
论文阅读笔记-Incorporating Copying Mechanism in Sequence-to-Sequence Learning - 教程
前言
最近看了一篇ACL2021的Dialog Policy Learning模型的文章,阅读笔记如下:
阅读笔记
模型结构里面使用到了一个Copying Mechanism的技巧,因此比较感兴趣的翻了这篇原文阅读。本篇论文提出了CopyNet模型,能够自动的,决定下一步的预测是生成模式还是复制模式。生成模式就是我们常说的注意力机制,复制模式就是这篇文章的一个创新点。复制模式其实不难理解,从我们人类的经验视角来看,在阅读文章或者做一些摘要的时候,除了自己会生成一些概括语句之外,还会从文章当中去摘抄一些核心句子。因此我们在生成句子时,可以选择性的复制某些关键词,比如如下这样:
如上述的一些人名等OOV_token,如果单单使用传统的Attention是无法处理的,所以应该依据某种手段来解决。Copying Mechanism从一定程度上克服这个问题,用原Paper的说法,模型只得更少的理解,就能够确保文字的保真度,对于摘要,对话系统等来说,能够提高文字的流畅度和准确率,并且也是端到端进行训练。
模型细节
在Decoder中,融入了Copying Mechanism,首先看一下模型的整体结构,如下图:就是模型依旧是Encoder-Decoder的结构,不过
模型的Encoder部分就是使用了Bi-RNN,编码得到的hidden state 统一用M MM表示(上图右侧的M MM),下面我们重点来讲一下Decoder。
Decoder
Decoder也是使用RNN来获取M MM的信息从而预测目标序列,只不过并不是直接解码,而是做了如下三个改动:
生成模式&复制模式
设有一个词表V = { v 1 , v 2 , . . . , v n } V=\{v_1,v_2,...,v_n\}V={v1,v2,...,vn},使用UNK表示OOV,输入表示为X = { x 1 , x 2 , . . . , x T s } X=\{x_1,x_2,...,x_{T_s}\}X={x1,x2,...,xTs}。因为 X XX当中涵盖一些词汇表中没有的单词,所以采用copy mode,可以输出部分OOV单词,这样就使得我们整个词表为V ∪ U N K ∪ X V\cup UNK\cup XV∪UNK∪X。在第 t tt步解码的state 表示为s t s_tst,y t y_tyt表示生成目标词概率,则两个模式的混合概率模型表示为:
p ( y t ∣ s t , y t − 1 , c t , M ) = p ( y t , g ∣ s t , y t − 1 , c t , M ) + p ( y t , c ∣ s t , y t − 1 , c t , M ) p(y_t|s_t,y_{t-1},c_t,M)=p(y_t,g|s_t,y_{t-1},c_t,M)+p(y_t,c|s_t,y_{t-1},c_t,M)p(yt∣st,yt−1,ct,M)=p(yt,g∣st,yt−1,ct,M)+p(yt,c∣st,yt−1,ct,M)
其中,g gg表示生成模式,c cc表示复制模式,则两个模式的概率模型分别为:
p ( y t , g ∣ ⋅ ) = { 1 Z e ψ g ( y t ) , y t ∈ V 0 , y t ∈ X ∩ V ˉ 1 Z e ψ g ( U N K ) , y t ∉ V ∪ X p(y_t,g|\cdot)=\left\{\begin{matrix}\frac{1}{Z}e^{\psi_g(y_t)}, & y_t\in V \\ 0, & y_t\in X\cap\bar{V} \\ \frac{1}{Z}e^{\psi_g(UNK)}, &y_t\notin V\cup X \end{matrix}\right.p(yt,g∣⋅)=⎩⎨⎧Z1eψg(yt),0,Z1eψg(UNK),yt∈Vyt∈X∩Vˉyt∈/V∪X
p ( y t , c ∣ ⋅ ) = { 1 Z ∑ j : x j = y t e ψ c ( x j ) , y t ∈ X 0 , o t h e r w i s e p(y_t,c|\cdot)=\left\{\begin{matrix} \frac{1}{Z}\sum_{j:x_j=y_t}e^{\psi_c(x_j)}, & y_t\in X \\ 0,& otherwise\end{matrix}\right.p(yt,c∣⋅)={Z1∑j:xj=yteψc(xj),0,yt∈Xotherwise
其中,ψ g ( ⋅ ) , ψ c ( ⋅ ) \psi_g(\cdot),\psi_c(\cdot)ψg(⋅),ψc(⋅)分别是generate mode和copy mode的分数计算方法,Z = ∑ v ∈ V ∪ { U N K } e ψ g ( x ) + ∑ x ∈ X e ψ c ( x ) Z=\sum_{v\in V\cup\{UNK\}}e^{\psi_g(x)}+\sum_{x\in X}e^{\psi_c(x)}Z=∑v∈V∪{UNK}eψg(x)+∑x∈Xeψc(x)则是两种模式间共享的归一化项,两种模式分数的计算方法:
- generate mode
ψ g ( y t = v i ) = v i T W o s t , v i ∈ V ∪ U N K \psi_g(y_t=v_i)=v_i^TW_os_t,v_i\in V\cup UNKψg(yt=vi)=viTWost,vi∈V∪UNK
其中,W o ∈ R ( N + 1 ) × d s W_o\in\mathbb{R}^{(N+1)\times d_s}Wo∈R(N+1)×ds,v i v_ivi是one-hot形式 - copy mode
ψ c ( y t = x j ) = σ ( h j T W c ) s t , x j ∈ X \psi_c(y_t=x_j)=\sigma (h_j^TW_c)s_t,x_j\in Xψc(yt=xj)=σ(hjTWc)st,xj∈X
其中,W c ∈ R d h × d s W_c\in\mathbb{R}^{d_h\times d_s}Wc∈Rdh×ds,σ \sigmaσ是一个非线性激活函数(tanh非线性激活函数比linear transformation的效果更好)
因此,总共需要考虑4个情况,目标词y t y_tyt倘若属于词汇表或者X XX,就分别计算上述两个概率;如果既不属于词汇表,也不属于源端,就是U N K UNKUNK;如果属于 X XX,但不属于词汇表,那么生成的概率为0;假设不属于X XX两种模式共享的归一化项,下图可见:就是,那么复制的概率为0。Z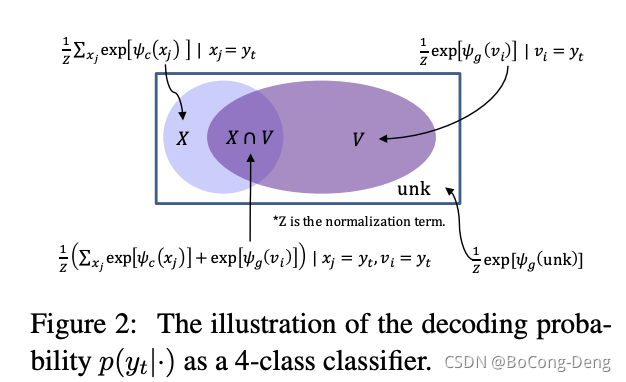
优化目标应该是在训练当中y t y_tyt作为目标词,整个模型的目标是要让y t y_tyt的混合概率最大,即-log似然概率最小:
L = − 1 N ∑ k = 1 N ∑ t = 1 T l o g [ p ( y t ( k ) ∣ y < t ( k ) , X ( k ) ) ] L=-\frac{1}{N}\sum_{k=1}^N\sum_{t=1}^Tlog[p(y_t^{(k)}|y_{<t}^{(k)},X^{(k)})]L=−N1k=1∑Nt=1∑Tlog[p(yt(k)∣y<t(k),X(k))]
没有出现在源端,则复制模式概率为零。这个词如果出现在了源端,然而不在目标词里,生成模式概率为0)。就是然后在预测的时候,由于没有目标词。按照作者给的模型框架图,应该是在最后一层前馈神经网,维度为词汇表的数量加源端句子的长度。然后把每一个词对应的概率加起来选择最大概率的词作为prediction(这个词若
State Update
注意力机制中,状态的更新为下公式:
s t = f ( y t − 1 , s t − 1 , c ) s_t=f(y_{t-1},s_{t-1},c)st=f(yt−1,st−1,c)
但是在CopyNet,y t − 1 y_{t-1}yt−1有一点小的变化,其被表达成以下形式:
[ e ( y t − 1 ) ; ζ ( y t − 1 ) ] T [e(y_{t-1});\zeta(y_{t-1})]^T[e(yt−1);ζ(yt−1)]T
前者是一个embedding,后者是一个加权和的计算,对于X XX中的词,如果其等于y t − 1 y_{t-1}yt−1,则以如下公式进行计算:
ζ ( y t − 1 ) = ∑ τ = 1 T S ρ t τ h τ \zeta(y_{t-1})=\sum_{\tau=1}^{T_S}\rho_{t\tau h_\tau}ζ(yt−1)=τ=1∑TSρtτhτ
ρ t τ = { 1 K p ( x τ , c ∣ s t − 1 , M ) , x τ = y t − 1 0 o t h e r w i s e \rho_{t\tau}=\left\{\begin{matrix} \frac{1}{K}p(x_\tau,c|s_{t-1},M), & x_\tau=y_{t-1} \\ 0 & otherwise \end{matrix}\right.ρtτ={K1p(xτ,c∣st−1,M),0xτ=yt−1otherwise
否则其概率为0。也就是说,大家挑选出等于y t − 1 y_{t-1}yt−1的词的隐层状态和词向量连接。其中K = ∑ τ ′ : x τ ′ = y t − 1 p ( x τ ′ , c ∣ s t − 1 , M ) K=\sum_{\tau^{'}:x_{\tau^{'}}=y_{t-1}}p(x_{\tau^{'}},c|s_{t-1},M)K=∑τ′:xτ′=yt−1p(xτ′,c∣st−1,M),是归一化项。论文中把这里的操作称之为selective read,与attentive read相似。attentive read是用decoder的隐状态和encoder隐状态做attention,是soft操控,而selective read是用t − 1 t-1t−1时刻的输出与encoder的输入做selection,不相等则为0,是hard操作。
实验结果
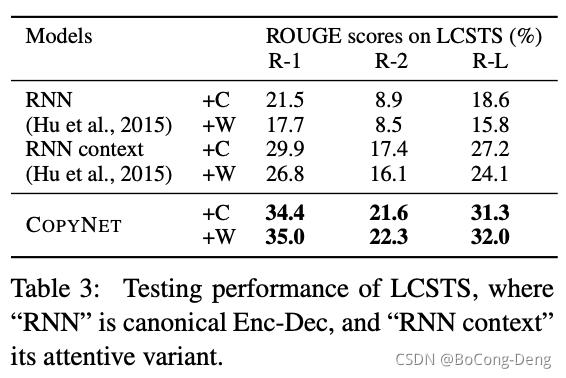
第一个实验是自动文摘,因为文摘任务当中,可以发现摘要中的大部分,都是可以从原文当中直接复制过来的。在源端可能会出现很多的out of vocabulary,所以基于注意力的encoder decoder模型,生成的摘要效果很差。
第二个实验用在单轮对话系统,在单轮对话任务当中,虽然基于注意力的encoder decoder模型,能够去生成完整的有语义的句子,可是往往答非所问。
总结
加入copy机制,不仅仅考虑生成模式,还考虑复制模式,对文摘或者单轮对话任务起到比较好的效果。CopyNet可以在一定程度上消除部分未登录词,不过并不能解决所有的未登录词问题,而且我觉得对于文本摘要此种需要从文章中提取关键词的任务好像更适合用CopyNet,因为文本摘要中的提取出来的命名实体识别的词更多一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号