大模型的原理学习(二)
(一) 介绍
(二) 损失函数
(三) CNN
(四) RNN
(五) Transformer架构
(六) GPT
(七) 幻觉问题
(八) RAG
(九) MCP
(十) Skills
第一篇链接回顾: 大模型的原理学习(一)
在第二篇中,我们开始学习下损失函数和拟合的概念。
拟合与损失函数
如何判断拟合的好不好?
损失函数或者代价函数(损失函数的平均值)

损失函数:
1、 均方误差
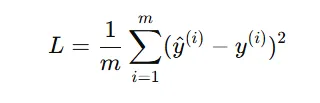
2、 二分类交叉熵
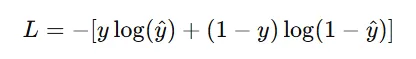
如何优化?
梯度下降法
目标:使得代价函数尽可能小,那就要求偏导
函数 =
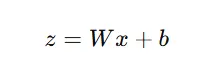
经过激活函数=
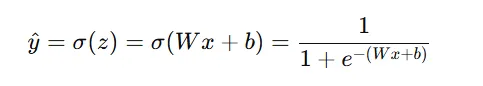
① 计算损失函数 ,选用二分类交叉熵 得到
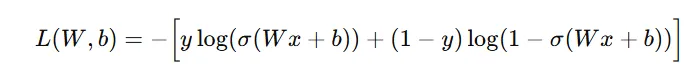
② 对损失函数中的 w 和 b 求偏导,偏导的作用代表的就是参数变化最快的方向,设置一个步长(学习率 η)
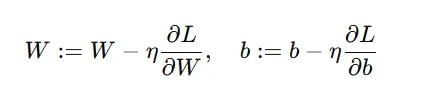
③ 更新参数:每经过一次计算,得到一个 W 和 b 就带入一下计算损失函数,看看损失函数有没有变小,如果变小了,说明本次 w 和 b 的调整是有效的,就更新 w 和 b
④ 继续重复 ①~③ 步骤,直到损失函数达到最小。
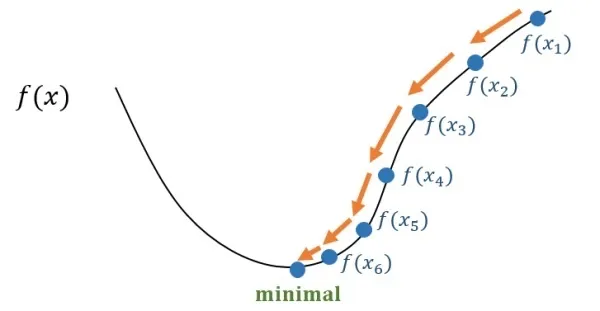
在神经网络中,是如何通过一层层隐藏函数,最终找出最优的输出?
前向传播:根据输入 x 计算出预测值 y
反向传播:计算预测值与实际值的损失函数,进行梯度优化
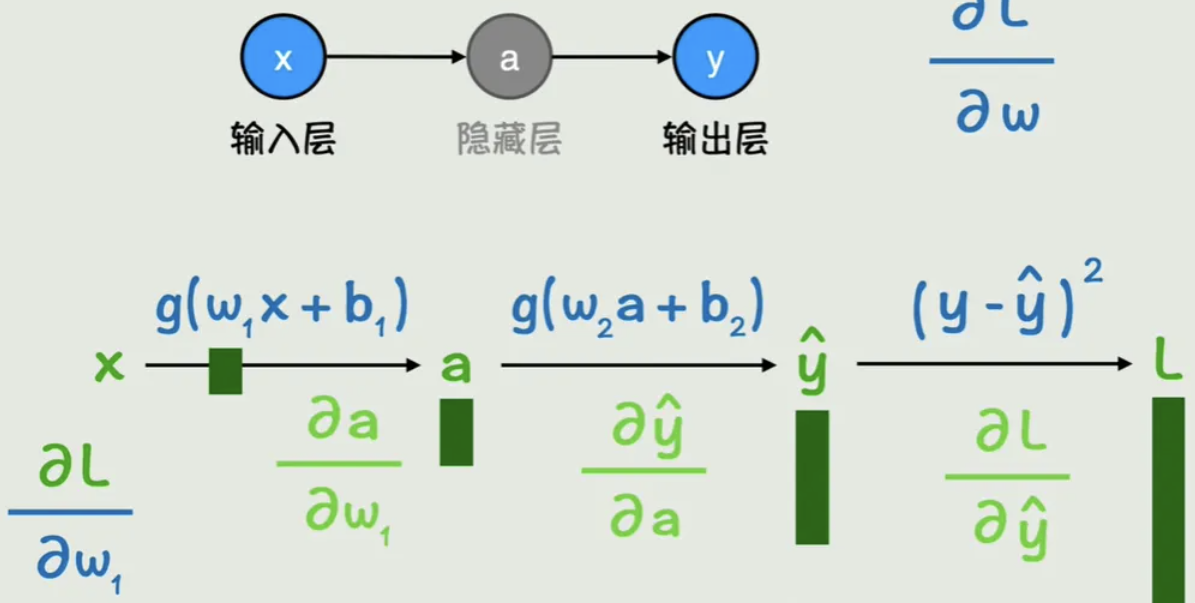
链式法则
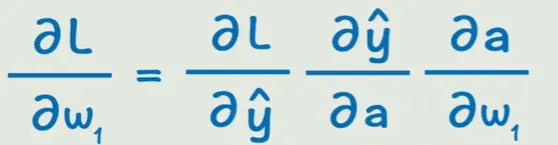
第三篇,我们将开始学习卷积神经网络的原理
卷积神经网络(Convolutional Neural Network, CNN)
前面我们都是以一个输入经过神经网络得到一个输出为例,那么当输入很多的时候,神经网络面临什么问题呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号