

1.4、Kibana使用说明
通过访问IP:5601即可
注:下列所有操作可结合elasticsearch-head进行学习
索引的创建删除操作
索引其实也可以理解成是一张表
索引创建
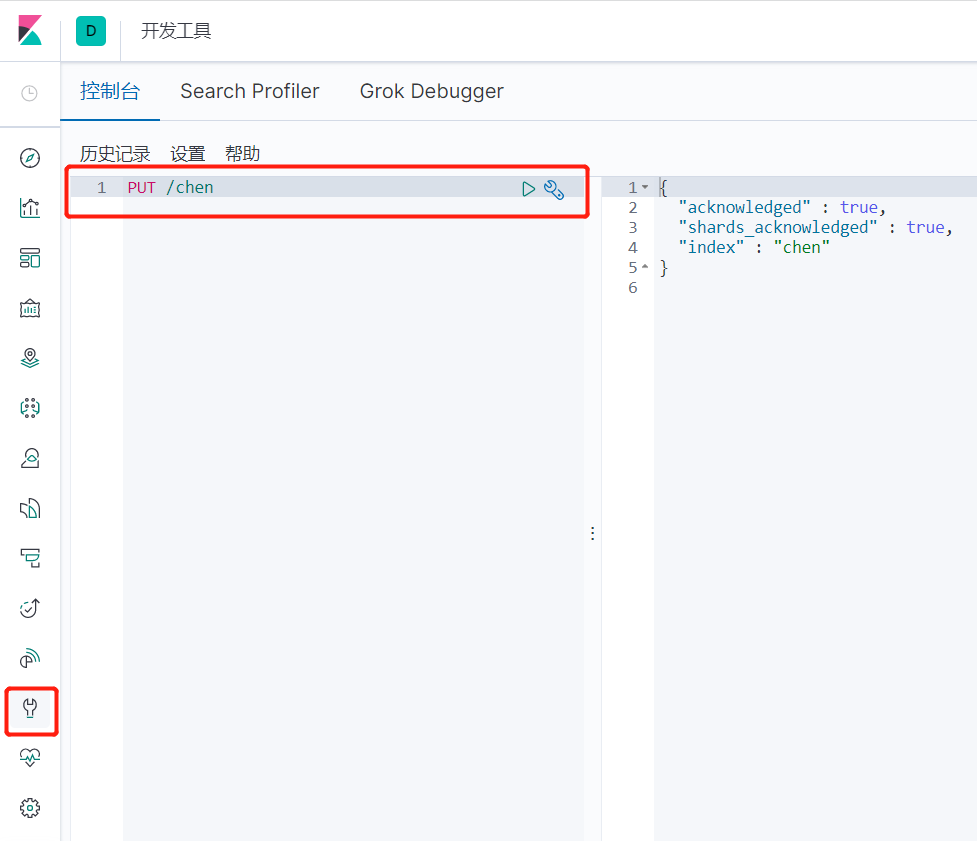
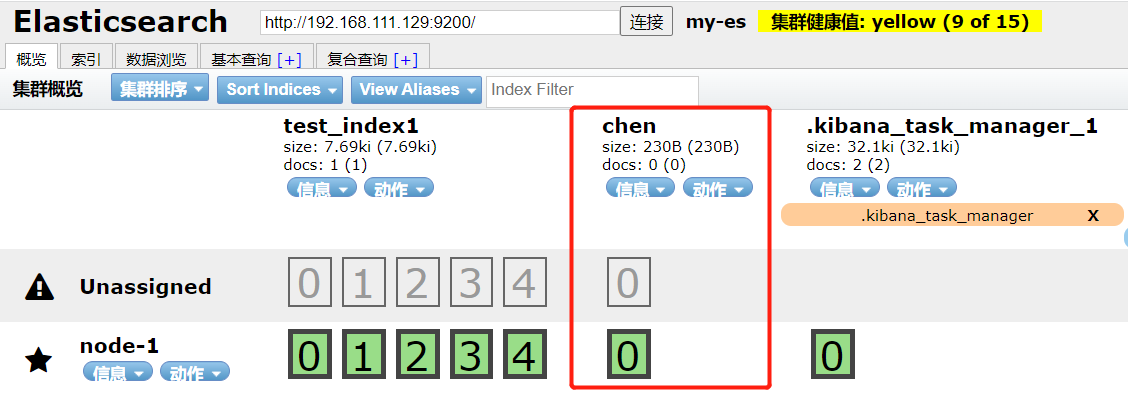
索引创建并赋值
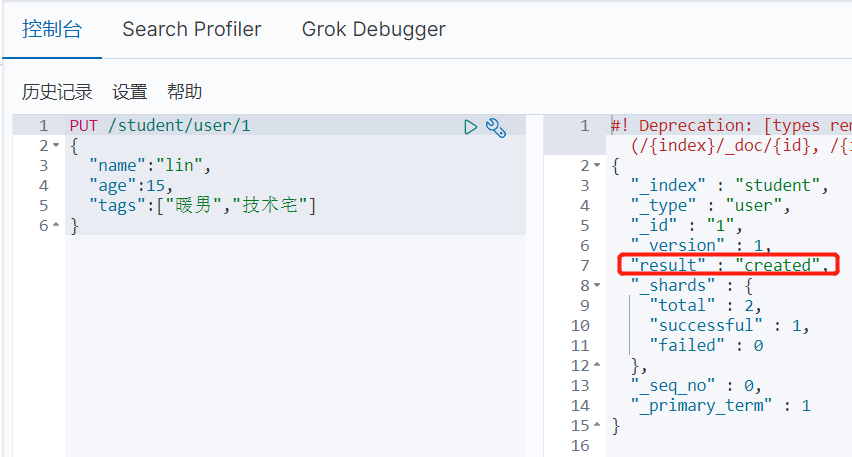
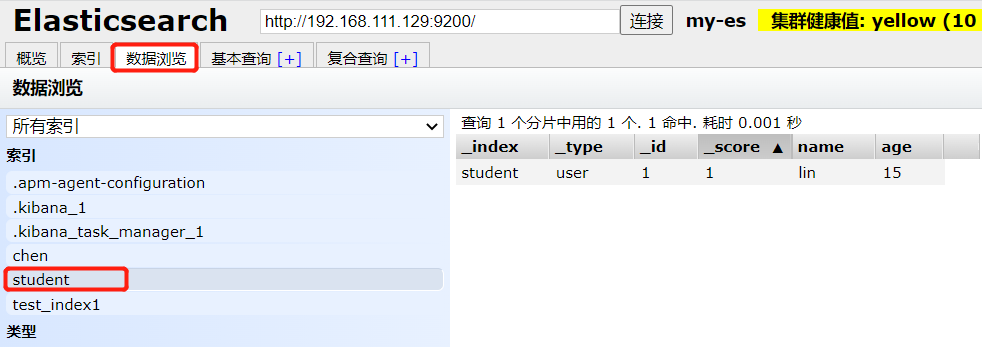
索引创建及定义属性
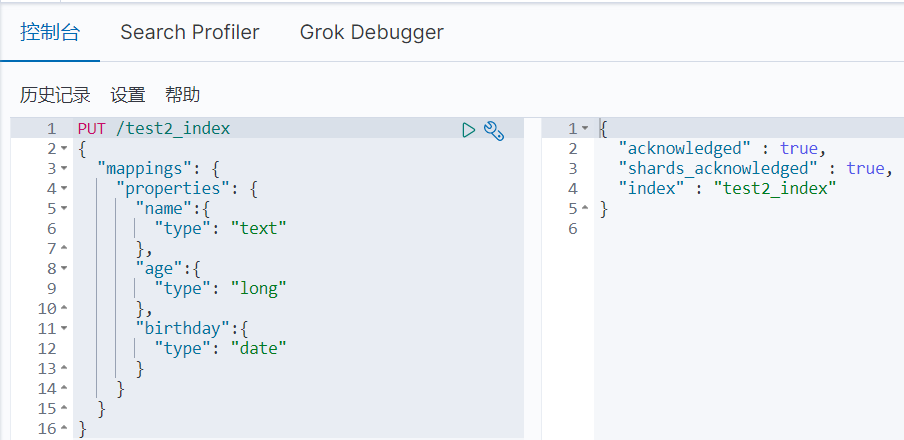
这里会涉及type为text类型,除了text类型,对于字符串还可以分配keyword类型,二者区别如下:
-
keyword类型的词语会被当成一个整体存储
-
text类型的词语则会被分词器拆分进行存储,中文是单个存储,英文是按照空格进行,在我们进行查找的时候默认都会进行拆分,这里的拆分规则和分词器字典无关
索引删除
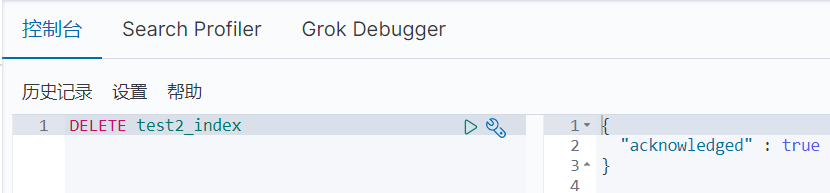
索引文档的增删改操作
增加索引文档
注:id需唯一,如果指向的是已存在的id,则会变为修改操作
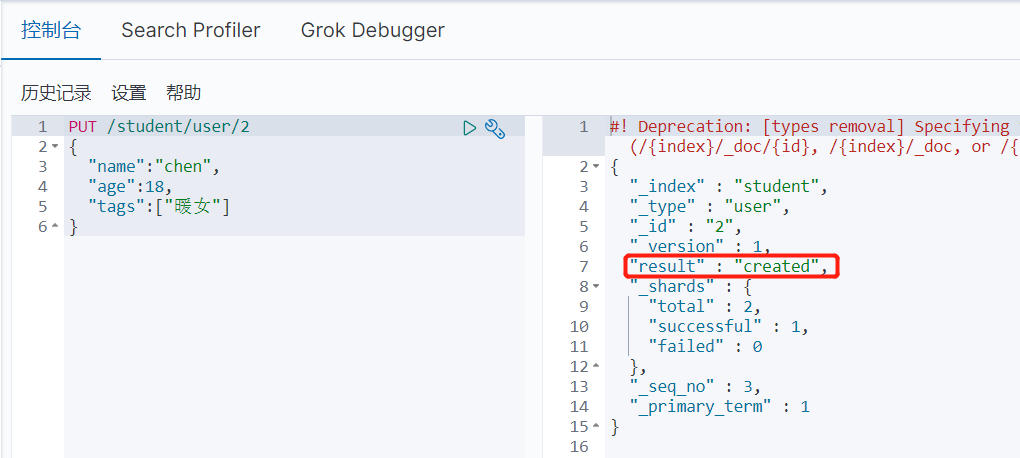
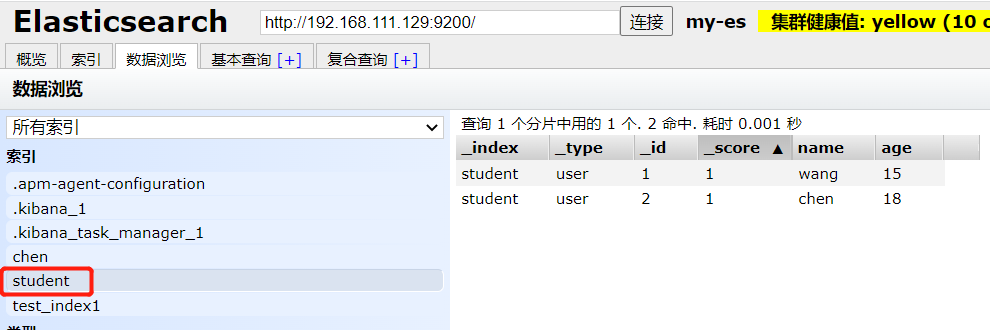
修改索引文档
虽然使用增加索引的方式也可以实现索引文档的修改,但是其实ES也提供了update方法来进行修改
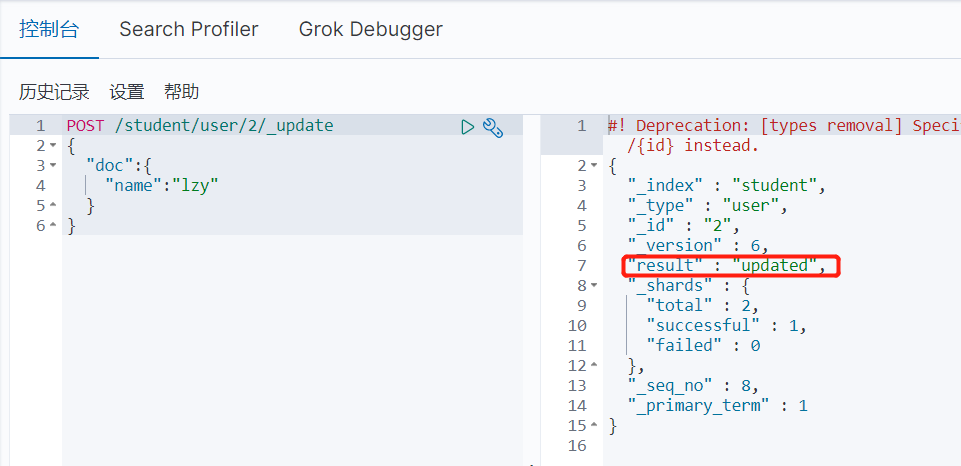
删除索引文档
其实删除索引和删除索引文档的区别就在于是否准确指定到具体的id,未指定则就会删除其索引
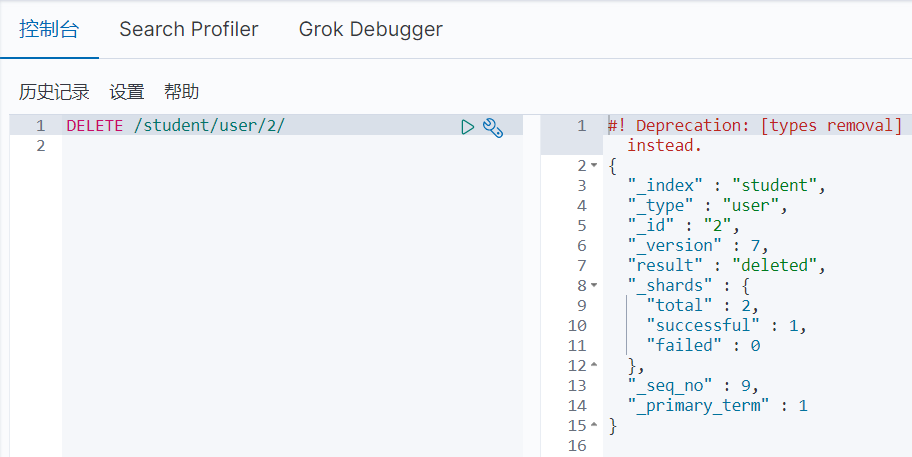
索引文档的简单查询
以下所有查询操作都基于该索引进行查询
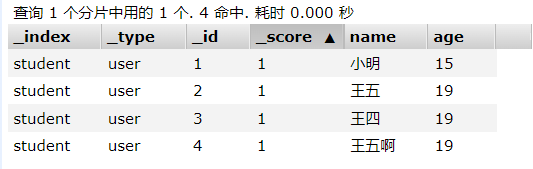
索引文档的条件查询
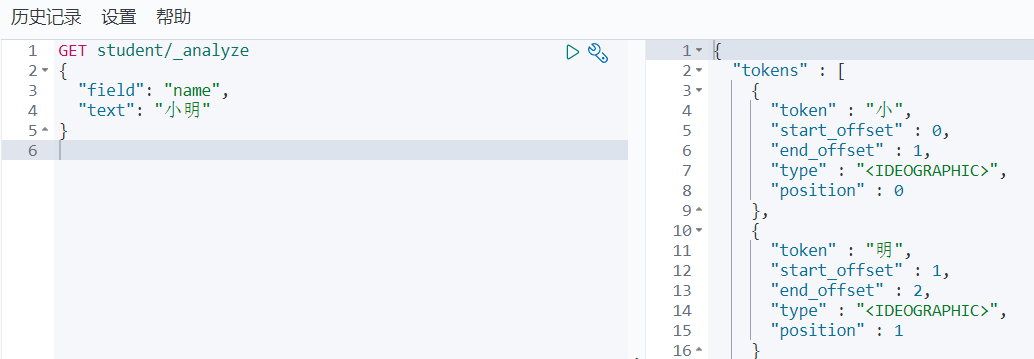
首先需要了解一点,我们的数据存储形式,在不考虑分词器的情况下
通过_analyze分析,默认text的存储形式是进行拆分存储,而keyword是不会进行拆分存储,这个其实上方创建索引并赋值时就有说明
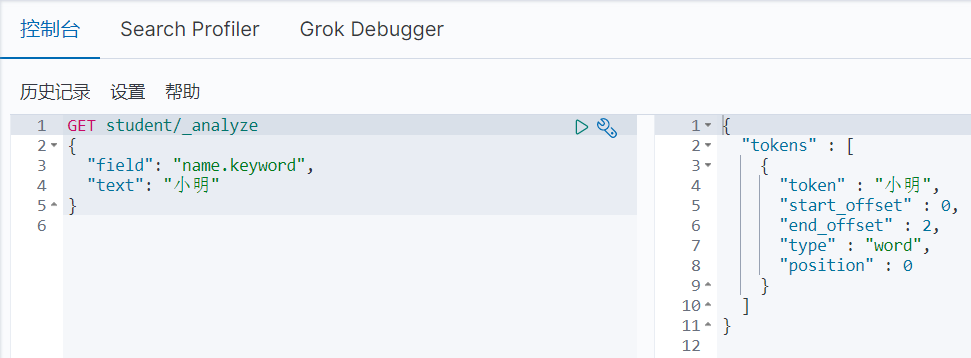
然后再来理解下Match和Term的区别
Match是模糊查询
Match查询时,我们的搜索词将会被分词进行查询
- 当查询text时,由于我们一句话是会拆分存储,搜索词也会被分词查询,所以只要包含任意字的都会被查出,也就是模糊匹配
- 当查询keyword时,由于我们一句话是不会被拆分存储,虽然搜索词分词了,但是因为存储词没有进行拆分,搜索词又必须对应上存储词,所以间接就成了精确匹配
Term是精确查询
Term查询时,我们的搜索词将不会被分词进行查询
- 当查询text时,由于我们一句话是会拆分存储,但是我们的搜索词又不会被分词,所以这时候我们只有单个字进行查询时才对应得上存储词的结果,间接也就成为了模糊匹配
- 当查询keyword时,由于我们一句话是不会被拆分存储,我们的搜索词也不会被分词,所以该情况就是精确匹配
总结
- 查询keyword:Match和Term查询都需要精确匹配
- 查询text:Match会进行分词查询,模糊匹配。Term只能通过单个字去进行查询,也是模糊匹配
注:汉语是一个字一个字分组,英文的话是以空格进行分组
通过下列例子可以进行更好的了解
Match模糊查询
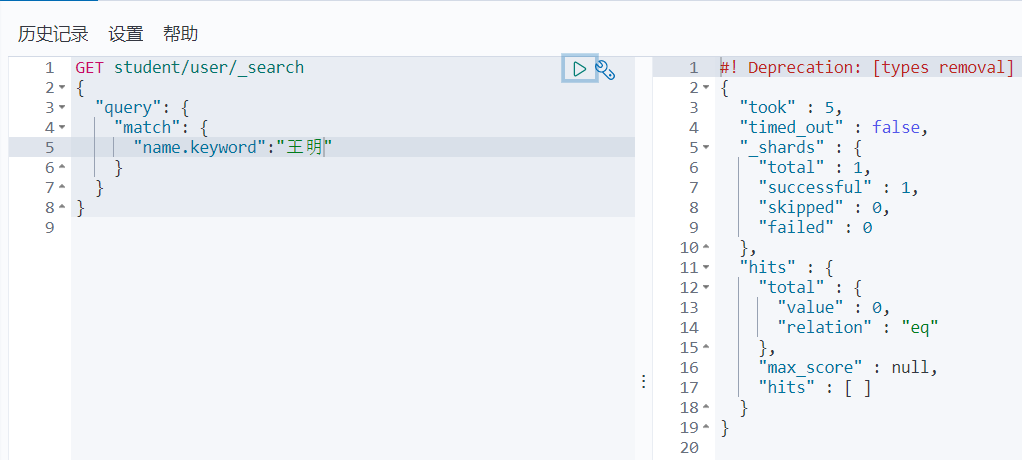
可以看出我们的搜索词是被分词进行查询的,又因为text也是拆分的,所以包含”王“和包含“明"的数据都被查出来了
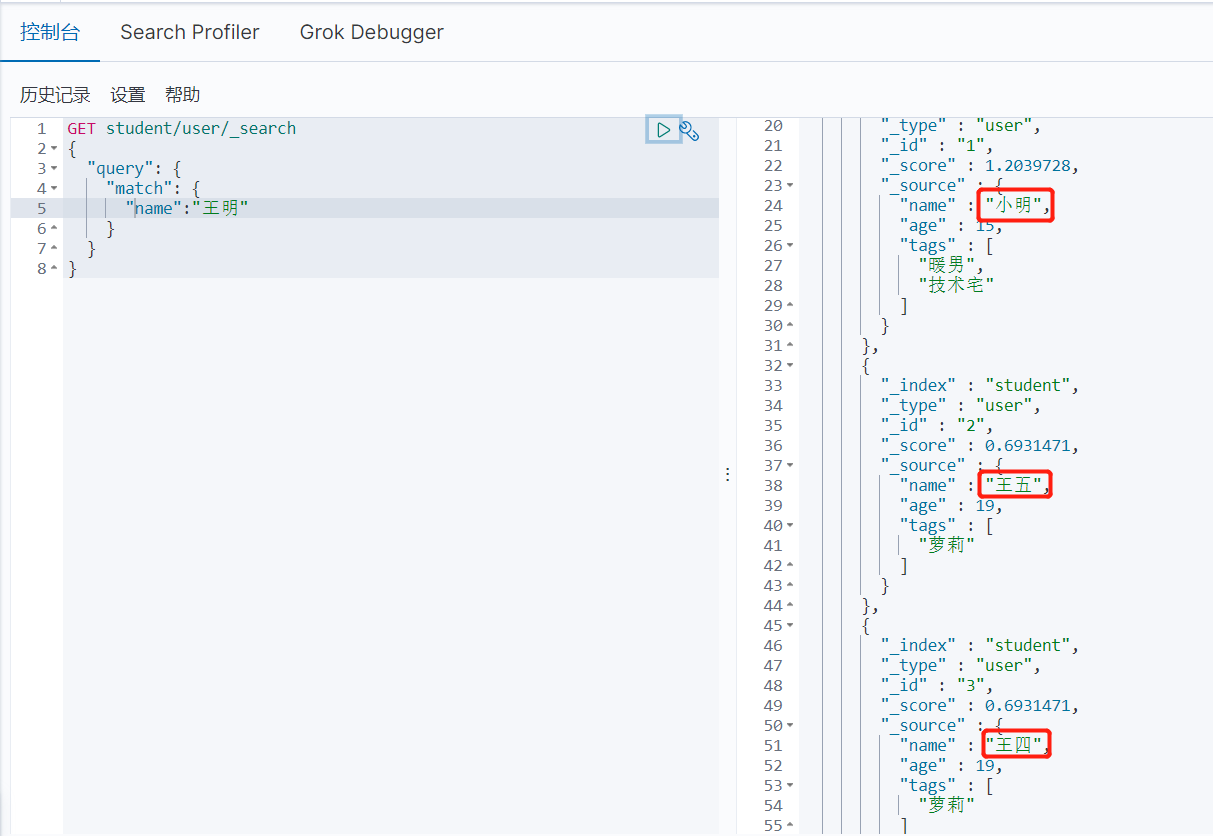
加上keyword后,虽然我们也是分词查询,但是索引数据是不拆分存储的,所以数据无法被查出来
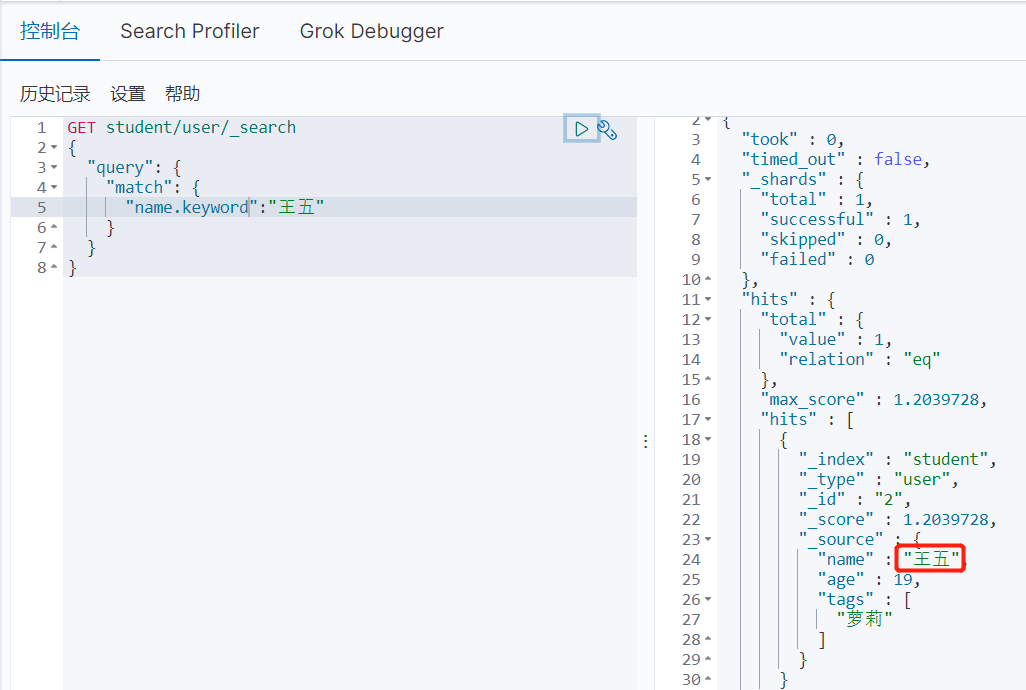
更换成别的查询条件后,可以发现,我们分词查询必须完全对应分词存储的数据,数据才会被查出来,也就是精确匹配
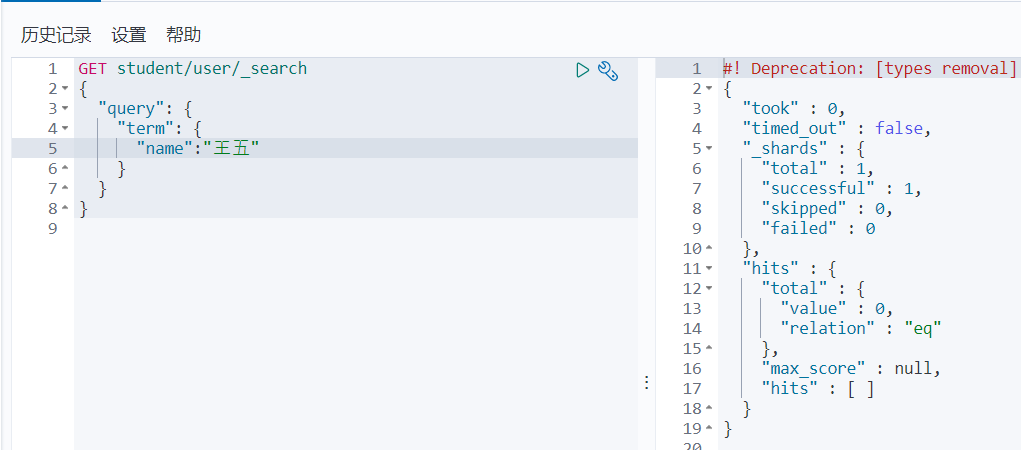
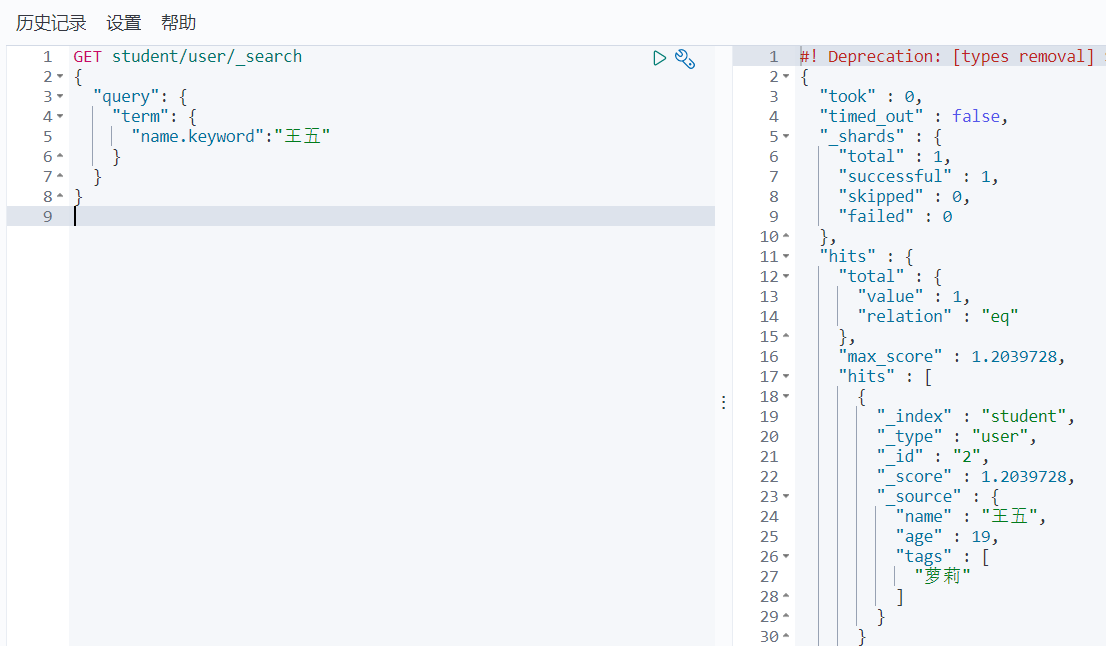
Term精确查询
可以看出,我们不分词查询,查分词存储,通过以下方式,是一个都无法对应上的
只有条件为单个字的时候才可以对应上
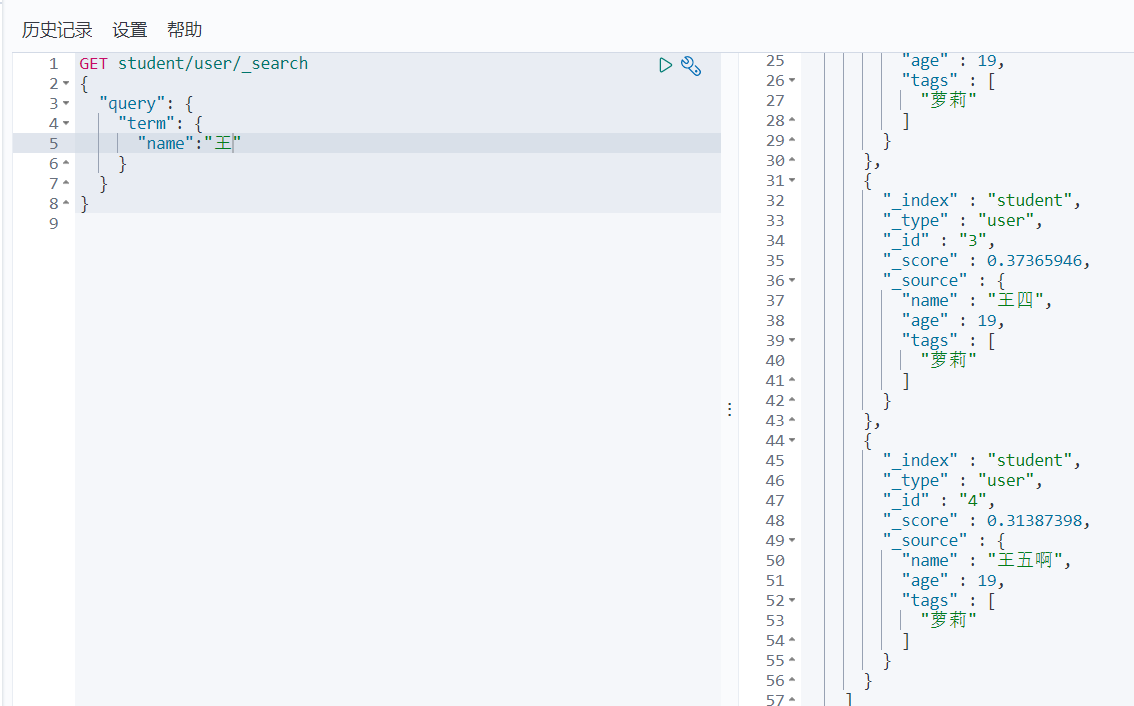
keyword的话,搜索词不分词,存储词不拆分,就只能是精确匹配了
其他方法说明
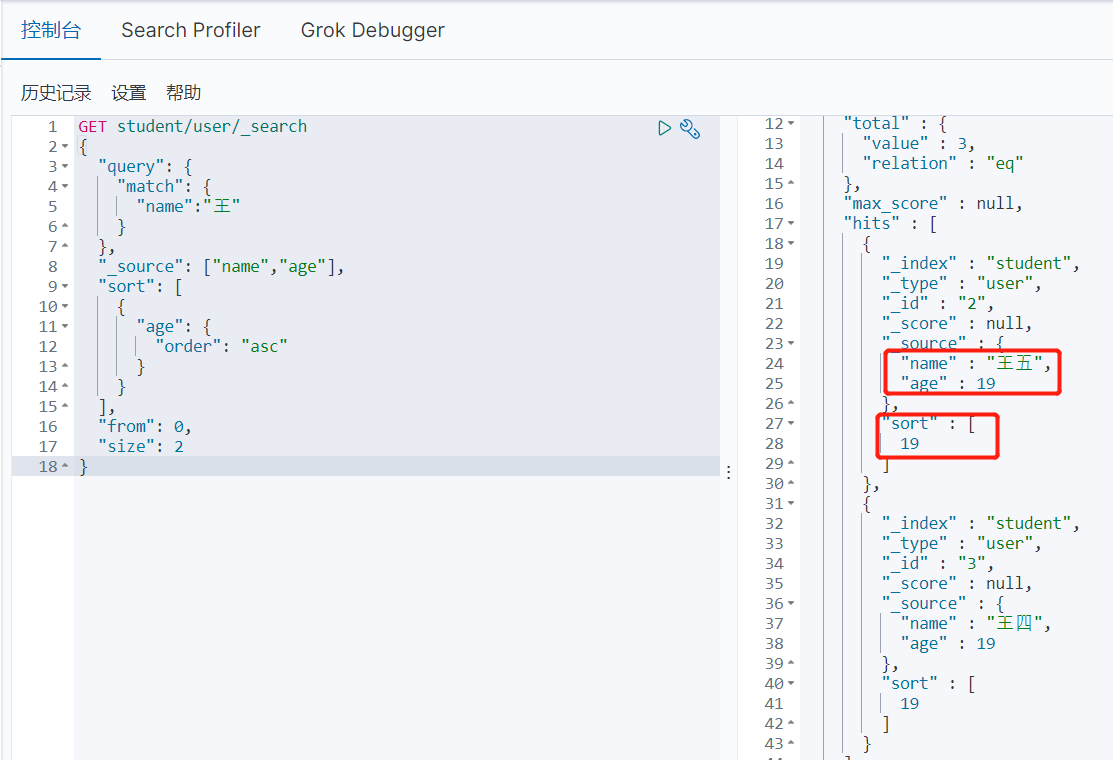
_source和sort
_source代表只输出指定属性,sort代表按照指定属性排序,from代表从第几个数据开始,size代表输出几个
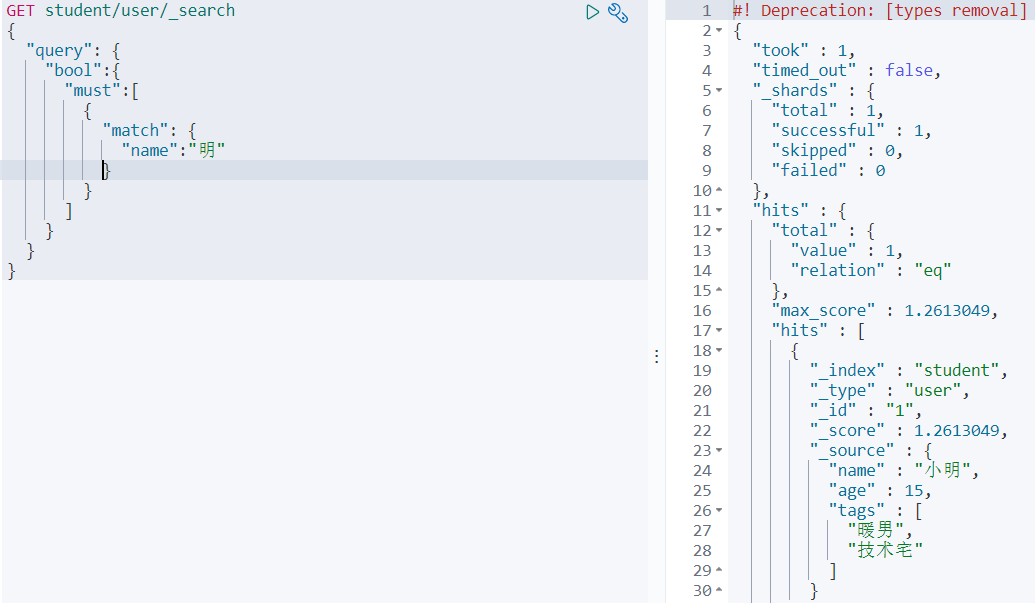
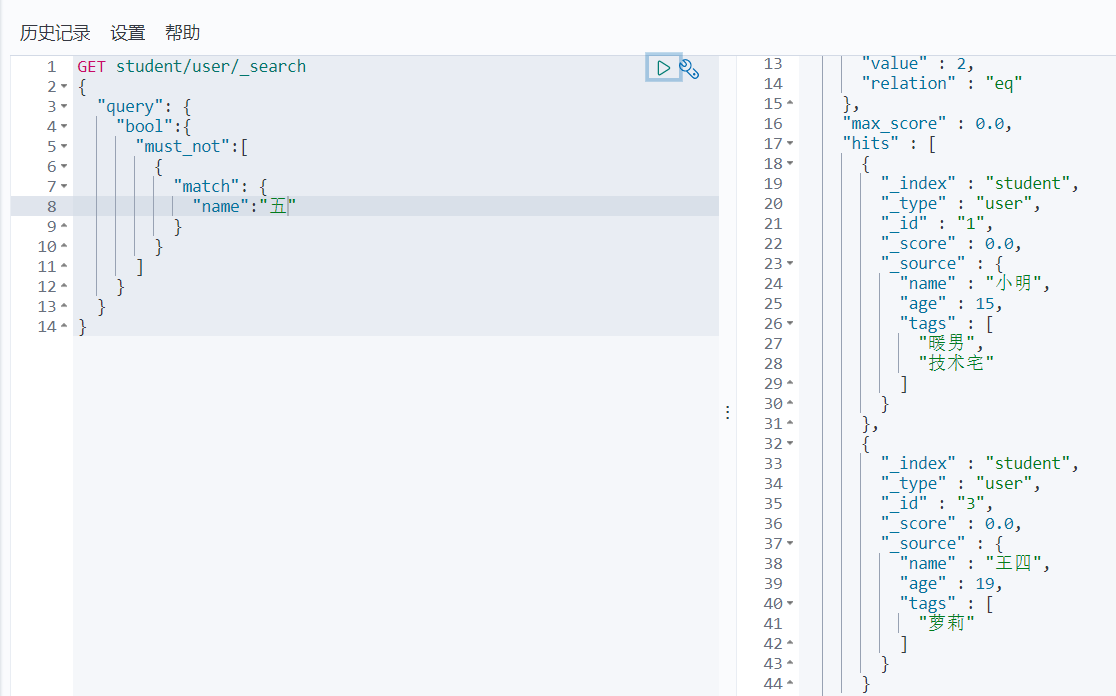
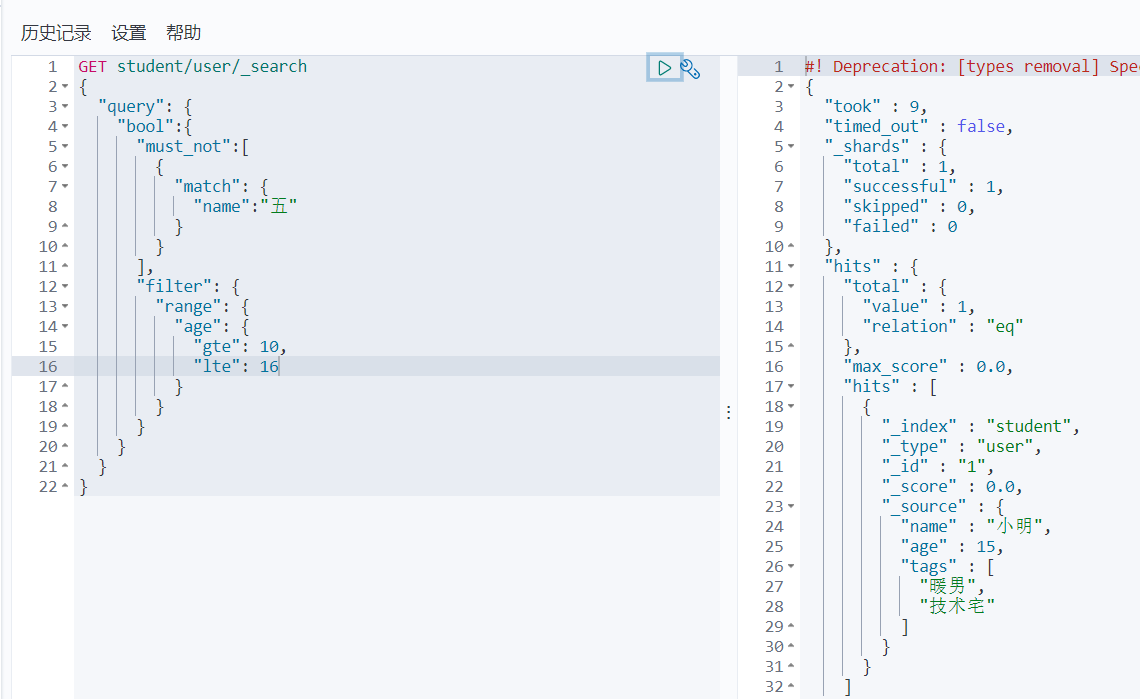
Bool多条件查询(must_not、must、should、filter)
通过bool可以进行多条件查询,must_not代表不匹配,must代表必须匹配,should代表只要有其中一个条件匹配即可,filter代表条件过滤器
must
must_not
filter
过滤出age大于10小于16的
should
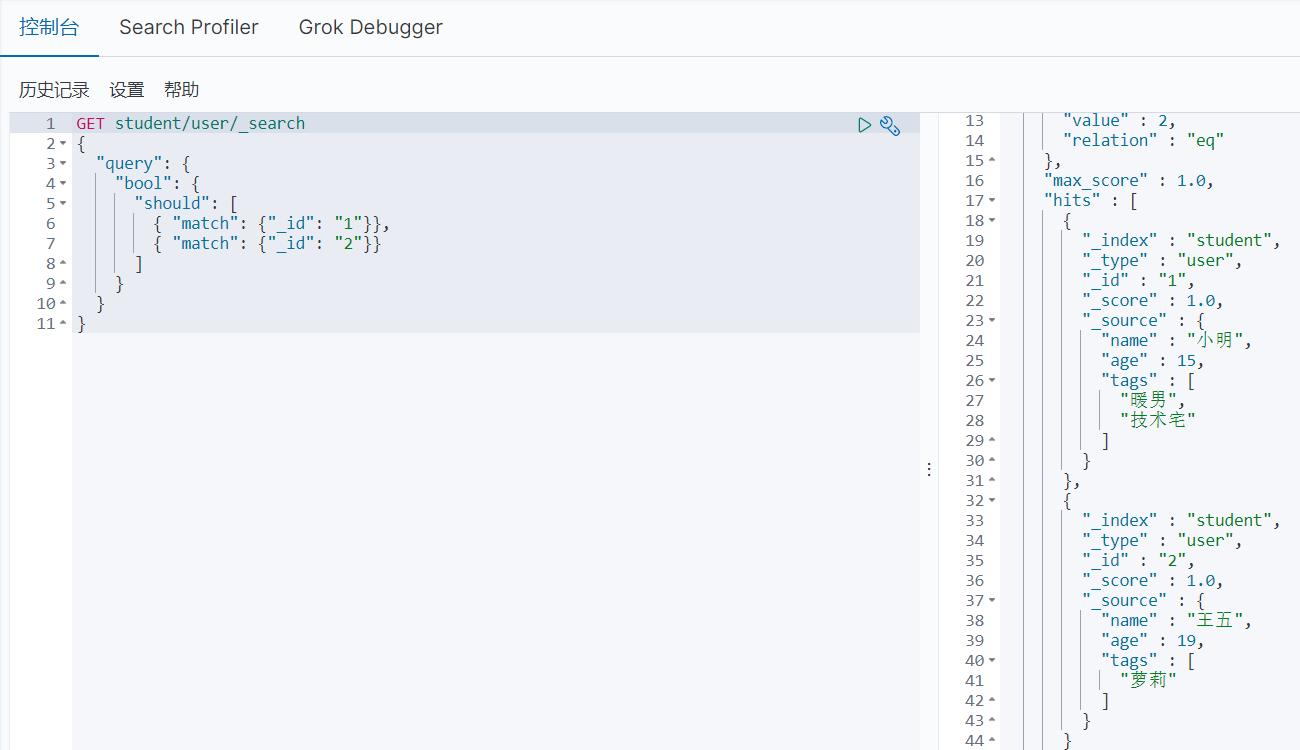
should使用注意事项
当should和must或filter一起使用时,should就会失效,具体可参考该博客:elasticsearch bool中should must联用问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号