
Qwen2-VL 阅读笔记 - 教程
一、 核心摘要与贡献
1. 核心问题意识:
- 问题1:分辨率僵化。现有LVLM通常将图像缩放到固定分辨率(如224x224),导致高分辨率图像细节丢失,无法像人眼一样感知多尺度信息。
- 疑问2:位置编码局限。传统1D位置编码难以有效建模图像(2D)和视频(2D+时间)的复杂空间与时序关系。
- 问题3:视频理解薄弱。许多模型将视频视为独立模态,缺乏与图像统一的处理范式,且对长视频的理解能力有限。
- 问题4:缩放规律不明。相较于纯文本LLM,LVLM在模型参数和数据规模上的缩放规律探索尚不充分。
2. 首要贡献:
- 提出了 Qwen2-VL系列模型(2B, 7B, 72B),在多项多模态基准测试中达到或超越了GPT-4o、Claude 3.5 Sonnet等顶尖模型的表现。
- 引入了 朴素动态分辨率机制,使模型能自适应处理任意分辨率和宽高比的图像。
- 提出了 多模态旋转位置编码(M-RoPE),有效统一并建模文本、图像和视频的位置信息。
- 采用了 统一的图像-视频处理范式,使用同一套架构处理两种模态,并承受长达20分钟以上的视频理解。
- 进行了全面的能力评估与缩放规律分析,验证了模型在通用VQA、文档理解、数学推理、多语言OCR、视频理解及智能体任务上的卓越性能。
- 开源了模型权重,促进社区发展。

二、 方法论深度解析
2.1 模型架构
- 整体框架:沿用成熟的
视觉编码器 (ViT) -> 视觉适配器 -> 大语言模型 (LLM)范式。 - 视觉编码器:在所有规模的模型中都使用一个675M参数的ViT,确保视觉计算成本恒定。
- 语言模型:基于强大的Qwen2系列LLM进行初始化。
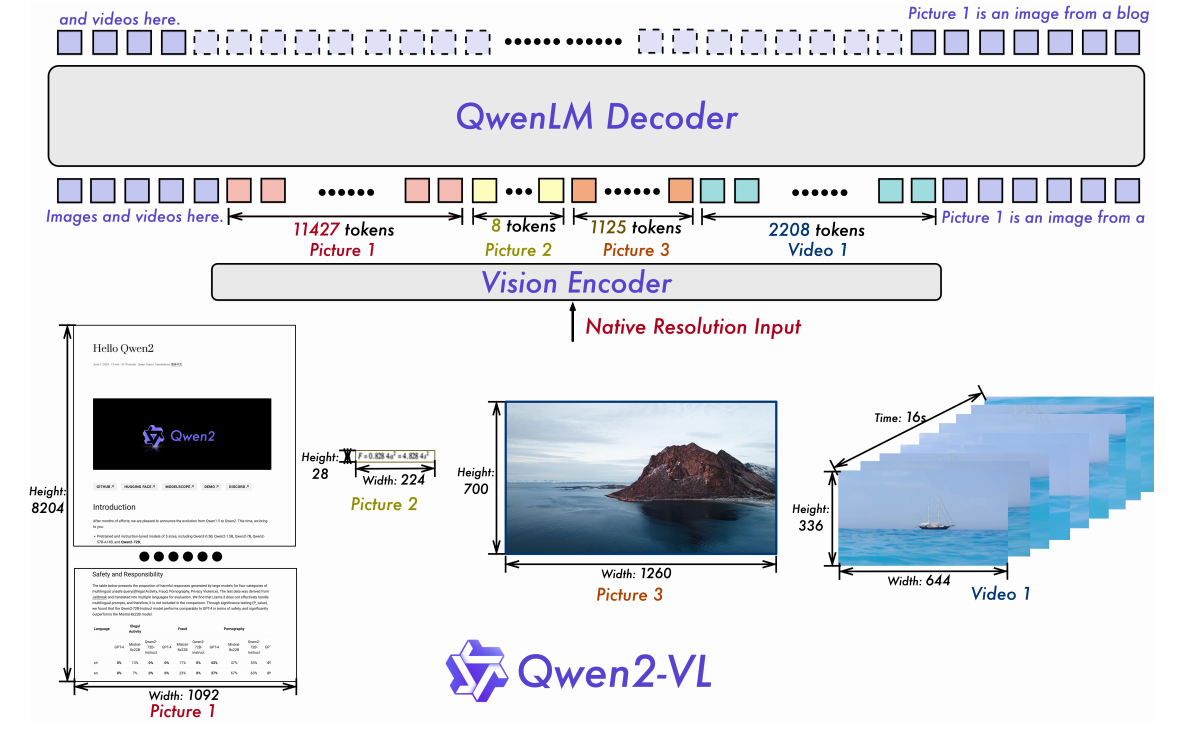
2.2 关键技术升级
1. 朴素动态分辨率
- 机制:移除ViT中的绝对位置嵌入,引入2D-RoPE来捕获图像的二维空间结构。图像按其原始分辨率处理,动态产生不同数量的视觉token。
- Token压缩:在ViT后使用一个简单的MLP,将相邻的
2x2视觉token压缩为1个token,以减少输入LLM的序列长度。例如,一个224x224的图像(patch=14)最终被压缩为仅66个token。 - 推理优化:凭借控制打包后的总序列长度来管理GPU内存应用。
2. 多模态旋转位置编码(M-RoPE)
- 核心思想:将传统的1D RoPE分解为三个独立的分量:时间、高度、宽度。
- 工作方式:
- 文本:时间、高、宽使用相同的位置ID,退化为1D-RoPE。
- 图像:每个视觉token的时间ID固定,高、宽ID由其空间位置决定。
- 视频:时间ID随帧数递增,每一帧内的高、宽ID与图像处理方式相同。
- 优势:
- 显式地建模了多模态数据的本质结构。
- 降低了图像/视频的位置ID数值,增强了模型在推理时对更长序列的外推能力。

3. 统一的图像与视频理解
- 统一处理:采用混合训练,同时使用图像和视频数据。
- 视频采样:以每秒2帧的速率采样,以尽可能保留信息。
- 3D卷积:在ViT的patch嵌入层启用深度为2的3D卷积,使模型能处理3D的"时空管",从而在不增加序列长度的情况下处理更多帧。
- 训练权衡:动态调整视频帧分辨率,将每个视频的总token数限制在16,384,以平衡长视频理解与训练效率。
2.3 训练策略与数据
三阶段预训练+指令微调:
- 第一阶段:仅训练ViT,使用大量图像-文本对,学习基础视觉-语言对齐。
- 第二阶段:解锁所有参数,使用更丰富的数据(图文交错文章、VQA、视频对话等)进行大规模预训练(累计1.4万亿token)。
- 第三阶段:冻结ViT,仅对LLM进行指令微调。使用ChatML格式构建数据,涵盖多轮对话、多图比较、视频理解、文档解析、智能体交互等。
数据构成:具备清洗后的网页内容、开源数据集和合成数据,知识截止日期为2023年6月。
三、 实验与性能分析
3.1 整体性能对比
- 综合表现:Qwen2-VL-72B在绝大多数基准测试中表现最佳,尤其在文档理解(DocVQA, InfoVQA)、OCR(OCRBench) 和需要综合能力的基准(MMVet, MMT-Bench)上优势明显。
- 与顶级模型对比:
- 在DocVQA(96.5)和InfoVQA(84.5)上显著超越GPT-4o和Claude 3.5。
- 在RealWorldQA(空间推理)和MME(综合感知与认知)上取得SOTA。
- 在MMMU(复杂多学科问题求解)上略逊于GPT-4o,表明在极高难度的推理任务上仍有提升空间。
3.2 细分能力评估
- 多语言OCR:
- 在内部多语言OCR基准上,Qwen2-VL-72B在韩语、日语、法语、德语等大多数语言上超越了GPT-4o,仅在阿拉伯语上稍弱。
- 在公开的MTVQA数据集上也达到了SOTA。
- 数学推理:
- 在MathVista(70.5)上超越其他LVLM,展示了强大的数理逻辑与视觉结合能力。
- 在更具挑战性的MathVision(25.9)上确立了开源模型的新标杆。
- 指代表达理解:
- 在RefCOCO/+/g材料集上,Qwen2-VL-72B取得了与顶尖通用模型(如CogVLM, Ferretv2)相媲美甚至更优的成绩,优于许多专用模型。
- 视频理解:
- 在MVBench, PerceptionTest, EgoSchema等多个视频基准上取得SOTA或接近SOTA的性能。
- 证明了模型缩放对视频能力提升的有效性。
- 视觉智能体:
- 函数调用:在类型匹配(93.1)和精确匹配(53.2)上均超越GPT-4o。
- UI管理(AITW):凭借强大的 grounding 能力,在操作准确率上大幅领先。
- 卡牌游戏:在Number Line, EZPoint等游戏中达到100%成功率,展现了强大的OCR与决策规划能力。
- 机器人控制(ALFRED):在valid-unseen集上小幅超越专用模型ThinkBot。
- 导航(VLN)挑战。就是:表现与GPT-4o相当,但仍落后于专用导航模型,表明对3D环境的结构化理解仍
3.3 消融研究
- 动态分辨率有效性:
- 动态分辨率策略在平均采用更少token的情况下,达到了与最优固定分辨率相当甚至更好的性能,证明了其高效性与鲁棒性。
- 提升性能,必须为不同图像选择合适的分辨率。就是单纯增大图像尺寸并不总
- M-RoPE有效性:
- 相比1D-RoPE,M-RoPE在多个下游任务,尤其是视频任务上带来稳定提升。
- 在长度外推测试中,尽管训练时最大序列长度为16K,模型在推理时能有效处理高达80K token的长视频输入。
- 模型缩放效应:
- 模型性能随参数规模增大而持续提升,特别是在数学能力上呈现强正相关。
- 对于OCR相关任务,即使小模型也表现出较强能力,说明该能力可能较早被掌握。
四、 定性展示亮点
论文借助大量示例展示了模型的实用能力:
- 复杂OCR与格式遵循:从密集的中文教材页面中准确提取并翻译文本,并能按要求整理成表格或JSON格式。
- 视觉推理:解除几何问题、计算立体图形的表面积和体积。
- 流程图与代码理解:理解算法流程图并生成对应伪代码。
- 长视频理解与多轮对话:准确描述长达数分钟的视频内容,并能进行多轮、深入的问答交互。
- 视觉智能体:在手机UI上一步步执行"寻找餐厅"的任务,在Blackjack游戏中根据牌面做出合理的"Hit/Stand"决策。
五、 总结与展望
Qwen2-VL系列通过其创新的动态分辨率、M-RoPE和统一架构,实用地克服了当前LVLM在感知细节、处理多模态位置信息和理解动态内容方面的核心痛点。它不仅在各种基准测试中确立了新的性能标杆,更通过强大的多语言支撑、长视频理解和智能体能力,展现了其作为下一代多模态基础模型的巨大潜力。
未来工作方向:
- 进一步提升在极度复杂推理任务(如MMMU) 上的性能。
- 探索更高效的长视频处理技术,突破当前token数量的限制。
- 持续扩展和优化智能体在真实、困难环境中的规划和执行能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号