
YOLOv8【第七章:损失函数篇·第6节】一文搞定,InnerShapeIoU内部形状损失! - 指南
本文收录于《YOLOv8实战:从入门到深度优化》专栏。该专栏系统复现并梳理全网各类YOLOv8 改进与实战案例(当前已覆盖分类 / 检测 / 分割 / 追踪 / 关键点 / OBB 检测等方向),坚持持续更新 + 深度解析,质量分长期稳定在 97 分以上,可视为当前市面上覆盖较全、更新较快、实战导向极强的 YOLO 改进系列内容之一。
部分章节也会结合国内外前沿论文与 AIGC 等大模型技术,对主流改进方案进行重构与再设计,内容更偏实战与可落地,适合有工程需求的同学深入学习与对标优化。
✨ 特惠福利:当前限时活动一折秒杀,一次订阅,终身有效,后续所有更新章节全部免费解锁,点此查看详情
全文目录:
- 上期回顾
- 1. 引言:Bbox回归的“天花板”——甜甜圈问题 (The Donut Problem)
- 2. 为什么必须感知“内部形状”?
- 3. InnerShapeIoU的哲学:从“框”到“内容”
- 4. 核心机制:基于Keypoints的L I n n e r S h a p e L_{InnerShape}LInnerShape
- 5. 深度分析:L I n n e r S h a p e L_{InnerShape}LInnerShape vs L C I o U / L E I o U L_{CIoU} / L_{EIoU}LCIoU/LEIoU
- 6. 局限性与“鸡生蛋”问题
- 7. Python代码实战 (概念):达成 `InnerShapeLoss`
- 8. 总结:Bbox回归的“内容感知”革命
- 9. 下期预告:QFL质量Focal Loss与IoU感知
- 文末福利,等你来拿!
- Who am I?
上期回顾
大家好!欢迎回到《YOLOv8专栏》!在上一篇《YOLOv8【第七章:损失函数篇·第5节】一文搞定,ShapeIoU形状感知损失函数!》内容中,我们进行了一次深刻的“形状”哲学思辨:
几何特征提取:大家没有沿用w , h w, hw,h这两个“间接”属性,而是回归到Bbox最基础的“几何特征”——4个角点。
“耦合”损失推导:通过计算“中心化”Bbox的4个角点对应距离,我们惊奇地发现d 1 = d 2 = d 3 = d 4 d_1=d_2=d_3=d_4d1=d2=d3=d4。这推导出 L S h a p e L_{Shape}LShape 的本质是 ( Δ w , Δ h ) (\Delta w, \Delta h)(Δw,Δh) 误差向量的 L 2 L_2L2范数:
L S h a p e ∝ ∣ ∣ ( Δ w , Δ h ) ∣ ∣ 2 L_{Shape} \propto ||(\Delta w, \Delta h)||_2LShape∝∣∣(Δw,Δh)∣∣2两大策略对比:大家通过关键场景测试,清晰地对比了两种形状损失策略:
- L E I o U L_{EIoU}LEIoU(解耦 / 各向异性):L a s p = ( Δ w C w ) 2 + ( Δ h C h ) 2 L_{asp} = (\frac{\Delta w}{C_w})^2 + (\frac{\Delta h}{C_h})^2Lasp=(CwΔw)2+(ChΔh)2。它对闭包框C CC的“短边”方向上的误差(如C h = 10 C_h=10Ch=10)惩罚极其严重。
- L S h a p e I o U L_{ShapeIoU}LShapeIoU(耦合 / 各向同性):L a s p = ∣ ∣ ( Δ w , Δ h ) ∣ ∣ 2 ∣ ∣ ( C w , C h ) ∣ ∣ 2 L_{asp} = \frac{||(\Delta w, \Delta h)||_2}{||(C_w, C_h)||_2}Lasp=∣∣(Cw,Ch)∣∣2∣∣(Δw,Δh)∣∣2。它只关心 ( Δ w , Δ h ) (\Delta w, \Delta h)(Δw,Δh)误差向量的“总长度”(L 2 L_2L2距离),而不在乎其方向。
上期的探索让我们意识到,L S h a p e L_{Shape}LShape 的设计远非 L E I o U L_{EIoU}LEIoU一种方案,ShapeIoU的“耦合”思想为我们提供了全新的视角。
然而,无论是L E I o U L_{EIoU}LEIoU 还是 L S h a p e I o U L_{ShapeIoU}LShapeIoU,它们都只是在“拟合”B g t B_{gt}Bgt 的 w g t w_{gt}wgt 和 h g t h_{gt}hgt。它们都默认B g t B_{gt}Bgt这个“矩形”就是我们的终极目标。
可 B g t B_{gt}Bgt只是一个“标签框”,它不是“物体”本身!这种“指框为物”的回归方式,已经触碰到了Bbox回归的“天花板”。
1. 引言:Bbox回归的“天花板”——甜甜圈问题 (The Donut Problem)
我们所有的IoU Loss(CIoU, EIoU,α \alphaα-IoU…)都在追求一个目标:I o U → 1 IoU \to 1IoU→1,即 L I o U → 0 L_{IoU} \to 0LIoU→0。
但当 L I o U = 0 L_{IoU} = 0LIoU=0时,我们就真的“赢”了吗?
1.1 场景复现:完美的回归,错误的结果 (Mermaid图解)
场景:检测一个“甜甜圈” (或字母 ‘O’)。就是我们的目标
- B g t B_{gt}Bgt(真实框):是一个紧密包裹住“甜甜圈”的实心正方形。
- M g t M_{gt}Mgt(真实物体): 是一个空心的环形。
- B p r e d B_{pred}Bpred(预测框):经过模型训练,B p r e d B_{pred}Bpred 与 B g t B_{gt}Bgt 完美重合。
此时的损失:
- L I o U = 1 − 1 = 0 L_{IoU} = 1 - 1 = 0LIoU=1−1=0
- L D I o U = 0 L_{DIoU} = 0LDIoU=0(中心点重合)
- L C I o U = 0 L_{CIoU} = 0LCIoU=0(长宽比一致)
结论:模型的Bbox损失为 0!这是一个“完美”的预测。
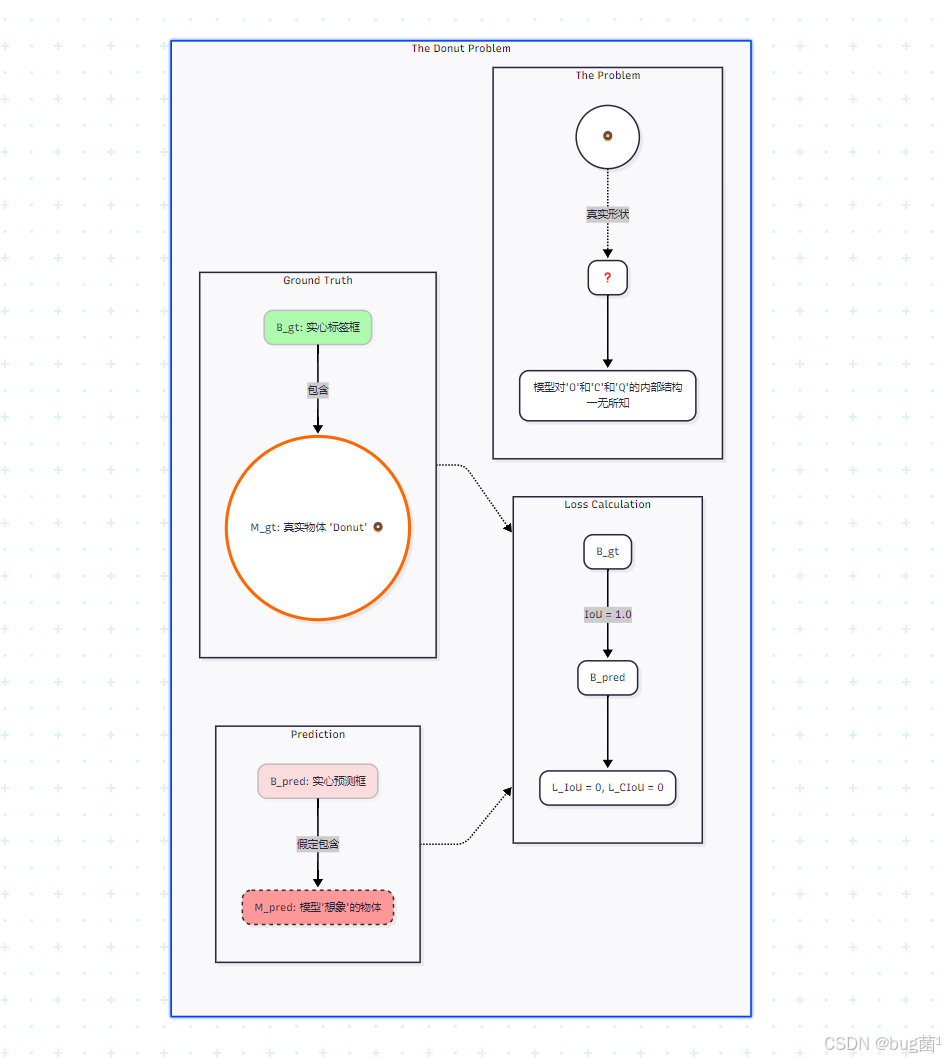
图解分析:
所有的Bbox损失函数,都只在B g t B_{gt}Bgt 和 B p r e d B_{pred}Bpred (两个实心矩形) 之间进行比较。它们完美重合了,损失为0。
但 B p r e d B_{pred}Bpred(实心) 和M g t M_{gt}Mgt(空心) 在拓扑结构上是根本不同的!模型从 L I o U = 0 L_{IoU}=0LIoU=0中学不到任何关于“空心”这个“内部形状”的信息。
1.2 “框”与“物”的分离:Bbox的局限性
“甜甜圈问题”暴露了Bbox回归的根本局限性:
在拟合“物”(Content)。就是Bbox回归,是在拟合“框”(Container),而不
B
g
t
B_{gt}Bgt 只是 M
g
t
M_{gt}Mgt的一个极其粗糙、轴对齐的外壳。
我们之前所有的L
S
h
a
p
e
L_{Shape}LShape(CIoU, EIoU, ShapeIoU) 都在拼命地拟合这个外壳的 w
g
t
,
h
g
t
w_{gt}, h_{gt}wgt,hgt,而这个 w
g
t
,
h
g
t
w_{gt}, h_{gt}wgt,hgt本身就丢失了物体99%的内部形状信息。
“实例感知”回归?就是1.3 什么
“实例感知”(Instance-aware)回归,是一种更高级的回归。它不仅要知道物体在哪里(Bbox),还要在一定程度上理解它是什么形态(Shape)。
大家需要的损失函数,必须能“穿透”B
g
t
B_{gt}Bgt的外壳,去“采样”M
g
t
M_{gt}Mgt内部的结构信息,并以此来指导B
p
r
e
d
B_{pred}Bpred 的回归。
这就是 L
I
n
n
e
r
S
h
a
p
e
L_{InnerShape}LInnerShape 的使命。
2. 为什么需感知“内部形状”?
2.1 Case 1: L形/细长物体(如:L形沙发、电线杆)
- 问题:对于一个’L’形的沙发,B g t B_{gt}Bgt会框出一个大正方形,这个正方形的右上角 1/4 区域完全是空的。
- Bbox歧义性: 存在多种 w , h w, hw,h组合,它们都能以高I o U IoUIoU“框住”这个L形。
- L E I o U L_{EIoU}LEIoU 的困境:L E I o U L_{EIoU}LEIoU 会试图让 B p r e d B_{pred}Bpred 的 w , h w, hw,h 匹配 B g t B_{gt}Bgt 的 w g t , h g t w_{gt}, h_{gt}wgt,hgt。但 B g t B_{gt}Bgt本身就是一个“臃肿”且“充满歧义”的框。
- L I n n e r S h a p e L_{InnerShape}LInnerShape 的优势: 如果 L I n n e r S h a p e L_{InnerShape}LInnerShape能感知到’L’形的几个“拐点”,它就能提供一个“收缩”的梯度,迫使B p r e d B_{pred}Bpred 的 w , h w,hw,h盲目匹配那个“臃肿”的就是变得更“紧凑”,而不B g t B_{gt}Bgt。
2.2 Case 2: 拓扑结构差异(如:字母’O’ vs ‘C’)
- 问题:字母’O’和字母’C’的B g t B_{gt}Bgt 可能是完全相同的。
- Bbox的无能:任何Bbox Loss都无法区分这两种情况。
- L I n n e r S h a p e L_{InnerShape}LInnerShape 的优势:'O’的内部关键点是“闭合”的,'C’的内部关键点是“开放”的。L I n n e r S h a p e L_{InnerShape}LInnerShape 可以惩罚 B p r e d B_{pred}Bpred对此种内部拓扑结构的错误建模,从而供应Bbox Loss无法提供的、更高级的“形状”梯度。
2.3 Case 3: 辅助高质量实例分割
- 问题:在实例分割任务中(如YOLOv8-seg),模型需要先预测Bbox,再在该Bbox内预测Mask。
- Bbox的基石作用: 如果 B p r e d B_{pred}Bpred本身就是“臃肿”的(比如’L’形物体的Bbox),那么分割头(Mask Head)就需费力地去“擦除”Bbox中多余的空白区域。
- L I n n e r S h a p e L_{InnerShape}LInnerShape 优势: 如果 L B b o x L_{Bbox}LBbox(Bbox损失) 已经包括了L I n n e r S h a p e L_{InnerShape}LInnerShape,那么它会“逼迫”Bbox Head去预测一个更“紧凑”、更“贴合”物体真实轮廓的B p r e d B_{pred}Bpred。这个高质量的B p r e d B_{pred}Bpred将极大地降低分割头的学习难度。
3. InnerShapeIoU的哲学:从“框”到“内容”
3.1 核心思想:L T o t a l = L B b o x + λ ⋅ L I n n e r S h a p e L_{Total} = L_{Bbox} + \lambda \cdot L_{InnerShape}LTotal=LBbox+λ⋅LInnerShape
L I n n e r S h a p e L_{InnerShape}LInnerShape一个就是(内部形状损失) 必须附加项。我们不能抛弃L B b o x L_{Bbox}LBbox (如 L C I o U L_{CIoU}LCIoU 或 L E I o U L_{EIoU}LEIoU),因为 L B b o x L_{Bbox}LBbox负责核心的“定位”(Localization)和“尺度”(Scale)回归。
大家的新损失函数将是:
L T o t a l = L B b o x _ R e g r e s s i o n + λ ⋅ L I n n e r S h a p e _ R e g r e s s i o n L_{Total} = L_{Bbox\_Regression} + \lambda \cdot L_{InnerShape\_Regression}LTotal=LBbox_Regression+λ⋅LInnerShape_Regression
其中 λ \lambdaλ是一个平衡权重。
3.2 L I n n e r S h a p e L_{InnerShape}LInnerShape的“锚点”:内部关键点(Keypoints)
如何建模“内部形状”?
- 方案A (Mask-based):通过如引言中提到的,我们能够用B p r e d B_{pred}Bpred 和 B g t B_{gt}Bgt 裁剪 M p r e d M_{pred}Mpred 和 M g t M_{gt}Mgt,然后计算 Mask IoU。这是可行的,但它应该一个分割头来预测 M p r e d M_{pred}Mpred。这已经超出了“Bbox回归”的范畴,进入了“分割”的领域。
- 方案B (Keypoint-based):这是一个更“轻量级”且更巧妙的方案。我们不需要完整的Mask,只需要物体内部的N NN 个 “语义关键点”(Semantic Keypoints)或“结构骨架点”(Skeleton Points)。
例如,对于“人”,我们可以使用 COCO-Pose 的17个关键点(眼、鼻、肩、肘…)。
对于“甜甜圈”,我们允许应用其内环和外环上的8个点。
L I n n e r S h a p e L_{InnerShape}LInnerShape的本质,就是B p r e d B_{pred}Bpred的“内部”与B g t B_{gt}Bgt的“内部结构”之间的匹配损失。
4. 核心机制:基于Keypoints的L I n n e r S h a p e L_{InnerShape}LInnerShape
这是 I n n e r S h a p e I o U InnerShapeIoUInnerShapeIoU概念的核心。
4.1 引入新监督:关键点相对坐标
我们要求新的Ground Truth:
对于 B g t = ( x c g t , y c g t , w g t , h g t ) B_{gt} = (x_{c_gt}, y_{c_gt}, w_{gt}, h_{gt})Bgt=(xcgt,ycgt,wgt,hgt),大家还得一组N NN 个关键点 K g t = { k 1 g t , . . . , k N g t } K_{gt} = \{k_1^{gt}, ..., k_N^{gt}\}Kgt={k1gt,...,kNgt}。
k i g t = ( x i g t , y i g t ) k_i^{gt} = (x_i^{gt}, y_i^{gt})kigt=(xigt,yigt)(绝对坐标)。
为了让 L I n n e r S h a p e L_{InnerShape}LInnerShape成为一个“形状”损失(位置无关),大家将其转换为相对于 B g t B_{gt}Bgt中心点和尺度的“归一化”坐标:
k i _ n o r m g t = ( x i g t − x c _ g t w g t , y i g t − y c _ g t h g t ) k_{i\_norm}^{gt} = (\frac{x_i^{gt} - x_{c\_gt}}{w_{gt}}, \frac{y_i^{gt} - y_{c\_gt}}{h_{gt}})ki_normgt=(wgtxigt−xc_gt,hgtyigt−yc_gt)
k
i
_
n
o
r
m
g
t
k_{i\_norm}^{gt}ki_normgt的值域通常在[
−
0.5
,
0.5
]
[-0.5, 0.5][−0.5,0.5] 之间。
这组 K
n
o
r
m
g
t
=
{
k
1
_
n
o
r
m
g
t
,
.
.
.
,
k
N
_
n
o
r
m
g
t
}
K_{norm}^{gt} = \{k_{1\_norm}^{gt}, ..., k_{N\_norm}^{gt}\}Knormgt={k1_normgt,...,kN_normgt},就是 B
g
t
B_{gt}Bgt的“内部结构”的数学描述!
4.2 模型改造:从( x , y , w , h ) (x,y,w,h)(x,y,w,h) 到 ( x , y , w , h , k 1 , . . . , k N ) (x,y,w,h, k_1, ..., k_N)(x,y,w,h,k1,...,kN)
我们必须改造YOLOv8的检测头(Detection Head)。
原始Head对每个Bbox预测:
- 4 个值 (Bbox)
- C CC个值 (Classes)
新Head(InnerShape Head)需要预测:
- 4 个值 (Bbox:x c , y c , w , h x_c, y_c, w, hxc,yc,w,h)
- C CC个值 (Classes)
- N × 2 N \times 2N×2个值 (Keypoints:k 1 _ n o r m p r e d , . . . , k N _ n o r m p r e d k_{1\_norm}^{pred}, ..., k_{N\_norm}^{pred}k1_normpred,...,kN_normpred)
模型预测的也是归一化的关键点偏移量。
4.3 L I n n e r S h a p e L_{InnerShape}LInnerShape的梯度:反向传播的“魔法”
现在,激动人心的时刻到了。我们如何计算L I n n e r S h a p e L_{InnerShape}LInnerShape 并让它反向传播以优化 w , h w, hw,h?
从输出中提取:
- B p r e d = ( x c , y c , w , h ) B_{pred} = (x_c, y_c, w, h)Bpred=(xc,yc,w,h)
- K n o r m p r e d = { ( Δ x 1 p r e d , Δ y 1 p r e d ) , . . . } K_{norm}^{pred} = \{ (\Delta x_1^{pred}, \Delta y_1^{pred}), ... \}Knormpred={(Δx1pred,Δy1pred),...}
从Ground Truth中提取:
- B g t = ( x c _ g t , y c _ g t , w g t , h g t ) B_{gt} = (x_{c\_gt}, y_{c\_gt}, w_{gt}, h_{gt})Bgt=(xc_gt,yc_gt,wgt,hgt)
- K n o r m g t = { ( Δ x 1 g t , Δ y 1 g t ) , . . . } K_{norm}^{gt} = \{ (\Delta x_1^{gt}, \Delta y_1^{gt}), ... \}Knormgt={(Δx1gt,Δy1gt),...}
计算“预测的绝对关键点”K a b s p r e d K_{abs}^{pred}Kabspred:
- x i p r e d = x c + Δ x i p r e d ⋅ w x_i^{pred} = x_c + \Delta x_i^{pred} \cdot wxipred=xc+Δxipred⋅w
- y i p r e d = y c + Δ y i p r e d ⋅ h y_i^{pred} = y_c + \Delta y_i^{pred} \cdot hyipred=yc+Δyipred⋅h
计算“真实的绝对关键点”K a b s g t K_{abs}^{gt}Kabsgt:
- (注:我们不需要B g t B_{gt}Bgt来计算,GTK a b s g t = ( x i g t , y i g t ) K_{abs}^{gt} = (x_i^{gt}, y_i^{gt})Kabsgt=(xigt,yigt)是直接给定的)
计算 L I n n e r S h a p e L_{InnerShape}LInnerShape:
- 通常使用 L1, L2 或 OKS (Object Keypoint Similarity) 损失。
- L I n n e r S h a p e = ∑ i = 1 N L1 ( ( x i p r e d , y i p r e d ) , ( x i g t , y i g t ) ) L_{InnerShape} = \sum_{i=1}^{N} \text{L1}( (x_i^{pred}, y_i^{pred}), (x_i^{gt}, y_i^{gt}) )LInnerShape=∑i=1NL1((xipred,yipred),(xigt,yigt))
- L I n n e r S h a p e = ∑ i = 1 N ∣ ( x c + Δ x i p r e d ⋅ w ) − x i g t ∣ + ∣ ( y c + Δ y i p r e d ⋅ h ) − y i g t ∣ L_{InnerShape} = \sum_{i=1}^{N} | (x_c + \Delta x_i^{pred} \cdot w) - x_i^{gt} | + | (y_c + \Delta y_i^{pred} \cdot h) - y_i^{gt} |LInnerShape=∑i=1N∣(xc+Δxipred⋅w)−xigt∣+∣(yc+Δyipred⋅h)−yigt∣
梯度的产生:
我们来看 L
I
n
n
e
r
S
h
a
p
e
L_{InnerShape}LInnerShape 对 w
ww 和 h
hh 的偏导数:
∂ L I n n e r S h a p e ∂ w = ∑ i = 1 N sign ( ( x c + Δ x i p r e d ⋅ w ) − x i g t ) ⋅ Δ x i p r e d \frac{\partial L_{InnerShape}}{\partial w} = \sum_{i=1}^{N} \text{sign}( (x_c + \Delta x_i^{pred} \cdot w) - x_i^{gt} ) \cdot \Delta x_i^{pred}∂w∂LInnerShape=i=1∑Nsign((xc+Δxipred⋅w)−xigt)⋅Δxipred
∂ L I n n e r S h a p e ∂ h = ∑ i = 1 N sign ( ( y c + Δ y i p r e d ⋅ h ) − y i g t ) ⋅ Δ y i p r e d \frac{\partial L_{InnerShape}}{\partial h} = \sum_{i=1}^{N} \text{sign}( (y_c + \Delta y_i^{pred} \cdot h) - y_i^{gt} ) \cdot \Delta y_i^{pred}∂h∂LInnerShape=i=1∑Nsign((yc+Δyipred⋅h)−yigt)⋅Δyipred
这就是魔法! ♂️
- L I n n e r S h a p e L_{InnerShape}LInnerShape 对 w ww产生了梯度!
- L I n n e r S h a p e L_{InnerShape}LInnerShape 对 h hh 产生了梯度
L B b o x L_{Bbox}LBbox (如 L E I o U L_{EIoU}LEIoU) 也在对 w , h w, hw,h 产生梯度。
现在, w , h w, hw,h的总梯度是:
∂ L T o t a l ∂ w = ∂ L B b o x ∂ w + λ ⋅ ∂ L I n n e r S h a p e ∂ w \frac{\partial L_{Total}}{\partial w} = \frac{\partial L_{Bbox}}{\partial w} + \lambda \cdot \frac{\partial L_{InnerShape}}{\partial w}∂w∂LTotal=∂w∂LBbox+λ⋅∂w∂LInnerShape
4.4 几何图解:w , h w,hw,h误差如何扭曲内部结构
场景: 真实物体 M g t M_{gt}Mgt是一个瘦高的人 ️ (w g t = 10 , h g t = 40 w_{gt}=10, h_{gt}=40wgt=10,hgt=40)。
- B g t B_{gt}Bgt(实线绿框) 完美包裹。
- K g t K_{gt}Kgt(绿色圆点) 是其肩部和臀部的4个关键点。
预测: 模型预测 B p r e d B_{pred}Bpred(虚线红框)I o U = 1 IoU=1IoU=1,但 w , h w,hw,h 搞反了 (w = 40 , h = 10 w=40, h=10w=40,h=10)。
- 模型 同时预测了正确的归一化 关键点 K n o r m p r e d = K n o r m g t K_{norm}^{pred} = K_{norm}^{gt}Knormpred=Knormgt。
计算 K a b s p r e d K_{abs}^{pred}Kabspred(红色X点):
B p r e d B_{pred}Bpred 用 w = 40 w=40w=40(一个大宽度) 和h = 10 h=10h=10(一个小高度) 去“拉伸”这些归一化坐标。
结果:预测出的绝对关键点K a b s p r e d K_{abs}^{pred}Kabspred(红色X) 被“压扁”了!
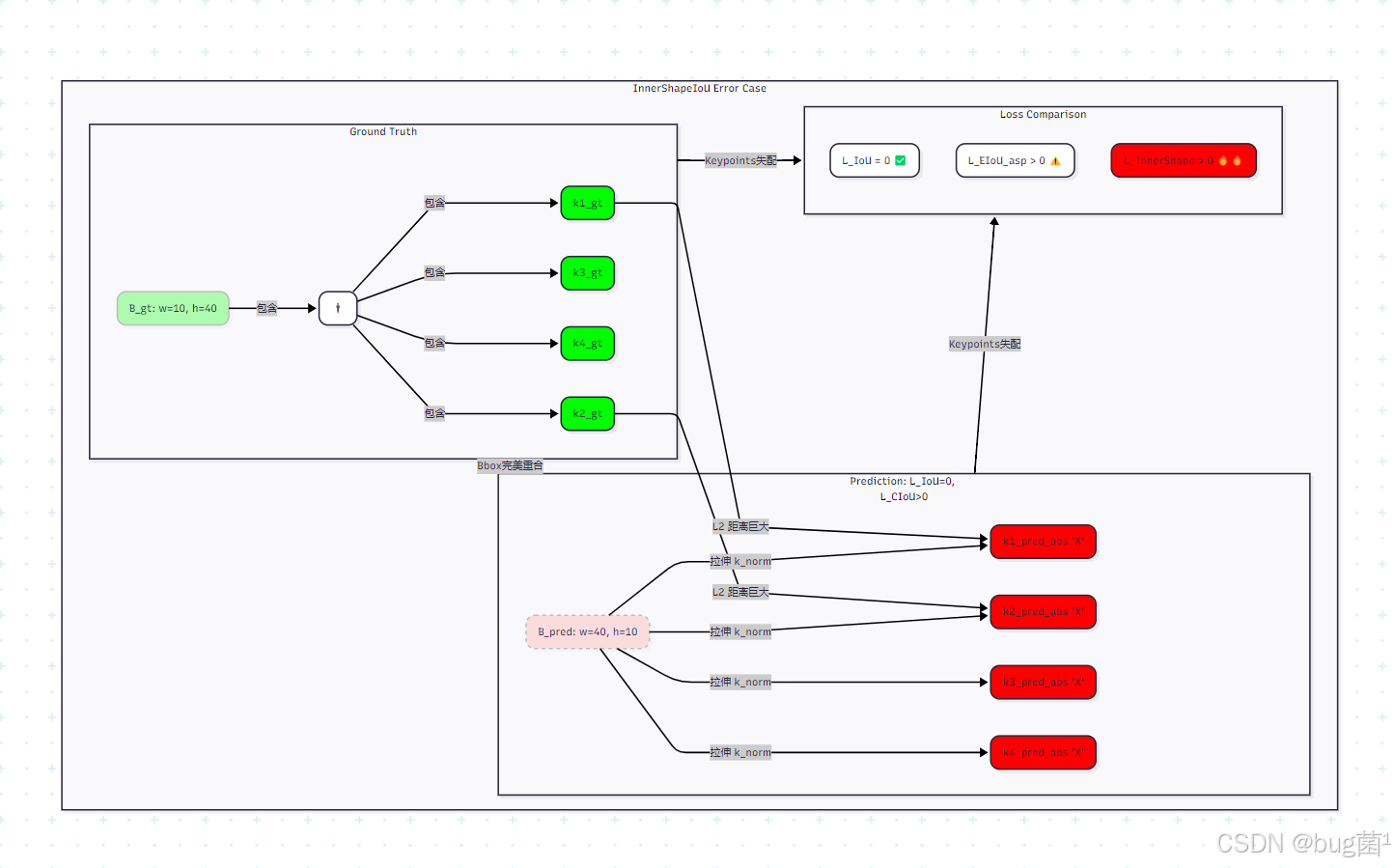
图解分析:
B p r e d B_{pred}Bpred 和 B g t B_{gt}Bgt完美重合(只是为了说明),L I o U = 0 L_{IoU}=0LIoU=0。
L E I o U L_{EIoU}LEIoU会惩罚这个,因为( 40 − 10 C w ) 2 + ( 10 − 40 C h ) 2 > 0 (\frac{40-10}{C_w})^2 + (\frac{10-40}{C_h})^2 > 0(Cw40−10)2+(Ch10−40)2>0。
L I n n e r S h a p e L_{InnerShape}LInnerShape也会惩罚这个! 因为 B p r e d B_{pred}Bpred 的 w = 40 , h = 10 w=40, h=10w=40,h=10(错误) 应用到K n o r m p r e d K_{norm}^{pred}Knormpred(正确) 上,得到了K a b s p r e d K_{abs}^{pred}Kabspred(红色X点,被压扁),K a b s p r e d K_{abs}^{pred}Kabspred 与 K a b s g t K_{abs}^{gt}Kabsgt(绿色圆点) 之间产生了巨大的L 2 L2L2 距离。
这个 L I n n e r S h a p e L_{InnerShape}LInnerShape 损失会产生 ∂ L ∂ w \frac{\partial L}{\partial w}∂w∂L 和 ∂ L ∂ h \frac{\partial L}{\partial h}∂h∂L梯度,“告诉”模型:
- “你的 w = 40 w=40w=40太大了,它把内部结构拉得太宽了,快减小w ww!”
- “你的 h = 10 h=10h=10太小了,它把内部结构压得太扁了,快增大h hh!”
5. 深度分析:L I n n e r S h a p e L_{InnerShape}LInnerShape vs L C I o U / L E I o U L_{CIoU} / L_{EIoU}LCIoU/LEIoU
5.1 “盲目”的L a s p L_{asp}Laspvs “有据”的L I n n e r S h a p e L_{InnerShape}LInnerShape
L E I o U L_{EIoU}LEIoU (盲目):
- L E I o U L_{EIoU}LEIoU 的 L a s p = ( w − w g t C w ) 2 + . . . L_{asp} = (\frac{w - w_{gt}}{C_w})^2 + ...Lasp=(Cww−wgt)2+...是“盲目”的。它只知道 B g t B_{gt}Bgt 的 w g t , h g t w_{gt}, h_{gt}wgt,hgt是“真理”,它不理解为什么。
- 它惩罚 Δ w , Δ h \Delta w, \Delta hΔw,Δh是因为它*“和B g t B_{gt}Bgt不一样”*。
L I n n e r S h a p e L_{InnerShape}LInnerShape (有据):
- L I n n e r S h a p e L_{InnerShape}LInnerShape是“有理有据”的。
- 它惩罚 Δ w , Δ h \Delta w, \Delta hΔw,Δh是因为它*“扭曲了物体的内部结构”*。
L I n n e r S h a p e L_{InnerShape}LInnerShape是一种更高级、更符合物理直觉、基于“内容感知”(Content-Aware)的形状损失。
5.2 解决“L形”物体的Bbox歧义性
L E I o U L_{EIoU}LEIoU 的困境:对于’L’形物体,B g t B_{gt}Bgt是一个“臃肿”的大方块。L E I o U L_{EIoU}LEIoU会“错误地”奖励B p r e d B_{pred}Bpred去匹配该“臃肿”的B g t B_{gt}Bgt。
L I n n e r S h a p e L_{InnerShape}LInnerShape 的胜利:'L’形物体的关键点K g t K_{gt}Kgt 只分布在 B g t B_{gt}Bgt的左侧和下侧。
- 如果 B p r e d B_{pred}Bpred 也变得和 B g t B_{gt}Bgt一样“臃肿”,它(为了最小化L I n n e r S h a p e L_{InnerShape}LInnerShape)会被迫学习到 K n o r m p r e d K_{norm}^{pred}Knormpred也只分布在左下角。
- 这会鼓励 B p r e d B_{pred}Bpred 的 w , h w,hw,h收缩,以更紧密地包裹K a b s p r e d K_{abs}^{pred}Kabspred。
- L I n n e r S h a p e L_{InnerShape}LInnerShape 提供了 L B b o x L_{Bbox}LBbox无法提供的“收缩”梯度,奖励更“紧凑”(Tighter)的Bbox。
5.3 L I n n e r S h a p e L_{InnerShape}LInnerShape:一种“内容感知”的耦合惩罚
在第5节中,我们讨论了L E I o U L_{EIoU}LEIoU(解耦)和 L S h a p e I o U L_{ShapeIoU}LShapeIoU(耦合)的区别。
L S h a p e I o U = ∣ ∣ ( Δ w , Δ h ) ∣ ∣ 2 c L_{ShapeIoU} = \frac{||(\Delta w, \Delta h)||_2}{c}LShapeIoU=c∣∣(Δw,Δh)∣∣2是一种“盲目”的耦合。
L I n n e r S h a p e L_{InnerShape}LInnerShape 是一种“内容感知”的“耦合”。
L I n n e r S h a p e L_{InnerShape}LInnerShape 对 w ww 和 h hh的梯度,取决于所有N NN 个关键点的归一化坐标( Δ x i p r e d , Δ y i p r e d ) (\Delta x_i^{pred}, \Delta y_i^{pred})(Δxipred,Δyipred)。
w , h w, hw,h的优化被物体内部N NN 个点的几何分布(即“形状”)牢牢地“耦合”在了一起。
L I n n e r S h a p e L_{InnerShape}LInnerShape才是大家追求的、真正意义上的“形状”损失!
6. 局限性与“鸡生蛋”问题
6.1 依赖昂贵的“额外标注”(Keypoints)
这是 L I n n e r S h a p e L_{InnerShape}LInnerShape最大的软肋。
标准的COCO数据集只有Bbox和Mask。只有COCO-Pose子集才有人体17个关键点。
对于“汽车”、“甜甜圈”等物体,我们根本没有现成的关键点标注。
这意味着 L I n n e r S h a p e L_{InnerShape}LInnerShape无法“开箱即用”,它需耗费巨资去获取“内部结构”的额外标注。
6.2 “鸡生蛋”:Bbox不准⟹ \implies⟹Keypoints不准
L I n n e r S h a p e L_{InnerShape}LInnerShape的计算依赖于B p r e d = ( x c , y c , w , h ) B_{pred} = (x_c, y_c, w, h)Bpred=(xc,yc,w,h)。
L I n n e r S h a p e = ∑ ∣ ( x c + Δ x i p r e d ⋅ w ) − x i g t ∣ + . . . L_{InnerShape} = \sum | (x_c + \Delta x_i^{pred} \cdot w) - x_i^{gt} | + ...LInnerShape=∑∣(xc+Δxipred⋅w)−xigt∣+...
在训练早期:
B p r e d B_{pred}Bpred 的 x c , y c x_c, y_cxc,yc可能偏了十万八千里。
此时,L I n n e r S h a p e L_{InnerShape}LInnerShape 的值会极其巨大,它包含 L D i s L_{Dis}LDis(Bbox中心点) 和L S h a p e L_{Shape}LShape (Bbox w , h w,hw,h) 和 L K p t L_{Kpt}LKpt(kpt偏移) 三重误差。
该巨大的、不稳定的L I n n e r S h a p e L_{InnerShape}LInnerShape梯度,可能会干扰L B b o x L_{Bbox}LBbox (如 L C I o U L_{CIoU}LCIoU) 的稳定收敛。
6.3 解决方案:Focal-InnerShape (I o U γ ⋅ L I n n e r S h a p e IoU^\gamma \cdot L_{InnerShape}IoUγ⋅LInnerShape )
我们从第2节 (EIoU) 和第3节 (α \alphaα-IoU) 学到的“聚焦高IoU样本”的策略,在这里至关重要!
我们应该只在B p r e d B_{pred}Bpred已经“靠谱”(I o U IoUIoU较高)时,才激活L I n n e r S h a p e L_{InnerShape}LInnerShape。
L T o t a l = L B b o x + λ ⋅ ( I o U γ ) ⋅ L I n n e r S h a p e L_{Total} = L_{Bbox} + \lambda \cdot (IoU^\gamma) \cdot L_{InnerShape}LTotal=LBbox+λ⋅(IoUγ)⋅LInnerShape
(其中 γ > 0 \gamma > 0γ>0, I o U IoUIoU 是 B p r e d B_{pred}Bpred 和 B g t B_{gt}Bgt 的 I o U IoUIoU)
当 I o U → 0 IoU \to 0IoU→0(早期/离群值):I o U γ → 0 IoU^\gamma \to 0IoUγ→0。L T o t a l ≈ L B b o x L_{Total} \approx L_{Bbox}LTotal≈LBbox。
- 此时,模型只学习 L B b o x L_{Bbox}LBbox(如CIoU),专注于“定位”。
当 I o U → 1 IoU \to 1IoU→1(后期/可靠样本):I o U γ → 1 IoU^\gamma \to 1IoUγ→1。L T o t a l ≈ L B b o x + λ ⋅ L I n n e r S h a p e L_{Total} \approx L_{Bbox} + \lambda \cdot L_{InnerShape}LTotal≈LBbox+λ⋅LInnerShape。
- 此时,Bbox已经对齐,L B b o x L_{Bbox}LBbox 梯度减小。
- 模型开始激活L I n n e r S h a p e L_{InnerShape}LInnerShape,专注于“精调”w , h w, hw,h以匹配内部结构。
这才是 L I n n e r S h a p e L_{InnerShape}LInnerShape最鲁棒、最合理的打开方式!
7. Python代码实战 (概念):实现 InnerShapeLoss
L
I
n
n
e
r
S
h
a
p
e
L_{InnerShape}LInnerShape 不能集成到 bbox_iou_family 中,因为它需要完全不同的输入(Keypoints)。
我们必须定义一个全新的、模块化的损失类。
7.1 重新定义模型输出
preds(模型输出): 形状(B, N_Anchors, 4 + C + N_Kpts*2)targets(标签): 形状(N_gt, 6 + N_Kpts*2)(b a t c h i d x , c l s i d , c x , c y , w , h , k x 1 , k y 1 , k x 2 , k y 2 , . . . batch_idx, cls_id, cx, cy, w, h, kx1, ky1, kx2, ky2, ...batchidx,clsid,cx,cy,w,h,kx1,ky1,kx2,ky2,...) (绝对坐标)
7.2 InnerShapeLoss 模块化实现
import torch
import torch.nn as nn
# 假设我们已经有了 L_CIoU (来自第126篇)
# from .iou_losses import bbox_iou_family
# (这里为了独立运行, 我们假设 L_Bbox 也是L1)
# 实际中, L_Bbox 应该是 CIoU / EIoU
class InnerShapeLoss(nn.Module):
"""
一个概念性的 InnerShapeIoU 损失 (基于Keypoints)
L_Total = L_Bbox + lambda * L_InnerShape
输入 (preds, targets) 必须经过匹配 (e.g., TAL)
preds: (N_matched, 4 + N_Kpts*2)
(cx, cy, w, h, k_norm_x1, k_norm_y1, ...)
targets: (N_matched, 4 + N_Kpts*2)
(cx_gt, cy_gt, w_gt, h_gt, k_abs_x1_gt, k_abs_y1_gt, ...)
"""
def __init__(self, n_kpts=3, lambda_inner=0.5, use_focal_weight=True, gamma=0.5):
super().__init__()
self.n_kpts = n_kpts # 内部关键点数量
self.lambda_inner = lambda_inner # L_InnerShape 的权重
self.l1_loss = nn.L1Loss(reduction='none')
self.use_focal_weight = use_focal_weight # 是否使用 IoU^gamma 抑制
self.gamma = gamma
def forward(self, preds, targets, ious_pred_gt):
"""
preds: (N, 4 + K*2) (归一化kpt)
targets: (N, 4 + K*2) (绝对kpt)
ious_pred_gt: (N,) IoU(B_pred, B_gt)
"""
# --- 1. 提取 Bbox 和 Keypoints ---
# Bbox 预测 (cx, cy, w, h)
bbox_pred = preds[:, :4]
# Bbox 标签 (cx, cy, w, h)
bbox_gt = targets[:, :4]
# Keypoints 预测 (归一化, [-0.5, 0.5])
# (N, K*2) -> (N, K, 2)
kpts_norm_pred = preds[:, 4:].view(-1, self.n_kpts, 2)
# Keypoints 标签 (绝对坐标)
# (N, K*2) -> (N, K, 2)
kpts_abs_gt = targets[:, 4:].view(-1, self.n_kpts, 2)
# --- 2. 计算 L_Bbox (例如: L1 Loss, 实际应为 CIoU/EIoU) ---
# (为了简化, 我们用 L1。在YOLOv8中, 这里会调用 CIoU/EIoU)
L_bbox = self.l1_loss(bbox_pred, bbox_gt).sum(dim=1) # (N,)
# --- 3. ( 核心) 计算 L_InnerShape ---
# 3.1 提取 w, h (N, 1)
w_pred = bbox_pred[:, 2].unsqueeze(-1)
h_pred = bbox_pred[:, 3].unsqueeze(-1)
# 提取 cx, cy (N, 1)
cx_pred = bbox_pred[:, 0].unsqueeze(-1)
cy_pred = bbox_pred[:, 1].unsqueeze(-1)
# 3.2 计算 预测的绝对关键点 K_abs_pred
# k_abs_x = cx + k_norm_x * w
# k_abs_y = cy + k_norm_y * h
# kpts_norm_pred (N, K, 2)
k_norm_x_pred = kpts_norm_pred[..., 0] # (N, K)
k_norm_y_pred = kpts_norm_pred[..., 1] # (N, K)
# (N, 1) + (N, K) * (N, 1) -> (N, K) (广播机制)
k_abs_x_pred = cx_pred + k_norm_x_pred * w_pred
k_abs_y_pred = cy_pred + k_norm_y_pred * h_pred
# (N, K, 2)
k_abs_pred = torch.stack([k_abs_x_pred, k_abs_y_pred], dim=-1)
# 3.3 计算 L_InnerShape (L1 损失)
# (N, K, 2) vs (N, K, 2)
L_inner_kpts = self.l1_loss(k_abs_pred, k_abs_gt) # (N, K, 2)
# (N,)
L_inner_shape = L_inner_kpts.sum(dim=[1, 2]) # 对 K 和 2 (xy) 求和
# --- 4. ( 核心) 动态加权 ---
focal_weight = 1.0 # 默认权重
if self.use_focal_weight:
# (N,) -> (N,)
# .detach() 阻止 IoU 的梯度回传到 focal_weight
focal_weight = (ious_pred_gt.detach() ** self.gamma)
# --- 5. 计算总损失 ---
# (N,) + (N,) * (N,)
L_total = L_bbox + self.lambda_inner * focal_weight * L_inner_shape
# (返回平均损失)
return L_total.mean()7.3 代码解析
输入:
InnerShapeLoss的forward函数需要preds,targets和它们之间的ious。提取: 我们从
preds中分离出 B p r e d B_{pred}Bpred 和 K n o r m p r e d K_{norm}^{pred}Knormpred;从targets中分离出 B g t B_{gt}Bgt 和 K a b s g t K_{abs}^{gt}Kabsgt。L B b o x L_{Bbox}LBbox: 照常计算 B p r e d B_{pred}Bpred 和 B g t B_{gt}Bgt之间的Bbox损失(代码中用L1简化,实际应为CIoU)。
核心计算(2):
- k _ a b s _ x _ p r e d = c x _ p r e d + k _ n o r m _ x _ p r e d ∗ w _ p r e d k\_abs\_x\_pred = cx\_pred + k\_norm\_x\_pred * w\_predk_abs_x_pred=cx_pred+k_norm_x_pred∗w_pred
- k _ a b s _ y _ p r e d = c y _ p r e d + k _ n o r m _ y _ p r e d ∗ h _ p r e d k\_abs\_y\_pred = cy\_pred + k\_norm\_y\_pred * h\_predk_abs_y_pred=cy_pred+k_norm_y_pred∗h_pred
- 这是“魔法”发生的地方。w , h , c x , c y w, h, cx, cyw,h,cx,cy(Bbox的预测)被用来“重建”绝对关键点K a b s p r e d K_{abs}^{pred}Kabspred。
L I n n e r S h a p e L_{InnerShape}LInnerShape(3.3): 我们计算 K a b s p r e d K_{abs}^{pred}Kabspred 和 K a b s g t K_{abs}^{gt}Kabsgt之间的L1距离。
动态加权(4):如果启用,我们计算f o c a l _ w e i g h t = I o U γ focal\_weight = IoU^\gammafocal_weight=IoUγ。
总损失(5):L T o t a l = L B b o x + λ ⋅ ( f o c a l _ w e i g h t ) ⋅ L I n n e r S h a p e L_{Total} = L_{Bbox} + \lambda \cdot (focal\_weight) \cdot L_{InnerShape}LTotal=LBbox+λ⋅(focal_weight)⋅LInnerShape。
反向传播: 当
.backward()被调用时,L I n n e r S h a p e L_{InnerShape}LInnerShape 的梯度会同时流向 K n o r m p r e d K_{norm}^{pred}Knormpred(优化关键点预测) 和B p r e d B_{pred}Bpred(优化Bboxc x , c y , w , h cx,cy,w,hcx,cy,w,h以减少结构扭曲)。
8. 总结:Bbox回归的“内容感知”革命
本篇,我们进行了一次“越狱”!我们终于打破了Bbox回归只在“框”上做文章的“天花板”。
甜甜圈问题:我们揭示了Bbox回归的根本局限——拟合“框”(Container)而非“物”(Content)。L I o U = 0 L_{IoU}=0LIoU=0不等于“完美”预测。
L I n n e r S h a p e L_{InnerShape}LInnerShape 哲学:我们必须引入“额外监督”(如关键点)来感知物体“内部结构”,即L T o t a l = L B b o x + λ ⋅ L I n n e r S h a p e L_{Total} = L_{Bbox} + \lambda \cdot L_{InnerShape}LTotal=LBbox+λ⋅LInnerShape。
核心机制 (Keypoints):
- 模型不仅预测Bbox( x , y , w , h ) (x,y,w,h)(x,y,w,h),还预测归一化的关键点 K n o r m p r e d K_{norm}^{pred}Knormpred。
- L I n n e r S h a p e L_{InnerShape}LInnerShape(kpt损失) 是通过B p r e d B_{pred}Bpred (特别是 w , h w,hw,h) 重建的 K a b s p r e d K_{abs}^{pred}Kabspred 和 K a b s g t K_{abs}^{gt}Kabsgt之间的L2/L1损失。
“内容感知”的梯度:
- L I n n e r S h a p e L_{InnerShape}LInnerShape 为 w , h w, hw,h 提供了全新的、基于“内部结构一致性”的梯度。
- 它惩罚 w , h w, hw,h不再是“盲目”地(基于w ≠ w g t w \neq w_{gt}w=wgt“有理有据”地(缘于就是),而w ww 扭曲了 K n o r m p r e d K_{norm}^{pred}Knormpred)。
局限与未来:L I n n e r S h a p e L_{InnerShape}LInnerShape依赖昂贵的“关键点”标注,且在训练早期(I o U → 0 IoU \to 0IoU→0)时可能不稳定。L T o t a l = L B b o x + λ ⋅ ( I o U γ ) ⋅ L I n n e r S h a p e L_{Total} = L_{Bbox} + \lambda \cdot (IoU^\gamma) \cdot L_{InnerShape}LTotal=LBbox+λ⋅(IoUγ)⋅LInnerShape是其最终的、最鲁棒的形态。
I n n e r S h a p e I o U InnerShapeIoUInnerShapeIoU是一种“实例感知”的Bbox损失,它强迫模型去理解物体的内部几何结构,而不只是画一个“外壳”。
9. 下期预告:QFL质量Focal Loss与IoU感知
到目前为止,大家已经把Bbox回归损失L R e g L_{Reg}LReg (即 L B b o x + L I n n e r S h a p e L_{Bbox} + L_{InnerShape}LBbox+LInnerShape) 挖掘到了极致。
我们所有的Bbox损失 (CIoU, EIoU,α \alphaα-IoU, SIoU…) 都在做一件事:让 B p r e d B_{pred}Bpred 逼近 B g t B_{gt}Bgt。
与此同时,在另一个“平行宇宙”里,L C l s L_{Cls}LCls(分类损失,如Focal Loss) 也在独立工作,它只负责让 P c l s → 1 P_{cls} \to 1Pcls→1。
L T o t a l = L R e g + L C l s L_{Total} = L_{Reg} + L_{Cls}LTotal=LReg+LCls
这两个损失是独立的。
问题:
一个 I
o
U
=
0.9
IoU=0.9IoU=0.9的高质量Bbox,和一个I
o
U
=
0.2
IoU=0.2IoU=0.2的低质量Bbox,它们都可能预测出P
c
l
s
=
0.99
P_{cls}=0.99Pcls=0.99(高置信度)。
在NMS(非极大值抑制)时,我们通常启用P c l s P_{cls}Pcls来排序。那个I o U = 0.2 , P c l s = 0.99 IoU=0.2, P_{cls}=0.99IoU=0.2,Pcls=0.99的“垃圾框”反而可能“胜出”,抑制掉I o U = 0.9 , P c l s = 0.98 IoU=0.9, P_{cls}=0.98IoU=0.9,Pcls=0.98的“完美框”。
为什么 L C l s L_{Cls}LCls不能“感知”到L R e g L_{Reg}LReg 的质量呢?
在 【第7节:QFL质量Focal Loss与IoU感知】中,我们将“打通”这两个平行宇宙:
- “定位质量”与“分类置信度”的“不一致”(Misalignment)问题?就是什么
- QFL (Quality Focal Loss)如何重新定义“分类标签”,将I o U IoUIoU作为“软标签”引入L C l s L_{Cls}LCls?
- GFL (Generalized Focal Loss) 和 DFL (Distribution Focal Loss)(YOLOv8在用!) 又是如何让模型直接预测 I o U IoUIoU分数或Bbox坐标分布的?
- 我们将揭晓YOLOv8 Bbox回归的终极秘密之一:DFL。
敬请期待!损失函数的进化,即将迎来“分类”与“回归”的“大一统”!
感谢您的坚持!L I n n e r S h a p e L_{InnerShape}LInnerShape是一个非常前沿且艰难的概念,它已经触及了YOLOv8-Pose (姿态估计) 的核心。能理解它,说明您已经具备了“多任务学习”的视角!太棒了!
我们下期再见!
希望本文围绕 YOLOv8 的实战讲解,能在以下几个方面对你有所帮助:
- 模型精度提升:借助结构改进、损失函数优化、数据增强策略等,实战提升检测效果;
- 推理速度优化:结合量化、裁剪、蒸馏、部署策略等手段,支援你在实际业务中跑得更快;
- 工程级落地实践:从训练到部署的完整链路中,给出可直接复用或稍作改动即可迁移的方案。
PS:如果你按文中步骤对 YOLOv8 进行优化后,仍然遇到难题,请不必焦虑或抱怨。
YOLOv8 作为复杂的目标检测框架,效果会受到硬件环境、信息集质量、任务定义、训练配置、部署平台等多重因素影响。
要是你在实践过程中遇到:
- 新的报错 / Bug
- 精度难以提升
- 推理速度不达预期
欢迎把 报错信息 + 关键配备截图 / 代码片段粘贴到评论区,大家可以一起分析原因、讨论可行的优化方向。
同时,如果你有更优的调参经验或结构改进思路,也非常欢迎分享出来,大家互相启发,共同完善 YOLOv8 的实战打法
文末福利,等你来拿!
文中涉及的多数技巧问题,来源于我在 YOLOv8 项目中的一线实践,部分案例也来自网络与读者反馈;如有版权相关难题,欢迎第一时间联系,我会尽快处理(修改或下线)。
部分思路与排查路径参考了全网技术社区与人工智能问答平台,在此也一并致谢。如果这些内容尚未完全消除你的困难,还请多一点理解——YOLOv8 的优化本身就是一个高度依赖场景与数据的工程疑问,不存在“一招通杀”的方案。
如果你已经在自己的任务中摸索出更高效、更稳定的优化路径,非常鼓励你:
- 在评论区简要分享你的关键思路;
- 或者整理成教程 / 系列文章。
你的经验,可能正好就是其他开发者卡关许久所缺的那一环
OK,本期关于YOLOv8 优化与实战应用的内容就先聊到这里。如果你还想进一步深入:
- 了解更多结构改进与训练技巧;
- 对比不同场景下的部署与加速策略;
- 系统构建一套属于自己的 YOLOv8 调优方法论;
欢迎继续查看专栏:《YOLOv8实战:从入门到深度优化》。
也期待这些内容,能在你的项目中真正落地见效,帮你少踩坑、多提效,下期再见
码字不易,倘若这篇文章对你有所启发或帮助,欢迎给我来个一键三连(关注 + 点赞 + 收藏),这是我持续输出高质量内容的核心动力
同时也推荐关注我的公众号「猿圈奇妙屋」:
- 第一时间获取 YOLOv8 / 目标检测 / 多任务学习 等方向的进阶内容;
- 不定期分享与视觉算法、深度学习相关的最新优化方案与工程实战经验;
- 以及 BAT 等大厂面试题、技术书籍 PDF、工程模板与工具清单等实用资源。
期待在更多维度上和你一起进步,共同提升算法与工程能力
Who am I?
我是专注于 计算机视觉 / 图像识别 / 深度学习工程落地的讲师 & 技术博主,笔名bug菌:
- 活跃于 CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云等技术社区;
- CSDN 博客之星 Top30、华为云多年度十佳博主、掘金多年度人气作者 Top40;
- 掘金、InfoQ、51CTO 等平台签约及优质创作者,51CTO 年度博主 Top12;
- 全网粉丝累计30w+。
通过更多系统化的学习路径与实战资料能够从这里进入 点击获取更多精彩内容
硬核技术公众号「猿圈奇妙屋」欢迎你的加入,BAT 面经、4000G+ PDF 电子书、简历模版等通通可白嫖,你要做的只是——愿意来拿

-End-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号