
Java-189 Guava Cache 源码剖析:LocalCache、Segment 与 LoadingCache 工作原理全解析 - 指南
TL;DR
- 场景:线上项目广泛使用 Guava Cache,但对 LocalCache / Segment / LoadingCache 具体行为缺乏源码级认知。
- 结论:Guava 通过 LocalCache+Segment 分段结构、引用队列和访问/写入队列,实现并发安全的本地缓存、过期与刷新策略。
- 产出:一份围绕体系类图、put/get 流程与过期重载机制的工程化笔记,可直接支撑排查缓存不一致和过期异常问题。

版本矩阵
| 运行环境 | 已验证 | 说明 |
|---|---|---|
| JDK 8 + Guava 31.1-jre | 是 | 基本类结构、LocalCache/Segment/LoadingCache 行为与文中描述一致,示例代码可直接运行。 |
| JDK 11 + Guava 32.1.x-jre | 是 | API 与核心实现保持一致,主要差异集中在内部细节与警告抑制,不影响文中分析结论。 |
| JDK 17 + Guava 33.x-jre | 部分 | 整体结构延续 LocalCache 设计,局部实现有演进,建议排查问题时以对应版本源码为准。 |
原理分析
体系类图
Guava Cache的体系类图: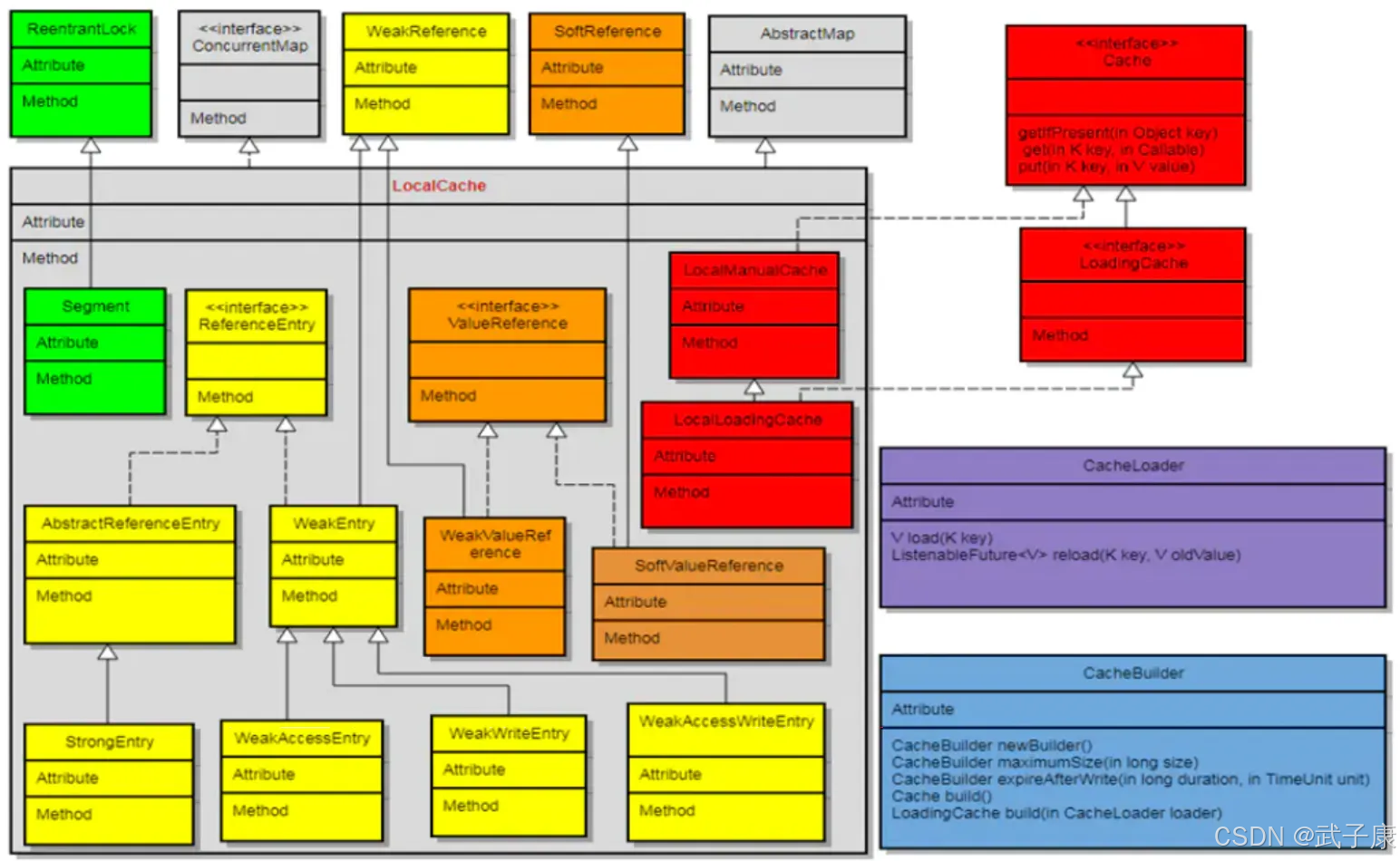
- CacheBuilder:类,缓存构建器。构建缓存的入口,指定缓存配置参数并初始化本地缓存。CacheBuilder在 build方法中,会把前面设置的参数,全部传递给 LocalCache,它自己实际不参与任何计算
- CacheLoader:抽象类,用于从数据源加载数据,定义 load、reload、loadAll 等操作。
- Cache:接口,定义 get、put、invalidate 等操作,这里只有缓存增删改查的操作,没有数据加载的操作
- LoadingCache:接口,继承自 Cache,定义 get、getUnchecked、getAll 等操作,这些操作基本上都会总数据源load数据
- LocalCache:类,整个 Guava Cache 的核心类,包含了 Guava Cache 的数据结构以及基本的缓存的操作方法
- LocalManualCache:LocalCache内部静态类,实现Cache接口,其内部的增删改查操作全部调用成员变量 LocalCache (LocalCache类型)的相应方法
- LocalLoadingCache:LocalCache内部静态类,继承自 LocalManualCache类,实现 LoadingCache接口,其所有操作也是调用成员变量 LocalCache的相应方法
LocalCache
LoadingCache这些类表示获取Cache的方式,可以有多种方式,但是他们的方法最终调用到LocalCache的方法,LocalCache是Guava Cache的核心类。
class LocalCache<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>LocalCache 为 Guava Cache 的核心类,LocalCache 的数据结构与 ConcurrentHashMap 很相似,都由多个 Segment 组成,且各 Segment 相互独立,互不影响,所以能够支持并行操作。
// Map的数组
final Segment<K, V>[] segments;
// 并发量 即segments数组的大小
final int concurrencyLevel;
...
// 访问后的过期时间 设置了expireAfterAccess就有
final long expireAfterAccessNanos;
// 写入后的过期时间 设置了expireAfterWrite就有
final long expireAfterWriteNa就有nos;
// 刷新时间 设置了refreshAfterWrite就有
final long refreshNanos;
// removal的事件队列 缓存过期后先放到该队列
final Queue<RemovalNotification<K, V>> removalNotificationQueue;
// 设置的removalListener
final RemovalListener<K, V> removalListener;
...每个 Segment 由一个Table和若干队列组成,缓存数据存储在Table中,其类型为 AtomicReferenceArray。
static class Segment<K, V> extends ReentrantLock {
/**
* 所属的 LocalCache 实例。
* Segment 通过其中的配置(过期策略、权重策略、等)来决定自身行为。
*/
final LocalCache<K, V> map;
/**
* 当前 segment 中「逻辑上存活」的元素个数(未过期且未被移除)。
*/
volatile int count;
/**
* 记录影响 table 结构的修改次数(结构性修改:插入、删除、rehash 等)。
*
* 作用:
* 1)在 size()、containsValue() 等批量读取操作中,用于检测遍历期间是否发生结构变化,
* 若遍历前后 modCount 不一致,则说明视图不再一致,需要重试。
* 2)配合 count 一起使用,作为内存可见性与「弱一致快照」的辅助机制。
*
* 可以类比为「版本号」字段,用于感知 Segment 内部结构是否被并发修改。
*/
int modCount;
/**
* 每个 Segment 自己的哈希表。
* 使用 AtomicReferenceArray 保存 ReferenceEntry,依赖 CAS 实现无锁更新。
*
* 与 ConcurrentHashMap 不同:
* - 这里存的是带引用语义的 Entry(ReferenceEntry),同时可能涉及弱引用/软引用。
* - 直接用普通数组在并发场景下无法保证线程安全,因此采用 AtomicReferenceArray。
*/
volatile AtomicReferenceArray<ReferenceEntry<K, V>> table;
/**
* 写入顺序队列:按「写入时间」排序的元素队列。
* - 元素写入(新建或替换)时加入队尾。
* - 主要用于基于写入时间的过期/淘汰策略。
*/
@GuardedBy("Segment.this")
final Queue<ReferenceEntry<K, V>> writeQueue;
/**
* 访问顺序队列:按「访问时间」排序的元素队列。
* - 每次访问(包括读和写)会把元素移动到队尾。
* - 主要用于 LRU / 基于访问时间的过期/淘汰策略。
*/
@GuardedBy("Segment.this")
final Queue<ReferenceEntry<K, V>> accessQueue;
}
interface ReferenceEntry<K, V> {
/**
* 返回该 Entry 当前持有的 ValueReference(可能是强引用、弱引用、软引用等包装)。
*/
ValueReference<K, V> getValueReference();
/**
* 设置该 Entry 的 ValueReference。
*/
void setValueReference(ValueReference<K, V> valueReference);
/**
* 返回哈希桶链表中的下一个 Entry。
* 用于在同一个 bucket 内进行冲突链表遍历。
*/
@Nullable
ReferenceEntry<K, V> getNext();
/**
* 返回该 Entry 的哈希值(通常为 key 的扰动哈希)。
*/
int getHash();
/**
* 返回该 Entry 的 key。
*/
@Nullable
K getKey();
/*
* 下面这些方法用于按访问顺序维护双向链表:
* - 使用 accessTime 以及内部的 prev/next 指针,将 Entry 串成按访问时间排序的链表。
* - 新访问的 Entry 会被移动到链表尾部,过期或被淘汰的 Entry 从链表头部移除。
*/
/**
* 返回该 Entry 最近一次被访问的时间(单位:纳秒)。
*/
long getAccessTime();
/**
* 设置该 Entry 最近一次访问时间(单位:纳秒)。
*/
void setAccessTime(long time);
}CacheBuilder
缓存构建器,构建缓存的入口,指定缓存配置参数并初始化本地缓存。
主要采用builder的模式,CacheBuilder的每一个方法都返回这个 CacheBuilder。
注意build方法有重载,带有参数的为构建一个具有数据加载功能的缓存,不带参数的构建一个没有数据加载功能的缓存。
LocalLoadingCache(
CacheBuilder<? super K, ? super V> builder,
CacheLoader<? super K, V> loader) {
// LocalLoadingCache 作为「加载型缓存」的包装实现,内部委托一个 LocalCache 来完成实际存取逻辑
super(new LocalCache<K, V>(builder, checkNotNull(loader)));
}
// 构造 LocalCache:真正持有数据、分段表和策略配置的核心实现
LocalCache(
CacheBuilder<? super K, ? super V> builder,
@Nullable CacheLoader<? super K, V> loader) {
// Segment 并发级别,取 builder 配置与 MAX_SEGMENTS 的较小值(默认并发级别通常为 4)
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
// key 的引用强度(强引用/弱引用等),由 CacheBuilder 决定
keyStrength = builder.getKeyStrength();
// value 的引用强度(强引用/弱引用/软引用等)
valueStrength = builder.getValueStrength();
// key 的等价关系(比较器),用于哈希与相等性判断
keyEquivalence = builder.getKeyEquivalence();
// value 的等价关系(比较器),用于统计、比较等场景
valueEquivalence = builder.getValueEquivalence();
// 整个缓存允许的最大权重(可以是条目数,也可以是自定义权重总和)
maxWeight = builder.getMaximumWeight();
// 权重计算器:支持按自定义权重进行淘汰控制(非简单按条目数)
weigher = builder.getWeigher();
// 访问后过期时间(纳秒):读/写访问都会刷新该时间,用于「expireAfterAccess」策略
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
// 写入后过期时间(纳秒):仅写入操作刷新,用于「expireAfterWrite」策略
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
// 自动刷新时间(纳秒):超过该时间后,下次访问会触发异步/同步刷新
refreshNanos = builder.getRefreshNanos();
// 移除监听器:元素被显式删除、覆盖、过期、容量淘汰或 GC 回收(弱/软引用)的回调
removalListener = builder.getRemovalListener();
// 移除通知队列:若为 NullListener,则使用丢弃队列;否则用无界并发队列缓存通知
removalNotificationQueue =
(removalListener == NullListener.INSTANCE)
? LocalCache.<RemovalNotification<K, V>>discardingQueue()
: new ConcurrentLinkedQueue<RemovalNotification<K, V>>();
// 计时器:用于过期与统计,recordsTime() 决定是否需要真实时间来源
ticker = builder.getTicker(recordsTime());
// Entry 工厂:根据 key 引用强度以及是否使用访问/写入队列,选择具体 Entry 实现
entryFactory = EntryFactory.getFactory(
keyStrength,
usesAccessEntries(),
usesWriteEntries()
);
// 全局统计计数器:记录命中率、加载时间、淘汰次数等
globalStatsCounter = builder.getStatsCounterSupplier().get();
// 默认缓存加载器:用于在缺失时加载 value
defaultLoader = loader;
// 初始容量:取 builder 初始容量与最大容量上限的较小值
int initialCapacity = Math.min(builder.getInitialCapacity(), MAXIMUM_CAPACITY);
// 若按权重淘汰且使用默认 weigher(权重≈条目数),则再用 maxWeight 裁剪一次初始容量
// 避免一开始就分配过大的 table
if (evictsBySize() && !customWeigher()) {
initialCapacity = Math.min(initialCapacity, (int) maxWeight);
}
}Put
这里进行 put 流程的分析:
● 上锁
● 清理队列元素:清理的是 keyReferenceQueue 和 valueReferenceQueue 两个队列,这两个队列是引用队列,如果发现key或者value被GC了,那么在put的时候触发清理
● setValue方法做的是将value写入到Entry
V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 加锁,保证当前 Segment 内 put 操作的线程安全
lock();
try {
// 当前时间戳(用于写入、过期判断等)
long now = map.ticker.read();
// 写入前的清理:处理过期、回收引用、队列清理等
preWriteCleanup(now);
...
// 当前 Segment 的哈希表
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
// 根据 hash 计算桶下标(length 为 2 的幂,通过位与加速取模)
int index = hash & (table.length() - 1);
// 桶中链表的头结点
ReferenceEntry<K, V> first = table.get(index);
// 在该桶的链表中查找是否已存在相同 key
// Look for an existing entry.
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
// 找到已存在的 entry
ValueReference<K, V> valueReference = e.getValueReference();
// 取出旧 value
V entryValue = valueReference.get();
// 旧 value 为 null(可能已被 GC 回收,仅剩下 key/Entry 外壳)
if (entryValue == null) {
++modCount;
if (valueReference.isActive()) {
// 已处于激活状态但 value 被回收,发送回收通知,尽量缩短持锁时间
enqueueNotification(
key,
hash,
entryValue,
valueReference.getWeight(),
RemovalCause.COLLECTED
);
// 复用原有 Entry,写入新 value,并写入写队列/访问队列
setValue(e, key, value, now);
// 逻辑上是“覆盖”,count 不变
newCount = this.count;
} else {
// 非激活引用,视作新插入:写入新 value,并加入写队列/访问队列
setValue(e, key, value, now);
// 元素数增加 1
newCount = this.count + 1;
}
// 写 volatile,保证 count 的内存可见性
this.count = newCount;
// 按权重/容量策略执行逐出
evictEntries(e);
return null;
} else if (onlyIfAbsent) {
// 已存在指定 key,并且配置为 onlyIfAbsent:
// 本次只做“读 + 访问更新”,不覆盖旧值,但需要更新访问队列
.......
setValue(e, key, value, now); // 存储数据,并写入写队列/访问队列(根据策略)
// 根据容量/权重淘汰数据
evictEntries(e);
return entryValue;
}
}
}
// 链表中不存在目标 key,新建 Entry
// Create a new entry.
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
// 绑定 value,并写入写队列/访问队列
setValue(newEntry, key, value, now);
......
} finally {
// 释放锁
unlock();
// 写入后的清理:处理通知回调、延迟删除等
postWriteCleanup();
}
}Get
Get流程分析:
● 获取对象引用(引用可能是非alive的,比如是需要失效的,比如是loading的)
● 判断对象引用是否是alive的(如果entry是非法的、部分回收的、loading状态、需要失效的,则认为不是alive)
● 如果对象是alive的,如果设置 refresh,则异步刷新查询value,然后等待返回最新的value
● 针对不是alive的,但却是在loading的,等待loading完成(阻塞等待)
● 这里如果value还没有拿到,则查询loader方法获取对应的值(阻塞获取)
// LoadingCache methods
// LocalCache 的对外入口:通过 LoadingCache 语义对外提供 get 能力,内部委派到 Segment
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key)); // 对 key 做 hash -> rehash
return segmentFor(hash).get(key, hash, loader);
}
// loading
// 对指定 key 执行加载型读取:优先无锁读,读不到或失效时再进入加锁加载流程
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
....
try {
if (count != 0) {
// 先做一次 volatile 读:
// - 非 0 说明当前段中「很可能」已有元素
// - 作为 volatile 读,可以刷新本段的可见性缓存
// 若为 0,可直接跳过查找,走加载路径
// 不使用 getLiveEntry,因为其中会忽略「正在加载中的值」
ReferenceEntry<K, V> e = getEntry(key, hash);
// 命中 Entry:说明 key 仍在表中(但值可能已过期)
if (e != null) {
long now = map.ticker.read();
// 当前时间戳,用于结合过期策略判断 value 是否仍然“活着”
V value = getLiveValue(e, now);
// 懒失效:在每次 get 时才检查是否过期,过期则视为未命中并回退到加载路径
......
}
}
// 运行到这里时,说明:
// - 段中没有元素(count == 0),或者
// - 未找到对应 Entry,或者
// - 找到了但已过期
// 统一进入加锁的加载路径
// at this point e is either null or expired
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
// 将底层异常按约定包装/转换后抛出
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
// 每次 get / put 后都做一次读后清理:
// - 清理过期条目
// - 回收无效引用
// - 维护队列/统计的一致性
postReadCleanup();
}
}过期重载
数据过期不会自动重载,而是通过get操作时执行过期重载,具体就是 CacheBuilder构造的LocalLoadingCache。
/**
* 支持自动加载(Loading)的本地缓存实现。
*
* 在 LocalManualCache 基础上增加了 CacheLoader:
* - 手动 put/get 仍然可用;
* - 未命中时可以通过 CacheLoader 自动加载。
*/
static class LocalLoadingCache<K, V> extends LocalManualCache<K, V>
implements LoadingCache<K, V> {
LocalLoadingCache(
CacheBuilder<? super K, ? super V> builder,
CacheLoader<? super K, V> loader) {
// LocalCache 内部持有 CacheLoader,用于 getOrLoad / getAll 时的自动加载
super(new LocalCache<K, V>(builder, checkNotNull(loader)));
}
// LoadingCache methods
/**
* 返回给定 key 对应的值;如果不存在则通过 CacheLoader 加载。
*
* 若加载过程中抛出异常,会被封装为 ExecutionException 抛出。
*/
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
/**
* 与 get(key) 类似,但不会声明受检异常:
* - 若加载抛出异常,会被包装为 UncheckedExecutionException(运行时异常)。
*/
@Override
public V getUnchecked(K key) {
try {
return get(key);
} catch (ExecutionException e) {
throw new UncheckedExecutionException(e.getCause());
}
}
/**
* 批量加载:对一组 key 执行 get/自动加载,并返回不可变 Map。
*
* 具体加载策略由 LocalCache + CacheLoader 决定(可能合并批量加载)。
*/
@Override
public ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException {
return localCache.getAll(keys);
}
/**
* 主动刷新指定 key:
* - 通常会异步触发 CacheLoader 重新加载;
* - 刷新期间旧值在一定时间窗口内仍可被读取。
*/
@Override
public void refresh(K key) {
localCache.refresh(key);
}
/**
* 使 LocalLoadingCache 可以作为 Function<K, V> 使用:
* - 语义等价于 getUnchecked(key)。
*/
@Override
public final V apply(K key) {
return getUnchecked(key);
}
// Serialization Support
private static final long serialVersionUID = 1L;
/**
* 自定义序列化代理:
* - 通过 LoadingSerializationProxy 进行序列化,
* 避免直接序列化 LocalLoadingCache 的内部结构。
*/
@Override
Object writeReplace() {
return new LoadingSerializationProxy<K, V>(localCache);
}
}错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 缓存偶发读到“看起来已经过期”的旧数据 | 仅配置 expireAfterWrite/expireAfterAccess,依赖懒失效;无 refreshAfterWrite 或手动 refresh | 打印命中/未命中与时间戳,结合 getLiveValue 行为分析;对热点 key 做压测复现 |
| 对一致性要求高的 key 配置 refreshAfterWrite 或显式 refresh;必要时在业务层加版本校验 | ||
| size() 在高并发下明显跳动,无法当作“真实条目数”使用 | LocalCache.Segment 的 count + modCount 设计为弱一致快照,非强一致计数 | 在压测/生产中循环打印 size(),与实际存取操作对比,观察抖动模式 |
| 避免用 size() 做容量/限流判断,仅用于监控;容量控制依赖 maximumSize / maximumWeight 配置 | ||
| QPS 突增时偶发长尾请求,堆栈显示卡在 CacheLoader / get() | CacheLoader 执行时间长,且多个线程对同一 key 发生串行等待(lockedGetOrLoad) | 采样堆栈与加载时间,统计 loader 调用耗时分布;关注热点 key 的 get() 调用链 |
| 优化数据源查询或引入本地合并加载;对超时场景增加兜底;对热点 key 适当预热以减少同步加载 | ||
| JVM 堆占用持续升高,怀疑 Guava Cache 导致“伪 OOM” | 未设置 maximumSize/maximumWeight 或 weigher 配置不合理,访问/写入队列清理不及时 | 通过 heap dump 统计 LocalCache.Segment / ReferenceEntry 数量与引用链长度 |
| 明确设置容量与权重策略;结合业务 TTL 选择 expireAfterWrite/expireAfterAccess,并配合定期访问 | ||
| 以为 refreshAfterWrite 会“强制返回新值”,实际仍返回旧值一段时间 | 误解 LocalLoadingCache.refresh 语义:刷新可异步执行,刷新期间旧值仍可能被读到 | 在 CacheLoader 和 refresh 路径打日志,观察同一 key 在刷新前后返回值与时间线 |
| 对强一致读路径不要依赖刷新语义;需要“强制新值”时显式 get+重载或引入版本号控制 | ||
| 代码阅读中误把 Segment.count / modCount 理解为“强一致版本号” | 这两个字段仅用于辅助弱一致遍历与快速变化检测,不保证读操作期间绝对不变 | 对比 size()/containsValue 实现与 CHM 设计,理解“多次尝试+不一致即放弃”的策略 |
| 在设计依赖缓存的业务逻辑时只假定“最终一致”,不要基于这些统计字段做强一致流程控制 |
其他系列
AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
AI模块直达链接
Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新… 深入浅出助你打牢基础!
Java模块直达链接
大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
大数据模块直达链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号