
音频克隆-GPT-SoVITS
前面做了一个视频拆分工具,随便添加了音频的一些处理,有一个功能是视频+文字生成一个新的音频。
使用的是TTS进行处理的,效果不行。
所以这里介绍一个更加强大的开源工具:GPT-SoVITS、
一:开源仓库:
仓库:https://github.com/RVC-Boss/GPT-SoVITS
官方文档: https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e
下载安装各种包,然后下载已经训练好的模型
模型: https://huggingface.co/lj1995/GPT-SoVITS/tree/main
模型存放位置 GPT-SoVITS\GPT_SoVITS\pretrained_models
二:运行
python webui.py
#查看报什么错,差什么安装什么。
#注意安装 jieba_fast 时需要电脑已经安装了Visual Studio 桌面生成工具。因为它需要c++进行编译。
#如果编译失败,或者没有环境,可以试试我的方法:
(1)下载: http://cdnhandler.wordzhgame.net/audios/jieba_fast-0.53-cp311-cp311-win_amd64.whl
(2)通过这个安装:pip install jieba_fast-0.53-cp311-cp311-win_amd64.whl
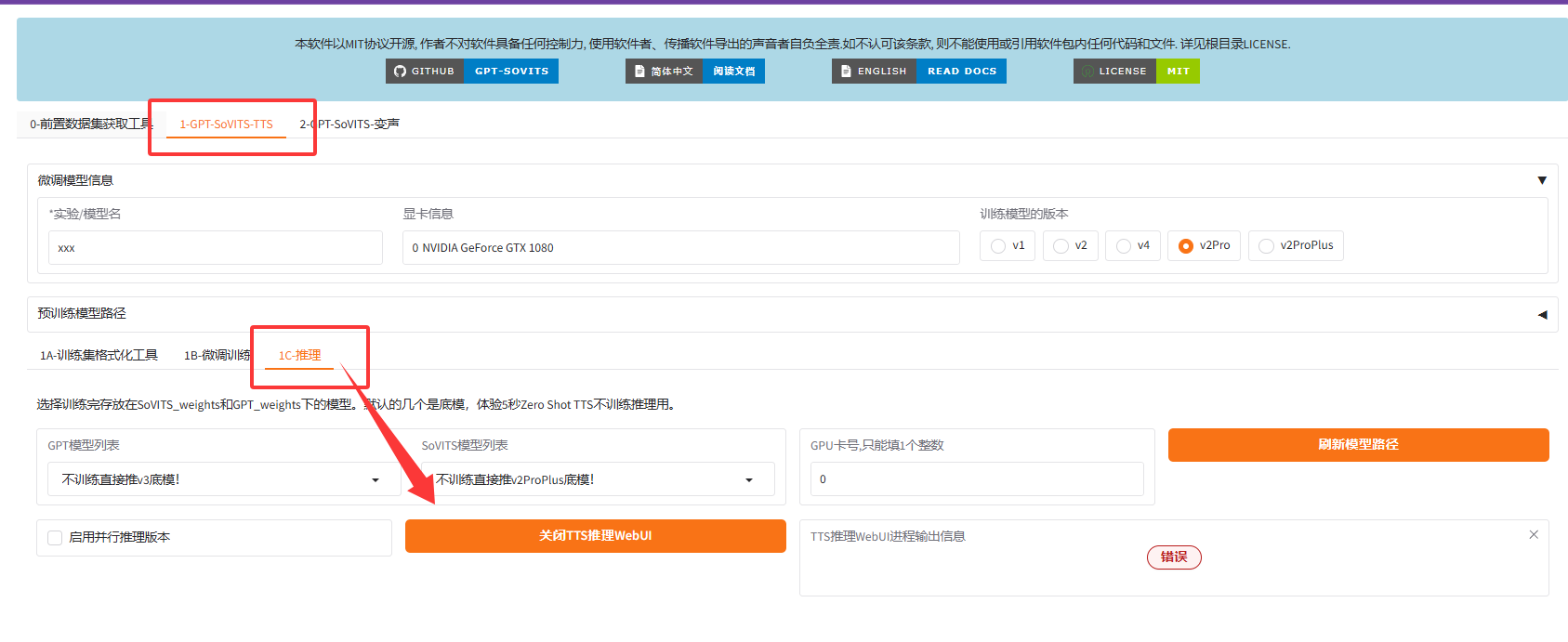
点击TTS推理按钮后,需要等待一段时间。它会自动打开另外要给窗口。
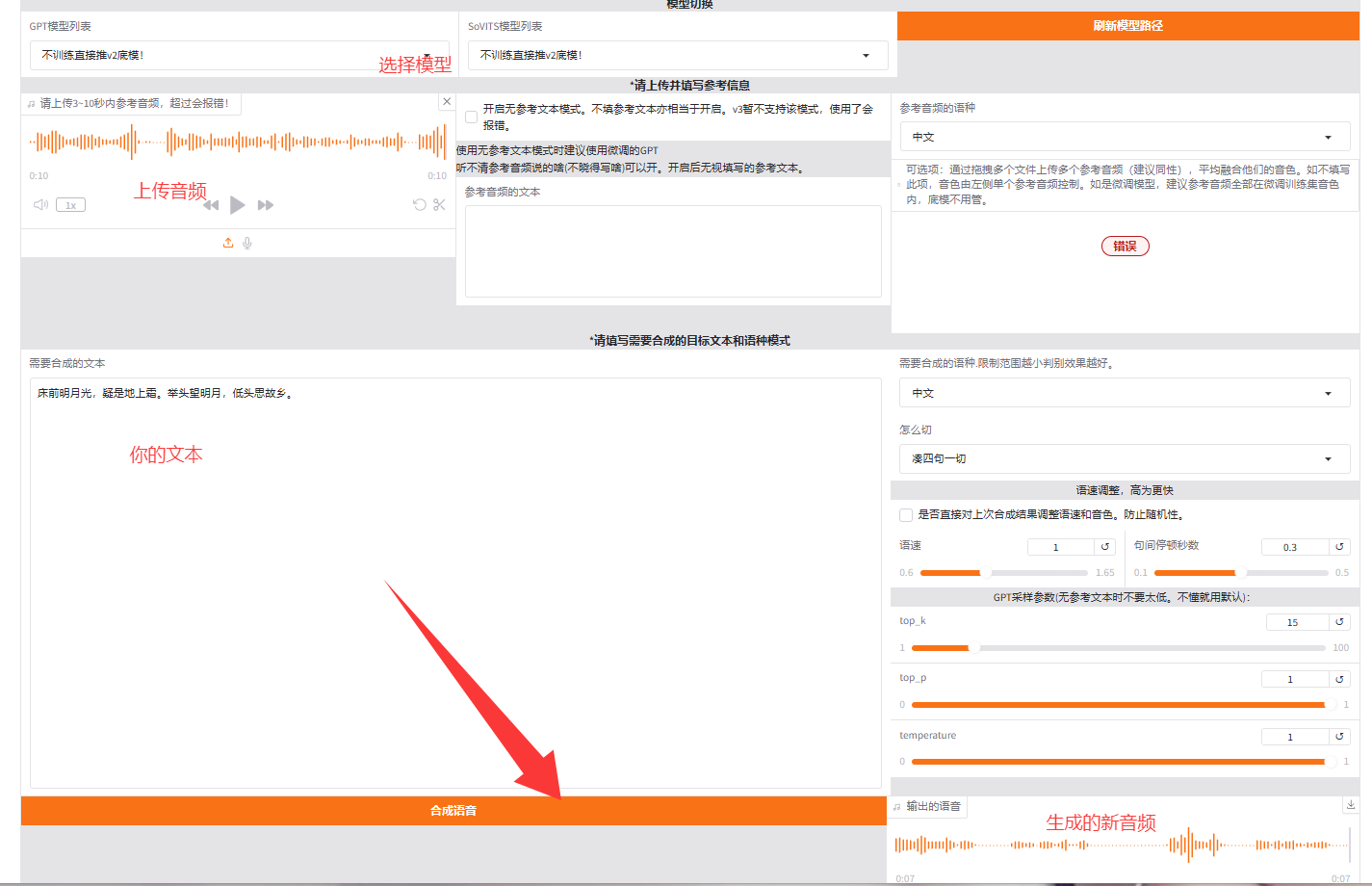
三:生成结果
关于模型的选择,可以参考官方文档:https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e
我比较喜欢的是 V3-V2Pro。

v2:不训练直接推v2底模
v2Pro:不训练直接推v2Pro底模
v2ProPlus:不训练直接推v2ProPlus底模
v3:不训练直接推v3底模
| v2 | v3 | |
| v2 | ||
| v2Pro | ||
| v2ProPlus |
这个是原始音频:
参考文档:
https://github.com/RVC-Boss/GPT-SoVITS
https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号