flink架构原理
行内大数据平台流计算:
一个作业启动一个flink集群,各个作业的flink集群是隔离的,在web ui点击cancel后将job cancel掉,同时将集群终止,将作业终止。
on k8s:一个tm一个slot。
on yarn:一个tm可有多个slot。
kafka topic
TopicSchema:{"type":"object","properties":{"id":{"type":"number"},"username":{"type":"string"}}}
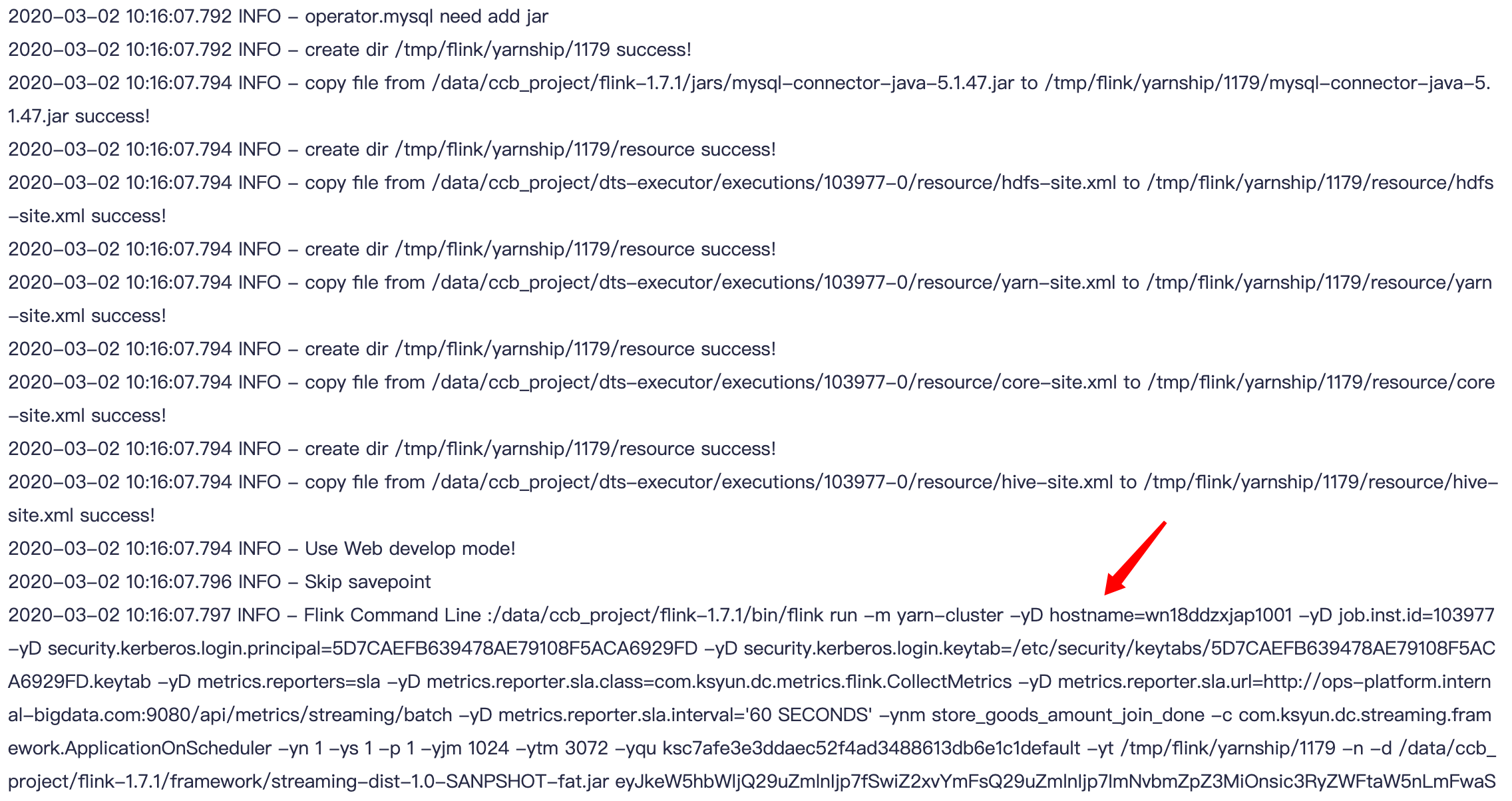
以上提交作业到yarn上的流程:
1、新建yarn目录
2、将MySQL驱动器传到yarn
3、将配置文件传到yarn
4、设置开发模式
5、启动flink并提交作业命令
flink-1.7.1/bin/flink run -m yarn-cluster -yD hostname=wn18ddzxjap1002 -yD job.inst.id=103989 -yD security.kerberos.login.principal=5D7... -yD security.kerberos.login.keytab=/etc/security/keytabs/5D7....keytab -yD metrics.reporters=sla -yD metrics.reporter.sla.class=com.ksyun.dc.metrics.flink.CollectMetrics -yD metrics.reporter.sla.url=http://ops-platform.internal-bigdata.com:9080/api/metrics/streaming/batch -yD metrics.reporter.sla.interval='60 SECONDS' -ynm store_goods_amount_join_done -c com.ksyun.dc.streaming.framework.ApplicationOnScheduler -yn 1 -ys 1 -p 1 -yjm 1024 -ytm 3072 -yqu ksccd365...-yt /tmp/flink/yarnship/1180 -n -d /flink-1.7.1/framework/streaming-dist-1.0-SANPSHOT-fat.jar
命令行参数:
-c:指定程序入口类
-p:指定多少个并发度
-yD:动态自定义参数
-m yarn-cluster -yn 1:使用yarn集群启动1个tm
-yjm:指定jm的内存大小
-ytm:指定tm的内存大小
-ys:每个tm的slot数量
-yqu:指定yarn资源队列
-d:以detached模式运行
flink list:查看进群上运行的job
flink cancel:取消job
flink list --all:查看所有job,包括cancel的

flink命令行参考:
https://my.oschina.net/u/3005325/blog/2998948
flink架构
flink运行时组件:作业管理器JobManager、任务管理器TaskManager、资源管理器Resource Manager、分发器Dispacher
Flink:批处理和流处理结合的统一计算框架,提供数据分发和并行化计算的流数据处理引擎,支持批处理和流处理。
Client:Client给用户提供向Flink系统提交用户任务(流式作业)的能力。
TaskManager:业务执行节点,执行具体的用户任务,可以有多个,各个manager平等。
JobManager:管理节点,管理所有的TaskManager,并决策用户任务在哪些TaskManager执行。JobManager在HA模式下可以有多个,但只有一个主JobMannager。






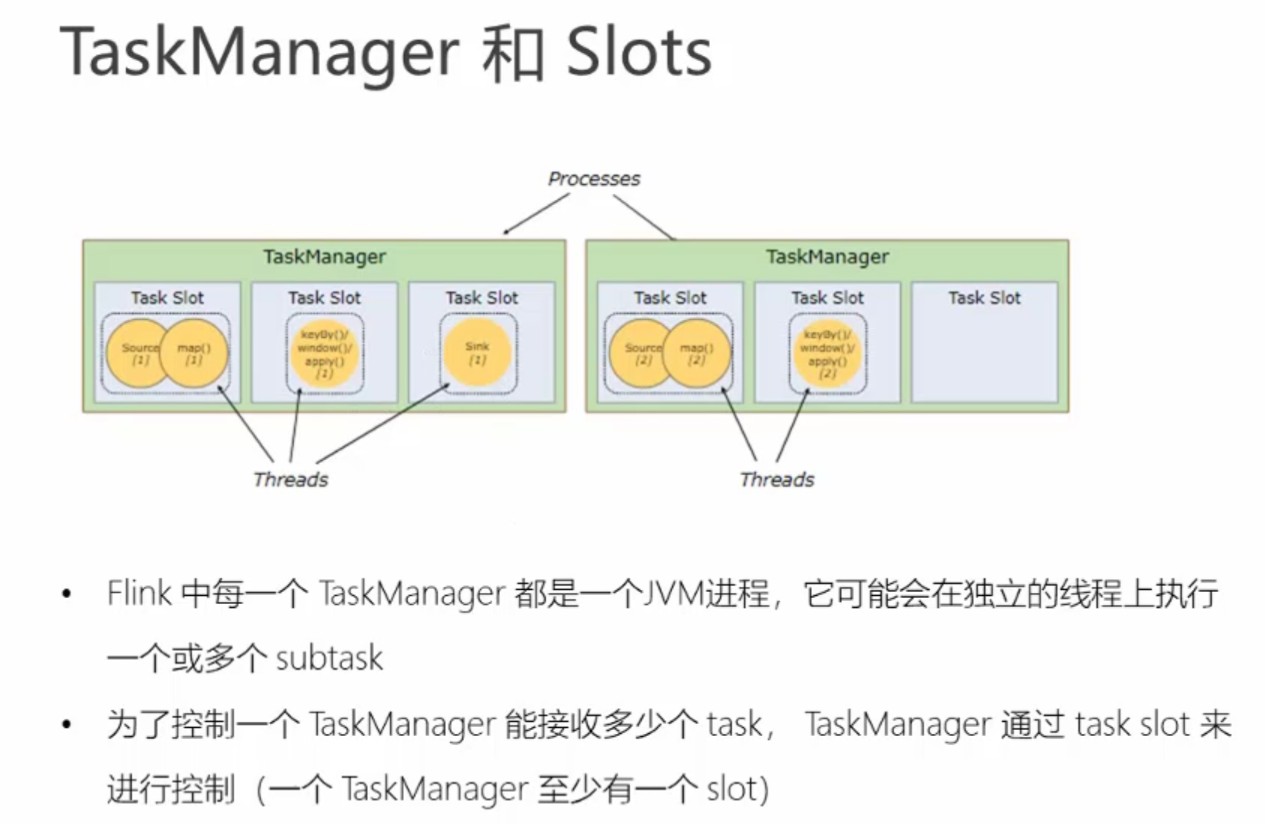
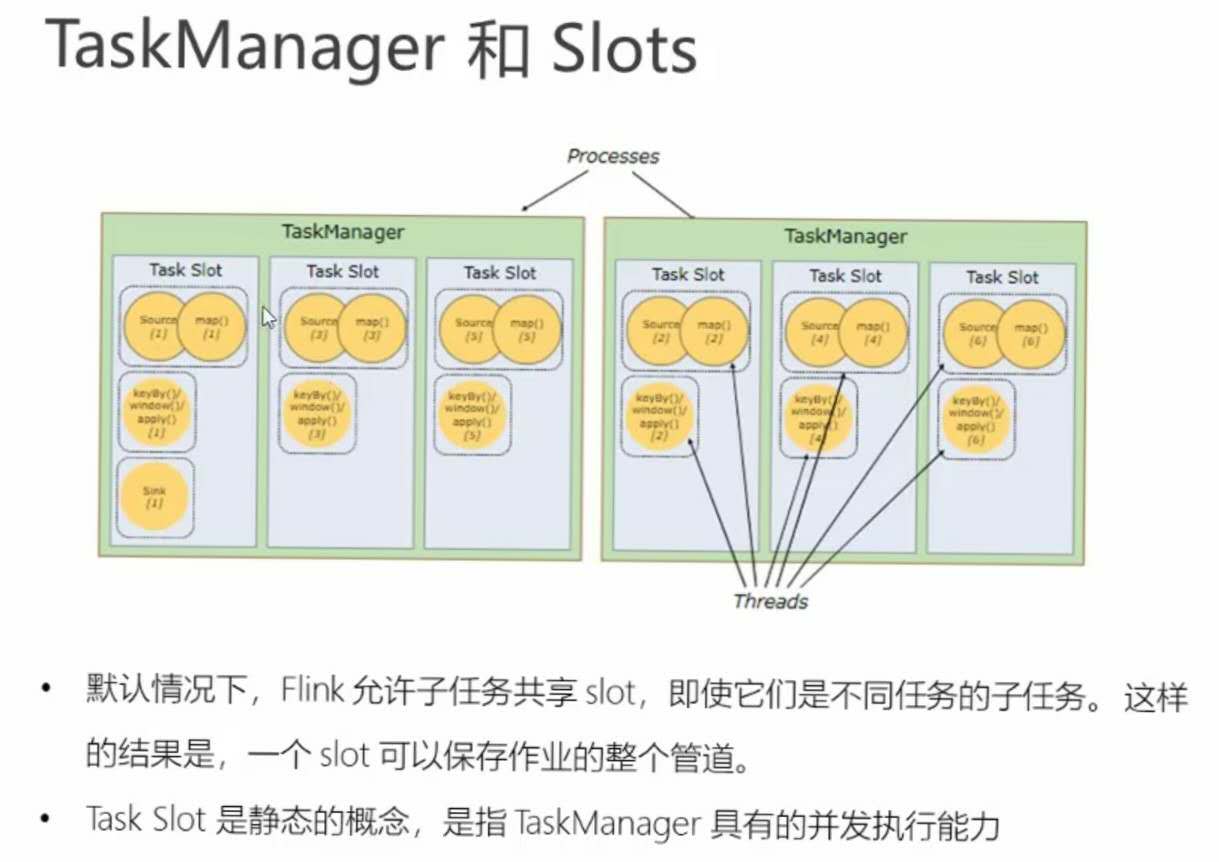
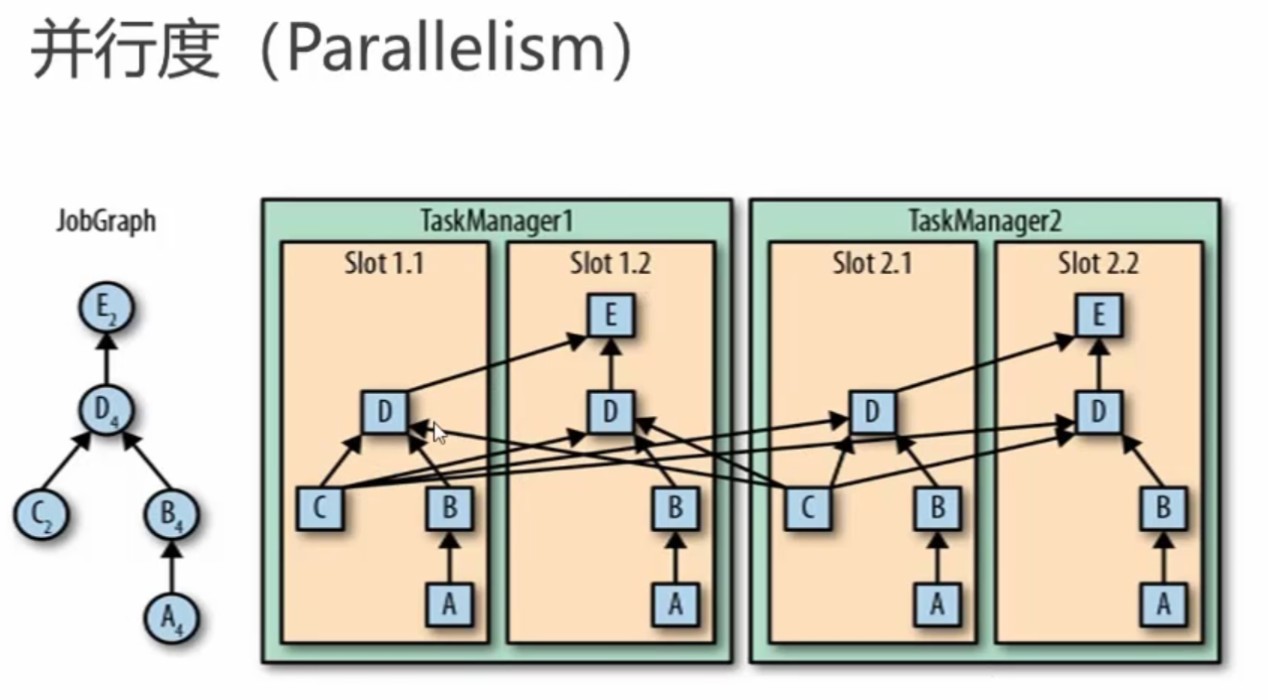
一个slot是flink处理的最小单元。
slot隔离的是内存,不是cpu。比如:
4cpu设置8slot,16g内存设置4slot,平均每个slot独占4g,但如果有的slot计算量过大,则可能导致内存撑爆。具体一个tm包含多少个slot,可根据机器、计算复杂度而定。
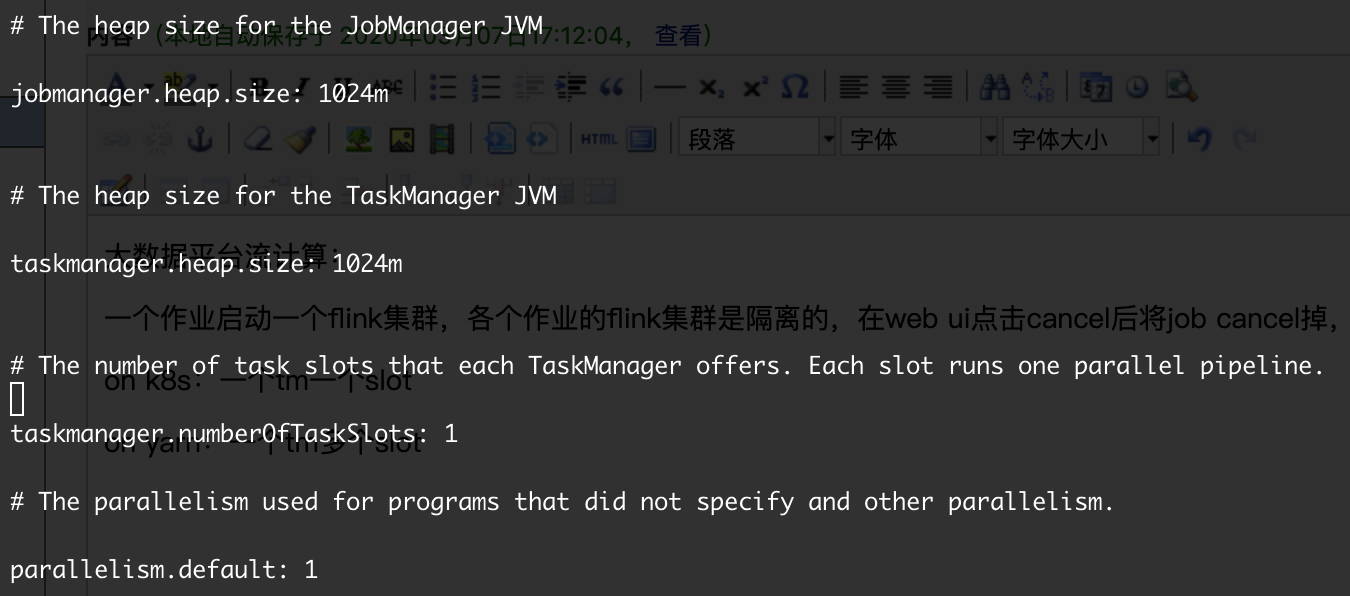
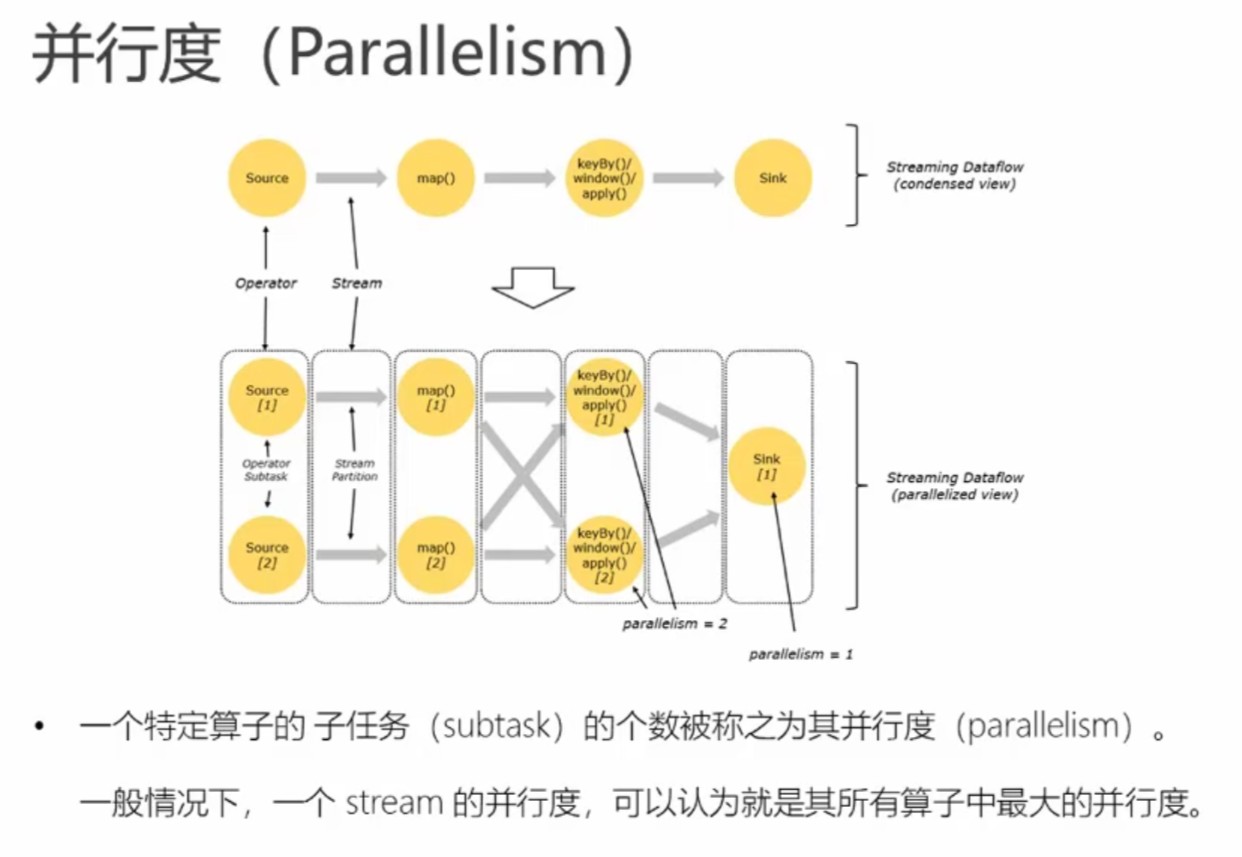
一个tm有多少个slot可在配置文件中配置,即numberOfTaskSlots配置项。而parallelism配置项即作业算子的并行度。
slot和parallelism的区分:
parallelism:表示这个算子任务可拆分成多少个子任务去运行。
slot:表示同时可支持多少个子任务并行。
设置并行度的权限大小关系:
代码设置并行度setParallelism(1) > 命令行提交设置的并行度 > 配置文件默认的并行度
每个算子在代码里都可分别设置并行度,source算子用socket读取数据时,并行度默认为1。
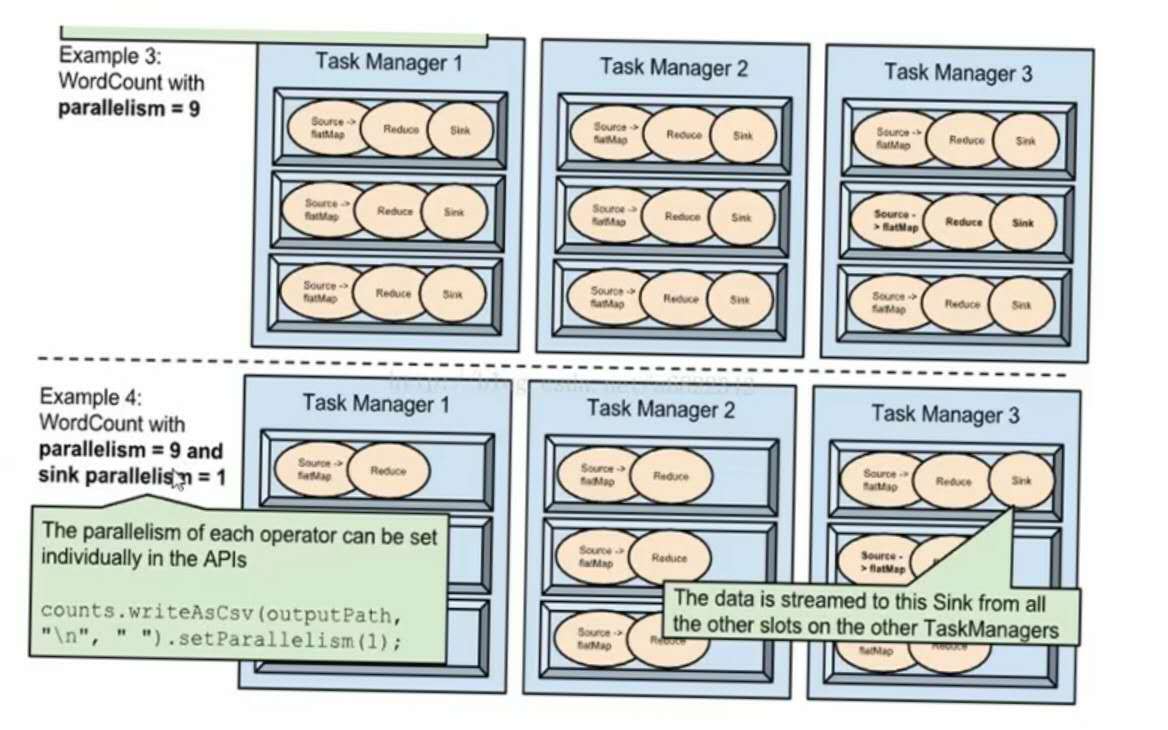
flink的并行:
数据并行:多个slot可同时处理数据,即多个子任务可同时运行。
任务并行:多个任务可同时运行。
作业并行:多个job同时在flink集群中运行(在行内大数据平台不支持这种并行,因为是采取的一个作业一个flink集群的模式,各个flink集群是隔离的)。
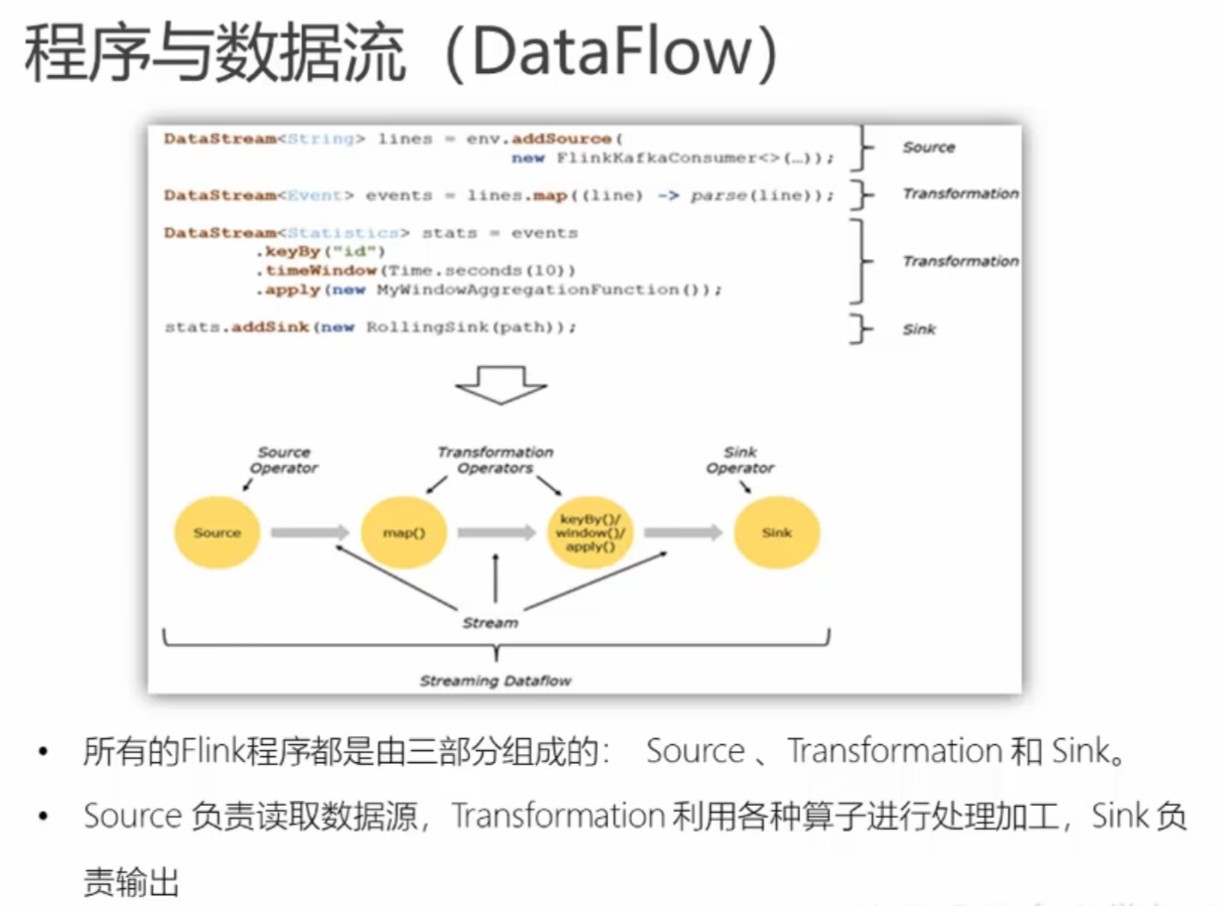
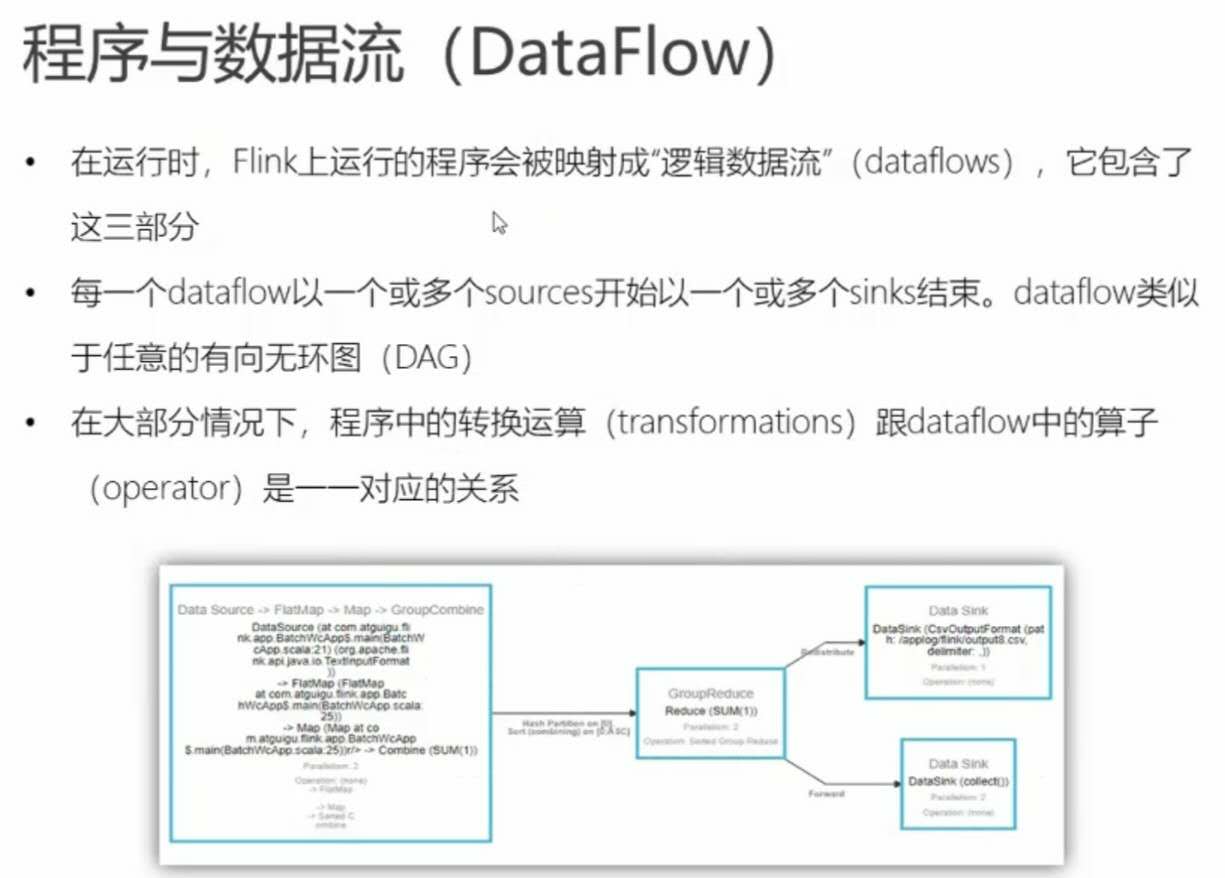


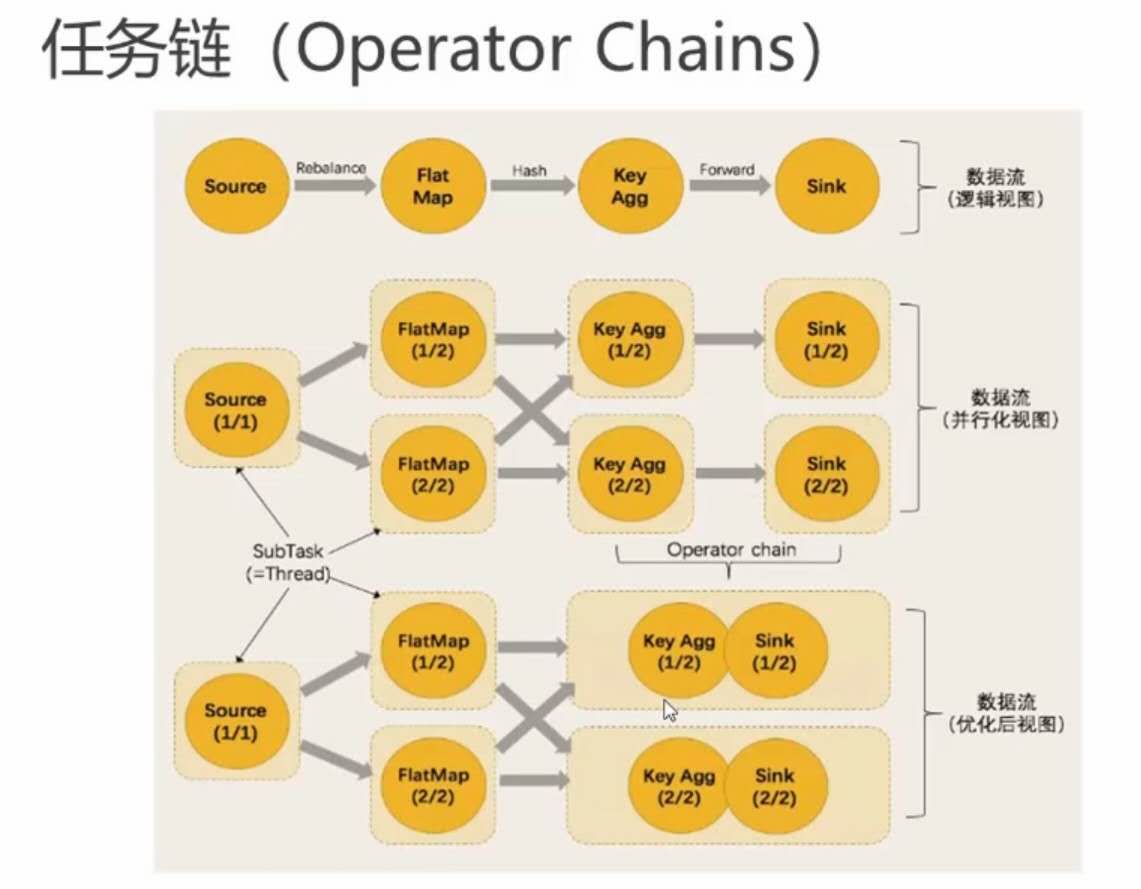
one to one且相同并行度的子任务可合并为一个任务,中间用->表示。
web ui中一个方框对应一个任务,一个->连接两个子任务。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号