
聊聊性能压测介入时机-性能工程系列一(前置介入) - 指南
1 引子
性能压测,往往都是系统测试完成后,即集成测试完成后,才开始介入,如功能测试完成后,集群测试完毕后,才根据项目的性能诉求进行压测,验证结果是否满足性能预期指标,这种后置的验证工作,会有哪些弊端?
- 发现性能问题,工程代码优化改造成本较高,甚至无法优化,比如:架构设计缺陷,链路设置缺陷,代码性能缺陷,动辙牵全身,影响面较广,且功能测试回归的成本也较高,甚至会带来其它风险,如优化后,功能有BUG,导至回归未发现,击穿线上,引发故障等问题;
- 链路中出现性能热点,排查,定位问题成本直线上升,特别是现在微服务架构设计,一条链路下来涉及到十几个服务的上下游,排查路径变长,调优及优化的频率较多,基本上优化成本也会直线上升;
2 时机
2.1 前置事项
基于上述的带来的问题,性能工程中的–性能验证,在什么阶段介入较为适宜,需要结合公司的实际情况,规范和实施性能验证的介入,比较流行的做法提倡验证左移,即早在10年前提出的测试左移思想, 那时互联网中只有少数几家引入此概念,随着互联网电商 的兴起,左移思想也是最近的7年前慢慢兴起,但不管是左移还是右移,也都是测试的一种策略,倘若完全按照概念生搬硬套,如没有能落地的场景,且无相关的资源配套,则左移也好,右移也好,其实效果都不是很明显,举个实际的案例:一个积分项目的平台,在进行开发之前,需要有技术细分环节,其中涉及到架构设计如下: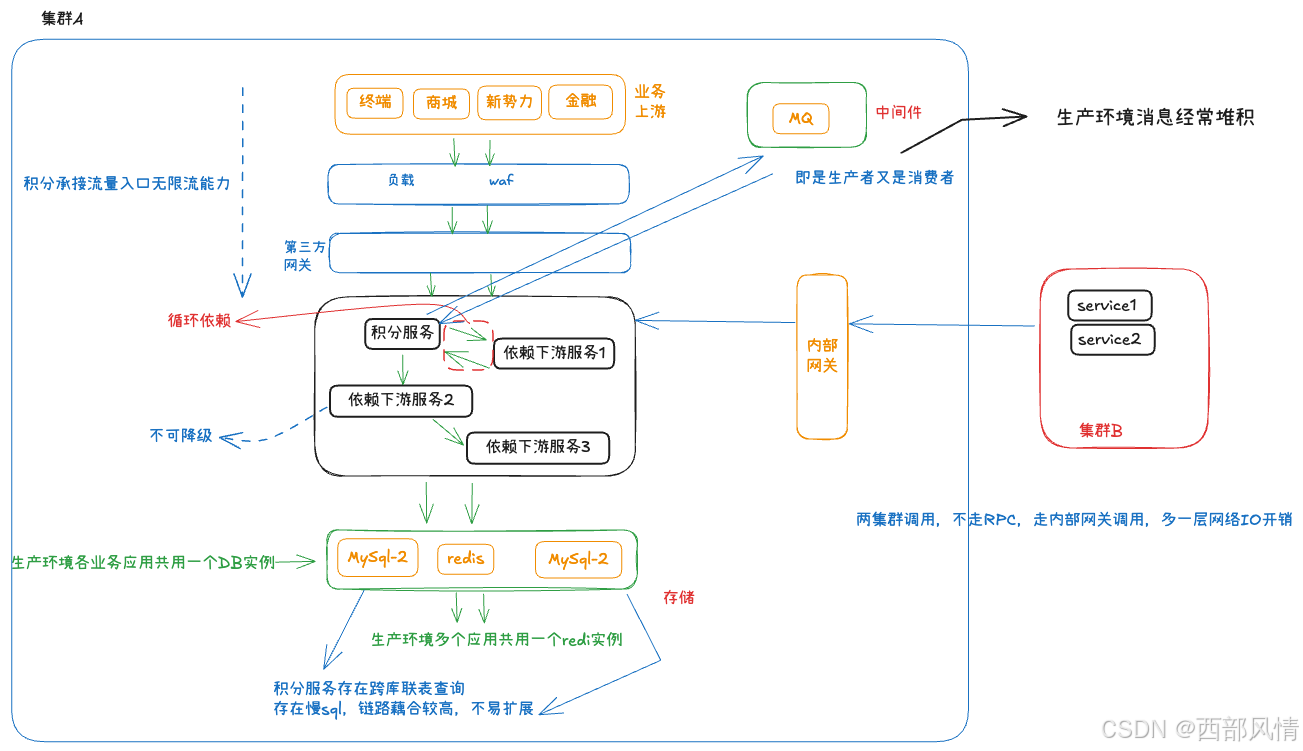
上图中的架构设计,哪怕没有明确指出具体的业务领域划分,也不知道服务与服务之间的链路设计关系,仅仅从架构设计评估,工作多年的老司机也可看出困难1,2;
- 否满足后续业务发展的诉求,系分文档中设计其实并明确体现出来,架构设计当时也并没有考虑相关业务扩展性及业务需求带来的影响,即左移的思想中,如何体现出架构设置的合理性,识别架构设计的缺陷需要有一定经验的人士进行识别及评估,此时光有左移思想,则未必将上述几点设计问题识别出来,并在设计阶段提前规避;就是基于上述积分系统的架构设计
- 基于上述的架构设计中,领域模型的边界划分,链路的设计的中鲁棒性,稳定性,限流,监控,熔断,高可用设计思想并没有放入其中,缺失与性能工程相关的设计理念;即前置介入测试的的思想中,如缺失这些设计理念,则唯一有约束的就是链路调中的接口性能在上下游调用中,接口响应的RT 得满足什么的阀值,才符合性能要求,此一点又突显单薄,且不同的业务不同的环境其阀值又不能一概而论,基于此点在不同的团队,又很达到统一的共识;
基于上述的情景,性能工程中的前置工作-即提前介入,需要有一定的规则,约束,及团队文化,签于此,还需要一套能快速支撑落的平台,这个平台不局限于架构的风险知识库类型,架构风险AI识别,针对链路设计的约束,单表查询RT约束,接口响应RT约束如能通过规则及约束结合devlop平台快速支撑(流程流转)并触发校验,或借助调用触发阀值后告警,对服务的接口RT,链路的RT进行前置约束,则在后续的集成中,因性能问题而进行的优化或改造成本将会降底数倍,
提前介入,在性能工程中需要做的事项:
性能建模:基于架构设计,对架设设计的方案结合业务发展及业务容量规划评估出对应的性能相关模型材料 ,这其中包括了科技特性,硬件资源,评估出容量的上限,识别潜在的性能热点,这个过程是需要相关的素材作为参考的:由业务性能指标,映射为技术技标,在由技术指标,推导出要求硬件资源,其实这个过程对架构师的要求及期经验都十分高,这个过程也避免了在架构设计时带来的性能肓区。我们用最常见订单链路进行分析举例:
业务诉求是新活动上市或在活动的前某一段时间,要求下单链路能够支撑30WQPS/秒,在此处理能力下下单链路的响应时间小于300ms,资源使用率(容器,DB,)资源使用率小于70%(这个指标暂认为伪命题,重点优先关注 RT,及处理能力),根据这个业务需求指标,大家映射成技术指标:下单链路的单个服务接口小于200ms,mysql数据库单库QPS小于等于1000(16c32g),缓存 redis 4c8g,简单命令的qps小于10000 ,对应的资源配置推导应用服务线程池核心数≥50,至少300,MySQL 连接池≥100至少300,Redis 缓存大于等于95%,利用建模可提前发现,应用对应的“线程池设置 最大连接线程数 20”“MySQL最大DB 连接池连接数 50” 等相关配置无法满足需求(默认设置值),避免等到压测才暴露问题。
注:
- 16c32g 普通的云数据库调配,官方实侧显示 -> mysql 处理简单的写事务,QPS上限为1000-2000,为了避免mysql过载(锁,慢查),一般会保留20%或30%的冗余
- 内存4c8g,单节点处理 “GET/SET” 等简便命令的 QPS 可达 10000-15000,但为避免网络带宽占满(Redis QPS 过高会占用大量网络资源),留 30% 冗余,因此定 “单节点 QPS≤10000”—— 确保 Redis 不成为链路瓶颈
- 应用服务线程池核心数≥50:用 “TPS = 线程数 × 单线程处理能力” 计算
- :线程数 ≥ 目标 TPS ÷ 单线程 TPS(即单线程每秒能处理的请求数)就是线程池核心数决定了应用服务 “同时能处理的请求数”,核心公式
单线程 TPS:单线程处理 1 个请求需 “主链路耗时 200ms”,则 1 秒能处理 1000ms÷200ms = 5个请求(即单线程 TPS=5);
目标 TPS=300000,則需线程数≥300000÷5=60000 —— >上述案例中为什么定应用服务器核心线程数 “≥200”?是因为案例中 “350” 是 “单节点线程池核心数”,而非总线程数!假设应用服务部署 200 节点,则总线程数 = 200 节点 ×350核心数 = 70000,70000×5≈350000 TPS,远超 300000目标 —— 留足冗余是为了应对 “请求耗时波动”(如偶尔耗时 250或300ms)。
而原来的 “线程池核心数 200”:若单节点 200 线程,200 节点总线程数 = 40000,40000×5≈200000 TPS<300000—— 这就是建模能提前发现 “200 不够” 的原因。
- :线程数 ≥ 目标 TPS ÷ 单线程 TPS(即单线程每秒能处理的请求数)就是线程池核心数决定了应用服务 “同时能处理的请求数”,核心公式
- MySQL 连接池≥100:“线程数 = 连接数” 的对应关系
- 应用服务处理订单请求时,“每个线程需 1 个 MySQL 连接”(同步调用场景),因此:
- MySQL 连接池最大数 ≥ 应用服务总线程数 ×(1 + 冗余比例)
- 应用服务总线程数 = 200 节点 ×200=40000?—— 不对,案例中 “100” 是 “单节点连接池最大数”!实际生产中,每个应用节点的连接池不会超过 “单节点线程数”(避免浪费连接),单节点线程数 50,留 100% 冗余(应对线程池扩容、临时请求激增),则单节点连接池≥50×2=100;
“50 不够” 的核心原因。就是原来的 “MySQL 连接池 50”:单节点 50 连接,若线程数增至 60(临时扩容),会出现 “线程等连接” 的情况 —— 这就
- Redis 缓存命中率≥95%:避免 MySQL 被 “穿透” 压垮
- MySQL QPS 上限:就是缓存命中率 =(Redis 命中请求数 ÷ 总请求数)×100%,命中率低会导致 “缓存穿透”(请求直接打向 MySQL),增加 MySQL 压力。“95%” 的依据
订单创建链路中,300000 TPS 里有 80% 需要查 Redis(如库存查询),即 Redis 总请求数 = 300000×80%=240000 QPS;
若缓存命中率 = 95%,则穿透到 MySQL 的请求数 = 240000×(1-95%)=12000 QPS;加上订单创建本身的 MySQL 写请求(约 800 QPS),MySQL 总 QPS=60+700=760<800(MySQL 上限)—— 符合要求;
若命中率降至 90%:穿透请求数 = 1200×10%=120,MySQL 总 QPS=120+700=820>800—— 会触发 MySQL 过载;
因此必须保证 “Redis 缓存命中率≥95%”,这是建模提前预判 “缓存穿透风险” 的关键。
- MySQL QPS 上限:就是缓存命中率 =(Redis 命中请求数 ÷ 总请求数)×100%,命中率低会导致 “缓存穿透”(请求直接打向 MySQL),增加 MySQL 压力。“95%” 的依据
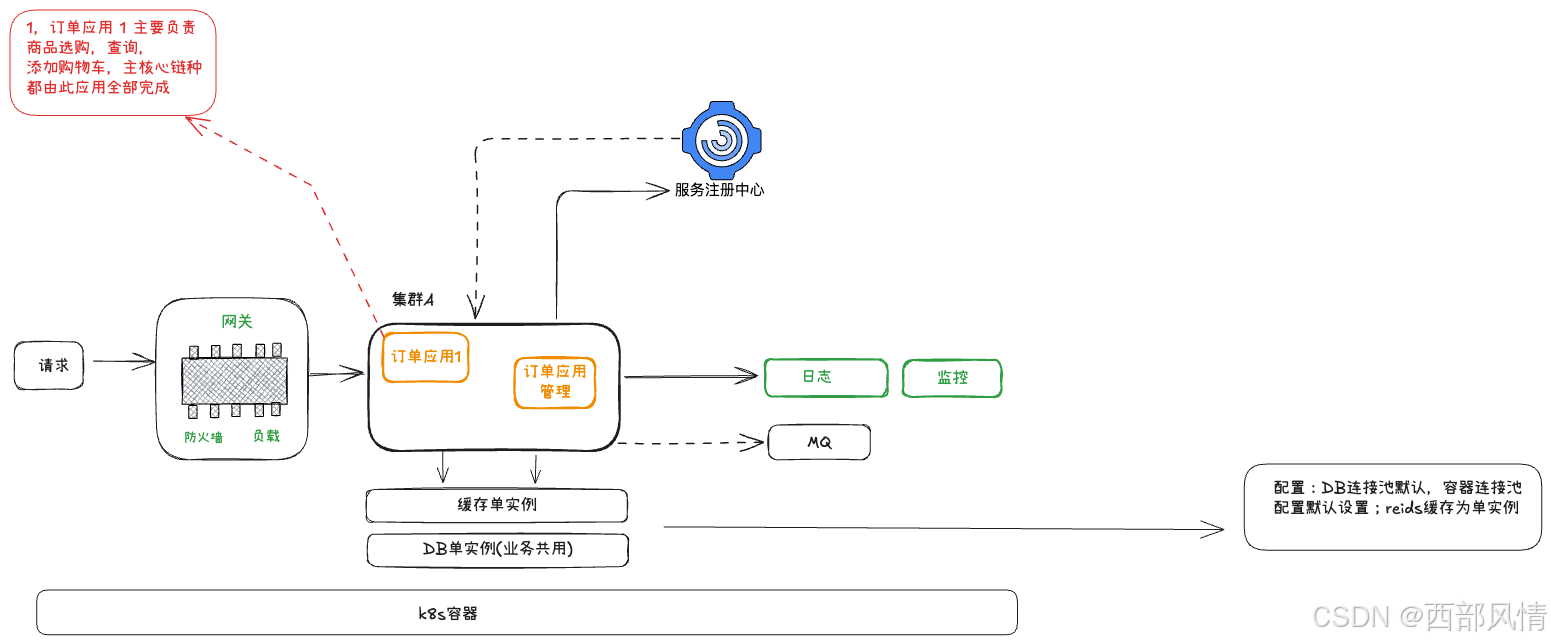
- 订单链路的架构设计第一版,未根据业务发展设计的第一版:
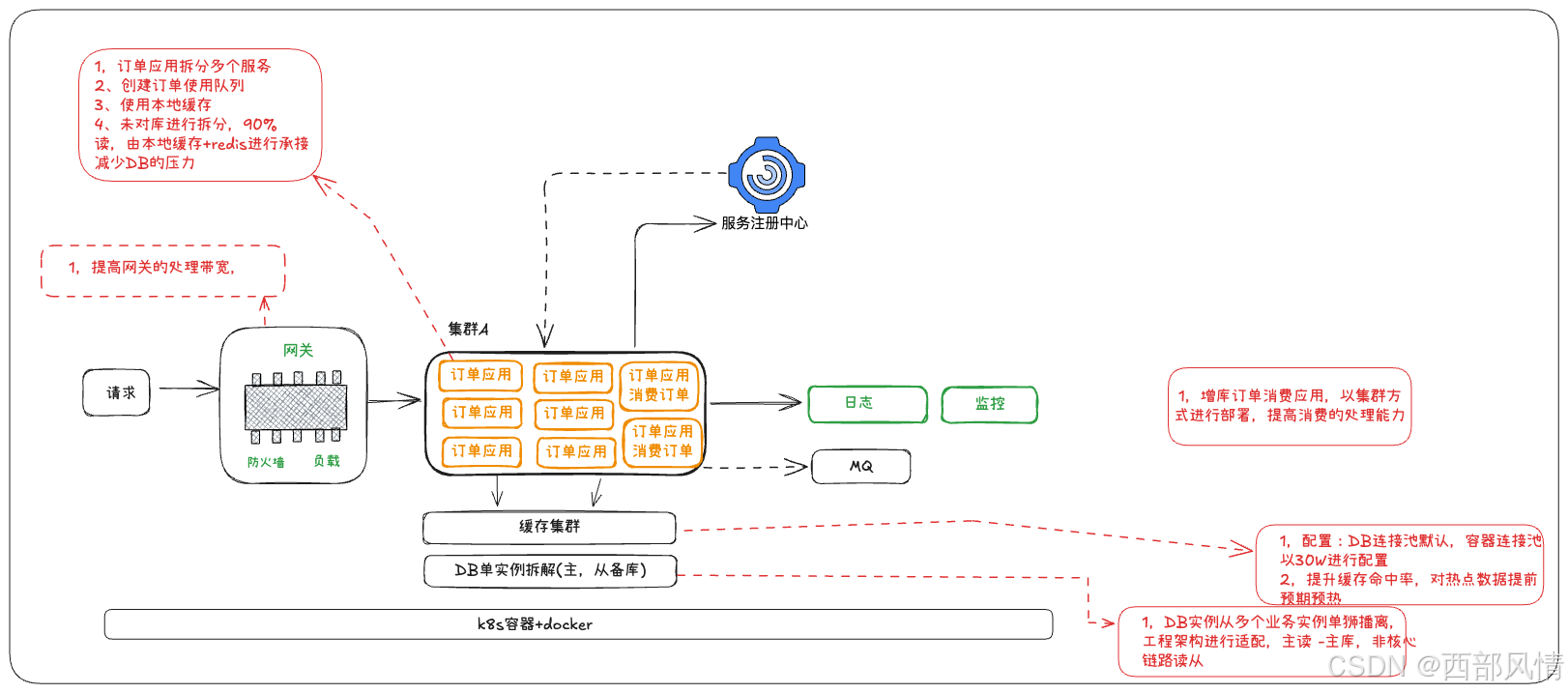
- 基于业务发展目标及发性能要求,根据上述推导过程,订单链路架构设计的优化版:
2.2 前置事项
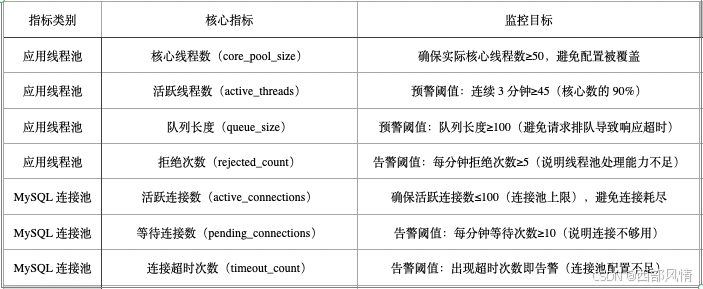
架构可监控
资源配置的有效性监控- 实时验证 “应用线程池核心数≥50、MySQL 连接池≥100” 的设置是否生效,避免 “设置与实际运行不符”(如线程池核心数被代码覆盖为 20);
- 线程池监控: 核心线程数大于50 ,进行告警
- 线程池监控: 活跃线程数大于80%,进行告警
- 线程池监控: 最大连接数大于80%,进行告警
性能目标监控
实时跟踪 “TPS≥300000、响应时间≤300ms”,当指标偏离目标时(如 TPS 降至 200000、响应时间升至 500ms),能快速告警;
- 用务TPS监控,大于300000,小于300000 告警
- 服务RT监控,95RT,90RT,100100RT 大于300 告警,小于250M鞠
- 链路流量监控:异常流量为0监控

- 实时验证 “应用线程池核心数≥50、MySQL 连接池≥100” 的设置是否生效,避免 “设置与实际运行不符”(如线程池核心数被代码覆盖为 20);
组件可监控
- 快速定位
- 当出现 “TPS 上不去、响应超时 时,10 分钟内定位到具体环节(如线程池队列堆积、MySQL 连接耗尽、Redis 耗时增加)
- 告警策略设置

3 前置总结
基于性能工程,仅局限于性能压测作为后置的业务评估,即缺失了性能工程的前期风险规避,又提高的后期性能工程的改造成本,故整体项目在架构设计阶段,需要将提前对性能做出预判,对性能工程中涉及到性能风险,设计风险,配置风险,监控观测可行性进行提前规则,避免后期介入成本,及改造成本 !

 浙公网安备 33010602011771号
浙公网安备 33010602011771号