
多域部署时的sequence方案
为什么要多域部署?
从稳定性上:当业务不断发展后,会面临系统稳定性、容灾、业务隔离等多种问题
从业务需求上:国际化应用往往需要全球化部署
数据库的面临的问题
多域部署时,往往会伴随着数据的迁移、双写等问题
数据如何同步?分库分表场景下如何生成全局唯一id?
我们的场景是什么?
我们目前在单元A(中心节点)部署了自己的系统,现在希望将系统部署到单元B,而数据库(mysql)是分库分表的,我们需要在单元B也部署一套同样数据库,单元A读写单元A数据库,单元B读写单元B数据库,这样只要不会出现双写,就不会有一致性风险。单元A存储全量数据,单元B存储单元数据,一部分业务迁移到单元B中
分库分表如何保证id全局唯一
我们的分库分表中间件使用的是tddl,核心是一张sequence表(这张sequence表也是分库的),记录id的范围,tddl会将id的步长范围内的id区间段读取到应用的内存中,每次获取id的时候会读取内存中的值
例如有一个业务表叫xxx_test,分4个库,每个库单表,那么四个库的表分别是xxx_test_01、xxx_test_02、xxx_test_03、xxx_test_04,如果步长是1000,那外步长就是1000*4 = 4000,那么这4个库的sequence表分别存储的起始值是0、1000、2000、3000,应用会随机从一个数据库中取一个id,使用内步长之内的id段,例如取了xxx_test_02,那么取到的就是1001~2000这个id段缓存在应用内存中自增使用,取完之后1000会依照外步长更新成5000,此时4个sequence表的数据分别是0、5000、2000、3000,对于每一张sequence表永远按照外步长更新,因此永远不会冲突
分库分表+多域部署如何保证id全局唯一
方案一:基于初始id的范围
直接订正sequence里各数据表的初始值即可,仅初始化的时候做好这项工作就行,基本无需开发工作
方案二:多数据源的sequence的占位错开
因为tddl可以根据dbGroupKeys的占位符来实现错位取值,因此可以利用dbGroupKeys的占位符来实现隔离,但是如果两个单元是不同的分库结构,这个方案是有问题的,仍然需要使用其他手段实现隔离
方案三:增加区域id的后缀
sequence表新增字段区域ID来标记各个单元,区域ID是在[1,99]区间内的一个整数值,然后使用如下公式来计算新的sequence值
regionSequence = sequence *100 + 区域ID
方案三也分为多种实现方法,但是只要在能获取到该区域的id即可,这个数据不论从数据库或者diamond获取均可以
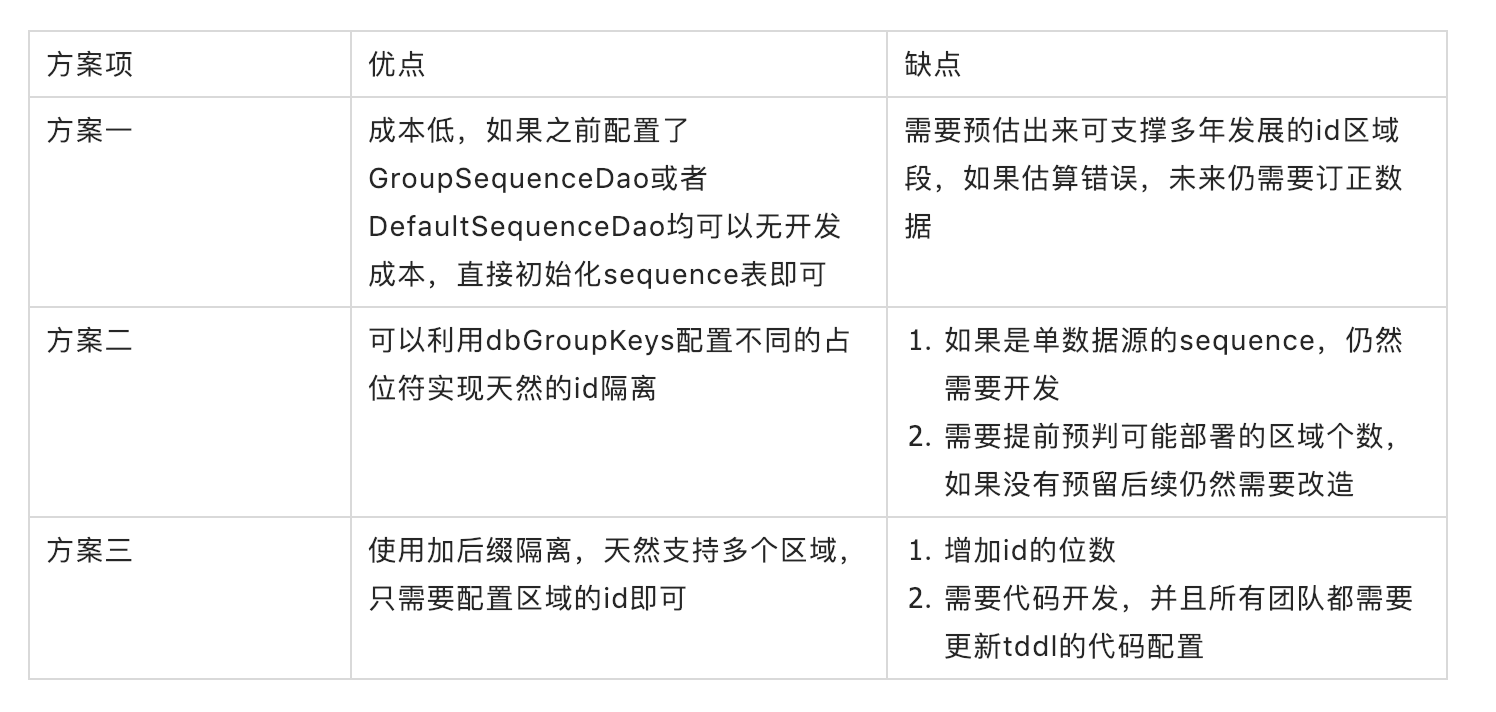
以上只是分库分表场景下多域部署全局唯一id的方案比较,供参考,即使是不同的分库分表中间件原理其实都是类似的,大家可以根据实际情况来选择方案和现实方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号