
《机器学习》第一次作业——第一至三章学习记录和心得
第一章 模式识别基本概念
1.模式识别
概念:
根据已有知识的表达或者说是函数映射,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值,是一种推理过程,可划分为“分类”和“回归”两种形式。
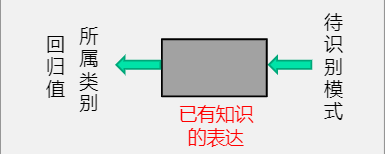
模型:
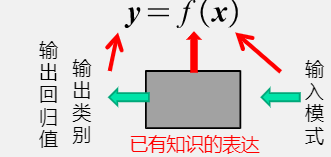
已有知识的表达方式,即f(x)。
模式识别任务的模型通过机器学习获得。
2.机器学习
概念:
利用训练样本,对目标函数进行学习优化(学习参数、模型结构等),得到理想的模型的过程。

3.模型质量的评价
泛化能力:
即训练得到的模型不仅要对训练样本有决策能力,也要对新的模式具有决策能力。
提升泛化能力的具体思路:不要过度训练,选择复杂度合适模型;通过调节正则系数,降低过拟合的程度

4.模型性能评估
留出法

K折交叉验证

留一验证

第二章 基于距离的分类器
1.MED分类器
基于欧式距离作为距离度量,没有考虑特征变化的不同及特征之间的相关性。
import pandas as pd
from sklearn.model_selection import train_test_split
from scipy.spatial.distance import euclidean
import numpy as np
import ai_utils
DATA_FILE = './data_ai_practice/fruit_data.csv'
FRUIT_NAME = ['apple','mandarin','orange','lemon']
FEAT_COLS = ['mass','width','height','color_score']
def get_pred_label(test_sample_feat,train_data):
"""
“近朱者赤” 找最近距离的训练样本,取其标签作为预测样本的标签
"""
dis_lis =[]
for idx,row in train_data.iterrows():
#训练样本特征
train_sample_feat = row[FEAT_COLS].values
计算距离
dis = euclidean(test_sample_feat,train_sample_feat)
dis_lis.append(dis)
最小距离对应的位置
pos = np.argmin(dis_lis)
pred_label = train_data.iloc[pos]['fruit_name']
return pred_label
def main():
"""
主函数
"""
#读取数据集
fruit_data = pd.read_csv(DATA_FILE)
划分数据集
train_data,test_data=train_test_split(fruit_data,test_size=1/5,random_state=10)
预测对的个数
acc_count = 0
分类器
for idx,row in test_data.iterrows():
#测试样本特征
test_sample_feat = row[FEAT_COLS].values
预测值
pred_label = get_pred_label(test_sample_feat,train_data)
真实值
true_label = row['fruit_name']
print('样本{}的真实标签{},预测标签{}'.format(idx,true_label,pred_label))
if true_label == pred_label:
acc_count += 1
准确率
accuracy = acc_count/test_data.shape[0]
print('预测准确率{:.2f}%'.format(accuracy*100))
解决方法:
使用特征白化去除特征变化的不同及特征之间的相关性。
欧氏距离进行特征白化后为马氏距离。
2.特征白化
目的:将原始特征映射到一个新的特征空间,使得在新空间中特征的协方差矩阵为单位矩阵,从而去除特征变化的不同及特征之间的相关性
过程:特征转化的过程:将特征转化分为两步:先去除特征之间的相关性(解耦),然后再对特征进行尺度变化(白化)。令W=W1W2,解耦:通过W1实现协方差矩阵对角化,去除特征之间的相关性。白化:通过W2对上一步变换后的特征再进行尺度变换实现所有特征具有相同方差。
3.MICD分类器
基于马氏距离,经过特征正交白化,去除特征变化的不同及特征之间的相关性,缺陷是会选择方差较大的类。
判别公式:
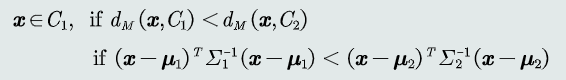
第三章 贝叶斯决策与学习
1.贝叶斯规则:
已知先验概率和观测概率,模式𝒙属于类𝐶𝑖后验概率的计算公式为:

2.分类器
MAP分类器
将测试样本决策分类给后验概率最大的那个类。给定所有测试样本, MAP分类器选择后验概率最大的类,等于最小化平均概率误差,即最小化决策误差。

贝叶斯分类器
在MAP分类器基础上,加入决策风险因素,得到贝叶斯分类器,给定一个测试样本𝒙,贝叶斯分类器选择决策风险最小的类。
给定所有测试样本 {𝒙},贝叶斯分类器的决策目标: 最小化期望损失。
3.监督式学习
参数化方法:给定表达式,学习表达函数中的参数。
4.最大似然估计
给定的𝑁个训练样本都是从𝑝(𝒙|𝜃)采样得到的、且都符合iid条件,则所有样本的联合概率密度为:
该函数称为似然函数
学习参数𝜃的目标函数:使得该似然函数最大

贝叶斯估计
给定参数𝜃分布的先验概率以及训练样本,估计参数θ分布的后验概率

5.KNN估计
给定𝒙,找到其对应的区域𝑅使其包含𝑘个训练样本,以此计算𝑝(𝒙) 。
优缺点:可以自适应的确定𝒙相关的区域𝑅的范围,但不是真正的概率密度表达,概率密度函数积分是 ∞ 而不是1。且容易受到噪声污染。

直方图方法
将特征空间分为m个格子,固定区域R的大小,计算𝒙属于哪个格子,计算所在格子的样本数。以此计算𝑝(𝒙)。
优缺点:减少由于噪声污染造成的估计误差,但是会受到区域交界处样本的影响,并且缺乏自适应能力。

核密度估计
以𝒙为中心固定带宽h,计算落入R的样本个数,以此计算𝑝(𝒙)。
优缺点:可以自适应确定R的代销,克服了KNN估计存在的噪声影响。但是要储存所有训练样本,耗费空间大。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号