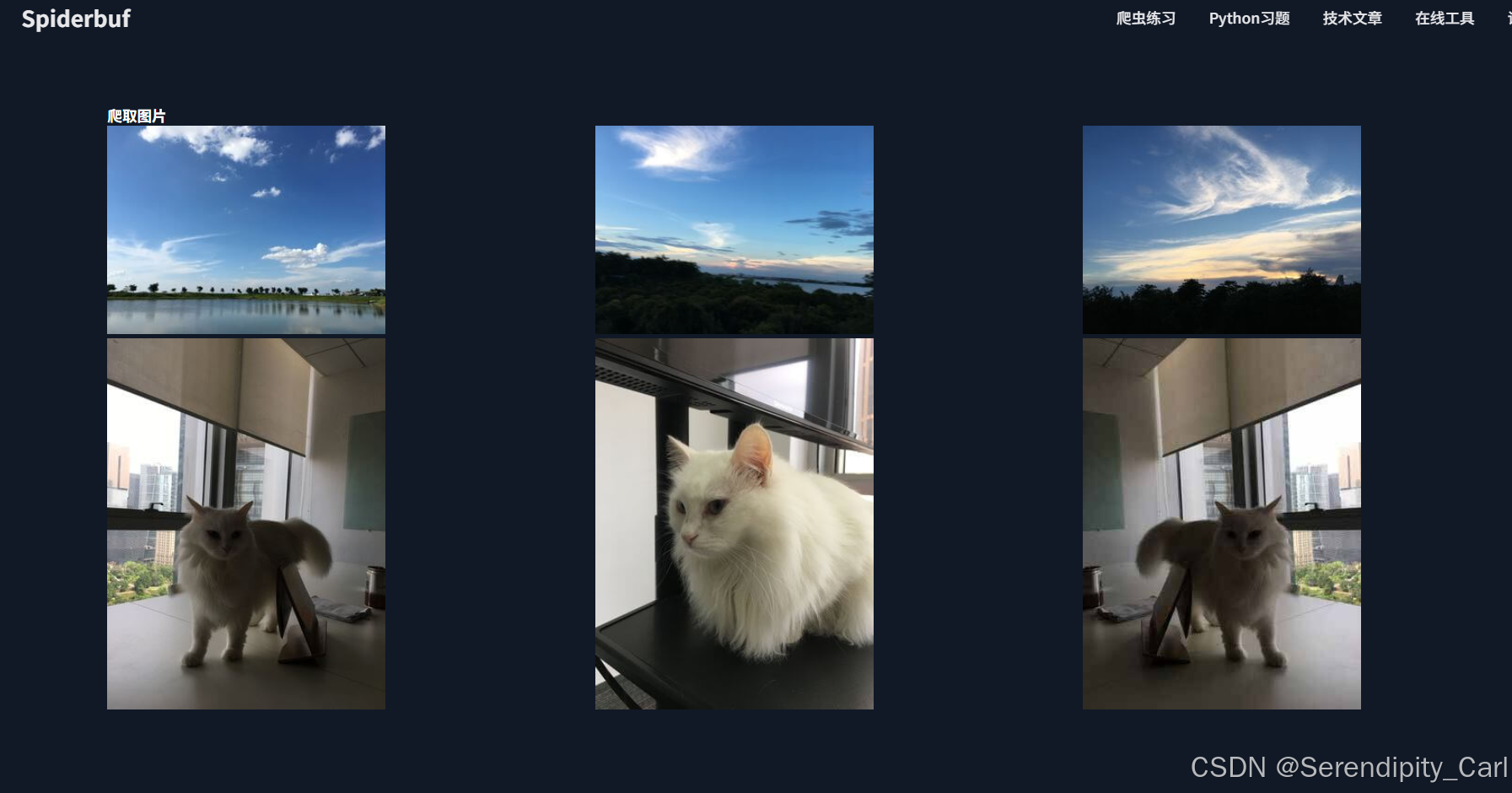
第五题就不一样了 是需要我们爬取几张图片
思路: 拿到所有的图片链接 对链接发请求 拿到二进制数据 进而进行保存
Explain:
当爬取的文件包含非文本数据(如图片、音视频、压缩包、可执行文件等)时,必须使用二进制模式保存
图片是由像素点组成的,每个像素有RGB值等二进制数据
如果以文本模式保存,编码转换会破坏文件结构,导致图片损坏
OK 我们来分析页面的结构
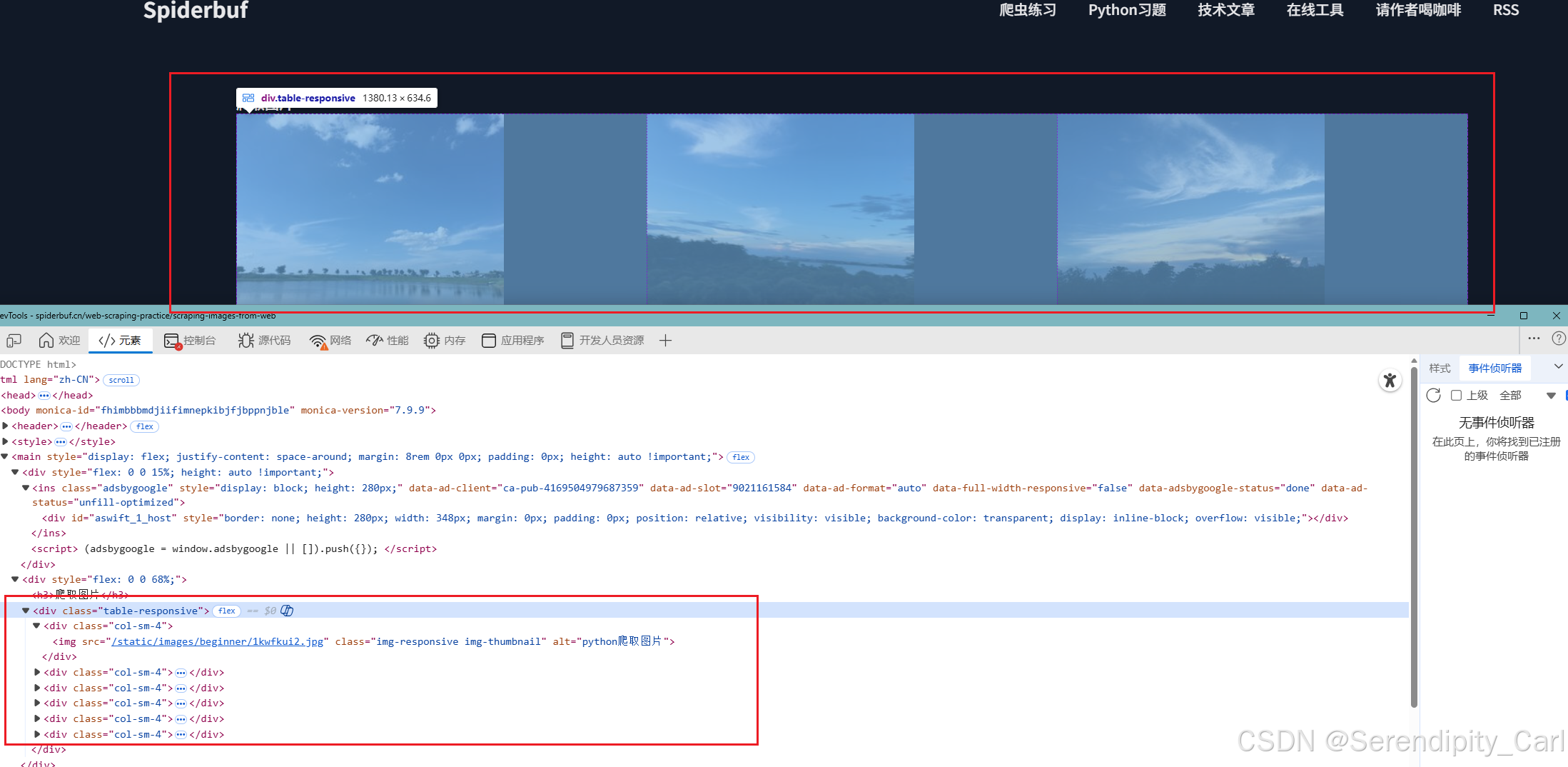
可以发现 所有的图片都在 class 类名为tabel-responsive的div标签中
根标签可以选则从这里开始 也可以直接通过img中的class属性来定位
OK 开始写代码
# 导包
import requests
from lxml import etree
url = 'https://spiderbuf.cn/web-scraping-practice/scraping-images-from-web'
# 构建请求头
headers = {
"content-type": "text/plain;charset=UTF-8",
"referer": "https://spiderbuf.cn/",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
images = html.xpath('.//img[@class="img-responsive img-thumbnail"]/@src')
print(images)打印出来 发现这个地址是不完整的

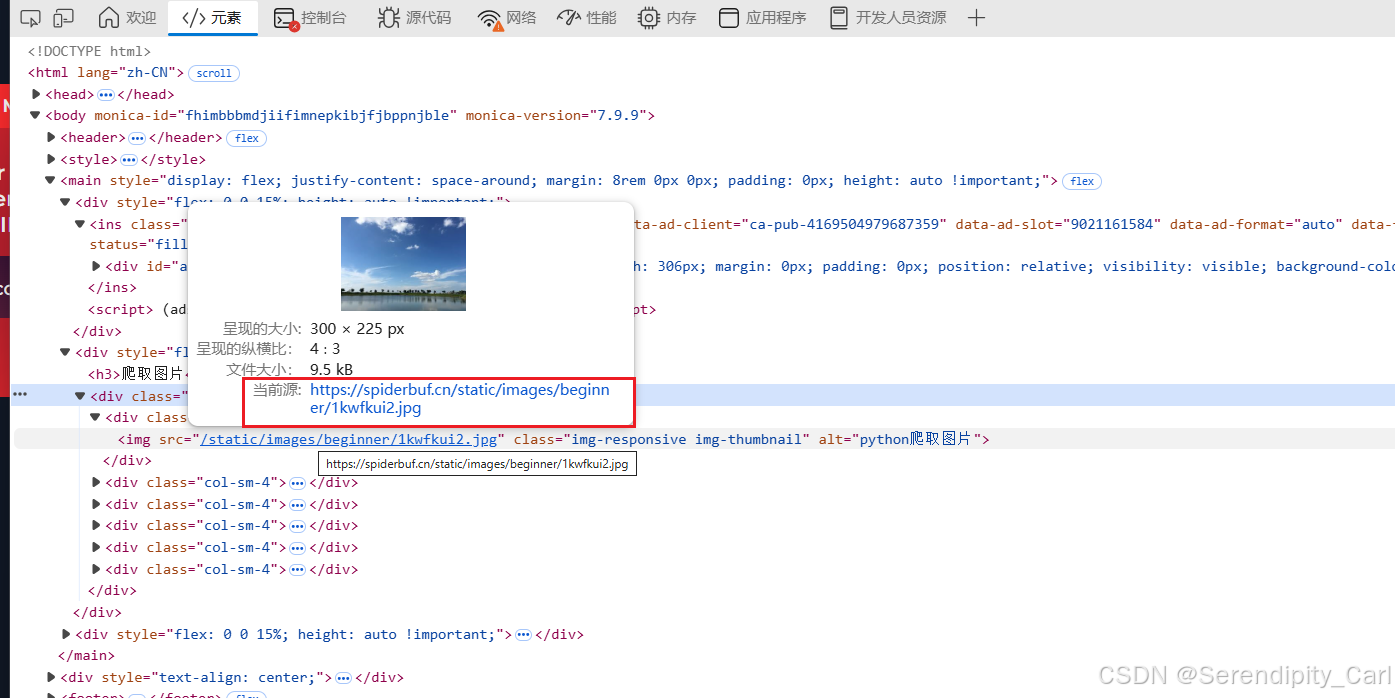
这个是完整的链接地址 我们需要做个拼接
# 返回的是个列表
# 遍历列表 拿到具体的值
for img in images:
# 拼接 打印
img_url = 'https://spiderbuf.cn'+ img
print(img_url)在终端点击链接可以看到图片 说明拼接没有问题
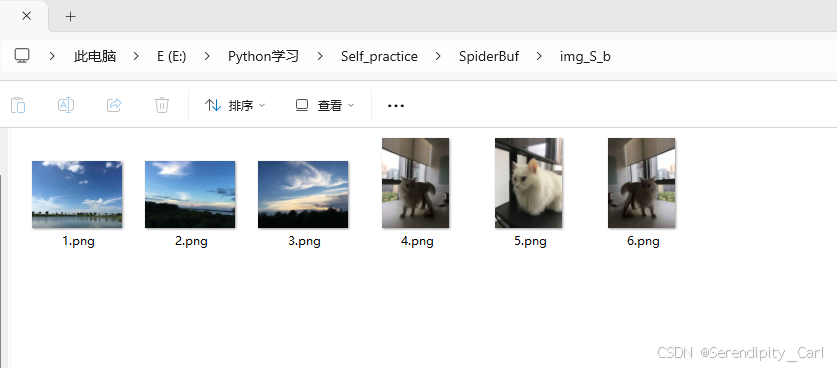
现在的需求是: 将所有的图片保存到当前的新的文件夹中 命名为1-5.jpg
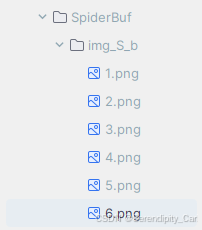
实现代码:
if not os.path.exists('img_S_b'):
os.makedirs('img_S_b')
for idx, img in enumerate(images):
img_url = 'https://spiderbuf.cn' + img
resp_img = requests.get(img_url, headers=headers).content
with open(f'./img_S_b/{idx + 1}.png', 'wb') as f:
f.write(resp_img)Explain:
检查当前目录下是否存在名为'img_S_b'的文件夹,如果不存在,则创建该文件夹。
具体逻辑:
1. `os.path.exists('img_S_b')` - 检查'img_S_b'路径是否存在
2. `not` - 对检查结果取反
3. `os.makedirs('img_S_b')` - 创建'img_S_b'目录及其父目录(如需要)
enumerate 就是相比较于没有 多了个idx 列表的索引值 方便后续保存图片
使用`enumerate()`函数遍历列表,同时获取每个元素的索引(idx)和对应的图像数据(img)。enumerate()会自动为列表中的每个元素生成从0开始的索引,便于在循环中同时访问索引位置和实际数据。
with open 和open 的区别 open 需要手动关闭文件 f.close()
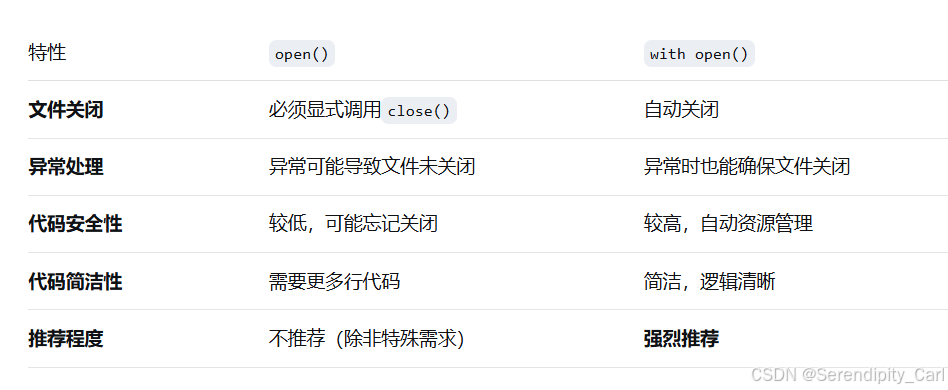
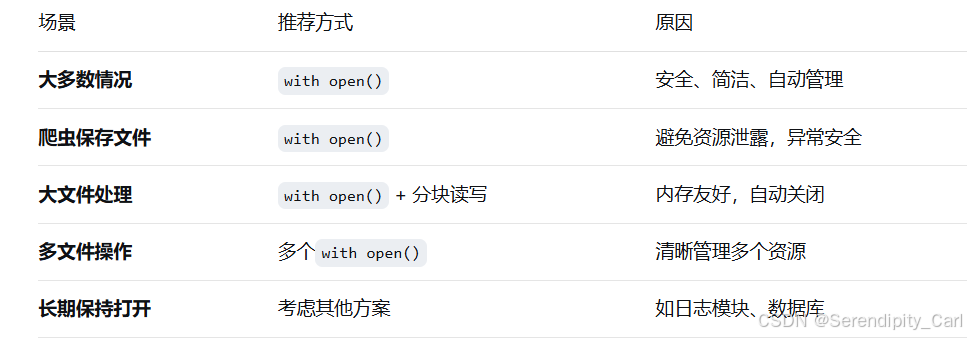
以wb 二进制的形式写入文件
至此 所有的图片爬取完毕
第六题:

前面基本的步骤就不讲了 分析此页面 发现和第三题的页面结构一样 我们把之前写的代码拿过来 修改url地址试一下

运行之后发现没有内容

回到页面当中分析原因---- 可以看到我们整个html页面都在这个iframe标签中
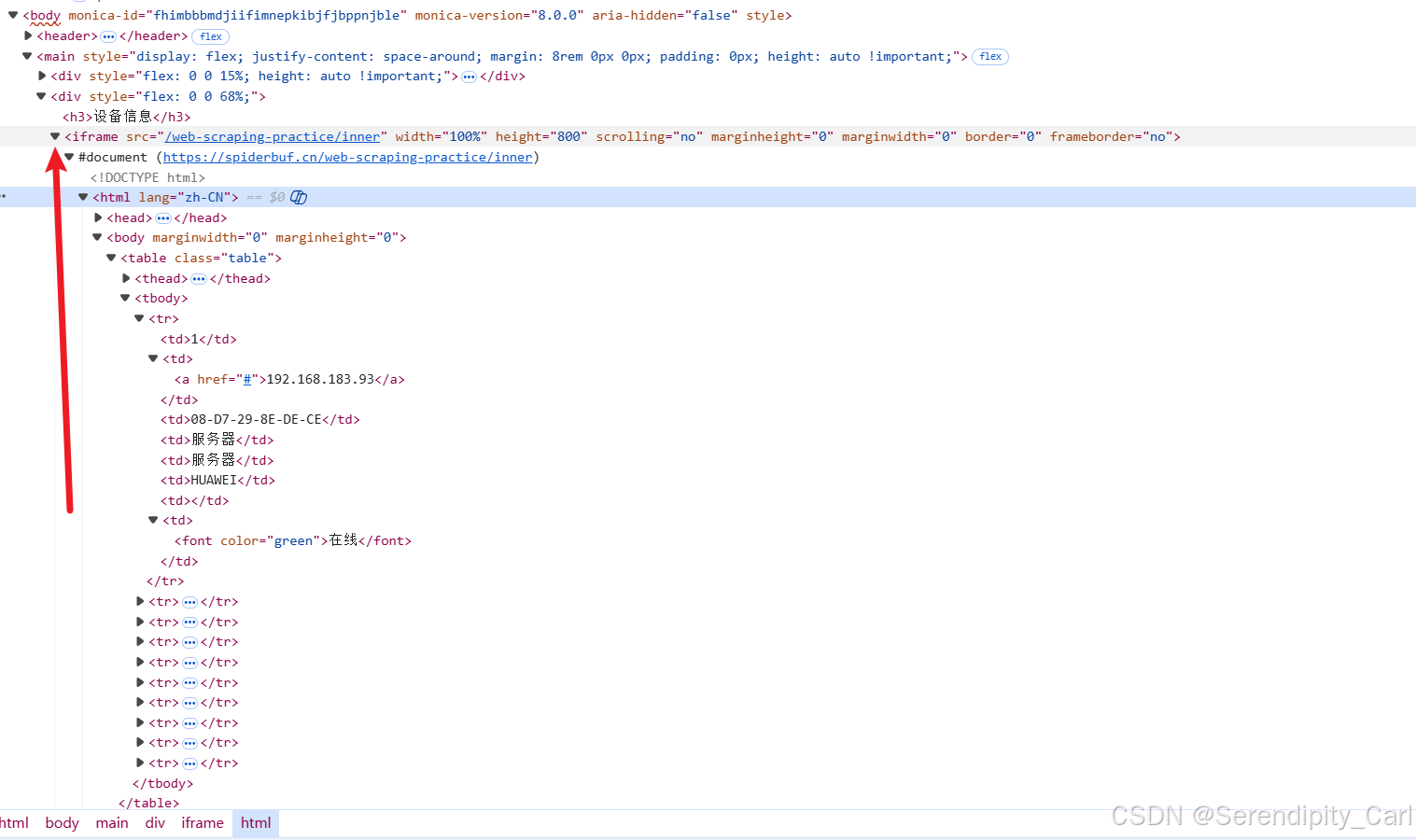
当数据在 iframe 中时 需要 先获取 iframe 的 src 地址 然后 单独请求 iframe 中的内容
相当于本网页中嵌入了别的网站的链接 需要到本来的网站的爬取数据
OK 开始写代码 这次我们写函数 有重复的代码
import requests
from lxml import etree
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
# "accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "你的cookie",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practices/1?order=learn",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
def get_inner_url(url):
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
ini_url = 'https://spiderbuf.cn' + ''.join(html.xpath('.//iframe/@src'))
return ini_url, html定义一个函数 形参将提取到的链接拼接好之后 和转换的html返回 方便后续发请求
之后再定义一个主函数
def main():
inner_url, html = get_inner_url('https://spiderbuf.cn/web-scraping-practice/scraping-iframe')
# 对实际的地址发起请求
inner_urls, htmls = get_inner_url(inner_url)
# 以下和之前的题目一样 就不解释了
lis = htmls.xpath('.//table[@class="table"]/tbody/tr')
f = open('S_b_6.csv', 'w', encoding='utf-8-sig', newline='')
f.write('number,ip_address,Mac_address,device_name,device_type,operating_system,opening_port,online\n')
for li in lis:
number = ''.join(li.xpath('./td[1]/text()'))
ip_address = ''.join(li.xpath('./td[2]/a/text()'))
Mac_address = ''.join(li.xpath('./td[3]/text()'))
device_name = ''.join(li.xpath('./td[4]/text()'))
device_type = ''.join(li.xpath('./td[5]/text()'))
operating_system = ''.join(li.xpath('./td[6]/text()'))
opening_port = ''.join(li.xpath('./td[7]/text()'))
if ',' in opening_port:
opening_port = opening_port.replace(',', ',')
if not opening_port:
opening_port = '无'
online = ''.join(li.xpath('./td[last()]/font/text()'))
all_data = f'{number},{ip_address},{Mac_address},{device_name},{device_type},{operating_system},{opening_port},{online}\n'
f.write(all_data)
f.close()
if __name__ == '__main__':
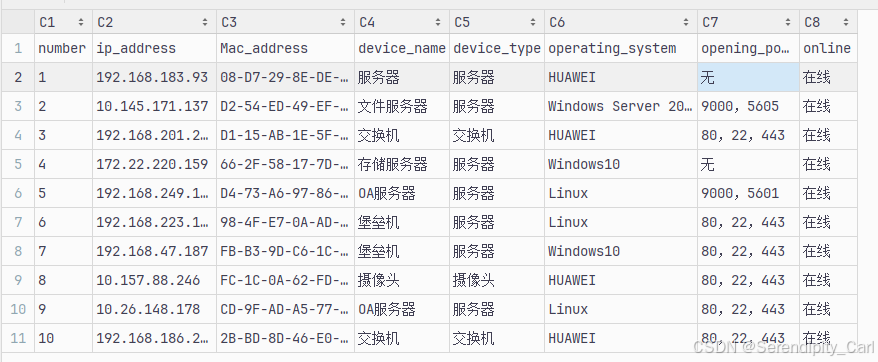
main()以下是爬取成功的数据
第七题:
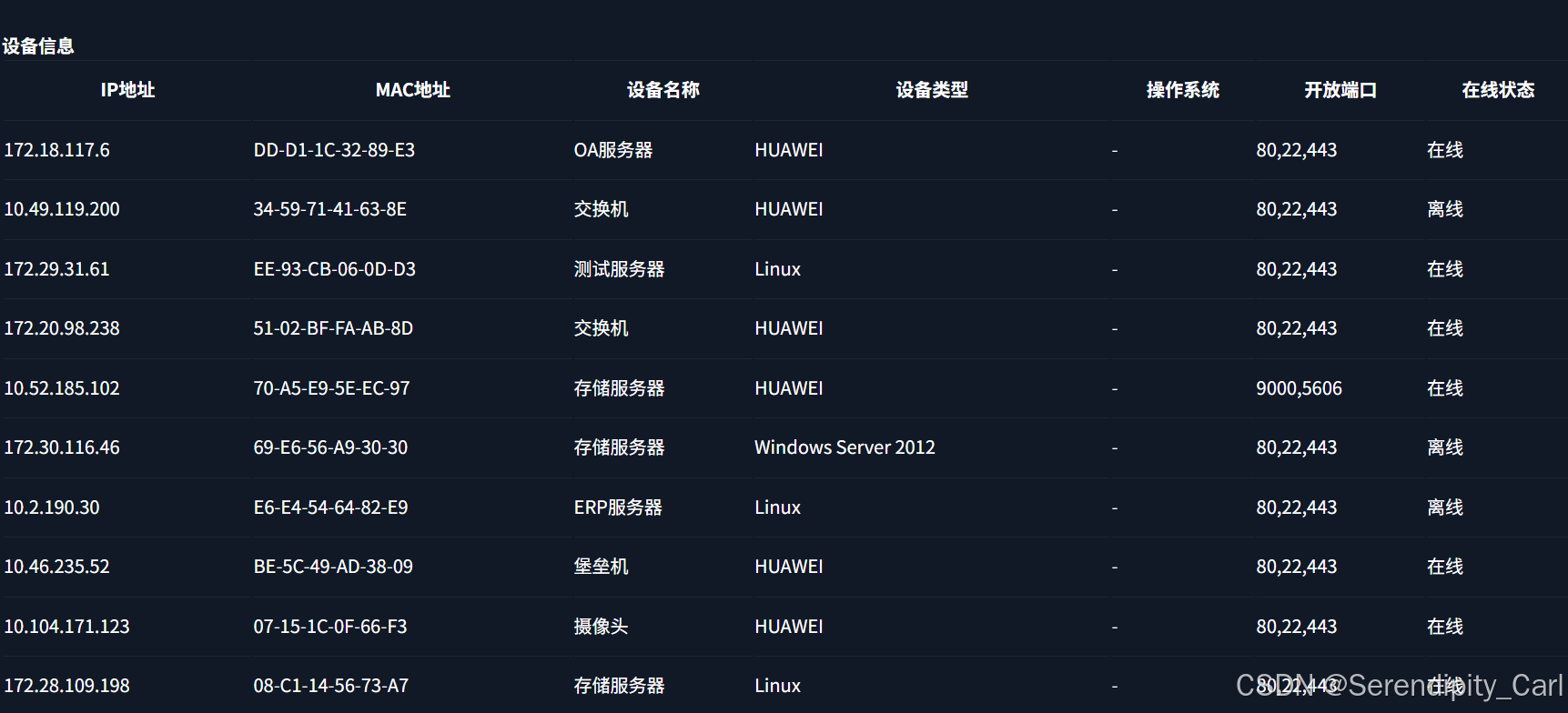
直接Ctrl+U 快捷键查看页面源代码 Ctrl+F搜索我们想要的数据
发现没有我们所需要的数据 此时为动态数据 为异步请求 由服务器返回给前端的数据
分析步骤 F12 打开开发者工具 Ctrl+R 刷新当前页面 点击网络 (Network) Ctrl+F 搜索数据
此时返回给我们数据所在的数据包 点进去即可
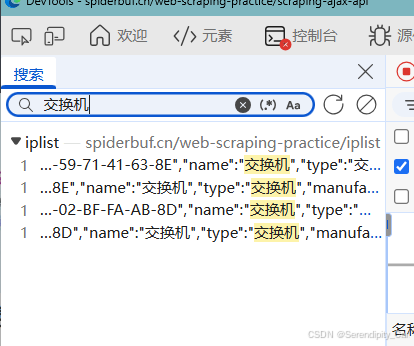
返回的是json格式的数据

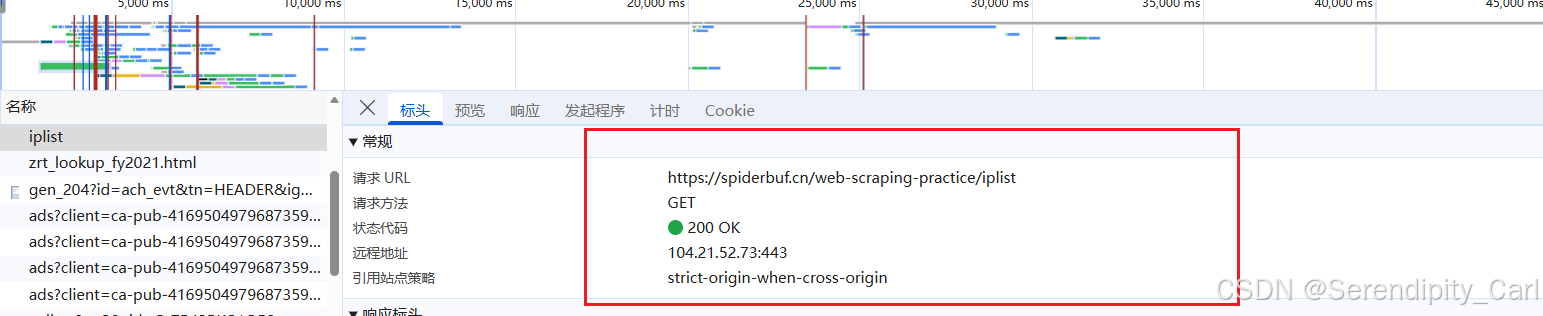
构建请求 模拟浏览器向服务器发送请求 拿到返回的json格式的数据
import requests
import pprint
url = 'https://spiderbuf.cn/web-scraping-practice/iplist'
headers = {
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"accept-encoding": "gzip, deflate, br, zstd",
"cache-control": "no-cache",
"cookie": "你的cookie",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://spiderbuf.cn/web-scraping-practice/scraping-ajax-api",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
resp = requests.get(url, headers=headers)
print(resp.json())打印之后发现 在终端会出现乱码 此时我们向之前那样处理 将accept-encoding 删掉 还是会这样
![]()
解决方法:
resp.encoding = resp.apparent_encoding
设置响应对象的编码格式
- `resp.encoding`:设置HTTP响应内容的解码方式
- `resp.apparent_encoding`:requests库自动检测到的内容编码格式
- 通过将两者相等,确保响应内容能以正确的编码方式进行解码,避免中文等非ASCII字符出现乱码问题
接着就是键值对取值了
lis = []
for li in resp.json():
ip = li['ip']
mac = li['mac']
manufacturer = li['manufacturer']
name = li['name']
ports = li['ports']
status = li['status']
types = li['type']
dit = {
'ip': ip,
'mac': mac,
'manufacturer': manufacturer,
'name': name,
'ports': ports,
'status': status,
'types': types
}
lis.append(dit)
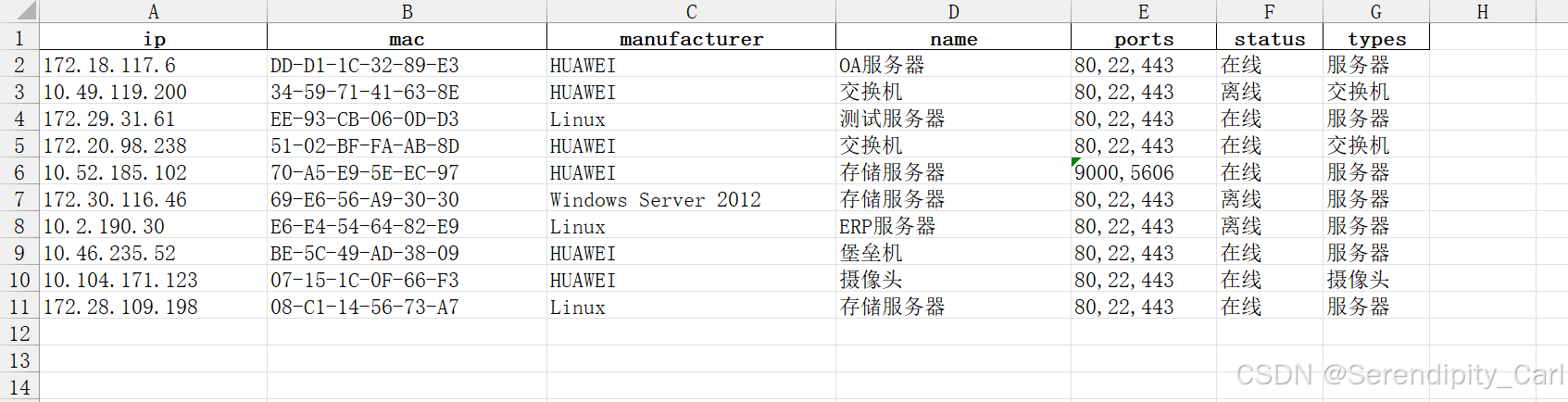
pd.DataFrame(lis).to_excel('S_b_7.xlsx', index=False)之前都是保存为csv文件 这次保存为xlsx文件
首先将字段存到字典当中 接着在外面定义一个空列表 将字典数据通过append方法加进去 最后通过pandas保存数据 别忘记导包
以下是爬取成功的数据图片
第八题:

分析可得 此页面是Post请求的静态数据 数据结构和第一题一样 把第一题的代码拿过来修改一下即可
找到对应的数据包查看携带的data
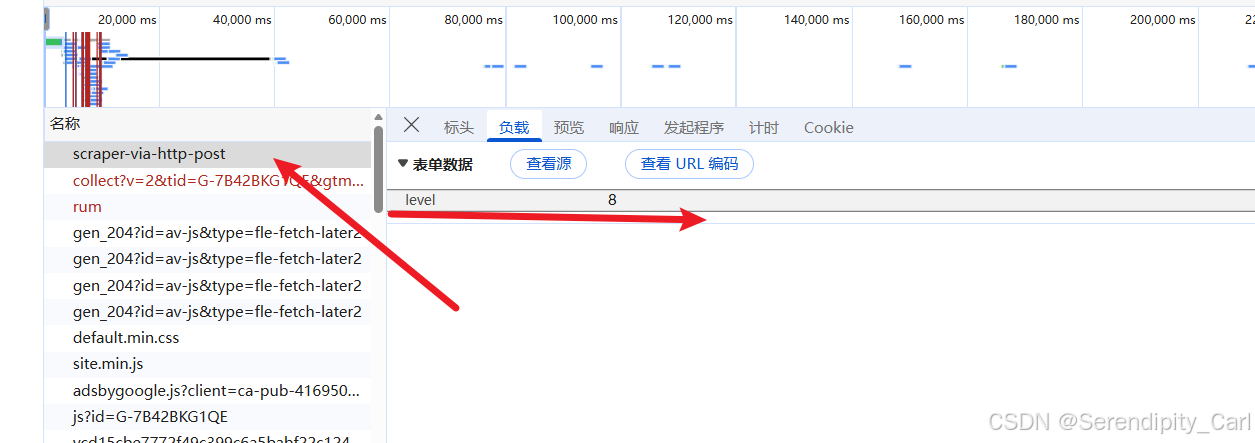
OK 开始写代码
import requests
from lxml import etree
# 修改地址
url = 'https://spiderbuf.cn/web-scraping-practice/scraper-via-http-post'
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
# "accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "你的cookie",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practices/1?order=learn",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
# 添加参数data
data = {
"level": 8
}
resp = requests.post(url, headers=headers, data=data)
f = open('S_b_8.csv', 'w', encoding='utf-8-sig', newline='')
html = etree.HTML(resp.text)
lis = html.xpath('.//table[@class="table"]/tbody/tr')
f.write('number,ip_address,Mac_address,device_name,device_type,operating_system,opening_port,online\n')
for li in lis:
number = ''.join(li.xpath('./td[1]/text()'))
ip_address = ''.join(li.xpath('./td[2]/text()'))
Mac_address = ''.join(li.xpath('./td[3]/text()'))
device_name = ''.join(li.xpath('./td[4]/text()'))
device_type = ''.join(li.xpath('./td[5]/text()'))
operating_system = ''.join(li.xpath('./td[6]/text()'))
opening_port = ''.join(li.xpath('./td[7]/text()'))
if ',' in opening_port:
opening_port = opening_port.replace(',', ',')
if not opening_port:
opening_port = '无'
online = ''.join(li.xpath('./td[last()]/text()'))
all_data = f'{number},{ip_address},{Mac_address},{device_name},{device_type},{operating_system},{opening_port},{online}\n'
f.write(all_data)
f.close()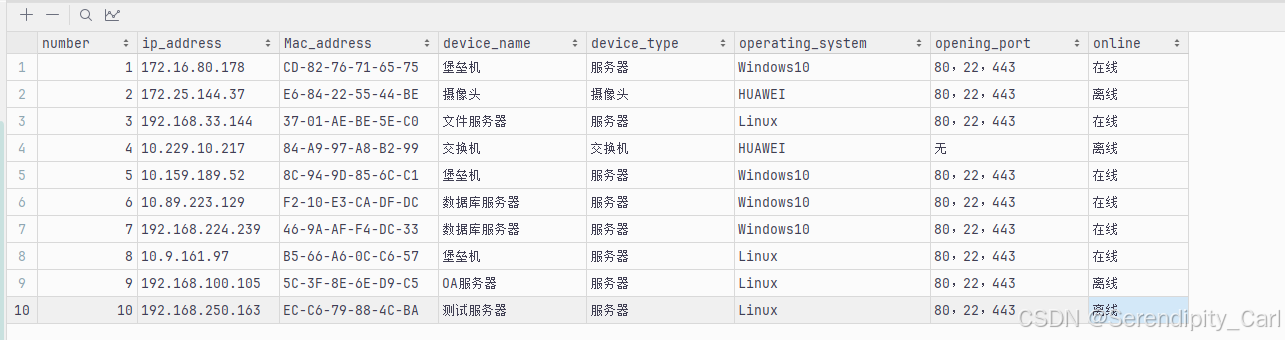
第九题:
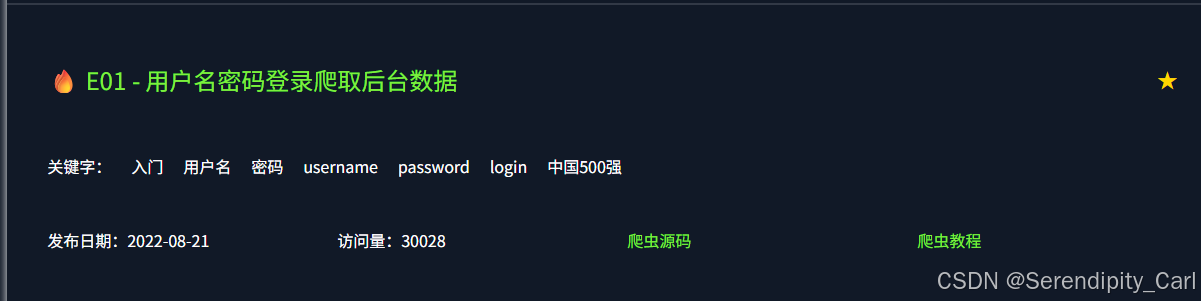
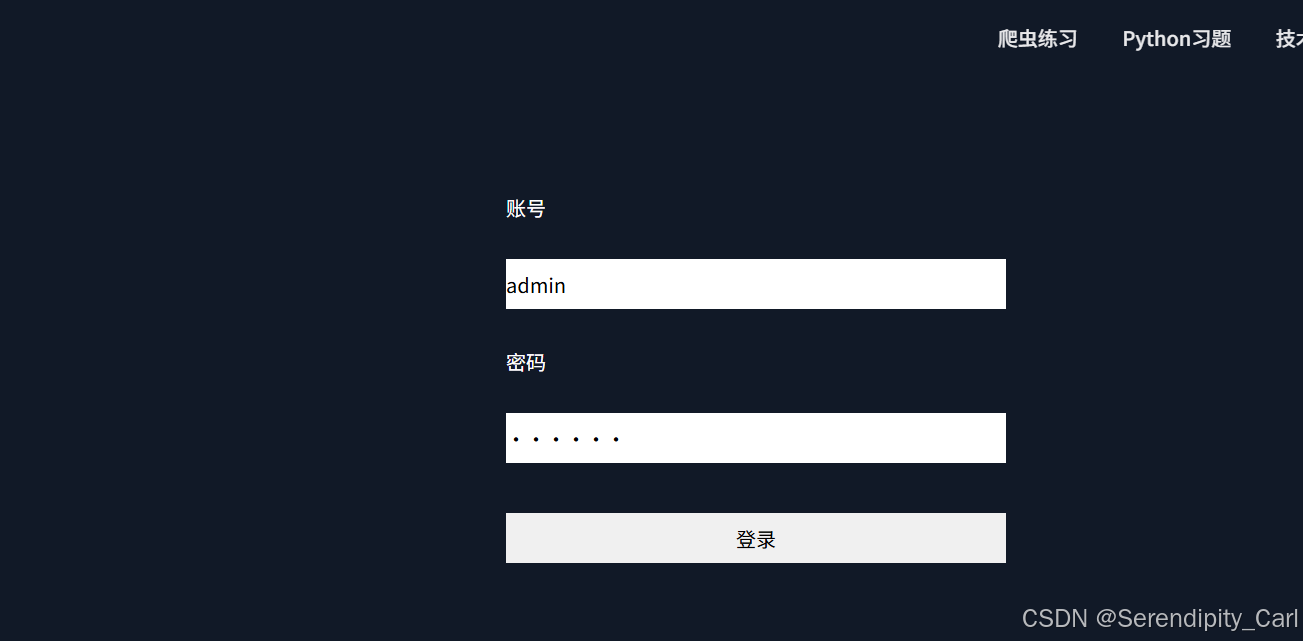
解释 点击登录 才能看到数据 进而爬取数据
我们需要抓包 拿到api接口
首先 F12 打开开发者工具 点击网络(network)

如果下面由数据包 点击那个禁止的图标 目的是清楚当前所有的数据包
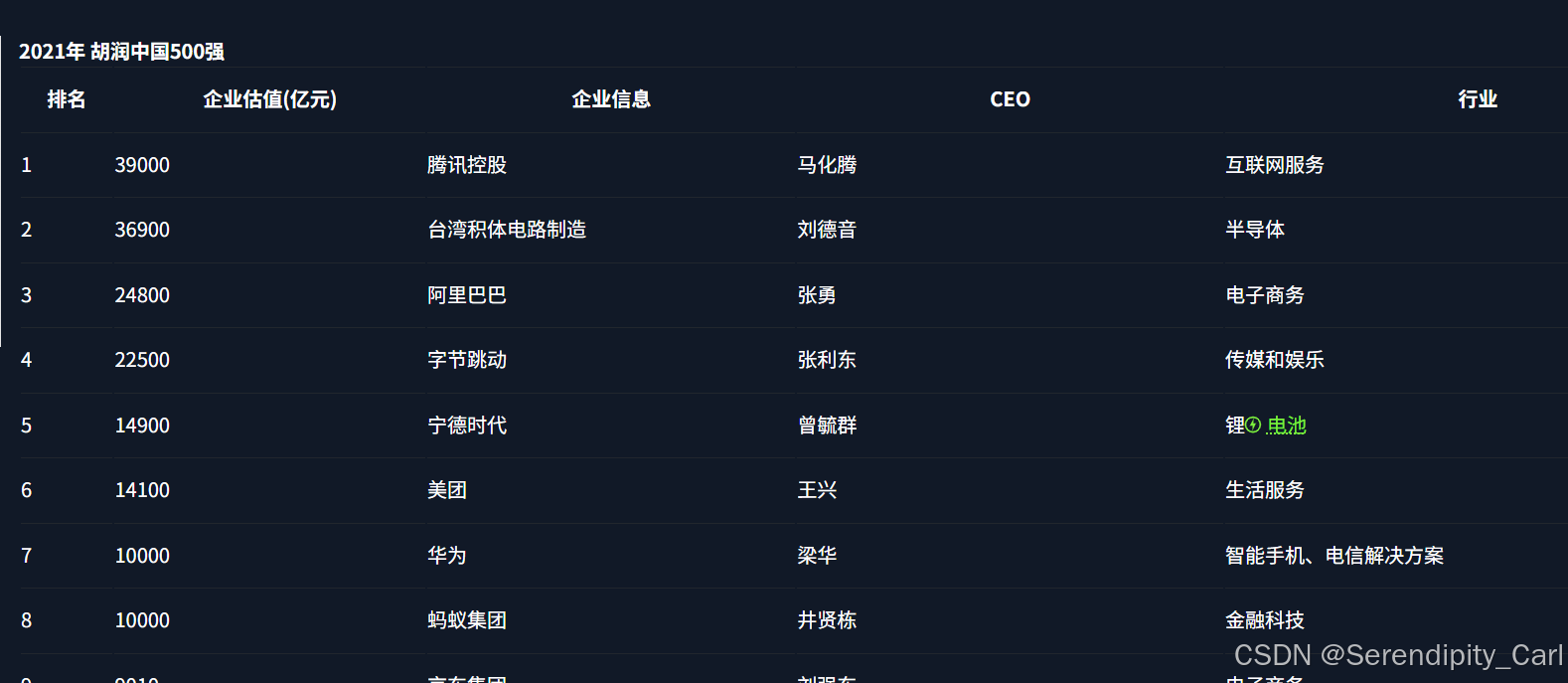
OK 登录成功我们可以看到返回的数据
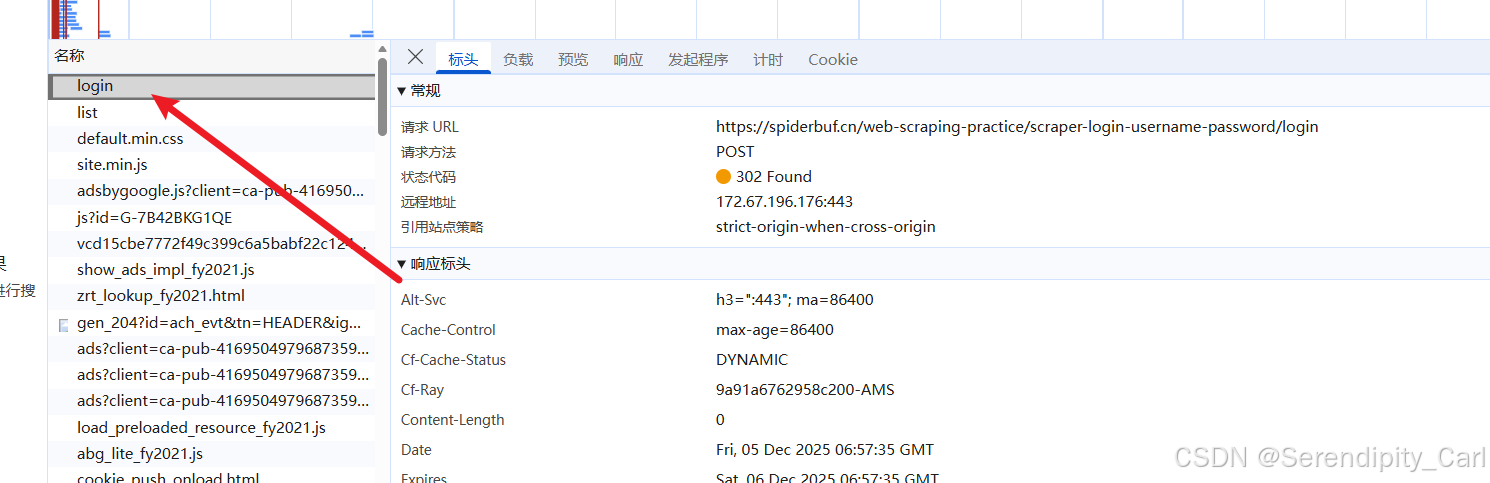
在数据包中找跟登录有关的数据包
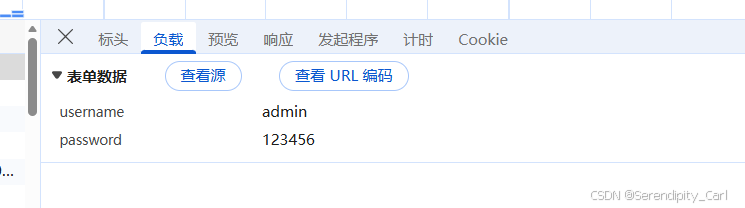
这里可以看到我们提交的信息 对此发请求即可
import requests
url = 'https://spiderbuf.cn/web-scraping-practice/scraper-login-username-password/login'
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"content-length": "30",
"content-type": "application/x-www-form-urlencoded",
"cookie": "你的cookie",
"origin": "https://spiderbuf.cn",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practice/scraper-login-username-password",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
data = {
'username': 'admin',
'password': 123456,
}
resp = requests.post(url, headers=headers, data=data)
print(resp.text)打印数据 查看我们的数据是否在其中
确定无误 对此页面数据提取
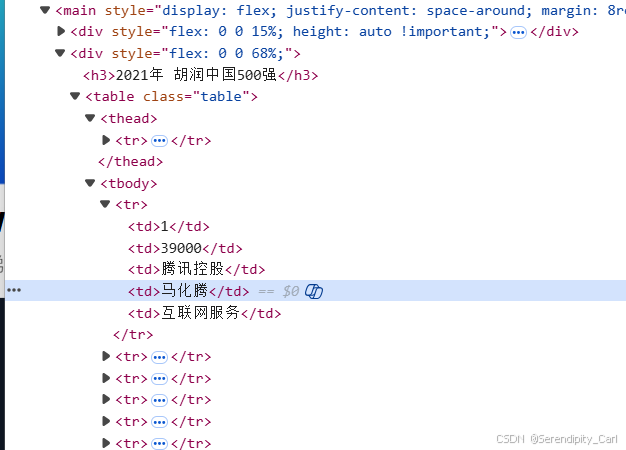
分析此结构可得 和第一题结构类似 拿第一题的代码过来修改即可
import requests
from lxml import etree
url = 'https://spiderbuf.cn/web-scraping-practice/scraper-login-username-password/login'
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"content-length": "30",
"content-type": "application/x-www-form-urlencoded",
"cookie": "你的cookie",
"origin": "https://spiderbuf.cn",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practice/scraper-login-username-password",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
data = {
'username': 'admin',
'password': 123456,
}
resp = requests.post(url, headers=headers, data=data)
f = open('S_b_9.csv', 'w', encoding='utf-8-sig', newline='')
html = etree.HTML(resp.text)
lis = html.xpath('.//table[@class="table"]/tbody/tr')
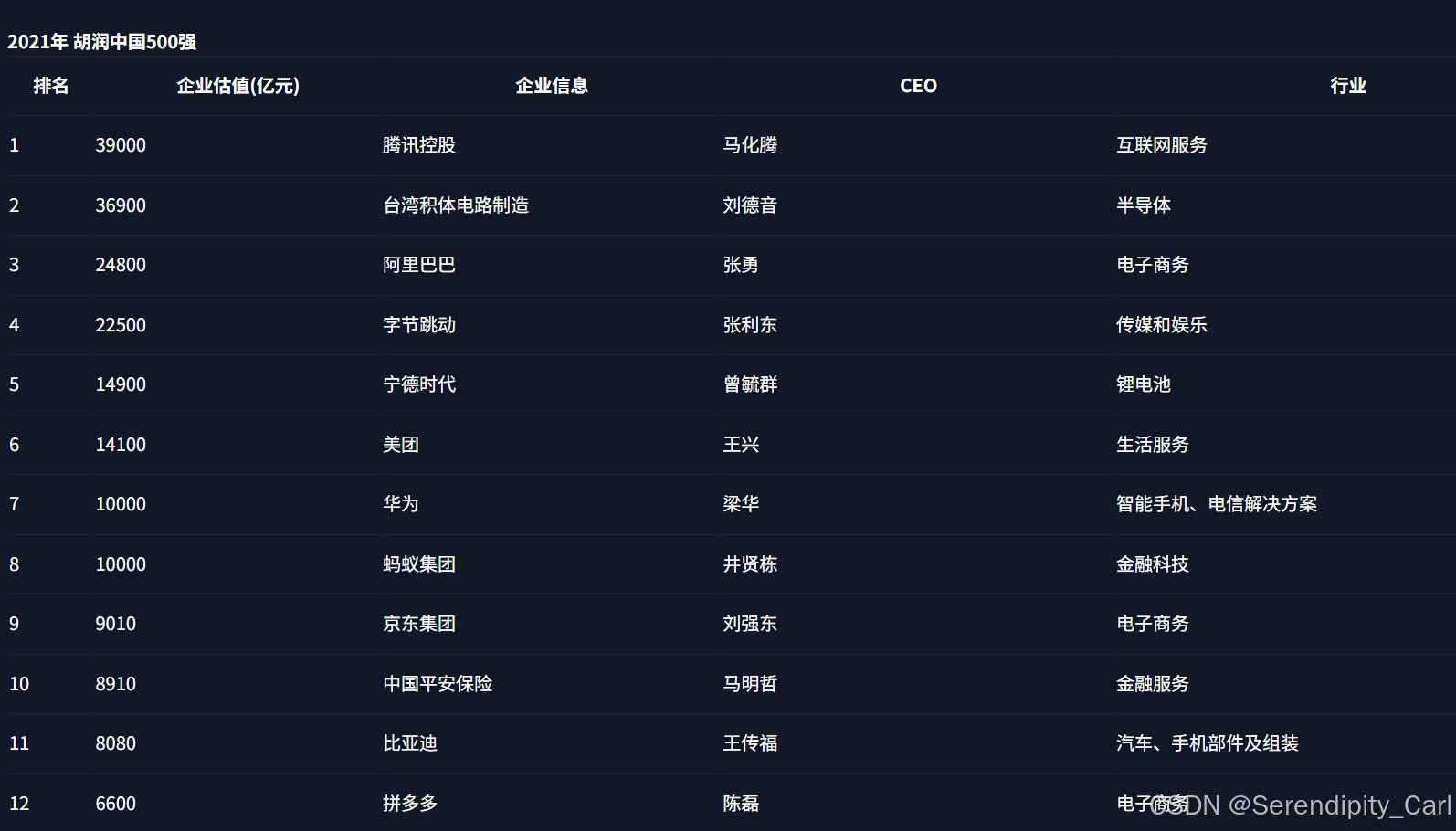
f.write('rank,value,company_info,CEO,industry\n')
for li in lis:
rank = ''.join(li.xpath('./td[1]/text()'))
value = ''.join(li.xpath('./td[2]/text()'))
company_info = ''.join(li.xpath('./td[3]/text()'))
CEO = ''.join(li.xpath('./td[4]/text()'))
industry = ''.join(li.xpath('./td[5]/text()'))
all_data = f'{rank},{value},{company_info},{CEO},{industry}\n'
f.write(all_data)
f.close()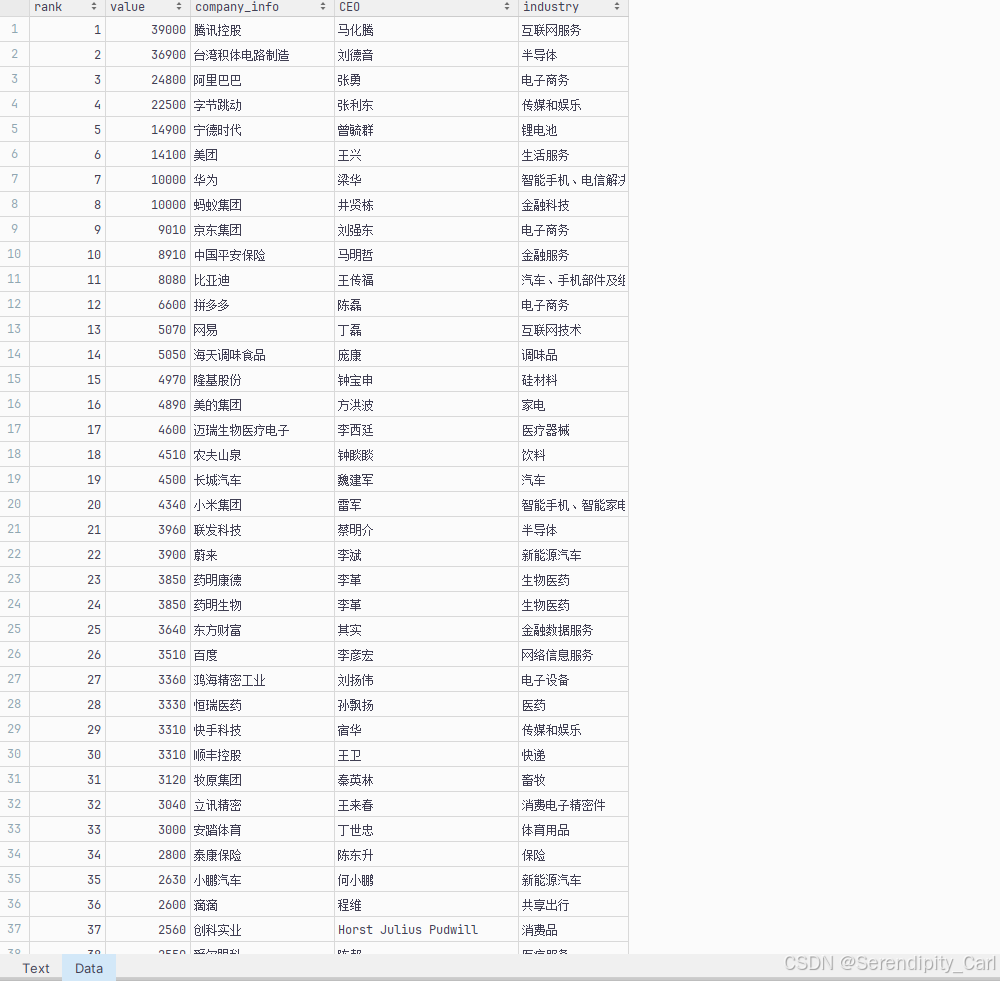
第十题:
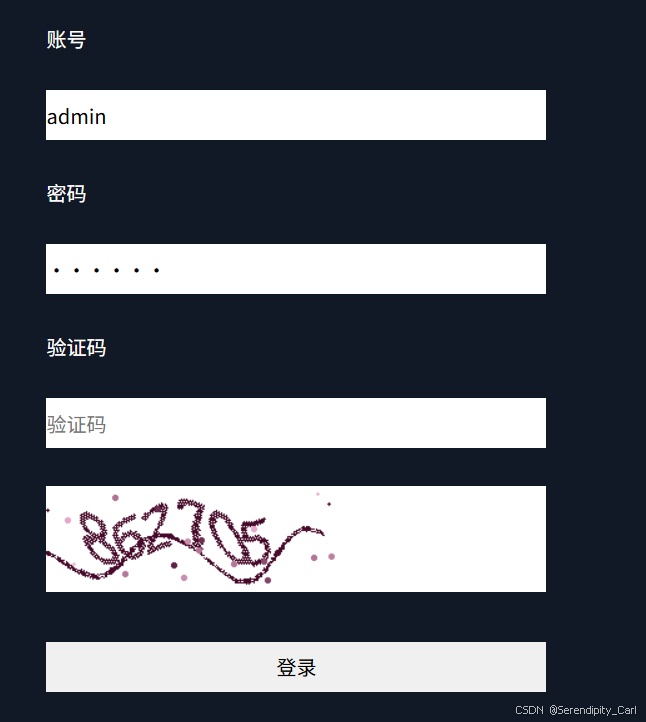
需要我们输入验证码 然后点击登录 才能获取到数据
思路:先拿到获取验证码的api接口 数据包 然后在获取 登录成功的api
F12 打开开发者工具 Ctrl+R刷新当前页面
每次我们刷新 验证码就会变 在 工具栏这里 选择img 意思是筛选返回的数据包类型为图像的

在数据包中找到返回的图片
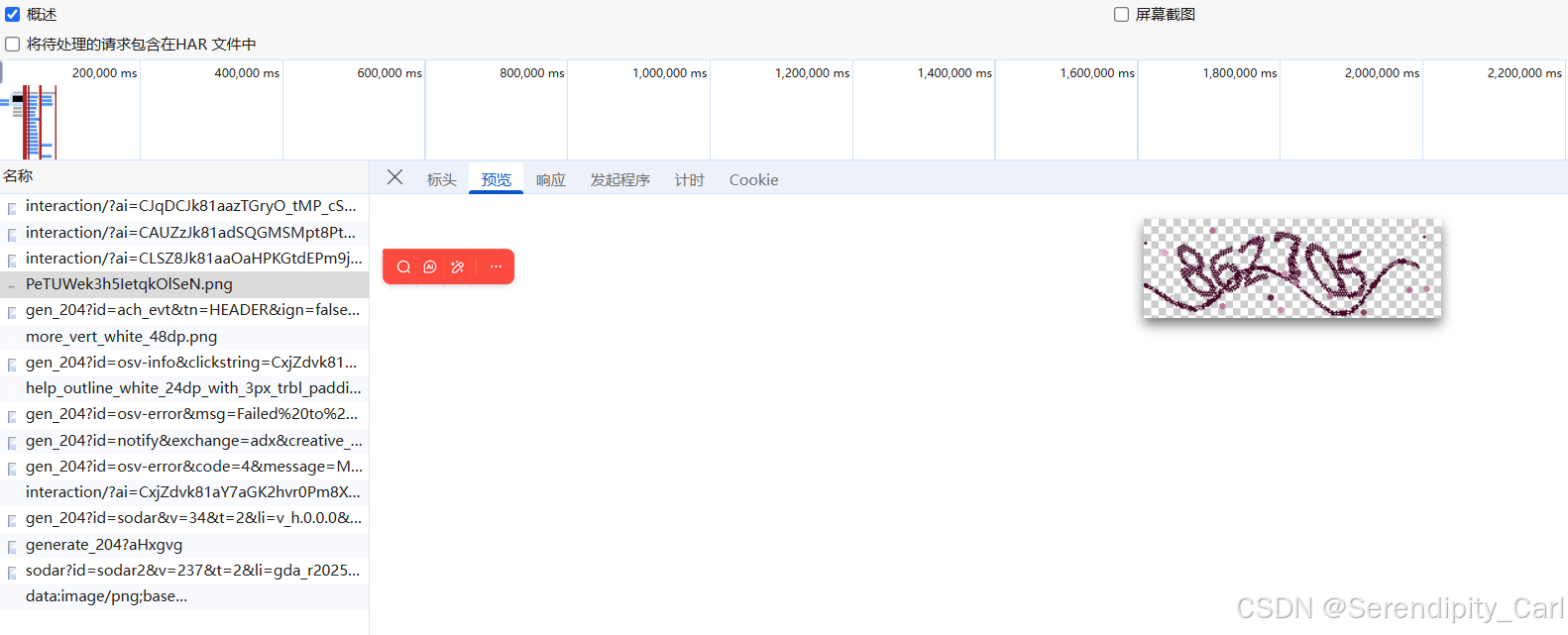
然后分析此图片的Url 可以再次刷新页面对比两个的区别
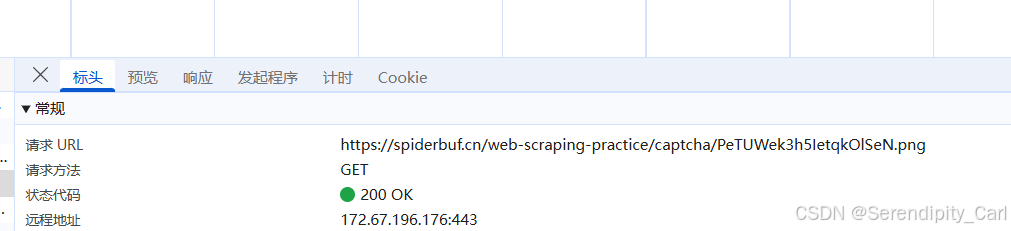
发现就是.png前面的一串英文不同 现在就是看怎么才能拿到这一串英文
我们复制这一串 Ctrl+F 搜索 发现在请求这个页面中的源代码中有
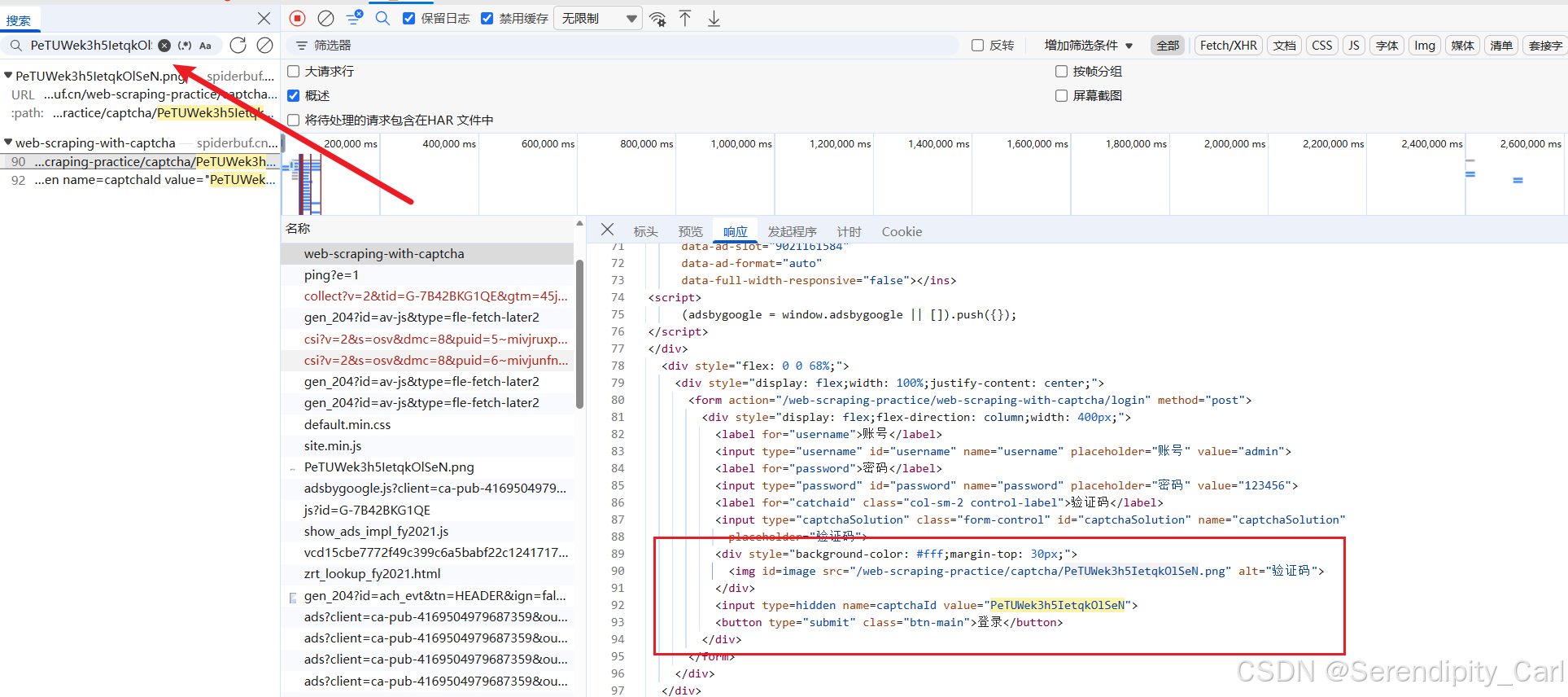
OK 开始写代码 模拟浏览器服务器发送请求 解析提取 id=imgae的img标签提取里面的src属性
然后拼接图片的Url 发送请求 拿到图片的二进制数据 保存到本地
import requests
from lxml import etree
def get_resp(url):
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"cookie": "你的cookie",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practices/2?order=learn",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
response = requests.get(url, headers=headers)
return response这里我们需要发三个请求 就写个函数方便些
# 程序入口
if __name__ == '__main__':
url_1 = 'https://spiderbuf.cn/web-scraping-practice/web-scraping-with-captcha'
resp = get_resp(url_1)
# 这里我直接这样写了 将响应的图片地址提取出来 然后拼接成图片的url
number_url = 'https://spiderbuf.cn' + etree.HTML(resp.text).xpath('.//img[@id="image"]/@src')[0]
# 将图片保存 写入二进制数据
with open('./img_S_b/yzm.png', 'wb') as f:
f.write(get_resp(number_url).content)
OK 我们将图片保存到本地之后 需要将图片中的数字读取出来
这里有个免费的模块可以使用 ddddocr 带带弟弟
用法如下
先安装 pip install ddddocr
然后导入 import ddddocr
# 实例化一个对象
# 这个是有广告的 show_ad=False 关闭广告
ocr = ddddocr.DdddOcr(show_ad=False)
# 读取图片
with open('./img_S_b/yzm.png', 'rb') as f:
numbers = ocr.classification(f.read())我们可以看一下是否成功读取数字
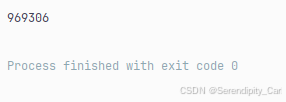
OK 下一步 对登录的api接口发起请求
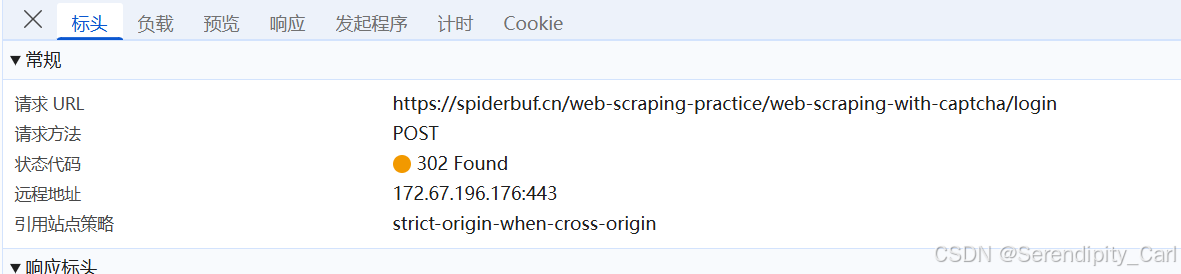
回到登录的页面 打开开发者工具 清楚当前所有的数据包(点击这个按钮)

然后输入验证码 点击登录 可以看到数据了

这个就是我们登录的数据包 可以Ctrl+F搜索 用户名 admin 搜到
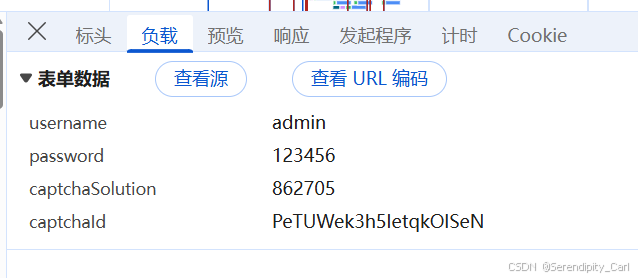
分析可得 Post方法 data表单数据中 传入验证码 以及验证码的id 就是前面在网页源代码中提取的一串英文
# 图片的id
captchaId = number_url.split('/')[-1].split('.')[0]
data = {
"username": "admin",
"password": "123456",
"captchaSolution": f"{numbers}",
"captchaId": f"{captchaId}"
}
log_url = 'https://spiderbuf.cn/web-scraping-practice/web-scraping-with-captcha/login'
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"cache-control": "no-cache",
"content-length": "84",
"content-type": "application/x-www-form-urlencoded",
"cookie": "__check_once=zfaItN7y1h71fZjY; _ga=GA1.1.708657061.1763371540; __gads=ID=98ca5ab3854f8f7b:T=1763371542:RT=1765101346:S=ALNI_MarOlLEhFCBjKmYlgNY0raV9R7gNg; __gpi=UID=000011b788c64afc:T=1763371542:RT=1765101346:S=ALNI_Mbts5XM02bKGB6uNwuvlFoz8CPhqw; __eoi=ID=cd119b00af58d9e4:T=1763371542:RT=1765101346:S=AA-AfjbIBrUY97XhQd5DGDYSZ-on; _ga_7B42BKG1QE=GS2.1.s1765106320$o12$g0$t1765106320$j60$l0$h0",
"origin": "https://spiderbuf.cn",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://spiderbuf.cn/web-scraping-practice/web-scraping-with-captcha",
"sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
inner_text = requests.post(log_url, data=data, headers=headers)
print(inner_text.text)验证码 以及图片的ID

这个验证码的模块 很多时候会识别不准确 推荐适用第三方打码平台 或者手动输入验证码
后面和上一题的解析是一样的 这里就不过多介绍了
之后再更新后面的题目
本次的案例分析就到此结束啦 谢谢大家的观看 你的点赞和关注是我更新的最大动力
如果感兴趣的话可以看看我之前的博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号