配合灯塔+subfinder搭建自动化信息收集系统
官方的项目库在2024年已经删库了,所以首先选择下面这个地址的ARL项目
https://github.com/huntingsec/ARL-Limited-Edition
在原项目的基础上,增加了指纹库,以及子域和目录的爆破字典。
一、选择购买vps
我建议搭建在vps服务器上面,不会混淆自己的本地环境,而且可以24小时不间断扫描
- ARL灯塔等工具的硬件要求
- ARL灯塔:官方推荐至少 2核4G内存(轻量级扫描可勉强用1核1G,但可能卡顿)。
- 其他自动化工具(如Xray、Nuclei、爬虫等):1G内存运行多个工具时会吃紧,尤其是处理大量数据时。
- 硬盘50G:足够存放工具和少量扫描结果(但长期运行需定期清理日志)。
- 2M带宽:
- 对ARL的主动扫描影响不大(扫描速度较慢但能用)。
- 如果用于代理或下载数据(如爬虫),2M带宽会明显受限。
- 个人使用场景
-
轻度使用(偶尔扫描少量目标):勉强够用,但体验较差(内存易爆,扫描慢)。
-
中高频使用(长期挂机/多任务):配置不足,建议升级到 2核2G/4G内存。
-
我这里购买的是华为云的Flexus 应用服务器 L 实例 这个性价比高
https://activity.huaweicloud.com/discount_area_v5/index.html
-
用这个来搭建信息收集系统是够了,但是如果还想要搭建nuclei等漏洞扫描器就不够了,需要至少2核4G,不然会很卡。
-
我买的是ubuntu22.04,区域选一个离你较近的就可以了。

-
购买好了以后,找到控制台
-
在管理控制台左上角单击,选择区域和项目。
-
在页面左上角单击图标,打开服务列表,选择“网络 > 虚拟私有云”。
-
进入虚拟私有云列表页面。
-
在左侧导航栏,选择“访问控制 > 安全组”。
-
进入安全组列表页面,进行配置。
入方向按照下图进行配置,对于不懂配置的可以先点击一键放常用端口,但是注意不要开放3389,20-21端口。
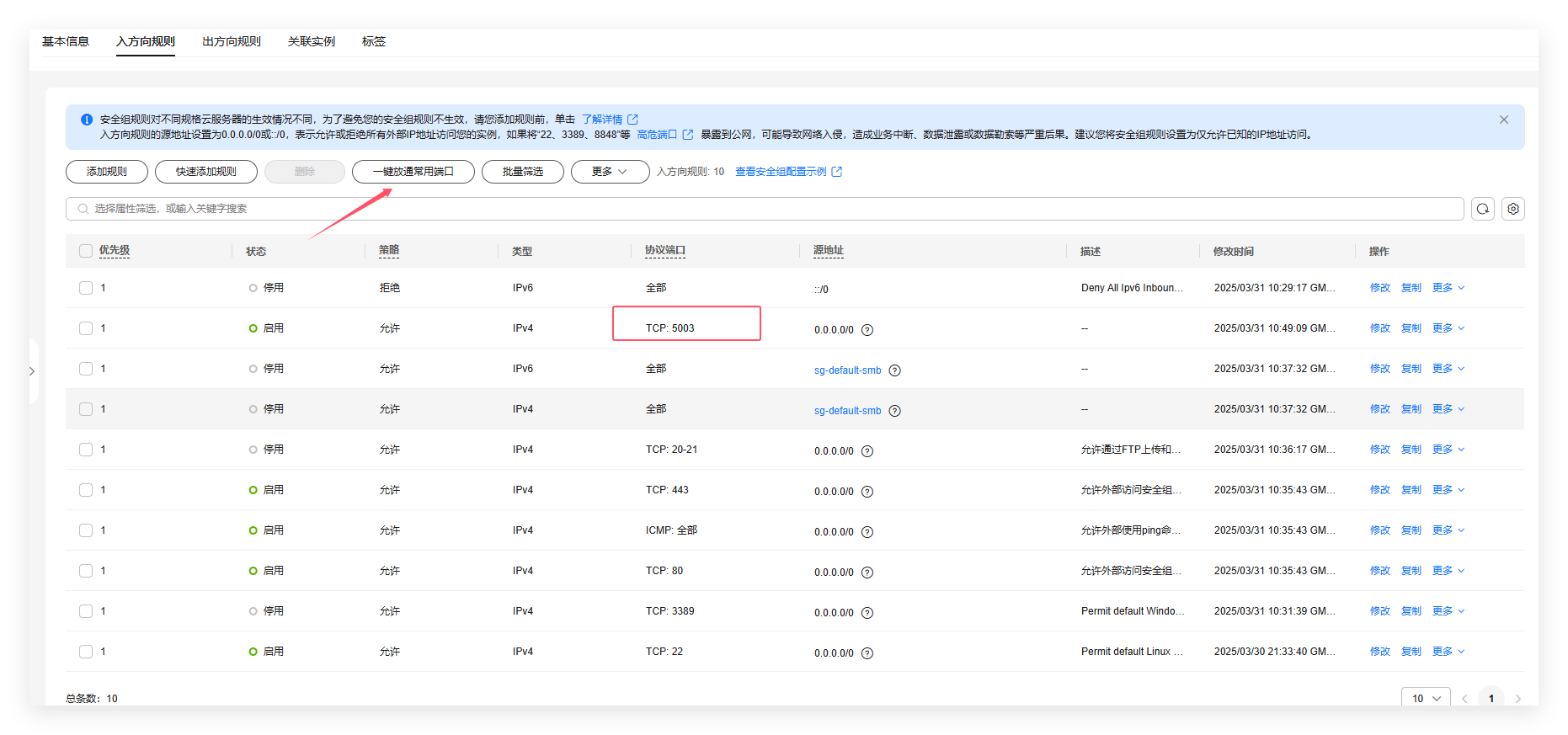
同时添加一个规则,允许5003端口,这是灯塔的默认端口

出方向就简单了,全部允许就好了,因为要扫描外部的服务和端口等信息
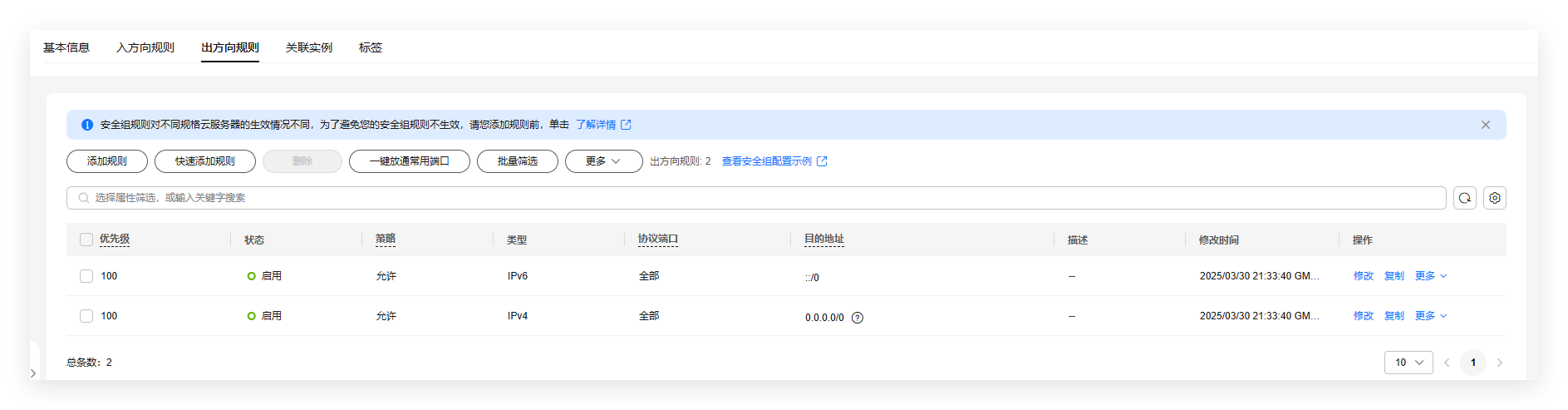
就这样就算配置好了。
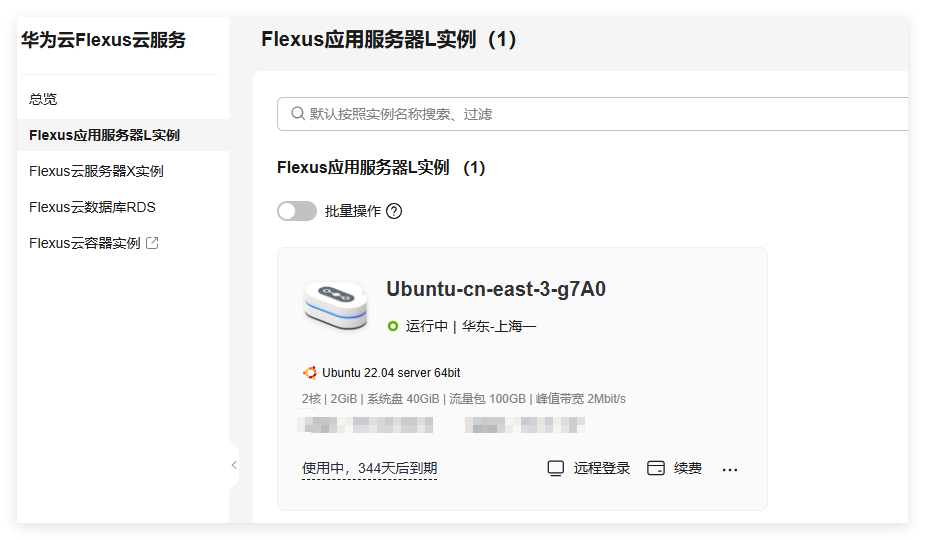
二、登录
用这个vnc登录
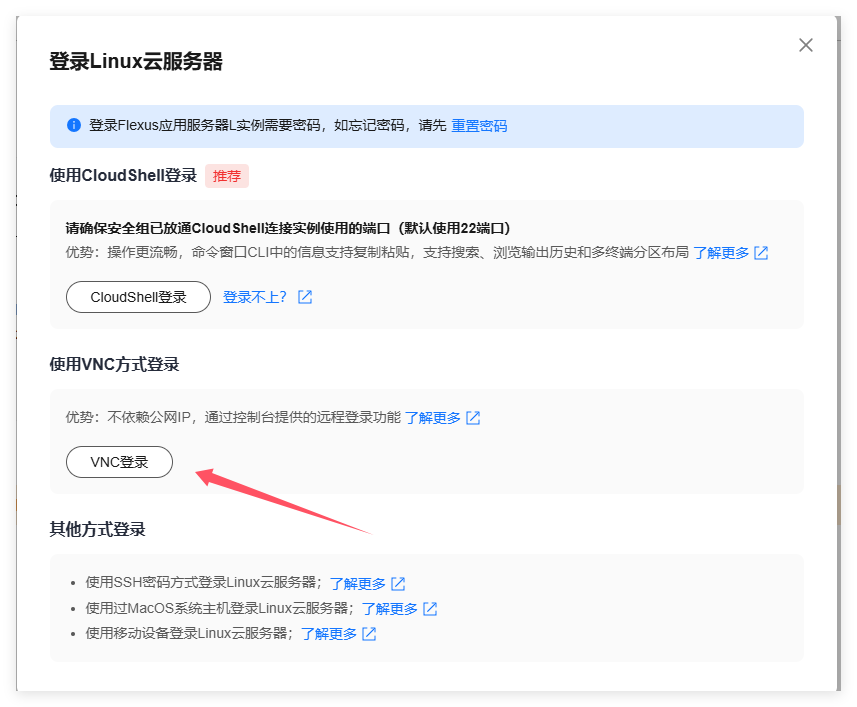
刚进来的时候,因为没有设置密码,需要点击重置密码
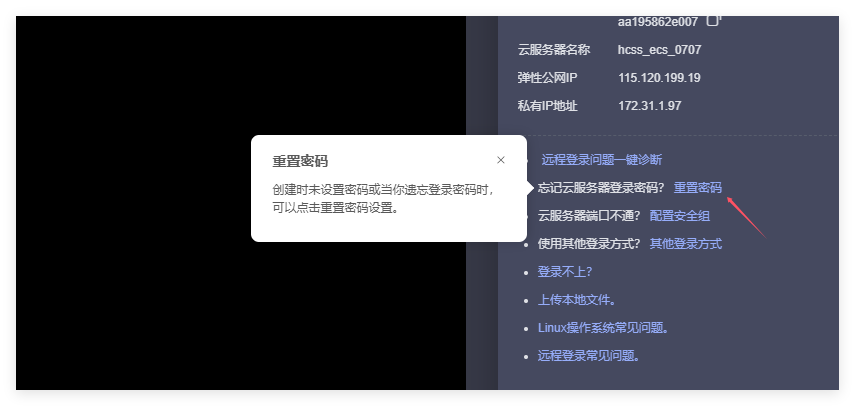
配置好密码以后就可以登录了,但是每次都要在网页去登录太麻烦了,所以在本地我使用FinalShell
FinalShell下载
下载地址:http://www.hostbuf.com/t/988.html
下载很简单,一直下一步就可以了,选择下载位置的时候,自己选一个常用的路径
连接linux
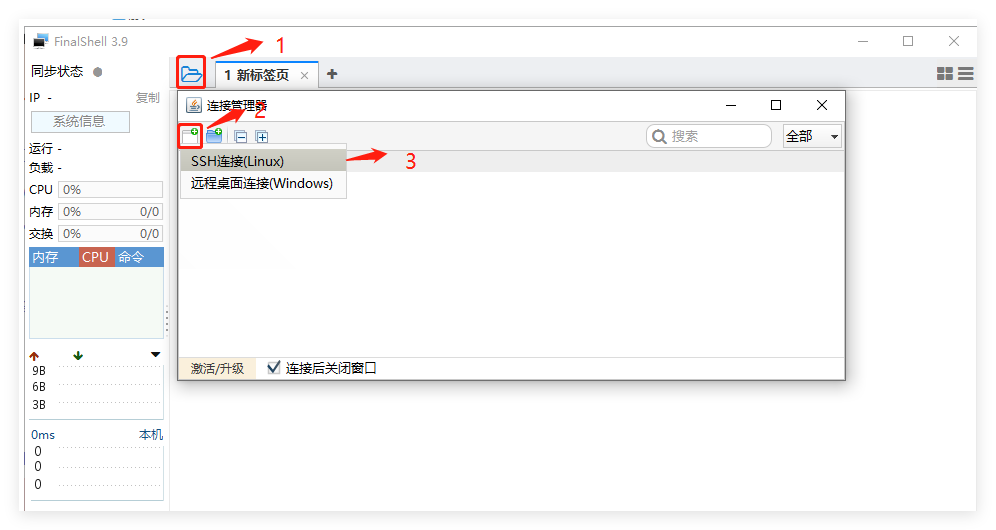
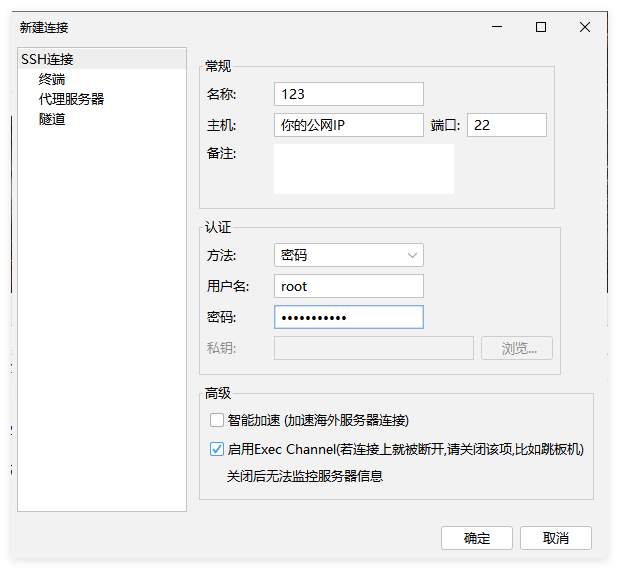
连接之后,看到如下界面:
(1) 左边部分是服务器的状态区域,可以查看CPU和内存的占用率等信息
(2) 右边上半部分是终端区域,命令都是在这里输入的
(3) 下半部分是可视化的目录区域,可以直接右键操作文件的增删改查,也可以传输文件
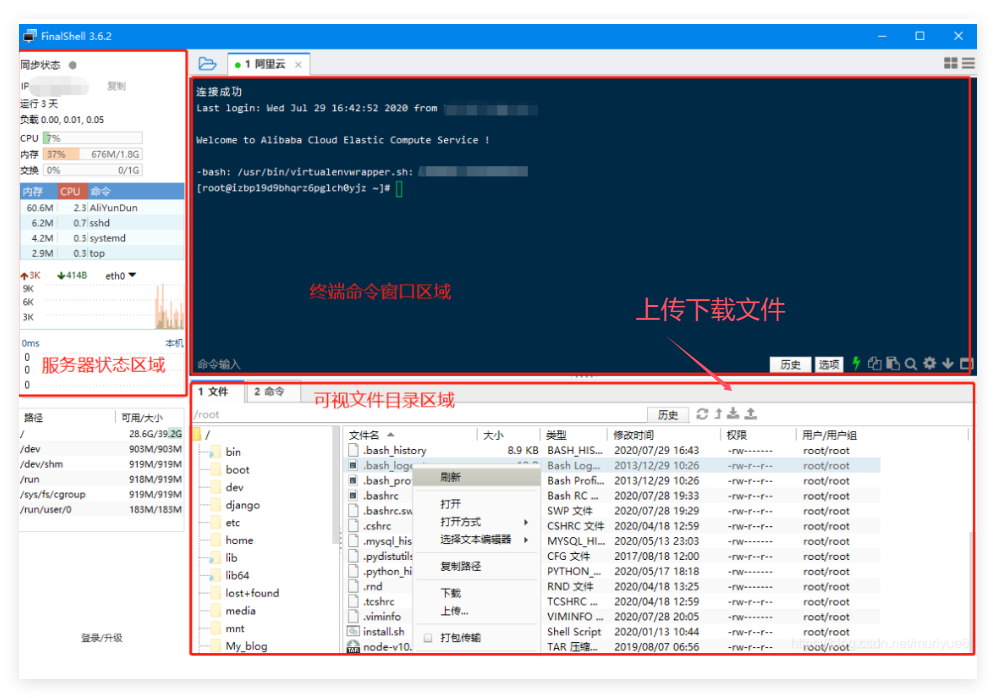
右键还可以换背景图片
三、配置ARL灯塔
3.1、安装Docker环境
sudo apt update && sudo apt install docker.io docker-compose -y
sudo systemctl enable docker --now
3.2、拉取 ARL 项目并启动
git clone https://github.com/huntingsec/ARL-Limited-Edition.git
cd ARL-Limited-Editionchmod +x install.sh./install.sh
我在使用这个命令的时候失败了,这个文件有600多MB,所以我直接访问https://github.com/huntingsec/ARL-Limited-Edition/releases
下载zip然后用FinalShell上传到/home目录
接着输入下面的命令
unzip ARL-Limited-Edition.zip
cd ARL-Limited-Editionchmod
cd docker

docker load -i arl_web.tar
docker load -i mongo.tar
docker load -i rabbitmq.tar
//Create a Docker volume for the database
docker volume create arl_db
//Start Docker containers in detached mode
docker-compose up -d
//Copy files to the Docker container
docker cp ../app/config.py $(docker ps|grep arl_worker|cut -d ' ' -f1):/code/app/
docker cp domain_2w.txt $(docker ps|grep arl_worker|cut -d ' ' -f1):/code/app/dicts
docker cp file_top_2000.txt $(docker ps|grep arl_worker|cut -d ' ' -f1):/code/app/dicts
docker cp common_password.txt $(docker ps|grep arl_worker|cut -d ' ' -f1):/opt/ARL-NPoC/xing/dicts/
//Run ARL-Finger-ADD
cd ARL-Finger-ADD
python ARl-Finger-ADD.py https://IP:5003/ admin password
systemctl restart docker
docker-compose down && docker-compose up -d
默认登陆账号密码:admin:arlpass
登陆即可使用了!
登录第一件事,修改密码!!!
登录第一件事,修改密码!!!
登录第一件事,修改密码!!!
修改一个复杂点的密码
3.3、增强灯塔
用vim命令编辑这个config文件

- 配置fofa的api-key(注意普通注册用户调用不了api)

- 这里的第三方API配置
这里面只要不需要key的,都可以把false改成true,需要key的,到对应的官网注册后在个人界面就可以看到api-key

举例hunter
其他的同理,自己注册就可以了。
下面的ARL_KEY认证key按照下面这个格式自己填就好了,不要太简单,不要填除了数字和字母以外的字符
API_KEY:"ff44256c-xxxx-xxxx-xxxx-xxxxxxxxxxx"

配置好了以后
按esc键,输入:wq进行保存
重启
docker-compose down && docker-compose up -d
docker restart arl_web
输入http://ip:5003 就可以访问了

四、自动化进行信息收集
4.1、anew
https://github.com/tomnomnom/anew/releases/tag/v0.1.1
直接下载
上传到服务器,解压tar -xzvf,
然后chmod +x anew
移动到系统路径
mv ./anew /usr/bin
这样就算成功了

4.2、subfinder
https://github.com/projectdiscovery/subfinder/releases
直接下载
上传到服务器,unzip命令解压
chmod +x subfinder
mv ./subfinder /usr/bin
像这样就成功了
接着我编写了自动运行的脚本bot.sh、调用ARL接口的脚本arlGetAassert.py,实现subfinder和ARL联动,扩大资产范围,设置24小时运行一次,将subfinder和调用灯塔的资产合并后去重,第一次运行会生成urls.txt、subs.txt同时将urls.txt复制一份并以当前运行时间命令作为备份,后面的每一次运行如果有新的资产那么会将新的资产追加到urls.txt里面,同时单独将新增加的资产放到一个文件里面以运行结束时的时间命名。
(这里调用ARL接口的脚本参考的文章https://blog.csdn.net/qq_47289634/article/details/139117299)
具体代码见下面(执行bot.sh前,chmod +x bot.sh)
arlGetAassert.py里面需要填入之前在config-docker.yaml里面配置的灯塔的认证key
bot.sh里面的TARGET_DOMAIN填入目标域名
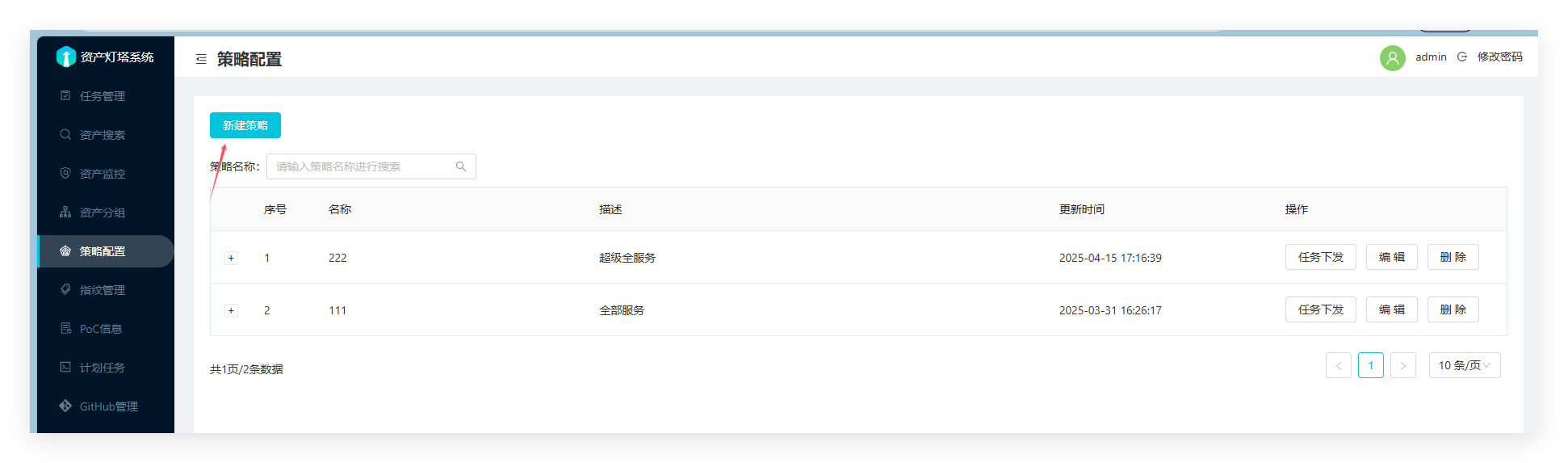
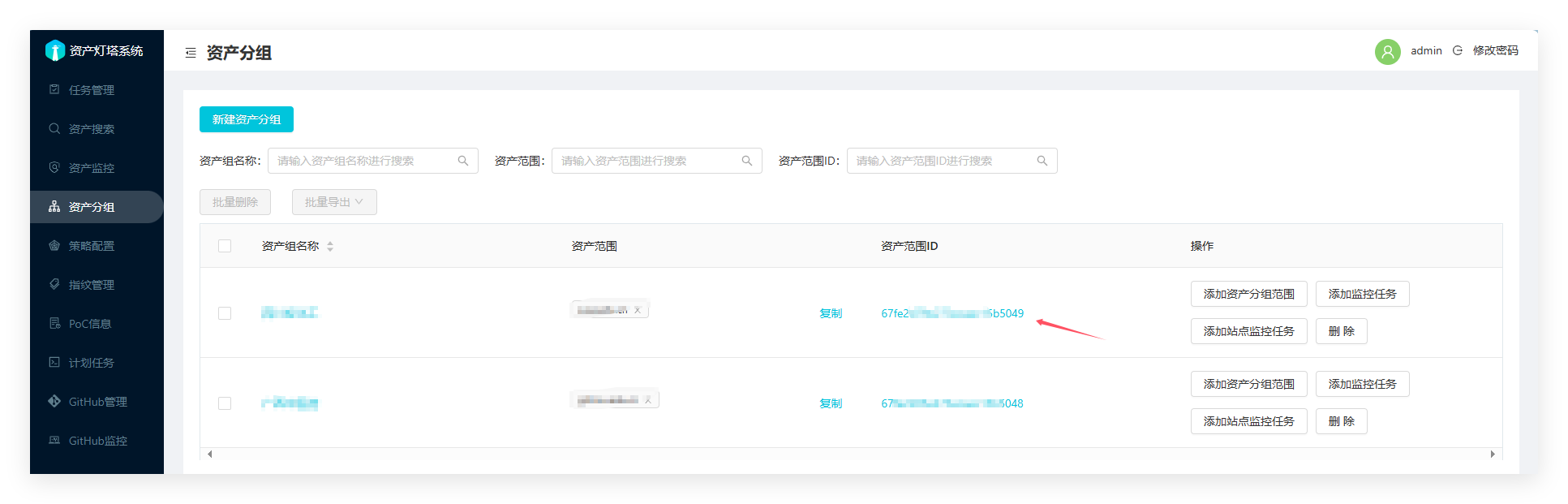
ARL_API_KEY填入灯塔里面的资产范围ID,没有就新建一个目标域名的,新建之前需要添加配置一个策略
url路径https://IP:5003/api/asset_domain/ 里面的IP填入你的vps公网IP
都填好以后,注意将arlGetAassert.py和bot.sh放到同一个目录
建议使用后台运行,运行命令:
nohup /bin/bash ./bot.sh > scan.log 2>&1 &
就是挂在后台运行,并将运行日志输出到scan.log里面
最后的目录结构以及效果

scan.log内容

下载bot.sh、arlGetAassert.py的地址
https://github.com/cllwlaq/autocheck-bot
arlGetAassert.py
import optparse
import requests
# 这个apikey是灯塔里面之前在config-docker.yaml里面配置的灯塔的认证key
apikey = "t44y56c-xxxx-xxxx-xxxx-xxxxxxxxxxx"
requests.packages.urllib3.disable_warnings()
def print_hi(name):
print(f'Hi, {name}') # 示例函数,未被调用
def task(scope_id):
headers = {'accept': 'application/json', 'Token': apikey} # 请求头
# 首次请求获取总条数
ceshi = requests.get(
"https://IP:5003/api/asset_domain/?size=100&tabIndex=1&scope_id=" + scope_id,
headers=headers,
verify=False # 关闭SSL验证(存在安全风险!)
)
json1 = ceshi.json()
number = json1['total'] # 总数据量
pages = number // 100 # 计算总页数(每页100条)
pages += 1
# 分页循环获取数据
for page in range(1, pages + 1):
data = requests.get(
f"https://IP:5003/api/asset_domain/?page={page}&size=100&tabIndex=1&scope_id={scope_id}",
headers=headers,
verify=False
)
json_data = data.json()
items = json_data['items'] # 当前页的数据列表
# 遍历并打印每个站点的名称
for item in items:
print("%s" % (item['domain']))
if __name__ == '__main__':
# 参数帮助信息
parser = optparse.OptionParser(
'python3 arlGetAassert.py -s scope_id -o result.txt\n'
'Example: python3 arlGetAassert.py -s 6229835c322616001dd91fe4\n'
)
# 定义 -s 参数(资产范围ID)
parser.add_option(
'-s', dest='scope_id', default='6229835c322616001dd91fe4',
type='string', help='scope_id 资产范围ID'
)
# 解析参数并调用任务函数
(options, args) = parser.parse_args()
task(options.scope_id)
bot.sh
#!/bin/bash
# 文件名:bot.sh
# 描述:自动化子域名收集与资产探测(每小时执行一次)
# 配置参数
TARGET_DOMAIN="example.com" # 目标域名(必改)
ARL_API_KEY="" # ARL API密钥 ,这是灯塔里面的资产范围ID
SUBFINDER_OUTPUT="./subs.txt" # SubFinder输出文件
URLS_HISTORY="urls.txt" # 历史记录文件
while true; do
echo "[$(date '+%Y-%m-%d %H:%M:%S')] 启动新一轮扫描..."
# Step 1: 执行SubFinder并检查结果
echo "正在运行SubFinder..."
if ! subfinder -d "$TARGET_DOMAIN" -o "$SUBFINDER_OUTPUT" -silent; then
echo "错误:SubFinder执行失败"
exit 1
fi
# 检查输出文件是否存在且非空
if [ ! -s "$SUBFINDER_OUTPUT" ]; then
echo "警告:未找到有效子域名,跳过后续步骤"
sleep 3600
continue
fi
# Step 2: 调用ARL API并处理结果
echo "从ARL获取资产..."
ARL_TEMP=$(mktemp)
if ! python3 arlGetAassert.py -s "$ARL_API_KEY" > "$ARL_TEMP"; then
echo "错误:资产获取失败"
rm -f "$ARL_TEMP"
exit 1
fi
# 合并并去重结果
COMBINED_TEMP=$(mktemp)
cat "$SUBFINDER_OUTPUT" "$ARL_TEMP" | sort -u > "$COMBINED_TEMP"
rm -f "$ARL_TEMP"
# 判断执行模式
if [ ! -f "$URLS_HISTORY" ]; then
# 第一次执行模式
echo "首次执行模式,生成初始记录文件..."
mv "$COMBINED_TEMP" "$URLS_HISTORY"
TIMESTAMP=$(date '+%y-%m-%d-%H:%M')
cp "$URLS_HISTORY" "${TIMESTAMP}.txt"
echo "首次扫描结果已保存至:${TIMESTAMP}.txt"
else
# 非首次执行模式
echo "增量执行模式,检测新增资产..."
NEW_TEMP=$(mktemp)
cat "$COMBINED_TEMP" | anew "$URLS_HISTORY" > "$NEW_TEMP"
rm -f "$COMBINED_TEMP"
if [ -s "$NEW_TEMP" ]; then
echo "发现新增资产数量:$(wc -l < "$NEW_TEMP")"
cat "$NEW_TEMP" >> "$URLS_HISTORY"
TIMESTAMP=$(date '+%y-%m-%d-%H:%M')
mv "$NEW_TEMP" "${TIMESTAMP}.txt"
echo "新增结果已保存至:${TIMESTAMP}.txt"
else
echo "未发现新增资产,跳过文件生成"
rm -f "$NEW_TEMP"
fi
fi
echo "[$(date '+%Y-%m-%d %H:%M:%S')] 本轮扫描完成,24小时后再次执行"
sleep 86400
done;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号