
【Linux】从版本控制到代码调试:Git 入门与 GDB 调试器学习指南 - 详解
/-----------Linux入门篇------------/
/-----------Linux工具篇------------/


文章专栏:< Linux >
其他专栏:< C++ > 、< 数据结构 > 、< 优选算法 >
目录
4.4.3 disable/enable breakpoints 指令
一、Git 版本控制器
1.1 什么是 Git?
Git 是一款分布式版本控制系统,可以理解为代码的 “时光机”—— 它能记录代码的每一次修改,让你随时回退到历史版本,还能支持多人协作开发。和传统的 SVN(svm只能通过服务端查看历史记录) 相比,Git 是 “客户端 - 服务端一体” 的设计,既可以本地单机管理代码,也能通过远程仓库(如 GitHub、Gitee)实现团队协作。
【问题】:什么是分布式?
【分布式的核心概念】:
将整体的任务、数据或功能分散部署到多个独立的节点(如计算机、服务器等)上,使各节点能并行处理任务;每个节点可拥有完整或部分资源,支持独立工作,节点之间通过网络进行协同与同步,无需依赖单一中心节点来驱动整个系统运行。
【分布式的典型特点】:
- 并行执行:多节点可同时处理任务,提升整体效率;
- 去中心化:无单一故障点,某一节点故障不影响系统整体运行;
- 弹性扩展:可通过新增节点快速拓展系统能力。
简单类比(以 Git 为例)
Git 作为分布式版本控制系统,核心特点是每个用户的本地都拥有完整的版本库:
- 既可以连接远端服务端(如 GitHub、GitLab)进行代码推送、拉取,实现团队协作;
- 也能在本地完全独立地完成提交、分支管理、版本回滚等所有版本控制操作;
- 多个用户可在各自本地 “并行” 开展开发,之后再通过同步操作整合修改,完美体现了分布式 “多节点独立工作 + 协同同步” 的特性。
【问题】:什么是集中式?
【集中式的核心概念】:
将系统的任务、数据或功能集中部署在单一的中心节点(如中央服务器)上,所有操作(如数据存储、任务处理)都依赖该中心节点完成;用户或从属节点需连接到中心节点才能开展工作,本地通常仅保留临时的工作副本,不具备独立处理核心任务的能力。
【集中式的典型特点】:
- 单一中心:系统依赖唯一的中心节点驱动,逻辑集中、管理便捷;
- 强依赖性:用户或从属节点必须连接中心节点才能完成核心操作,若中心节点故障,整个系统将无法正常运行;
- 扩展受限:系统能力受中心节点的硬件、性能上限约束,难以快速弹性扩展。
简单类比(以 SVN 为例)
SVN 作为集中式版本控制系统,核心特点是仅中央服务器保存完整的版本库:
- 用户必须连接到中央服务器,才能执行提交、更新、分支管理等版本控制操作;
- 本地仅保留当前工作副本,无完整版本库,无法在断网或中心服务器不可用时独立进行版本管理;
- 多用户需串行或依赖中心节点的调度开展协作,体现了集中式 “单一中心驱动 + 节点强依赖” 的特性。
1.2 Git 核心概念
- 仓库(Repository):分为本地仓库(你电脑里的代码库)和远程仓库(如 GitHub 上的共享代码库);
- 版本控制:像管理实验报告版本一样,Git 能记录代码的每一次修改(比如 “实验报告 v1”“实验报告究极版”),随时回溯;
- 分布式协作:每个开发者都有完整的代码库,既可以本地开发,又能通过远程仓库同步协作(比如张三、李四可以分别改代码,再合并到同一个远程仓库)。
1.3 GitHub 与 Gitee
Git 是版本控制工具,而 GitHub、Gitee 是基于 Git 的商业化代码托管平台—— 你可以把它们理解为 “代码的社交网络”,既能存代码,又能和全球开发者协作、学习优质项目。类似地,基于 Linux 内核也衍生出了 CentOS、Ubuntu 等商业化操作系统,原理是相通的~
二、Git 基础操作
1. Git安装
- 安装 Git:在 Linux 上可通过包管理器快速安装,比如 CentOS 用
yum install git,Ubuntu 用apt install git;
2. 远程仓库与本地仓库联动(以 Gitee 为例)
【新建仓库】:
进入gitee后点右上角的+,点击后就能看到新建仓库这一选项,点击后就到了下述界面
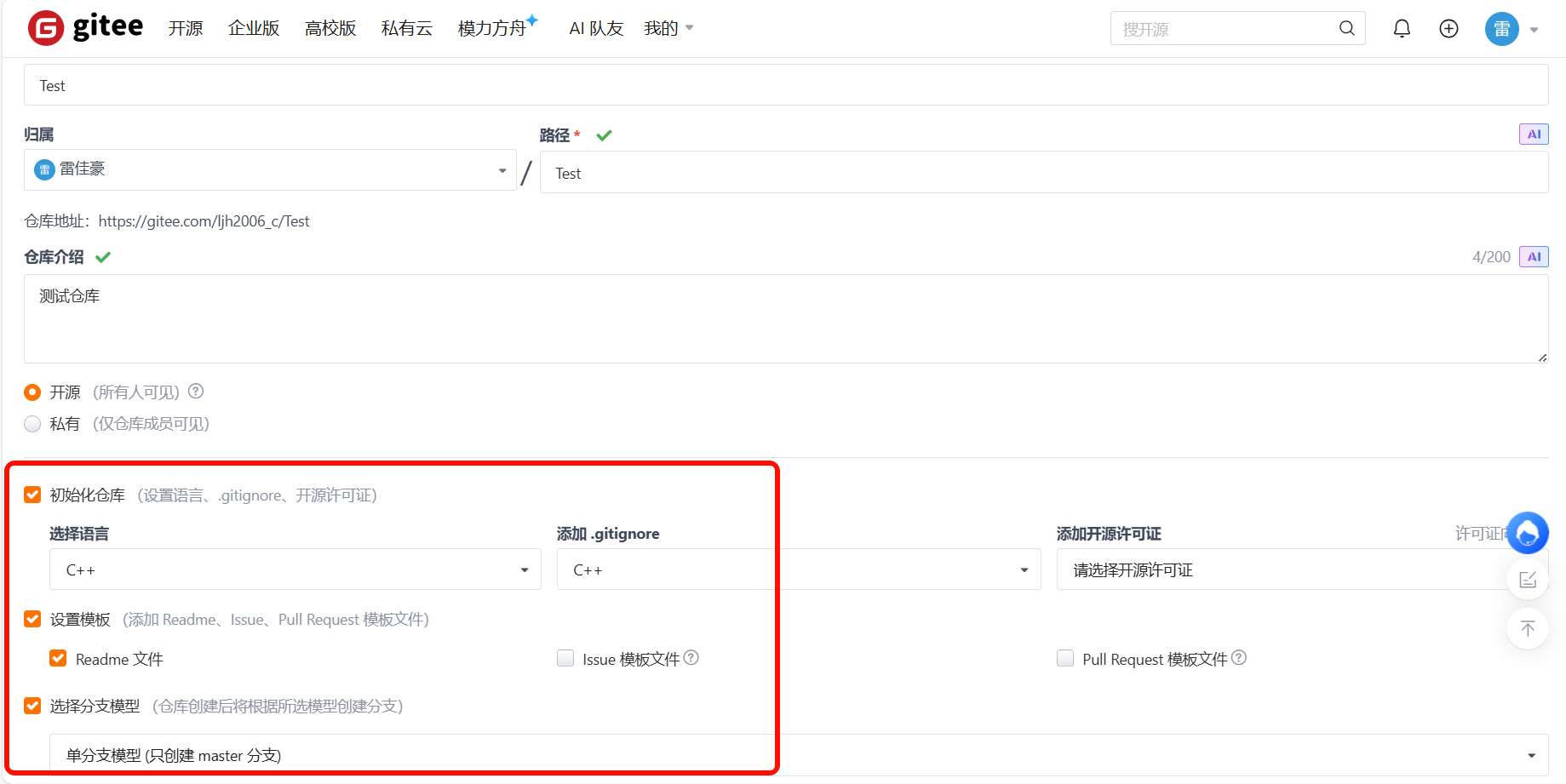
在这里,选择你需要的代码语言来保存版本。README文件用于仓库的说明,创建时会自动生成中英文版本。在分支选项中,这里推荐选择单分支是为了简化项目管理,特别是在项目初期或只是用于代码托管时,不需要复杂的分支结构。单分支模式更适合简单的版本控制,避免了多分支带来的合并冲突和管理开销。
【将远端仓库拉到本地】:
点击新建仓库右上角的克隆和下载:
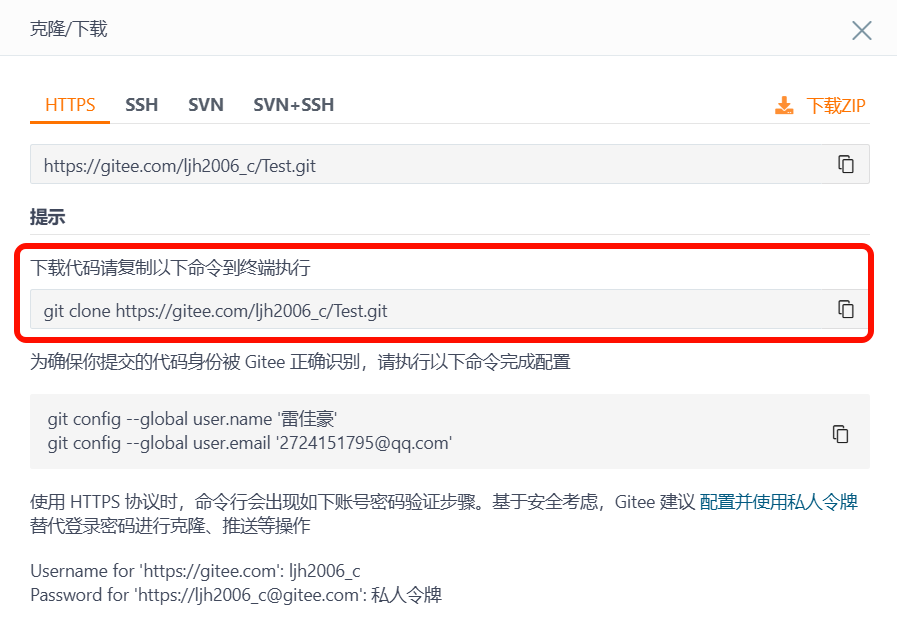

克隆成功!!!
#将远端仓库克隆到本地的命令
git clone 仓库地址
Test仓库此时就在我们的当前目录下,大家使用时尽量放在普通用户下,我这只是示范,所以就没有切换用户了。
3. 身份配置
当我们将远端仓库拉取到本地,为了确保提交的代码身份被Gitee/GitHub正确识别,需要在本地进行相关配置
git config --global user.email "你的邮箱"
git config --global user.name "你的名字"Git 配置 user.name 和 user.email,是为了给代码提交打上专属身份标签,方便后续查看提交历史、追溯修改责任。
4. 代码提交的 “三板斧”
【第一招】:git add—— 把文件加入 “待提交队列”把需要版本管理的文件告知 Git,命令格式:
git add 文件名 # 单个文件
git add . # 当前目录所有文件
【第二招】:git commit—— 提交修改到本地仓库把 “待提交队列” 的修改保存到本地仓库,同时写提交日志(描述这次改了啥,这块不能随便填写):
git commit -m "提交日志:比如‘新增登录功能’"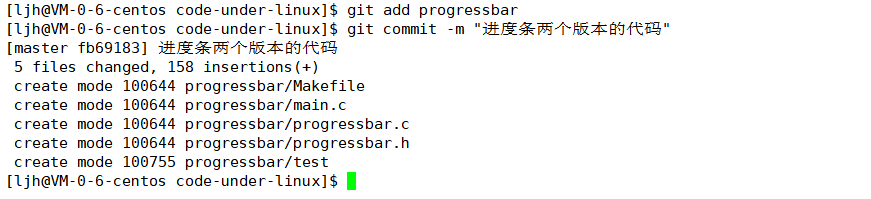
【第三招】:git push—— 同步修改到远程仓库把本地仓库的修改推送到 GitHub 等远程仓库,命令:
git push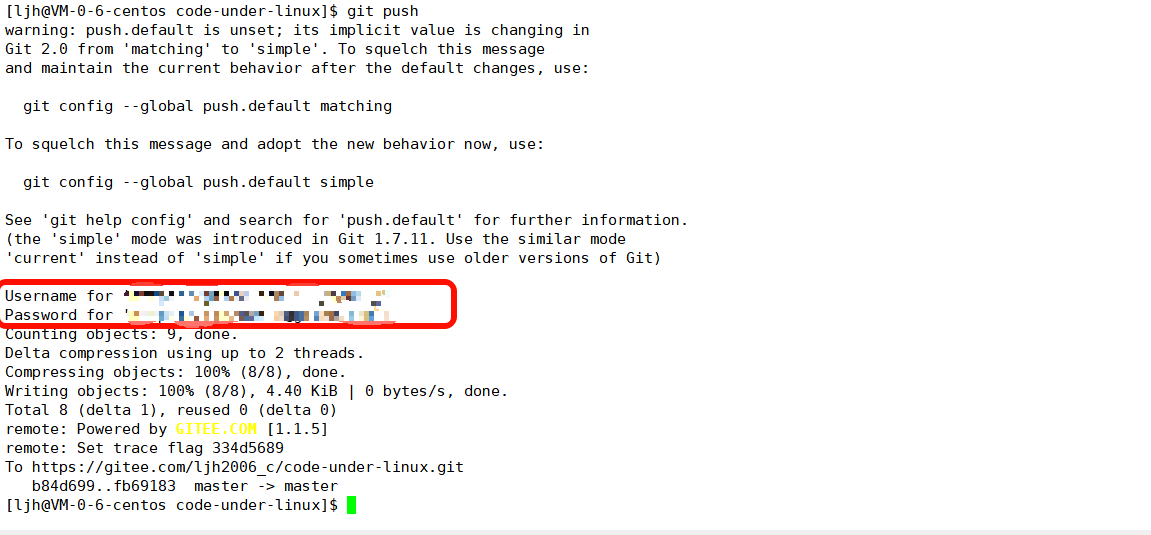
首次推送可能需要输入 GitHub 账号密码(或配置 SSH 密钥免密,新手不建议配置免密),在圈的地方输入你的账号和密码即可,账号会回显,密码不会回显。
【配置免密码提交】:https://blog.csdn.net/camillezj/article/details/55103149
Git 工作流程围绕工作区、暂存区、本地仓库三个区域展开,操作需在仓库目录内进行:
- 工作区:项目目录中可见的文件(如仓库下的代码文件、文档),修改后仅存于此,未被 Git 跟踪为新版本;
- 执行
git add命令,将工作区的修改加入暂存区(可理解为 “待提交清单”);- 执行
git commit命令,将暂存区内容提交到本地仓库(.git目录是本地仓库的核心,提交后形成版本记录并保存);- 最后通过
git push可将本地仓库的变更同步到远程仓库。
5. git其他选项
【git log命令】
作用:查看历史提交记录
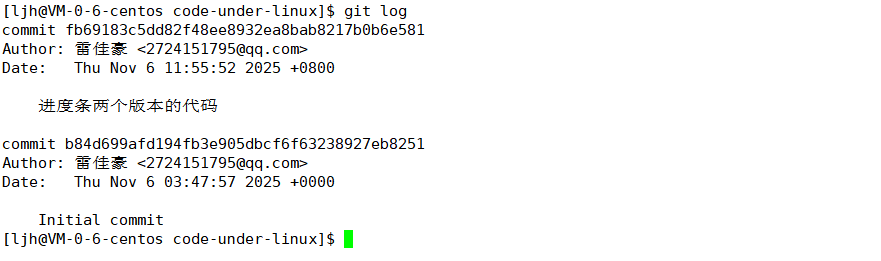
历史提交记录的信息,包含你的信息、日志、提交时间等等
【git status命令】
作用:查看当前目录状态

显示当前没有东西可以提交的内容,工作区已清理
【.gitignore文件】
作用是指定 Git 版本控制中需要忽略的文件或目录,让这些文件 / 目录不被纳入版本管理,简单来说就是去掉杂项文件,只保留需要使用的文件
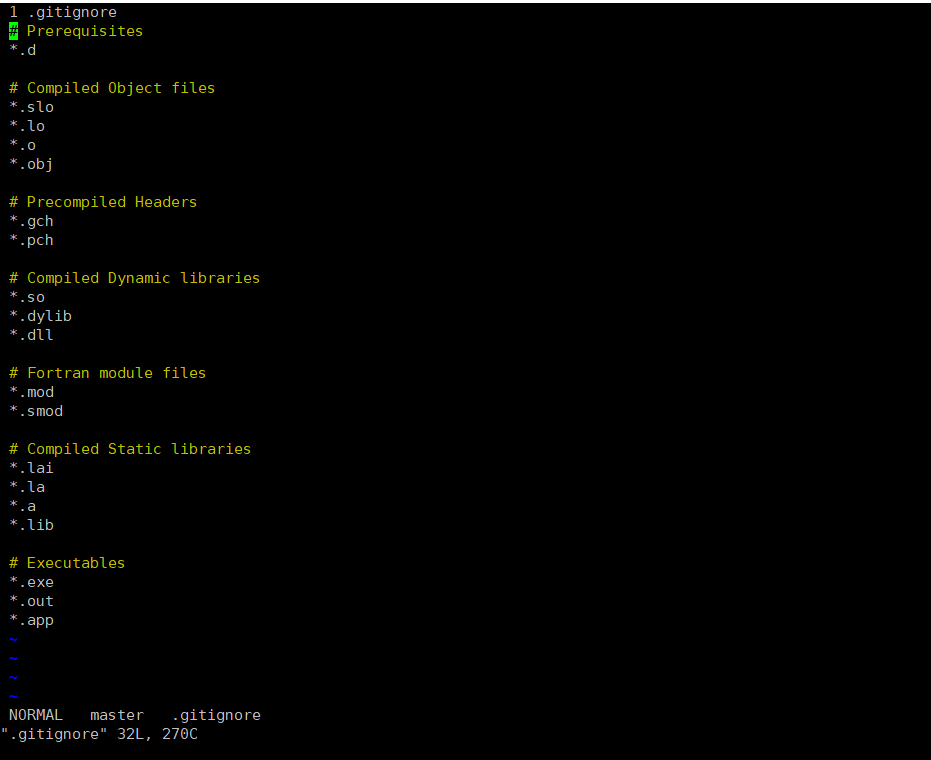
在 .gitignore 文件中,通过通配符(如 *.exe、*.out)可以指定 “匹配该后缀的所有文件都被忽略,不推送到远程仓库”。如果要添加自定义的杂项文件,需要用 *后缀 的格式(比如要忽略所有 .tmp 临时文件,就写 *.tmp);如果只写后缀(如 tmp),Git 会把它当作 “名为 tmp 的文件” 来处理,无法实现批量忽略同后缀文件的效果。
三、gdb前置知识
- 程序的发布方式有两种,debug模式和release模式
- Linux gcc/g++出来的二进制程序,默认是release模式
- 要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
- gdb是系统默认安装的,所以可以直接使用
【如何确认gcc/g++默认编译出来的结果是release版本还是debug版本】
没带 "-g" 选项编译出来的结果:

带 "-g" 选项编译出来的结果:
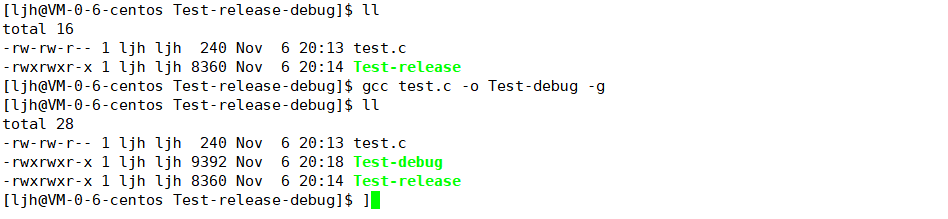
可以看到两次编译后的文件大小不同,那么带 "-g" 选项编译后的可执行程序多了什么呢?
多出来的就是调试信息,这样也可以间接证明gcc默认编译出来的结果是release版本
【readelf指令】
- 语法:
readelf [选项] [ELF文件]- 功能:用于显示 ELF 格式文件(如可执行文件、库文件)的详细信息,可查看文件头、节信息、符号表等内容
- 常用选项:
-h显示 ELF 文件头信息-l显示程序头表信息-S显示节头表信息-s显示符号表信息-d显示动态段信息-w显示调试信息--help查看所有选项说明

在 Linux 系统中,虽然可执行文件是二进制格式,但其内部结构采用了 ELF (Executable and Linkable Format/可执行与可链接格式)格式,可以通过 readELF 工具查看。
四、gdb相关调试指令
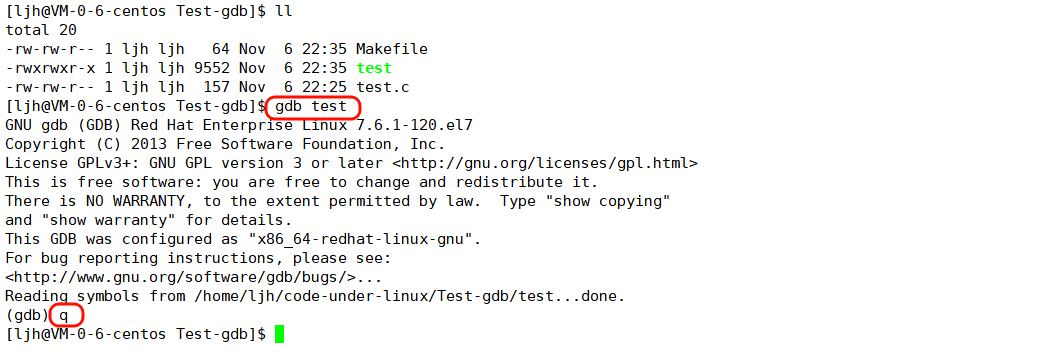
4.1 进入gdb和退出gdb指令
- 进入gdb指令:gdb可执行文件名称
- 退出gdb指令:quit(q) 或者 ctrl + d
4.2 查看源代码指令
list / l 行号:显示指定行号附近的源代码,从上次位置继续向下列,每次列 10 行。list / l 函数名:列出指定函数的源代码。
注意:gbd会默认记录最近一次的指令,可以回车执行最近一次指令。
【用行号查看演示】:

l 5就是显式第五行上面的5行和下面的5行也就是每次显式10行

输入一次指令后,按回车就会自动向下再输出10行,输出完就显示有多少行

这个时候想要再从头看可以输入l 0,一般从头开始的话,只输输入 l的话会自动输出10行
【查看函数演示】:

显式sum函数附近的10行代码,反正也是每次输出10行,按空格就继续输出10行,输出完就显示一共多少行
4.3 run/r指令
作用:运行程序。
核心特点:
- 执行后会直接启动程序并运行至结束(类似 IDE 中的 “运行” 功能,如 VS 的 F5 键);
- 若程序无断点,会一次性跑完所有逻辑,因此通常需要结合断点指令(如
b 行号或b 函数名) 来实现调试暂停,进而逐步分析程序流程。
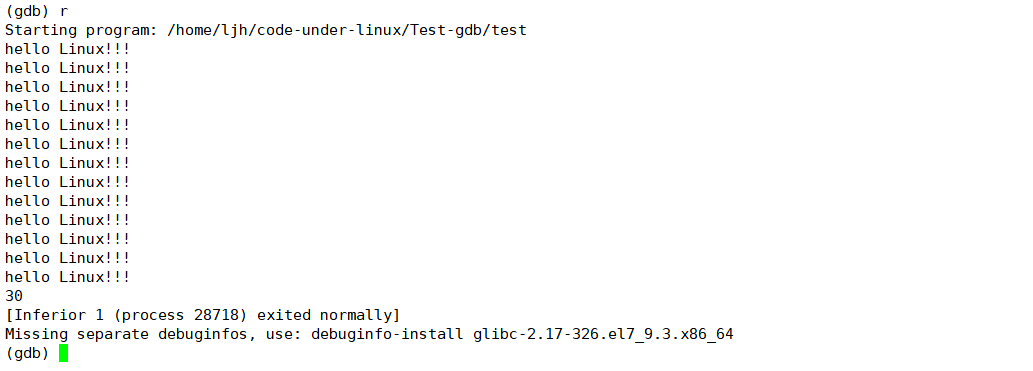
没打断点就一次性跑完了,要像vs那样调试的话得必须打断点,确实有点烦人,不好用!!!
4.4 断点相关调试指令
4.4.1 break/b指令
这是 GDB 调试中用于设置断点的
break(简写b)指令,有四种常见用法:
break 行号(或b 行号):在代码的指定行设置断点,程序运行到该行时会暂停。例如break 20(或b 20),会在第 20 行设置断点。break 函数名(或b 函数名):在指定函数的开头设置断点,程序进入该函数时会暂停。例如break main(或b main),会在main函数的开头设置断点。- break 文件名:行号(或 b 文件名:行号):在指定文件的指定行设置断点。例如
break test.c:20(或b test.c:20),会在test.c文件的第 20 行设置断点。- break 文件名:函数名(或 b 文件名:函数名):在指定文件的指定函数开头设置断点。例如
break test.c:sum(或b test.c:sum),会在test.c文件的sum函数开头设置断点。- 在 GDB 中如果不指定文件名,
break指令会默认在当前调试的主文件(通常是包含main函数的文件)中设置断点
分别在20行和main函数处打断点:

如果在第 20 行或main函数入口设置断点时,该行是空行,GDB 会自动定位到下方最近的有效语句处暂停执行,main函数的情况同理。
指定文件打断点:

4.4.2 d 指令
这是 GDB 调试中用于删除断点的 delete breakpoints 指令(简写d),有两种常见用法:
- d :删除所有断点。
- d n:删除序号为
n的断点。

第一个指令是删除序号为3的断点,第二个指令是删除所有断点,Num下的编号就对应了每个断点的序号
4.4.3 disable/enable breakpoints 指令
| 功能 | 完整指令 | 简写指令(常用) | 示例 |
|---|---|---|---|
| 禁用指定断点 | disable breakpoints 序号 | disable 序号 /dis 序号 | (gdb) dis 1(禁用序号 1 的断点) |
| 禁用所有断点 | disable breakpoints | disable / dis | (gdb) dis(禁用所有) |
| 启用指定断点 | enable breakpoints 序号 | enable 序号 /en 序号 | (gdb) en 1(启用序号 1 的断点) |
| 启用所有断点 | enable breakpoints | enable / en | (gdb) en(启用所有) |
禁用断点后就不会生效了
4.4.4 info breakpoints 指令
这是 GDB 调试中用于查看断点信息的 info breakpoints(简写
info(或i) breakpoints)指令:
- info (或 i) breakpoints:参看当前设置了哪些断点,包括断点行号、状态、数量等详细信息。

| 列名 | 核心含义(图标版) |
|---|---|
| Num | 断点序号(操作标识),序号呈线性增长,前面用过的序号纵使删除当前序号指定的断点,依旧不会用到 |
| Type | 断点类型(普通 / 观察等) |
| Disp | ⚙️ 处置方式(保留 / 自动删) |
| Enb | 启用状态(y = 启用 /n = 禁用) |
| Address | 内存地址(机器码位置) |
| What | 具体位置(文件 + 行号 / 函数) |
4.5 next/n 指令
这是 GDB 调试中用于单条执行代码的 next(简写 n)指令:
- n 或 next:单条执行(逐行执行,跳过函数内部调用,将函数调用视为 “一行” 执行)。
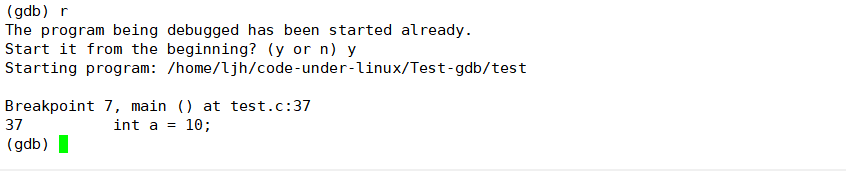
当前运行到第一个断点(main 函数处),输入n执行两次后却进入了sum函数,按理next不该进入函数才对?
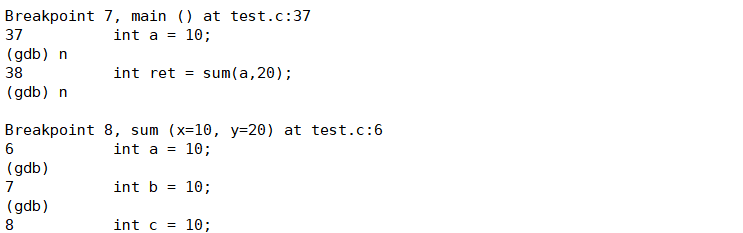
这是因为 sum函数内部设置了断点,next执行sum函数调用时,会在函数的断点处暂停(此为断点触发的暂停,并非next主动进入函数内部单步)。
4.6 step/s 指令
这是 GDB 调试中用于逐语句执行代码的 step(简写 s)指令:
- s 或 step:进入函数调用(若当前行是函数调用,会进入函数体内部逐句执行)。
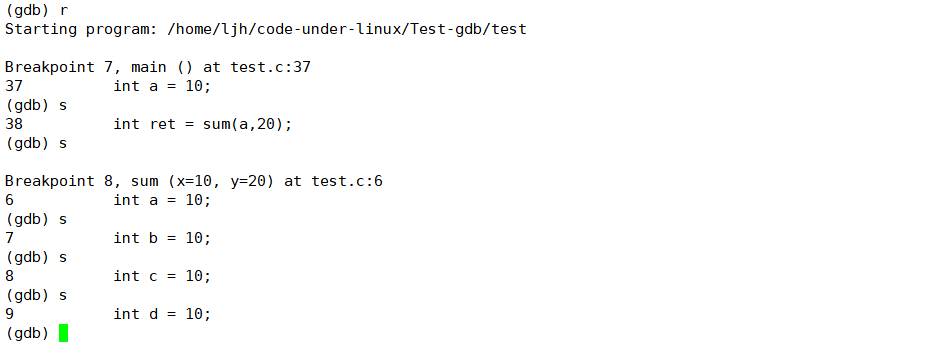
4.7 finish 指令
这是 GDB 调试中用于执行到函数返回的 finish 指令:
- finish:执行到当前函数返回,然后停下来等待命令。
在main函数中用finish,没有实际调试作用,不能这么用~
在sum函数中用会直接跳到函数调用处

4.8 print/p 指令
可打印表达式值,支持修改变量(修改后并打印)、调用函数;
p 变量是其简写形式,用于快速打印单个变量值,二者功能本质一致,p是更简洁的常用操作方式。
GDB 中$1$2这类序号,是同一个 GDB 调试会话内 **print/p操作的临时计数标记,按执行顺序线性递增;只有完全退出 GDB 并重新启动调试会话时,序号才会从$1重新开始;仅重新运行程序(不退出 GDB)时,序号会持续累加,不会重置。**
临时修改变量值:
直接调用函数,不论函数是否被执行,都会打印该函数的结果

4.9 set var指令
set var 变量名=新值(例如set var a=20,纯修改变量值,执行后无自动输出)
4.10 continue(或 c)指令
c(例如输入c,程序从当前断点位置继续连续执行,直到遇到下一个断点或程序结束)
在运行后,输入c,无断点就直接运行结束了
4.11 display指令
display 变量名(例如display a,跟踪查看变量a,程序每次暂停时都会自动显示其当前值)

相当于vs监视窗口
4.12 undisplay指令
undisplay 序号(例如undisplay 1,取消序号为 1 的变量跟踪;若要取消所有,可多次执行或用delete display系列指令)
4.13 until指令
until 行号(例如until 50,程序从当前位置连续执行到第 50 行后暂停,适合快速跳过循环等场景),只能往后跳
4.14 breaktrace (或 bt)指令
bt(例如输入 bt,查看当前程序的函数调用栈,包括各级函数的调用关系、参数和返回地址等)

这张图完美展示了函数调用栈(栈帧)随程序执行的动态变化过程:
- 阶段 1(
add函数中):调用栈有 3 层(main→sum→add),因为add还在执行,没返回sum。- 阶段 2(
sum函数中):add执行完返回,调用栈变为 2 层(main→sum),因为sum还在执行,没返回main。- 阶段 3(
main函数中):sum执行完返回,调用栈只剩 1 层(main),因为所有子函数都已返回。每一次函数调用会 “压栈”(新增栈帧),函数返回会 “出栈”(移除栈帧),这就是调用栈的动态变化逻辑~
4.15 info (i) locals指令
info locals(或i locals,例如输入info locals,查看当前栈帧中所有局部变量的名称和值)
类似于调试器的 **“自动监视窗口”,它会实时显示当前栈帧(即当前执行的函数)中所有局部变量的名称和值 **,只聚焦于程序运行到 “当前代码块” 时的变量状态,非常方便查看函数内局部变量的实时变化。
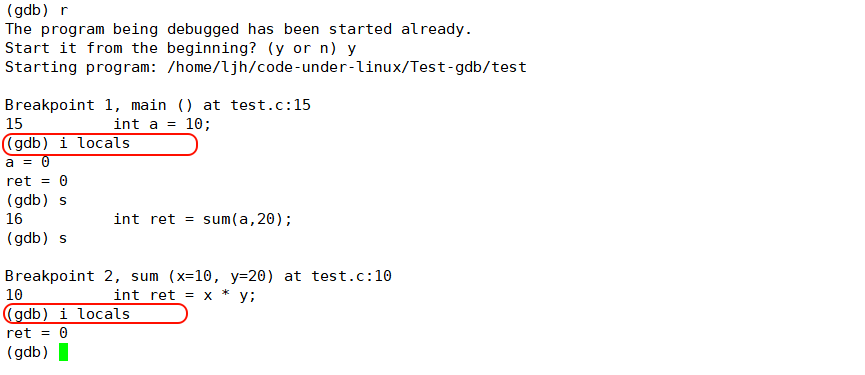
不是常显示的,运行到下一句就不会显示,需要你再次手动操作


 浙公网安备 33010602011771号
浙公网安备 33010602011771号