【1.109】继承--查找继承的属性(数据和函数)顺序
这里需要补充一下python中类的种类(继承需要):
在python2x版本中存在两种类.:
⼀个叫经典类. 在python2.2之前. ⼀直使⽤的是经典类. 经典类在基类的根如果什么都不写.
⼀个叫新式类. 在python2.2之后出现了新式类. 新式类的特点是基类的根是object类。
python3x版本中只有一种类:
python3中使⽤的都是新式类. 如果基类谁都不继承. 那这个类会默认继承 object
虽然在python3中已经不存在经典类了. 但是经典类的MRO最好还是学⼀学.
这是⼀种树形结构遍历的⼀个最直接的案例. 在python的继承体系中.
我们可以把类与类继承关系化成⼀个树形结构的图.
java c 只能继承一个类
多个类 顺序
如果经典类 就是深度优先 就是从左 的下到底 然后再从右的下到底减一
如果是新式类 就是广度优先 从左 的 下到 底减一 然后再从右的下到底
1、子类 先于 父类被检查
2、多个父类 会根据 他们在列表中的顺序被检查
3、如果对于下一个类存在两个合法的选择,选择第一个父类
#coding:utf-8 class A: # def test(self): # print('A') pass class B(A): # def test(self): # print('B') pass class C(A): # def test(self): # print('C') pass class D(B): # def test(self): # print('D') pass class E(C): # def test(self): # print('E') pass class F(D,E): # def test(self): # print('F') pass # f1=F() # f1.test() #经典类:F->D->B->A-->E-->C 这在 python 2 执行查找顺序 #新式类 print(F.__mro__) #(<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>,
<class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
#F-->D->B-->E--->C--->A
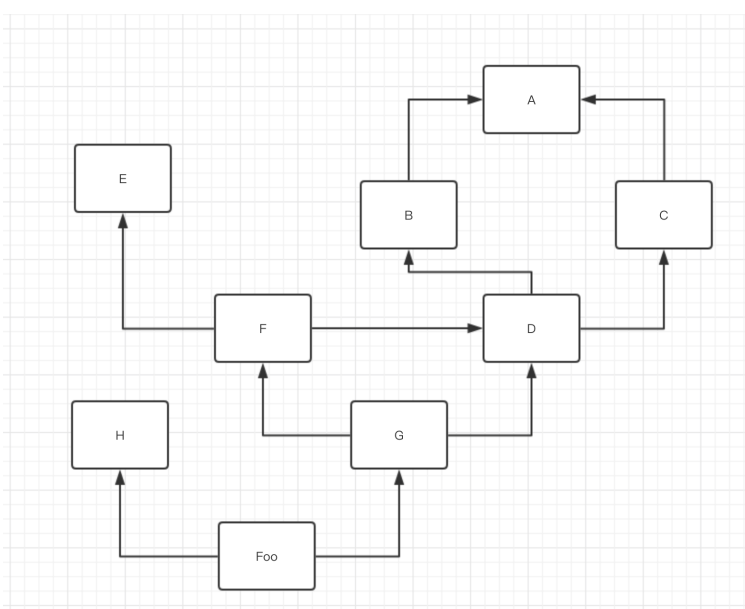
上图的新式类 也就是广度优先 继承查找顺序: # foo -- H G F E D B C A
由于 这里 H E 都是基类 且继承者只有以及继承 所以同父类时 先选择先继承的父类 一般先继承的父类都在左边
mro 是按照 c3 算法:后面有讲
那C3到底怎么看更容易呢? 其实很简单. C3是把我们多个类产⽣的共同继
承留到最后去找. 所以. 我们也可以从图上来看到相关的规律. 这个要⼤家⾃⼰多写多画图就
能感觉到了. 但是如果没有所谓的共同继承关系. 那⼏乎就当成是深度遍历就可以了
如果是经典类 就是深度优先 顺序: foo--H--G---F---E--D--B--A--C
A 这里 在经典类中 A 就必须先找 因为他用深度优先
简单. 记住. 从头开始. 从左往右. ⼀条路跑到头, 然后回头. 继续⼀条路跑到头. 就是经典类的MRO算法.
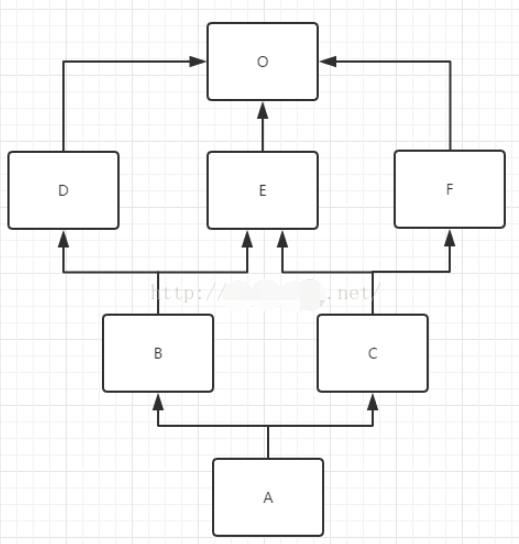
mro(A) = mro( A(B,C) )
原式= [A] + merge( mro(B),mro(C),[B,C] )
mro(B) = mro( B(D,E) )
= [B] + merge( mro(D), mro(E), [D,E] ) # 多继承
= [B] + merge( [D,O] , [E,O] , [D,E] ) # 单继承mro(D(O))=[D,O]
= [B,D] + merge( [O] , [E,O] , [E] ) # 拿出并删除D
= [B,D,E] + merge([O] , [O])
= [B,D,E,O]
mro(C) = mro( C(E,F) )
= [C] + merge( mro(E), mro(F), [E,F] )
= [C] + merge( [E,O] , [F,O] , [E,F] )
= [C,E] + merge( [O] , [F,O] , [F] ) # 跳过O,拿出并删除
= [C,E,F] + merge([O] , [O])
= [C,E,F,O]
原式= [A] + merge( [B,D,E,O], [C,E,F,O], [B,C])
= [A,B] + merge( [D,E,O], [C,E,F,O], [C])
= [A,B,D] + merge( [E,O], [C,E,F,O], [C]) # 跳过E
= [A,B,D,C] + merge([E,O], [E,F,O])
= [A,B,D,C,E] + merge([O], [F,O]) # 跳过O
= [A,B,D,C,E,F] + merge([O], [O])
= [A,B,D,C,E,F,O]
---------------------
那C3到底怎么看更容易呢? 其实很简单. C3是把我们多个类产⽣的共同继
承留到最后去找. 所以. 我们也可以从图上来看到相关的规律. 这个要⼤家⾃⼰多写多画图就
能感觉到了. 但是如果没有所谓的共同继承关系. 那⼏乎就当成是深度遍历就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号