
Week10-数据库
week 10
1 介绍
1.1 数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
1.2 关系型数据库管理系统
RDBMS即关系数据库管理系统(Relational Database Management System)的特点:
- 数据以表格的形式出现
- 每行为各种记录名称
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
RDBMS的一些术语:
- 数据库: 数据库是一些关联表的集合。.
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同的数据,例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余可以使系统速度更快。(表的规范化程度越高,表与表之间的关系就越多;查询时可能经常需要在多个表之间进行连接查询;而进行连接操作会降低查询速度。例如,学生的信息存储在student表中,院系信息存储在department表中。通过student表中的dept_id字段与department表建立关联关系。如果要查询一个学生所在系的名称,必须从student表中查找学生所在院系的编号(dept_id),然后根据这个编号去department查找系的名称。如果经常需要进行这个操作时,连接查询会浪费很多的时间。因此可以在student表中增加一个冗余字段dept_name,该字段用来存储学生所在院系的名称。这样就不用每次都进行连接操作了。)
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
1.3 Mysql数据库
Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。其他RDMS还包括:Oracle,Sql Server,DB2,Postresql,Sqlite,Access等。非关系型:mongodb,redis,memcache。
2 Mysql安装
2.1 Linux
yum -y install mysql-server mysql


1.解压tar包 cd /software tar -xzvf mysql-5.6.21-linux-glibc2.5-x86_64.tar.gz mv mysql-5.6.21-linux-glibc2.5-x86_64 mysql-5.6.21 2.添加用户与组 groupadd mysql useradd -r -g mysql mysql chown -R mysql:mysql mysql-5.6.21 3.安装数据库 su mysql cd mysql-5.6.21/scripts ./mysql_install_db --user=mysql --basedir=/software/mysql-5.6.21 --datadir=/software/mysql-5.6.21/data 4.配置文件 cd /software/mysql-5.6.21/support-files cp my-default.cnf /etc/my.cnf cp mysql.server /etc/init.d/mysql vim /etc/init.d/mysql #若mysql的安装目录是/usr/local/mysql,则可省略此步 修改文件中的两个变更值 basedir=/software/mysql-5.6.21 datadir=/software/mysql-5.6.21/data 5.配置环境变量 vim /etc/profile export MYSQL_HOME="/software/mysql-5.6.21" export PATH="$PATH:$MYSQL_HOME/bin" source /etc/profile 6.添加自启动服务 chkconfig --add mysql chkconfig mysql on 7.启动mysql service mysql start 8.登录mysql及改密码与配置远程访问 mysqladmin -u root password 'your_password' #修改root用户密码 mysql -u root -p #登录mysql,需要输入密码 mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'your_password' WITH GRANT OPTION; #允许root用户远程访问 mysql>FLUSH PRIVILEGES; #刷新权限
2.2 Window
#1、下载:MySQL Community Server 5.7.16 http://dev.mysql.com/downloads/mysql/ #2、解压 如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:\mysql-5.7.16-winx64 #3、添加环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】 #4、初始化 mysqld --initialize-insecure #5、启动MySQL服务 mysqld # 启动MySQL服务 #6、启动MySQL客户端并连接MySQL服务 mysql -u root -p # 连接MySQL服务器 上一步解决了一些问题,但不够彻底,因为在执行【mysqd】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题: 注意:--install前,必须用mysql启动命令的绝对路径 # 制作MySQL的Windows服务,在终端执行此命令: "c:\mysql-5.7.16-winx64\bin\mysqld" --install # 移除MySQL的Windows服务,在终端执行此命令: "c:\mysql-5.7.16-winx64\bin\mysqld" --remove 注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令: # 启动MySQL服务 net start mysql # 关闭MySQL服务 net stop mysql
3 Mysql数据类型
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
3.1 数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 字节 | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 字节 | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 字节 | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 字节 | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 字节 | (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 字节 | (-3.402 823 466 E+38,1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 字节 | (1.797 693 134 862 315 7 E+308,2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
3.2 日期和时间类型
| 类型 | 大小 (字节) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2037 年某时 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
3.3 字符串类型
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-65535 字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65 535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65 535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295字节 | 极大文本数据 |
4 库操作
4.1 系统数据库
information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等;
performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象 ;
mysql: 授权库,主要存储系统用户的权限信息;
test: MySQL数据库系统自动创建的测试数据库。
4.2 创建数据库
语法:
CREATE DATABASE 数据库名 charset utf8;
4.3 数据库相关操作
查看数据库:
show databases;
show create database db1;
select database();
选择数据库:
USE 数据库名;
删除数据库:
DROP DATABASE 数据库名;
修改数据库:
alter database db1 charset utf8;
5 表操作
5.1 创建表
语法:
CREATE TABLE table_name (column_name column_type);
创建一个student表:
create table student( id INT NOT NULL AUTO_INCREMENT, name CHAR(32) NOT NULL, age INT NOT NULL, register_date DATE, PRIMARY KEY (id) );
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
CREATE TABLE `student2` ( `id` int(11) NOT NULL, `name` char(16) NOT NULL, `class_id` int(11) NOT NULL, PRIMARY KEY (`id`), KEY `fk_class_key` (`class_id`), CONSTRAINT `fk_class_key` FOREIGN KEY (`class_id`) REFERENCES `class` (`id`) #定义外键 )
5.2 查看表结构
语法:
describe student; #查看表结构,可简写为desc 表名 show create table student\G; #查看表详细结构,可加\G
5.3 插入表数据
语法:
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
5.3 复制表
复制表结构+记录 (key不会复制: 主键、外键和索引):
create table new_service select * from service;
只复制表结构:
create table new1_service select * from service where 1=2;
5.4 删除表
DROP TABLE 表名;
5.5 常用命令
5.5.1 ALTER命令
1. 修改表名
ALTER TABLE 表名
RENAME 新表名;
ALTER TABLE testalter_tbl RENAME TO alter_tbl;
2. 增加字段
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…],
ADD 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] FIRST;
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;
alter table student add phone int(11) not null;
3. 删除字段
ALTER TABLE 表名
DROP 字段名;
alter table student drop register_date;
4. 修改字段
ALTER TABLE 表名
MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE testalter_tbl MODIFY c CHAR(10);
ALTER TABLE testalter_tbl MODIFY j BIGINT NOT NULL DEFAULT 100;
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…]
ALTER TABLE testalter_tbl CHANGE i j BIGINT;
5.5.2 查询
语法:
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[OFFSET M ][LIMIT N]
- 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
- SELECT 命令可以读取一条或者多条记录。
- 你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
- 你可以使用 WHERE 语句来包含任何条件。
- 你可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
- 你可以使用 LIMIT 属性来设定返回的记录数。
like子句:
SELECT field1, field2,...fieldN table_name1, table_name2...WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue' select *from student where name binary like "%Li"; select *from student where name binary like binary "%Li"; #只匹配大写
排序:
SELECT field1, field2,...fieldN table_name1, table_name2...ORDER BY field1, [field2...] [ASC [DESC]]
使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。 select *from student where name like binary "%Li" order by stu_id desc;
分组:
SELECT column_name, function(column_name) FROM table_name WHERE column_name operator value GROUP BY column_name; SELECT name, COUNT(*) FROM employee_tbl GROUP BY name; SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP; SELECT coalesce(name, '总数'), SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
5.5.3 修改
UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause] update student set age=18 ,name="zhouxy" where stu_id>3;
5.5.4 删除
DELETE FROM table_name [WHERE Clause]<br><br>delete from student where stu_id=5;
6 Mysql连接
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
6.1 INNER JOIN(只显示2个表的交集)
select * from ccs_acct INNER JOIN ccs_order on ccs_acct.ACCT_NBR = ccs_order.ACCT_NBR; select ccs_acct.*,ccs_order.* from ccs_acct,ccs_order where ccs_acct.ACCT_NBR = ccs_order.ACCT_NBR;
6.2 LEFT JOIN
select * from a LEFT JOIN b on a.a = b.b;
6.3 RIGHT JOIN
select * from a RIGHT JOIN b on a.a = b.b;
6.4 FULL JOIN
mysql不支持full join。
select * from a FULL JOIN b on a.a = b.b; select * from a left join b on a.a = b.b UNION select * from a right join b on a.a = b.b;
7 事务
- 在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务
- 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
- 事务用来管理insert,update,delete语句
事务是必须满足4个条件(ACID): Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性):
- 事务的原子性:一组事务,要么成功;要么撤回。
- 稳定性 : 有非法数据(外键约束之类),事务撤回。
- 隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit选项 决定什么时候把事务保存到日志里。
begin; #开始一个事务 insert into a (a) values(555); rollback; 回滚 , 这样数据是不会写入的
8 索引
索引的功能就是加速查找。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
常用索引:
普通索引INDEX:加速查找
唯一索引:
-主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
-唯一索引UNIQUE:加速查找+约束(不能重复)
联合索引:
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引
索引类型:
hash类型的索引:查询单条快,范围查询慢 btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
8.1 创建索引
创建表时:
CREATE TABLE 表名 ( 字段名1 数据类型 [完整性约束条件…], 字段名2 数据类型 [完整性约束条件…], [UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [索引名] (字段名[(长度)] [ASC |DESC]) );
create table t1(
id int,
name char,
age int,
sex enum('male','female'),
unique key uni_id(id),
index ix_name(name) #index没有key
);
CREATE在已存在的表上创建索引:
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ;
create index ix_age on t1(age);
ALTER TABLE在已存在的表上创建索引:
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 ON 表名 (字段名[(长度)] [ASC |DESC]) ; alter table t1 add index ix_sex(sex);
8.2 删除索引
DROP INDEX 索引名 ON 表名;
9 pymysql模块
import pymysql #创建链接 conn=pymysql.connect(host='localhost',user='root',password='123',database='testdb') #创建游标 cursor=conn.cursor() #执行sql语句 #part1 # sql='insert into userinfo(name,password) values("root","123456");' # res=cursor.execute(sql) #执行sql语句,返回sql影响成功的行数 # print(res) #part2 # sql='insert into userinfo(name,password) values(%s,%s);' # res=cursor.execute(sql,("root","123456")) #执行sql语句,返回sql影响成功的行数 # print(res) #part3 sql='insert into userinfo(name,password) values(%s,%s);' res=cursor.executemany(sql,[("root","123456"),("lhf","12356"),("eee","156")]) #执行sql语句,返回sql影响成功的行数 print(res) conn.commit() #提交后才发现表中插入记录成功 cursor.close() #关闭游标 conn.close() #关闭链接
查询:
import pymysql #链接 conn=pymysql.connect(host='localhost',user='root',password='123',database='egon') #游标 cursor=conn.cursor() # 游标设置为字典类型 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) #执行sql语句 sql='select * from userinfo;' rows=cursor.execute(sql) #执行sql语句,返回sql影响成功的行数rows,将结果放入一个集合,等待被查询 # cursor.scroll(3,mode='absolute') # 相对绝对位置移动 # cursor.scroll(3,mode='relative') # 相对当前位置移动 res1=cursor.fetchone() res2=cursor.fetchone() res3=cursor.fetchone() res4=cursor.fetchmany(2) res5=cursor.fetchall() print(res1) print(res2) print(res3) print(res4) print(res5) print('%s rows in set (0.00 sec)' %rows) conn.commit() #提交后才发现表中插入记录成功 cursor.close() conn.close()
10 SQLAchemy
orm英文全称object relational mapping,就是对象映射关系程序。
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
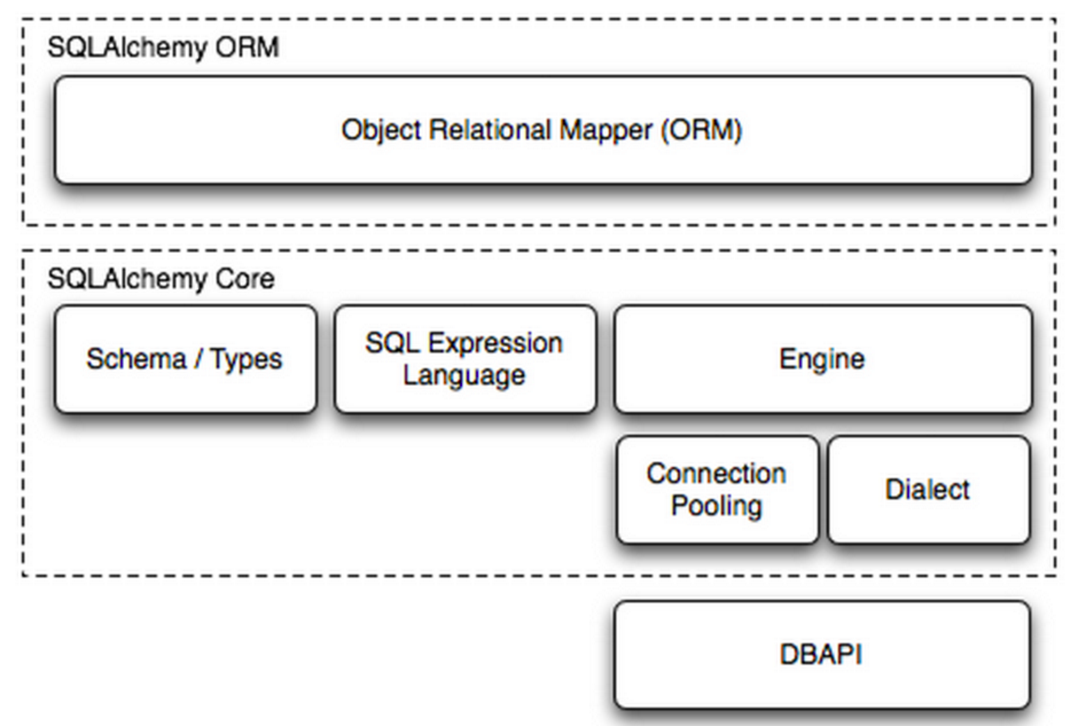
1、使用者通过ORM对象提交命令 2、将命令交给SQLAlchemy Core(Schema/Types SQL Expression Language)转换成SQL 3、使用 Engine/ConnectionPooling/Dialect 进行数据库操作 3.1、匹配使用者事先配置好的engine 3.2、engine从连接池中取出一个链接 3.3、基于该链接通过Dialect调用DB API,将SQL转交给它去执
总的来说就是根据类创建对象,对象转换成SQL,执行SQL。
10.1 创建表
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship engine = create_engine("mysql+pymysql://root:alex3714@localhost/testdb",encoding='utf-8', echo=True) #echo=True打印信息 Base = declarative_base() #生成orm基类 #创建单表:业务线 class Business(Base): __tablename__='business' id=Column(Integer,primary_key=True,autoincrement=True) bname=Column(String(32),nullable=False,index=True) #多对一:多个服务可以属于一个业务线,多个业务线不能包含同一个服务 class Service(Base): __tablename__='service' id=Column(Integer,primary_key=True,autoincrement=True) sname=Column(String(32),nullable=False,index=True) ip=Column(String(15),nullable=False) port=Column(Integer,nullable=False) business_id=Column(Integer,ForeignKey('business.id')) __table_args__=( UniqueConstraint(ip,port,name='uix_ip_port'), Index('ix_id_sname',id,sname) ) #一对一:一种角色只能管理一条业务线,一条业务线只能被一种角色管理 class Role(Base): __tablename__='role' id=Column(Integer,primary_key=True,autoincrement=True) rname=Column(String(32),nullable=False,index=True) priv=Column(String(64),nullable=False) business_id=Column(Integer,ForeignKey('business.id'),unique=True) #多对多:多个用户可以是同一个role,多个role可以包含同一个用户 class Users(Base): __tablename__='users' id=Column(Integer,primary_key=True,autoincrement=True) uname=Column(String(32),nullable=False,index=True) class Users2Role(Base): __tablename__='users2role' id=Column(Integer,primary_key=True,autoincrement=True) uid=Column(Integer,ForeignKey('users.id')) rid=Column(Integer,ForeignKey('role.id')) __table_args__=( UniqueConstraint(uid,rid,name='uix_uid_rid'), ) def init_db(): Base.metadata.create_all(engine) #创建表结构 def drop_db(): Base.metadata.drop_all(engine) if __name__ == '__main__': init_db()
10.2 操作表
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String,ForeignKey from sqlalchemy.orm import sessionmaker engine=create_engine('mysql+pymysql://root@127.0.0.1:3306/db1?charset=utf8',max_overflow=5) Base=declarative_base() #多对一:假设多个员工可以属于一个部门,而多个部门不能有同一个员工 class Dep(Base): __tablename__='dep' id=Column(Integer,primary_key=True,autoincrement=True) dname=Column(String(64),nullable=False,index=True) class Emp(Base): __tablename__='emp' id=Column(Integer,primary_key=True,autoincrement=True) ename=Column(String(32),nullable=False,index=True) dep_id=Column(Integer,ForeignKey('dep.id')) def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) drop_db() init_db() Session=sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 session=Session() #生成session实例
打印具体字段在定义表的类下面加上:
def __repr__(self): return "<User(name='%s', password='%s')>" % ( self.name, self.password)
10.2.1 增
row_obj=Dep(dname='销售') #按关键字传参,无需指定id,因其是自增长的 session.add(row_obj) session.add_all([ Dep(dname='技术'), Dep(dname='运营'), Dep(dname='人事'), ]) session.commit() #现此才统一提交,创建数据
10.2.2 删
session.query(Dep).filter(Dep.id > 3).delete()
session.commit()
10.2.3 改
session.query(Dep).filter(Dep.id > 0).update({'dname':'哇哈哈'})
session.query(Dep).filter(Dep.id > 0).update({'dname':Dep.dname+'_SB'},synchronize_session=False)
session.query(Dep).filter(Dep.id > 0).update({'id':Dep.id*100},synchronize_session='evaluate')
session.commit()
10.2.4 查
#查所有,取所有字段 res=session.query(Dep).all() #for row in res:print(row.id,row.dname) #查所有,取指定字段 res=session.query(Dep.dname).order_by(Dep.id).all() #for row in res:print(row.dname) res=session.query(Dep.dname).first() print(res) #过滤查 res=session.query(Dep).filter(Dep.id > 1,Dep.id <1000) #逗号分隔,默认为and print([(row.id,row.dname) for row in res])
10.2.5 其他
#条件 res=session.query(Emp).filter(Emp.id.between(1,3),Emp.ename == '周小律').all() res=session.query(Emp).filter(~Emp.id.in_([1,3,99,101]),Emp.ename == '周小律') #~代表取反,转换成sql就是关键字not from sqlalchemy import and_,or_ res=session.query(Emp).filter(and_(Emp.id > 0,Emp.ename=='周小律')).all() res=session.query(Emp).filter(or_(Emp.id < 2,Emp.ename=='功周小律')).all() res=session.query(Emp).filter( or_( Emp.dep_id == 3, and_(Emp.id > 1,Emp.ename=='周小律'), Emp.ename != '' ) ).all() #通配符 res=session.query(Emp).filter(Emp.ename.like('%律%')).all() #限制limit res=session.query(Emp)[0:5:2] #排序 res=session.query(Emp).order_by(Emp.dep_id.desc()).all() res=session.query(Emp).order_by(Emp.dep_id.desc(),Emp.id.asc()).all() #分组 from sqlalchemy.sql import func res=session.query(Emp.dep_id).group_by(Emp.dep_id).all() res=session.query( func.max(Emp.dep_id), func.min(Emp.dep_id), func.sum(Emp.dep_id), func.avg(Emp.dep_id), func.count(Emp.dep_id), ).group_by(Emp.dep_id).all() res=session.query( Emp.dep_id, func.count(1), ).group_by(Emp.dep_id).having(func.count(1) > 2).all() #连表 #笛卡尔积 res=session.query(Emp,Dep).all() #select * from emp,dep; #where条件 res=session.query(Emp,Dep).filter(Emp.dep_id==Dep.id).all() # for row in res: # emp_tb=row[0] # dep_tb=row[1] # print(emp_tb.id,emp_tb.ename,dep_tb.id,dep_tb.dname) #内连接 res=session.query(Emp).join(Dep) #join默认为内连接,SQLAlchemy会自动帮我们通过foreign key字段去找关联关系 res=session.query(Emp.id,Emp.ename,Emp.dep_id,Dep.dname).join(Dep).all() #左连接:isouter=True res=session.query(Emp.id,Emp.ename,Emp.dep_id,Dep.dname).join(Dep,isouter=True).all() #右连接:同左连接,只是把两个表的位置换一下 #组合 q1=session.query(Emp.id,Emp.ename).filter(Emp.id > 0,Emp.id < 5) q2=session.query(Emp.id,Emp.ename).filter( or_( Emp.ename.like('%小%'), Emp.ename.like('%律%'), ) ) res1=q1.union(q2) #组合+去重 res2=q1.union_all(q2) #组合,不去重 print([i.ename for i in q1.all()]) print([i.ename for i in q2.all()]) print([i.ename for i in res1.all()]) print([i.ename for i in res2.all()])
10.2.6 子查询
子查询当做一张表来用,调用subquery():
#示例:查出id大于2的员工,当做子查询的表使用 #原生SQL: # select * from (select * from emp where id > 2); #ORM: res=session.query( session.query(Emp).filter(Emp.id > 8).subquery() ).all()
子查询当做in的范围用,调用in_:
#示例:#查出销售部门的员工姓名 #原生SQL: # select ename from emp where dep_id in (select id from dep where dname='销售'); #ORM: res=session.query(Emp.ename).filter(Emp.dep_id.in_( session.query(Dep.id).filter_by(dname='销售'), #传的是参数 # session.query(Dep.id).filter(Dep.dname=='销售') #传的是表达式 )).all()
子查询当做select后的字段,调用as_scalar():
#示例:查询所有的员工姓名与部门名 #原生SQL: # select ename as 员工姓名,(select dname from dep where id = emp.dep_id) as 部门名 from emp; #ORM: sub_sql=session.query(Dep.dname).filter(Dep.id==Emp.dep_id) #SELECT dep.dname FROM dep, emp WHERE dep.id = emp.dep_id sub_sql.as_scalar() #as_scalar的功能就是把上面的sub_sql加上了括号 res=session.query(Emp.ename,sub_sql.as_scalar()).all()
10.2.7 正/反查
class Emp(Base): __tablename__='emp' id=Column(Integer,primary_key=True,autoincrement=True) ename=Column(String(32),nullable=False,index=True) dep_id=Column(Integer,ForeignKey('dep.id')) #在ForeignKey所在的类内添加relationship的字段,注意: #1:Dep是类名 #2:depart字段不会再数据库表中生成字段 #3:depart用于Emp表查询Dep表(正向查询),而xxoo用于Dep表查询Emp表(反向查询), depart=relationship('Dep',backref='xxoo') #示例:查询员工名与其部门名 res=session.query(Emp.ename,Dep.dname).join(Dep) #迭代器 for row in res: print(row[0],row[1]) #等同于print(row.ename,row.dname) #SQLAlchemy的relationship在内部帮我们做好表的链接 #查询员工名与其部门名(正向查) res=session.query(Emp) for row in res: print(row.ename,row.id,row.depart.dname) #查询部门名以及该部门下的员工(反向查) res=session.query(Dep) for row in res: # print(row.dname,row.xxoo) print(row.dname,[r.ename for r in row.xxoo])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号