
第一题
核心代码与运行结果:
点击查看代码
import requests
from bs4 import BeautifulSoup
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
resp = requests.get(url)
resp.encoding = resp.apparent_encoding
html = resp.text
soup = BeautifulSoup(html, 'html.parser')
# 找到表格主体
tbody = soup.find('tbody')
# 获取所有行
tr_list = tbody.find_all('tr')
# 存储数据
data = []
for tr in tr_list:
# 获取行中的所有单元格
td_list = tr.find_all('td')
# 检查是否有足够的单元格
if len(td_list) < 5:
continue
# 提取排名信息
rank_div = td_list[0].find('div')
rank = rank_div.get_text().strip() if rank_div else ""
# 提取学校名称
name_span = td_list[1].find('span', class_='name-cn')
name = name_span.get_text().strip() if name_span else ""
# 提取省份信息
province = td_list[2].get_text().strip()
# 提取学校类型
school_type = td_list[3].get_text().strip()
# 提取总分
total_score = td_list[4].get_text().strip()
# 确保所有字段都有值后添加到数据列表
if all([rank, name, province, school_type, total_score]):
data.append({
'rank': rank,
'name': name,
'province': province,
'type': school_type,
'score': total_score
})
# 打印表头和数据
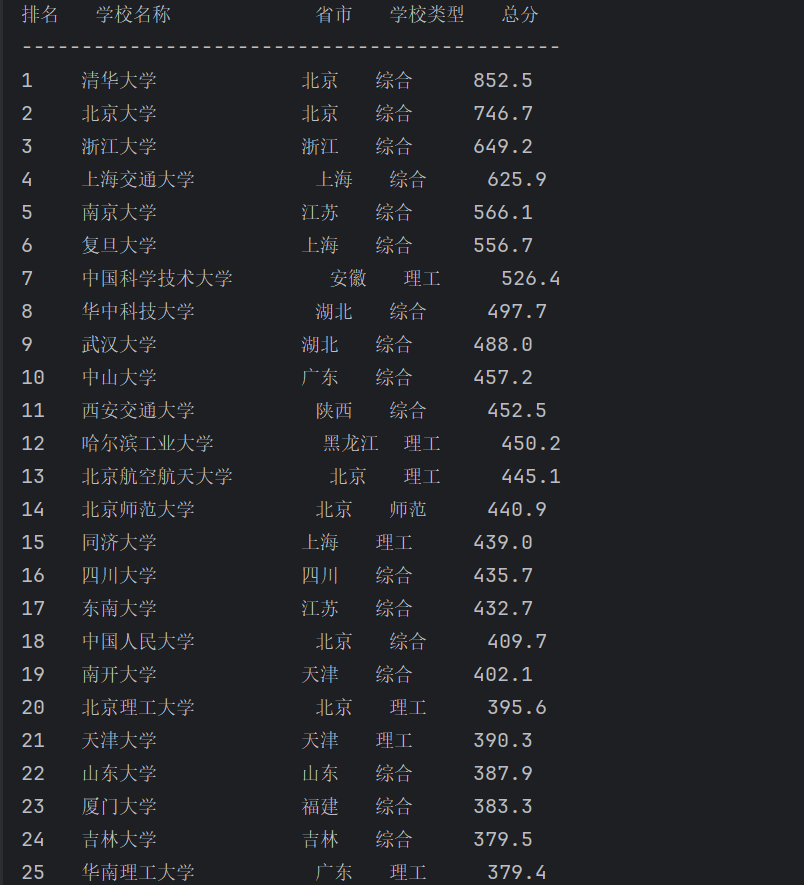
print(f"{'排名':<4} {'学校名称':<15} {'省市':<4} {'学校类型':<6} {'总分':<4}")
print("-" * 45)
for row in data:
print(f"{row['rank']:<4} {row['name']:<15} {row['province']:<4} {row['type']:<6} {row['score']:<4}")

心得体会:
对要爬取的数据检查就可以很快速地定位到主体表格,最主要的就是找到网页编写html的规律,这样就可以很快速地了解每个排名数据的提取方法
第二题
核心代码与运行结果:
点击查看代码
import re
import requests
import html
url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab"
resp = requests.get(url)
resp.encoding = "gbk"
html_text = resp.text
# 存储数据
data = []
# 匹配商品列表的ul标签
ul = r'<ul[^>]*id="component_59"[^>]*>(.*?)</ul>'
ul_match = re.search(ul, html_text, re.S)
if ul_match:
ul_note = ul_match.group(1) # 获取ul标签内的内容
# 匹配ul中的所有li标签(商品项)
li_ = r'<li[^>]*id="\d+"[^>]*>(.*?)</li>'
li_list = re.findall(li_, ul_note, re.S)
# 遍历每个商品项
for li_each in li_list:
# 提取商品名称
name_match = re.search(r'<a[^>]*title="([^"]*)"[^>]*name="itemlist-title"', li_each, re.S)
name = name_match.group(1).strip() if name_match else ""
# 提取商品价格
price_match = re.search(r'<span class="price_n">\s*(.*?)\s*</span>', li_each, re.S)
price = price_match.group(1).strip() if price_match else ""
# 将¥转换为¥
price = html.unescape(price)
if all([price, name]):
data.append({
'price': price,
'name': name
})
print(f"\n最终提取到 {len(data)} 个商品")
for row in data:
print(f"{row['price']:<10} {row['name']:<30}")


心得体会:
定位的方法和第一题相同,但是要使用正则表达式匹配还是得写得精确一点,不然很容易匹配到犄角旮旯里去,导致爬取失败
第三题
核心代码与运行结果:
点击查看代码
import urllib.request
import re
import os
import time
from urllib.parse import urljoin, urlparse
def get_page_content(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req, timeout=10)
html_content = resp.read().decode('utf-8')
return html_content
except Exception as e:
print(f"获取页面失败: {e}")
return None
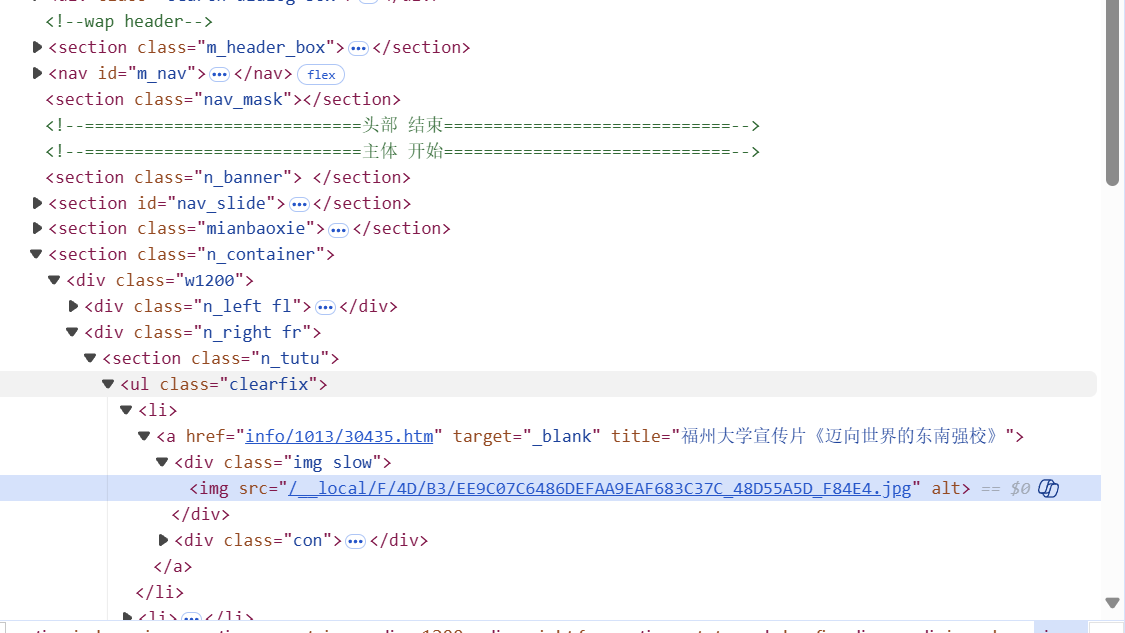
def get_image_urls(html_content, page_url):
# 匹配img标签中的src属性
img_pattern = r'<img[^>]+src="([^">]+)"'
img_urls = re.findall(img_pattern, html_content, re.I)
# 匹配CSS背景图片
css_pattern = r'background-image:\s*url\([\'"]?([^\'"\)]+)[\'"]?\)'
css_urls = re.findall(css_pattern, html_content, re.I)
# 合并所有图片URL
all_urls = img_urls + css_urls
valid_image_urls = []
# 将相对路径转换为绝对路径
for img_url in all_urls:
full_url = urljoin(page_url, img_url)
valid_image_urls.append(full_url)
return valid_image_urls
def download_image(img_url, download_folder):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://news.fzu.edu.cn/'
}
# 请求图片
req = urllib.request.Request(img_url, headers=headers)
response = urllib.request.urlopen(req, timeout=10)
img_data = response.read()
# 从URL中提取文件名
filename = os.path.basename(urlparse(img_url).path)
if not filename:
filename = f"image_{int(time.time())}.jpg"
filepath = os.path.join(download_folder, filename)
with open(filepath, 'wb') as f:
f.write(img_data)
print(f"下载成功: {filename}")
return True
except Exception as e:
print(f"下载失败: {e}")
return False
def main():
url = "https://news.fzu.edu.cn/yxfd.htm"
download_folder = "fzu_images"
if not os.path.exists(download_folder):
os.makedirs(download_folder)
html_content = get_page_content(url)
if not html_content:
return
image_urls = get_image_urls(html_content, url)
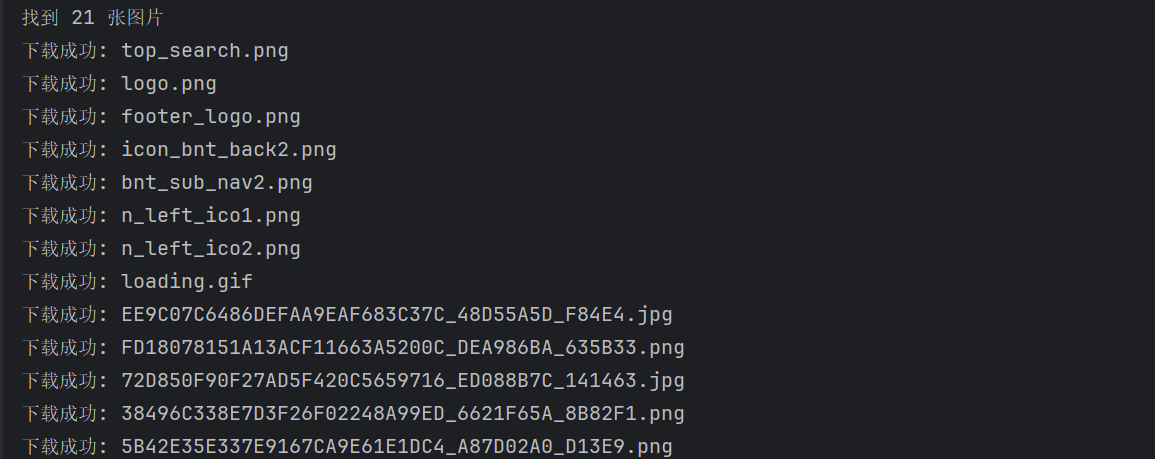
print(f"找到 {len(image_urls)} 张图片")
# 下载图片
downloaded_count = 0
for img_url in image_urls:
if download_image(img_url, download_folder):
downloaded_count += 1
time.sleep(0.5)
print(f"下载完成! 共下载 {downloaded_count} 张图片")
if __name__ == "__main__":
main()

心得体会:
基本步骤都相差无几,主要难点就是从html里提取到图片的链接,可以通过元素面板搜索页面内的img标签,再提取其url就可以下载,css背景图也是同一个道理
Gitee仓库路径:
https://gitee.com/wudilecl/2025_crawl

 浙公网安备 33010602011771号
浙公网安备 33010602011771号