NO.3 4 章 模拟、算法初步
NO.3章 入门篇(1)——入门模拟
1. 输入“2 a”
1 scanf("%d", &n); 2 getchar(); //scanf("%c", &sig) 可以收空格,即sig==' ',所以需用getchar()来接住 3 sig=getchar();
2. 四舍五入
因为'round': identifier not found,不能从<cmath>中调进来,需自己定义
法一:宏定义
法二:inline 函数
inline double round( double d ){ return floor( d + 0.5 ); //<cmath>里的函数:向上取整:floor(double);向下取整:ceil(double) }
法三:用于对 整数/2 之后的值四舍五入
if(n%2==1) m=n/2+1; //n为奇数,向上取整(0.5) else row=n/2;
3. 对数组中的元素赋相同的值 (int a[];)
法一:memset(a, 0, sizeof(a)); 法二:#define bzero(a, size) (void)memset((p), 0, (size))
4. sqrt() 函数相关
'sqrt' : ambiguous call to overloaded function. 此处涉及到C++函数重载的概念。
当编译器看到sqrt(4)的时候,它会试图去找一个sqrt(int)的函数,但是找不到。于是退而求其次,找一个可以从int转换过去的sqrt,结果一下找到了两个。一个是sqrt(long double),另一个是sqrt(float)。
编译器认为把int转换成long double或者float都很合理,于是编译器就晕菜了,不知道程序员的真正意图到底是要用哪一个。
解决:使用 sqrt(long double)、sqrt(float),或sqrtf()。 法一:sqrt(4.0) //因为4.0不是int,编译器不需要做转换,直接用对应的就行了 法二:sqrtf(4) //因为sqrtf只有一个函数原型sqrtf(float),就直接把int转换成float了
5. 有多组测试数据时
输入n,输入n个不同的数...;
输入n,输入n个不同的数...;
...多组测试
while(scanf("%d", &n) != EOF){ //EOF: end of the file for(int i=0; i<n; i++) scanf("%d", a[i]); }
6. 日期处理
(1)定义——平年和闰年每个月的天数
int month[13][2]={ {0,0}, {31,31}, {28,29}, {31,31}, {30,30}, {31,31}, {30,30}, {31,31}, {31,31}, {30,30}, {31,31}, {30,30}, {31,31} }
(2)判断是否为闰年
bool isLeap(int year){ return (year%4==0 && year%100!=0) //1996 || (year%400==0) //2000 }
(3)eg. 求日期time1和time2的差值
int time1, y1, m1, d1; //设:总日期,年,月,日 int time2, y2, m2, d2;
7. 进制转换
(1)P进制x -> 十进制y
int y=0, product=1; //product=1, p, p^2, p^3... while(x!=0){ y=y + (x%10)*product; //x%10:每次获取x的个位 x=x/10; //去掉x的个位 product*=p; }
(2)十进制y -> Q进制z ("除基取余法" 基:要转换成的进制Q)
int z[40], num=0; //数组z存放Q进制y的每一位 do{ //do...while使满足:y=0时,z[0]=0 z[num++] = y%Q; //从后往前输出,即Q进制数z y = y/Q; }while(y!=0);
8. 字符串处理——判断回文串
只需遍历字符串的前一半(不需要取到 i==len/2 ):
若出现字符 str[i] != str[len-1-i],则不是回文串;若前一半的所有字符 str[i]==str[len-1-i],则是回文串。
(1)while( gets(str) ) {}; //输入一整行字符串,包括空格;此处输入多行 (2)int len=strlen(str); //取字符串长度
9. 字符数组 -> 字符串
在空格的位置添加字符串结束符:"\0" (eg. 见PAT(B) 1009)
char str[10]; gets(str); //输入一整行字符串,包括空格,以换行结束 int k=0, len=strlen(str); for(int i=0; i<len; i++) { if(str[i] != ' ') ana[k++]=str[i]; else ana[k++]='\0'; //字符串结束符 } ana[k++]='\0'; printf("%s", ana); //字符数组 -> 字符串
补充:
1. 'srandom': identifier not found
在vc++中程序中用了srandom()和random(),头文件为stdlib.h
但编译出现错误-----error C3861: “srandom”: 找不到标识符。
原因是现在vc++编译器的库函数中没有srandom()和random(),分别用srand()和rand()代替了。
#include <stdlib.h> //定义杂项函数及内存分配函数,一般在用到rand()和srand()函数时需要包含此头文件
2. 'int64_t' : undeclared identifier
解决:#include <stdint.h>,或者改为 int64_T
NO.4章 入门篇(2)——算法初步
1. 排序
1)选择排序
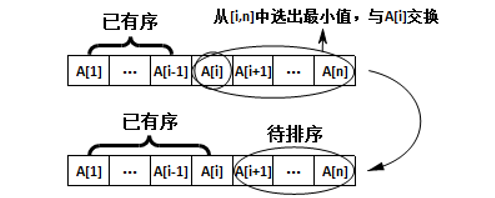
1 //选择排序 2 void selectSort(char* A) { //n趟操作 3 int n = strlen(A); 4 for (int i = 0; i < n; i++) { //选出[i, n]中最小的元素,下标为k 5 int k = i; 6 for (int j = i; j < n; j++) { 7 if (A[j] < A[k]) { 8 k = j; //k指向最小的元素 9 } 10 } 11 int temp = A[i]; //交换A[k]与A[i] 12 A[i] = A[k]; 13 A[k] = temp; 14 } 15 }
2)插入排序



1 //插入排序 2 void insertSort(char* A) { 3 int n = strlen(A); //n为元素个数 4 for (int i = 1; i < n; i++) { //进行n-1趟排序 5 int temp = A[i], j = i; //temp临时存放A[i],j从i开始往前枚举 6 while (j > 0 && temp < A[j - 1]) { //当temp小于前一个元素A[j-1] 7 A[j] = A[j - 1]; //把A[j-1]后移一位至A[j] 8 j--; 9 } 10 A[j] = temp; //将temp插入位置j 11 } 12 }
3)sort()的应用


1 //sort()的应用 2 //(1)相关结构体的定义 3 struct Student { 4 char name[10]; 5 char id[10]; 6 int score; 7 int r; //排名 8 }stu[maxlen]; 9 10 //(2)cmp函数的编写 11 //两个学生分数不同,则分数高的排在前面 12 //否则(分数相同),则姓名字典序小的排在前面 13 bool cmp(Student a, Student b) { 14 if (a.score != b.score) return a.score > b.score; 15 else return strcmp(a.name, b.name); 16 //strcmp(str1, str2):比较两个char[]的字典序大小 17 //字典序:str1<str2时返回负数;str1==str2时返回0;str1>str2时返回正数 18 } 19 //main()中:sort(stu, stu+n, cmp); //按cmp()设定的规则排序 20 21 //(3)记录个体的排名:分数相同排名相同,但占用一个排位 22 //法一 23 void rank1(Student* stu, int n) { 24 stu[0].r = 1; 25 for (int i = 1; i < n; i++) { 26 if (stu[i].score == stu[i - 1].score) { 27 stu[i].r = stu[i - 1].r; 28 } 29 else { 30 stu[i].r = i + 1; 31 } 32 } 33 } 34 //法二 35 void rank2(Student* stu, int n) { 36 int r = 1; 37 for (int i = 0; i < n; i++) { 38 if (i > 0 && stu[i].score != stu[i - 1].score) { 39 r = i + 1; 40 } 41 stu[i].r = r; //或直接输出排名 42 } 43 }
2. 哈希(散列)
散列的定义与整数散列
- 题目要求:M个预查询的数中每个数在N个数中出现的次数
- 思路:设定一个int型数组 hashTable[10010] ,然后在输入 N 个数时进行预处理,即当输入的数为 x 时 ,hashTable[x]++,时间复杂度为 O(N+M)
#include <cstdio> int main() { int n, m, x; scanf("%d%d", &n, &m); for (int i = 0; i<n; i++) { scanf("%d", x); hashTable[x]++; // 记录每个数出现次数 } for (int i = 0; i<m; i++) { // 输出 M 个数中每个数在 N 个数中出现的次数 scanf("%d", x); printf("%d\n", hashTable[x]); } return 0; }
注:可能是10^9大小的整数,或者甚至是一个字符串,就不能将它们直接作为数组下标了
这时候可以使用散列,即 ” 将元素通过一个函数转换为整数,使得该整数可以尽量唯一的代表这个元素 “
- 常用的散列函数有 直接定址法、平方取中法、除留余数法(H(key) = key % mod)
- 解决冲突的方法:线性探测法、平方探测法、链地址法
字符串hash初步
字符串均由大写字母 A~Z 构成
- 不妨把 A~Z 视为 0~25 ,这样就把26个大写字母对应到二十六进制中
- 接着按照将二十六进制转换为十进制的思路,便可实现将字符串映射为整数的需求
int hashFunc(char S[], int len) { // hash 函数,将字符串 S 转换为整数 int id = 0; for (int i=0; i<len; i++) { id = id * 26 + (S[i] - 'A'); // 将二十六进制转换为十进制 } return id; }
字符串中出现小写字母 a~z
- 那么可以把 A~Z 视为 0~25 ,而把 a~z 视为 26~51
- 就变成了五十二进制转换为十进制的问题
int hashFunc1(char S[], int len) { // hash 函数,将字符串 S 转换为整数 int id = 0; for(int i=0; i<len; i++){ if(S[i] >= 'A' && S[i] <= 'Z') { // 大写字母 id = id*52 + (S[i] -'A'); } else if(S[i] >= 'a' && S[i] <= 'z') { // 小写字母 id = id*52 + (S[i] -'a') + 26; } } return id; }
字符串中出现了数字(两种方法)
- 按照小写字母的处理方法,增大进制数至62
- 如果保证在字符串的末尾是确定个数的数字,那么就可以把前面的英文字母的部分按上面的思路转换成整数,再将末尾的数字直接拼接上去。例如对由三个字符加一位数字组成的字符串 ”BCD4“ 来说,可以先将前面的 ”BCD“ 转换为整数 731 ,然后直接拼接上末位4变为7314即可
int hashFunc2(char S[], int len) { // hash 函数,将字符串 S 转换为整数 int id = 0; for(int i=0; i<len-1; i++) { id = id*26 + (S[i]-'A'); // 将二十六进制转换为十进制 } id = id*10 + (S[len-1] - '0'); // 拼接末位 return id; }
eg. 给出 N 个字符串(由恰好三位大写字母组成),再给出 M 个查询字符串,问每个查询字符串在N个字符串中出现的次数
- 将字符串转换为整数,然后利用上面的整数散列解决该问题
1 #include <cstdio> 2 const int maxn = 100; 3 char S[maxn][5], temp[5]; 4 int hashTable[26 * 26 * 26 + 10] = { 0 }; 5 6 int hashFunc(char S[], int len) { //哈希函数:将字符串 S 转换为整数 7 int id = 0; 8 for (int i=0; i<len; i++) { 9 id = id * 26 + (S[i] - 'A'); //len=3; 0*26 + 1*26 + 2*26 +... 10 } 11 return id; 12 } 13 int main() { 14 int n, m; 15 scanf("%d%d", &n, &m); 16 for (int i=0; i<n; i++) { 17 scanf("%s", S[i]); 18 int id = hashFunc(S[i], 3); // 将字符串s[i]转换为整数 19 hashTable[id]++; // 该字符串出现次数+1 20 } 21 for (int i=0; i<m; i++) { 22 scanf("%s", temp); 23 int id = hashFunc(temp, 3); //将temp转换为整数 id = id*26 + (S[i]-'A'); 24 printf("%d\n", hashTable[id]); // 输出该字符串出现次数 25 } 26 return 0; 27 }
3. 分治递归
分治
- 分解:将原问题划分为若干个规模较小而结构与原问题相同或相似的子问题
- 解决:递归求解所有子问题
- 合并:将子问题的解合并为原问题的解
递归
1)使用递归求解 n 的阶乘
// n! = 1*2*...*n int F(int n) { if(n==0) return 1; // 当到达递归边界F(0)时,返回F(0)==1 else return F(n-1)*n; // 递归式一直递归下去(没有到达递归边界时) }
2)求 Fibonacci 数列 的第 n 项
// Fibonacci 数列 : F(0)=1,F(1)=1...F(n)=F(n-1)+F(n-2) int F(int n) { if(n==0 || n==1) return 1; // 递归边界 else return F(n-1) * F(n-2); // 递归式 }
3)全排列
思路:将将原问题分解为若干个子问题 :输出以 1 开头的全排列,输出以 2 开头的全排列.....
1 #include <cstdio> 2 const int maxn = 11; 3 // n 输入个数,P 当前排列,hashTable 记录整数 x 是否在 P 中 4 int n, P[maxn], hashTable[maxn] = { false }; 5 6 // 当前处理排列的第 index 号位 7 void generateP(int index) { 8 if (index == n + 1) { // 递归边界,已经处理完排列的1~n位 9 for (int i = 1; i <= n; i++) { 10 printf("%d ", P[i]); // 输出当前排列 11 } 12 printf("\n"); 13 return; 14 } 15 for (int x = 1; x <= n; x++) { // 枚举 1~n 16 if (hashTable[x] == false) { // 若 x 还未填入,填入 P[index] 17 P[index] = x; // 填入x 18 hashTable[x] = true; // 标记 x 已在 P 中 19 generateP(index + 1); // 处理排列的第 index+1 号位 20 hashTable[x] = false; // 还原状态(已处理完P[index]的子问题) 21 } 22 } 23 } 24 int main() { 25 n = 3; // 欲输出 1~3 的全排列 26 generateP(1); // 从P[1]开始填 27 return 0; 28 }
4)n 皇后问题
在一个 n*n 的国际象棋棋盘上放置 n 个皇后,使得这 n 个皇后两两均不在同一行、同一列、同一条对角线上,求合法的方案数
法一:暴力
法二:回溯(思路:在全排列的基础上加上检查)
1 #include <cstdio> 2 const int maxn = 11; 3 // n 输入个数; P 当前排列; hashTable 记录整数x是否在P中 4 int n, P[maxn], hashTable[maxn] = { false }, cnt = 0; 5 6 // 处理第 index 列的皇后 7 void generateP(int index) { 8 if (index == n + 1) { // 递归边界,生成一个合法方案 9 cnt++; // 能到达此处一定合法 10 return; 11 } 12 for (int x = 1; x <= n; x++) { // 遍历第 x 行 13 if (hashTable[x] == false) { // 第 x 行还没有皇后 14 bool flag = true; // 判断新皇后会不会引起冲突 15 for (int pre = 1; pre<index; pre++) { // 遍历之前的皇后 16 //第index列皇后的行号为 x, 第pre列皇后的行号为 P[pre] 17 if (abs(index - pre) == abs(x - P[pre])) { 18 flag = false; // 与之前的皇后在一条对角线,冲突 19 break; 20 } 21 } 22 if (flag) { // 若可以把皇后放在第x行 23 P[index] = x; // 令 index 列皇后的行数为 x 24 hashTable[x] = true; // 标记第x行已被占用 25 generateP(index + 1); // 处理第 index+1 行的皇后 26 hashTable[x] = false; // 递归完毕,还原第x行为未占用 27 } 28 } 29 } 30 } 31 int main() { 32 n = 8; // 八皇后 33 generateP(1); 34 printf("count = %d \n", cnt); // n=8 时 ,count = 92 35 return 0; 36 }
4. 贪心
5. 二分
6. 双指针

 浙公网安备 33010602011771号
浙公网安备 33010602011771号