
详细介绍:C++ 日志4——多线程异步日志
多线程异步日志系统
3.1 系统的分析:多线程日志的挑战
文档首先清晰地指出了多线程程序对日志库的新需求:
问题所在
线程安全:多个线程并发写日志时,日志消息不能出现交织(一条日志被截断成多段)。
性能瓶颈:
全局锁方案:简单的用一个全局mutex保护IO,所有线程争抢同一把锁,性能堪忧。
每线程单独文件:分析日志时需要在多个文件间跳转,极其不便,且不一定能提速。
业务线程阻塞:如果业务线程直接写磁盘,在磁盘IO慢时会被阻塞。
解决方案:异步日志
文档提出了优雅的解决方案:
用一个工作线程负责收集日志消息,并写入日志文件,其他业务线程只需向这个"日志线程"发送日志消息。
这就是"异步日志"的核心思想:将日志的生成与写入分离到不同的线程中。
前端(生产者和用线程):只负责生成日志消息,放入缓冲区。
后端(消费者或日志线程):负责将缓冲区中的日志写入文件。
这种架构带来了两大好处:
非阻塞:业务线程不会被磁盘IO阻塞。
批处理:减少线程唤醒和系统调用次数。
3.2 系统的设计:双缓冲技术
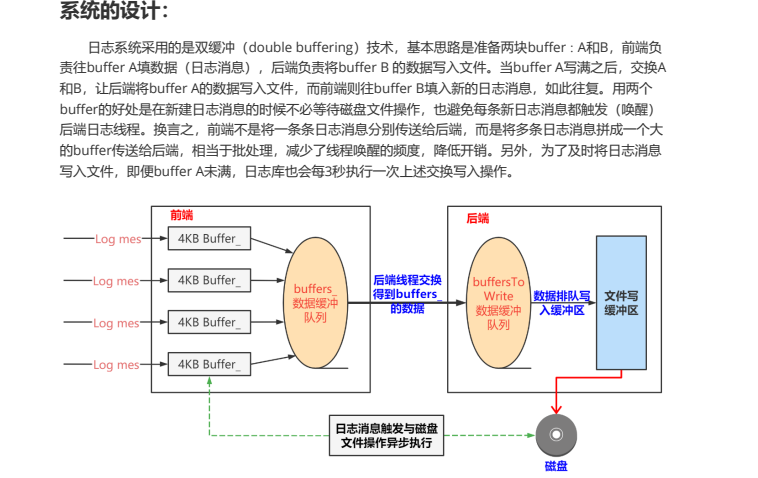
文档采用了双缓冲(double buffering) 技术,这是实现高性能异步日志的关键。
双缓冲的基本思路
text
准备两块buffer:A和B
前端负责往buffer A填数据(日志消息)
后端负责将buffer B的数据写入文件
当buffer A写满之后:
1. 交换A和B(瞬间完成)
2. 后端将buffer A(现在是旧数据)写入文件
3. 前端往buffer B(现在是空buffer)填入新的日志消息
如此往复双缓冲的优势
减少线程同步:前端在大部分时间操作不同的buffer,减少与后端的竞争。
批处理优化:前端不是一条条传送日志,而是将多条日志拼成大的buffer传送,大幅减少线程唤醒和系统调用次数。
及时性保证:即使buffer未满,也会定期(如3秒)执行交换写入操作,防止日志丢失。
架构示意图
text
前端线程
↓
Log mes→ 4KB Buffer A
Log mes→ 4KB Buffer A
...
↓ (当A满或超时)
交换 A ↔ B
↓
后端线程处理Buffer A(旧数据)
↓
buffersToWrite 数据缓冲队列
↓
文件写缓冲区
↓
磁盘文件3.3 系统类型的设计
AsyncLogging 类头文件
cpp
namespace tulun {
class AsyncLogging {
private:
AsyncLogging(const AsyncLogging&) = delete;
AsyncLogging& operator=(const AsyncLogging&) = delete;
void workthreadfunc(); // 工作线程函数
private:
const int flushInterval_; // 定期刷新间隔(秒)
std::atomic running_; // 是否正在运行
const string basename_; // 日志文件名
const size_t rollSize_; // 回滚大小
std::unique_ptr ptthread_; // 后端线程
std::mutex mutex_; // 互斥锁
std::condition_variable cond_; // 条件变量
std::string currentBuffer_; // 当前前端缓冲区
std::vector buffers_; // 已满缓冲区队列
tulun::LogFile output_; // 日志文件对象
public:
AsyncLogging(const string& basename, size_t rollSize, int flushInterval = 3);
~AsyncLogging();
void append(const string& info);
void append(const char* info, int len);
void start();
void stop();
void flush();
};
} 核心数据成员分析
currentBuffer_:前端线程当前正在写入的缓冲区
类型是
std::string,利用其动态扩容特性
buffers_:存储已写满的缓冲区(等待后端线程处理)
使用
vector<std::string>作为队列
同步机制:
mutex_:保护currentBuffer_和buffers_cond_:通知后端线程有数据需要处理
output_:复用之前实现的
LogFile,负责实际的文件写入和滚动
3.4 系统的实施和测试
常量和构造函数
cpp
static const int BufMaxLen = 4000; // 单个缓冲区最大长度
static const int BufQueueSize = 16; // 缓冲区队列初始大小
AsyncLogging::AsyncLogging(const std::string& basename, size_t rollSize, int flushInterval)
: flushInterval_(flushInterval),
running_(false),
rollSize_(rollSize),
ptthread_(nullptr),
output_(basename, rollSize, false) { // LogFile不需要线程安全,由本类保证
currentBuffer_.reserve(BufMaxLen); // 预分配内存
buffers_.reserve(BufQueueSize); // 预分配vector容量
}设计要点:
BufMaxLen = 4000:略小于4KB,与内存页大小对齐预分配内存避免运行时动态扩容
启动和停止
cpp
void AsyncLogging::start() {
running_ = true;
// 创建后端工作线程
ptthread_.reset(new std::thread(&AsyncLogging::workthreadfunc, this));
}
void AsyncLogging::stop() {
running_ = false;
cond_.notify_all(); // 唤醒可能阻塞的线程
ptthread_->join(); // 等待线程结束
}前端接口:append方法
这是最关键的生产者代码:
cpp
void AsyncLogging::append(const char* info, int len) {
std::unique_lock _lock(mutex_);
// 如果当前缓冲区剩余空间不足
if (currentBuffer_.size() >= BufMaxLen ||
(currentBuffer_.capacity() - currentBuffer_.size()) < len) {
// 将当前缓冲区移到队列中
buffers_.push_back(std::move(currentBuffer_));
// 重置当前缓冲区(move后currentBuffer_为空)
currentBuffer_.reserve(BufMaxLen);
// 通知后端线程
cond_.notify_all();
}
// 将数据追加到当前缓冲区
currentBuffer_.append(info, len);
} 关键技术点:
std::move优化:避免不必要的内存拷贝条件判断:只有当缓冲区满或空间不足时才通知后端
锁范围:只在操作共享数据时加锁,时间尽可能短
后端线程:workthreadfunc方法
这是最复杂的消费者逻辑:
cpp
void AsyncLogging::workthreadfunc() {
std::vector buffersToWrite; // 本地队列,减少锁持有时间
buffersToWrite.reserve(BufQueueSize);
while (running_) {
{
std::unique_lock _lock(mutex_);
// 等待条件触发:超时或缓冲区满
if (buffers_.empty()) {
cond_.wait_for(_lock, std::chrono::seconds(flushInterval_));
}
// 无论因何醒来,都将currentBuffer_放入队列
buffers_.push_back(std::move(currentBuffer_));
currentBuffer_.reserve(BufMaxLen);
// 交换到本地队列,快速释放锁
buffersToWrite.swap(buffers_);
buffers_.reserve(BufQueueSize); // 保持容量
} // 释放锁
// 处理堆积保护:防止生产速度 > 消费速度
if (buffersToWrite.size() > 25) {
char buf[256];
snprintf(buf, sizeof buf, "Dropped log messages at larger buffers\n");
fputs(buf, stderr);
// 丢弃多余日志,只保留2个缓冲区
buffersToWrite.erase(buffersToWrite.begin() + 2, buffersToWrite.end());
}
// 批量写入文件
for (const auto& buffer : buffersToWrite) {
output_.append(buffer.c_str(), buffer.size());
}
buffersToWrite.clear();
}
output_.flush(); // 退出前确保所有数据落盘
} 精妙的设计细节:
双重缓冲队列:
buffers_:全局队列,受mutex保护buffersToWrite:线程本地队列,无锁操作
锁范围优化:
只在交换数据时加锁
文件写入时不持有锁,允许前端继续生产
堆积处理:
当生产速度远超消费速度时,丢弃多余日志
防止内存耗尽导致程序崩溃
唤醒机制:
超时唤醒:保证日志及时性(默认3秒)
数据唤醒:缓冲区满时立即处理
刷新接口
cpp
void AsyncLogging::flush() {
std::vector buffersToWrite;
{
std::unique_lock _lock(mutex_);
buffers_.push_back(std::move(currentBuffer_));
buffersToWrite.swap(buffers_);
}
for (const auto& buffer : buffersToWrite) {
output_.append(buffer.c_str(), buffer.size());
}
output_.flush();
buffersToWrite.clear();
} 3.5 倒计时门闩优化
文档还介绍了一个优化:使用CountDownLatch确保工作线程真正启动后再返回。
CountDownLatch 实现
cpp
namespace tulun {
class CountDownLatch {
public:
explicit CountDownLatch(int count);
void wait();
void countDown();
int getCount() const;
private:
mutable std::mutex mutex_;
std::condition_variable condition_;
int count_;
};
}
// 实现
CountDownLatch::CountDownLatch(int count) : count_(count) {}
void CountDownLatch::wait() {
std::unique_lock _lock(mutex_);
while (count_ > 0) {
condition_.wait(_lock);
}
}
void CountDownLatch::countDown() {
std::unique_lock _lock(mutex_);
--count_;
if (count_ == 0) {
condition_.notify_all();
}
} 在AsyncLogging中的使用
cpp
class AsyncLogging {
// 添加成员
tulun::CountDownLatch latch_;
// 修改构造函数
AsyncLogging(...) : ..., latch_(1) {}
// 修改start方法
void start() {
running_ = true;
ptthread_.reset(new std::thread(&AsyncLogging::workthreadfunc, this));
latch_.wait(); // 等待工作线程真正启动
}
// 修改workthreadfunc
void workthreadfunc() {
latch_.countDown(); // 通知主线程已启动
// ... 原有逻辑
}
};这个优化的意义:防止在AsyncLogging对象析构时,工作线程还未启动完成。
3.6 测试代码
单线程测试
cpp
tulun::AsyncLogging* asynclog = nullptr;
void asyncWriteFile(const string& info) {
asynclog->append(info);
}
void asyncFlushFile() {
asynclog->flush();
}
int main() {
asynclog = new tulun::AsyncLogging("yhping", 1024 * 10); // 10KB滚动
tulun::Logger::setOutput(asyncWriteFile);
tulun::Logger::setFlush(asyncFlushFile);
asynclog->start();
for (int i = 0; i < 1000; ++i) {
LOG_INFO << "main " << i;
std::this_thread::sleep_for(std::chrono::milliseconds(200));
}
return 0;
}多线程测试
cpp
void func(char ch) {
for (int i = 0; i < 1000; ++i) {
LOG_INFO << "thread " << ch << " count " << i;
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
int main() {
asynclog = new tulun::AsyncLogging("yhping", 1024 * 10);
tulun::Logger::setOutput(asyncWriteFile);
tulun::Logger::setFlush(asyncFlushFile);
asynclog->start();
// 启动多个线程同时写日志
std::thread tha(func, 'a');
std::thread thb(func, 'b');
std::thread thc(func, 'c');
tha.join();
thb.join();
thc.join();
return 0;
}异步日志系统设计总结
性能优势
低延迟:业务线程只操作内存缓冲区,不阻塞在磁盘IO
高吞吐:批量写入减少系统调用次数
线程安全:通过清晰的锁策略保证数据一致性
可靠性保证
防堆积:当生产过快时,丢弃日志保护系统
定期刷新:即使缓冲区未满也定期写入,减少数据丢失风险
优雅退出:停止时确保所有缓冲数据写入磁盘
工程实践价值
这个异步日志设计是工业级日志库的典型实现,被广泛应用于:
高性能服务器程序
交易系统
实时数据处理系统
它展示了如何通过生产者-消费者模式、双缓冲技术、批量处理等经典技术解决实际的并发性能问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号