
爬虫案例之爬取当当网书籍信息(最新独特版) - 教程
网站:余华-当当网
温馨提示: 本案例仅供学习交流使用
| requests(发送HTTP请求) | lxml(用于解析数据模块) |
| pandas(数据保存模块) | urllib(请求 解码) |
| os(操作系统交互库) |
首先 明确爬取的数据
- 书籍名称
- 作者
- 书籍的价格
- 出版时间
- 出版社
- 书评
步骤:
- 简单分析界面 对前端的html结构有个了解
- 构建请求 模拟浏览器向服务器发送请求
- 解析数据 提取我们所需要的数据
- 保存数据 对数据进行持久化保存 如csv excel mysql
一.发送请求
查看源代码 查看是否为静态数据 Ctrl+U 快速打开页面源代码界面
Ctrl+f 搜索我们想爬取的数据 发现存在 此为静态数据
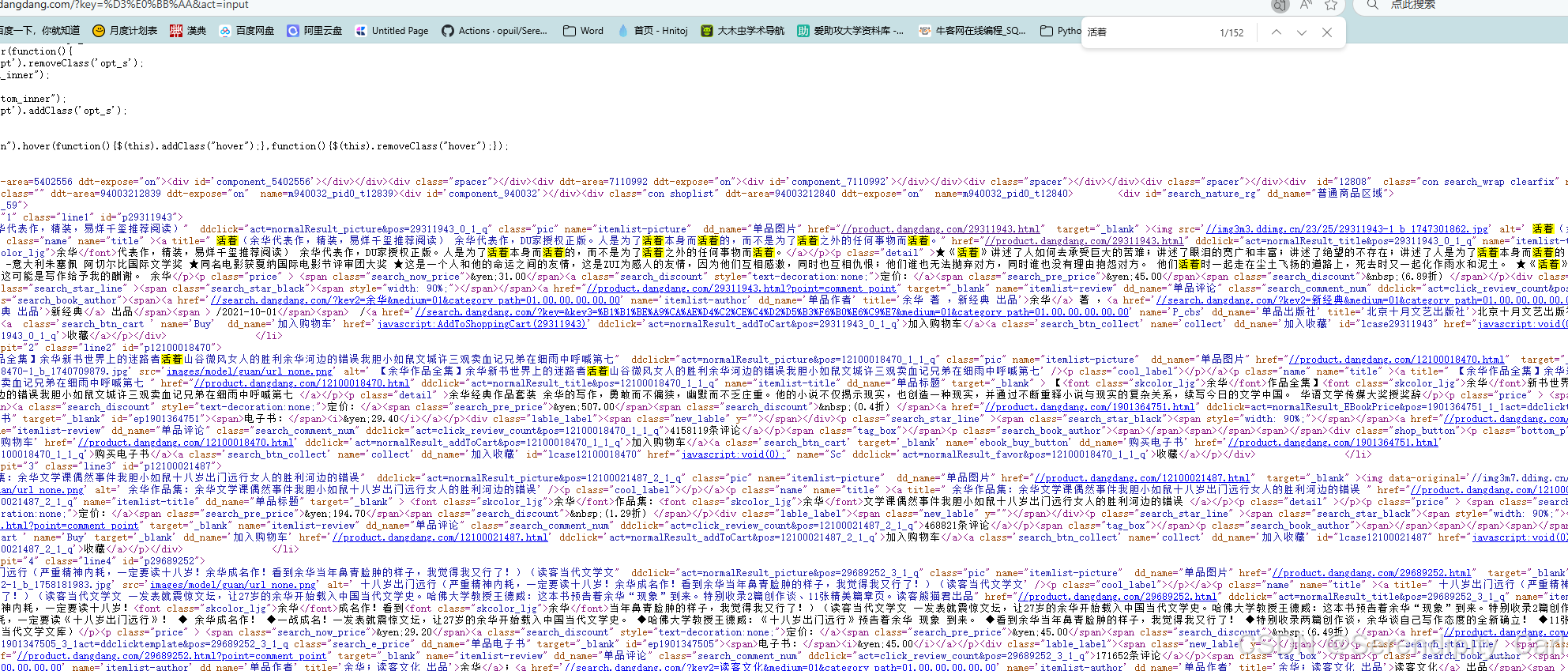
接着我们开始 分析数据所在的结构
打开页面 F12 or 右击检查 打开开发者工具
点击左上角的这个像鼠标的 然后去页面中去选要爬取的数据 查看分析节点
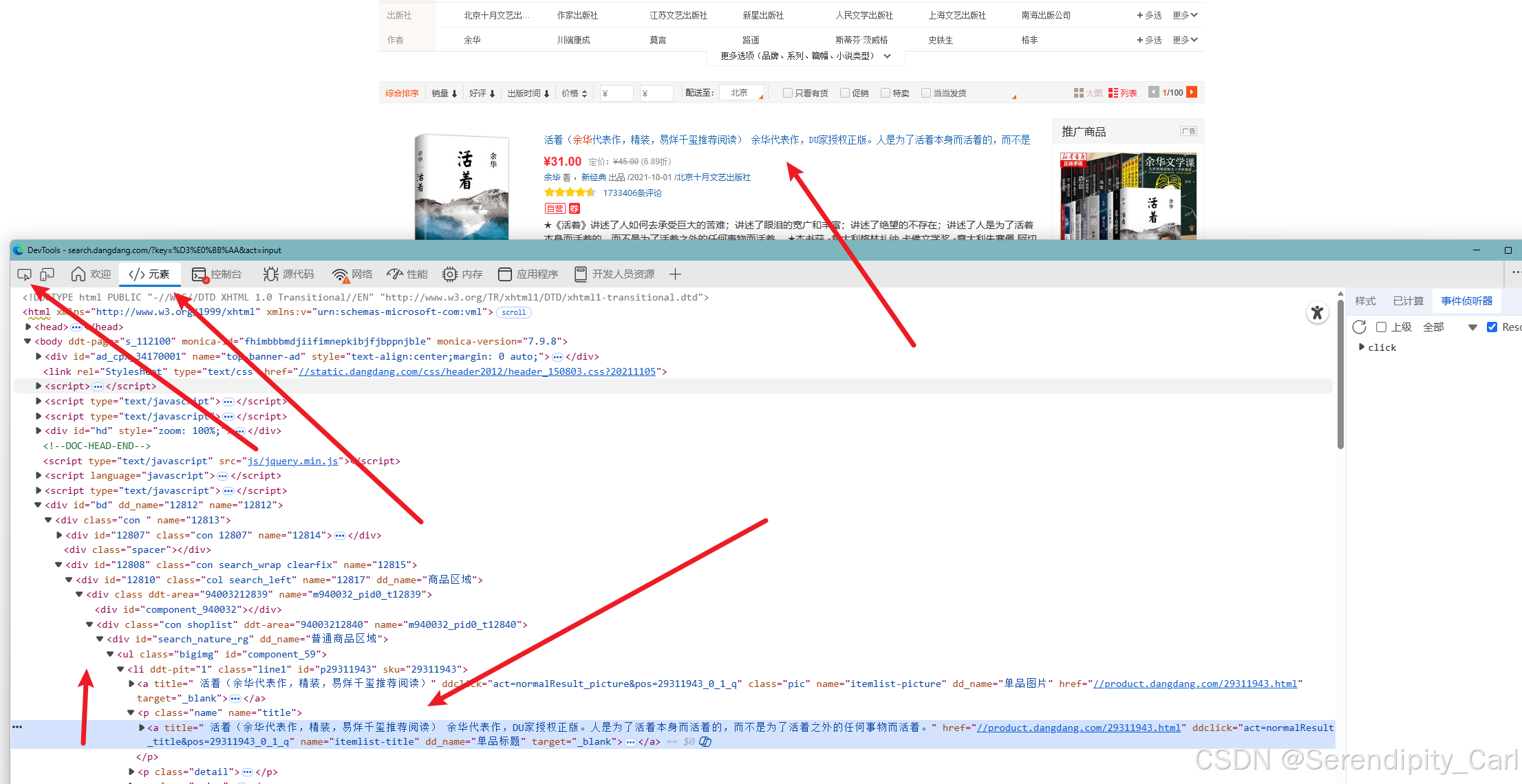
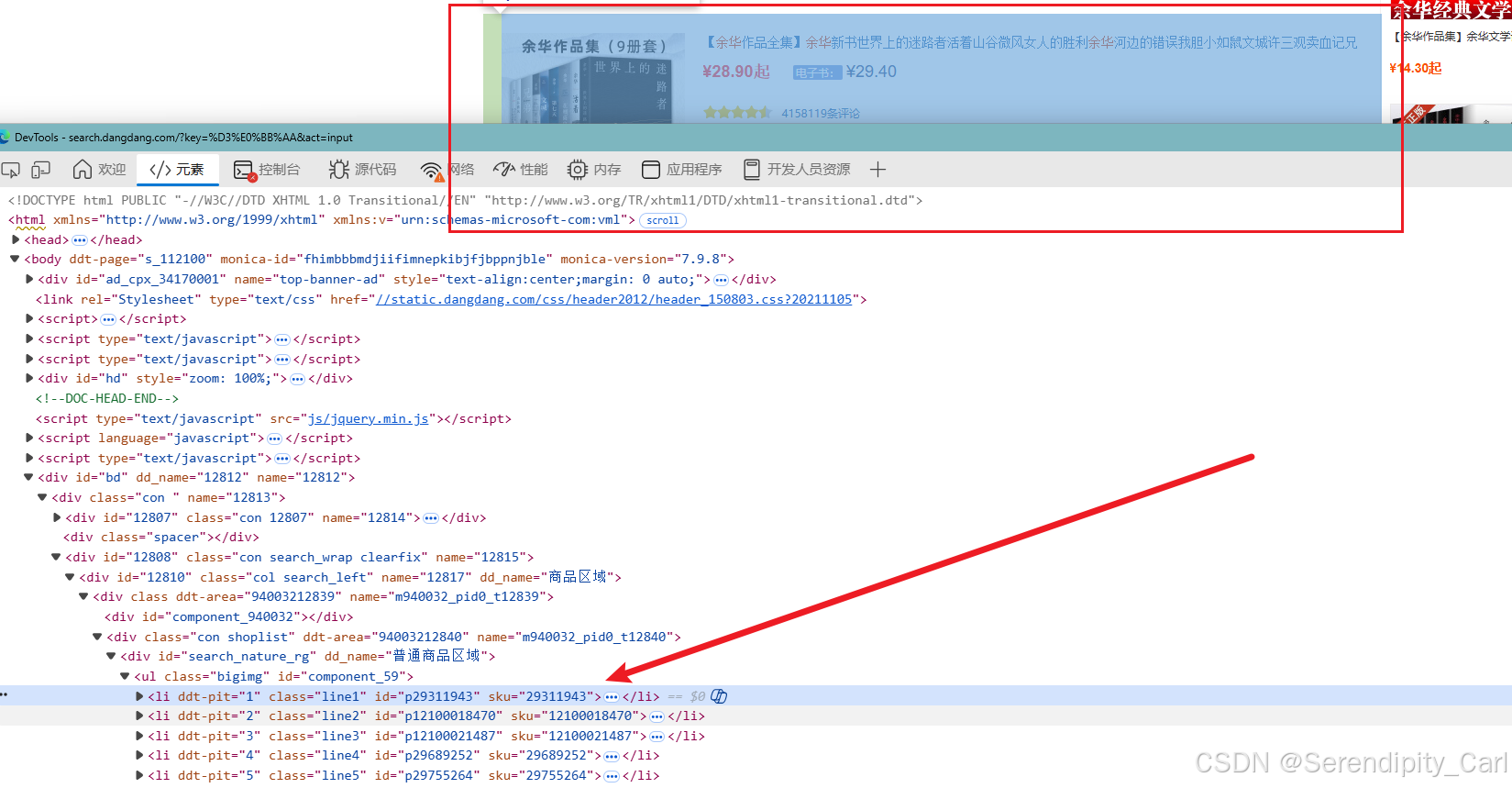
通过分析可得 每个书籍的所有信息都在id属性为 search_nature_rg ul标签下面的li标签中
OK 简单地分析了结构之后 我们开始写代码
首先复制 浏览器中的地址 接着构建请求体 UserAgent(包含浏览器的基本信息 载荷 浏览器类型等) Referen(防盗链 简单来说就是你目前这个页面是从哪里跳转过来的) Cookie(包含了用户的一些登陆基本信息 ) 在浏览器复制就可以了
点击网络 接着 按快捷键Ctrl+R 刷新 加载数据包 手动刷新也行 点击标头下滑 复制即可
headers 通过键值对的形式构建 字典类型的
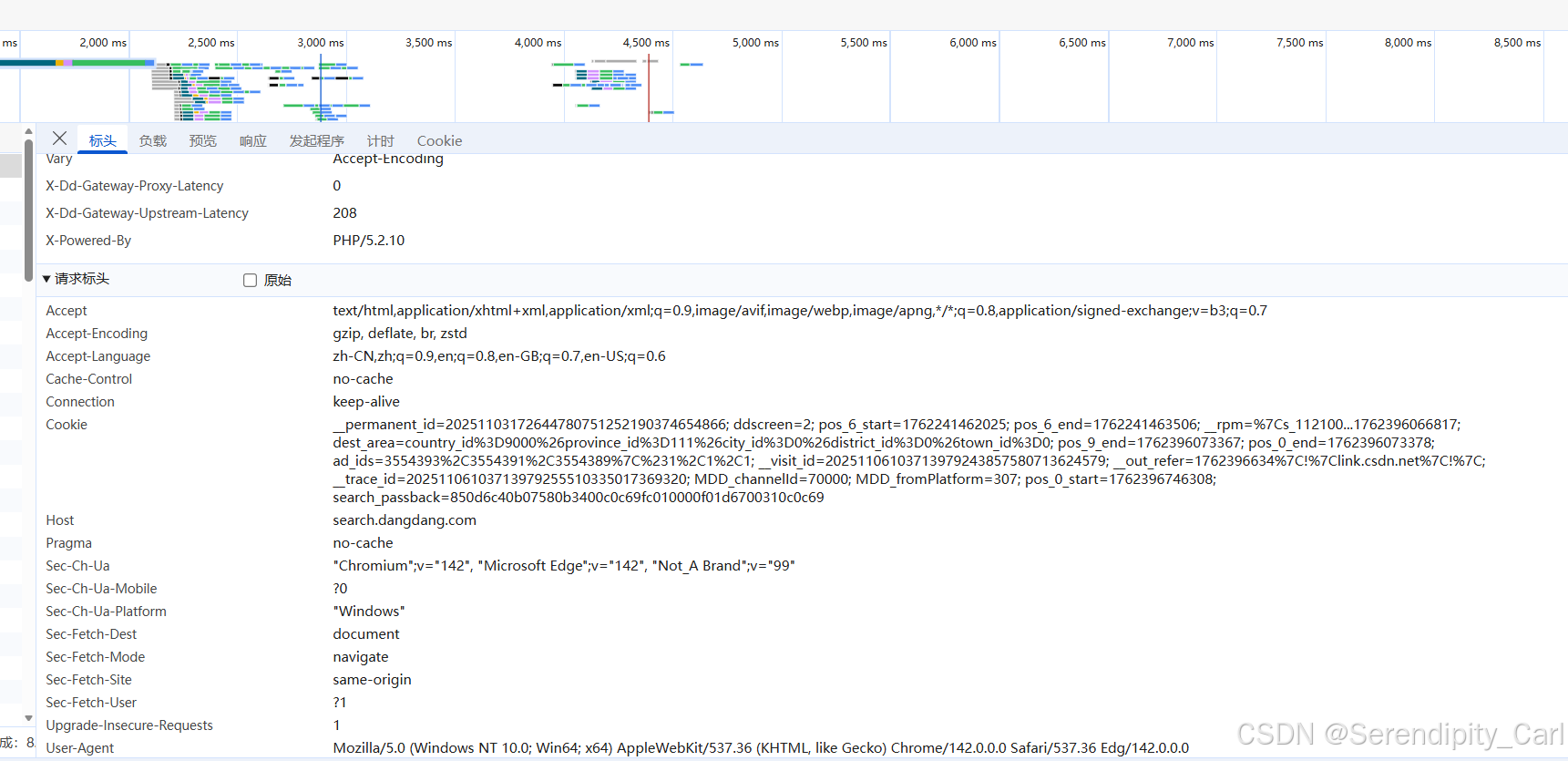
本网站复制个UA就够了
二. 解析数据 提取数据
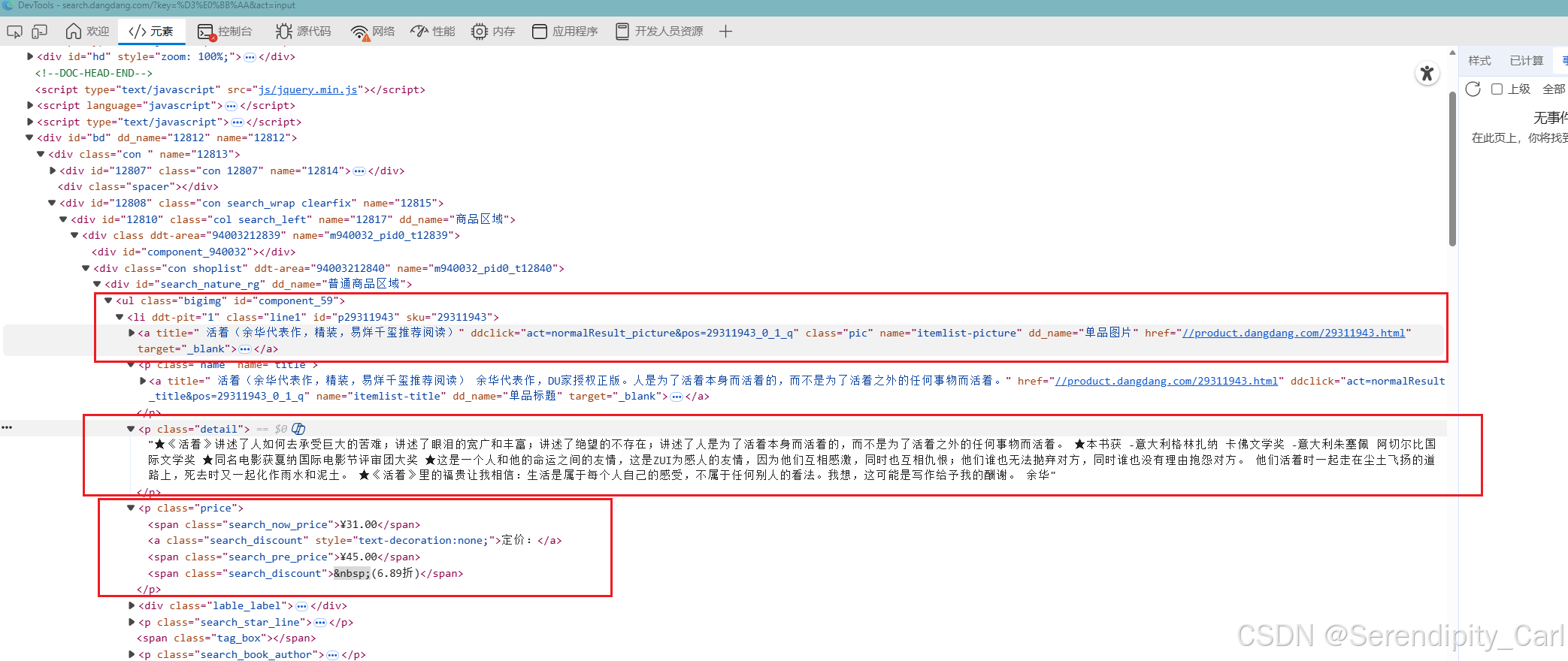
用开发者工具面板中的左上角箭头去选择爬取的数据 点击即可看到 html结构
- 书名:直接找 class属性为pic 的a标签 提取里面的title属性
- 价格:找class属性为price的p标签 下面的第一个span标签 提取里面的文本
- 评论:在class属性为detail的p标签 提取里面的文字
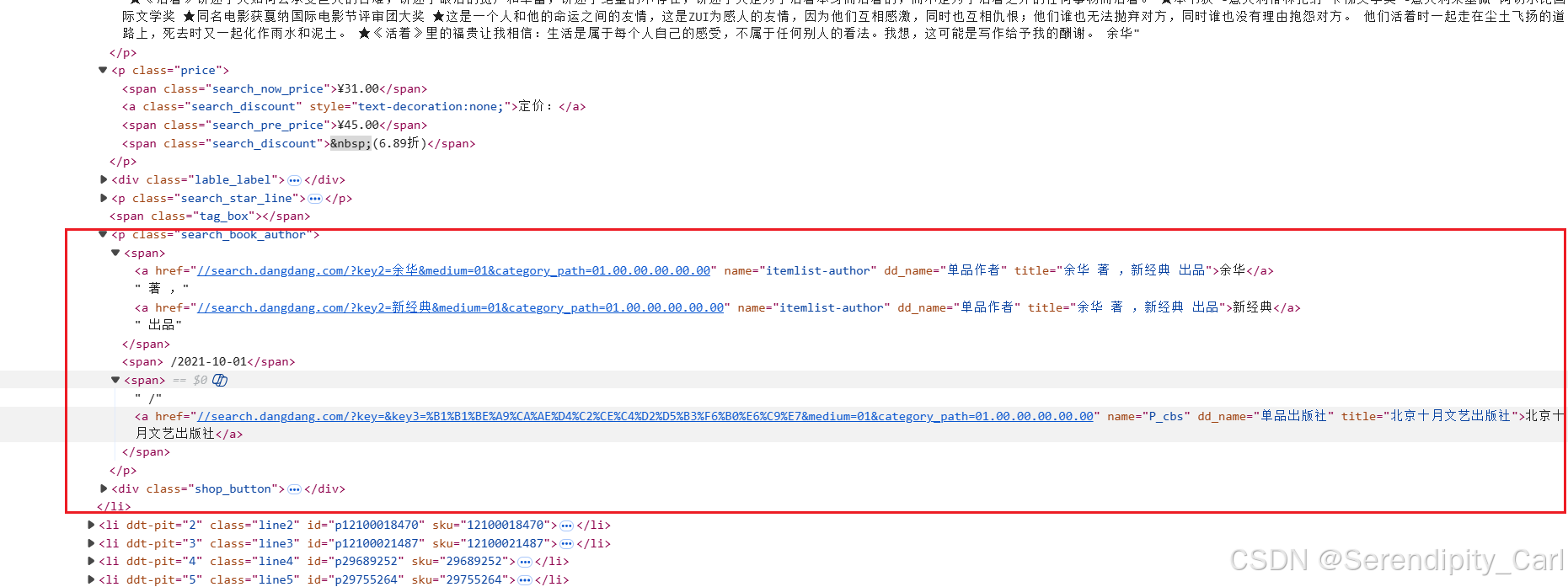
- 作者:找到对应的class属性 下面第一个span标签 中的第一个a标签中的文本
- 时间:对应class属性 第二个span 标签里头的文本
- 出版社:对应class属性 下的第三个span标签 下面的第一个a标签中的文本
到此 这个数据所在的结构以及分析完了 还是很简单的 就是有点费眼睛
现在可以开始写代码了
温馨提示: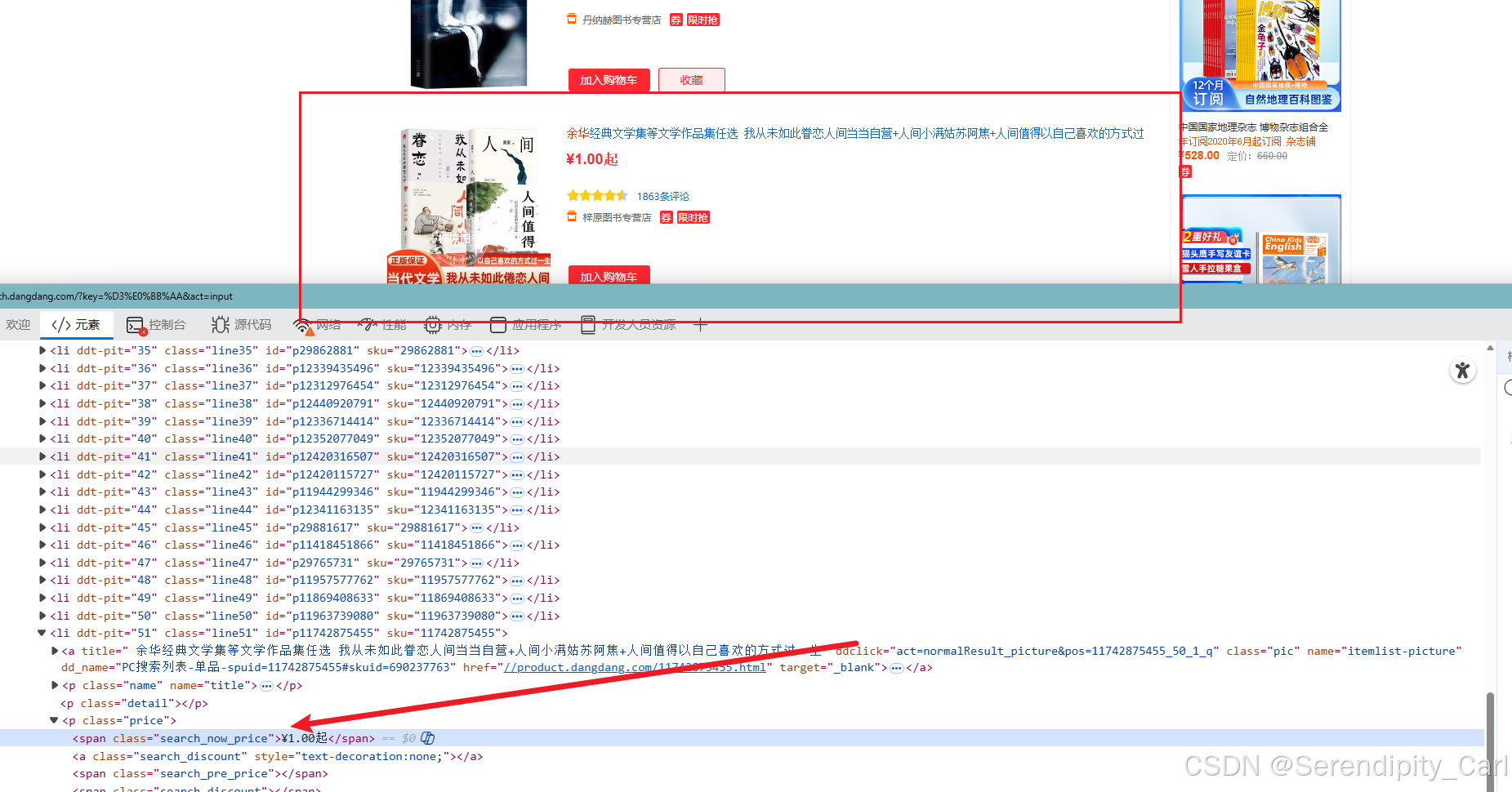
在取price价格的时候 之前我们定位的classs属性找不到 为空
个别会在 search_now_price 这个属性中 需要写个判断
# 今天我们写个函数 来爬取数据
# 参数传入url 其它照写不误
def get_data(url):
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0',
}
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
# 拿到包含所有书籍信息的li标签
lis = html.xpath('//div[@id="search_nature_rg"]/ul[@class="bigimg"]//li')
data = []
# 循环 提取当中的数据
for li in lis:
# 提取出来的数据 转换成str格式 使用对应的strip方法去除其中的空格
name = ''.join(li.xpath('./a[@class="pic"]/@title')).strip()
price = ''.join(li.xpath('.//p[@class="price"]/span[1]/text()'))
# 有的字段 会出现没有的情况 这时候我们需要做个判断 如果得到的数据为空 则执行另外一个逻辑
if not price:
price = ''.join(li.xpath('.//span[@class="search_now_price"]/text()'))
comment = ''.join(li.xpath('.//p[@class="detail"]/text()'))
# 没有评论则赋值 暂无评论 以下类似
if not comment:
comment = '暂无评论'
author = ''.join(li.xpath('.//p[@class="search_book_author"]/span[1]/a[1]/text()'))
if not author:
author = '暂无作者'
# 时间取出来 会发现前面都有个/ 我们可以通过字符串的替换方法将其替换为空
time = ''.join(li.xpath('.//p[@class="search_book_author"]/span[2]/text()')).replace('/', '')
if not time:
time = '暂无出版时间'
publisher = ''.join(li.xpath('.//p[@class="search_book_author"]/span[3]/a[1]/text()'))
if not publisher:
publisher = '暂无出版社'
# 最后我们打印出 字段名 确认返回的数据准确无误
# 保存数据 将数据存储到字典中 键值对的方式
dit = {
"name": name,
"author": author,
"price": price,
"time": time,
"publisher": publisher,
"comment": comment
}
# 在循环之前 定义一个列表 将字典存到列表中
data.append(dit)
# 最后将保存的数据返回出去
return data到此 获取数据 存储数据的代码就写完了
三.保存数据到本地
需求是 通过作者名字和页码来保存为excel文件 余华为一个文件夹 里面存储的是每一页的书籍数据
例如: 余华 --> 余华_1 余华_2
然后用户可以在终端输入 书籍的作者 即可爬取相对应的数据信息
例如: 输入 莫言 就爬取莫言相关的书籍信息
写一个main函数
def main():
# python中创建文件夹的模块 需要导入re模块
# 如果不存在该作者的文件夹 就创建
if not os.path.exists(f'{author}'):
os.makedirs(f'{author}')
author_in = quote(author, encoding='gbk')
# 采集前十页的数据 当然 你们也可以定制 想采集多少输入即可
for i in range(1, 11):
# 调用之前的函数 将Url地址中的参数用字符串模板替换一下
result = get_data(f'https://search.dangdang.com/?key={author_in}&act=input&page_index={i}')
# 保存数据 将之前函数返回的列表数据 通过Pandas 保存为excel文件
# 将result列表 转换成 DataFrme 二维数据 保存到当前目录中author文件夹中 不使用额外的索引
pd.DataFrame(result).to_excel(f'./{author}/{author}_{i}.xlsx', index=False)
# 来个交互信息展示 可以看得更加清楚些
print(f'第{i}页数据爬取完毕')Explain:
![]()
可以注意到浏览器地址栏中的作者格式是这种编码 我们需要将将中文转换成%形式
URL编码(百分号编码) 常用于Url参数传递 会将非ASCII字符转换为%xx 形式 (xx是字符在指定编码下的十六进制值)
from urllib.parse import quote
chinese_str = '余华'
# 指定为gbk编码
encode_str = quote(chinese_str,encoding='gbk')#常见编码:GBK、GB2312、UTF-8
# 使用不同的编码会返回不同的结果 自己可以查看 当前网页采用的是什么编码
# 在标头信息中 或者都试一下 看哪个和请求的url相匹配
最后写个程序的入口即可
if __name__ == '__main__':
main()这个案例就结束啦 案例源码附下 供大家学习交流使用
import requests
from lxml import etree
import pandas as pd
import os
from urllib.parse import quote
def get_data(url):
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0',
}
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
lis = html.xpath('//div[@id="search_nature_rg"]/ul[@class="bigimg"]//li')
data = []
for li in lis:
name = ''.join(li.xpath('./a[@class="pic"]/@title')).strip()
price = ''.join(li.xpath('.//p[@class="price"]/span[1]/text()'))
if not price:
price = ''.join(li.xpath('.//span[@class="search_now_price"]/text()'))
comment = ''.join(li.xpath('.//p[@class="detail"]/text()'))
if not comment:
comment = '暂无评论'
author = ''.join(li.xpath('.//p[@class="search_book_author"]/span[1]/a[1]/text()'))
if not author:
author = '暂无作者'
time = ''.join(li.xpath('.//p[@class="search_book_author"]/span[2]/text()')).replace('/', '')
if not time:
time = '暂无出版时间'
publisher = ''.join(li.xpath('.//p[@class="search_book_author"]/span[3]/a[1]/text()'))
if not publisher:
publisher = '暂无出版社'
dit = {
"name": name,
"author": author,
"price": price,
"time": time,
"publisher": publisher,
"comment": comment
}
data.append(dit)
return data
def main():
author = input('请输入你想要爬取书籍的作者:')
# 如果不存在该作者的文件夹 就创建
if not os.path.exists(f'{author}'):
os.makedirs(f'{author}')
author_in = quote(author, encoding='gbk')
for i in range(1, 11):
result = get_data(f'https://search.dangdang.com/?key={author_in}&act=input&page_index={i}')
pd.DataFrame(result).to_excel(f'./{author}/{author}_{i}.xlsx', index=False)
print(f'第{i}页数据爬取完毕')
if __name__ == '__main__':
main()爬取的内容如下 (部分)


本次的案例分析就到此结束啦 谢谢大家的观看 你的点赞和关注是我更新的最大动力
如果感兴趣的话可以看看我之前的博客
主包也会不断学习进步 给大家带来更加优质的文章 详细的教程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号