本地搭建一个对嘴AI工具
图片+音频=说话视频
这就是本次需要实现的功能。
一:环境
window10电脑(GPU越大越好,我的是专享8G,有点小了)。
Python 3.11.9。
CUDA Version: 12.9。(驱动支持的最大 CUDA 版本,之前版本太低了,下载个新的安装,升级,重新启动电脑)
二:ComfyUI工具
ComfyUI:作为Stable Diffusion用户界面。之前的文章介绍过怎么安装:https://github.com/comfyanonymous/ComfyUI
ComfyUI_Sonic: 核心框架:https://github.com/smthemex/ComfyUI_Sonic 。 下载后解压到文件夹\ComfyUI\custom_nodes\下面。
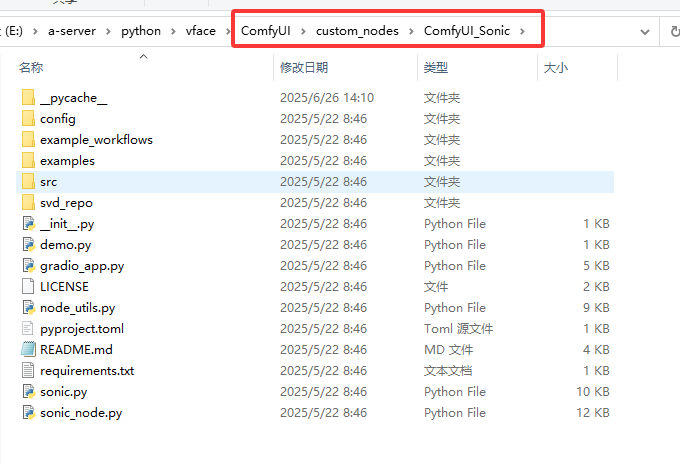
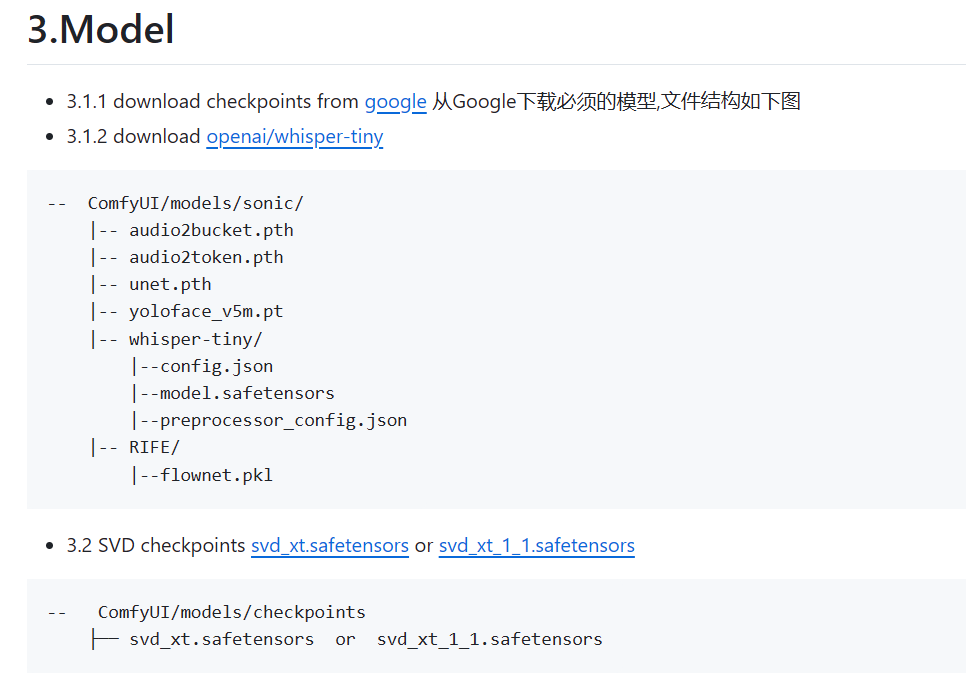
直接根据安装文档进行安装,包括模型下载:“3.Model“。
三:直接运行
1:运行过程中有错误,比如有的模块没有安装,直接安装就行。
python .\main.py
成功启动后,浏览器直接访问 : http://127.0.0.1:8188
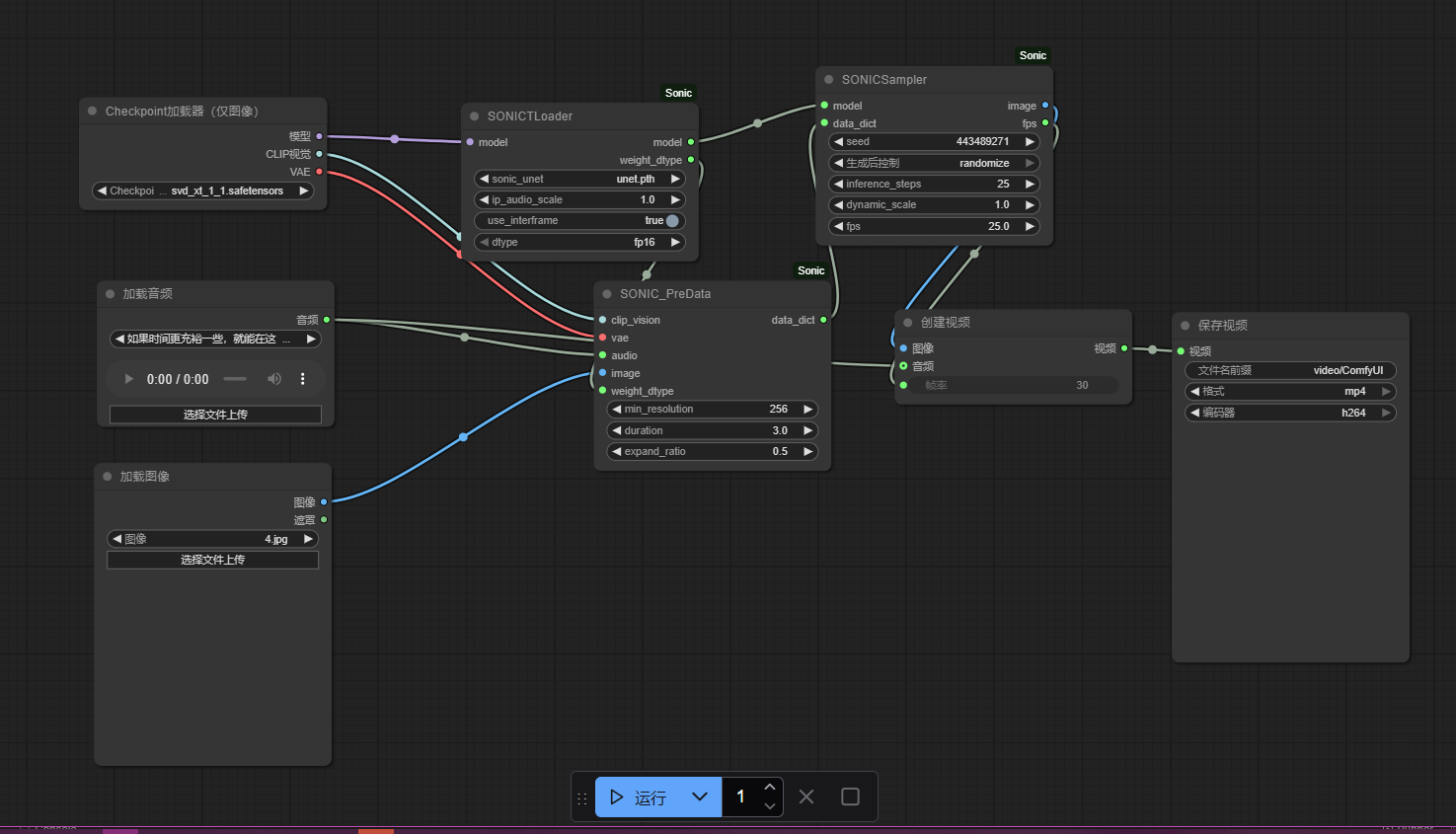
2:加载移动json。在文件夹下:\ComfyUI\custom_nodes\ComfyUI_Sonic\example_workflows 找到example.json。
将其推到浏览器打开的ui界面中。
3:上传自己的图片和音频:将图片和音频上传到相应位置,注意有个时长需要调整为跟音频一样的时间长度。
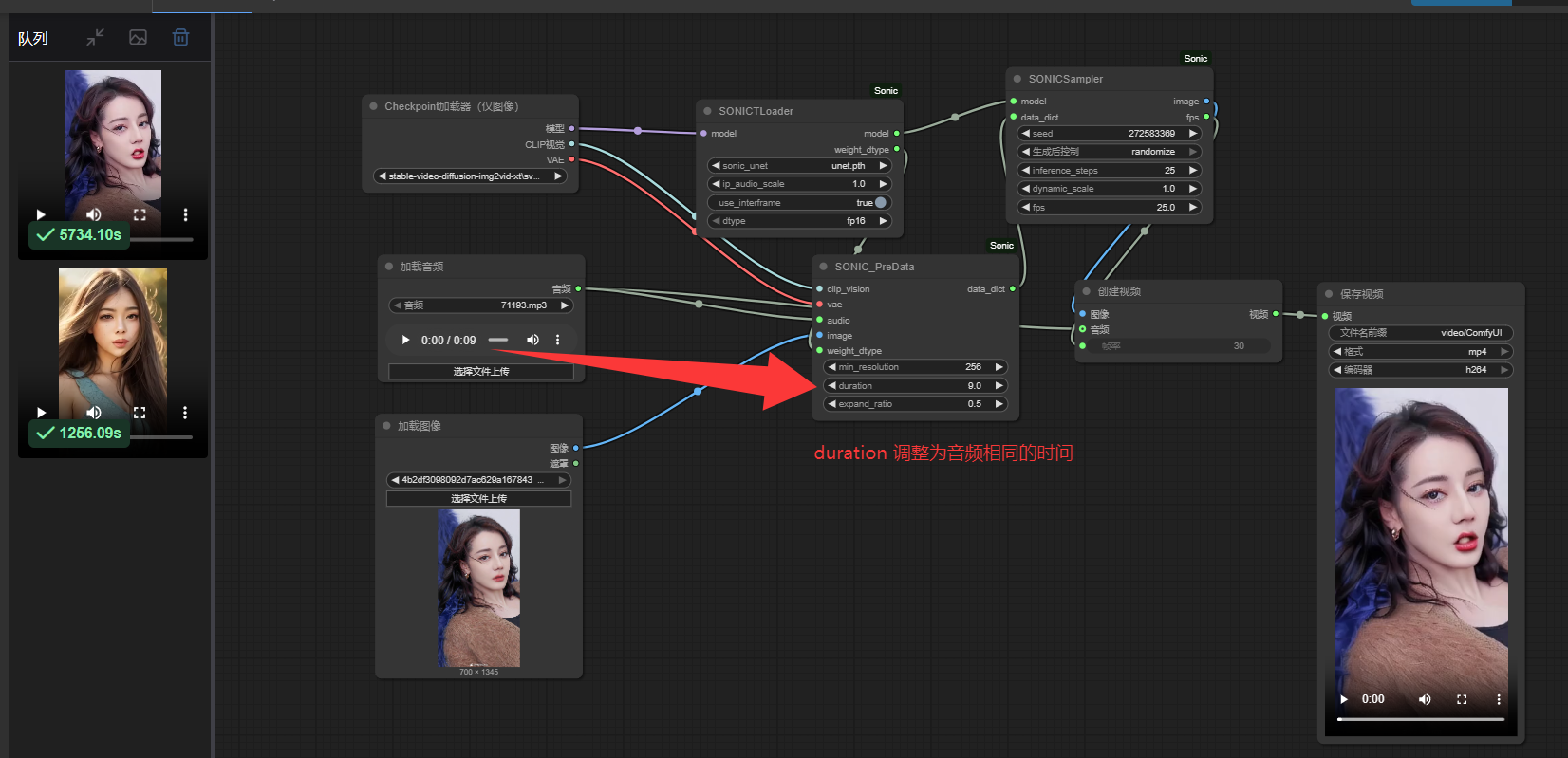
4:点击运行后,需要等待了,如果你的GPU比较大,那等待的时间就比较短。
生成的视频文件根据你最后的那个输出配置,一般在文件夹 \ComfyUI\output 中。
查看文档:https://github.com/smthemex/ComfyUI_Sonic

 浙公网安备 33010602011771号
浙公网安备 33010602011771号