第七周-云计算运维作业
1. 总结pg和mysql的优劣势。
| 特性类别 | PostgreSQL 优势 | PostgreSQL 劣势 | MySQL 优势 | MySQL 劣势 |
|---|---|---|---|---|
| 标准兼容性 | 高标准 SQL 支持(如窗口函数、CTE、递归查询) | 学习曲线较陡,对初学者不太友好 | 简单,适合快速开发 | 缺乏高级 SQL 特性 |
| 性能(简单 vs 复杂查询) | 复杂查询和写操作性能强 | 简单查询和高并发读操作性能一般 | 简单查询和高并发读操作性能优异 | 复杂查询和写操作性能可能不如 PostgreSQL |
| 事务支持和并发控制 | 完整的 ACID 和高级的 MVCC 支持 | 高度复杂的并发处理和事务管理可能带来性能开销 | InnoDB 提供了基本的事务支持,行级锁 | MyISAM 只支持表级锁,事务支持较为基础 |
| 数据类型和扩展性 | 丰富的数据类型(如 JSON、数组、地理空间数据) | 复杂的功能增加了管理和维护的复杂性 | 足够满足大多数应用场景,支持多种存储引擎 | 缺乏丰富的数据类型和扩展选项 |
| 数据完整性 | 复杂的约束、外键支持和触发器,保证高数据完整性 | 强制数据一致性,可能影响性能 | 支持基础的数据完整性机制 | 默认配置下(如 MyISAM)缺乏外键和一致性检查 |
| 复制和分片 | 逻辑复制、流式复制适合高可用性需求 | 配置和管理复杂 | 主从复制、主主复制和分片机制灵活 | 分片依赖应用逻辑,缺乏内置分片支持 |
| 高级功能和扩展 | 自定义类型、函数、操作符,插件系统丰富 | 高级特性需要深入的学习和理解 | 基本查询和索引足够,插件系统简单 | 高级特性支持有限 |
| 地理空间支持 | PostGIS 提供强大的地理空间数据和操作支持 | 复杂性和功能的增加需要更多学习 | 支持基本的地理空间数据类型和操作 | 地理空间支持不如 PostgreSQL 强大 |
| 备份和恢复 | 支持热备份、WAL 归档,适合复杂备份需求 | 配置复杂的备份恢复方案需要较多管理工作 | 简单的 mysqldump 和热备份,易于使用 | 高级备份选项较少,可能影响服务的连续性 |
| 管理和易用性 | 高度灵活,但管理和操作复杂 | 初学者和简单应用的设置较为繁琐 | 易于安装和使用,适合快速开发 | 高级配置和调优可能比较繁琐 |
| 社区支持和文档 | 强大的社区和商业支持,丰富的文档和资源 | 文档和资源对初学者可能显得技术化 | 广泛的社区支持和丰富的使用经验 | 文档和资源的质量和完整性有所不均 |
| 安全性和权限管理 | 高级的安全控制和细粒度的访问控制 | 配置和管理复杂,需要时间和精力 | 基本的安全控制简单,适合快速部署 | 默认安全配置较为简单,可能需要额外配置 |
| 内存使用 | 强大的特性和复杂查询可能需要更多内存和资源 | 资源使用可能增加系统成本 | 高并发场景下表现良好 | 处理大数据集时可能面临内存管理和性能瓶颈 |
| 升级和迁移 | 高度灵活的版本升级和迁移支持,但可能复杂 | 版本升级和数据迁移可能涉及复杂的变更和测试 | 版本升级和迁移相对简单 | 版本升级可能影响服务的连续性 |
| 成本 | 丰富的功能和复杂性可能增加管理和维护成本 | 学习和维护复杂特性需要额外成本 | 性能高效,满足大多数中小型应用 | 高并发场景下可能需要更多硬件资源 |
2. 总结pg二进制安装和编译安装。
官网:https://www.postgresql.org/download/linux/redhat/
二进制安装:
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
sudo dnf -qy module disable postgresql
sudo dnf install -y postgresql14-server
sudo /usr/pgsql-14/bin/postgresql-14-setup initdb
sudo systemctl enable postgresql-14
sudo systemctl start postgresql-14
编译安装:
wget https://ftp.postgresql.org/pub/source/v14.10/postgresql-14.10.tar.gz
tar -xzf postgesql-14.10.tar.gz
cd postgesql-14.10
./configure
make
make install
mkdir /var/lib/pgsql/data
chown postgres /usr/local/pgsql/data
-u postgres /var/lib/pgsql/bin/initdb -D /var/lib/pgsql/data
sudo -u postgres /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l logfile start #启动
3. 总结pg服务管理相关命令 pg_ctl 和pgsql命令选项及示例和不同系统的初始化操作
pg_ctl
pg_ctl 是用于启动、停止和管理 PostgreSQL 数据库服务器的命令行工具。它提供了多种操作模式和选项,使管理员可以方便地控制数据库服务。
- 初始化PostgreSQL数据库实例
- 启动、终止、重启PostgreSQL数据库
- 查看PostgreSQL数据库状态
- 重新读取数据库配置文件、允许给一个指定的PostgreSQL进行发送信号
- 控制或者standby服务器为可读写
- 在windows平台允许为数据库实例注册或取消一个系统服务
例子:
#可以设定$PGDATA变量,不需要再设置-D,多实例除外
1.启动数据库服务
pg_ctl start -D /usr/local/pgsql/data -l logfile
-D /path/to/data_directory:指定数据库的数据目录。
-l logfile:指定日志文件,用于记录启动过程。
2.停止数据库服务
pg_ctl stop -D /usr/local/pgsql/data
3.重启数据库服务
pg_ctl restart -D /usr/local/pgsql/data
4.重新加载配置
pg_ctl reload -D /usr/local/pgsql/data
#重新加载 postgresql.conf 文件中的配置,而无需重启数据库服务。
5.查看服务状态
pg_ctl status -D /usr/local/pgsql/data
psql 命令行工具
psql 是 PostgreSQL 的命令行界面工具,用于与数据库服务器交互,执行 SQL 查询和管理数据库。
例子:
连接到数据库
psql -U username -d dbname -h hostname -p port
-U username:指定连接的用户名。
-d dbname:指定要连接的数据库名。
-h hostname:指定数据库服务器的主机名。
-p port:指定连接的端口(默认是 5432)。
从文件执行 SQL 脚本
psql -f /path/to/script.sql -d dbname
-f /path/to/script.sql:指定要执行的 SQL 脚本文件。
直接执行 SQL 命令
psql -c "SELECT * FROM table_name;" -d dbname
-c "SQL command":直接执行一条 SQL 命令。
下面都由14版本为例
#12或12以下可能需要初始化数据库
/usr/psql-14/bin/postgresql-14-setup initdb
#设置环境变量
vim /etc/profile.d/pgsql.sh
export PGHOME=/usr/local/pgsql
export PATH=$PGHOME/bin/data
export PGDATA=/pgsql/data
export PGUSER=postgres
export MANPATH=/usr/local/pgsql/share/man:$MANPATH
#按需要去进行内核参数优化
vi /etc/sysctl.conf
vi /etc/security/limits.conf
- 总结pg数据库结构组织
PostgreSQL 数据库的结构可以按层次从上至下分为以下几个部分:
集群 (Cluster)#对应一个实例,即一个数据库目录
数据库 (Database)
模式 (Schema)#与mysql不太相同的是,postgreSql在一个数据库下可以有创建多个不同空间,而mysql则将数据库与模式相连
表 (Table)
数据 (Data)
-
实现pg远程连接。输入密码和无密码登陆
远程连接psql -h 192.168.1.100 -p 5432 -d mydb -U myuser
-h ip
-d 数据库
-U 用户
利用 .pgpass文件实现免密码远程登录
#hostname:port:databse:username:password
10.0.0.200:5432:testdb:postgres:root
chmod 600 .pgpass #建议600
psql -U postgres -h 10.0.0.200 -d testdb -w #需要跟指定文件匹配才行
- 总结库,模式,表的添加和删除操作。表数据的CURD。同时总结相关信息查看语句。
创建数据库:
create database sdb1;
删除数据库:
drop database sdb1;
创建模式:
create schema test;
删除模式:
drop schema test CASCADE
#CASCADE移除所有相关联的数据库对象
创建表:
CREATE TABLE test.t1 (
id PRIMARY KEY,
o_date DATE NOT NULL
);
删除表:
drop table test.t1;
CRUD
插入数据:
insert into test.t1 values(1,'1111-1-1');
查询数据:
\dt test.t1
更新数据:
uupdate test.t1
set date='2222-2-2'
where id=1;
删除数据:
delete from test.t1
where id=1;
查看
\dn #列出所有模式
\d #列出所有表,视图。序列
\d (table_name) 查看表结构
\dt #列出所有表名
\dt (table_name)查看表信息
\dt t* 列出所有t开头的表
\dt+ #列出表信息和大小
7. 总结pg的用户和角色管理。
用户权限
#与mysql不同的是,添加了角色(组),权限由角色管理,当用户需要时则将角色赋予用户。并且创建用户可以完全不带权限
用户(Role)管理
| 操作 | 命令 | 示例 |
|---|---|---|
| 创建角色 | CREATE ROLE role_name; |
CREATE ROLE readonly; |
| 创建用户 | CREATE USER user_name WITH PASSWORD 'password'; |
CREATE USER alice WITH PASSWORD 'secret'; |
| 修改用户密码 | ALTER USER user_name WITH PASSWORD 'new_password'; |
ALTER USER alice WITH PASSWORD 'newsecret'; |
| 修改角色属性 | ALTER ROLE role_name WITH option_name; |
ALTER ROLE readonly WITH LOGIN; |
| 删除角色 | DROP ROLE role_name; |
DROP ROLE readonly; |
| 列出角色 | \du |
\du |
| 显示角色信息 | SELECT * FROM pg_roles WHERE rolname='role_name'; |
SELECT * FROM pg_roles WHERE rolname='alice'; |
权限分配和回收
| 操作 | 命令 | 示例 |
|---|---|---|
| 分配权限 | GRANT privilege ON object TO role; |
GRANT SELECT ON mytable TO readonly; |
| 回收权限 | REVOKE privilege ON object FROM role; |
REVOKE SELECT ON mytable FROM readonly; |
| 授予所有权限 | GRANT ALL PRIVILEGES ON object TO role; |
GRANT ALL PRIVILEGES ON DATABASE mydb TO alice; |
| 回收所有权限 | REVOKE ALL PRIVILEGES ON object FROM role; |
REVOKE ALL PRIVILEGES ON DATABASE mydb FROM alice; |
| 查看对象权限 | \dp [object_name] |
\dp mytable |
| 查看角色权限 | \du+ role_name |
\du+ alice |
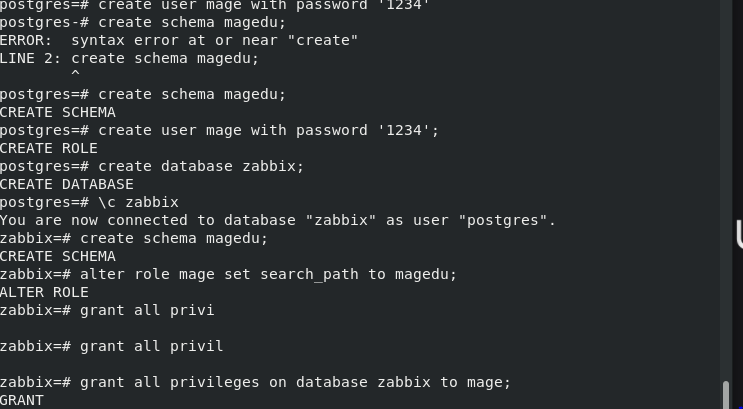
8. 添加mage用户,magedu模式,准备zabbix库,配置mage用户的默认模式magedu,要求mage用户给zabbix库有所有权限。
9. 总结pgsql的进程结构,说明进程间如何协同工作的。
PostgreSQL 的进程结构
Postmaster(主进程):
Postmaster 进程是 PostgreSQL 的管理进程,负责启动和管理其他所有子进程。它在数据库服务器启动时首先启动,负责监听客户端连接、启动新的服务进程、管理系统资源以及处理信号(如关闭请求)。
客户端连接进程(Backend Process):
每个客户端连接到数据库时,Postmaster 进程会为其生成一个新的 Backend Process。这个进程专门处理与该客户端相关的所有 SQL 操作(查询、插入、更新、删除等)。每个连接都有其独立的 Backend Process,这样可以隔离不同连接之间的操作,增强稳定性和安全性。
辅助进程(Auxiliary Processes):
辅助进程负责处理数据库运行中的各种后台任务。常见的辅助进程包括:
WAL Writer(预写式日志进程):
负责将内存中的 WAL (Write-Ahead Logging) 日志写入磁盘。WAL 日志记录了所有对数据库的更改,在系统崩溃时用于数据恢复。#类似事务日志;假设在脏数据未写入时数据库宕机,可通过WAL还原未宕机前的数据库状态
Checkpoint Process(检查点进程):
定期将内存中的脏数据页刷新到磁盘,并更新检查点信息。检查点减少了恢复时间,因为系统在崩溃后只需要从最近的检查点开始重放 WAL 日志。
#当事务完成时会有一个检查点
Background Writer(后台写进程):
负责将后台缓冲区中的脏数据页异步地刷新到磁盘,以减少检查点时的 I/O 峰值负载。#简单说就是将脏数据等到一定数量在写入磁盘
Autovacuum Process(自动清理进程):
定期执行 VACUUM 操作,清理无效的元组,防止表膨胀,保持表性能。它还负责自动分析以更新表的统计信息。
Stats Collector(统计信息收集进程):
收集数据库操作的统计信息,如表和索引的使用情况。这些统计数据用于优化器来决定最优的查询执行计划。
Archiver Process(归档进程):
负责将已完成的 WAL 日志文件复制到指定的归档位置,用于备份和灾难恢复。#二进制日志
sqllogger(系统日志进程)
#默认未开启,通过配置文件postgresql.conf设置参数logging_collect设置为on开启进程
它从postmaster主进程、所有的服务进程以及其他辅助进程收集所有的stder输出,并将这些输出写入到日志文件中
startup进程
用于数据库恢复进程
session(会话进程)
每一个用户发起连接后,一旦验证成功,postmaster进程就会fork一个新的子进程负责连接此用户
#表现形式:postgres postgres[local]idie
10. 总结pgsql的数据目录中结构,说明每个文件的作用,并可以配上一些示例说明文件的作用。
base #存储所有数据库的实际数据文件。每个数据库都有一个对应的子目录,子目录名是数据库的 OID
current_logfiles #记录当前正在使用的日志文件路径,通常用于系统函数pg_current_logfile()引用
global#对应pg_global表空间,存放实列中的共享对象
log: 通常包含数据库的日志文件,记录了数据库操作和系统消息。
pg_commit_ts: 存储事务提交时间的数据,用于MVCC(多版本并发控制)。
pg_dynshmem: 动态共享内存区域的状态信息。
pg_hba.conf: 客户端认证和主机访问控制列表。
pg_ident.conf: 用户名和系统用户身份映射配置。
pg_ident.conf与pg_hba.conf
pg_ident.conf
map1 test dba
pg_hba.conf
local all all ident map=map1
#使用ident,如果不添加map,则进入mysql时需要数据库用户与本机用户想匹配,而加入map(加入规则),则按规则;比如test对应dba用户和数据库,则使用test用户时作为dba用户进入数据库
pg_logical: 逻辑复制和订阅信息。
pg_multixact: 多事务ID的状态信息,用于共享行锁。
pg_notify: LISTEN和NOTIFY命令使用的通知队列。
pg_replslot: 复制槽信息,用于流复制。
pg_serial: 序列化事务信息。
pg_snapshots: 导出的快照文件。
pg_stat: 统计信息,用于监控和优化。
pg_stat_tmp: 临时统计数据。
pg_subtrans: 子事务状态信息。
pg_tblspc: 符号链接到数据库表空间的目录。
pg_twophase: 两阶段提交的事务状态文件。
PG_VERSION: 数据目录的PostgreSQL版本。
pg_wal: WAL日志,用于数据恢复和复制。
pg_xact: 事务状态信息。
postgresql.auto.conf: 自动配置参数,通常由ALTER SYSTEM命令设置。
postgresql.conf: 主要的数据库配置文件。
postmaster.opts: 启动数据库时使用的选项。
postmaster.pid: 数据库服务器进程的PID文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号