mysql刷题题后感
刷题的时候会将一些题目收藏,也会收藏错题,做完了整合一下,会有一些补充知识点。
题目来源是牛客网。牛客网公司真题_免费模拟题库_企业面试|笔试真题 (nowcoder.com)
函数篇(和长篇大论的查询有交集)
Q1:
查询语句select stuff('lo ina',3, 1, 've ch')结果为?love
love china
china love
china
答:stuff,删除并加入字符,STUFF(原字符, 开始位置, 删除长度, 插入字符)
从指定的起点处开始删除指定长度的字符,并在此处插入另一组字符,所以这个题的答案应该是 love china
Q2:

查询null的值:select * from student_table where name is null ;
3.查询非null的值,就需要使用is not null词组判断
Q3:

解析:RANK() OVER(PRITITION xxx ORDER BYxxx)作用已经在长篇大论的查询里面讲了。以及over是窗口函数。
补充:

Q4:

解析:正确答案是DF。

主要是,score不是主键,所以score可能为空。
Q5:
Q6:

解析:
Q7:

(这一道题好难分类啊),D选项是错的,字段 = 别名 仅限 SQL Server 。
Q8:

解析:链接:
Q9:

解析:
Q10:

解析:
赋予登陆权限的语句是grant usage on 数据库 to 用户,@%表示任何主机的通配符。
给数据库赋予登录权限的语句是grant usage on ... to。因此答案A、C都不正确。题目中只说secretData数据库中的某个表有绝密文件,但是对新创建的用户可拥有登录权限,而没有其他权限。并没有说只对secretData数据库,因此题目引入该数据库只是一个干扰信息,所以答案B错误,因此答案选择D
(这一道题被人骂了,被人说是垃圾文字游戏)
Q11:Alter相关
不放题目了。
| CHANGE COLUMN <旧列名> <新列名> <新列类型>
| ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT }
| MODIFY COLUMN <列名> <类型>
| DROP COLUMN <列名>
| RENAME TO <新表名> }
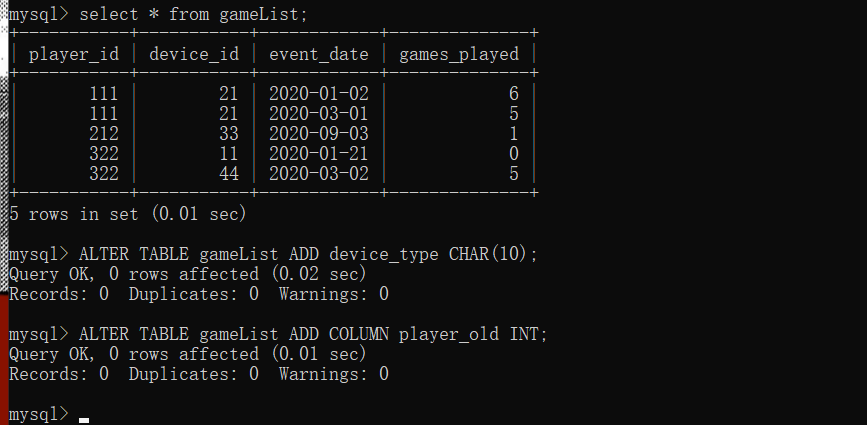
Q12:
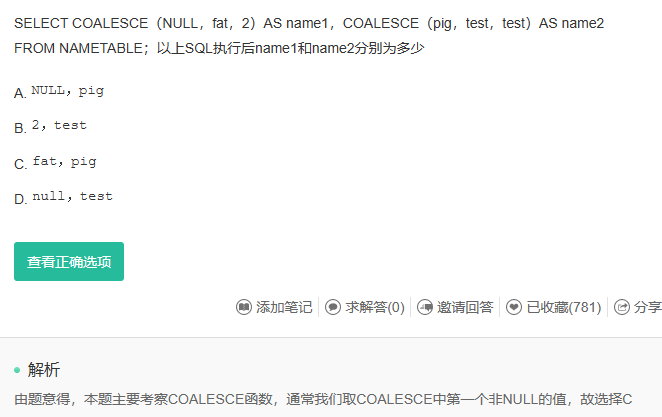
Q13:
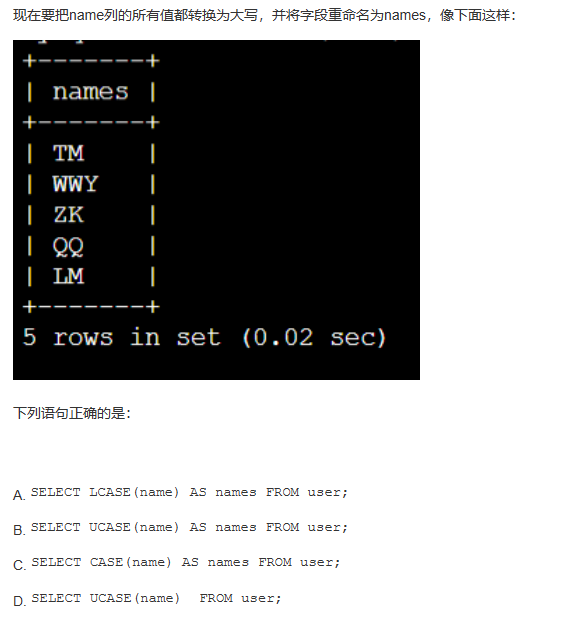
解析:
Q14:
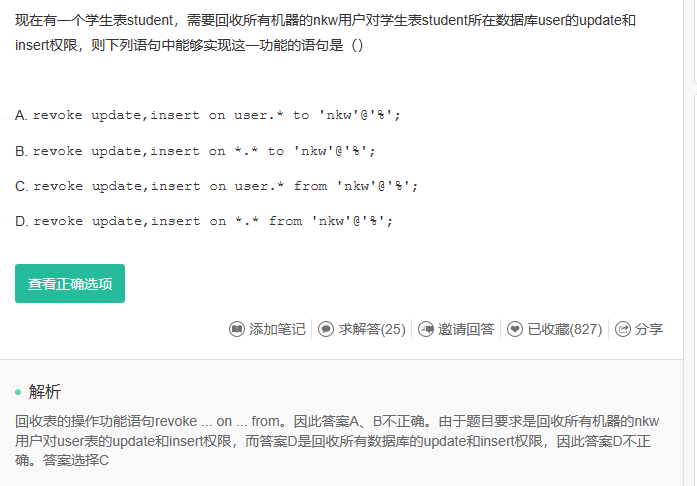
- 出来 SELECT 的 WHERE 可以限制一条记录被选中外,T-SQL 没有提供查询表中单条记录的方法,但我们常常会遇到需要逐行读取记录的情况。
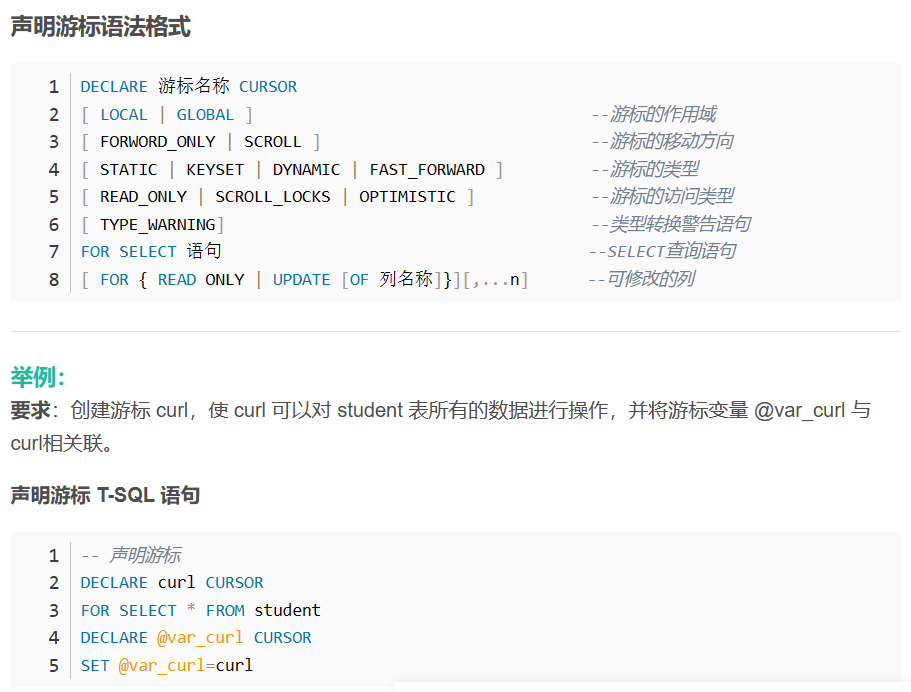



连接篇(有一些连接题目我归到长篇大论的查询里面了)
Q1:
Mysql中表student_table(id,name,birth,sex),插入如下记录:
('1001' , '' , '2000-01-01' , '男');
('1002' , null , '2000-12-21' , '男');
('1003' , NULL , '2000-05-20' , '男');
('1004' , '张三' , '2000-08-06' , '男');
('1005' , NULL , '2001-12-01' , '女');
('1006' , '张三' , '2001-12-02' , '女');
执行
select t1.name from
(select * from student_table where sex = '女')t1
inner join
(select * from student_table where sex = '男')t2
on t1.name = t2.name;
的结果行数是()?
4
3
2
1
答:这里的连接是inner join , 内连接,就是左右外连接删掉null的行数。主表是女表,所以说至少有两行,null是不参加配对的,所以应该是1行。
这里是官方解析:inner join时只会对非NULL的记录做join,并且2边都有的才会匹配上,所以结果只有'张三',是1行,选D。
Q2:

具体的解析在长篇大论的查询里面有讲啦,主表是男,所以至少4条,然后由于null是没有办法匹配的(嗯,null和任何值都是false,是比较独立的值,length和<>也不能识别null,嗯,所以有了is NULL 语句),张三那一条又只有一条匹配的,所以最多就是4条。
Q3:
(不放题目了) join 和inner join是等同的。
Q4:

解析:答案选C
Q5:
Q6:

长篇大论的查询
Q1:
student_table(id,name,birth,sex),查询男生、女生人数分别最多的3个姓氏及人数。
select *
from (select sex,substr(name,1,1) AS first_name , count(*) AS c1
from student_table where length(name) >= 1 AND sex = '男'
GROUP BY first_name
ORDER BY sex , c1 desc LIMIT 3
)t1
UNION ALL
select *
from(select sex , substr(name , 1,1) AS first_name , count(*) AS c1
from student_table where length(name) >= 1 AND sex = '女'
GROUP BY first_name
ORDER BY sex , c1 desc LIMIT 3
)t2
解析:length是为了避免连姓名都没有。这里GROUP BY不用连接sex,是因为where已经挑出了sex的条件,所以group by就没有必要了,试想一下都是男性没必要通过sex分组啊,这里ORDER BY也加上了sex,其实可以不用加的。还有一个需要注意的,新建的表必须加一下别名。
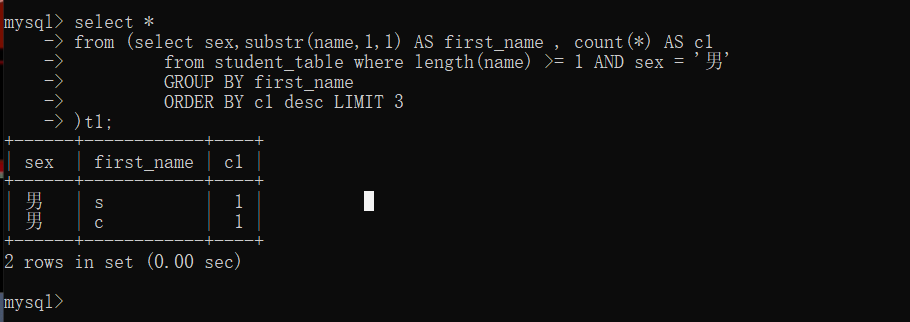
我这里贴一下其他的错误选项:
one.
SELECT sex ,substr(name,1,1) as first_name ,count(*) as c1
from student_table where length(name) >=1 and sex = '男'
group by first_name order by sex ,c1 desc limit 3
union all
SELECT sex ,substr(name,1,1) as first_name ,count(*) as c1
from student_table where length(name) >=1 and sex = '女'
group by first_name order by sex ,c1 desc limit 3 ;
解析:这选项的错误原因是order by 和 union的优先级问题,union的优先级高过order by。
建议对比一下正确选项,记一下正确选项的union写法。
在Mysql的参考手册中,并没有对union和order by的优先级进行说明,它建议的方法是,对SQL语句加上(),这样能使SQL的语义更清晰.
second.
SELECT sex ,substr(name,1,1) as first_name ,count(*) as c1
from student_table where length(name) >=1
group by first_name , sex order by sex ,c1 desc limit 3 ;
解析:该题目是三条记录,男生女生的人数是不确定。
Q2:
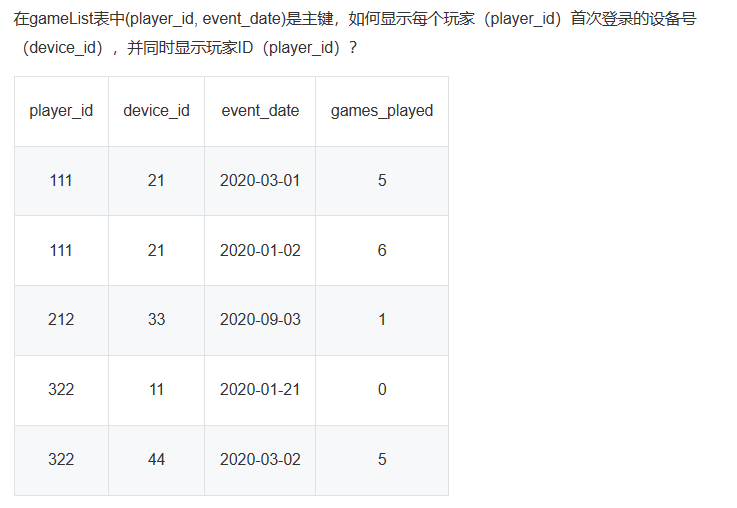
这里写一下正确选项:
SELECT player_id, device_id
FROM(SELECT * ,rank() over (partition by player_id order by event_date ) as rank_date from gamelist )t
WHERE t.rank_date=1
解析:链接:

单纯将rank输出的话:
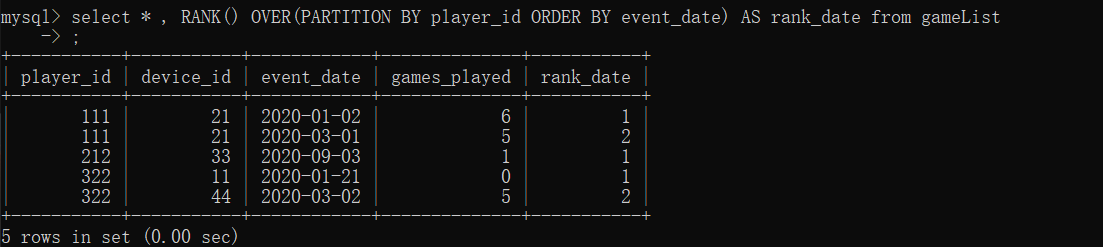
可以看出来,RANK () OVER 就是对那列进行分组,对每一列的event_date排序,然后按从上到下的顺序标等级(rank),讲到这里就应该懂了。
Q3:

很熟悉对吧,这个专项练习就喜欢考这个。
full join,在mysql(至少版本8之前包括版本8)都是不支持full join,所以替代语句是left join + right join (语句的实现中间还要加一个union all),接下来是正确选项:
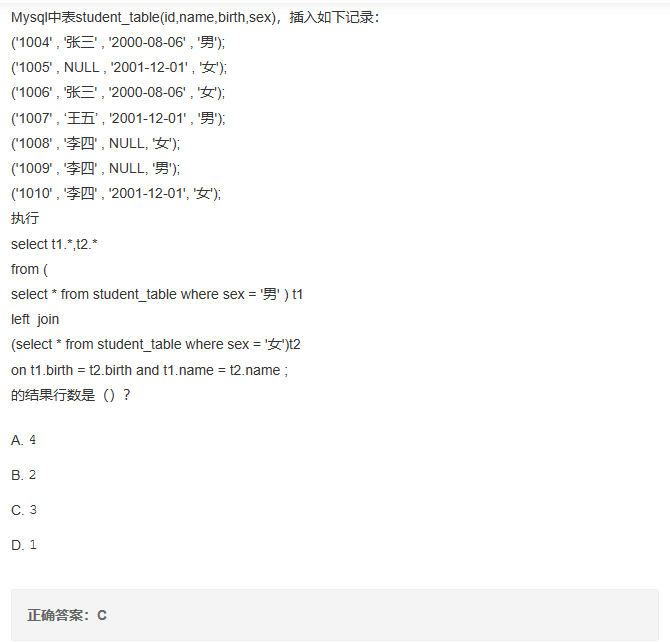
select t1.*,t2.*
from (
select * from student_table where sex = '男' ) t1
left join
(select * from student_table where sex = '女')t2
on t1.name = t2.name
union all
select t1.*,t2.*
from (
select * from student_table where sex = '男' ) t1
right join
(select * from student_table where sex = '女')t2
on t1.name = t2.name
where t1.name is null ;
同样的,这里也要先select * ,然后加上括号(原因前几题讲过)。
下面的链接本来是想借一下图的,但是发现写的很好,建议去看下面的链接。
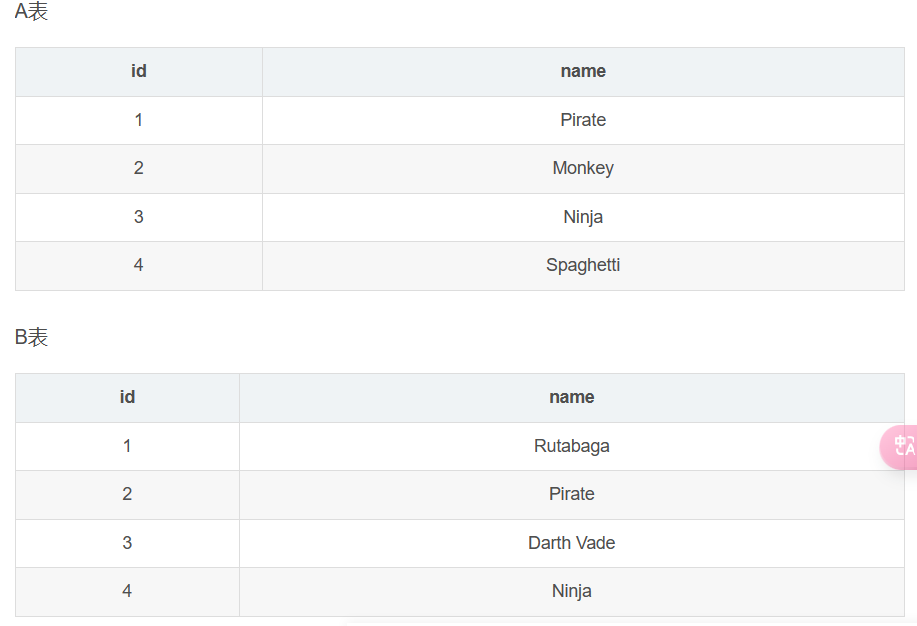
left join:
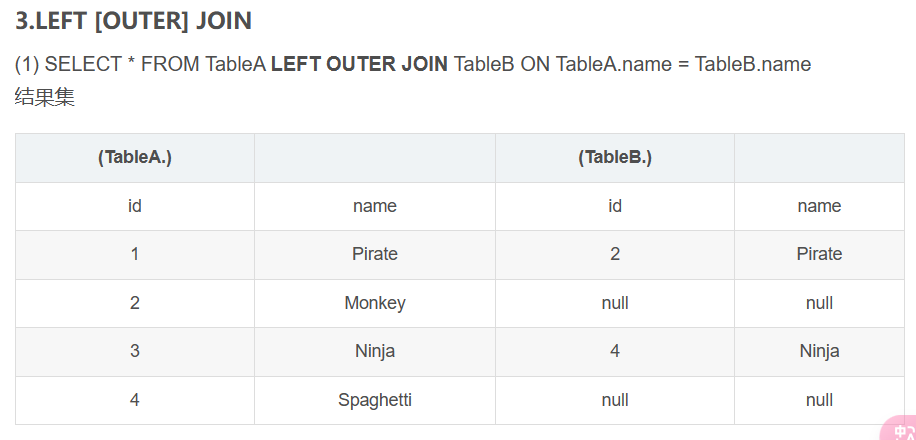
其实就是和left join连着的表是主表,所以直接将表的左边换成主表(也就是说至少是主表的行数),有关系的将右表的相关记录连上,如果没有的就记上null。
right join:
和left joiin 类似的,嗯,比如说table b RIGHT JOIN table a,其实就可以转换成table a LEFT JOIN table b。然后就和left join 一样了。
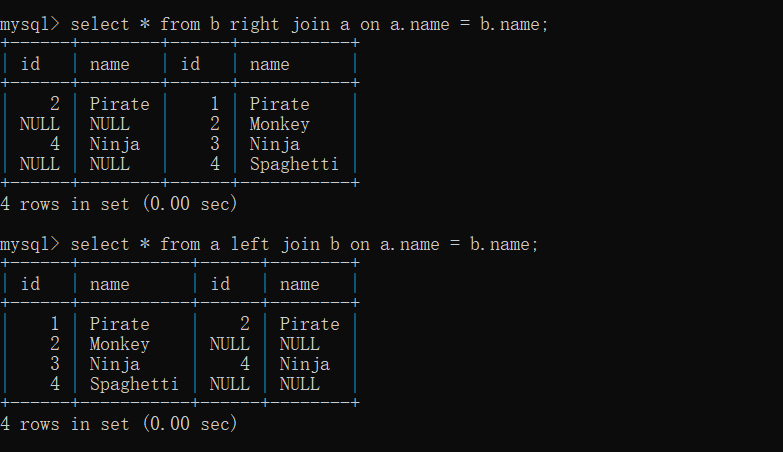
看,只是位置不一样,但是主表是一样的。
full join:
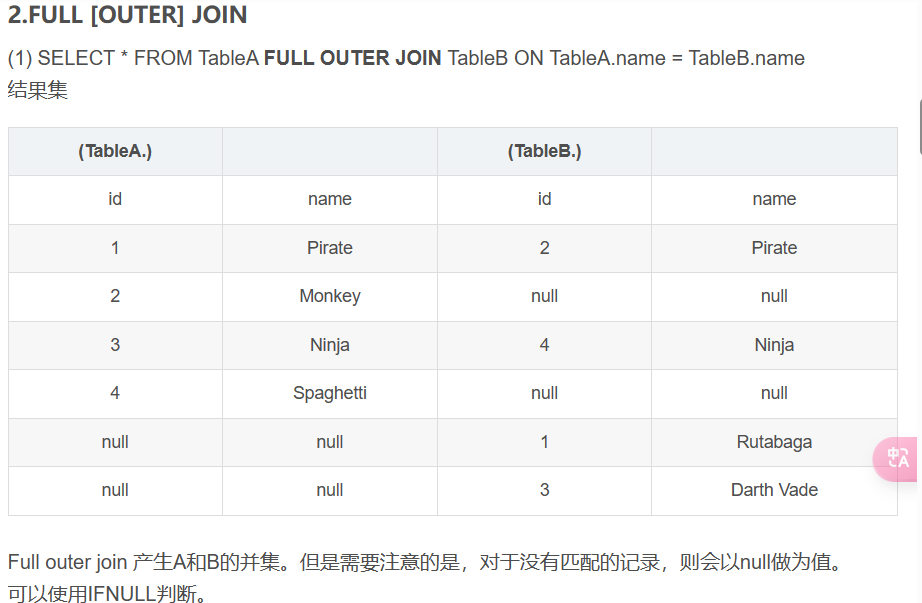
我们看一下结果,前四行是a left join b,后四行原本是a right join b,然后删去了几行重复的,在下面的例子就是删掉了重复的| 1 | Pirate | 2 | Pirate |和| 3 | Ninja | 4 | Ninja |
所以right join那里要选择null的。
+------+-----------+------+--------+
| id | name | id | name |
+------+-----------+------+--------+
| 1 | Pirate | 2 | Pirate |
| 2 | Monkey | NULL | NULL |
| 3 | Ninja | 4 | Ninja |
| 4 | Spaghetti | NULL | NULL |
| NULL | NULL | 1 | Rutabaga |
| 1 | Pirate | 2 | Pirate |
| NULL | NULL | 3 | Darth Vade |
| 3 | Ninja | 4 | Ninja |
+------+--------+------+------------+
inner join:
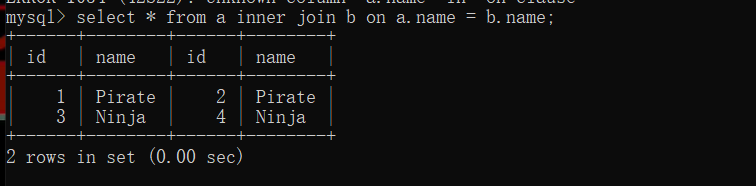
inner join就是两者都有的记录。
我本以为我学会了,我就不会错了,但是之后我还是载了,因为我不看题目(真的吗)
哦对了,full outer join 和full join 是一样的。
Q4:
收藏的题目,额,应该是想要记录一个点。
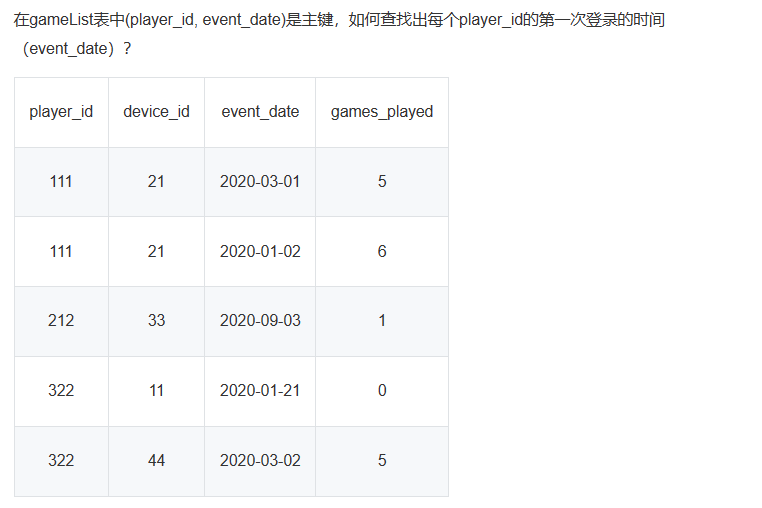
这里是使用min,然后记录一下错误选项:
SELECT player_id, min(event_date) as first_login FROM gameList WHERE min(event_date) GROUP BY player_id
这个就是语法错误,我想要记录的是各个语句的书写顺序。
书写顺序:
select[distinct]
from
join(如left join)
on
where
group by
having
union
order by
limit
执行顺序:
from
on
join
where
group by
having
select
distinct
union
order by
(对,没错,order by比select 后,选出条件后的表然后再排序,好像是这么一个逻辑,但是也可以先order ,不过这样的数据可能会处理得多。当然这个顺序不要硬记,记几个就可以了,比如order 比 select 慢,union 比 order by 快,聚合函数不能用在where语句遇到了再记。
Q5:
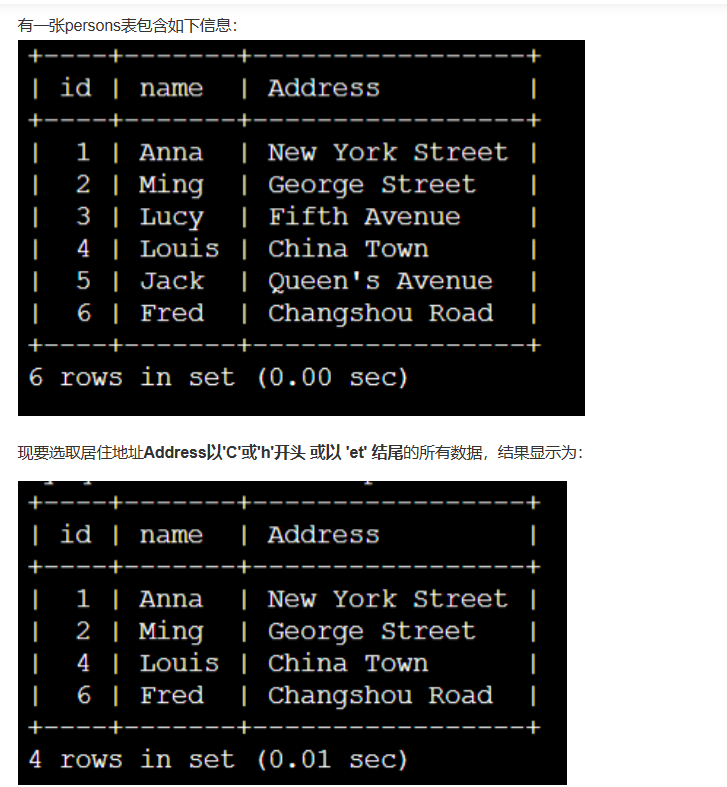
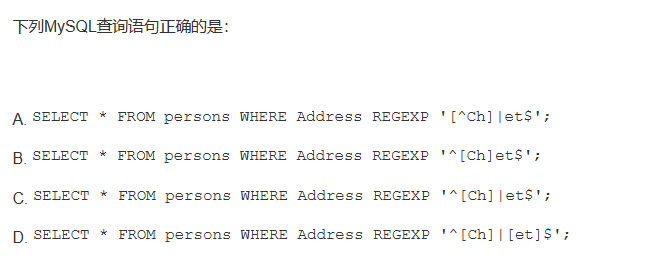
解析:
MySQL 中使用 REGEXP 来操作正则表达式的匹配。
- ^ 该符号表示匹配输入字符串的开始位置;
- $表示匹配输入字符串的末尾位置;
- [...] 表示匹配所包含的任意一个字符;
- [^...]表示不能匹配括号内的任意单个字符;
- x|y 这条竖线表示匹配x 或匹配y。
所以这道题选c。
Q6:

解析:

题目那个更像是sql server 的格式: 详细实例全面解析SQL存储过程-SQL 教程-w3cschool
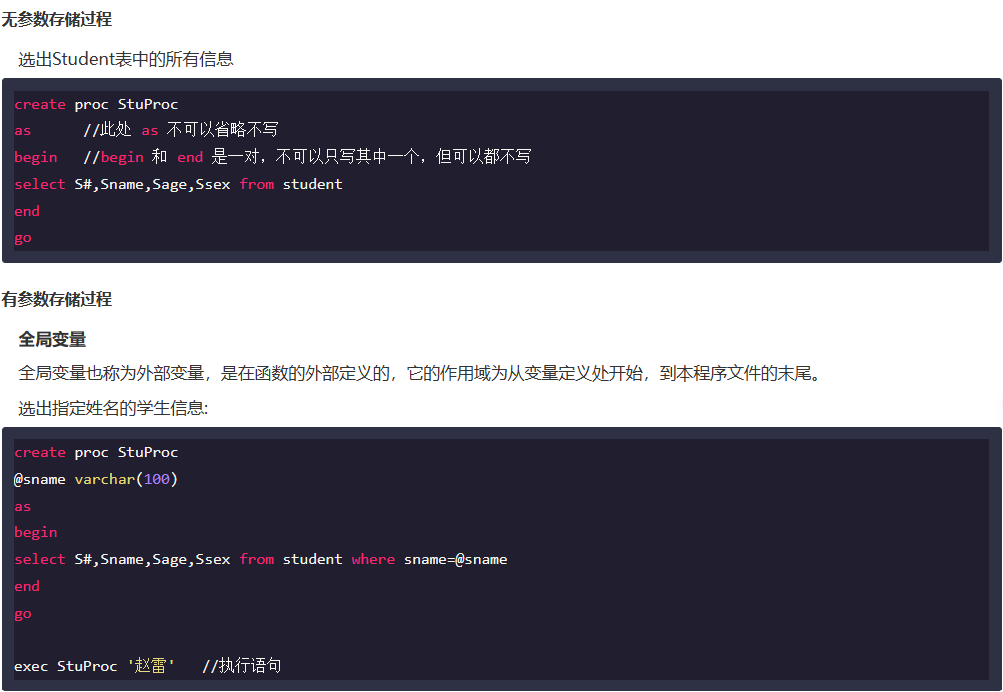
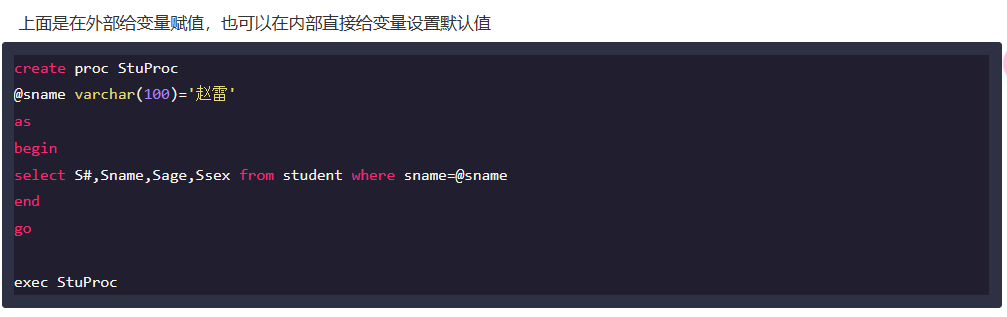
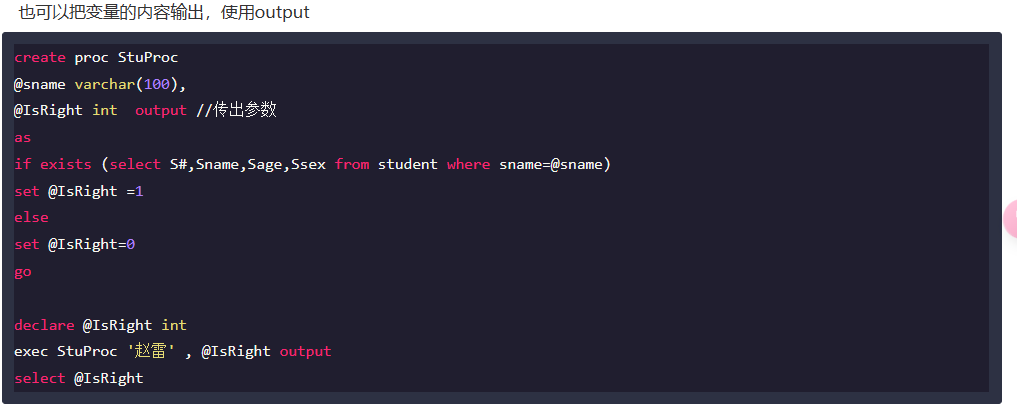
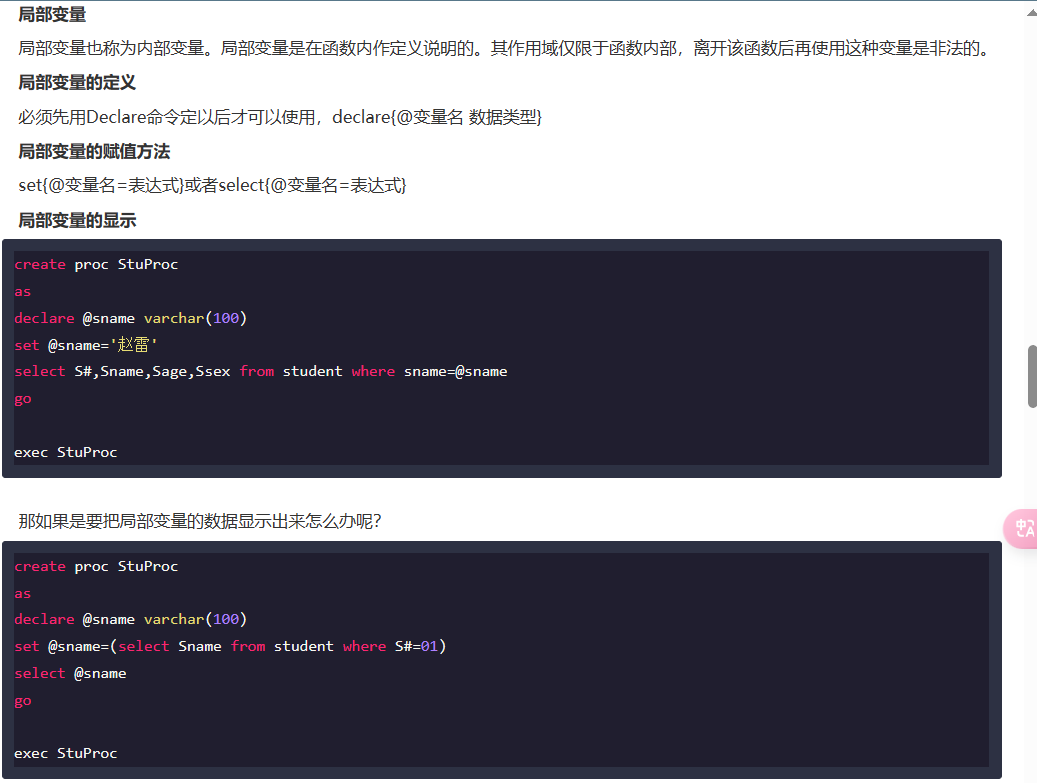
先记一下,之后要写的话写熟悉就行了。
Q7:
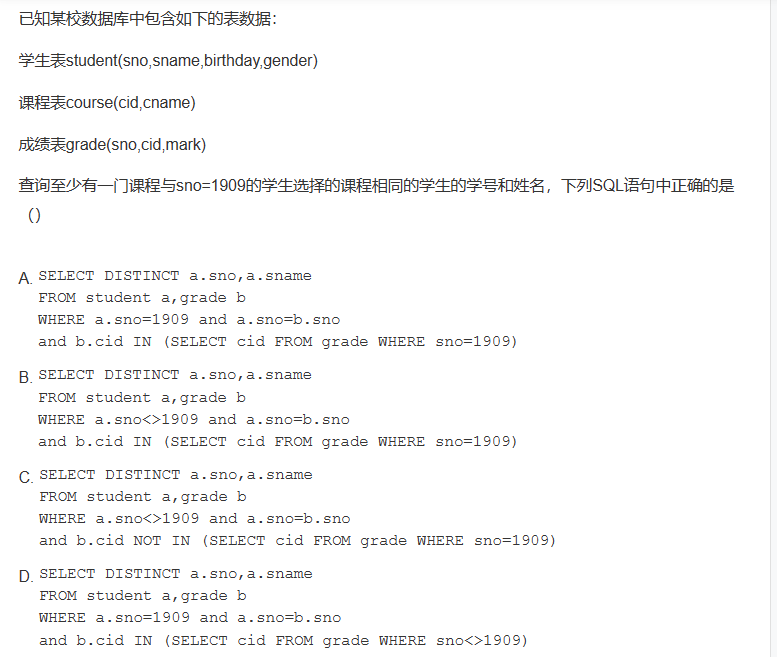
(这种收藏就是为了自己写一遍,很简单的,逻辑是成绩表和学号表的sno联系好找到cid,然后找cid在sno 为1909 的学生选的课程,这样子就是至少)
Q8:

(写这种的时候,真的好痛苦)
创建视图 语句如下 create view 视图名 as select * from 表名 where 条件
先说一下,这一道题选B,B是错的,因为where语句语法不对。
A和C的选项,一个是表示qcontent(题目内容),一个是qcid(题目id),然后都是创建视图的语句,很简单。
D选项
首先select语句中,view_teacher通过as起了别名question_2,所以在select时是找不到view_teacher.tname和view_teacher.v_tid的,因此会报错“Unknown column 'view_teacher.tname' in 'field list'”;其次,在create view语句中,question_2这个别名是找不到的,因此会报错“Table 'test_db.question_2' doesn't exist”。
这一个选项可以看成是先select然后再create(仔细看,select有分号),当然你要是问我为什么要这么做,我只能说我也没见过,不应该是这种写法,select是选出列形成一张表,但是create view确实从view_teacher(question_2)中create,没有逻辑啊。
Q9:

解析:看了官方解析很久,看不太懂突然想了一下有评论区啊。

(屏蔽的那个是DEFAULT)
Q10:
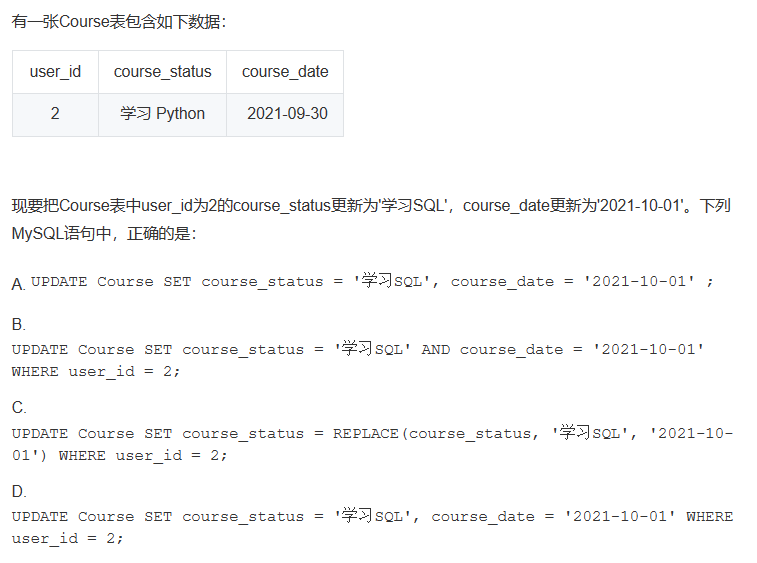
解析:alter是改类名的,update是改数据的,在前面还是后面的题讲过,update是数据操纵语言,ALTER确实数据定义语言。
正确的UPDATE更新语法为:
UPDATE table_name SET field1 = new-value1, field2 = new-value2 [WHERE Clause];
所以D选项才是正确的;
A错在没有添加WHERE指定筛选行,所以会更新全部数据!
B错在更新多列数据的间隔符号是逗号,不是AND语句;(注意,这里是逗号,不是AND)
C错在REPLACE函数虽然可以批量修改数据,但是REPLACE的正确语法应该是:
REPLACE INTO tab_name(field1, field2...) VALUES (value1, value2)...;(和INSERT 是同语法)
因此此题用不到REPLACE批量修改的方法。
Q11:
表employee:
+-----+-----------+
| eno | ename |
+-----+-----------+
| 1 | 小李 |
| 2 | 小王 |
| 3 | 小刚 |
| 4 | 小虎 |
+----+------------+

解析:评论区解析

(那个row_NUMBER()有讲过。这个解释是真的好,所以搬过来了)
Q12:

解析:DATEDIFF(d1,d2),计算日期 d1->d2 之间相隔的天数,d1-d2,负值说明前一个日期比后一个小,所以D的意思就是d2是前一天,d1是后一天,d1的kilometer小于d2的了
DATE_ADD()函数
1、定义:函数向日期添加指定的时间间隔。
2、语法:DATE_ADD(date,INTERVAL expr type)
(其实c选项也是错的)
Q13:

其实就是希望可以写一下,D选项其实也是对的,官方出的答案是C。
case语句可以在select中出现(在经典题里面也出现了)
Q14:


解析:其实就是,行转列,那么就要按照sno分组,然后用select来选出列。
Q15:
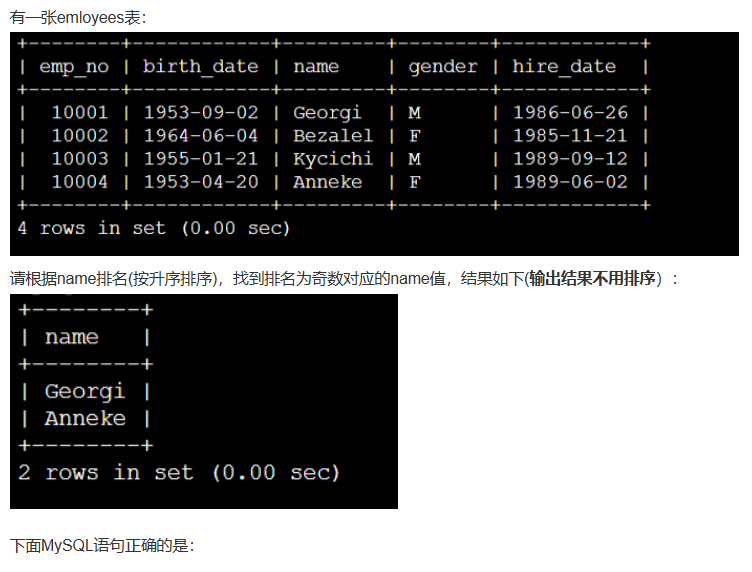

解析:选b,输出结果不用排序,注意。
Q16:

解析:
All():对所有数据都满足条件,整个条件才成立,>=all()等价于max,<=all()等价于min;
Any:只要有一条数据满足条件,整个条件成立,>any()等价于>min,<any()等价于<max;
some的作用和Any一样(记一下,any的关系)
Q17:
给一下这道题的链接:

(有一说一,这个语句太长了,逻辑就是多表查询分别查出来id和name,然后用inner join和原表相连,inner join的使用场景注意一下。)
这个更好⬇
(select maxid from
(select max(id) maxid from student_table group by name having count(name)>1) a);
Q18:

解析:正确是B,A是被distinct害了。
Q19:

选d。不选C选项是不是因为not in后面需要直接跟值而不是一个表
数据库原理篇:(原理嘛,记一下)
Q1:

官方解析:
数据控制语言DCL,主要用于对用户权限的授权和回收;A选项,DDL主要的命令有CREATE、ALTER、DROP等,大多在建立表时使用;B选项,DML包括SELECT、UPDATE等,对数据库里的数据进行操作;D选项,数据库事务包括COMMIT、ROLLBACK等,主要用于对事务的提交、回收和设置保存点。
补充:DDL , 数据定义语言。DML,数据操纵语言。TCL,事务控制语言,TCL包括COMMIT(提交)命令、ROLLBACK(回滚)命令、SAVEPOINT(保存点)命令:
Q2:
-
视图可以解决检索数据时一个表中得不到一个实体所有信息的问题
-
视图是一种数据库对象,是从数据库的表或其他视图中导出的基表
-
若基表的数据发生变化,则变化也会自动反映到视图中
-
数据库存储的是视图的定义,不存放视图对应的数据
解析:视图是虚拟表,视图所引用的表被称为视图的基表。这里选的是B
补充知识点:数据库中为什么要建立视图,它有什么好处?-CSDN博客
只是为了查询某一个信息然后去建立一个和其他表数据高度冗余的表,是不好的,所以就选需要视图。
创建视图的语句:创建视图 语句如下 create view 视图名 as select * from 表名 where 条件
比如:CREATE VIEW view_s AS SELECT * FROM STU WHERE 性别='男'
Q3:

解析是没有什么用的,要看评论区大哥。

Q4:

A选项,不能定义一个check约束后,立即在同一个批处理中使用;C选项,Create default,Create rule,Create trigger,Create procedure,Create view等语句同一个批处理中只能提交一个;D选项,不能把规则和默认值绑定到表字段或自定义字段上之后,立即在同一个批处理中使用。
所以B选项正确。
Q5:


A选项,结果集为一个值,一般使用=、<、>等运算符;C选项,结果类似于一张虚拟表,父查询中只能使用EXISTS或NOT EXISTS;D选项,通常是利用UNION、EXCEPT、INTERSECT集合运算符实现两个表之间的数据查询。
Q6:

解析:学生书店图书,是三个实体,实体个数大于两个时为多元联系
(那个,可能有点没啥关系,一个班级多个学生,是一对多)
Q7:

解析:链接:
Q8:

解析: 先执行的是where,分组函数是在分组后(即group by)后才能起作用,所以where中的分组函数会报错!其实很多时候要么是语句语法问题,或者语句逻辑问题,要不是语句的优先级问题。
Q9:

解析:(同样觉得评论很好)

Q10:

解析:

Q11:

解析:视图是一个虚拟表,c错误,只是相当于临时表,对其中所引用的基础表来说,MySQL视图的作用类似于筛选,自然不能新建一个表。
Q12:

解析:

索引的组织方式是B++树索引,还是Hash索引与数据库的内模式有关。
Q13:

解析:链接:
游标是一种从包括多条数据记录的结果集中每次提取一条记录以便处理的机制,可以看做是查询结果的记录指针。A选项,游标允许定位在结果集的特定行;B选项,从结果集的当前位置检索一行或一部分行;C选项,支持对结果集中当前位置的行进行数据修改。
Q14:

解析:
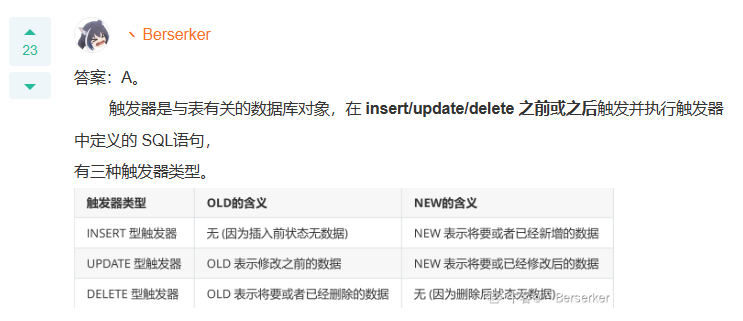
Q15:

解析:

解析:把叉乘看成叉烧了。
Q16:

解析:主要是这道的做法,我没什么见过。
Q17:

解析:这里的C选项,被修改的应该是参照表。参照表就是设置外键的,被参照表就是键被引用的那个表

Q18:

解析:

Q19:

解析:
这个记一下(恼
Q20:
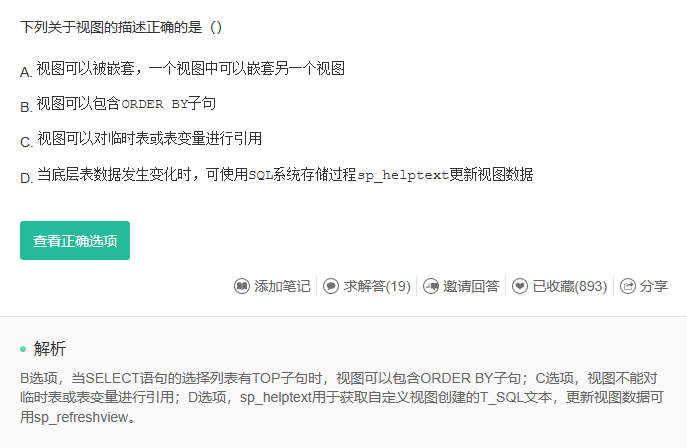

解析:意思大概就是,最好不要直接框定视图的定义,不要用order,不要用join,不要用distinct这些表示特定意思的。
Q21:

解析:选D
Q22:
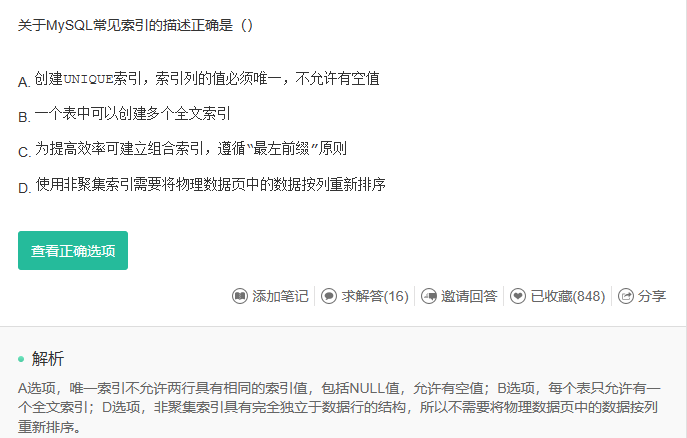

索引除了快没有其他的作用,数据库利用各种各样的快速定位技术,能够大大提高查询效率。特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍。
关于非聚集索引:聚集索引与非聚集索引的总结 - {-)大傻逼 - 博客园 (cnblogs.com)
聚集(clustered)索引,也叫聚簇索引。
定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
单单从定义来看是不是显得有点抽象,打个比方,一个表就像是我们以前用的新华字典,聚集索引就像是拼音目录,而每个字存放的页码就是我们的数据物理地址,我们如果要查询一个“哇”字,我们只需要查询“哇”字对应在新华字典拼音目录对应的页码,就可以查询到对应的“哇”字所在的位置,而拼音目录对应的A-Z的字顺序,和新华字典实际存储的字的顺序A-Z也是一样的,
非聚集(unclustered)索引。
定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致。
Q23

数据库管理系统对并发事务不同的调度可能会产生不同的结果,比如两个事务T1和T2,先执行T1或者先执行T2产生的结果可能是不一样的。由于串行调度没有事务间的相互干扰,所以串行调度是正确的。另外,执行结果等价于串行调度的调度也是正确的,称为可串行化调度。

Q24:


Q25:
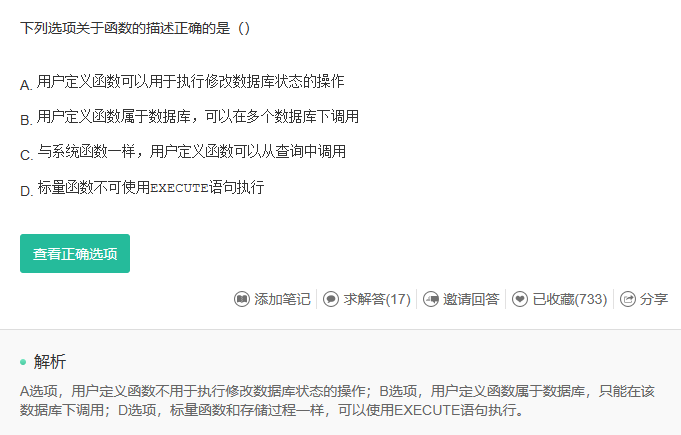
解析:
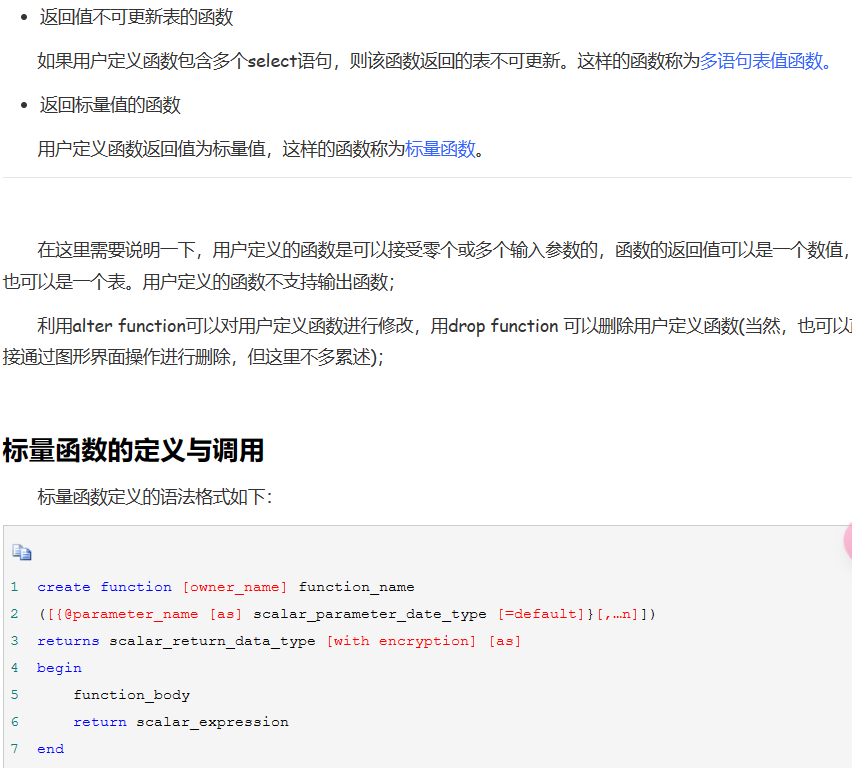
系统函数就是系统函数,日期函数之类的。

Q26:
Q27:
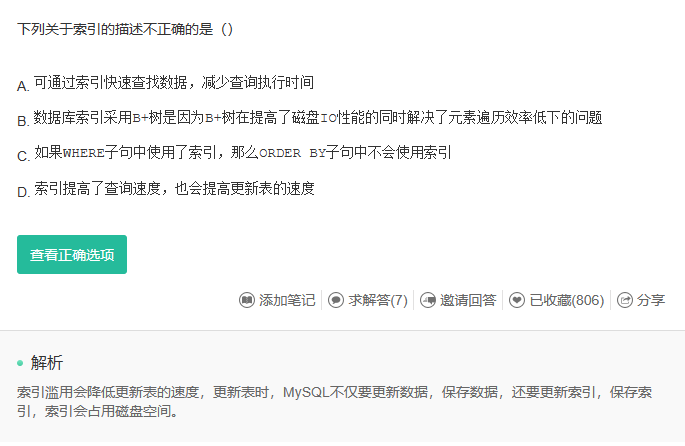
选d
Q28:
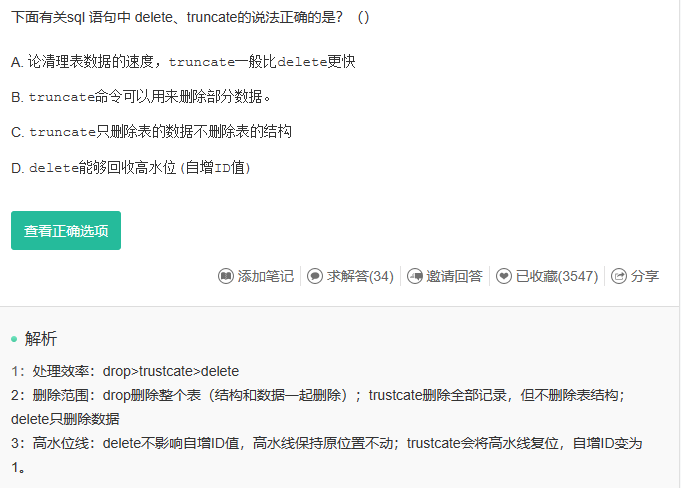
解析:
1:处理效率:drop>trustcate>delete
Q29:

解析:写一下union all 和union 的区别。
Q30:

解析:答案有问题,iracle是支持values的,mysql都支持。
Q31:
- 可串行化SERIALIZABLE:加锁后,如果发现其他用户正在对表进行操作,则本用户操作会被延迟(不能并行),直到对方COMMIT。如果等待时间过长,本用户会判超时,此次操作不会被执行
Q32:(懒得放题)

Q33:
(2)数据操纵(SQL DML)数据操纵分成数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。
(3)数据控制(DCL)包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。
最后:
写完了,太好了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号