
简单累计功能
Series sum() 返回一个 统计值
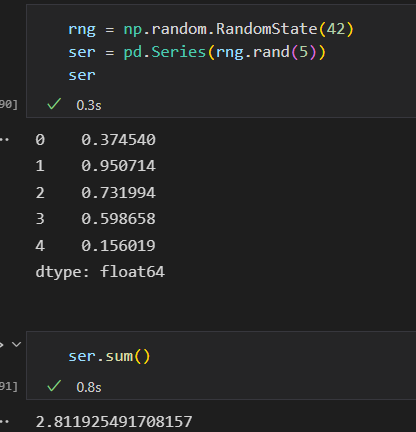
DataFrame sum。默认对每列进行统计
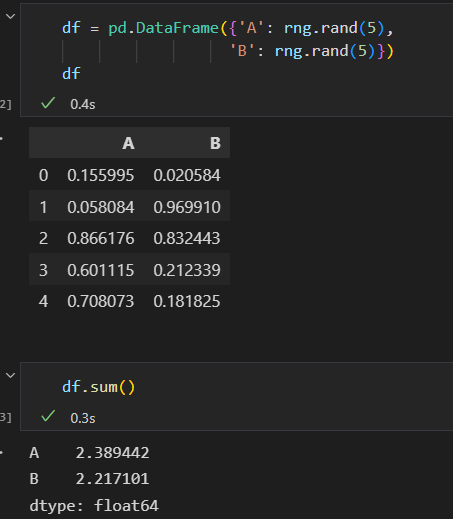
设置axis参数,对每一行 进行统计
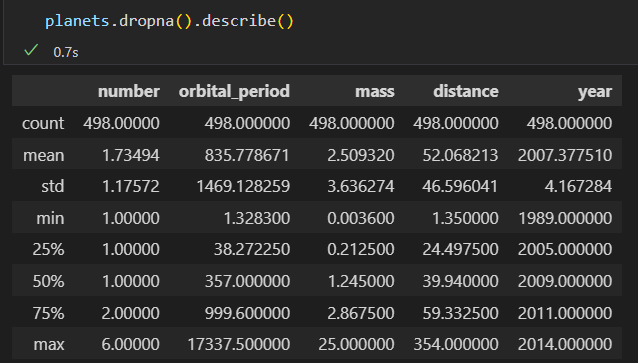
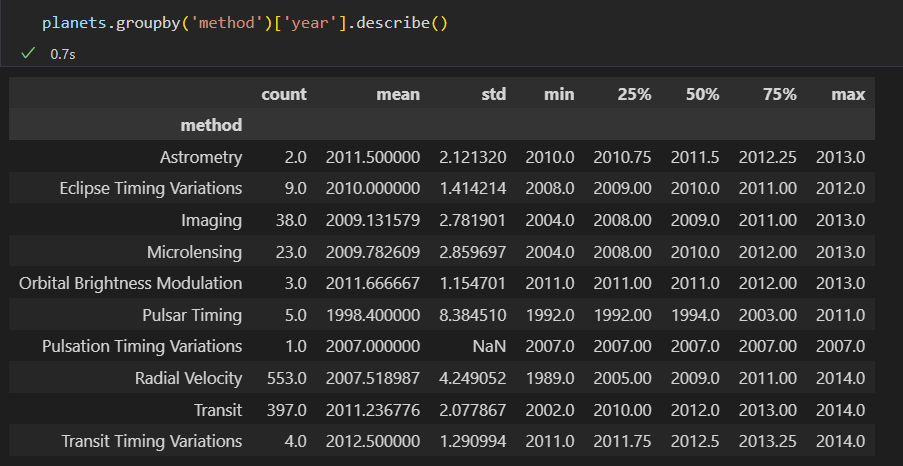
describe()可以计算每一列的若干常用统计值。
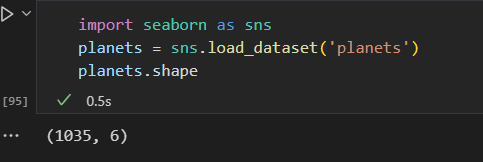
获取seaborn planets数据
github: https://github.com/mwaskom/seaborn-data.git
windows: 放在用户目录下(在线下载卡。超时。)
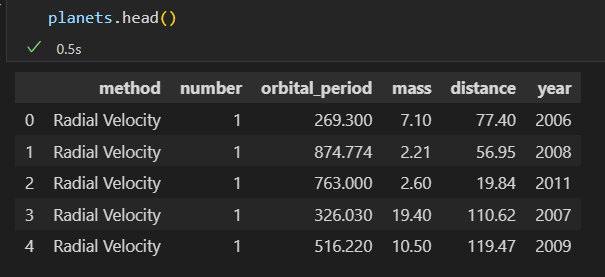
dropna()丢弃有缺失值的行。
Pandas累计方法
| Aggregation | Description |
|---|---|
| count() | Total number of items |
| first(), last() | First and last item |
| mean(), median() | Mean and median |
| min(), max() | Minimum and maximum |
| std(), var() | Standard deviation and variance |
| mad() | Mean absolute deviation |
| prod() | Product of all items |
| sum() | Sum of all items |
Groupy: 分割、应用和组合
split、 apply、combine
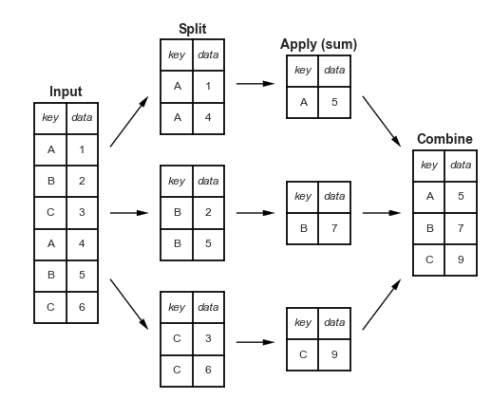
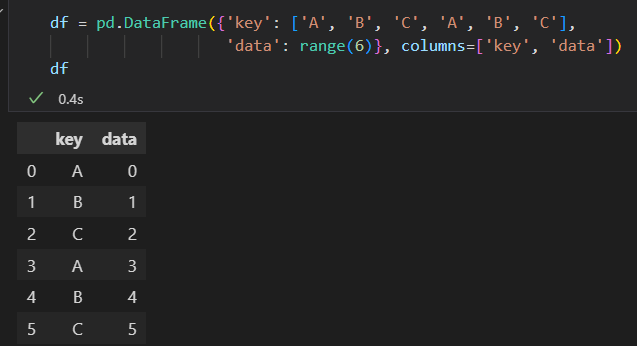
groupby()方法传递参数列名。返回值是个DataFrameGroupBy对象。

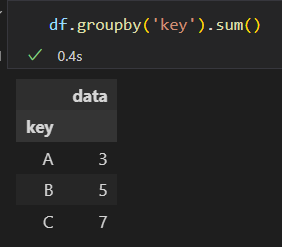
GroupBy对象。
可以看成是DataFrame的集合。
常用的操作:aggregate(累计)、filter(过滤)、transform(转换)、apply(应用)
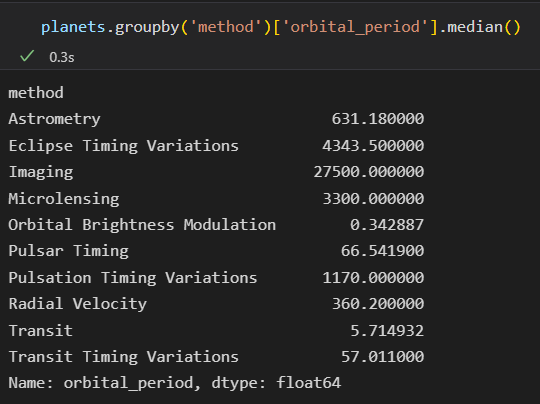
1)按列取值
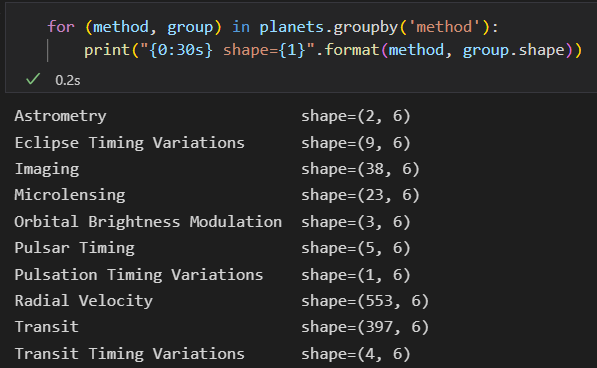
2)按组迭代,返回的每一组都是Series 或 DataFrame
3) 调用方法
累计 过滤 转换 应用
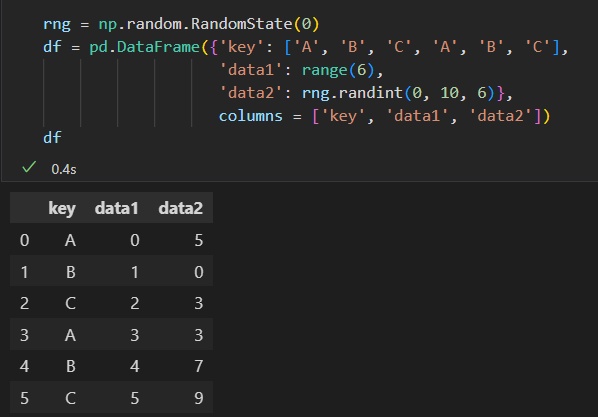
1)累计 aggregate
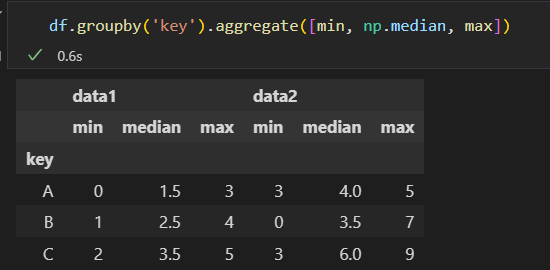
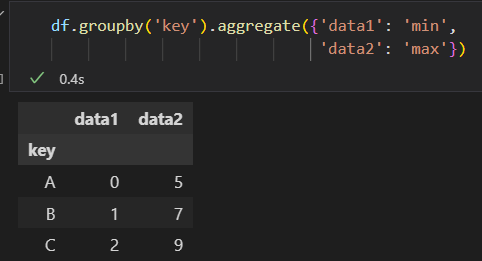
2) 过滤 filter
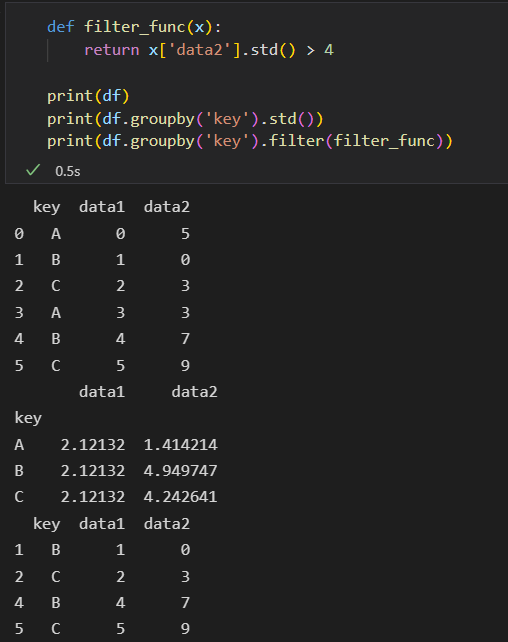
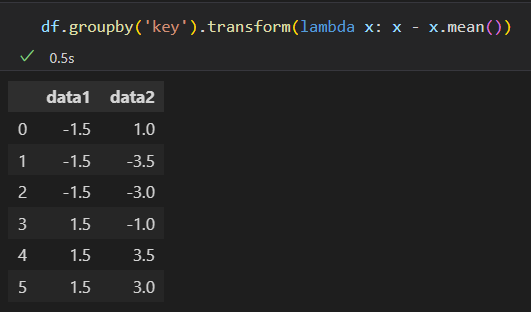
- 转换 transform
累计操作 对组内全量数据缩减的结果。 而 转换 操作 会返回一个新的全量数据
![]()
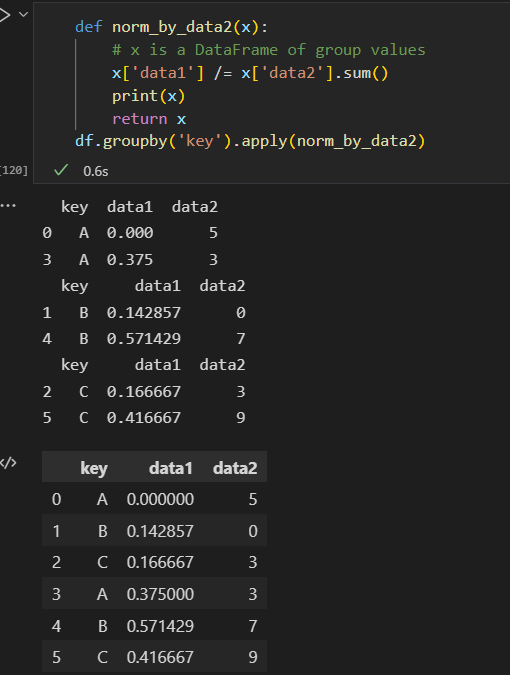
4)apply()
输入一个DataFrame 对象,f返回一个Pandas对象 或 单个数值。 组合操作会 适应返回结果类型。
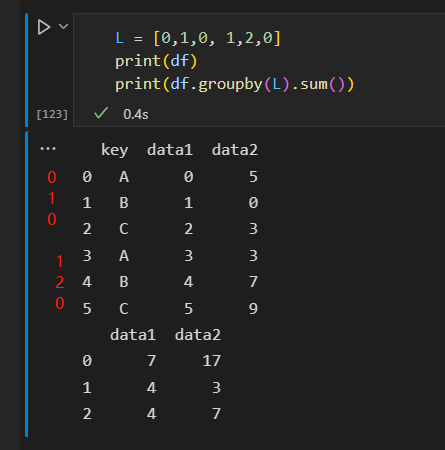
设置分割的键
1)将列表、数组、Series或 索引作为分组键
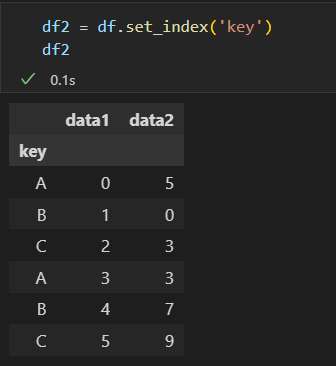
2)用字典或 Series将索引 映射到 分组名称
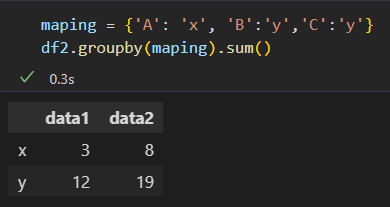
3)任意python函数,函数映射到索引
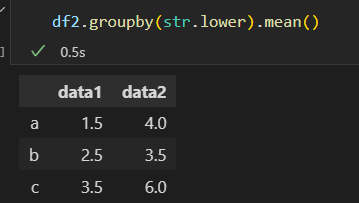
分组案例
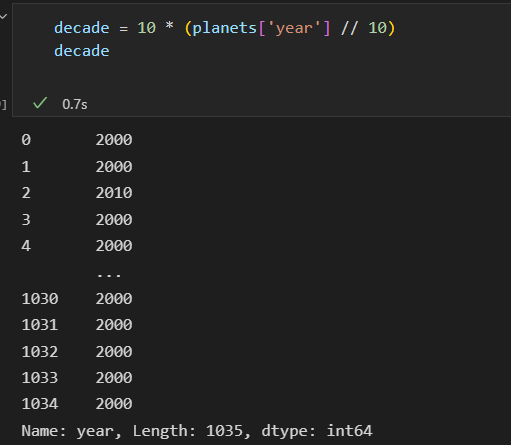
以十年为一个时间段。
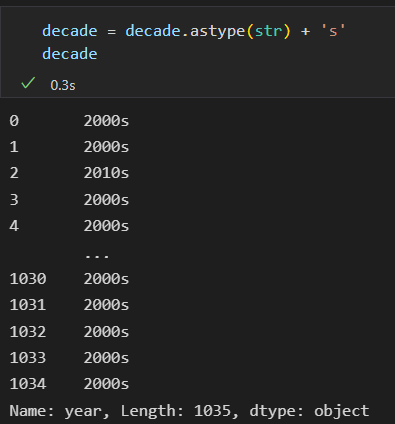
加上s
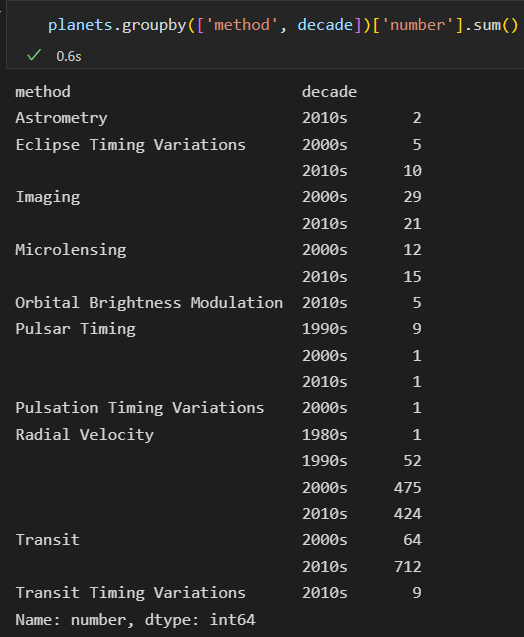
这里 groupby 俩个值。懵逼了。
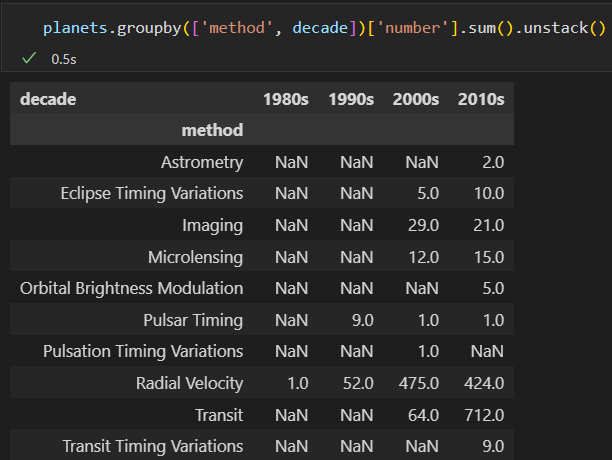
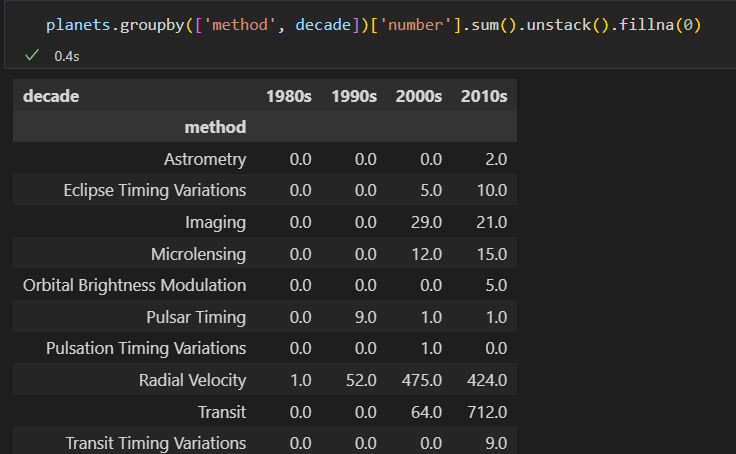
数据透视表
groupby 是探索数据内部的关联性 。
数据透视表: pivottable 是一种类似的操作方法。常见与Excel与类似的表格 应用中。
数据透视表 将每一列 数据作为输入, 输出将数据不断细分 成多个维度累计信息的 二维数据表。
是多维的GroupBy累计操作。
泰坦尼克号 乘客 数据
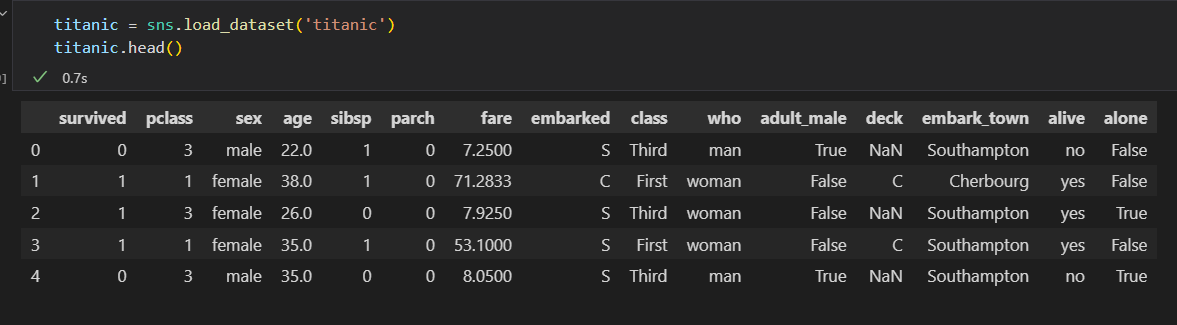
1)按照性别 、最终生还状态 进行分组
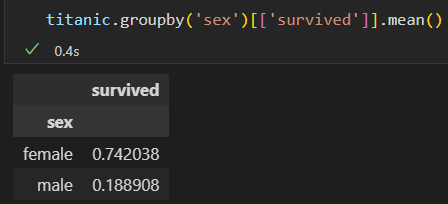
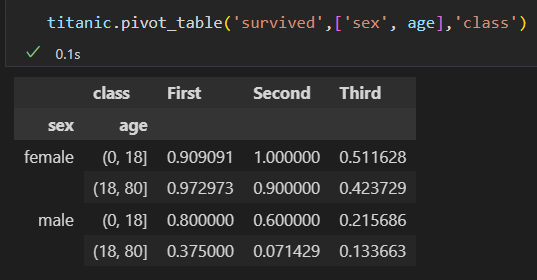
2)进一步 探索,不同性别与船舱 等级的生还情况。
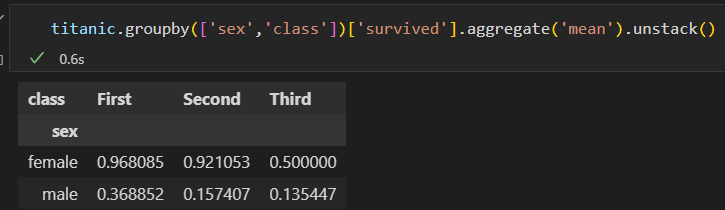
3)上面这个是不是感觉很复杂。使用pivot_table 就会简单
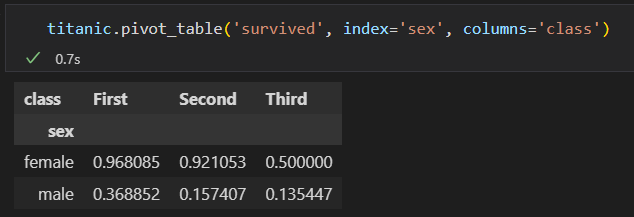
一等舱的女性 生还率最高。 三等舱的生还率 最低
好好努力
4)再把年龄也加进去。 多级数据透视表
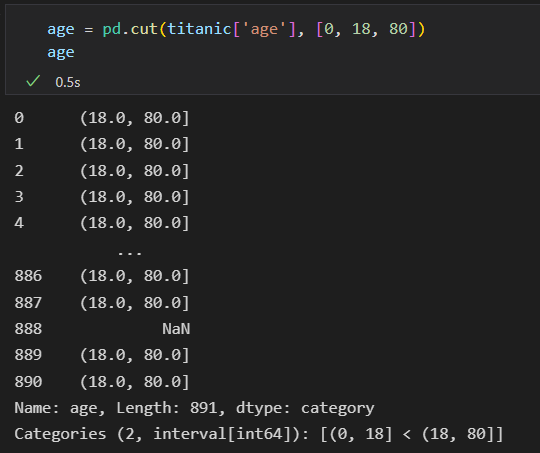
5)其他选项


 浙公网安备 33010602011771号
浙公网安备 33010602011771号