
【强化学习】 REINFORCE 算法 - 教程
REINFORCE 算法
策略梯度法中,一个主要问题是:采用了不相关的奖励信息。在PG计算梯度时,启用了总回报G(τ)G(\tau)G(τ)作为权重,它包含了整个轨迹的回报(也就是说,站在时刻 t 的视角去看,这个总回报既包含了时刻 t 之前的奖励,也具备了时刻t之后的奖励),实际上,在评估当前动作的时候,只需要关注从这一动作开始直到轨迹结束的“后续表现”(也叫 “rewards to go”),即当前以及未来的奖励,而不应该考虑过去的奖励 。
为了应对这个问题,REINFORCE 算法使用 GtG_tGt 来代替 G(τ)G(\tau)G(τ)作为权重。 表示从当前时刻 t 到轨迹结束的总回报,也就是只要「现在」和「未来」,不要「过去」:
Gt=∑k=tTγk−trkG_t= \sum_{k=t}^T \gamma^{k-t} r_kGt=∑k=tTγk−trk表示从时刻 t 开始的累积折扣回报, $ r_k$ 表示在时刻 k 的奖励(初始化为 t ),γ\gammaγ表示折扣率 。( 对比G(τ)=∑t=0TγtrtG(\tau)=\sum_{t=0}^T \gamma^t r_tG(τ)=∑t=0Tγtrt 理解)
这样一来,启用GtG_tGt作为权重许可更准确地估计策略梯度。REINFORCE 算法的梯度计算公式如下: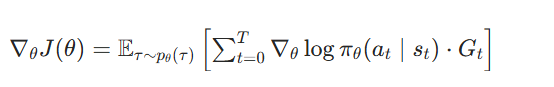
带基线(Baseline)的REINFORCE 算法
借助就是REINFORCE 算法通过用“rewards to go”代替轨迹整体回报改进了PG,但由于强化学习采样轨迹来计算策略梯度的,但这种梯度计算方法往往具有较高的方差,意味着每次采样得到的梯度值差异可能很大,会影响策略更新的稳定性和收敛速度 。
方差较高的原因:
- 智能体每次与环境交互产生的轨迹具体多样性和随机性
- 策略更新后,策略的微小变化可能会导致生成的轨迹发生很大改变
为了减少方差,能够引入基线(Baseline)。核心思想是,为每一步的“后续奖励”减去一个基准值,在数学上表示为b,即参考线,它不一定是一个常数,更多时候是状态sts_{t}st的一个函数。这个参考线的实际意义是当前的状态下回报奖励的期望,那么超出期望(Baseline)的部分就是优势(Advantage)。在实际训练中,大家会用优势代替原来的“后续奖励”进行梯度估计,以减小方差。具体来说,利用Gt−b(st)G_t-b(s_t)Gt−b(st) 来代替 GtG_tGt作为权重,其中b(st)b(s_t)b(st) 是当前状态 sts_tst 的基线值。
带基线的REINFORCE的梯度计算公式如下: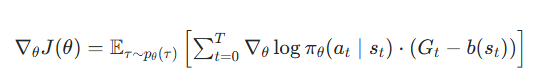
那么当前状态sts_tst 的基线值 b(st)b(s_t)b(st) 如何计算?
“rewards to go” 即当前动作之后的奖励在强化学习中被称为Q 函数(动作价值函数)Qπ(s,a)Q^\pi(s,a)Qπ(s,a),即在状态 s 采取动作 a 后,未来能获得的累积奖励期望。(即上面的GtG_tGt )
当前状态 sts_tst 的基线值 b(st)b(s_t)b(st) 通常通过状态价值函数Vπ(s)V^\pi(s)Vπ(s)表示,状态价值函数Vπ(s)V^\pi(s)Vπ(s)指的是“状态 s 下的未来累积折扣回报期望”(基准值),可以被认为是对当前状态下「好坏」程度的评估 。Vπ(s)V^\pi(s)Vπ(s)通常由一个网络估计出来(如用一个神经网络(价值模型)拟合Vπ(s)V^\pi(s)Vπ(s),并与策略模型联合训练)
通过动作价值函数Qπ(s,a)Q^\pi(s,a)Qπ(s,a)减去状态价值函数Vπ(s)V^\pi(s)Vπ(s), 我们得到优势函数:Aπ(s,a)=Qπ(s,a)−Vπ(s)A^\pi(s,a) = Q^\pi(s,a) - V^\pi(s)Aπ(s,a)=Qπ(s,a)−Vπ(s), 具体的含义是在某个状态 s 下,选择某个动作 a 相比于平均走法能提升多少胜率。倘若这个动作带来的预期回报Qπ(s,a)Q^\pi(s,a)Qπ(s,a)远高于当前状态的基准水平Vπ(s)V^\pi(s)Vπ(s)相对的好,即相对优势。就是,那么这个动作的优势就是正的,说明它非常值得采用;反之,则说明不如平均水平。优势函数在意的不是绝对的好,而

 浙公网安备 33010602011771号
浙公网安备 33010602011771号