
【普通解法】从左到右遍历str1的每一个字符,然后看如果 以当前字符作为第一个字符出发 是否匹配 str2字符串。
【KMP算法】
1)生成一个nextArr数组,长度与str2字符串长度一样。i 的 值 含义是 str[0 - i-1】中,必须以str[i-1] 结尾的后缀子串 与 必须以 str[0]开头的前缀子串,最大匹配长度是多少。
快速生成 nextArr数组,先等等
2)

假设 str1 从 i 到 j - 1 和 str2 从 0 到 j-1一样。从j不一样了。
然后str2的索引退回到 t2 索引 继续 和 str1的 j匹配。 圆圈就代表 最长前缀子串。
str1 索引不回退,是因为 中间其他位置不可能再完全匹配 str2了。
使用反证法:
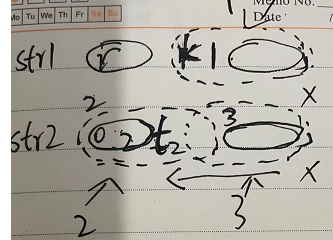
假设str1 能从 k开始能够完全 匹配 str2. 看虚线部分。
说明 虚线1 和 虚线2 一样。
又因为str1 和 str2 从 0 到 j-1 一样。说明 虚线 1 和 虚线 3 一样。
那么 虚线2 和虚线3 一样,那么最长前缀子串 就不是咱开始的了。
如果咱的最长子串 算的是对的,那么 str1索引从j开始就没问题。
【nextArr数组生成】

1)从左到右依次求解。
在 求解到 i的时候, 0 到 i-1的值已经求出来了。
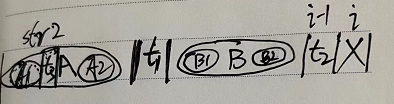
计算i的时候,已经知道i-1的最长前缀 A 和 最长后缀 B的匹配区域, A=B
然后判断 A区域下一个 t1位置的值 和B区域下一个 t2位置 的 值 ,也就是 i-1位置的值,俩个是否相等。
如果相等: 那么 nextArr[i] 的值就是 nextArr[i-1]的值加1.

如果不相等: 那么继续往回跳。看t1字符之前的 前缀 和 后缀的匹配情况。 判断 t3 和 t2是否相等。
A 和 B相等,t1的前缀 A1 和 t1的后缀 A2相等, A1=A2
A=B。 B1=B2 .那么 A1=B2.
直到 t1的最长前后缀为0 结束。开始下一个位置的计算。
java实现:
public class KMP {
public static int getIndexOf(String str1, String str2) {
if (str1 == null || str2 == null || str2.length() < 1 || str1.length() < str2.length()) {
return -1;
}
char[] str1_arr = str1.toCharArray();
char[] str2_arr = str2.toCharArray();
int str1_length = str1_arr.length;
int str2_length = str2_arr.length;
int[] nextArr = getNextArr(str2);
int str1_index = 0;
int str2_index = 0;
// 循环终止条件。 str1_index 越界 或者 str2_index 越界
// str1_index 越界,str2_index没越界,说明没匹配到
// str1_index 不越界,str2_index 越界, 说明匹配到了
// str1_index 和 str2_index一起越界。 也匹配到了。
while (str1_index < str1_length && str2_index < str2_length) {
if (str1_arr[str1_index] == str2_arr[str2_index]) {
// 一样。都向右走
str1_index++;
str2_index++;
} else if (nextArr[str2_index] == -1) {
// 说明 str2 往回退到 起点了。 等价 str2_index == 0
// str1 继续往右走就好。
str1_index++;
} else {
// str2 指针往回退, nextArr[str2_index]
str2_index = nextArr[str2_index];
}
}
// 如果str_length == str2_index ,说明匹配到了。
// str1_index - str2_index 就是 匹配到的起始位置。
return str2_length == str2_index ? str1_index - str2_index : -1;
}
public static int[] getNextArr(String str) {
char[] str_arr = str.toCharArray();
if (str_arr.length == 1) {
return new int[] { -1 };
}
int[] nextArr = new int[str_arr.length];
nextArr[0] = -1; // 起始位置 记为 -1.好判断。
nextArr[1] = 0; // 1 的前缀后缀不存在,所以是0
int current_index = 2; // 从2 开始
int pre_pos_value = 0; // 保存当前的最长前缀 后缀的长度。开始从2 计算。nextArr[1] 就是0 。
while (current_index < str_arr.length) {
if (str_arr[current_index - 1] == str_arr[pre_pos_value]) {
// 比较的字符不相等,比较的后一个字符永远是 current_index -1 的位置
nextArr[current_index] = pre_pos_value + 1; // t1 和 t2 的值相等。那么 current_index就是前面 的nextArr[]值 + 1
current_index++; // 继续下一个。
} else if (pre_pos_value > 0) {
// 比较的字符不相等,比较的后一个字符永远是 current_index -1 的位置
// 比较的字符不相等,那么就看 t1 的 pre_pos_value. pre_pos_value 是从0开始的。这个是个很重要的信息。是长度,也是索引。
// A1区域的最长前缀 后缀 不为 0 。
pre_pos_value = nextArr[pre_pos_value];
} else {
// 比较的字符不相等,比较的后一个字符永远是 current_index -1 的位置
// 往回跳,A1区域的最长前缀 后缀 已经为 0 。。不存在最长前后缀了。
nextArr[current_index] = 0;
// 然后可以计算下一个了
current_index++;
}
}
return nextArr;
}
public static void main(String[] args) {
String str = "abcabcababaccc";
String match = "ababa";
System.out.println(getIndexOf(str, match));
}
}
明天再用python实现吧。
python 忘记 对 最长前后缀 增加 1 了。
python 初始化数组之后,使用append新增。
# coding: utf-8
def kmp(str1, str2):
str1_index = 0
str2_index = 0
next_arr = get_next_arr(str2)
print(f"next_arr{next_arr}")
while str1_index < len(str1) and str2_index < len(str2):
if str1[str1_index] == str2[str2_index]:
# 字符一样
str1_index += 1
str2_index += 1
elif next_arr[str2_index] == -1:
# str2往回跳到 位置0 了
str1_index += 1
else:
str2_index = next_arr[str2_index]
print(str2_index)
print(str1_index)
if str2_index == len(str2):
return str1_index - str2_index
else:
return -1
def get_next_arr(str2):
next_arr = [-1, 0]
cur_index = 2
pre_pos_value = 0
while cur_index < len(str2):
if str2[cur_index-1] == str2[pre_pos_value]:
# t1 == t2
next_arr.append(pre_pos_value + 1)
cur_index += 1
pre_pos_value += 1 # 忘记对pre_pos_value进行增加了。
elif pre_pos_value > 0:
# t1往回跳
pre_pos_value = next_arr[pre_pos_value]
else:
# 最长前缀为0.
next_arr.append(0)
cur_index += 1
return next_arr
str1 = "abcabcababaccc"
str2 = "ababa"
print(kmp(str1,str2))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号