XV6

大纲
- Version: xv6 2022
- xv6 book 2022
- xv6 中文课程翻译
- xv6 实验
- My XV6 Github
Lec01 系统调用与I/O Redirect
-
int open(const char *pathname, int flags);:-
The file descriptor returned by a successful call will be the lowest-numbered file descriptor not currently open for the process.
-
open会返回当前进程未使用的最小文件描述符序号。(A newly allocated file descriptor is always the lowest numbered unused descriptor of the current process) 若我们刚刚关闭了文件描述符1,而文件描述符0还对应着console的输入,则open一定可以返回1。
-
flags in XV6:
-
#define O_RDONLY 0x000 #define O_WRONLY 0x001 #define O_RDWR 0x002 #define O_CREATE 0x200 #define O_TRUNC 0x400 -
O_RDWR is both reading and writing;
-
O_CREATE o create the file if it doesn’t exist
-
O_TRUNC to truncate the file to zero length (如果成功以写权限打开已有的常规文件,就把该文件的长度截断为 0(即变成空文件))
-
-
-
pid_t wait(int *wstatus);- 学生提问:如果父进程有多个子进程,wait是不是会在第一个子进程完成时就退出?这样的话,还有一些与父进程交错运行的子进程,是不是需要有多个wait来确保所有的子进程都完成?
- Robert教授:是的,如果一个进程调用fork两次,如果它想要等两个子进程都退出,它需要调用wait两次。每个wait会在一个子进程退出时立即返回。当wait返回时,你实际上没有必要知道哪个子进程退出了,但是wait返回了子进程的进程号,所以在wait返回之后,你就可以知道是哪个子进程退出了。
-
File Descriptors- By convention, a process reads from file descriptor 0 (standard input), writes output to file descriptor 1 (standard output), and writes error messages to file descriptor 2 (standard error). As we will see, the shell exploits the convention to implement I/O redirection and pipelines.
- The shell ensures that it always has three file descriptors open (user/sh.c:151), which are by default file descriptors for the console.(Shell确保它始终有三个文件描述符打开, 0,1,2正好是其默认的三个描述符)
-
cat- XV6 cat core code
- cat 不会知道它是在从文件、控制台还是管道中读取。类似地,cat 也不会知道它是在向控制台、文件或其他地方打印。文件描述符的使用以及文件描述符 0 是输入、文件描述符 1 是输出的约定,使得 cat 的实现非常简单。
-
pid_t fork(void);- Although fork copies the file descriptor table, **each underlying(底层) file offset is shared between parent and child. **
-
int dup(int oldfd);- The dup() system call creates a copy of the file descriptor oldfd, using the lowest-numbered unused file descriptor for the new descriptor. (dup 系统调用复制一个现有的文件描述符,返回一个新的文件描述符,该描述符引用相同的底层 I/O 对象。这两个文件描述符共享偏移量,就像 fork 复制的文件描述符一样。)
- 如果两个文件描述符是通过一系列 fork 和 dup 调用从同一个原始文件描述符派生出来的,那么它们会共享偏移量。否则,文件描述符不会共享偏移量,即使它们是由对同一个文件进行的 open 调用产生的。
-
I/O Redirect-
实现
cat < output.txt, 利用fork会复制父进程文件描述符且使用close 等API更改文件描述符不会影响父进程的特性,先close(0)关闭原先输入文件描述符,然后再open("output.txt"), 此时open返回的一定是0,因为open优先使用未分配的最小的文件描述符,最后因为cat规定从文件描述符0读入数据,从文件描述符1输出数据,所以我们的目的已经达成了。 -
char *argv[2]; argv[0] = "cat"; argv[1] = 0; if(fork() == 0) { close(0); open("input.txt", O_RDONLY); exec("cat", argv); } -
实现
ls existing-file non-existing-file > tmp1 2>&1, 2>&1 告诉 shell 为该命令提供一个文件描述符 2,它是描述符 1 的副本。实现照样是先fork,然后close(2)关闭当前的文件描述符2使下一个可用的文件描述符为2,使用dup(1)使文件描述符2是文件描述符1的复制
-
pipes 管道-
管道是一个暴露给进程的小内核缓冲区,以一对文件描述符的形式出现,一个用于读取,一个用于写入。向管道的一端写入数据会使该数据在管道的另一端可用。管道为进程间通信提供了一种方式。
-
int pipe(int pipefd[2]);创建一个管道,这是一个可用于进程间通信的单向数据通道。数组 pipefd 用于返回两个指向管道两端的文件描述符。pipefd[0] 表示管道的读端。pipefd[1] 表示管道的写端。写入管道写端的数据会被内核缓冲,直到从管道的读端读取。 -
int p[2]; char *argv[2]; argv[0] = "wc"; argv[1] = 0; pipe(p); if(fork() == 0) { close(0); dup(p[0]); close(p[0]); close(p[1]); exec("/bin/wc", argv); } else { close(p[0]); write(p[1], "hello world\n", 12); close(p[1]); } -
fork()会把父进程的地址空间复制一份(现代实现为 copy-on-write),所以父子各自拥有自己的p和argv变量副本;但它们初始值相同,且指向/引用的一些内存(只读的字面量、内核的 pipe 对象)可能是同一物理资源。 -
如果没有可用数据,管道上的 read 函数要么等待数据写入,要么等待所有指向写入端的文件描述符关闭;在后一种情况下,read 函数将返回 0,就像到达了文件末尾一样。否则read 函数会一直阻塞,直到不可能有新数据到达。
-
在fork() == 0 下的分支中最后执行
close(p[1]);就是因为上述原因:通过pipe在子进程下有了指向写入端的文件描述符,如果不将其关闭,在执行exec后,/bin/wc将一直阻塞在read函数上 -
上述两点存疑,等具体学到了read系统调用处在来修正:
read()会在有数据可读时立刻返回,而在你的程序里若总有一方会写入一个字节,从而可解除阻塞。只有当缓冲区为空 且 所有写端都已经关闭时,read()才会返回0(EOF);否则如果还有可能写入,read()会阻塞直到有数据到来,但这不是永久死锁——因为另一个进程有写操作,会写入数据从而唤醒阻塞的read()。 -
具体而言上述因为
wc的实现比较特殊:其用while(read())这样包裹住了read, 很可能因为缓冲区数据全部被读完了且有写端开着而导致read一直阻塞在内核 -
XV6 实现类似 a | b 的代码: 大致是通过fork两次生成两个子进程分别处理管道的左端命令和右端命令,通过pipe实现让a命令的输出链接到p[1], 让b命令链接到p[0]
-
对于
a | b | c这样多管道的命令可以创建进程数,叶子节点为命令,中间节点是等待左右子节点完成的进程 -
管道的优势:
- 管道会自动清理自己
- 管道可以传递任意长度的数据流
- 管道允许管道阶段的并行执行
- 如果你正在实现进程间通信,管道的阻塞读写比文件的非阻塞语义更高效。
-
文件系统
xv6 文件系统提供数据文件,其中包含:
- 未解释的字节数组(文件,设备)
- 目录
- 目录形成一个树状结构,从称为根的特殊目录开始。像/a/b/c 这样的路径引用根目录/中名为 a 的目录内名为 b 的目录内名为 c 的文件或目录。
- 不以/开头的路径相对于调用进程的当前目录进行解析,当前目录可以通过 chdir 系统调用更改。
其中包含对数据文件和其他目录的命名引用。
文件名只是目录里的条目(name),真实的“文件”是磁盘上的 inode(包含元数据和数据指针),多个名字可以指向同一个 inode(这就是硬链接)。
-
文件名 ≠ 文件本体。目录条目保存名字和对 inode 的引用;inode 才是真正保存文件类型、大小、磁盘块位置、权限、链接计数等信息的地方。
-
一个 inode 可以有 多个名字(links/硬链接),因为目录里可以有多个条目引用同一个 inode。
-
inode including its type (file or directory or device),
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device
struct stat {
int dev; // File system’s disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};
在xv6中目录和阅读目录很神奇:
-
首先目录也是个文件,我们甚至可以通过
open得到目录的文件描述符 -
遍历目录中的文件甚至是通过不断
read目录的文件描述符得到struct dirent中的内容: -
// kernel/fs.h // Directory is a file containing a sequence of dirent structures. #define DIRSIZ 14 struct dirent { ushort inum; // 目录下文件的inode number char name[DIRSIZ]; // 目录下文件的名称 }; -
while(read(fd, &de, sizeof(de)) == sizeof(de)){ if(de.inum == 0) continue; memmove(p, de.name, DIRSIZ); p[DIRSIZ] = 0; if(stat(buf, &st) < 0){ // 此时的buf为文件的完整路径名 printf("ls: cannot stat %s\n", buf); continue; } printf("%s %d %d %d\n", fmtname(buf), st.type, st.ino, st.size); } -
可以理解为目录也是文件,其中保存在文件中的内容为目录下的文件信息,它们以
struct dirent中的内容进行存放
Lec03 OS Organization and System Calls
隔离性(isolation)
- 你需要在不同的应用程序之间有强隔离性。
- 你也需要在应用程序和操作系统之间有强隔离性。
- 使用操作系统的一个原因,甚至可以说是主要原因就是为了实现multiplexing和内存隔离。
- 隔离的角度来稍微看看Unix接口
- fork创建了进程,进程本身不是CPU,但是它们对应了CPU, 它们使得你可以在CPU上运行计算任务。应用程序不能直接与CPU交互,只能与进程交互。操作系统内核会完成不同进程在CPU上的切换。
- 应用程序<--进程-->CPU
- 进程抽象了CPU,这样操作系统才能在多个应用程序之间复用一个或者多个CPU。
- 我们可以认为exec抽象了内存。当我们在执行exec系统调用的时候,我们会传入一个文件名,而这个文件名对应了一个应用程序的内存镜像。内存镜像里面包括了程序对应的指令,全局的数据。应用程序可以逐渐扩展自己的内存,但是应用程序并没有直接访问物理内存的权限。操作系统会提供内存隔离并控制内存,操作系统会在应用程序和硬件资源之间提供一个中间层。exec是这样一种系统调用,它表明了应用程序不能直接访问物理内存。
- files基本上来说抽象了磁盘。操作系统会决定如何将文件与磁盘中的块对应,确保一个磁盘块只出现在一个文件中,并且确保用户A不能操作用户B的文件。通过files的抽象,可以实现不同用户之间和同一个用户的不同进程之间的文件强隔离。
防御性(Defensive)
当你在做内核开发时,这是一种你需要熟悉的重要思想。操作系统需要确保所有的组件都能工作,所以它需要做好准备抵御来自应用程序的攻击。
通常来说,需要通过硬件来实现这的强隔离性:
- 硬件支持包括了两部分,第一部分是user/kernel mode,kernel mode在RISC-V中被称为Supervisor mode但是其实是同一个东西(通过ecall(系统调用) 实现从user mode 到 kernel mode)
- 第二部分是page table或者虚拟内存(Virtual Memory)。
宏内核 vs 微内核 (Monolithic Kernel vs Micro Kernel)
什么程序应该运行在kernel mode?敏感的代码肯定是运行在kernel mode,因为这是Trusted Computing Base(内核有时候也被称为可被信任的计算空间(Trusted Computing Base))
- 其中一个选项是让整个操作系统代码都运行在kernel mode。大多数的Unix操作系统实现都运行在kernel mode。比如,XV6中,所有的操作系统服务都在kernel mode中,这种形式被称为Monolithic Kernel Design(宏内核)
- 首先,如果考虑Bug的话,这种方式不太好。从安全的角度来说,在内核中有大量的代码是宏内核的缺点。
- 另一方面,一个操作系统,它包含了各种各样的组成部分,比如说文件系统,虚拟内存,进程管理,这些都是操作系统内实现了特定功能的子模块。宏内核的优势在于,因为这些子模块现在都位于同一个程序中,它们可以紧密的集成在一起,这样的集成提供很好的性能。例如Linux,它就有很不错的性能。
- 另一种设计主要关注点是减少内核中的代码,它被称为Micro Kernel Design(微内核)。微内核的目的在于将大部分的操作系统运行在内核之外。
- 例如,内核通常会有一些IPC的实现或者是Message passing;非常少的虚拟内存的支持,可能只支持了page table;以及分时复用CPU的一些支持。
- 比如文件系统可能就是个常规的用户空间程序。现在,文件系统运行的就像一个普通的用户程序,就像echo,Shell一样,这些程序都运行在用户空间。假设我们需要让Shell能与文件系统交互,比如Shell调用了exec,必须有种方式可以接入到文件系统中(因为我们需要隔离性,即各个应用进程之前不能干扰)
- 通常来说,这里工作的方式是,Shell会通过内核中的IPC系统发送一条消息,内核会查看这条消息并发现这是给文件系统的消息,之后内核会把消息发送给文件系统。文件系统会完成它的工作之后会向IPC系统发送回一条消息说,这是你的exec系统调用的结果,之后IPC系统再将这条消息发送给Shell。
- 现在,对于任何文件系统的交互,都需要分别完成2次用户空间<->内核空间的跳转。与宏内核对比,在宏内核中如果一个应用程序需要与文件系统交互,只需要完成1次用户空间<->内核空间的跳转,所以微内核的的跳转是宏内核的两倍。通常微内核的挑战在于性能更差
编译运行kernel in QEMU
我们来看传给QEMU的几个参数:
- -kernel:这里传递的是内核文件(kernel目录下的kernel文件),这是将在QEMU中运行的程序文件。
- -m:这里传递的是RISC-V虚拟机将会使用的内存数量
- -smp(SMP = Symmetric Multi-Processing):这里传递的是虚拟机可以使用的CPU核数
- -drive:传递的是虚拟机使用的磁盘驱动,这里传入的是fs.img文件
// make qemu的部分输出:
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -global virtio-mmio.force-legacy=false -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
- -machine virt: 使用 QEMU 提供的通用 “virt” 虚拟机硬件平台
- -bios none: 不加载固件或 BIOS,直接从
-kernel指定的内核入口启动。 - -nographic: 不打开 QEMU 的图形窗口,把串口输出重定向到当前终端。
- -global virtio-mmio.force-legacy=false: 全局设置 VirtIO 设备使用 modern 模式(非 legacy 模式)。
- -drive file=fs.img,if=none,format=raw,id=x0
- 创建一个虚拟驱动器:
file=fs.img→ 磁盘镜像文件(原始格式)if=none→ 不立即附加到控制器(先创建裸驱动器对象)format=raw→ 镜像是原始格式(不是 qcow2 等压缩格式)id=x0→ 给它取名x0,后面会用到。
- 创建一个虚拟驱动器:
- -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
- 添加一个 VirtIO 块设备(虚拟磁盘):
drive=x0→ 绑定前面创建的磁盘x0bus=virtio-mmio-bus.0→ 挂在 virtio-mmio 的第 0 号总线上(virt 平台用 MMIO 方式连接 VirtIO 设备)。
- 添加一个 VirtIO 块设备(虚拟磁盘):
// 生成kernel/kernel
riscv64-linux-gnu-ld -z max-page-size=4096 -T kernel/kernel.ld -o kernel/kernel kernel/entry.o kernel/kalloc.o kernel/string.o kernel/main.o kernel/vm.o kernel/proc.o kernel/swtch.o kernel/trampoline.o kernel/trap.o kernel/syscall.o kernel/sysproc.o kernel/bio.o kernel/fs.o kernel/log.o kernel/sleeplock.o kernel/file.o kernel/pipe.o kernel/exec.o kernel/sysfile.o kernel/kernelvec.o kernel/plic.o kernel/virtio_disk.o kernel/start.o kernel/console.o kernel/printf.o kernel/uart.o kernel/spinlock.o
// 生成fs.img 这是保存了用户程序的镜像文件
mkfs/mkfs fs.img README user/xargstest.sh user/_cat user/_echo user/_forktest user/_grep user/_init user/_kill user/_ln user/_ls user/_mkdir user/_rm user/_sh user/_stressfs user/_usertests user/_grind user/_wc user/_zombie
- VirtIO 是一种 半虚拟化(paravirtualization)I/O 标准,主要用于虚拟机中的高效设备驱动。
- 在传统虚拟化中虚拟机(Guest OS)看到的设备是模拟硬件,虚拟化层(Hypervisor,比如 QEMU/KVM)必须模拟这些设备的寄存器和行为 → 很耗 CPU。
- VirtIO 直接让 Guest 和 Hypervisor 通过约定好的高效接口交换数据,而不是假装成真实硬件。
特点:- 不模拟真实设备,而是用一个虚拟设备规范(VirtIO 设备)。
- Guest OS 和 Hypervisor 都理解这种协议,直接交互,减少模拟开销。
- Guest 中的驱动是 VirtIO 驱动,不是硬件驱动。
XV6 启动过程
QEMU中使用gdb调试XV6
make CPUS=1 qemu-gdb
输出:
*** Now run 'gdb' in another window.
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 1 -nographic -global virtio-mmio.force-legacy=false -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0 -S -gdb tcp::26000
- 本质上来说QEMU内部有一个gdb server,当我们启动之后,QEMU会等待gdb客户端连接。
- 现在 QEMU 已经启动了一个 GDB server(监听在 TCP 26000 端口),并且因为
-S参数,它暂停在 CPU 复位状态,等待调试器接管。 - 我们按照指引应该已经安装了
gdb-multiarch - to quit qemu type Ctrl-a x
gdb-multiarch
输出
warning: File "/home/cilinmengye/Github/xv6-labs-2022/.gdbinit" auto-loading has been declined by your auto-load safe-path' set to "$debugdir:$datadir/auto-load".
To enable execution of this file add
add-auto-load-safe-path /home/cilinmengye/Github/xv6-labs-2022/.gdbinit
line to your configuration file "/home/cilinmengye/.config/gdb/gdbinit".
To completely disable this security protection add
set auto-load safe-path /
line to your configuration file "/home/cilinmengye/.config/gdb/gdbinit".
For more information about this security protection see the
"Auto-loading safe path" section in the GDB manual. E.g., run from the shell:
info "(gdb)Auto-loading safe path"
我们的.gdbinit下有一些在gdb中执行的命令,能帮我们配置好调试环境, 现在GDB 在保护你不去自动执行一个未知路径的 .gdbinit 文件(可能有恶意命令)。但 GDB 发现它不在“安全路径”里,所以拒绝加载。安装上述提示完成:
mkdir -p ~/.config/gdb
echo 'add-auto-load-safe-path /home/cilinmengye/Github/xv6-labs-2022/.gdbinit' >> ~/.config/gdb/gdbinit
启动过程
-
kernel/kernel.ld提示从_entry开始: 这个时候没有内存分页,没有隔离性,并且运行在M-mode(machine mode)。-
在机器模式下,CPU 从_entry(kernel/entry.S:6)开始执行 xv6。RISC-V 启动时分页硬件是禁用的:虚拟地址直接映射到物理地址。
-
加载程序将 xv6 内核加载到物理地址 0x80000000 的内存中。它将内核放在 0x80000000 而不是 0x0 的原因是地址范围 0x0:0x80000000 包含了 I/O 设备。
-
_entry 指令设置堆栈,以便 xv6 可以运行 C 代码, 具体而言设置了
sp = stack0 + (hartid * 4096), 然后内核有了堆栈,_跳转到start执行C代码-
// kernel/start.c __attribute__ ((aligned (16))) char stack0[4096 * NCPU];
-
-
函数 start 执行一些仅在机器模式下允许的配置,然后切换到监督模式:
- mret 指令用于从之前的监督模式到机器模式的调用返回
- 函数start中像执行系统调用一般实现切换到监督模式:
- 在 mstatus 寄存器中将特权模式设置为监督模式
- 将 main 的地址写入 mepc 寄存器
- 将 0 写入页表寄存器 satp 来禁用监督模式中的虚拟地址转换
- 将所有中断和异常委托给监督模式。
-
在跳转到监督模式之前,start 执行了一项额外的任务:它编程时钟芯片以生成计时器中断。然后start 通过调用 mret“返回”到监督模式。同时跳转到了mepc记录的main函数中执行(kernel/main.c:11)。
-
-
kernel/main.c函数已经运行在supervisor mode了-
执行
kernel/proc.c中的userinit(): userinit有点像是胶水代码/Glue code(胶水代码不实现具体的功能,只是为了适配不同的部分而存在), 准备用户空间为启动第一个进程调用SYS_exec执行程序/init做准备userinit(kernel/proc.c:212)用于创建第一个进程。- 第一个进程执行一个用 RISC-V 汇编语言编写的小程序,initcode.S(user/initcode.S:1),通过调用 exec 系统调用重新进入内核。
- 一旦内核完成 exec,它返回到用户空间的/init 进程(user/init.c:15)
- Init会创建一个新的控制台设备文件,然后将其作为文件描述符 0、1 和 2 打开。接着它在控制台上启动一个 shell。系统启动完成。
-
执行完
userinit后,执行到scheduler函数,已知执行完scheduler后就会切换进程,逐渐执行到我们上述创建的第一个进程
-
-
在执行
userinit(kernel/proc.c:212)创建的第一个进程时到kernel/syscall.c下 -
然后到
kernel/sysfile.c 中的 sys_exec下,sys_exec中的第一件事情是从用户空间读取参数,它会读取path,也就是要执行程序的文件名。这里首先会为参数分配空间,然后从用户空间将参数拷贝到内核空间 -
然后执行到
user/init.c, 会为用户空间设置好一些东西,比如配置好console,调用fork,并在fork出的子进程中执行shell。
userinit 细节
userinit
- -->
allocproc:- Look in the process table for an UNUSED proc and init it
- Allocate a trapframe page.
- -->
proc_pagetable- map the trampoline code (这份代码在kernel text中物理地址是在运行时动态得知的,虚拟地址是固定的写在
kernel/memlayout.h) - map the trapframe page (虚拟地址是固定的写在
kernel/memlayout.h)
- map the trampoline code (这份代码在kernel text中物理地址是在运行时动态得知的,虚拟地址是固定的写在
- Set up new context to start executing at forkret in user space
- Look in the process table for an UNUSED proc and init it
- -->
uvmfirst- allocate one user page and copy initcode's instructions and data into it.
操行系统组织
操作系统必须满足三个要求:多路复用、隔离和交互:
- 例如,即使进程数量多于硬件 CPU 数量,操作系统也必须确保所有进程都有机会执行。
- 如果一个进程出现错误并发生故障,它不应该影响不依赖于该错误进程的其他进程。
- 完全隔离过于严格,因为应该允许进程有意地交互;管道就是一个例子。
xv6 是用“LP64” C 语言编写的,这意味着 C 编程语言中的长(L)和指针(P)都是 64 位的,但 int 是 32 位的。
Xv6 是为 qemu 的“-machine virt”选项模拟的支持硬件编写的。这包括 RAM、包含引导代码的 ROM、连接到用户键盘/屏幕的串行连接以及用于存储的磁盘。
- The inter-module interfaces are defined in defs.h (kernel/defs.h)

XV6 进程
xv6 中的隔离单位(与其他 Unix 操作系统一样)是进程。进程抽象防止一个进程破坏或监视另一个进程的内存、CPU、文件描述符等。它还防止进程破坏内核本身,这样进程就不能绕过内核的隔离机制。内核必须小心地实现进程抽象,因为有错误或恶意的应用程序可能会欺骗内核或硬件做坏事(例如,绕过隔离)。
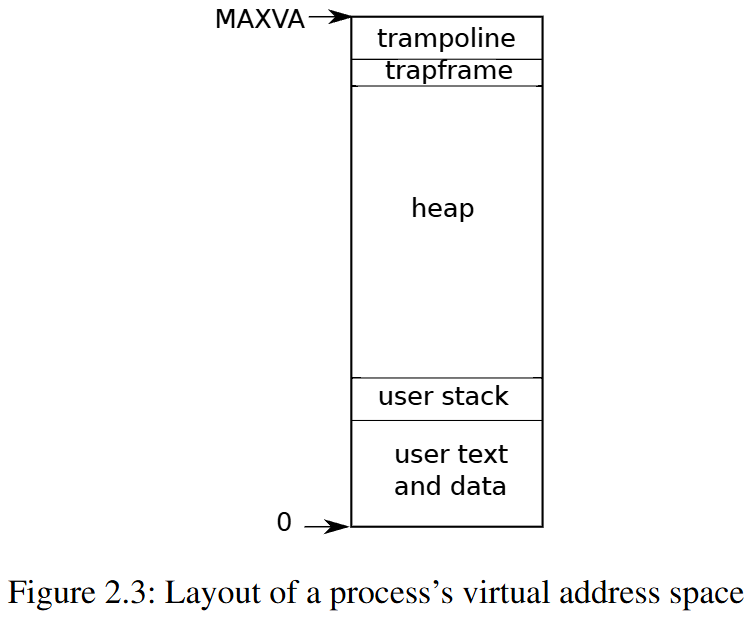
- pointers on the RISC-V are 64 bits wide; the hardware only uses the low 39 bits when looking up virtual addresses in page tables; and xv6 only uses 38 of those 39 bits. maximum address is defined as
MAXVAinkernel/riscv.h(#define MAXVA (1L << (9 + 9 + 9 + 12 - 1))) - At the top of the address space xv6 reserves a page for a trampoline and a page mapping the process’s trapframe to switch to the kernel
- The xv6 kernel maintains many pieces of state for each process, which it gathers into a struct proc
(kernel/proc.h:86).- 进程最重要的内核状态部分是其页表、内核堆栈和运行状态。
- 每个进程都有一个执行线程(简称线程),用于执行进程的指令。线程可以被挂起并在之后恢复。为了透明地在进程间切换,内核会挂起当前正在运行的线程,并恢复另一个进程的线程。
- 线程的大部分状态(局部变量、函数调用返回地址)都存储在它的栈上。
- 每个进程有两个栈:用户栈和内核栈(p->kstack)。
- 当进程执行用户指令时,只有它的用户栈在使用中,而内核栈是空的。
- 当进程进入内核(执行系统调用或中断时),内核代码会在进程的内核栈上执行;当进程处于内核中时,它的用户栈仍然包含保存的数据,但并未被主动使用。
- 一个进程的线程会在积极使用其用户栈和内核栈之间交替。内核栈是独立的(并且对用户代码是受保护的) 。这样即使进程损坏了它的用户栈,内核仍然可以执行。
- 一个进程可以通过执行 RISC-V 的 ecall 指令来进行系统调用,该指令会提升硬件特权级别,并将程序计数器改变为一个内核定义的入口点。在入口点的代码会切换到内核栈,并执行实现系统调用的内核指令。当系统调用完成后,内核会切换回用户栈
- returns to user space by calling the sret instruction, which lowers the hardware privilege level and resumes executing user instructions just after the system call instruction.
- 一个进程的线程可以在内核中“阻塞”以等待 I/O,并在 I/O 完成后从它停止的地方继续执行。
- Process state
p->state:- allocated
- ready to run
- running
- waiting for I/O
- exiting
p->pagetable包含进程的页表
现实世界 VS XV6
- 现代操作系统支持一个进程内包含多个线程,以允许单个进程利用多个 CPU。
- 在进程内支持多个线程涉及相当多的机制,这些机制 xv6 没有,包括潜在的接口变更(例如,Linux 的 clone,fork 的一个变体),以控制进程的哪些方面线程可以共享。
- 线程之前共享进程的:
- 地址空间
- 所有线程共享同一块虚拟内存,包括代码段、数据段、堆(heap)。
- 全局变量 & 静态变量
- 打开的文件描述符(open file descriptors)
- 信号处理器(signal handlers)
- 进程的当前工作目录
- 进程的用户 ID、组 ID
- 内存映射区域(memory-mapped files, shared libraries)
- 地址空间
- 这些是线程自己的,不与其他线程共享:
- 线程栈(stack)
- 每个线程有自己的栈空间,存放该线程的局部变量、函数调用信息等。
- 寄存器上下文
- 包括程序计数器(PC)、通用寄存器等,保证线程切换时能恢复执行。
- 线程局部存储(Thread Local Storage, TLS)
- 特殊关键字(如 C 里的
__thread/ C++ 里的thread_local)声明的变量。
- 特殊关键字(如 C 里的
- 线程栈(stack)
Lec04 Page tables
Address Spaces
我们想要某种机制,能够将不同程序之间的内存隔离开来,这样类似的事情就不会发生(例如cat程序弄乱了Shell程序的内存镜像,隔离性被破坏了)。一种实现方式是地址空间(Address Spaces)。
- 我们给包括内核在内的所有程序专属的地址空间。
- 当我们运行cat时,它的地址空间从0到某个地址结束。当我们运行Shell时,它的地址也从0开始到某个地址结束。内核的地址空间也从0开始到某个地址结束。
- 如果cat程序想要向地址1000写入数据,那么cat只会向它自己的地址1000,而不是Shell的地址1000写入数据。
- 基本上来说,每个程序都运行在自己的地址空间,并且这些地址空间彼此之间相互独立。在这种不同地址空间的概念中,cat程序甚至都不具备引用属于Shell的内存地址的能力。
页表
- page table保存在内存中,MMU只是会去查看page table
- 在RISC-V上一个叫做SATP的寄存器会保存地址地址关系表单(page table)
- 每个应用程序都有自己独立的表单,并且这个表单定义了应用程序的地址空间。所以当操作系统将CPU从一个应用程序切换到另一个应用程序时,同时也需要切换SATP寄存器中的内容,从而指向新的进程保存在物理内存中的地址对应表单。
有关RISC-V的一件有意思的事情是,虚拟内存地址都是64bit, 但是实际上,在我们使用的RSIC-V处理器上,并不是所有的64bit都被使用了,也就是说高25bit并没有被使用。这样的结果是限制了虚拟内存地址的数量,虚拟内存地址的数量现在只有\(2^{39}\)个,大概是512GB。
-
当然,如果必要的话,最新的处理器或许可以支持更大的地址空间,只需要将未使用的25bit拿出来做为虚拟内存地址的一部分即可。
-
被使用的39bit中,有27bit被用来当做index,12bit被用来当做offset。
在RISC-V中,物理内存地址是56bit。所以物理内存可以大于单个虚拟内存地址空间,但是也最多到\(2^{56}\)。大多数主板还不支持\(2^{56}\)这么大的物理内存
- 物理内存地址是56bit,其中44bit是物理page号(PPN,Physical Page Number),剩下12bit是offset完全继承自虚拟内存地址(也就是地址转换时,只需要将虚拟内存中的27bit翻译成物理内存中的44bit的page号,剩下的12bitoffset直接拷贝过来即可)。
- 这是由硬件设计人员决定的。所以RISC-V的设计人员认为56bit的物理内存地址是个不错的选择。可以假定,他们是通过技术发展的趋势得到这里的数字。比如说,设计是为了满足5年的需求,可以预测物理内存在5年内不可能超过2^56这么大。

- 第一个标志位是Valid。如果Valid bit位为1,那么表明这是一条合法的PTE,你可以用它来做地址翻译。对于刚刚举得那个小例子(注,应用程序只用了1个page的例子),我们只使用了3个page directory,每个page directory中只有第0个PTE被使用了,所以只有第0个PTE的Valid bit位会被设置成1,其他的511个PTE的Valid bit为0。这个标志位告诉MMU,你不能使用这条PTE,因为这条PTE并不包含有用的信息。
- 下两个标志位分别是Readable和Writable。表明你是否可以读/写这个page。
- Executable表明你可以从这个page执行指令。
- User表明这个page可以被运行在用户空间的进程访问。
- 其他标志位并不是那么重要,他们偶尔会出现,前面5个是重要的标志位。
当page table为空, MMU会告诉操作系统或者处理器,抱歉我不能翻译这个地址,最终这会变成一个page fault。如果一个地址不能被翻译,那就不翻译。就像你在运算时除以0一样,处理器会拒绝那样做。
页表缓存(Translation Lookaside Buffer)
你会经常看到它的缩写TLB。基本上来说,这就是Page Table Entry的缓存,也就是PTE的缓存。
处理器第一次查找一个虚拟地址时,硬件通过3级page table得到最终的PPN,TLB会保存虚拟地址到物理地址的映射关系。这样下一次当你访问同一个虚拟地址时,处理器可以查看TLB,TLB会直接返回物理地址,而不需要通过page table得到结果。
有很多种方法都可以实现TLB,对于你们来说最重要的是知道TLB是存在的。
这是处理器中的一些逻辑,对于操作系统来说是不可见的,操作系统也不需要知道TLB是如何工作的。你们需要知道TLB存在的唯一原因是,如果你切换了page table,操作系统需要告诉处理器当前正在切换page table,处理器会清空TLB。
所以操作系统知道TLB是存在的,但只会时不时的告诉操作系统,现在的TLB不能用了,因为要切换page table了。在RISC-V中,清空TLB的指令是
sfence_vma。
学生提问:在这个机制中,TLB发生在哪一步,是在地址翻译之前还是之后?
Frans教授:整个CPU和MMU都在处理器芯片中,所以在一个RISC-V芯片中,有多个CPU核,MMU和TLB存在于每一个CPU核里面。RISC-V处理器有L1 cache,L2 Cache,有些cache是根据物理地址索引的,有些cache是根据虚拟地址索引的,由虚拟地址索引的cache位于MMU之前,由物理地址索引的cache位于MMU之后。
操作系统对于这里的地址翻译有完全的控制,它可以实现各种各样的功能。比如,当一个PTE是无效的,硬件会返回一个page fault,对于这个page fault,操作系统可以更新 page table并再次尝试指令。
Kernel Page Table
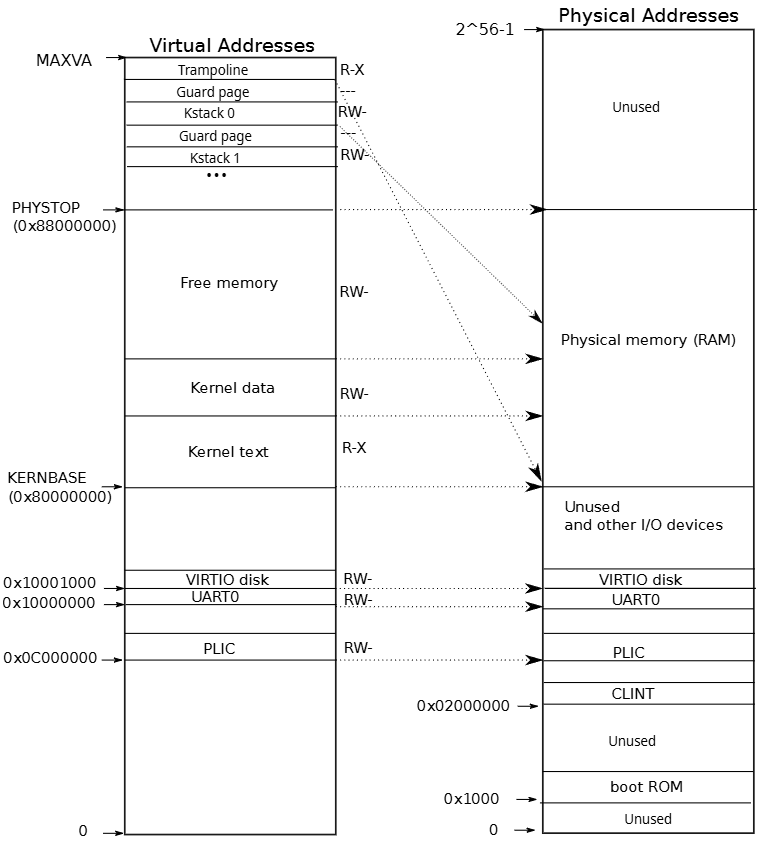
- 图中的右半部分的结构完全由硬件设计者决定。当操作系统启动时,会从地址0x80000000开始运行,这个地址其实也是由硬件设计者决定的。
- 主板的设计人员决定了,在完成了虚拟到物理地址的翻译之后,如果得到的物理地址大于0x80000000会走向DRAM芯片,如果得到的物理地址低于0x80000000会走向不同的I/O设备。这是由这个主板的设计人员决定的物理结构。
- 首先,物理地址0是保留的,物理地址0x10090000对应以太网,地址0x80000000对应DDR内存,处理器外的易失存储(Off-Chip Volatile Memory),也就是主板上的DRAM芯片。
- 地址0x1000是boot ROM的物理地址,当你对主板上电,主板做的第一件事情就是运行存储在boot ROM中的代码,当boot完成之后,会跳转到地址0x80000000,操作系统需要确保那个地址有一些数据能够接着启动操作系统。
- PLIC是中断控制器(Platform-Level Interrupt Controller)
- CLINT(Core Local Interruptor)也是中断的一部分。所以多个设备都能产生中断,需要中断控制器来将这些中断路由到合适的处理函数。
- UART0(Universal Asynchronous Receiver/Transmitter)负责与Console和显示器交互。
- VIRTIO disk,与磁盘进行交互。
- maximum address is defined as
MAXVAinkernel/riscv.h(#define MAXVA (1L << (9 + 9 + 9 + 12 - 1)) == 0x4000000000 (0有9个))
学生提问:当读指令从CPU发出后,它是怎么路由到正确的I/O设备的?比如说,当CPU要发出指令时,它可以发现现在地址是低于0x80000000,但是它怎么将指令送到正确的I/O设备?
Frans教授:你可以认为在RISC-V中有一个多路输出选择器(demultiplexer)。
- 虚拟空间地址由操作系统决定,因为我们想让XV6尽可能的简单易懂,所以这里的虚拟地址到物理地址的映射,大部分是相等的关系。
- 当机器刚刚启动时,还没有可用的page,XV6操作系统会设置好内核使用的虚拟地址空间。(上述左图就是内核使用的虚拟地址空间)
- 比如说内核会按照这种方式设置page table,虚拟地址0x02000000对应物理地址0x02000000。这意味着左侧低于PHYSTOP的虚拟地址,与右侧使用的物理地址是一样的。
trampoline 页面 and 内核栈 + 保护页(guard page)
trampoline page包含了内核的trap处理代码
大多数内核虚拟地址是“直接映射(direct-mapped)”到物理内存的(内核可以通过一个固定偏移直接访问物理内存)。
有少数页面不是按那种直接映射来放的,其中两个例外是:
- trampoline 页面:在虚拟地址空间的顶端被单独映射(用于陷入/返回),并且内核同时在它的 direct map 区也映射了同一个物理页(所以同一物理页在虚拟空间里出现了两次映射)。
- 一处映射在固定的高位虚拟地址(通常用常量
TRAMPOLINE表示),这是为 trap/interrupt 入口专门设置的; - 另一处映射在内核的 direct-mapping(物理内存的内核虚拟地址区)里,按“内核基址 + 物理地址偏移”的方式映射,用于内核以直接物理偏移读写该页。
- 一处映射在固定的高位虚拟地址(通常用常量
- 内核栈页面 + 保护页:每个进程有自己的内核栈,高地址处有实际栈页,栈下面紧跟一个未映射的保护页(guard page),其 PTE 无效(PTE_V 不设置),若内核栈溢出访问到保护页则触发页异常以便 panic —— 这比静默覆盖其它内核内存更安全。
- 除此之外,这里还有两件重要的事情:
- 第一件事情是,有一些page在虚拟内存中的地址很靠后,比如kernel stack在虚拟内存中的地址就很靠后。
- 这是因为在它之下有一个未被映射的Guard page,这个Guard page对应的PTE的Valid 标志位没有设置,这样,如果kernel stack耗尽了,它会溢出到Guard page。
- 但是因为Guard page的PTE中Valid标志位未设置,会导致立即触发page fault,这样的结果好过内存越界之后造成的数据混乱。立即触发一个panic(也就是page fault),你就知道kernel stack出错了。
- 同时我们也又不想浪费物理内存给Guard page,所以Guard page不会映射到任何物理内存,它只是占据了虚拟地址空间的一段靠后的地址。
- 同时,kernel stack被映射了两次,在靠后的虚拟地址映射了一次,在PHYSTOP下的Kernel data中又映射了一次,但是实际使用的时候用的是上面的部分,因为有Guard page会更加安全。
- 这是众多你可以通过page table实现的有意思的事情之一: 你可以将两个虚拟地址映射到同一个物理地址。XV6至少在1-2个地方用到类似的技巧。这的kernel stack和Guard page就是XV6基于page table使用的有趣技巧的一个例子。
- 第二件事情是权限。例如Kernel text page被标位R-X,意味着你可以读它,也可以在这个地址段执行指令,但是你不能向Kernel text写数据。通过设置权限我们可以尽早的发现Bug从而避免Bug。
- 第一件事情是,有一些page在虚拟内存中的地址很靠后,比如kernel stack在虚拟内存中的地址就很靠后。
Free Memory for user process
在kernel page table中,有一段Free Memory,它对应了物理内存中的一段地址:

XV6使用这段free memory来存放用户进程的page table,text和data。如果我们运行了非常多的用户进程,某个时间点我们会耗尽这段内存,这个时候fork或者exec会返回错误。
内核作为一个特殊的程序和普通用户程序所看到的虚拟地址内存映像是不一样的,内核需要额外考虑需要很多内存映像,如设备的,boot ROM的,网络的...
同时可以说内核为进程放弃了一些自己的内存,但是进程的虚拟地址空间理论上与内核的虚拟地址空间一样大,虽然实际中肯定不会这么大。
如下为用户程序的虚拟内存映像:
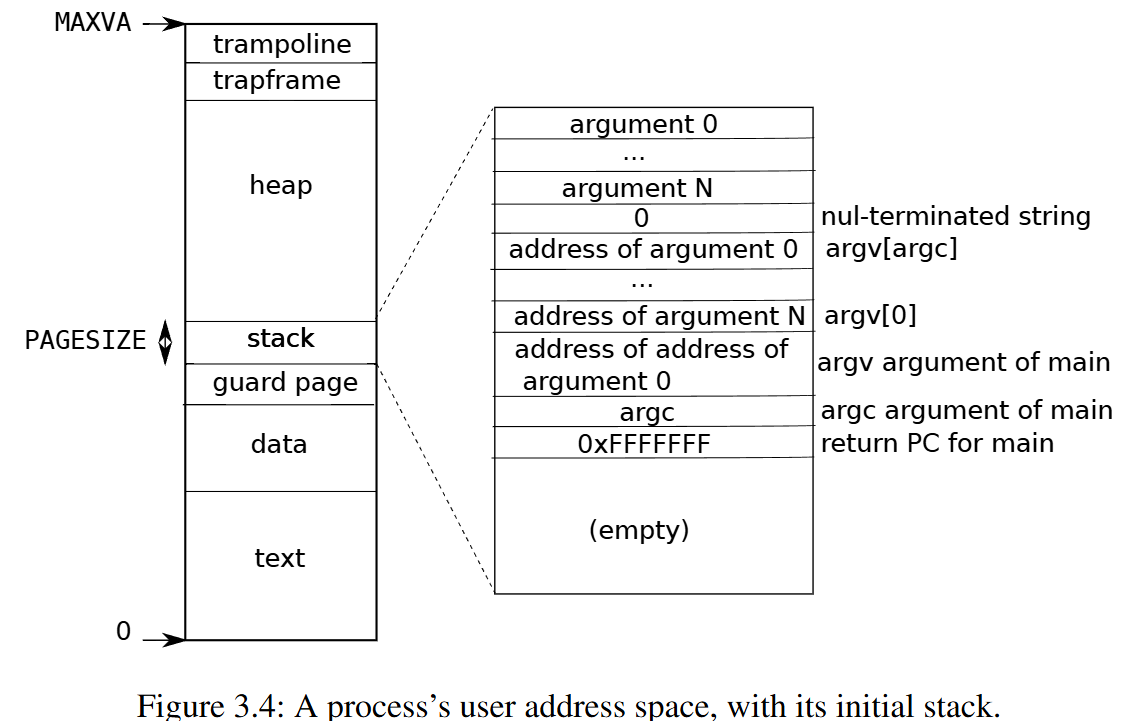
- 每一个用户进程都有一个对应的kernel stack 和 user stack
kvminit 函数
kernel/main.c kvminit()kernel/vm.c kvminit()- kvmmap函数,将每一个I/O设备映射到内核。
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
memlayout.h- UART0对应了地址0x10000000
- 所以,通过kvmmap可以将物理地址映射到相同的虚拟地址(注,因为kvmmap的前两个参数一致)。
- 所以总结一下,
kvminit是用来初始化kernel的vm, 其会调用kalloc函数生成页目录 ,调用kvmmap函数将虚拟地址映射到物理地址:void kvmmap(pagetable_t kpgtbl, uint64 va, uint64 pa, uint64 sz, int perm)- sz为映射内存的大小
- perm为权限
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);- etext是kernel text的最后一个地址
kvminithart 函数
将kvminit得到的kernel页目录地址设置到SATP寄存器
管理虚拟内存的一个难点是,一旦执行了类似于SATP这样的指令,你相当于将一个page table加载到了SATP寄存器,你的世界完全改变了。现在每一个地址都会被你设置好的page table所翻译。
因为kernel page的映射关系中,虚拟地址到物理地址是完全相等的。所以,在我们打开虚拟地址翻译硬件之后,地址翻译硬件会将一个虚拟地址翻译到相同的物理地址。我们接下来的行动并不会出错
walk 函数
walk函数模拟了MMU,返回的是va对应的最低级page table的PTE
每个CPU核只有一个SATP寄存器,但是在每个proc结构体,如果你查看proc.h,里面有一个指向page table的指针,这对应了进程的根page table物理内存地址。
Code: creating an address space
pagetable_t in kernel/riscv.h as typedef uint64 *pagetable_t; // 512 PTEs
Lec05 Calling conventions and stack frames RISC-V (TA)
RISC-V寄存器
hartid 就是 RISC-V 中的 “hardware thread id” —— 每个物理核心或硬件线程(hart)在系统中的唯一编号。内核用这个编号区分不同的 CPU(per-CPU/hart)资源和数据结构(比如每个 hart 的 kernel stack、lock、cpu struct 等)
hartid 从哪儿来(硬件/CSR)
- CSR(control and status register) 寄存器
- 当要保存这个寄存器时,通常保存到进程的
trapframe
tp 是 RISC-V 的一个通用寄存器(寄存器名为 x4),在 RISC-V ABI 中约定用作“thread pointer”(线程指针 / TLS 基址)——也就是指向当前线程/进程的线程局部存储(或内核中用作每-hart 指针/ID)的寄存器。
草稿寄存器
(mscratch 和 sscratch)向异常处理程序提供一个空闲可用的寄存器。
Stack and GDB
学生提问:.asm文件和.s文件有什么区别?
TA:我并不是百分百确定。这两类文件都是汇编代码,.asm文件中包含大量额外的标注,而.s文件中没有。所以通常来说当你编译你的C代码,你得到的是.s文件。如果你好奇我们是如何得到.asm文件,makefile里面包含了具体的步骤。
语法差别:AT&T vs Intel
-
AT&T(默认 GCC 输出):操作数顺序
src, dest,寄存器以%rax形式,立即数以$1,指令后缀如movq。 -
Intel(更贴近文档/Windows/NASM):操作数顺序
dest, src,寄存器rax,没有$前缀,更常见于.asm文件示例。
Makefile中通过$(OBJDUMP) -S $K/kernel > $K/kernel.asm
扩展一下就是riscv64-linux-gnu-objdump -S ./kernel/kernel > ./kernel.asm
Caller-saved(调用者保存)寄存器:调用某个函数之前,如果调用者(caller)想在调用后仍然使用这些寄存器的值,必须在调用前自己保存;被调用函数可以随便覆盖它们。也叫 volatile / 临时寄存器。
Callee-saved(被调用者保存)寄存器:被调用函数(callee)在使用这些寄存器之前,必须先把原值保存到栈(或其它地方),在返回前再恢复;调用者可以假定这些寄存器在调用后仍然保持不变。也叫 non-volatile / 保存寄存器。
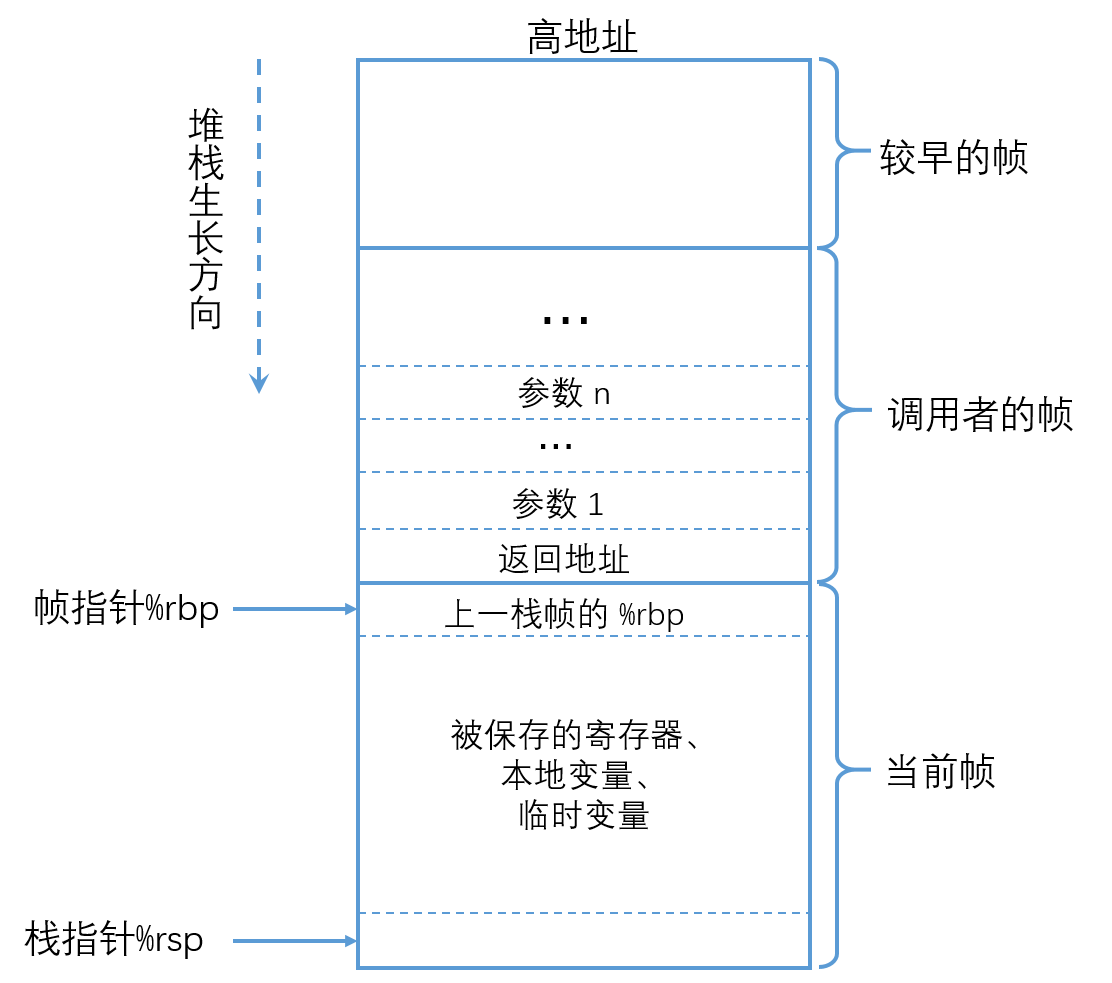
每一次我们调用一个函数,函数都会为自己创建一个Stack Frame,并且只给自己用。函数通过移动Stack Pointer来完成Stack Frame的空间分配。
有关Stack Frame中有两个重要的寄存器:
- 第一个是SP(Stack Pointer),它指向Stack的底部并代表了当前Stack Frame的位置。
- 第二个是FP(Frame Pointer),它指向当前Stack Frame的顶部。
- 因为Return address和指向前一个Stack Frame的的指针都在当前Stack Frame的固定位置,所以可以通过当前的FP寄存器寻址到这两个数据。
我们保存前一个Stack Frame的指针的原因是为了让我们能跳转回去。所以当前函数返回时,我们可以将前一个Frame Pointer存储到FP寄存器中。所以我们使用Frame Pointer来操纵我们的Stack Frames,并确保我们总是指向正确的函数。
案例
给一段用gdb查看栈帧的输出:
(gdb) bt
#0 syscall () at kernel/syscall.c:133
#1 0x0000000080001d16 in usertrap () at kernel/trap.c:67
#2 0x0505050505050505 in ?? ()
(gdb) info frame 0
Stack frame at 0x3fffffdfe0:
pc = 0x80001fe2 in syscall (kernel/syscall.c:133); saved pc = 0x80001d16
called by frame at 0x3fffffe000
source language c.
Arglist at 0x3fffffdfe0, args:
Locals at 0x3fffffdfe0, Previous frame's sp is 0x3fffffdfe0
(gdb) info frame 1
Stack frame at 0x3fffffe000:
pc = 0x80001d16 in usertrap (kernel/trap.c:67); saved pc = 0x505050505050505
called by frame at 0x0, caller of frame at 0x3fffffdfe0
source language c.
Arglist at 0x3fffffe000, args:
Locals at 0x3fffffe000, Previous frame's sp is 0x3fffffe000
Saved registers:
ra at 0x3fffffdff8, fp at 0x3fffffdff0, s1 at 0x3fffffdfe8, s2 at 0x3fffffdfe0, pc at 0x3fffffdff8
-
Stack frame at xxx表示当前函数的frame point(frame register的值) -
pc = xxx; saved pc = xxx前者表示当前函数执行到的pc值,后者表示下次要返回时,应该回到的pc值- 你可以看到如果当前栈帧为0,每次执行时pc = xxx是会随着执行而变动的,因为pc值变了
- 但是如果是以前执行的栈帧,那么会固定在执行跳转的指令的下一条指令
-
called by frame at xxx, caller of frame at xxx前者表示调用当前栈帧函数的函数的frame point,后者表示当前栈帧函数所调用的函数的frame point -
Arglist at xxx表示当前栈帧函数的参数所在栈帧中的位置 -
典型情况(没有 frame pointer 或编译器/CFI 指定 CFA 就等于 caller SP): Previous frame's sp 的值会显示和Stack frame一样
- 什么时候它们会不同:
- 如果编译器保留并用 frame pointer(如 rbp / s0/fp) 管理帧,DWARF 可能定义
CFA = fp + offset,这时Stack frame at(CFA)会是fp+offset,而Previous frame's sp仍然可能是不同的值(caller 的真实 SP)。 - 或者 DWARF/CFI 指定
CFA = $sp + 16(有偏移),那么Stack frame at=caller_sp + 16,与Previous frame's sp不同。 - 在启发式(没有 CFI)展开时,GDB 可能用不同规则计算,两者也可能不相等。
- 如果编译器保留并用 frame pointer(如 rbp / s0/fp) 管理帧,DWARF 可能定义
- 什么时候它们会不同:
Struct
基本上来说,struct在内存中是一段连续的地址,如果我们有一个struct,并且有f1,f2,f3三个字段。
当我们创建这样一个struct时,内存中相应的字段会彼此相邻。你可以认为struct像是一个数组,但是里面的不同字段的类型可以不一样。
Lec06 Isolation & system call entry/exit
Trap 与 用户状态和内核状态
每当
- 程序执行系统调用
- 程序出现了类似page fault、运算时除以0的错误
- 一个设备触发了中断使得当前程序运行需要响应内核设备驱动
都会发生用户空间和内核空间的切换,其通常被称为trap
- 用户/内核状态
- 32 通用寄存器(包含很重要的stack pointer(也叫做堆栈寄存器 stack register))
- 此外在硬件中还有一个寄存器叫做程序计数器(Program Counter Register)。
- 表明当前mode的标志位,这个标志位表明了当前是supervisor mode还是user mode。
- 还有一堆控制CPU工作方式的寄存器,比如SATP(Supervisor Address Translation and Protection)寄存器,它包含了指向page table的物理内存地址(详见4.3)
- STVEC(Supervisor Trap Vector Base Address Register)寄存器,它指向了内核中处理trap的指令的起始地址。
- SEPC(Supervisor Exception Program Counter)寄存器,在trap的过程中保存程序计数器的值。
- SSRATCH(Supervisor Scratch Register)寄存器,这也是个非常重要的寄存器(详见6.5)。
- 这些寄存器表明了执行系统调用时计算机的状态
- trap之前CPU的所有状态都设置成运行用户代码而不是内核代码,我们实际上需要更改一些这里的状态,这样我们才可以运行系统内核中普通的C程序
- 保存32 通用寄存器和pc
- xv6视乎和NEMU中一样, 调用ecall指令时pc是由硬件保存到了sepc中,同时将stvec寄存器中的值放到pc中,设置异常号scause...
- 将mode改成supervisor mode(调用ecall指令时硬件完成的)
- 切换SATP寄存器(在这之前会等待其他还用user page table的操作)和堆栈寄存器
- 即现在我们还在user page table,我们需要切换到kernel page table。
- 我们需要创建或者找到一个kernel stack,并将Stack Pointer寄存器的内容指向那个kernel stack。这样才能给C代码提供栈。
- ... 更多详情信息应该阅读
kernel/trampoline.S- 如进入trap后除了上述保存上下文的操作,还会切换到内核的hartid, 清空TLB,跳转到usertrap()处理异常
- 需要特别指出的是,supervisor mode中的代码并不能读写任意物理地址。在supervisor mode中,就像普通的用户代码一样,也需要通过page table来访问内存。
- 保存32 通用寄存器和pc
Trap代码执行流程
-
ECALL指令 -->
-
kernel/trampoline.S中的uservec:- trap.c sets stvec to point here, so traps from user space start here, in supervisor mode, but with a user page table
- each process has a separate p->trapframe memory area, trapframe用于保存当前进程的上下文;(TRAPFRAME) in every process's user page table.
-
保存完上下文等操作后就跳转到
kernel/trap.c下的usertrap执行, 依据异常号scause- 要么是处理系统调用
- 要么处理设备中断
-
处理完后调用
kernel/trap.c 下的usertrapret为了用户空间的代码恢复执行- 其会调用
kernel/trampoline.S 下的userret用汇编代码完成一些恢复上下文的事情。最终,在这个汇编函数中会调用机器指令返回到用户空间,并且恢复ECALL之后的用户程序的执行。
- 其会调用
中断开关细节
当 hart 因 ecall(或其它 trap/interrupt)进入 trap handler 时,硬件会把当前的 “允许中断” 状态存起来并把中断禁止掉;在执行返回指令(mret / sret / uret 等)时,硬件会把先前保存的中断允许位恢复回来(也就是说只有在 trap 发生前中断是 enable 的情况下,返回时才会重新启用)。这是 RISC-V 特权规范规定的标准行为。
具体细节
uservec函数
首先执行ecall需要保存用户进程的状态,此时内核不能更改任何用户进程状态的寄存器,那么问题来了,我们要将用户进程的状态存放到哪呢?
- 存放到trapframe page
- 每一个用户进程都用一个独立的trapframe page空间,且trapframe page被映射到了相同的虚拟地址上
- trapframe page记录于user page table中,kernel page table未做相关记录
- trapframe page中的内容除了32个通用寄存器还包括内核事先存放在trapframe中的数据:
- uint64 kernel_satp; // kernel page table
- uint64 kernel_sp; // top of process's kernel stack
- uint64 kernel_trap; // usertrap()
- uint64 epc; // saved user program counter
- uint64 kernel_hartid; // saved kernel tp
那么内核如何知道用户进程的trapframe page在哪?
- 我们之前说了每个进程的trapframe page被映射到了相同的虚拟地址上,内核直接定义了
#define TRAPFRAME (TRAMPOLINE - PGSIZE)(kernel/memlayout.h) - 所以可以通过直接执行
csrw sscratch, a0 li a0, TRAPFRAME让a0的值暂存到sscratch, 然后让a0得到进程trapframe page的值去使用
内核每次要返回用户态时(即通过执行sret),都会调用usertrapret(kernel/trap.c),其中内核会存放一些数据到用户进程的trapframe page中:
我们首次进入内核的程序是user/initcode.S,其非常简单而且是用汇编代码编写,没有使用到栈,所以最初最初的内核栈我们没有设置好也没关系,经过user/initcode.S要返回时调用usertrapret我们就设置好了栈,整体结构如下:
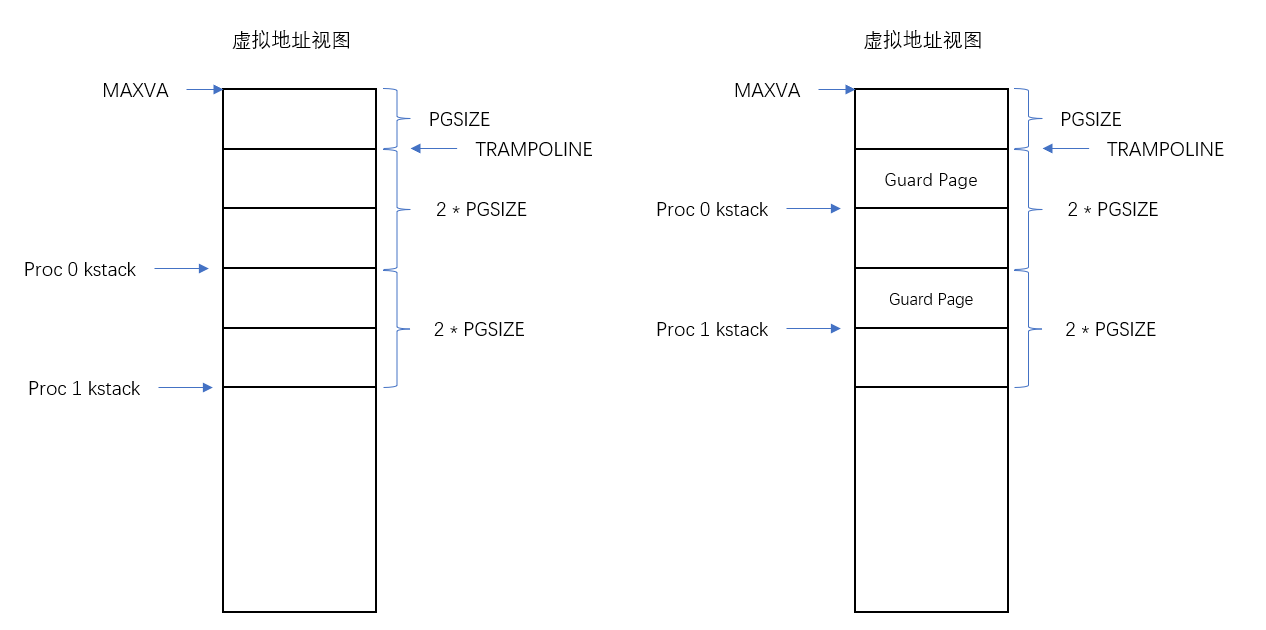
左图为在kernel/proc.c初始化进程的stack时的栈分布
在通过usertrapret的p->trapframe->kernel_sp = p->kstack + PGSIZE;矫正后,p->trapframe->kernel_sp所代表的stack point会如右图所示,即这个操作就是留出了Guard Page而已
// set up trapframe values that uservec will need when
// the process next traps into the kernel.
p->trapframe->kernel_satp = r_satp(); // kernel page table
p->trapframe->kernel_sp = p->kstack + PGSIZE; // process's kernel stack
p->trapframe->kernel_trap = (uint64)usertrap;
p->trapframe->kernel_hartid = r_tp(); // hartid for cpuid()
这些数据确实被使用到了(kernel/trampoline.S)
# initialize kernel stack pointer, from p->trapframe->kernel_sp
# 切换回进程的内核栈
ld sp, 8(a0)
# make tp hold the current hartid, from p->trapframe->kernel_hartid
# 切换回内核的hartid
ld tp, 32(a0)
# load the address of usertrap(), from p->trapframe->kernel_trap
# 设置内核处理异常的代码地址
ld t0, 16(a0)
# fetch the kernel page table address, from p->trapframe->kernel_satp.
# 切换回内核的page table
ld t1, 0(a0)
为什么我们要使用内存中一个新的区域(指的是trapframe page),而不是使用程序的栈?
- 这个问题的答案是,我们不确定用户程序是否有栈,必然有一些编程语言没有栈,对于这些编程语言的程序,Stack Pointer不指向任何地址。当然,也有一些编程语言有栈,但是或许它的格式很奇怪,内核并不能理解
- 比如,编程语言以堆中以小块来分配栈,编程语言的运行时知道如何使用这些小块的内存来作为栈,但是内核并不知道。所以,如果我们想要运行任意编程语言实现的用户程序,内核就不能假设用户内存的哪部分可以访问,哪部分有效,哪部分存在。
- 所以内核需要自己管理这些寄存器的保存,这就是为什么内核将这些内容保存在属于内核内存的trapframe中,而不是用户内存。
为什么代码没有崩溃?毕竟我们在内存中的某个位置执行代码,程序计数器保存的是虚拟地址,如果我们切换了page table,为什么同一个虚拟地址不会通过新的page table寻址走到一些无关的page中?看起来我们现在没有崩溃并且还在执行这些指令。
- 因为我们还在trampoline代码中,而trampoline代码在用户空间和内核空间都映射到了同一个地址。
usertrap函数
处理中断嵌套和CTE重入
w_stvec((uint64)kernelvec);- 目前为止,我们只讨论过当trap是由用户空间发起时会发生什么。
- 如果trap从内核空间发起,将会是一个非常不同的处理流程,因为从内核发起的话,程序已经在使用kernel page table。所以当trap发生时,程序执行仍然在内核的话,很多处理都不必存在。
- 可以理解为如果这个时候在内核态再出现任何的异常就走
kernelvec吧
p->trapframe->epc = r_sepc();- 当程序还在内核中执行时,我们可能切换到另一个进程,并进入到那个程序的用户空间,然后那个进程可能再调用一个系统调用进而导致SEPC寄存器的内容被覆盖。
- PS: 这里有个奇怪的点,既然如此为何没有保存其他的CSR寄存器呢?
- 在开中断之前
intr_on, 我们已经保存了sepc,使用了scause和sstatus,之后不会再使用到scause和sstatus,所以我们可以不用保存scause和sstatus寄存器
- 在开中断之前
- PS: 同时这里还有个奇怪的点,此时因为完全处于内核态了,使用的是内核的page table,为何内核的page table可以引用得到用户态的TRAPFRAME?TRAPFRAME不是只在user page table上吗?
- 因为
p->trapframe本身就是记录的物理地址,而这一片物理地址已经被内核通过kvmmap映射过了(即虚拟地址==物理地址), 所以内核有相应的映射关系不会出错 - 其初始化代码在
kernel/proc.c:p->trapframe = (struct trapframe *)kalloc()
- 因为
开中断
intr_on(); 中断总是会被RISC-V的trap硬件关闭, 有些系统调用需要许多时间处理为了使中断可以更快的服务,我们需要在保存完用户进程上下文,设置完中断嵌套的内容后就可以打开中断了
usertrapret函数
-
intr_off();关闭中断 -
w_stvec(trampoline_uservec);因为我们将要从内核态回到用户态,要设置下trampoline_uservec(其实其值就是uservec),含义就是如果接下来出现任何的异常就走uservec吧 -
设置SSTATUS寄存器- 这个寄存器的SPP bit位控制了sret指令的行为,该bit为0表示下次执行sret的时候,我们想要返回user mode而不是supervisor mode。
- 这个寄存器的SPIE bit位控制了,在执行完sret之后,是否打开中断。因为我们在返回到用户空间之后,我们的确希望打开中断,所以这里将SPIE bit位设置为1。
-
实际上,我们会在汇编代码trampoline中完成page table的切换,并且也只能在trampoline中完成切换
- 因为只有trampoline中代码是同时在用户和内核空间中映射。但是我们现在还没有在trampoline代码中,我们现在还在一个普通的C函数中
-
sret是我们在kernel中的最后一条指令,当我执行完这条指令:
- 程序会切换回user mode
- SEPC寄存器的数值会被拷贝到PC寄存器(程序计数器)
- 重新打开中断
Kernel Page Table 和 User Page Table切换细节
首先User page Table一直是保存在p->pagetable上
Kernel Page Tabel复杂一点,在操作系统启动时,主CPU通过调用kvminit创建了内核线程统一的页目录并保存在pagetable_t kernel_pagetable; (kernel/vm.c:12);然后再调用kvminithart()将CPU上的satp寄存器写成kernel_pagetable
然后其他副CPU做的事情就只是调用kvminithart()
这时每个CPU都是在运行调度器线程,我们知道调度器线程-->内核线程
内核线程会通过usertrapret-->用户线程
在usertrapret中有p->trapframe->kernel_satp = r_satp();, 这样就完成了每个内核线程将内核页目录保存的目录,下次再次从user model发生trap时,会从这里恢复内核页目录
关于硬件和软件的权衡
为什么ecall不多做点工作来将代码执行从用户空间切换到内核空间呢?为什么ecall不会保存用户寄存器,或者切换page table指针来指向kernel page table,或者自动的设置Stack Pointer指向kernel stack,或者直接跳转到kernel的C代码,而不是在这里运行复杂的汇编代码?
RISC-V秉持了这样一个观点:ecall只完成尽量少必须要完成的工作,其他的工作都交给软件完成。这里的原因是,RISC-V设计者想要为软件和操作系统的程序员提供最大的灵活性:
- 举个例子,因为这里的ecall是如此的简单,或许某些操作系统可以在不切换page table的前提下,执行部分系统调用。切换page table的代价比较高,如果ecall打包完成了这部分工作,那就不能对一些系统调用进行改进,使其不用在不必要的场景切换page table。
- 某些操作系统同时将user和kernel的虚拟地址映射到一个page table中,这样在user和kernel之间切换时根本就不用切换page table。对于这样的操作系统来说,如果ecall切换了page table那将会是一种浪费,并且也减慢了程序的运行。
- 或许在一些系统调用过程中,一些寄存器不用保存,而哪些寄存器需要保存,哪些不需要,取决于于软件,编程语言,和编译器。通过不保存所有的32个寄存器或许可以节省大量的程序运行时间,所以你不会想要ecall迫使你保存所有的寄存器。
- 最后,对于某些简单的系统调用或许根本就不需要任何stack,所以对于一些非常关注性能的操作系统,ecall不会自动为你完成stack切换是极好的。
Lec08 Page faults
Page Fault Basics
-
在XV6中,一旦用户空间进程触发了page fault,会导致进程被杀掉。这是非常保守的处理方式。
-
stval故障地址或其他异常相关信息字写入stval- 当出现page fault的时候,XV6内核会打印出错的虚拟地址,并且这个地址会被保存在STVAL寄存器中。
- 当一个用户应用程序触发了page fault,page fault会使用trap机制将程序运行切换到内核
- 不同场景的page fault有不同的响应。不同的场景是指,比如因为load指令触发的page fault、因为store指令触发的page fault又或者是因为jump指令触发的page fault。
- 在SCAUSE保存了trap机制中进入到supervisor mode的原因
-
在page fault handler中我们或许想要修复page table,并重新执行对应的指令, 通过SEPC得到触发page fault的指令的地址。
Lazy page allocation
sbrk是XV6提供的系统调用,它使得用户应用程序能扩大自己的heap。
在XV6中,sbrk的实现默认是eager allocation。这表示了,一旦调用了sbrk,内核会立即分配应用程序所需要的物理内存。
- 通常来说,应用程序倾向于申请多于自己所需要的内存。这意味着,进程的内存消耗会增加许多,但是有部分内存永远也不会被应用程序所使用到。
利用lazy allocation:
- 使用虚拟内存和page fault handler
- sbrk系统调基本上不做任何事情,唯一需要做的事情就是提升p->sz,将p->sz增加n,其中n是需要新分配的内存page数量。但是内核在这个时间点并不会分配任何物理内存。
- 之后在某个时间点,应用程序使用到了新申请的那部分内存,这时会触发page fault,因为我们还没有将新的内存映射到page table。所以,如果我们解析一个大于旧的p->sz,但是又小于新的p->sz 的虚拟地址,我们希望内核能够分配一个内存page,并且重新执行指令。
使用lazy allocation,应用程序怎么才能知道当前已经没有物理内存可用了?
- 返回一个错误并杀掉进程。因为现在已经OOM(Out Of Memory)了,内核也无能为力
Copy On Write Fork
动机
fork创建一个子进程,其会创建父进程地址空间的一个完整的拷贝
但是exec做的第一件事情就是丢弃这个地址空间而且创建一个新的地址空间。
这里看起来有点浪费。
优化
当我们创建子进程时,与其创建,分配并拷贝内容到新的物理内存,其实我们可以直接共享父进程的物理内存page。所以这里,我们可以设置子进程的PTE指向父进程对应的物理内存page。
- 为了确保进程间的隔离性,我们可以将这里的父进程和子进程的PTE的标志位都设置成只读的。
- 在某个时间点,当我们需要更改内存的内容时,如父进程或者子进程都可能会执行store指令来更新一些全局变量,这时就会触发page fault,因为现在在向一个只读的PTE写数据。
- 在得到page fault之后,我们需要拷贝相应的物理page。
- 然后将page fault相关的物理内存page拷贝到新分配的物理内存page中,并将新分配的物理内存page映射到子进程。这时,新分配的物理内存page只对子进程的地址空间可见,所以我们可以将相应的PTE设置成可读写
- 同时当分配新地址空间给子进程后,原先的相应的PTE对于父进程也变成可读写的了。
- 重新执行store指令
- 因为子进程的地址空间来自于父进程的地址空间的拷贝,所以地址空间是相同的,不论是父进程还是子进程,都会有相同的处理方式。
新增元数据
- 内核必须要能够识别什么时候是一个copy-on-write场景。

- RSW 字段保留给操作系统使用,硬件将忽略该字段。内核可以随意使用这两个bit位。所以可以做的一件事情就是表示当前PTE是一个copy-on-write page。
共享的细节
- 当父进程退出时我们需要更加的小心,因为我们要判断是否能立即释放相应的物理page。如果有子进程还在使用这些物理page,而内核又释放了这些物理page,我们将会出问题。
- 我们需要对于每一个物理内存page的引用进行计数,当我们释放虚拟page时,我们将物理内存page的引用数减1,如果引用数等于0,那么我们就能释放物理内存page。所以在copy-on-write lab中,你们需要引入一些额外的数据结构或者元数据信息来完成引用计数。
Demand Paging
动机
程序的二进制文件可能非常的巨大,将它全部从磁盘加载到内存中将会是一个代价很高的操作。又或者data区域的大小远大于常见的场景所需要的大小,我们并不一定需要将整个二进制都加载到内存中。
优化
- 为什么不再等等,直到应用程序实际需要这些指令的时候再加载内存?
- 所以对于exec,在虚拟地址空间中,我们为text和data分配好地址段,但是相应的PTE并不对应任何物理内存page。对于这些PTE,我们只需要将valid bit位设置为0即可。
- 第一次page fault: 用户应用程序运行的第一条指令时,即位于地址0的指令是会触发第一个page fault的指令(应用程序是从地址0开始运行。text区域从地址0开始向上增长)
细节
我们这样延迟加载可能在某一时刻会遇到多个应用程序按照demand paging的方式启动,它们二进制文件的和大于实际物理内存的容量。
这其实回到了之前的一个问题:在lazy allocation中,如果内存耗尽了该如何办?
如果内存耗尽了,一个选择是撤回page(evict page):
-
什么样的page可以被撤回?并且该使用什么样的策略来撤回page?Least Recently Used(LRU)
-
在PTE中有个A标识符位,Access bit,任何时候一个page被读或者被写了,这个Access bit会被设置。
-
没有被Access过的page可以直接撤回,同时Access bit可以帮助我们实现LRU
-
那是不是要定时的将Access bit恢复成0?
是的,这是一个典型操作系统的行为。操作系统会扫描整个内存,这里有一些著名的算法例如clock algorithm,就是一种实现方式。
-
-
如果你要撤回一个page,你需要在dirty page和non-dirty page中做选择。dirty page是曾经被写过的page,而non-dirty page是只被读过, 选择哪个来撤回?
- 如果dirty page之后再被修改需要写两次,一次将dirty page对应的内存page写入文件系统,一次将需要替换上来的内容写入内存page
- 现实中会选择non-dirty page。可以直接撤回page。
- PTE D 标识符表示自从上次清除 D 位以来,该页是否被写入过。
现实世界
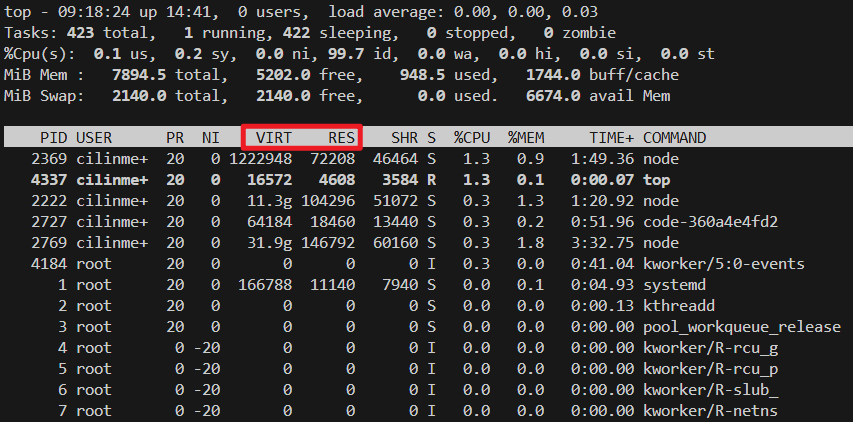
注意VIRT和RES两个字段分别表示虚拟内存地址空间的大小和实际使用的内存数量,从这里可以看出,实际使用的内存数量远小于地址空间的大小。
其中使用到的原理就是上述我们的lazy page等一系列延迟分配,按需分配的策略
Lec09 Interrupts
同步异常与异步异常
同步异常(synchronous exception)是由指令本身直接引起的陷入(trap/exception),也就是说它与当前正在执行的那条指令“同步”发生,发生时能精确地把故障发生的指令定位下来(通常通过保存出错指令的地址)。典型例子:非法指令、访问异常(page fault / access fault)、对齐错误、ECALL(系统调用)和断点(EBREAK)。这些都是同步异常
-
同步异常:由指令执行引发,发生在指令边界,可复现、可定位(deterministic)。处理时通常需要知道“是哪条指令”导致的(CPU 会保存 faulting PC)。
-
异步中断(asynchronous interrupt):由外部事件触发(定时器到期、外设发中断、IPI 等),与当前正在执行的指令流无直接对应,发生时不是“这条指令出了问题”,而是“外部事件需要处理”。
简言之:同步=指令自己造成;异步=来自外部/硬件事件。
设备中断
设备中断和系统调用有如下区别:
- asynchronous。当硬件生成中断时,Interrupt handler与当前运行的进程在CPU上没有任何关联。
- 但如果是系统调用的话,系统调用发生在运行进程的context下。
- Interrupt handler并不运行在任何特定进程的context中,它只是处理中断。
- concurrency。CPU和生成中断的设备是并行的在运行。网卡自己独立的处理来自网络的packet,然后在某个时间点产生中断,但是同时,CPU也在运行。所以我们在CPU和设备之间是真正的并行的,我们必须管理这里的并行。
- program device。我们这节课主要关注外部设备,例如网卡,UART,而这些设备需要被编程。
所有的设备都连接到处理器上,处理器上是通过Platform Level Interrupt Control,简称PLIC来处理设备中断。中断到达PLIC之后,PLIC会路由这些中断。如果所有的CPU核都正在处理中断,PLIC会保留中断直到有一个CPU核可以用来处理中断。所以PLIC需要保存一些内部数据来跟踪中断的状态。具体流程是:
- PLIC会通知当前有一个待处理的中断
- 其中一个CPU核会Claim接收中断,这样PLIC就不会把中断发给其他的CPU处理
- CPU核处理完中断之后,CPU会通知PLIC
- PLIC将不再保存中断的信息
大部分驱动都分为两个部分,bottom/top:
- bottom部分通常是Interrupt handler。当一个中断送到了CPU,并且CPU设置接收这个中断,CPU会调用相应的Interrupt handler。
- top部分,是用户进程,或者内核的其他部分调用的接口。
- 对于UART来说是read/write接口
- UART = Universal Asynchronous Receiver/Transmitter它是一种串口通信设备,在硬件中负责把 CPU/内存里的并行数据 ↔ 转换成 串行数据,并在两端之间进行异步传输。
在xv6中设置中断
相关寄存器

无论位于何种特权模式,所有异常都默认将控制权转移到 M 模式的异常处理程序。但 Unix 系统中大多数异常都应发送给 S 模式下的操作系统。
-
mideleg(Machine Interrupt Delegation,机器中断委托)CSR 控制将哪些中断委托给 S 模式
-
medeleg(Machine Exception Delegation, 机器态异常委托) CSR 将同步异常委托给 S 模式
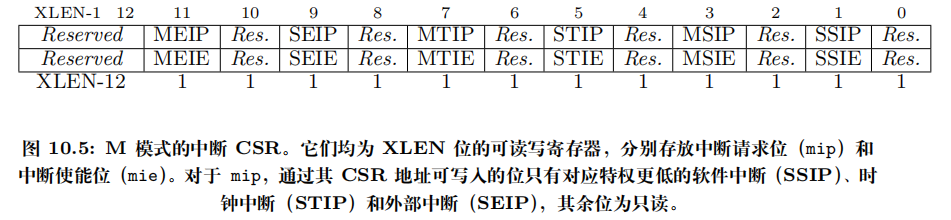
-
*IP(例如MEIP,SEIP,MTIP,STIP,MSIP,SSIP)
表示 Interrupt Pending(中断挂起)位,位于mip(Machine Interrupt Pending)或sip(Supervisor Interrupt Pending)这类 CSR 中。某位为 1 表示对应类型的中断在该特权级“挂起”了(有事件等待处理)。 -
*IE(例如MEIE,SEIE,MTIE,STIE,MSIE,SSIE)
表示 Interrupt Enable(中断使能)位,位于mie(Machine Interrupt Enable)或sie(Supervisor Interrupt Enable)这类 CSR 中。某位为 1 表示允许该类中断在该特权级被响应(如果全局允许且满足其它条件就会产生陷入)。
M / S 前缀表示目标特权级(M = Machine,S = Supervisor)。第二部分字母说明中断类型(E = External,T = Timer,S = Software)。
-
MEIP — Machine External Interrupt Pending(机器态外部中断挂起)
-
SEIP — Supervisor External Interrupt Pending(监督态外部中断挂起)
-
MTIP — Machine Timer Interrupt Pending(机器态定时器中断挂起)
-
STIP — Supervisor Timer Interrupt Pending(监督态定时器中断挂起)
-
MSIP — Machine Software Interrupt Pending(机器态软件中断 / IPI 挂起)
-
SSIP — Supervisor Software Interrupt Pending(监督态软件中断挂起)
-
MEIE — Machine External Interrupt Enable(机器态外部中断使能)
-
SEIE — Supervisor External Interrupt Enable(监督态外部中断使能)
-
MTIE — Machine Timer Interrupt Enable(机器态定时器中断使能)
-
STIE — Supervisor Timer Interrupt Enable(监督态定时器中断使能)
-
MSIE — Machine Software Interrupt Enable(机器态软件中断使能)
-
SSIE — Supervisor Software Interrupt Enable(监督态软件中断使能)
### XV6开关中断

上述为M model下的中断相关,这里为S model下的中断相关
根据委托 CSR 的配置,可能由 M 模式或 S 模式处理,但永远不会由 U 模式处理。
S 模式响应异常的具体行为也和 M 模式非常相似。若硬件线程响应异常并将其委托给 S 模式,则硬件会原子地进行如下状态转换,此时将使用 S 模式的 CSR,而不是 M 模式:
• 将发生异常的指令 PC 存入 sepc, 并将 PC 设为 stvec。
• 按图 10.3 将异常原因写入 scause,并将故障地址或其他异常相关信息字写入stval。
• 将 sstatus.SIE 置零以屏蔽中断,并将 SIE 的旧值存放在 SPIE 中。
• 将异常发生前的特权模式存放在 sstatus.SPP,并将当前特权模式设为 S。
在xv6下S model出来异常时的开关中断代码如下:
// kernel/riscv.h
// enable device interrupts
static inline void
intr_on()
{
w_sstatus(r_sstatus() | SSTATUS_SIE);
}
// disable device interrupts
static inline void
intr_off()
{
w_sstatus(r_sstatus() & ~SSTATUS_SIE);
}
启动流程
_entry()-->start: 将所有的中断都设置在Supervisor mode
-->main调用如下函数处理
- -->
consoleinit:调用- -->
uartinit: 配置好UART芯片使其可以被使用:- 先关闭UART芯片中断(即写IER寄存器,控制UART是否产生中断)
- 之后设置波特率(串口线的传输速率),设置字符长度为8bit
- 重置FIFO
- 最后再重新打开UART芯片中断
- -->
- -->
plicinit: PLIC与外设一样,也占用了一个I/O地址(0xC000_0000)。我们往对应的I/O地址上写使得- 使能UART的中断, 即设置PLIC会接收UART中断
- 设置PLIC接收来自IO磁盘的中断
- -->
plicinithart: 设置CPU对UART和IO磁盘的中断感兴趣 - -->
scheduler- -->
intr_on: 设置SSTATUS寄存器打开CPU接收中断
- -->
XV6 在多核(CPU)中每个cpu都会执行上述代码设置中断
设备驱动
驱动程序是操作系统中管理特定设备的代码:它配置设备硬件,指示设备执行操作,处理产生的中断,并与可能等待设备 I/O 的进程交互。
许多设备驱动程序在两种上下文中执行代码:一个在进程的内核线程中运行的上半部,以及一个在中断时执行的下半部。
- 上半部通过 read 和 write 等系统调用被调用,这些调用希望设备执行 I/O。这段代码可以要求硬件启动一个操作(例如,请求磁盘读取一个数据块)
- 然后代码等待操作完成。最终设备完成操作并触发中断。
- 驱动程序的中断处理程序作为下半部,确定哪个操作已完成,如果合适则唤醒等待的进程,并告诉硬件开始处理任何等待的下一个操作。
Console Drive,UART,键盘,显示器的整体关系
Console Drive的代码在kernel/console.c
UART Drive的代码在kernel/uart.c
键盘和显示器都是QEMU提供的硬件
键盘 ----> UART ----> 显示器
写 ↑ 写
↓
Console Drive
Console Drive内部实现了cons.buf用于缓冲数据
Console等待用户输入命令
- 在
user/init.c:19中我们初始化得到了Console的文件描述符,然后我们执行user/sh.c程序,不同通过user/sh.c getcmd来获得用户输入的命令 - 最终会通过read 系统调用 调用
consoleread(kernel/console.c:80), consoleread 从cons.buf中获取数据,若cons.buf无数据则通过sleep等待(kernel/console.c:96)
键盘输入字符
- 当用户输入字符时,UART 硬件请求 RISC-V 触发中断,中断处理程序调用 devintr(kernel/trap.c:178)
- 因为是UART引起的中断,devintr 会调用 uartintr(kernel/uart.c:176)
- uartintr(kernel/uart.c:176)从 UART 硬件读取由键盘输入字符,并将它们交给 consoleintr(kernel/console.c:136)
- consoleintr
- consoleintr 对退格键和一些其他字符进行特殊处理
- **将有意义的字符放入cons.buf中,当收到换行符时,consoleintr 唤醒等待的 consoleread **
- 调用
consputc(其调用uartputc_sync)把一个字符输出到显示器(通过 UART),并且对退格键做“可视擦除”的特殊处理。- 什么叫做通过 UART 把一个字符输出到显示器? 看下面的例子
Sh中通过write主动输出字符到显示器
本质上因为 QEMU 把它模拟的串口设备(比如 16550)和宿主机的显示器(display)连起来了,所以当 xv6 在虚拟机里往 THR 写字节时,QEMU 接收到这个写操作并把相应的字符输出到宿主display 或 QEMU 的串口窗口上.
- 在sh程序中调用
write(2, "$ ", 2); - 最终会通过write 系统调用 调用
consolewrite(kernel/console.c:59),consolewrite会调用uartputc(c) uartputc会调用uartstart执行WriteReg(THR, c);- 接下来的任务是硬件的事情了,最终就显示到了我们的显示器上
I/O并发
不管是我们Sh中通过write系统调用写入,还是键盘通过中断写入,最终都会通过uartputc或uartputc_sync这样的API写入到THR寄存器上
uartputc_sync直接写到THR寄存器上,不会等待 uart drive 中内部实现的uart_tx_bufuartputc会将字符先写入 uart drive 中内部实现 uart_tx_buf,然后再写入到THR寄存器上- 这是为了写入进程不必等待 UART 完成发送,只需将数据放入缓冲区uart_tx_buf即可
每次 UART 完成发送一个字节时,它都会生成一个中断使得uartintr 调用 uartstart
uartstart又将 uart drive 中内部实现 uart_tx_buf 中的字节取出写入到THR寄存器上
这一个过程有点像正反馈一样,一旦输出了一个字符就会通过中断不断将uart_tx_buf中的其他字符输出
因此,如果进程向控制台写入多个字节,通常第一个字节会通过
uartputc调用uartstart发送,而剩余的缓冲字节会在uartintr接收到传输完成中断时通过uartstart调用发送。直到uart_tx_buf为空。
通过缓冲和中断将设备活动与进程活动解耦
- 进程可以发送输出而无需等待设备
- 本质因为我们在uart中设置了缓冲区uart_tx_buf,发送到THR寄存器上的数据可以先放到缓冲区,而不用等待THR寄存器空闲
- 随后通过中断(因为次 UART 完成发送一个字节时,它都会生成一个中断),进而自动地调用中断处理函数,中断处理函数会从缓冲区取数据发送到THR寄存器
- 控制台驱动程序可以在没有进程等待读取的情况下处理输入
- 本质因为我们在console dirve中设置了缓冲区cons.buf, 来自键盘的输入可以先放到缓冲区中而不用等待进程的读取
- 通过键盘产生的中断时刻查看是否换行(即表示一行命令输入完成了),从而自动地唤醒
consoleread
这种解耦可以通过允许进程与设备 I/O 并发执行来提高性能,这在设备较慢(如 UART)或需要立即关注(如回显输入的字符)时尤为重要。这个概念有时被称为 I/O 并发。
UART驱动的top部分
UART (Universal Asynchronous Receiver/Transmitter) 本质上只是一种 串行通信控制器,它本身不会“知道”对面是什么设备。UART 只是把 CPU 内部的 数据寄存器 中的字节,转化为一连串的电平信号(发送时),或把接收到的电平信号还原为字节(接收时)。
所以 UART 本质上只是 一个传输通道。
想看一下如何从Shell程序输出提示符“$ ”到Console。
首先Shell程序来自init.c,是userinit时创建执行的进程。
init.c
-
if(open("console", O_RDWR) < 0){ // 如果第一次 open 失败(例如 console 节点还不存在) mknod("console", CONSOLE, 0); // 创建一个设备节点 open("console", O_RDWR); // 因为是在初始化时,所以console是第一个打开的文件,这里的文件描述符0。 } dup(0); // stdout dup(0); // stderr // 最终 0,1,2 三个 fd 都指向同一个打开的 console // 确保标准输入/输出/错误(fd 0,1,2)都已连接到一个控制台设备 // 方便后续的程序可以直接使用 read(0,...) / printf / 写 stderr 等与控制台交互。 -
exec("sh", argv);-->getcmd() in user/sh.c-
-->
write(2, "$ ", 2)-
-->
sys_write -
// kernel/proc.h struct file *ofile[NOFILE]; // kernel/file.h struct file { enum { FD_NONE, FD_PIPE, FD_INODE, FD_DEVICE } type; int ref; // reference count char readable; char writable; struct pipe *pipe; // FD_PIPE struct inode *ip; // FD_INODE and FD_DEVICE uint off; // FD_INODE short major; // FD_DEVICE }; uint64 sys_write(void) { struct file *f; int n; uint64 p; argaddr(1, &p); argint(2, &n); if(argfd(0, 0, &f) < 0) // argfd中通过文件描述符fd,得到myproc()->ofile[fd] return -1; return filewrite(f, p, n); }- -->
filewrite(struct file *f, uint64 addr, int n) in file.c- filewrite函数中首先会判断文件描述符的类型
- 于设备类型的文件描述符,我们会为这个特定的设备执行设备相应的write函数:
devsw[f->major].write(1, addr, n); - -->
consolewrite(int user_src, uint64 src, int n) in console.c- -->
uartputc(int c) in uart.c - uartputc函数将字符写入给UART设备,所以你可以认为consolewrite是一个UART驱动的top部分。
- 在UART的内部会有一个环形buffer(这是内核内存,我们内核内部实现的FIFO,与硬件的FIFO是不一样的)用来收发数据; 当buffer是满的时候会sleep一段时间,将CPU出让给其他进程。否则:
- -->
uartstart通知设备执行操作。首先是检查当前设备是否空闲,如果空闲的话,我们会从buffer中读出数据,然后将数据写入到THR(Transmission Holding Register)发送寄存器WriteReg(THR, c);。 - THR上的数据会被硬件发送到对端设备的接收器,最后放入对端的 RHR/RX FIFO,供对端处理器读取。
- 一旦数据写入完到THR,系统调用会返回,用户应用程序Shell就可以继续执行。这里从内核返回到用户空间的机制与lec06的trap机制是一样的。
- -->
- -->
- -->
-
-
硬件在物理线上发送字节
- UART 硬件按配置波特率把 THR 中的字节序列化并发出(加起始位/停止位/校验位等)。这个过程与 CPU 并行进行,耗时由波特率决定。
发送寄存器变“空”并触发中断
- 当硬件把 THR 的内容移入移位寄存器/发送完成后,THR 空(或 FIFO 有空位),UART 会把对应的 pending 位置 1(例如
TXE/THRE),并在中断允许时产生中断。
uartstart
- LSR (offset 5):线路状态寄存器,报告数据准备好 (Data Ready)、THR 空、发送完成、帧/溢出/校验错误等状态。驱动用它做轮询或判断何时可写下一个字节。
(ReadReg(LSR) & LSR_TX_IDLE) == 0如果该位为 0,说明硬件当前还在忙(THR/FIFO 没空位),不能写新字节,驱动返回并等待硬件中断通知。
- RBR (offset 0, read):接收缓冲寄存器,内核/驱动从这里读到串口收到的字节。
- THR (offset 0, write):发送保持寄存器,写入一个字节后 UART 会把它序列化并发送。
可以将uartstart() 当做是把内核缓冲“泵”到硬件 THR/FIFO 的函数
- 其具体实现中
while(1)外层循环:循环尝试继续从缓冲拿字节并写入 THR,直到缓冲空或硬件变忙为止。 - 它既可能由
uartputc直接调用以立刻开始发送 - 也会被 ISR 在 THR 空中断里调用继续发送后续字节(当 THR/FIFO 有空位(可再写入)时会触发中断。
中断处理程序(top-half ISR)会再次调用 uartstart())
UART驱动的bottom部分
处理设备中断
如果我们通过键盘向Console输出字符,即键盘生成了一个中断会发生什么?
处理中断老样子来到了usertrap in kernel/trap.c
- -->
devintr- 通过SCAUSE寄存器判断当前中断是否是来自于外设的中断
- -->
plic_claim in plic.c- 在这个函数中,当前CPU核会告知PLIC,自己要处理中断,PLIC_SCLAIM会将中断号返回
- 发现是UART中断 -->
uartintr in uart.c- 若有数据则从UART的接受寄存器RHR中读取数据
uartgetc,之后将获取到的数据传递给consoleintr(这是键盘向Console输入数据发生中断会执行的代码)- -->
consputc向uart写,内部调用的是uartputc_sync(c) - 写入console 内部维护的cons.buf中, 并wakeup等待cons.buf的进程
- -->
- 否则-->
uartstart
- 若有数据则从UART的接受寄存器RHR中读取数据
并发上的问题
consoleread和consoleintr中调用了acquire(因为consoleread取缓冲区而consoleintr写缓冲区), 该锁保护Console drive的数据结构免受并发访问:
- 两个在不同 CPU 上的进程可能会同时调用
consoleread - 硬件可能会在某个 CPU 正在执行
consoleread时要求该 CPU 处理Console(实际上是 UART)中断 - 硬件还可能在
consoleread执行时在其他 CPU 上发送Console中断
并发需要特别注意的另一个方面是,一个进程可能正在等待设备输入,但中断信号输入到达时,可能正在运行的是另一个进程(或者根本没有进程)
producer/consumser并发
在uart driver中我们有个buffer
- 调用
uartputc函数的为producer - Interrupt handler,也就是uartintr函数,在这个场景下是consumer
也告诉我们driver的top和bottom代码能够通过中断在不同的CPU下并发执行
这里的buffer存在于内存中,并且只有一份,所以,所有的CPU核都并行的与这一份数据交互。所以我们才需要lock。
同样在console drive中,也有一个buffer
- 这个场景下Shell变成了consumser,因为Shell是从buffer中读取数据
- 而键盘是producer,它将数据写入到buffer中
UART 现实世界
传输数据过慢
UART 驱动程序通过读取 UART 控制寄存器逐字节获取数据,这种模式称为程序化 I/O,因为软件在驱动数据移动。
在需要高速移动大量数据的设备通常使用直接内存访问(DMA):
- DMA 设备硬件直接将接收到的数据写入 RAM,并从 RAM 读取发送数据。
- 现代磁盘和网络设备使用 DMA。
- DMA 设备的驱动程序会在 RAM 中准备数据,然后通过向控制寄存器写入单个数据来通知设备处理准备好的数据。(基本原理和UART一样)
中断导致CPU开销过高
如果你有一个高性能的设备,例如你有一个千兆网卡,这个网卡收到了大量的小包,网卡每秒可以生成1.5Mpps,这意味着每一个微秒,CPU都需要处理一个中断,这就超过了CPU的处理能力。那么当网卡收到大量包,并且处理器不能处理这么多中断的时候该怎么办呢?
- 高速设备(如网络和磁盘控制器)会使用一些技巧来减少中断的需求。
- 一种技巧是将一批输入或输出请求作为一个中断来处理。
- 另一种技巧是驱动程序完全禁用中断,并定期检查设备是否需要关注。这种技术称为轮询。、
- 如果设备执行操作非常快,轮询是有意义的,但如果设备大部分时间处于空闲状态,轮询就会浪费 CPU 时间。
- 一些驱动程序会在轮询和中断之间动态切换。
双重复制导致过慢
UART 驱动程序先将接收到的数据先复制到内核的缓冲区,然后再复制到用户空间。这种双重复制会显著降低性能。
- 一些操作系统能够直接在用户空间缓冲区和设备硬件之间移动数据,通常使用 DMA。
- 应用程序可能需要对设备执行那些普通 read/write 不能完成的控制操作。(例如,在Console drive中启用/禁用行缓冲)
ioctl系统调用可以处理这种情况
定时器中断
为何需要定时器中断
Xv6 使用定时器中断来维持其时钟,并使其能够在计算密集型进程之间切换;如果内核线程有时会花费大量时间进行计算,而没有返回用户空间,在内核线程之间公平地分配 CPU 时间片是有用的
-
Xv6 编程了这个时钟硬件,使其定期中断每个 CPU, 强制进行线程切换 (内核代码需要意识到它可能会被挂起(由于定时器中断)并在不同的 CPU 上恢复)
-
RISC-V 要求定时器中断必须在机器模式下而不是监督模式下进行。RISCV 机器模式不使用分页,并且有一套独立的控制寄存器,因此将普通的 xv6 内核代码在机器模式下运行并不实用。因此,xv6 完全独立于上述的陷阱机制来处理定时器中断。
-
usertrap 和 kerneltrap 中的 yield 调用会导致这种切换。
定时器相关寄存器

在看上述复杂的寄存器之前我们先看个简单的:

当 CPU 从 S 模式下发生异常或中断时,硬件会自动做两件事:
- 保存:把当前的中断使能标志
SIE(Supervisor Interrupt Enable)保存到SPIE中。 - 关闭中断:把
SIE清零,禁止进一步的中断进入。
SPIE位作用就是进入异常前 SIE 的历史记录
SIE位作用就是在S Model下启用或禁用所有中断:
- 当 SIE 清零时,S Model下不会接受中断。
- 当 HART 以User Model运行时,SIE 中的值将被忽略,并启用S Model级中断。
- S Model程序可以使用 SIE CSR 禁用单个中断源。
SPP位指示 hart(代表CPU的id) 在进入S Model之前执行的特权级别。
- 当发生trap时,如果trap源自User Model,则 SPP 设置为 0,否则设置为 1。
- 当执行 sret 指令从trap处理程序返回时,如果 SPP 位为 0,则特权级别设置为User Model;
- 如果 SPP 位为 1,则特权级别设置为S Model;然后 SPP 设置为 0。
sstatus寄存器是mstatus寄存器的子集
- 重点:
sstatus不是一个独立的硬件寄存器,而是mstatus中某些位的“窗口”或“投影”。
好了现在我们来看看mstatus中的内容,其中的MIE, MPP, MPIE作用和S model下的差不多:
- mstatus:全局状态寄存器(machine status)。
MIE:M 模式全局中断使能。SIE:S 模式全局中断使能。MPP:当 trap 返回时,要回到哪个模式(00=U,01=S,11=M)。MPIE/SPIE:保存 trap 发生前的中断开关状态。
- medeleg / mideleg:中断或异常委托寄存器。
- 默认所有 trap 进入 M 模式;通过这些寄存器可以“下放”给 S 模式。
- xv6 就是把大部分 trap 下放到 S 模式,唯独 定时器中断不能下放,所以它必须先在 M 模式处理。
- mhartid:当前硬件线程(hart)的 ID。多核 CPU 中每个 hart 都有唯一 ID。xv6 把它存进
tp寄存器,用于cpuid()。
上述各种寄存器位之间的从trap中保存和恢复都是为了支持嵌套中断
进入 trap 时:
xPIE ← xIE(保存原来是否开中断)- 如果 xIE=0(比如 SIE=0),说明在进入 trap 前,中断是关的。那不是应该收不到中断吗?为什么还会发生 trap?
- trap 的来源分两类
- 异步 trap:也就是我们常说的 中断 (interrupt),比如时钟中断、外设中断。它们确实受 xIE 控制。
- 如果
xIE=0,那么这一层级的中断不会触发。
- 如果
- 同步 trap:比如执行了非法指令、访存出错、系统调用(ecall)。
- 这类 trap 和 xIE 是否开中断无关,只要错误发生了,trap 就会触发。 所以即使
xIE=0,trap 依然可能发生,只是不会有异步中断而已。
- 这类 trap 和 xIE 是否开中断无关,只要错误发生了,trap 就会触发。 所以即使
- 异步 trap:也就是我们常说的 中断 (interrupt),比如时钟中断、外设中断。它们确实受 xIE 控制。
xIE ← 0(先关中断,保证 trap 处理原子性)xPP ← 当前模式(保存之前在哪个模式运行)
执行 xRET(如 mret/sret)返回时:
xIE ← xPIE(恢复中断开关状态)模式 ← xPP(回到原先的模式)xPIE ← 1(准备下次 trap)
初始化定时器中断
start
(kernel/start.c:63) 用于设置接收定时器中断:
void
start()
{
// set M Previous Privilege mode to Supervisor, for mret.
// 把 MSTATUS.MPP 设为 S,并把 MEPC 设为 main,这样执行 mret 时就在 supervisor model 下执行 main()。
unsigned long x = r_mstatus();
x &= ~MSTATUS_MPP_MASK;
x |= MSTATUS_MPP_S;
w_mstatus(x);
// set M Exception Program Counter to main, for mret.
// requires gcc -mcmodel=medany
w_mepc((uint64)main);
// disable paging for now.
// 关闭分页(w_satp(0))因为 machine 模式不使用分页,等待 supervisor 启用自己页表
w_satp(0);
// delegate all interrupts and exceptions to supervisor mode.
// 把异常/中断 medeleg/mideleg 大量委派给 S-mode(让大部分中断/异常走 supervisor 处理)。
w_medeleg(0xffff);
w_mideleg(0xffff);
w_sie(r_sie() | SIE_SEIE | SIE_STIE | SIE_SSIE);
// configure Physical Memory Protection to give supervisor mode
// access to all of physical memory.
w_pmpaddr0(0x3fffffffffffffull);
w_pmpcfg0(0xf);
// ask for clock interrupts.
timerinit();
// keep each CPU's hartid in its tp register, for cpuid().
int id = r_mhartid();
w_tp(id);
// switch to supervisor mode and jump to main().
asm volatile("mret");
}
sstatus.SIE(在 sstatus 中)是 总开关,决定 S 模式是否能响应中断。
sie 里的 SEIE/STIE/SSIE 是 分开关,决定具体哪类中断能触发。所以,要让 S 态能响应时钟中断,必须同时:
- 打开总开关:
sstatus.SIE = 1 - 打开分开关:
sie.STIE = 1
-
SIE[SEIE] → 开启 外部中断 (Supervisor External Interrupt)
-
SIE[STIE] → 开启 时钟中断 (Supervisor Timer Interrupt)
-
SIE[SSIE] → 开启 软件中断 (Supervisor Software Interrupt)
-
软件中断 (Software Interrupt) 是一种 由 CPU 自己的控制寄存器触发的中断信号,而不是由外部设备(如网卡、磁盘)或定时器硬件产生的。
- 在 RISC-V 中,每个 hart(硬件线程/CPU 核心)都有一个 MSIP(Machine Software Interrupt Pending)位(在 CLINT 芯片里)。
- 当某个 hart 的 MSIP 被设置为 1 时,它就会产生一个软件中断。
-
外部中断:由芯片外设(如磁盘、串口、网卡)发出的信号。
定时器中断:由定时器硬件周期性触发。
软件中断:由软件(内核/其他核)通过写寄存器主动触发。
-
最后使用内联汇编编写的mret十分重要:它的功能是:从机器模式的异常或中断处理程序返回到异常发生前的程序状态。
执行 mret 时,CPU 会自动做几件事情(基于 RISC-V Privileged Spec):
- 恢复特权级
- 从
mstatus.MPP(Machine Previous Privilege)中读取以前的特权级,并设置当前特权级M-mode→MPP的值。 - 例如:如果异常发生前是
S-mode,那么MPP = S,执行mret后 CPU 会切回 S 模式。
- 从
- 恢复中断使能位
mstatus.MIE ← mstatus.MPIEMPIE记录的是异常发生前的 Machine 中断使能状态。- 执行
mret后,允许/禁止中断恢复到 trap 前的状态。
- 设置 MPIE
- 执行
mret时,MPIE ← 1(按照规范设定,方便下次异常使用)
- 执行
- 跳转到异常发生前的地址
- PC ←
mepc(Machine Exception Program Counter) mepc是在异常发生时由硬件保存的返回地址。
- PC ←
经过start的设置,我们执行完start后就会跳转到main函数执行,并且处于S model下
timerinit
// arrange to receive timer interrupts.
// they will arrive in machine mode at
// at timervec in kernelvec.S,
// which turns them into software interrupts for
// devintr() in trap.c.
void
timerinit()
{
// each CPU has a separate source of timer interrupts.
int id = r_mhartid();
// ask the CLINT for a timer interrupt.
// timerinit() 用 CLINT(核心本地中断控制器)设置 下一次触发时间。
int interval = 1000000; // cycles; about 1/10th second in qemu.
*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;
// prepare information in scratch[] for timervec.
// scratch[0..2] : space for timervec to save registers.
// scratch[3] : address of CLINT MTIMECMP register.
// scratch[4] : desired interval (in cycles) between timer interrupts.
uint64 *scratch = &timer_scratch[id][0];
scratch[3] = CLINT_MTIMECMP(id);
scratch[4] = interval;
w_mscratch((uint64)scratch);
// set the machine-mode trap handler.
w_mtvec((uint64)timervec);
// enable machine-mode interrupts.
w_mstatus(r_mstatus() | MSTATUS_MIE);
// enable machine-mode timer interrupts.
w_mie(r_mie() | MIE_MTIE);
}
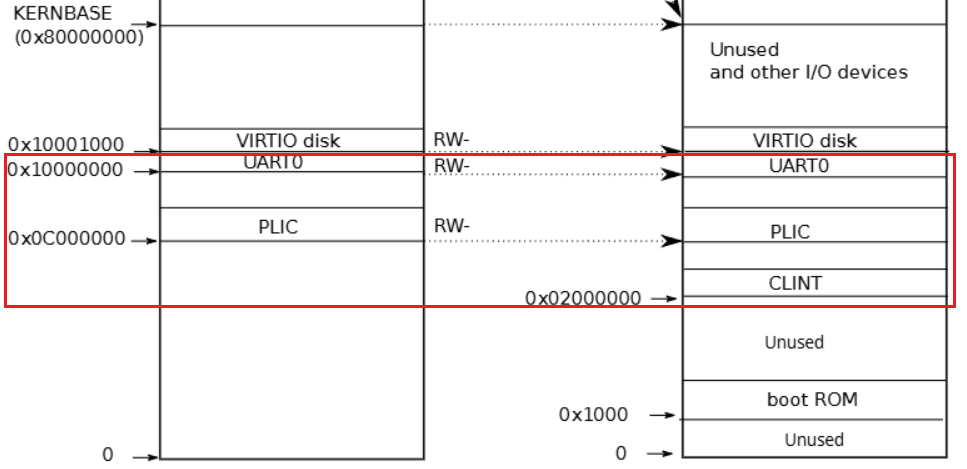
PLIC和 CLINT 硬件(本地中断器)也通过MMIO在物理内存映射了一块地址用于与硬件沟通,在XV6代码中kernel/memlayout.h有相关内容:
// core local interruptor (CLINT), which contains the timer.
#define CLINT 0x2000000L
#define CLINT_MTIMECMP(hartid) (CLINT + 0x4000 + 8*(hartid))
#define CLINT_MTIME (CLINT + 0xBFF8) // cycles since boot.
-
CLINT(Core Local Interruptor)是 RISC-V 的一个片上外设,每个核(hart)都有自己的一组 CLINT 寄存器。
- 它提供两种功能:
- 软件中断 (MSIP) → 用于核间通信(IPI)。
- 定时器中断 (MTIME / MTIMECMP) → 提供周期性的时钟信号。
- 它提供两种功能:
-
CLINT_MTIME- 作用:一个不断递增的 64 位计数器(以 CPU 的时钟周期为单位)。
- 谁来更新? 硬件自动递增,软件不能手动写。
- 用法:内核用它来获取当前时间(以 tick 表示,不是人类能直接看懂的秒)。
比如:拿到的就是当前“硬件时钟”。
uint64 t = *(uint64*)CLINT_MTIME; -
CLINT_MTIMECMP(hartid)- 作用:每个 CPU 核心都有一个独立的 比较寄存器 (MTIMECMP)。
- 用法:软件往里写一个“将来时刻”。
- 当
MTIME >= MTIMECMP(hart)时,CLINT 就会对这个 hart 触发 定时器中断 (MTI)。
比如上述代码中的:意思是“现在的时间再加上
interval个时钟周期后,触发一次定时器中断”。*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;
timervec
在 start.c 里,xv6 会为每个 hart 设置好一个 mscratch 区域(一块内存),存储必要的信息:
scratch[0,8,16]:用来暂存寄存器(a1, a2, a3)。scratch[24]:保存这个 hart 的CLINT_MTIMECMP地址。scratch[32]:保存定时器间隔interval。
M-mode trap handler(timervec)执行时:
- 保存寄存器。
- 更新
mtimecmp(设置下一个闹钟)。 - 向 S-mode 发一个“软件中断”,让 S-mode 来执行调度逻辑。
- 恢复寄存器并返回(
mret)。
.globl timervec
.align 4
timervec:
# start.c has set up the memory that mscratch points to:
# scratch[0,8,16] : register save area.
# scratch[24] : address of CLINT's MTIMECMP register.
# scratch[32] : desired interval between interrupts.
csrrw a0, mscratch, a0
sd a1, 0(a0)
sd a2, 8(a0)
sd a3, 16(a0)
# schedule the next timer interrupt
# by adding interval to mtimecmp.
ld a1, 24(a0) # CLINT_MTIMECMP(hart)
ld a2, 32(a0) # interval
ld a3, 0(a1) # 当前 mtimecmp 值
add a3, a3, a2 # mtimecmp = mtimecmp + interval
sd a3, 0(a1) # 写回 -> 设置下一次闹钟
# arrange for a supervisor software interrupt
# after this handler returns.
li a1, 2
csrw sip, a1
ld a3, 16(a0)
ld a2, 8(a0)
ld a1, 0(a0)
csrrw a0, mscratch, a0
mret
上述内容其实就是在向CLINT 硬件(本地中断器)编程
同时在XV6中定时器中断是由M Model处理的,其不关心你当前是在哪个特权级(U/S/M),它一定会切到 M-mode,然后走 mtvec,执行timervec
然后我们在timervec中又不断更新mtimecmp,使得定时器中断可以重复发生
Lec10 Multiprocessors and locking
为什么要使用锁?
应用程序运行在多个CPU核上, 可能系统调用并行的运行在多个CPU核上,那么它们可能会并行的访问内核中共享的数据结构。
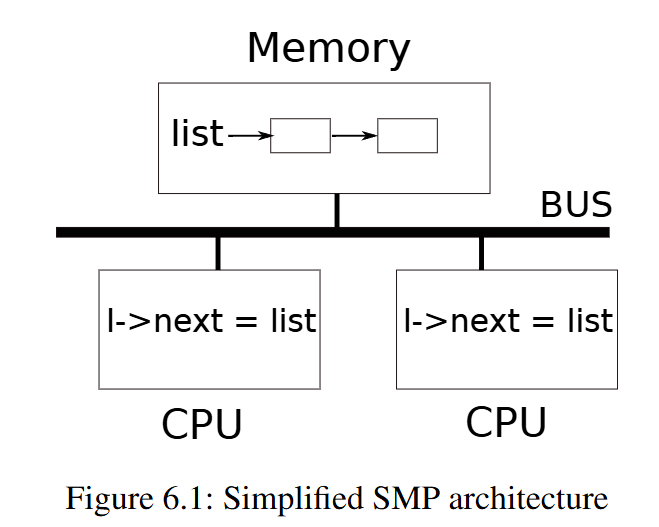
当并行的访问数据结构时,例如一个核在读取数据,另一个核在写入数据,我们需要使用锁来协调对于共享数据的更新,以确保数据的一致性。所以,我们需要锁来控制并确保共享的数据是正确的。
什么时候使用锁?
锁限制了并发性,也限制了性能。那这带来了一个问题,什么时候才必须要加锁呢?非常保守同时也是非常简单的规则:
- 如果两个进程访问了一个共享的数据结构,并且其中一个进程会更新共享的数据结构,那么就需要对于这个共享的数据结构加锁。
- 但是同时这条规则某种程度上来说又太过严格了。如果有两个进程共享一个数据结构,并且其中一个进程会更新这个数据结构,在某些场合不加锁也可以正常工作。不加锁的程序通常称为lock-free program
自动加锁真的正确吗?
为什么不一旦我们有了一个共享的数据结构,任何操作这个共享数据结构都需要获取锁,那么对于XV6来说,每个结构体都需要自带一个锁,当我们对于结构体做任何操作的时候,会自动获取锁。这样会不会能够避免race condition?
答案是不能够避免,锁应该与操作而不是数据关联,所以自动加锁在某些场景下会出问题
对于文件操作,文件从一个目录移到另一个目录,我们现在将文件d1/x移到文件d2/y。
如果我们按照前面说的,对数据结构自动加锁。现在我们有两个目录对象,一个是d1,另一个是d2,那么我们会先对d1加锁,删除x,之后再释放对于d1的锁;之后我们会对d2加锁,增加y,之后再释放d2的锁。这是我们在使用自动加锁之后的一个假设的场景。
完成了第一步,也就是删除了d1下的x文件,但是还没有执行第二步,也就是创建d2下的y文件时。其他的进程会看到什么样的结果?是的,其他的进程会看到文件完全不存在。这明显是个错误的结果
这里正确的解决方法是,我们在重命名的一开始就对d1和d2加锁,之后删除x再添加y,最后再释放对于d1和d2的锁。
锁的特性和死锁
通常锁有三种作用:
- 锁可以避免丢失更新。
- 锁可以打包多个操作,使它们具有原子性。
- 锁可以维护共享数据结构的不变性。
- 共享数据结构如果不被任何进程修改的话是会保持不变的。
- 如果某个进程acquire了锁并且做了一些更新操作,共享数据的不变性暂时会被破坏。
- 但是在release锁之后,数据的不变性又恢复了。
死锁
-
同一个进程(CPU)多次acquire同一个锁
- 首先acquire一个锁,然后进入到critical section;
- 在critical section中,再acquire同一个锁;
- 第二个acquire必须要等到第一个acquire状态被release了才能继续执行,但是不继续执行的话又走不到第一个release,所以程序就一直卡在这了。
- XV6会探测这样的死锁,如果XV6看到了同一个进程多次acquire同一个锁,就会触发一个panic。
-
deadly embrace(拥抱)/ (或者可以叫循环等待,哲学家吃饭问题)
-
多核下,例如CPU_A和CPU_B,对a, b两个共享数据结构进行操作
-
CPU_A需要先操作a,再操作b; CPU_B需要先操作b,再操作a
-
CPU_A获得a的锁,若并行下此时CPU_B同时获得b的锁
-
然后CPU_A想要获得b的锁,CPU_B想要获得a的锁
-
死锁了
-
// 代码案例: // CPU_A: pthread_mutex_lock(&A); pthread_mutex_lock(&B); ... pthread_mutex_unlock(&B); pthread_mutex_unlock(&A); // CPU_B pthread_mutex_lock(&B); pthread_mutex_lock(&A); ... pthread_mutex_unlock(&A); pthread_mutex_unlock(&B); -
解决方案是,如果你有多个锁,你需要对锁进行排序,所有的操作都必须以相同的顺序获取
- 确定对于所有的锁对象的全局的顺序,例如给锁分配一个全局顺序(例如
A的 id = 1,B的 id = 2),规则:总是先拿 id 小的锁,再拿 id 大的锁。 - 所以如果内核中的某个代码路径需要同时持有多个锁,那么所有代码路径以相同的顺序获取这些锁非常重要。如果它们不这样做,就有死锁的风险。
- 确定对于所有的锁对象的全局的顺序,例如给锁分配一个全局顺序(例如
-
但是这样又违背了代码抽象的原则。
- 如果一个模块m1中方法g调用了另一个模块m2中的方法f,那么m1中的方法g需要知道m2的方法f使用了哪些锁。因为如果m2使用了一些锁,那么m1的方法g必须集合f和g中的锁,并形成一个全局的锁的排序。
- 这意味着在m2中的锁必须对m1可见,这样m1才能以恰当的方法调用m2。
- 在完美的情况下,代码抽象要求m1完全不知道m2是如何实现的。但是不幸的是,具体实现中,m2内部的锁需要泄露给m1,这样m1才能完成全局锁排序。
- 所以当你设计一些更大的系统时,锁使得代码的模块化更加的复杂了。
-
锁与性能
基本上来说,如果你想获得更高的性能,你需要拆分数据结构和锁。如果你只有一个big kernel lock,那么操作系统只能被一个CPU运行。如果你想要性能随着CPU的数量增加而增加,你需要将数据结构和锁进行拆分。
通常来说,开发的流程是:
- 先以coarse-grained lock(注,也就是大锁)开始。
- 再对程序进行测试,来看一下程序是否能使用多核。
- 如果可以的话,那么工作就结束了,你对于锁的设计足够好了;如果不可以的话,那意味着锁存在竞争,多个进程会尝试获取同一个锁,因此它们将会序列化的执行,性能也上不去,之后你就需要重构程序。
锁的实现
不同处理器的具体实现可能会非常不一样,处理器的指令集通常像是一个说明文档,它不会有具体实现的细节,具体的实现依赖于内存系统是如何工作的,比如说:
- 多个处理器共用一个内存控制器,内存控制器可以支持这里的操作,比如给一个特定的地址加锁,然后让一个处理器执行2-3个指令,然后再解锁。因为所有的处理器都需要通过这里的内存控制器完成读写,所以内存控制器可以对操作进行排序和加锁。
- 如果内存位于一个共享的总线上,那么需要总线控制器(bus arbiter)来支持。总线控制器需要以原子的方式执行多个内存操作。
- 如果处理器有缓存,那么缓存一致性协议会确保对于持有了我们想要更新的数据的cache line只有一个写入者,相应的处理器会对cache line加锁,完成两个操作。
自旋锁
在xv6中有两个接口:
// kernel/spinlock.h
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};
// kernel/spinlock.c
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk);
// Release the lock.
void
release(struct spinlock *lk)
关中断
在acquire中首先需要进行关中断,防止出现死锁
可以想象下如下场景:
在单CPU下,若acquire时没有关中断,如代码执行到临界区突然来了个中断,然后处理中断;
但是处理中断程序同样需要获得同一把锁,这导致中断处理程序等待锁释放,但是锁释放需要等待中断处理程序完成.
开中断在release中完成
相关代码在kernel/spinlock.c中实现:
void
push_off(void)
{
int old = intr_get();
intr_off();
if(mycpu()->noff == 0)
mycpu()->intena = old;
mycpu()->noff += 1;
}
void
pop_off(void)
{
struct cpu *c = mycpu();
if(intr_get())
panic("pop_off - interruptible");
if(c->noff < 1)
panic("pop_off");
c->noff -= 1;
if(c->noff == 0 && c->intena)
intr_on();
}
我们在定时器相关寄存器中介绍过了当通过硬件/指令强制进入trap时,硬件关中断会做的一系列设置寄存器的事情,以及通过mret/sret返回时开中断做的一系列设置寄存器的事情,这一系列事情做的重要的内容就是支持嵌套中断
而我们实现锁这里只想临时关中断/开中断,但是也要实现支持嵌套中断
// kernel/proc.h
// Per-CPU state.
struct cpu {
struct proc *proc; // The process running on this cpu, or null.
struct context context; // swtch() here to enter scheduler().
int noff; // Depth of push_off() nesting.
int intena; // Were interrupts enabled before push_off()?
};
cpu.noff: 记录当前禁中断被 push 了多少次cpu.intena: 保存第一次push_off调用前的中断状态,只有noff为 0 时才保存,目的是在全部 pop 后把中断恢复到调用之前的状态(如果原来就是禁的,就不启中断)
push_off()/pop_off() 是成对、按嵌套计数工作的。每次 push_off() 都把一个计数(noff)加 1;只有当你对应地调用相同次数的 pop_off()(把计数减回到 0)时,才会真正可能恢复中断状态。
当第一次 push_off() 被调用时,会把调用之前CPU 的中断使能状态保存到 mycpu()->intena。当最后一个(最外层的)pop_off() 把 noff 减到 0 时,会根据保存的 intena 决定是否打开中断:
- 如果进入
push_off()时中断原本是 开启(intena=1),在全部pop_off()匹配后会 恢复为开启(调用intr_on())。 - 如果进入时中断原本是 关闭(
intena=0),在全部pop_off()匹配后仍保持关闭(不会intr_on())。
因此 push_off()/pop_off() 不会错误地把原来关闭的中断打开,它只会在合适的时候恢复原来的状态。
test-and-set
自旋锁通过类似如下思路进行实现:
void
acquire(struct spinlock *lk) {
while (lk->locked == 1);
lk->locked = 1;
}
void
release(struct spinlock *lk) {
lk->locked = 0;
}
但是上述代码可能是不够的因为普通的C代码while (lk->locked == 1);等缺乏原子性,我们需要硬件协助我们完成原子性
amoswap(atomic memory swap)指令:AMOSWAP.W rd, rs2, (rs1)会先让t = rs1, rs1 = rs2,rd = t; 这个过程是原子的。
有了这个利器,我们通过实现来替换掉while (lk->locked == 1); lk->locked = 1;, 可以保证原子地询问:
a5 = 1
s1 = &lk->locked
amoswap.w.aq a5, a5, (s1) // 即t = s1, s1 = a5 = 1, a5 = t; 返回lk->locked旧值,令lk->locked = 1
实际上xv6也就是这么实现的:while(__sync_lock_test_and_set(&lk->locked, 1) != 0)其汇编代码就是上述内容

release相关代码也可以用amoswap完成了:
a5 = 0
s1 = &lk->locked
amoswap.w.aq a5, a5, (s1)
xv6相关实现:__sync_lock_release(&lk->locked);

memory ordering
编译器或者处理器可能会重排指令以获得更好的性能:
例如:
locked <-- 1
x <- x+1
locked <-- 0
因为x与locked之前没有依赖关系,编译器或者处理器可能会将指令重排为:
locked <-- 1
locked <-- 0
x <- x+1
or
x <- x+1
locked <-- 1
locked <-- 0
但是对于并发执行,很明显这将会是一个灾难。如果我们将critical section与加锁解锁放在不同的CPU执行,将会得到完全错误的结果。
因为我们必须保证临界区的指令必须在锁的区域执行而不能因为指令重排跑到了锁外执行。所以指令重新排序在并发场景是错误的。
为了禁止,或者说为了告诉编译器和硬件不要这样做,我们需要使用memory fence或者叫做synchronize指令,来确定指令的移动范围。
__sync_synchronize();
通过在acquire使用while(__sync_lock_test_and_set(&lk->locked, 1) != 0)之后立刻调用 __sync_synchronize(); 禁止后续访存提前
以及在release使用__sync_lock_release(&lk->locked);之前调用__sync_synchronize(); 禁止前面访存延后
能够保证临界区的代码都在锁中执行
现实世界
大多数操作系统支持 POSIX 线程(Pthreads),它允许一个用户进程在多个 CPU 上并发运行多个线程。Pthreads 支持用户级锁、屏障等。
- 用户级锁(user-level lock / user-space lock)是指在用户态完全或主要由用户态代码实现的锁。 它们通常用原子指令在用户空间处理“快路径”,因此在无争用或轻度争用时往往不需要系统调用。
- 但在发生争用且需要阻塞线程时,许多用户级锁会退到内核(例如通过
futex)以挂起/唤醒线程——这时就会发生系统调用。- 例如简单的自旋锁(spinlock)或某些针对用户线程库的互斥实现(green-thread 的锁)。它们只使用 CPU 原子操作(CAS、atomic_exchange),永远不进内核。
多CPU竞争锁高开销问题
锁本质其实就是一个数据结构,通过原子指令更新数据实现的。
当多个 CPU 竞争同一把锁时,锁对应的缓存行在 CPU 间不断地移动或被失效(invalidate),导致昂贵的互连/一致性通信;
- 缓存一致性协议,当一个 CPU 要对某缓存行做写(或执行原子读改写,atomic RMW),该缓存行必须处于 Exclusive/Modified 状态;如果其他 CPU 有该行的副本,协议会先让其它副本失效(invalidate)或将所有者的行迁移过来。
- 所以,即使实际的“临界工作”很小(比如只改一个字),争用带来的一致性通信也会吞掉大量时间。
无锁数据结构
无锁数据结构是指在并发访问时不使用互斥锁来保证一致性的并发数据结构;它们依赖于硬件提供的原子操作(如 CAS / LL-SC / 原子交换 / 原子加减 等)来实现并发安全。目的是在高并发下减少上下文切换和锁竞争带来的开销,从而提高吞吐与延迟可预测性。
例如对于链表,我们在访问其时不需要锁;我们在插入其时通过原子指令即可完成插入,也不需要锁;
这样的链表是无锁数据结构
Lec11 Thread switching
线程状态
因为XV6中每个进程只有一个线程,所以XV6中进程和线程之前的区别很模糊,且现在大多数主流OS(Linux 的 pthreads(NPTL)、Windows 线程、现代 Java HotSpot(多数平台))都是one-to-one 即 每创建一个用户线程,内核就创建一个对应的内核线程(可被调度器直接调度)。
XV6中的进程实现其实也很像线程了,所以为了学习线程,接下来的内容我都以线程名称。
因为XV6中每个进程只有一个线程,所以各个线程之间并不共享地址空间; Linux,允许在一个用户进程中包含多个线程,进程中的多个线程共享进程的地址空间。但是在Linux中跟踪每个进程的多个线程比XV6中每个进程只有一个线程要复杂的多。
Robert教授:Linux是支持一个进程包含多个线程,Linux的实现比较复杂,或许最简单的解释方式是:几乎可以认为Linux中的每个线程都是一个完整的进程。
Linux中,我们平常说一个进程中的多个线程,本质上是共享同一块内存的多个独立进程。所以Linux中一个进程的多个线程仍然是通过一个内存地址空间执行代码。如果你在一个进程创建了2个线程,那基本上是2个进程共享一个地址空间。之后,调度就与XV6是一致的,也就是针对每个进程进行调度。
我们可以随时保存线程的状态并暂停线程的运行,并在之后通过恢复状态来恢复线程的运行。线程的状态包含:
- 程序计数器
- 寄存器
- Stack
- 运行状态
- RUNNING,线程当前正在某个CPU上运行
- RUNABLE,线程还没有在某个CPU上运行,但是一旦有空闲的CPU就可以运行
- SLEEPING, 不想运行在CPU上的线程,因为这些线程可能在等待I/O或者其他事件
堆呢?
堆上的地址一般由变量保存,变量一般都在寄存器和Stack上,若这些变量丢失了,就会造成我们常说的内存泄漏
线程调度
接下来我们关注的是一个CPU如何在多个线程之间来回切换
XV6有2种调度方式:
- pre-emptive scheduling (抢占式调度),即使用户代码本身没有出让CPU,定时器中断仍然会将CPU的控制权拿走,并出让给线程调度器。
- voluntary scheduling (自愿调度),等待I/O或者其他事件导致睡眠让出(yield)CPU
接下来我们主要来看下因定时器中断导致的pre-emptive scheduling
XV6中有3种类型的线程:
- 用户线程 (在U model)
- 内核线程(在S model)
- 调度器线程(在S model)
- 每一个调度器线程都有自己独立的栈。实际上调度器线程的所有内容,包括栈和context,与用户进程不一样,都是在系统启动时就设置好了。
entry.S和start.c文件,你就可以看到为每个CPU核设置好调度器线程。
当在一个CPU_0上用户线程A切换到用户线程B的过程为(注意每个CPU都有一个调度器线程):
用户线程A --> 内核线程A --> CPU_0调度器线程 --> 内核线程B --> 用户线程B
用户线程A-->内核线程A 或者 内核线程B --> 用户线程B 的过程我们已经很熟悉了,在kernel/trampoline.S和kernel/trap.c中已经见到很多次了。
当内核线程A --> CPU_0 调度器线程:
- 内核线程A会将其状态保存在proc->context中
- CPU_0 调度器线程从cpu->context中恢复状态
当CPU_0 调度器线程 --> 内核线程B:
- CPU_0 调度器线程会保存状态到cpu->context
- 内核线程B会从proc->context中恢复状态
保存在context中的内容为何会比处理中断时保存在trapframe的内容少了许多?
- 我们调用
swtch函数将内核线程状态保存到proc->context, 或者保存调度器线程状态到proc->context;swtch我们是当做普通函数调用, 编译器知道调用发生,会把caller-saved寄存器按约定保存到调用者栈上(如果需要保留),所以被调用函数只需遵守调用约定,通常只需保存callee-saved(即swtch中执行的内容)- 普通函数调用始终在同一model下,不会跨model; 比如当内核线程A --> CPU_0调度器线程调用的
swtch就是在S model下发生的函数调用
- 普通函数调用始终在同一model下,不会跨model; 比如当内核线程A --> CPU_0调度器线程调用的
- 处理中断(trap)是由硬件触发并由硬件/启动汇编直接跳到内核入口的,其并不遵守调用约定(比如突然来了定时器中断你让谁去保存调用者保存寄存器?)
- trap涉及model的切换,这个过程需要切换地址空间,需要切换栈所以保存的内容会更多
最初的线程调度
最初在kernel/entry.S和kernel/start.c中,我们获得了栈la sp, stack0, 这个栈正是当前CPU调度器线程使用的。
从start.c执行到kernel/main.c经过一系列初始化,我们最后调用了scheduler() (kernel/proc.c: 444)
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
其代码如上,for(;;)是一个无限循环,也就是说schedule会无限遍历全部线程,若发现处于RUNNABLE状态则调用swtch切换到内核线程上执行。(注意p->lock在p线程处于RUNNING期间并不会一直被p线程获得到)
然后在初始化时,我们应该设置了initcode线程为RUNNABLE,所以这里会调用swtch,保存CPU调度器线程(这里可以得知CPU调度器线程恢复后下一条执行的指令为c->proc = 0;),恢复内核线程执行.
初始化的内核线程
// kernel/proc.c:143
// Set up new context to start executing at forkret,
// which returns to user space.
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
// kernel/proc.c: 512
// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
void
forkret(void)
{
static int first = 1;
// Still holding p->lock from scheduler.
release(&myproc()->lock);
if (first) {
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
first = 0;
fsinit(ROOTDEV);
}
usertrapret();
}
可以看到初始化的内核线程基本就是恢复context后执行usertrapret();恢复到用户线程执行
后续的线程调度
-
当定时器中断到来,我们会调用
yield()(kernel/trap.c: usertrap)处理,注意此时中断是关闭的-
--> 在
yield()(kernel/proc.c: 506)中我们在线程的临界区中执行sched() -
acquire(&p->lock); p->state = RUNNABLE; sched(); release(&p->lock); -
为何要上锁?
- 注意
acquire和release之间的临界区是关闭了中断的 - 我们可以对线程状态进行上锁的行为理解为令其他CPU/调度器暂时看不到这个线程。我们需要保证调度线程时的原子性
- 注意
-
在调用
swtch期间需要关闭中断,想象一下如果在内核线程A执行swtch时突然来了个定时器中断,内核线程A的状态保存不完善,在处理内核中断时实际上调用的还是yield,这个时候恢复内核线程A的状态也是不完善的。 -
出让CPU涉及到很多步骤,我们需要将进程的状态从RUNNING改成RUNABLE,我们需要将进程的寄存器保存在context对象中,并且我们还需要停止使用当前进程的栈。锁这里确保了三个步骤的原子性。从CPU核的角度来说,三个步骤要么全发生,要么全不发生。
-
就这里而言想象一下如果有另一个CPU的调度器看到了我们的线程A成RUNNABLE然后执行它,就会导致现在有线程A执行在两个CPU上,这是不对的。我们在下面可以看到
schedule依旧会调用swtch,其同样使用了锁。-
--> 在
sched() (kernel/proc.c: 486)做了一些合理性检查(包括要获得当前proc->lock,当前不在嵌套中断下,当前proc处于RUNNING状态,当前关闭了中断), 就执行到了swtch(&p->context, &mycpu()->context)-
-->
swtch kernel/swtch.S:swtch接受两个参数swtch(a,b),其会将当前CPU寄存器保存到a context上,将b context恢复到CPU寄存器上 -
这里对应着内核线程A-->CPU_0 调度器线程,可以看到其实现中恢复了保存在cpu->context中的返回地址,ret指令将程序计数器跳到寄存器
ra(x1)中保存的返回地址,所以接下来运行的内容为CPU_0 调度器线程跳走之前的下一条指令ld ra, 0(a1) ... ret- --> CPU_0调度器线程执行
c->proc = 0; (kernel/proc.c:scheduler:467)(具体为何会执行到这里见上述) - 这里对应着CPU_0 调度器线程 --> 内核线程B; CPU_0调度器线程其实一直就在执行
scheduler函数,schedulder函数通过进程表单找到下一个RUNABLE进程,然后通过swtch切换到内核线程- --> 内核线程B恢复保存在proc->context中的内容,并从中断处理函数中返回(因为内核线程一定是因为处理中断才调用到yield函数的), 最后恢复到用户线程B
- --> CPU_0调度器线程执行
-
-
-
线程除了寄存器以外的还有很多其他状态,它有变量,堆中的数据等等,但是所有的这些数据都在内存中,并且会保持不变。我们没有改变线程的任何栈或者堆数据。
所以线程切换的过程中,处理器中的寄存器是唯一的不稳定状态,且需要保存并恢复。而所有其他在内存中的数据会保存在内存中不被改变,所以不用特意保存并恢复。我们只是保存并恢复了处理器中的寄存器,因为我们想在新的线程中也使用相同的一组寄存器。
Lec13 Sleep & Wake up
线程切换过程中锁的限制
XV6中 线程切换(内核线程A-->CPU调度器线程 -->)的过程中需要一直持有内核线程A的p->lock, 为啥请看上述后续的线程调度相关内容:
-
在线程切换的最开始,线程先获取自己的锁,并且直到调用switch函数时也不释放锁
-
调度器线程会在线程完全停止使用自己的栈之后,再释放进程的锁。释放锁之后,就可以由其他的CPU核再来运行线程,因为这些线程现在已经不在运行了。释放锁的设计很巧妙:
-
// kernel/proc.c:470 swtch(&c->context, &p->context); // Process is done running for now. // It should have changed its p->state before coming back. c->proc = 0; } release(&p->lock); -
当内核线程A切换到CPU调度线程时,CPU调度线程下一个要执行的指令为
c->proc = 0;然后release(&p->lock);注意这里释放的是内核线程A的锁,因为上一条指令swtch(&c->context, &p->context);就是从CPU调度线程切换到内核线程A的代码
XV6中,不允许进程在执行switch函数的过程中,持有任何其他的锁。
Sleep&Wakeup实现Coordination
所谓 Coordination 可以理解为让进程或者线程等待一些特定的事件:
- 从Pipe中读数据, 但是Pipe当前又没有数据,需要等待一个Pipe非空的事件。
- 读取磁盘,告诉磁盘控制器请读取磁盘上的特定块,这或许要花费较长的时间,尤其当磁碟需要旋转时。
- 一个Unix进程可以调用wait函数。这个会使得调用进程等待任何一个子进程退出。所以这里父进程有意的在等待另一个进程产生的事件。
等待可以通过一直busy-wait或者是Sleep&Wakeup实现
Lost wakeup
我们先设计第一版的Sleep和Wakeup的伪代码:
- sleep和wakeup函数需要通过某种方式链接到一起 。也就是说,如果我们调用wakeup函数,我们只想唤醒正在等待刚刚发生的特定事件的线程
- 所以,sleep函数和wakeup函数都带有一个叫做sleep channel的参数。我们在调用wakeup的时候,需要传入与调用sleep函数相同的sleep channel。
sleep(chan) {
Lock(&p->lock); // 线程切换过程中锁的限制明确说明了在线程切换即调用swtch要上锁,锁有关中断的功能
p->state = SLEEPING;
p->chan = chan;
swtch();
UnLock(&p->lock);
}
wakeup(chan) {
for each p in procs[] {
if p->state == SLEEPING && p->chan == chan {
p->state = RUNNABLE;
}
}
}
我们接下来构建一个场景,以简单理解的uart发送字符重构伪代码为例,每当向uart THR寄存器发送完字节后,都会有中断发生,相应地有uartintr函数处理:
int done;
uartwrite(buf){
for each c in buf {
Lock(&uart_tx_lock);
while done == 0 { // while done == 0 是因为可能有多个线程带着相同的chan进入sleep,我们wakeup会唤醒全部这些线程,但是很可能会出现有线程先一步让done = 0了,其他线程应该继续sleep
Unlock(&uart_tx_lock); // 我们要在sleep放锁,否则唯一期望改变done值的uartintr函数也会尝试获取锁而导致死锁
sleep(&tx_chan);
Lock(&uart_tx_lock);
}
send c to THR; // 我们要防止多个线程同时向THR写
done = 0; // done = 0表示THR并非空闲,需要等待
UnLock(&uart_tx_lock);
}
}
uartintr() {
Lock(&uart_tx_lock); // 因为设备的top(这里即uartwrite)和bottom(这里即uartintr)可以并行运行,且done为共享变量所以需要加锁
done = 1;
wakeup(&tx_char);
Unlock(&uart_tx_lock);
}
上述代码会出现一个严重的问题,其现象表现为:
终端输出了一些字符后卡住了,只有当用户手动输入一些内容后才会再输出一些内容
-
卡住是因为发生了wakeup lost; 假设我们有线程A,线程B。线程A在执行
uartwrite时在sleep和unlock之间发生了中断Unlock(&uart_tx_lock);
// INTERRUPT
sleep(&tx_chan);
Lock(&uart_tx_lock);- 此时线程A还没有变成SLEEPING状态,且放弃了锁。
- 于此同时线程B早早就调用了
uartintr并且在等待线程A的锁,线程A在释放完锁后,线程B立刻获得锁,并且紧接着执行wakeup,但是这里的wakeup是虚空索敌,因为线程A没有进入SLEEPING状态! - 假设线程B执行完后,线程A接着执行。此时线程A才调用sleep让线程A变成SLEEPING状态,但是却没有机会调用uartintr执行wakeup了(因为线程A在sleep没有写THR)
-
用户手动输入字符再次调用了
uartwrite,即使wakeup lost了,但是done还是为1的,所以写THR后引发了中断调用了uartintr才恢复正常
避免Lost wakeup
上述问题发生的原因是在Unlock和sleep之间有时间窗口,导致其他线程有机可乘在我们将线程设置为SLEEPING之前调用了wakeup
我们需要将释放锁和设置进程为SLEEPING状态这两个行为合并为一个原子操作。
那么我们要如何实现呢?
总不能实现成这样吧:
sleep(&tx_chan);
Unlock(&uart_tx_lock);
// INTERRUPT
Lock(&uart_tx_lock);
这样会引起更加严重的死锁。
答案是再来一把锁,并且将uart_tx_lock传参给sleep, 目的就是在sleep中用新锁保护设置SLEEPING的原子性同时释放掉uart_tx_lock锁, 我们来修改下sleep和wakeup
sleep(chan, lk) {
if (lk != &p->lock) {
Lock(&p->lock);
UnLock(lk);
}
p->state = SLEEPING;
p->chan = chan;
swtch();
if (lk != &p->lock) {
UnLock(&p->lock);
Lock(lk);
}
}
wakeup(chan) {
for each p in procs[] {
Lock(&p->lock); // 配合sleep, 为了让sleep得到锁后,wakeup不能做任何事,避免wakeup lost
if p->state == SLEEPING && p->chan == chan {
p->state = RUNNABLE;
}
UnLock(&p->lock);
}
}
通过p->lock的保护, 我们能够确保释放锁和设置进程为SLEEPING状态这两个行为合并为一个原子操作(因为我们将其放在了p->lock的临界区里了)
调用swtch后切换到调度器线程中,调度器线程会释放掉p->lock, 说明此时当前线程彻底不用了,wakeup才能终于获取进程的锁,发现它正在SLEEPING状态,并唤醒它。
总结:
sleep传参的锁被称为sleep的condition lock,这里的condition是发生了中断并且硬件准备好了传输下一个字符。可以理解为只有条件满足时,sleep才会再次上锁condition lock,否则将condition lock留给其他处理线程用吧- sleep函数只有在获取到进程的锁p->lock之后,才能释放condition lock。
- wakeup函数只有在同时获取到sleep的condition lock和p->lock后才能查看进程。
API改动了,相应的调动方式也会改动:
int done;
uartwrite(buf){
for each c in buf {
Lock(&uart_tx_lock);
while done == 0 {
// Unlock(&uart_tx_lock); sleep中的实现帮助我们完成了释放和上锁
sleep(&tx_chan, &uart_tx_lock);
// Lock(&uart_tx_lock);
}
send c to THR; // 我们要防止多个线程同时向THR写
done = 0; // done = 0表示THR并非空闲,需要等待
UnLock(&uart_tx_lock);
}
}
uartintr() {
Lock(&uart_tx_lock); // 因为设备的top(这里即uartwrite)和bottom(这里即uartintr)可以并行运行,且done为共享变量所以需要加锁
done = 1;
wakeup(&tx_char);
Unlock(&uart_tx_lock);
}
Sleep & Wakeup 场景使用
Pipe/sleep和wakeup模板总结
总得来说若需要使用到sleep和wakeup都可以遵守如下一套模板:
消费者 {
Lock(conditional lock);
...
while (!condition) {
sleep(chan, conditional lock);
}
...
Unlock(conditional lock)
}
生产者 {
Lock(conditional lock);
生产
wakeup(conditional lock);
Unlock(conditional lock);
}
Sleeplock
// Long-term locks for processes
struct sleeplock {
uint locked; // Is the lock held?
struct spinlock lk; // spinlock protecting this sleep lock
// For debugging:
char *name; // Name of lock.
int pid; // Process holding lock
};
// kernel/sleeplock.c
void
initsleeplock(struct sleeplock *lk, char *name)
{
initlock(&lk->lk, "sleep lock");
lk->name = name;
lk->locked = 0;
lk->pid = 0;
}
void
acquiresleep(struct sleeplock *lk)
{
acquire(&lk->lk);
while (lk->locked) {
sleep(lk, &lk->lk);
}
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
}
void
releasesleep(struct sleeplock *lk)
{
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk);
release(&lk->lk);
}
可以看到上述代码与模板如出一辙
lk->locked为conditional, lk->lk为conditional lock
当lk->locked为1时,说明已经有线程已经"消费完"conditional lock;其他线程尝试拿时要等待conditional,要先释放conditional lock;
Exit 系统调用
一个进程如果退出的话:
- 我们需要释放用户内存 (释放page table,释放trapframe对象)....等(在kernel/proc.c: freeproc中)
- 将进程在进程表单中标为REUSABLE
- ZOMBIE 状态。进程不会再运行同时进程资源也并没有完全释放
- UNUSED 状态。在ZOMBIE 状态进程资源下得到了完全释放
但是有些相当矛盾且严重的问题
- 当我们释放进程时,其仍然在运行代码,即持有运行代码所需要的一些资源。当它还在执行代码,它就不能释放正在使用的资源。所以我们需要一种方法来释放掉这些关键资源
- kill掉线程,可能这个线程还在运行(可能执行了一些比较重要的操作:在内核中持有锁,更新内核中的数据结构等)。我们不能立刻将线程kill掉
// kernel/proc.c
void
exit(int status)
{
struct proc *p = myproc();
if(p == initproc)
panic("init exiting");
// Close all open files.
for(int fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd]){
struct file *f = p->ofile[fd];
fileclose(f);
p->ofile[fd] = 0;
}
}
// 接下来是类似的处理,进程有一个对于当前目录的记录,这个记录会随着你执行cd指令而改变。在exit过程中也需要将对这个目录的引用释放给文件系统。
begin_op();
iput(p->cwd);
end_op();
p->cwd = 0;
acquire(&wait_lock);
// Give any children to init.
reparent(p);
// Parent might be sleeping in wait().
wakeup(p->parent);
acquire(&p->lock); // 这里上锁是因为我们要执行sched了,sched其实也就是要调用swtch,我们需要关中断
p->xstate = status;
p->state = ZOMBIE; // 接下来,进程的状态被设置为ZOMBIE。
release(&wait_lock);
// Jump into the scheduler, never to return.
sched();
panic("zombie exit");
}
- 关闭了所有已打开的文件.
- 如果一个进程要退出,但是它又有自己的子进程,接下来需要设置这些子进程的父进程为init进程
- 每一个正在exit的进程,都有一个父进程中的对应的wait系统调用。父进程中的wait系统调用会完成进程退出最后的几个步骤, 即上述我们说的释放掉关键资源
- 所以如果父进程退出了,那么子进程就不再有父进程,当它们要退出时就没有对应的父进程的wait。所以在exit函数中,会为即将exit进程的子进程重新指定父进程为init进程,也就是PID为1的进程。(init进程的工作就是在一个循环中不停调用wait)
- 我们需要通过调用wakeup函数唤醒当前进程的父进程,当前进程的父进程或许正在等待当前进程退出。(同时需要防止一种情况:父进程和子进程同时在退出,这也是
wait_lock的作用: helps ensure that wakeups of wait()ing parents are not lost. ) - 设置进程的状态是ZOMBIE后,进程不会再运行了,调度器线程会决定运行其他的进程。
Wait 系统调用
如果一个进程exit了,并且它的父进程调用了wait系统调用,父进程的wait会返回。wait函数的返回表明当前进程的一个子进程退出了。
// kernel/proc.c
// Wait for a child process to exit and return its pid.
// Return -1 if this process has no children.
int
wait(uint64 addr)
{
struct proc *pp;
int havekids, pid;
struct proc *p = myproc();
acquire(&wait_lock);
for(;;){ // 死循环
// Scan through table looking for exited children.
havekids = 0;
for(pp = proc; pp < &proc[NPROC]; pp++){ // 它会扫描进程表单,找到父进程是自己且状态是ZOMBIE的进程。
if(pp->parent == p){
// make sure the child isn't still in exit() or swtch().
acquire(&pp->lock);
havekids = 1;
if(pp->state == ZOMBIE){
// Found one.
pid = pp->pid;
if(addr != 0 && copyout(p->pagetable, addr, (char *)&pp->xstate,
sizeof(pp->xstate)) < 0) {
release(&pp->lock);
release(&wait_lock);
return -1;
}
freeproc(pp); // 完成释放进程资源的最后几个步骤。
release(&pp->lock);
release(&wait_lock);
return pid;
}
release(&pp->lock);
}
}
// No point waiting if we don't have any children.
if(!havekids || killed(p)){
release(&wait_lock);
return -1;
}
// Wait for a child to exit.
sleep(p, &wait_lock); //DOC: wait-sleep
}
}
wait 在 Linux 中为pid_t wait(int *wstatus)阻塞当前进程直到任一子进程终止或有状态变化,返回已改变状态的子进程 PID,并(若 wstatus 非空)把子进程状态编码写入 *wstatus
在XV6中有相同的语义,其在死循环for(;;)中遍历进程条目,如果其没有子进程则会退出并返回-1;
如果有子进程但是子进程没有处于ZOMBIE状态的,则将执行sleep等待子进程出现ZOMBIE,这也是为什么在exit中需要调用wakeup(p->parent);因为子进程(生产者)要告诉父进程(消费者)我是ZOMBIE了
在xv6中传入的参数int64 addr, 以及exit传入参数int status,他们之间是相互协调的:
exit(status):子进程调用,告诉内核“我要结束了,退出码是status”。内核把进程状态改为ZOMBIE并把status存到子进程的结构(这里是pp->xstate),等待父进程来wait()把它取走并回收资源wait(addr):父进程调用,阻塞直到有子进程变为ZOMBIE。当找到一个退出的子进程时,内核把子进程的退出状态(pp->xstate)拷贝到父进程用户空间的addr指向的位置(如果addr != 0),然后回收子进程并返回该子进程的 pid。- 如果父进程传
0表示“不需要返回状态”,内核就不会尝试写回。
// kernel/proc.c
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
static void
freeproc(struct proc *p)
{
if(p->trapframe)
kfree((void*)p->trapframe);
p->trapframe = 0;
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED; // 子进程的状态会被设置成UNUSED,之后,fork系统调用才能重用进程在进程表单的位置。
}
- 释放了trapframe
- 释放了page table
- 如果我们需要释放进程内核栈,那么也应该在这里释放。(但是我们没有释放)
- 如果由正在退出的进程自己在exit函数中执行这些步骤,将会非常奇怪,所以这些资源都是由父进程释放的。
wait不仅是为了父进程方便的知道子进程退出,wait实际上也是进程退出的一个重要组成部分。在Unix中,对于每一个退出的进程,都需要有一个对应的wait系统调用
Kill 系统调用
实际上,在XV6和其他的Unix系统中,kill系统调用基本上不做任何事情。
// Kill the process with the given pid.
// The victim won't exit until it tries to return
// to user space (see usertrap() in trap.c).
int
kill(int pid)
{
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++){
acquire(&p->lock);
if(p->pid == pid){
p->killed = 1;
if(p->state == SLEEPING){
// Wake process from sleep().
p->state = RUNNABLE;
}
release(&p->lock);
return 0;
}
release(&p->lock);
}
return -1;
}
- 它先扫描进程表单,找到目标进程。然后只是将进程的proc结构体中killed标志位设置为1。如果进程正在SLEEPING状态,将其设置为RUNNABLE。
p->killed会在kernel/trap.c: usertrap中使用到:
if(killed(p))
exit(-1);
// kernel/proc.c
// 其中killed中为:
int
killed(struct proc *p)
{
int k;
acquire(&p->lock);
k = p->killed;
release(&p->lock);
return k;
}
所以kill系统调用并不是真正的立即停止进程的运行,它更像是这样:如果进程在用户空间,那么下一次它执行系统调用它就会退出,又或者目标进程正在执行用户代码,当时下一次定时器中断或者其他中断触发了,进程才会退出。
- 所以从一个进程调用kill,到另一个进程真正退出,中间可能有很明显的延时。
- 如果进程在内核中执行被阻塞住了(如等待I/O),其状态为SLEEPING, 我们的kill也能够 先设置进程状态为RUNNABLE让其可再运行(所以我们需要注意写代码时,若线程/进程从Sleep醒来,也可能是因为是被执行了kill而不是wakeup), 一般I/O相关代码需要判断下进程是否被kill,然后返回;因为I/O相关代码一般也是系统调用,其会返回到
usertrap中,其中会再次判读进程是否被kill,从而调用exit(-1)让进程退出
这种温和的方式可以使得进程若不适宜在这个时间点退出,其可以选择完成相关内容再退出:

virtio_disk.c文件中的一段代码. 这里一个进程正在等待磁盘的读取结束,这里没有检查进程的killed标志位。因为现在可能正在创建文件的过程中,而这个过程涉及到多次读写磁盘。
我们希望完成所有的文件系统操作,完成整个系统调用,之后再检查p->killed并退出。
托孤的init进程
//
// init: The initial user-level program
#include "kernel/types.h"
#include "kernel/stat.h"
#include "kernel/spinlock.h"
#include "kernel/sleeplock.h"
#include "kernel/fs.h"
#include "kernel/file.h"
#include "user/user.h"
#include "kernel/fcntl.h"
char *argv[] = { "sh", 0 };
int
main(void)
{
int pid, wpid;
if(open("console", O_RDWR) < 0){
mknod("console", CONSOLE, 0);
open("console", O_RDWR);
}
dup(0); // stdout
dup(0); // stderr
for(;;){
printf("init: starting sh\n");
pid = fork();
if(pid < 0){
printf("init: fork failed\n");
exit(1);
}
if(pid == 0){
exec("sh", argv);
printf("init: exec sh failed\n");
exit(1);
}
for(;;){
// this call to wait() returns if the shell exits,
// or if a parentless process exits.
wpid = wait((int *) 0);
if(wpid == pid){
// the shell exited; restart it.
break;
} else if(wpid < 0){
printf("init: wait returned an error\n");
exit(1);
} else {
// it was a parentless process; do nothing.
}
}
}
}
可以看到整个内核启动时的流程:
-
在打开console设备后就进入死循环,在其中fork出子进程执行sh程序
-
然后父进程就调用wait一直等待子进程
- 当结束的进程是sh,则重启sh
- 否则什么也不做
-
如果fork失败了,init也会退出,但是在exit中判断了,如果退出的是init,则会panic:
// kernel/proc.c: 13 struct proc *initproc; // kernel/proc.c: exit if(p == initproc) panic("init exiting");
总结
exit和wait是配套使用的:
- 调用exit的子进程 最终会被设置成状态ZOMBIE
- 调用wait的父进程会查表状态为ZOMBIE的子进程, 然后调用函数
freeproc释放子进程资源 - kill是温和的,其只会设置进程状态为p->killed = 1, 内核代码应该检查当前运行的进程的p->killed,如果发现为1,调用exit
Lec14 File systems
XV6中文件系统的目的是实现如下典型的文件系统API:
int write(int, const void*, int);
int read(int, void*, int);
int open(const char*, int);
int link(const char*, const char*);
int unlink(const char*);
操作系统实现的文件系统并不是唯一构建一个存储系统的方式,数据库也能持久化的存储数据,但是数据库就提供了一个与文件系统完全不一样的API。
- 现代的数据库大部分构建在操作系统自带的文件系统之上
文件系统中核心的数据结构就是inode和file descriptor。
inode数据结构保存文件的元数据:大小、权限、时间戳、指向磁盘块的指针等信息;文件名存在目录项里,目录项会指向 inode。file descriptor指向内核中的 file table entry,其中记录着当前读写位置(偏移量),读/写/追加等访问模式,指向 inode 的引用,其= 进程访问文件的临时入口。
文件系统层次结构
尽管文件系统的API很相近并且内部实现可能非常不一样。但是很多文件系统都有类似的结构。因为文件系统还挺复杂的,所以最好按照分层的方式进行理解。可以这样看:
- 在最底层是磁盘,也就是一些实际保存数据的存储设备,正是这些设备提供了持久化存储。
- 在这之上是buffer cache或者说block cache,这些cache可以避免频繁的读写磁盘。这里我们将磁盘中的数据保存在了内存中。
- 为了保证持久性,再往上通常会有一个logging层。许多文件系统都有某种形式的logging,我们下节课会讨论这部分内容,所以今天我就跳过它的介绍。
- 在logging层之上,XV6有inode cache,这主要是为了同步(synchronization),我们稍后会介绍。inode通常小于一个disk block,所以多个inode通常会打包存储在一个disk block中。为了向单个inode提供同步操作,XV6维护了inode cache。
- 再往上就是inode本身了。它实现了read/write。
- 再往上,就是文件名,和文件描述符操作。

现在让我们从下往上看:
- 访问磁盘的速度比访问内存慢几个数量级,因此文件系统必须维护一个内存中的常用块缓存。
- 文件系统必须支持崩溃恢复。也就是说,如果发生崩溃(例如断电),文件系统在重启后仍需正常工作。风险在于崩溃可能会中断一系列更新,导致磁盘上的数据结构不一致(例如一个既被文件使用又被标记为空闲的块)。
- 不同进程可能同时操作文件系统,因此文件系统代码必须协调以维护不变性。
Disk 磁盘层
实际中有非常非常多不同类型的存储设备,工作方式完全不一样,但是对于硬件的抽象屏蔽了这些差异。
磁盘驱动通常会使用一些标准的协议,例如PCIE与磁盘交互。
我们可以将磁盘看做一个巨大的block的数组:
- block通常是操作系统或者文件系统视角的数据。它由文件系统定义,在XV6中它是1024字节
- sector通常是磁盘驱动可以读写的最小单元,它过去通常是512字节。
- 其实上述中Super Block一般不是第一个块,第一个块是block0, block0要么没有用,要么被用作boot sector来启动操作系统。
- 第二个块block1 通常被称为super block,它描述了文件系统。例如文件系统类型,inode表起始位置,inode和数据块个数
- 在xv6的实现中还有多个block用于log,我上图未表现出来
- i-bmap是inode表的位图,用于得知在inode表中哪些位置是空闲的
- d-bmap是数据区域的位图,用于得知在数据区域中哪些位置是空闲的
- inode表用于存放inode数据结构
- 数据区域block用于存储文件和目录内容
所以如果我们想要寻找inode32, 已知inode 64B, inode表起始位置inodeStartAddr, 则inode32的数据在
在xv6中的实现不一定如上一样,其实现如下:
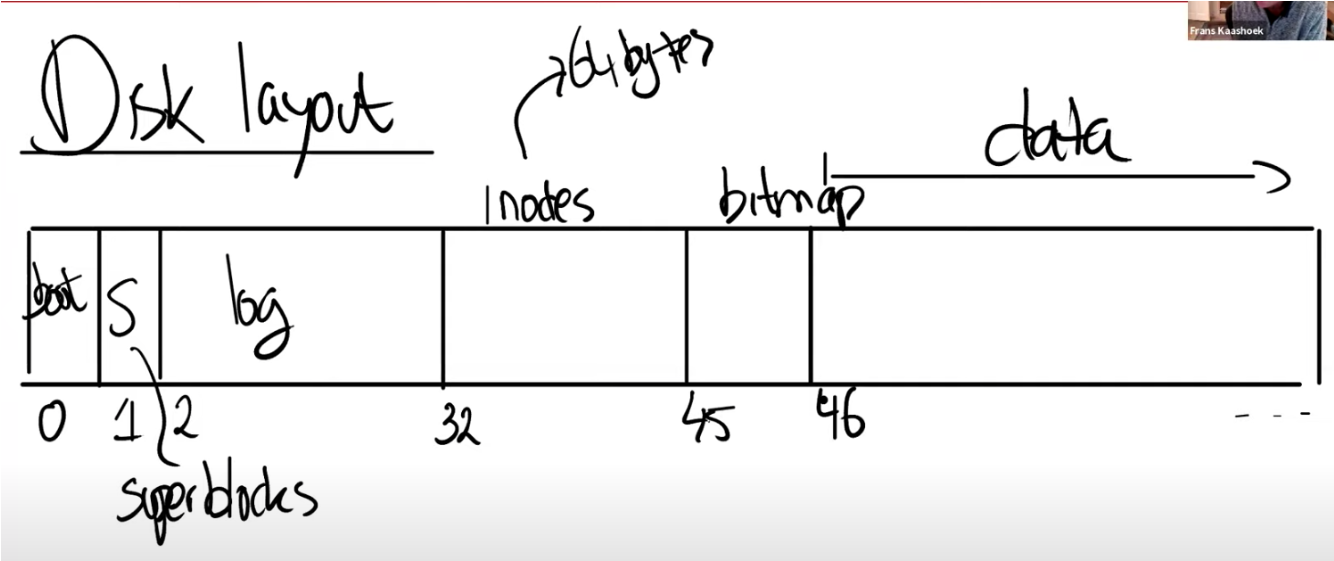
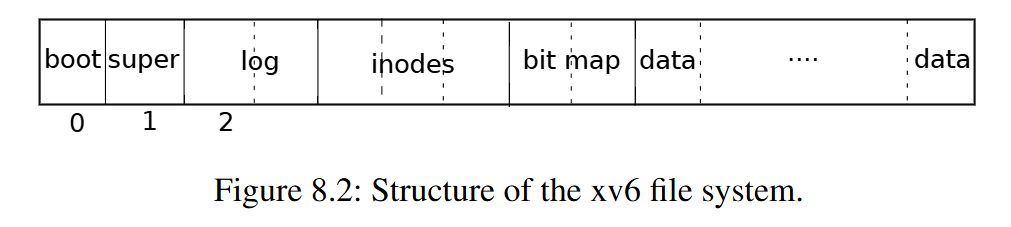
可以看到其只有d-bmap,没有i-bmap,同时inodes表在bmap的前面。但是不管如何原理是一样的
代码实现
// kernel/fs.h
// Bitmap bits per block
#define BPB (BSIZE*8)
// Block of free map containing bit for block b
#define BBLOCK(b, sb) ((b)/BPB + sb.bmapstart)
// Blocks.
// Allocate a zeroed disk block.
// returns 0 if out of disk space.
static uint
balloc(uint dev)
{
int b, bi, m;
struct buf *bp;
bp = 0;
for(b = 0; b < sb.size; b += BPB){
bp = bread(dev, BBLOCK(b, sb));
for(bi = 0; bi < BPB && b + bi < sb.size; bi++){
m = 1 << (bi % 8);
if((bp->data[bi/8] & m) == 0){ // Is block free?
bp->data[bi/8] |= m; // Mark block in use.
log_write(bp);
brelse(bp);
bzero(dev, b + bi);
return b + bi;
}
}
brelse(bp);
}
printf("balloc: out of blocks\n");
return 0;
}
// Free a disk block.
static void
bfree(int dev, uint b)
{
struct buf *bp;
int bi, m;
bp = bread(dev, BBLOCK(b, sb));
bi = b % BPB;
m = 1 << (bi % 8);
if((bp->data[bi/8] & m) == 0)
panic("freeing free block");
bp->data[bi/8] &= ~m;
log_write(bp);
brelse(bp);
}
sb表示super blockBPB表示的是一个block d-map位图能够表示的block数量(BSIZE为1024B,一个B有8位,d-map位图中1位能够指示1个block是否空闲)BBLOCK(b, sb)表示block b在d-map磁盘上的blockno
balloc外循环读取每个位图块。内循环检查单个位图块中的所有每块位数 (BPB) 位。如果两个进程尝试同时分配块可能发生的竞争条件,通过缓冲区缓存一次只允许一个进程使用一个位图块的事实来防止。
bfree找到正确的位图块并清除正确的位。
Buffer Cache层
为何需要Buffer Cache?
- Caching disk blocks in memory reduces the number of disk reads
- 同步对磁盘块的操作,确保内存中一个磁盘块只有一个Buffer Cahce块副本,且同一时间只有一个内核线程使用该副本;
如何实现的Buffer Cache层?
-
在xv6中buffer cache的实现在
kernel/bio.c和kernel/buf.h -
struct buf { int valid; // has data been read from disk? int disk; // does disk "own" buf? uint dev; uint blockno; struct sleeplock lock; uint refcnt; struct buf *prev; // LRU cache list struct buf *next; uchar data[BSIZE]; }; struct { struct spinlock lock; struct buf buf[NBUF]; // Linked list of all buffers, through prev/next. // Sorted by how recently the buffer was used. // head.next is most recent, head.prev is least. struct buf head; } bcache; -
bcache即是我们的buffer cache, 在xv6中以链表的方式组织真正保存数据的buf, 主要是为了以LRU的顺序排序,在链表头是最近最常使用的缓存,在链表尾是最不常用的 -
磁盘,device 设备上的block都可能被buffer cache缓存,我们通过dev和blockno来找到某个block对应的buffer cache block
相关API
-
struct buf *b -
void binit(void): 初始化,构建出链表,初始化每个buffer cache block上的睡眠锁(为了保证同一时间只有一个内核线程使用该buffer cache block) -
static struct buf* bget(uint dev, uint blockno): 在buffer cache 链表上查找是否缓存了设备dev上第blockno个block, 返回一个struct buf *- 若缓存了将这个buffer cache block引用数(b->refcnt)++,说明现在多了一个线程需要使用这个buffer cache block, 并上锁(acquiresleep(&b->lock))返回;
- 若没有缓存则查找是否有空闲的(b->refcnt == 0)的buffer cache block, 若没有则直接panic
- 更优雅的响应可能是睡眠直到缓冲区变为空闲,尽管这样可能会有死锁的可能性, 但是xv6没有实现
- 若有空闲的buffer cache block,则将这个buffer cache block初始化
- 设置dev, blockno, 表示现在这个buffer cache block缓存的block是设备dev上第blockno个block
- 设置valid = 0, 说明现在这个buffer cache block还没有从disk上得到它要缓存的数据
- 设置refcnt = 1, 说明现在有一个线程需要使用这个buffer cache block
-
static struct buf* bread(uint dev, uint blockno): 调用bget得到设备dev上第blockno个block对应的缓存,若无缓存b->valid == 0, 则从磁盘上读取填充virtio_disk_rw(b, 0) -
void bwrite(struct buf *b): 将buffer cache block中的数据写入对应的disk block中 -
void brelse(struct buf *b)释放buffer cache block,操作是将这个buffer cache block的refcnt--并移动到链表头,注意只有当这个buffer cache block的refcnt == 0才能释放
Logging 层
为什么需要Loggging层?
许多文件系统操作涉及对磁盘的多次写入,而在写入子集之后发生崩溃可能会使磁盘上的文件系统处于不一致状态。
同时我们需要实现崩溃恢复
例如:
- 某一个inode引用了block,其想要free掉这个block,这个过程中发生了崩溃,block被标志成free,但是inode的引用还在。重启后可能导致这个block又被分配给了其他inode,这个时候有两个inode指向了同一个block, 可能导致文件的数据严重错误
- block被分配了,但是还没来得及被inode引用就崩溃了,这个时候就造成了内存泄露
Logging 实现一致性的基本思路
xv6 的系统调用不会直接写入磁盘上的文件系统数据结构(on-disk file system data structures),而是会将一个系统调用中所有对磁盘的写入操作详细地记录在Log中,当系统崩溃重启时会读取Log上的操作重新执行一遍
- 一旦系统调用记录(log)完整了其全部的写入操作,其就会在磁盘Log中写入一个特殊提交记录(commit),表示完成了一个完整的操作。
- 此时xv6会尝试将上述写入操作复制到磁盘上的文件系统数据结构上,完成后则会擦除掉磁盘上的Log
- 若此时发生了崩溃,即写入操作没有完整地实现在磁盘上的文件系统数据结构上,那么磁盘上的Log不会消失,那么重启后会继续尝试将上述写入操作复制到磁盘上的文件系统数据结构上
- 此时xv6会尝试将上述写入操作复制到磁盘上的文件系统数据结构上,完成后则会擦除掉磁盘上的Log
- 若系统调用因为崩溃没有记录完整的写入操作,则Log上不存在提交记录,在重启恢复时也不会尝试改动磁盘上的文件系统数据结构了
Log使操作在崩溃时具有原子性:恢复后,要么操作的所有写入都出现在磁盘上,要么它们一个都不出现。
Logging层的实现逻辑
Logging层实现的数据结构
// kernel/log.c
struct logheader { // named as header block
int n;
int block[LOGSIZE]; // named as logged blocks
};
struct log {
struct spinlock lock;
int start; // 在磁盘上的block位置
int size; // 在磁盘上log区的大小
int outstanding; // how many FS sys calls are executing.
int committing; // in commit(), please wait.
int dev; // log区所属的设备(为磁盘)
struct logheader lh;
};
struct log log;
logheader.n: The count in the header block on disk is either zero, indicating that there is no transaction in the log, or non-zero, indicating that the log contains a complete committed transaction with the indicated number of logged blocks. 其记录的是一次group commit所涉及到的block数量logheader.block: for each of the logged blocks, 即记录的是一次group commit所涉及到的block在设备的disk上的blockno- Xv6 writes the header block when a transaction commits, but not before(这个操作就是所谓的特殊提交 commit) and sets the count to zero after copying the logged blocks to the file system.
- 事务中途崩溃会导致日志的头部块计数为零
- 事务提交(commit)后崩溃会导致计数为非零。
我们可以将Logging层所要完成的任务分为四步:
-
log writes:当有文件系统写操作时,我们并不直接更新文件系统数据结构本身,而是先将写操作记录到log中,这个所谓的记录到log是指记录到log 的in-memory,即Logging层的数据结构中,此时还没有落盘。
-
commit op: 当文件系统写操作都结束了时(即这个时候文件系统写操作已经记录在了log in-memory),然后将记录到log的on-disk,即写到磁盘的Log区
-
install log: 我们尝试将log中的操作真正写入到磁盘上
-
clean log: 完成log中操作的持久化后我们就可以不用这个log了, 清除log
-
同时我们需要知道什么时候开始的事务(transaction),已经什么时候结束的事务,以便我们执行log(所以在代码实现里我们有了
begin_op和end_op) -
同时我们还需要在crash时利用log进行恢复(代码实现
recover_from_log)
Logging层的代码实现
log writes
log_write 代替了 bwrite, 在实现Logging之后,任何Logging层之上的层若想写入改动磁盘上的内容,应该调用log_write,而不是bwrite
log_write的参数是要写入设备dev第blockno个block在buffer cache层对应的buffer,我们会记录在log的in-memory数据结构中记录下写操作涉及的设备dev和设备上第blockno个block
void
log_write(struct buf *b)
{
int i;
acquire(&log.lock);
if (log.lh.n >= LOGSIZE || log.lh.n >= log.size - 1)
panic("too big a transaction");
if (log.outstanding < 1)
panic("log_write outside of trans");
for (i = 0; i < log.lh.n; i++) {
if (log.lh.block[i] == b->blockno) // log absorption
break;
}
log.lh.block[i] = b->blockno;
if (i == log.lh.n) { // Add new block to log?
bpin(b);
log.lh.n++;
}
release(&log.lock);
}
log.outstanding表示有多少个线程在进行文件系统写操作log.lh.n记录的是当前group commit 文件系统写操作涉及的block数量- 当多次对同一个block进行写操作并不会引发
log.lh,n++,而是覆盖掉
- 当多次对同一个block进行写操作并不会引发
bpin(b)表示将传入的buffer cache"钉"在buffer cache层中,不能让其换下,因为buffer cache中的数据从buffer cache层换下意味着我们要将buffer cache中的数据写入磁盘了,但是因为我们实现了Logging,我们要保证write ahead rule, 即我们需要先将所有的block写入到log中,之后才能实际的更新文件系统block。
// Copy modified blocks from cache to log.
static void
write_log(void)
{
int tail;
for (tail = 0; tail < log.lh.n; tail++) {
struct buf *to = bread(log.dev, log.start+tail+1); // log block
struct buf *from = bread(log.dev, log.lh.block[tail]); // cache block
memmove(to->data, from->data, BSIZE);
bwrite(to); // write the log
brelse(from);
brelse(to);
}
}
将文件系统写入操作的数据以block为单位(因为我们实现了buffer cache,所以所有的写数据并不会直接写入磁盘中而是在buffer cache上)copy到Logging层对应的buffer cache
Commit log
static void
commit()
{
if (log.lh.n > 0) {
write_log(); // Write modified blocks from cache to log
write_head(); // Write header to disk -- the real commit
install_trans(0); // Now install writes to home locations
log.lh.n = 0;
write_head(); // Erase the transaction from the log
}
}
write_log继续看我们上面的代码其中有bwrite(to);,其将文件系统写入操作的数据落盘到了磁盘的Log区
// Write in-memory log header to disk.
// This is the true point at which the
// current transaction commits.
static void
write_head(void)
{
struct buf *buf = bread(log.dev, log.start);
struct logheader *hb = (struct logheader *) (buf->data);
int i;
hb->n = log.lh.n;
for (i = 0; i < log.lh.n; i++) {
hb->block[i] = log.lh.block[i];
}
bwrite(buf);
brelse(buf);
}
将log的数据结构logheader落盘到磁盘的Log区中
从上述可以知道磁盘的Log区数据分布为:
其中Data是文件系统写入操作的数据
install log
// Copy committed blocks from log to their home location
static void
install_trans(int recovering)
{
int tail;
for (tail = 0; tail < log.lh.n; tail++) {
struct buf *lbuf = bread(log.dev, log.start+tail+1); // read log block
struct buf *dbuf = bread(log.dev, log.lh.block[tail]); // read dst
memmove(dbuf->data, lbuf->data, BSIZE); // copy block to dst
bwrite(dbuf); // write dst to disk
if(recovering == 0)
bunpin(dbuf);
brelse(lbuf);
brelse(dbuf);
}
}
尝试将log中的操作真正写入到磁盘上
当我们实现将数据落盘到磁盘上后就可以bunpin(dbuf);了,我们不需要再"钉"住这块buffer cache了,其上的数据被换下去也无所谓了
clean log
static void
commit()
{
if (log.lh.n > 0) {
write_log(); // Write modified blocks from cache to log
write_head(); // Write header to disk -- the real commit
install_trans(0); // Now install writes to home locations
log.lh.n = 0;
write_head(); // Erase the transaction from the log
}
}
其中的:
log.lh.n = 0;
write_head(); // Erase the transaction from the log
如上两个操作设置log中文件系统写操作的block为0,表明无log记录
最后通过write_head将这个数据落盘到Log区中,表明消除了log
从crash中恢复
static void
recover_from_log(void)
{
read_head();
install_trans(1); // if committed, copy from log to disk
log.lh.n = 0;
write_head(); // clear the log
}
read_head()表示从磁盘的Log区中读取logheadr,然后通过install_trans(1)进行恢复,最后消除log
事务的开始与结束
// called at the start of each FS system call.
void
begin_op(void)
{
acquire(&log.lock);
while(1){
if(log.committing){
sleep(&log, &log.lock);
} else if(log.lh.n + (log.outstanding+1)*MAXOPBLOCKS > LOGSIZE){
// this op might exhaust log space; wait for commit.
sleep(&log, &log.lock);
} else {
log.outstanding += 1;
release(&log.lock);
break;
}
}
}
// called at the end of each FS system call.
// commits if this was the last outstanding operation.
void
end_op(void)
{
int do_commit = 0;
acquire(&log.lock);
log.outstanding -= 1;
if(log.committing)
panic("log.committing");
if(log.outstanding == 0){
do_commit = 1;
log.committing = 1;
} else {
// begin_op() may be waiting for log space,
// and decrementing log.outstanding has decreased
// the amount of reserved space.
wakeup(&log);
}
release(&log.lock);
if(do_commit){
// call commit w/o holding locks, since not allowed
// to sleep with locks.
commit();
acquire(&log.lock);
log.committing = 0;
wakeup(&log);
release(&log.lock);
}
}
-
当文件系统正在commit时
log.committing,若还想开始事务则需要等待,因为我们希望一个事务不要出现在多次commit中 -
当文件系统的log区大小不足时,若还想开始事务则需要等待
-
为什么XV6的log大小是30?因为30比任何一个文件系统操作涉及的写操作数都大,Robert和我看了一下所有的文件系统操作,发现都远小于30,所以就将XV6的log大小设为30。我们目前看过的一些文件系统操作,例如创建一个文件只包含了写5个block。实际上大部分文件系统操作只会写几个block。
-
cache size至少要跟log size一样大, 因为我们再log还没有落盘时需要将buffer cache先钉住,不允许其换下而导致数据落盘
-
log.outstanding表示当前group commit有多少个线程要执行事务
所谓的group commit是并发文件系统调用而得来的,即可能有多个线程并发进行文件系统的写操作,其在log大小充足的情况下会被一起commit
Inode 层
// kernel/file.h
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // 表明inode是文件还是目录。
short major;
short minor;
short nlink; // nlink字段,也就是link计数器,用来跟踪究竟有多少文件名指向了当前的inode。
uint size; // 表明了文件数据有多少个字节。
uint addrs[NDIRECT+1]; // 指向了文件数据所在的地址(以block为单位),如1,则表示在数据区的第一个block处
};
- 在xv6中一个block 1024B
- block 地址 4B (uint), 这说明在xv6中最多有\(2^{32} = 4TB\)的磁盘大小,因为block地址最大也就这么大
uint addrs[NDIRECT+1];- 在xv6中
NDIRECT为12,表示有12个direct block number,所以的direct block number即表示直接记录了block的地址 - 还有一个indirect block number,其指向了一个block,这个block中保存的全部都是direct block number ,在xv6中总共有\(1024 / 4 = 256\)个direct block number在indirect block number指向的block中
- 所以在xv6中一个文件最多可以保存\((256+12)*1024\)B数据
- 在xv6中
可以模仿多级页表那样来个多级indirect block number从而可以扩大文件大小
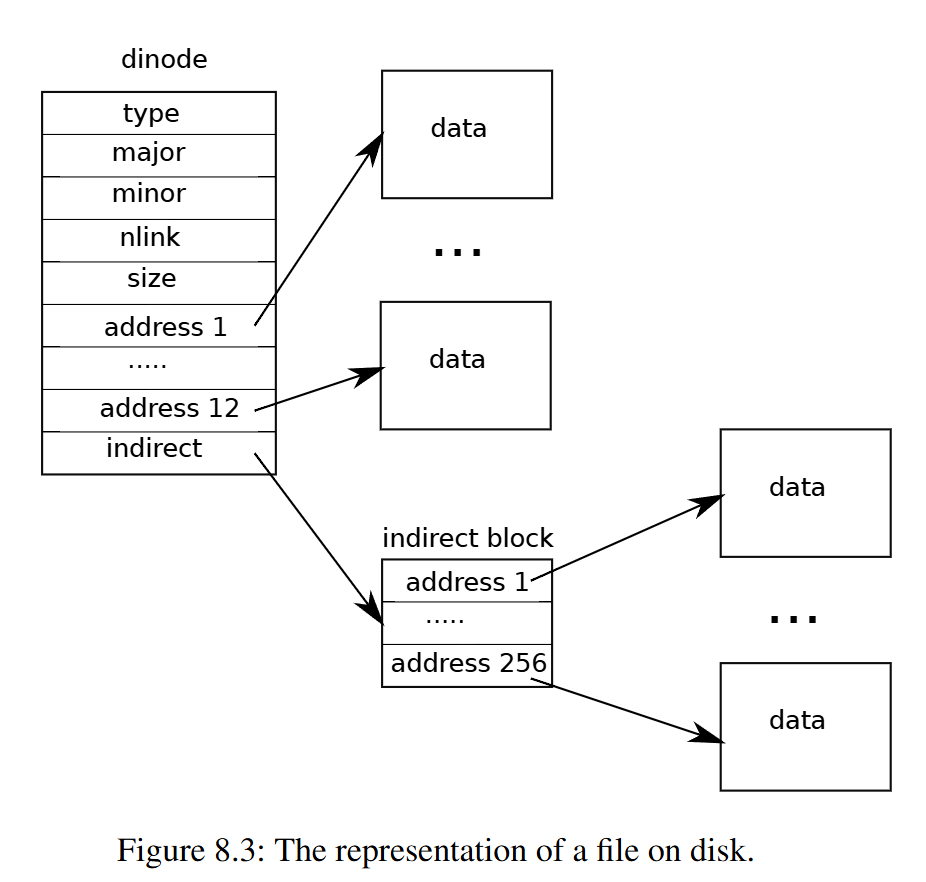
上述实现方式是xv6中的实现方式来记录文件数据,我们完全可以采取其他如B+树等来实现
addrs字段维护的相关代码在kernel/fs.c:bmap
// Return the disk block address of the nth block in inode ip.
// If there is no such block, bmap allocates one.
// returns 0 if out of disk space.
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0){
addr = balloc(ip->dev);
if(addr == 0)
return 0;
ip->addrs[bn] = addr;
}
return addr;
}
bn -= NDIRECT;
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0){
addr = balloc(ip->dev);
if(addr == 0)
return 0;
ip->addrs[NDIRECT] = addr;
}
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
addr = balloc(ip->dev);
if(addr){
a[bn] = addr;
log_write(bp);
}
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
- 为
inode ip查找/分配第bn个block, 并返回这个block在磁盘上的blockno - 首先会查看12个直接数据block,若12个直接数据block分配完了再去间接数据block
- 若间接数据block未分配,则通过
balloc分配一个block给间接数据block,然后再将其当做索引继续分配
已知文件字节访问数据
我们想要实现read系统调用。假设我们需要读取文件的第8000个字节,我们应该如何在文件系统中访问到呢?
- 首先计算这个字节所在的block:\(8000 / 1024 = 7\)
- 已知其在文件的第7个block,接下来直接通过文件的inode数据结构得到inode.addrs[7], 即在整个磁盘中文件的第7个block所在的位置
- 然后求具体在block的位置$8000 % 1024 = 832,则我们在block中第832个字节读取数据
目录 + 读取目录文件
假设已知根目录/的inode, 我想要知道/y/x的数据
其实目录也是文件,只不过其保存的数据是一个个directory entries
// kernel/fs.h
// directory entries
struct dirent {
ushort inum; //这前2个字节包含了目录中文件或者子目录的inode编号
char name[DIRSIZ]; //包含了文件或者子目录名
};
根目录的inode被称为root inode,通常有固定的inode编号,这里我们假设为1
我们在inode区找到inode = 1的inode数据结构
然后通过inode中的addr可以得到文件数据的保存地址,我们一个个(线性地)访问这些地址,从这些地址中读取出directory entries,从中找到名为y的文件并得到其inode
然后通过inode循环上述操作即可得到x
很明现,这里的结构不是很有效。为了找到一个目录名,你需要线性扫描。实际的文件系统会使用更复杂的数据结构来使得查找更快,当然这又是设计数据结构的问题,而不是设计操作系统的问题。
相关代码实现在kernel/fs.c:541
代码实现
inode 分为 on-disk 数据结构 和 in-memory 数据结构
- on-disk 数据结构包含文件大小和数据块编号列表的磁盘数据结构。
- in-memory 数据结构包含磁盘 inode 的副本以及内核中需要的额外信息。其是正在被使用的inode信息
on-disk inode
磁盘上的 inode 被压缩到一个连续的磁盘区域中,称为 inode 块(区)。每个 inode 的大小相同
// kernel/fs.h
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
type == 0表示磁盘上的 inode 是空闲的。- nlink 字段用于计算引用此 inode 的目录条目数量,以便识别何时应该释放磁盘上的 inode 及其数据块。
- 这里的nlink被运用于硬链接,一个文件可以有多个名字(叫 硬链接 hard link),不同名字都指向同一个 inode。
- in-memory inode中的
nlink字段用于软链接,
- size 字段记录文件内容字节数。
- addrs 数组记录包含文件内容的磁盘块编号。含义同上述in-memory inode
in-memory inode
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
The kernel keeps a table of in-use inodes in memory to provide a place for synchronizing access to inodes used by multiple processes.
nlink(磁盘上的链接计数)
- 含义:有多少个目录项(dirent)指向这个 inode(也就是有多少个硬链接)。
- 语义:控制文件在目录树中的“名字”数量;当
nlink==0且没有进程用它时,文件数据才可被删除。
ref(内存中的引用计数)
- 含义:内核中有多少个 活的引用 指向这个
struct inode *(即有多少个地方正在使用/持有这个内存 inode)。 - 语义:防止内存 inode 在仍被使用时被回收或重用;当
ref归零,内存槽可被回收。
会存在 nlink == 0(磁盘目录树中没有名字)但 ref > 0(内存中仍有打开的引用/进程在用)的情况。文件内容在这种情况下不会立即被释放,直到最后一个 ref 释放时才真正回收。
struct {
struct spinlock lock;
struct inode inode[NINODE];
} itable;
void
iinit()
{
int i = 0;
initlock(&itable.lock, "itable");
for(i = 0; i < NINODE; i++) {
initsleeplock(&itable.inode[i].lock, "inode");
}
}
itable.lock保护两个不变量:- 一个 inode 最多只出现在 inode 表中一次
- 内存中的 inode 的 ref 字段计数内存中指向该 inode 的指针数量。
- 每个内存中的 inode 都有一个包含睡眠锁的 lock 字段,这确保了对 inode 字段(如文件长度)以及 inode 的文件或目录内容块的独占访问。
那么我们的on-disk inode 如何保证synchronizing access?
通过buffer cache层
a typical sequence is:
// ip = iget(dev, inum)
// ilock(ip)
// ... examine and modify ip->xxx ...
// iunlock(ip)
// iput(ip)
分配inode以及初始化inode
// Allocate an inode on device dev.
// Mark it as allocated by giving it type type.
// Returns an unlocked but allocated and referenced inode,
// or NULL if there is no free inode.
struct inode*
ialloc(uint dev, short type)
{
int inum;
struct buf *bp;
struct dinode *dip;
for(inum = 1; inum < sb.ninodes; inum++){
bp = bread(dev, IBLOCK(inum, sb));
dip = (struct dinode*)bp->data + inum%IPB;
if(dip->type == 0){ // a free inode
memset(dip, 0, sizeof(*dip));
dip->type = type;
log_write(bp); // mark it allocated on the disk
brelse(bp);
return iget(dev, inum);
}
brelse(bp);
}
printf("ialloc: no inodes\n");
return 0;
}
ialloc逐块遍历磁盘上的 inode 结构,寻找一个标记为空闲的 inode(type == 0), 并标记dip->type = type;
// Find the inode with number inum on device dev
// and return the in-memory copy. Does not lock
// the inode and does not read it from disk.
static struct inode*
iget(uint dev, uint inum)
{
struct inode *ip, *empty;
acquire(&itable.lock);
// Is the inode already in the table?
empty = 0;
for(ip = &itable.inode[0]; ip < &itable.inode[NINODE]; ip++){
if(ip->ref > 0 && ip->dev == dev && ip->inum == inum){
ip->ref++;
release(&itable.lock);
return ip;
}
if(empty == 0 && ip->ref == 0) // Remember empty slot.
empty = ip;
}
// Recycle an inode entry.
if(empty == 0)
panic("iget: no inodes");
ip = empty;
ip->dev = dev;
ip->inum = inum;
ip->ref = 1;
ip->valid = 0;
release(&itable.lock);
return ip;
}
通过尾调用返回 iget的内容,实际上iget做的就是在itable上(即in-memory inode)返回一个条目
- 当这个条目是已经被引用了的,则条目ref++
- 否则初始化下这个条目
// Lock the given inode.
// Reads the inode from disk if necessary.
void
ilock(struct inode *ip)
{
struct buf *bp;
struct dinode *dip;
if(ip == 0 || ip->ref < 1)
panic("ilock");
acquiresleep(&ip->lock);
if(ip->valid == 0){
bp = bread(ip->dev, IBLOCK(ip->inum, sb));
dip = (struct dinode*)bp->data + ip->inum%IPB;
ip->type = dip->type;
ip->major = dip->major;
ip->minor = dip->minor;
ip->nlink = dip->nlink;
ip->size = dip->size;
memmove(ip->addrs, dip->addrs, sizeof(ip->addrs));
brelse(bp);
ip->valid = 1;
if(ip->type == 0)
panic("ilock: no type");
}
}
// Unlock the given inode.
void
iunlock(struct inode *ip)
{
if(ip == 0 || !holdingsleep(&ip->lock) || ip->ref < 1)
panic("iunlock");
releasesleep(&ip->lock);
}
在读取或写入 inode 的元数据或内容之前,代码必须使用 ilock 锁定 inode。
记住:The kernel keeps a table of in-use inodes in memory to provide a place for synchronizing access to inodes used by multiple processes.
一旦 ilock 对 inode 拥有独占访问权它会从磁盘(更可能是缓冲区缓存)读取 inode。
inode的释放
iput释放对某个内存 inode 的引用
// Drop a reference to an in-memory inode.
// If that was the last reference, the inode table entry can
// be recycled.
// If that was the last reference and the inode has no links
// to it, free the inode (and its content) on disk.
// All calls to iput() must be inside a transaction in
// case it has to free the inode.
void
iput(struct inode *ip)
{
acquire(&itable.lock);
if(ip->ref == 1 && ip->valid && ip->nlink == 0){
// inode has no links and no other references: truncate and free.
// ip->ref == 1 means no other process can have ip locked,
// so this acquiresleep() won't block (or deadlock).
acquiresleep(&ip->lock);
release(&itable.lock);
itrunc(ip); // 清空文件内容(释放所有直接块和间接块)。
ip->type = 0; // 标记 inode 空闲。
iupdate(ip); // 把修改后的 inode 写回磁盘。
ip->valid = 0;
releasesleep(&ip->lock);
acquire(&itable.lock);
}
ip->ref--;
release(&itable.lock);
}
-
iupdate(struct inode *ip)把内存 inode 的内容写回磁盘 dinode。 -
itrunc(struct inode *ip)释放 inode 所有内容块,让文件变空。-
// 释放直接块: for(i = 0; i < NDIRECT; i++){ if(ip->addrs[i]){ bfree(ip->dev, ip->addrs[i]); ip->addrs[i] = 0; } } -
if(ip->addrs[NDIRECT]){ // 读取间接块。 bp = bread(ip->dev, ip->addrs[NDIRECT]); a = (uint*)bp->data; // 遍历里面的 NINDIRECT 个地址,逐一释放。 for(j = 0; j < NINDIRECT; j++){ if(a[j]) bfree(ip->dev, a[j]); } brelse(bp); // 最后释放间接块本身。 bfree(ip->dev, ip->addrs[NDIRECT]); ip->addrs[NDIRECT] = 0; } -
ip->size = 0; // 文件大小清零。 iupdate(ip); // 把更改写回磁盘。 -
itrunc相当于把文件内容彻底丢弃,回收所有数据块,inode 变成空壳。
-
从inode中读写数据,更新inode状态
int readi(struct inode *ip, int user_dst, uint64 dst, uint off, uint n)int writei(struct inode *ip, int user_src, uint64 src, uint off, uint n)
从inode ip中偏移量为off开始,读取/写入字节n大小的数据,数据读到dst/来自src, 通过user_dst/user_src来判断空间是否来自用户空间(因为内核和用户空间的页目录不同,所以不能直接在地址空间上相互copy)
Directory and Pathname 层
代码在kernel/fs.c: 541
File Descriptor
代码在kernel/file.candkernel/sysfile.c and kernel/file.h
struct file {
enum { FD_NONE, FD_PIPE, FD_INODE, FD_DEVICE } type;
int ref; // reference count
char readable;
char writable;
struct pipe *pipe; // FD_PIPE
struct inode *ip; // FD_INODE and FD_DEVICE
uint off; // FD_INODE
short major; // FD_DEVICE
};
首先文件被分类为4类:
- Pipe (内核内部维护一个buffer)
- Inode (磁盘使用)
- device (设备使用,设备大多需要实现驱动代码,即设备的top部分和bottom部分,其中有设备专门的读和写)
- none (debug使用)
file这个数据结构维护了pipe, inode, device这三个文件种类所需的全部元数据
struct {
struct spinlock lock;
struct file file[NFILE];
} ftable;
- 文件表,xv6固定系统能够打开的文件数最大为NFILE
- 当需要打开新文件时,会调用
filealloc遍历ftable查找file->ref == 0的文件结构体
fileread和filewrite两个函数会识别file的类型:
- 若为pipe,则读和写调用
kernel/pipe.c下的piperead和pipewrite - 若为device, 则调用设备自身驱动实现的读和写
- 若为inode, 则调用我们上述介绍的inode那一套读写了
文件描述符的实现重点在kernel/sysfile.c, 对于每一个进程在struct proc 下应该都有一个struct file *ofile[NOFILE];
在进程打开一个文件file时,需要分配文件描述符给这个文件fdalloc, 其实现逻辑为遍历进程的ofile, 若ofile[i] == 0则将文件描述符i分配给这个文件, 同时ofile[i] == file
这样就将文件与文件描述符进行绑定了
当进程open文件,得到其文件描述符,通过传递文件描述符给read和write系统调用,其最终会通过文件描述符得到对应的file结构体
传递file结构体给filewrite和fileread,在这个两个函数上会最终实现读写的逻辑
运用
Mmap
现实世界,文件系统和虚拟内存相结合实现mmap,将文件映射到进程的虚拟内存中(其实相当于将Buffer cache层暴露出来了而已)
void *mmap(void *start, size_t length, int prot, int flags,int fd, off_t offset),下面就其参数解释如下:
- start:用户进程中要映射的用户空间的起始地址,通常为NULL(由内核来指定)
- length:要映射的内存区域的大小
- prot:期望的内存保护标志
- flags:指定映射对象的类型
- fd:文件描述符(由open函数返回)
- offset:设置在内核空间中已经分配好的的内存区域中的偏移,例如文件的偏移量,大小为PAGE_SIZE的整数倍
- 返回值:mmap()返回被映射区的指针,该指针就是需要映射的内核空间在用户空间的虚拟地址
logging层API调用顺序
// log_write() replaces bwrite(); a typical use is:
// bp = bread(...)
// modify bp->data[]
// log_write(bp)
// brelse(bp)
Inode层API调用顺序
// Thus a typical sequence is:
// ip = iget(dev, inum)
// ilock(ip)
// ... examine and modify ip->xxx ...
// iunlock(ip)
// iput(ip)
//
SP NEMU: 硬件中断
硬件中断的实质是一个数字信号, 当设备有事件需要通知CPU的时候, 就会发出中断信号. 这个信号最终会传到CPU中, 引起CPU的注意. 支持中断机制的设备控制器都有一个中断引脚, 这个引脚会和CPU的INTR引脚相连, 当设备需要发出中断请求的时候, 它只要将中断引脚置为高电平, 中断信号就会一直传到CPU的INTR引脚中.
-
为了更好地管理各种设备的中断,请求中断控制器最主要的作用就是充当设备中断信号的多路复用器, 即在多个设备中断信号中选择其中一个信号, 然后转发给CPU.
-
CPU每次执行完一条指令的时候, 都会看看INTR引脚, 看是否有设备的中断请求到来. 一个例外的情况就是CPU处于关中断状态, 此时即使INTR引脚为高电平, CPU也不会响应中断.
-
CPU的关中断状态和中断控制器是独立的, 中断控制器只负责转发设备的中断请求, 最终CPU是否响应中断还需要由CPU的状态决定.
-
如果中断到来的时候, CPU没有处在关中断状态, 它就要马上响应到来的中断请求. 我们刚才提到中断控制器会生成一个中断号, CPU将会保存中断上下文, 然后把这个中断作为异常处理过程的原因, 找到并跳转到入口地址
中断嵌套
在进行优先级低的中断处理的过程中, 响应另一个优先级高的中断
- 那么堆栈将是保存中断上下文信息的唯一选择.
- 如果选择把上下文信息保存在一个固定的地方, 发生中断嵌套的时候, 第一次中断保存的上下文信息将会被优先级高的中断处理过程所覆盖, 从而造成灾难性的后果.
- 上下文被覆盖, 被中断进程回不到原来的PC, 去到错误的地址,
中断和用户进程初始化
我们知道, 用户进程从Navy的
_start开始运行, 并且在_start中设置正确的栈指针. 如果在用户进程设置正确的栈指针之前就到来了中断, 我们的系统还能够正确地进行中断处理吗?
之前我们实现的上下文切换中有个重大缺陷导致还不能运行多个用户程序,即我们之前用户进程的中断上下文是放在用户栈的,且我们没有在上下文保存阶段保存用户栈sp的地址
若在用户进程设置正确的栈指针之前就到来了中断, 就会到错误的位置存放上下文。
一般中断都是用内核栈, 甚至x86有中断栈, 他们的栈底都是不依赖于用户栈sp的, 所以在设置栈指针之前就到来了中断, 系统是可以正常处理中断的. 稍后我们会修改实现:
- 如果是从用户态进入CTE(trap), 则在CTE(trap)保存上下文之前, 先切换到内核栈, 然后再保存上下文
- 如果将来返回到用户态, 则在CTE从内核栈恢复上下文之后, 则先切换到用户栈, 然后再返回
我们可以通过栈指针的值来判断当前位于用户态还是内核态, 因为内核地址和用户地址是分开的:
- 如何识别进入CTE之前处于用户态还是内核态? - pp (Previous Privilege)
- CTE的代码如何知道内核栈在什么位置? - ksp (Kernel Stack Pointer)
- 如何知道将要返回的是用户态还是内核态? - np (Next Privilege)
- CTE的代码如何知道用户栈在什么位置? - usp (User Stack Pointer)
np、usp被__am_irq_handle使用后会变化(上下文切换)pp、ksp被__am_irq_handle使用后被赋值因此在
np、usp会变的情况下, 为了防止旧值丢失, 需要把他们存入Context保存起来.而
pp、ksp值在被__am_irq_handle使用后会被覆盖, 所以在__am_irq_handle前可以被随意赋值. 这两个状态类似caller saved registers, 无论中间更新多少次, 只要最后能恢复为正确的值即可.
CTE的重入(re-entry)问题
代码是否可能在离开CTE之前又再次进入CTE? 我们知道yield()是通过CTE来实现的, 如果用户进程通过系统调用陷入内核之后, 又执行了yield(), 就会出现CTE重入的现象.
另一种引发CTE重入的现象是上文介绍的中断嵌套: 第一次中断到来的时候代码会进入CTE, 但在第二次中断可能会在代码离开CTE之前到来.
小心CTE的重入(re-entry)问题对我们的代码带来的逻辑问题
问题在于
pp值在没有改变. 假如pp == USER, 那么无论嵌套CTE多少次,__am_irq_handle看到的pp还是USER, 而我们的预期是从第一次嵌套开始pp就是KERNEL了.
操作系统和中断
在真实的操作系统中, 系统调用的处理是在打开中断的状态下进行的. 这是因为系统调用的处理时间可能会非常长, 例如SYS_read可能会从机械磁盘中读取大量数据, 如果操作系统一直处于关中断的状态, 就无法及时响应系统中的各种中断请求: 通过时钟中断维护的系统时钟可能会产生明显的滞后, 网卡因为缓冲区满了而丢弃大量的网络包...
这就给操作系统的设计带来了很大的挑战: 因为中断的到来是不可预测的, 这就意味着CTE的重入可能会发生在系统调用处理过程中的任何地方. 更麻烦的是, 不止CTE的代码会产生重入, 操作系统中的很多代码也可能会产生重入. 因此操作系统开发者必须非常谨慎地编写相应的代码, 稍有不慎就会出现全局变量因重入而被覆盖的问题.
正因为这样的挑战, 我们在PA中就简单地通过关中断来回避这个问题. 事实上, 重入可以认为是一种特殊的并发, 在下学期的操作系统课上, 你将会对并发有更深刻的认识.
Lab: Xv6 and Unix utilities
- To quit qemu type: Ctrl-a x (press Ctrl and a at the same time, followed by x).
- if you type Ctrl-p, the kernel will print information about each process.
- run
make gradeto test your solutions with the grading program
sleep
- how you can obtain the command-line arguments passed to a program.
int argc, char *argv[]
- If the user forgets to pass an argument, sleep should print an error message.
fprintf(2, "xxx");exit(1);
- Use the system call
sleep.- 声明在
user/user.h - 定义在
user/usys.S
- 声明在
在xv6中并不像NEMU中在navy-libs中实现了libs等库,xv6通过一种暴力且巧妙的方法调用系统调用:
- 但是最终都是要通过
ecall指令实现U model --> S model 执行系统调用
这里有个BUG,应该不是我现在的问题:
多次调用sleep,会提示:
exec sleep failed
primes
这个实验很有意思,通过read在内核的阻塞达到同步
没有这个同步你会看到你的print乱七八糟
我使用递归实现,能够使用递归的原理是:
- Hint:
readreturns zero when the write-side of a pipe is closed.
原理图:
find
- Don't recurse into "." and ".."
- 这个提示很有意思,因为在xv6中"." and ".."也被认定为目录类型
- to get a clean file system run
make clean- 简单暴力地将
fs.img磁盘删除了
- 简单暴力地将
Lab: system calls
add some new system calls to xv6
Using gdb
Looking at the backtrace output, which function called
syscall?

What is the value of
p->trapframe->a7and what does that value represent? (Hint: lookuser/initcode.S, the first user program xv6 starts.)
在执行完kernel/syscall.c下syscall下的struct proc *p = myproc()后:

定义在
kernel/proc.h表示线程的状态
p->trapframe->a7表示系统调用对应的整数,即异常号
What was the previous mode that the CPU was in?
user mode
Write down the assembly instruction the kernel is panicing at. Which register corresponds to the varialable
num?
80001ff6: 00002683 lw a3,0(zero) # 0 <_entry-0x80000000>
num <--> a3
Why does the kernel crash? Hint: look at figure 3-3 in the text; is address 0 mapped in the kernel address space? Is that confirmed by the value in
scauseabove? (See description ofscausein RISC-V privileged instructions)


scause 0x000000000000000d
sepc=0x0000000080001ff6 stval=0x0000000000000000
scause == 13, 果然就是Load page fault
What is the name of the binary that was running when the kernel paniced? What is its process id (
pid)?
// you can print out the process's name:
p p->name
$1 = "initcode\000\000\000\000\000\000\000"
p p->pid
$2 = 1
gdb debug xv6:
System call tracing
将tracing 系统调用 做成trace系统调用,其核心思想为:
trace系统调用的功能就是:
- 将要追踪的系统调用的掩码(mask)保存到进程的状态中
- 因为子进程会复制父进程的状态,所以掩码也能能够被复制
修改syscall函数(in kernel/syscall.c) ,syscall函数开始就会通过myproc函数得到当前进程的状态,我们只要依据进程状态中保存的掩码就能判断是否要打印trace的系统调用信息
- 因为我们是通过printf函数输出,但是目前printf系统调用只实现了
x, d, s, p这几个占位符,所以我们在printf中不能使用类似%ld, %lu这些占位符
user中系统调用函数生成的原理
我们在user中能够通过使用声明在user/user.h中的系统调用函数,但是真正这些函数的实现在哪?
在user/usys.S
而这个文件又是如何生成的呢?
是通过user/usys.pl自动生成的,我们每当需要再添加系统调用时需要在user/usys.pl下添加下entry(xxx)
Sysinfo
在xv6中 kernel/vm.c copyout函数:
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len);
想了想,为何我在完成NEMU的nanos-lite完全没有考虑过这个问题?我具体要为将内核中的数据放到用户态的内存而担忧?
这是因为在NEMU中,NEMU的硬件完成将vm->pa的转换(即硬件完成MMU的工作),而在xv6中MMU是由操作系统完成的
- To collect the number of processes, add a function to
kernel/proc.c- 需要注意因为是多线程, 可能需要上锁
- To collect the amount of free memory, add a function to
kernel/kalloc.ckalloc.c整体的功能是将free memory以页(PGSIZE)为单位分块- 将页以链表的形式管理起来且只分配不回收;要得到剩余的空闲内存大小只要遍历链表即可
Lab: page tables
Speed up system calls
-
allocproc函数可以理解为作用是为将要执行的进程分配各个页 -
proc_pagetable函数主要是做映射(即调用mappages) -
主要我们需要在user model使用USYSCALL,所以PTE除了PTE_R标识外,还需要PTE_U
- if PTE_U is not set, the PTE can be used only in supervisor mode.
-
主要需要在
proc_freepagetable中释放掉与USYSCALL的映射-
即设置USYSCALL相关PTE, 即不设置PTE_V,表示非法,未映射
-
V 位表示该 PTE 的其余字段是否有效(V=1 时有效)。若 V=0,则遍历到此
PTE 的虚拟地址翻译过程将触发页故障
-
Print a page table
vmprint()
- arg:
pagetable_t if(p->pid==1) vmprint(p->pagetable)inexec.cjust before thereturn argc- format
- The first line displays the argument to
vmprint. - Each PTE line is indented by a number of
" .."that indicates its depth in the tree. - Each PTE line shows the PTE index in its page-table page, the pte bits, and the physical address extracted from the PTE.
- Don't print PTEs that are not valid.
PTE_V
- Don't print PTEs that are not valid.
- The first line displays the argument to
RV64 Sv39
-
Sv39 使用4 KiB基页。
-
PTE 的大小(8 字节)
-
Sv39 的512 GiB地址空间被划分为:
- \(2^9\) 个1 GiB的吉页 (即VPN[2]为9位)
- 每个吉页被进一步划分为 \(2^9\) 个2 MiB的兆页(即VPN[1]为9位)
- 每个兆页被进一步划分为\(2^9\) 个4 KiB的基页。(即VPN[2]为9位)
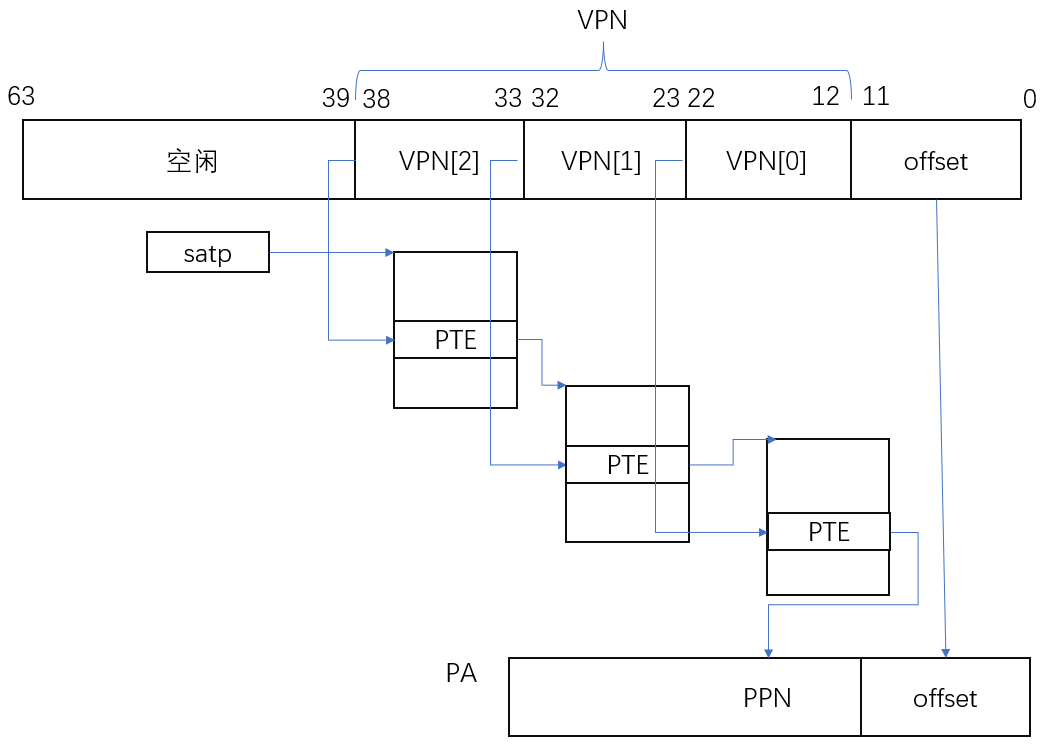
- 一级页表 PTE物理地址:satp.PNN << 12 + VPN[2] * 8
- 因为satp.PNN需要左移12位,因为保存物理地址时我们忽略掉了一定是0的底12位
- 同时可以将VPN[i]当做页表的下标,每个PTE 8B, 所以需要乘以8
- 二级页表 PTE物理地址: PTE.PPN << 12 + VPN[1] * 8
- 三级页表 PTE物理地址: PTE.PPN << 12 + VPN[0] * 8
- 叶子PTE 最终的物理地址: PTE.PPN << 12 + VA_OFFSET
-
依旧每个页表都是4KiB的大小
-
虚拟地址:64位,真正使用的为39位,高25位空闲
-
物理地址:56位, 其中12位有对齐4KiB的位移,所以PPN为44位


- 页目录地址PA: satp.PPN << 12
输出:
page table 0x0000000087f6b000
..0: pte 0x0000000021fd9c01 pa 0x0000000087f67000
.. ..0: pte 0x0000000021fd9801 pa 0x0000000087f66000
.. .. ..0: pte 0x0000000021fda01b pa 0x0000000087f68000
.. .. ..1: pte 0x0000000021fd9417 pa 0x0000000087f65000
.. .. ..2: pte 0x0000000021fd9007 pa 0x0000000087f64000
.. .. ..3: pte 0x0000000021fd8c17 pa 0x0000000087f63000
..255: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..511: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..509: pte 0x0000000021fdcc13 pa 0x0000000087f73000
.. .. ..510: pte 0x0000000021fdd007 pa 0x0000000087f74000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000
What does page 0 contain? What is in page 2? When running in user mode, could the process read/write the memory mapped by page 1? What does the third to last page contain?
首先这个进程是我们userinit中通过exec(init, argv)创建的进程,创建代码在user/initcode.S
-
内核在使用
exec执行新进程时会使用free memory来给新进程放置其text,data等 -
page 0中的内容可读可写可执行,应该是用户程序的text
-
page 1,2,3 可读可写不可执行应该是用户程序的data或者stack
-
后面的内容应该是trapframe, 最后应该是trampoline
-
可看Lec03
依据:
Detect which pages have been accessed
目标:
**Add a new feature to xv6 that detects and reports this information to userspace by inspecting the access bits in the RISC-V page table. **
- implement
pgaccess(), a system call that reports which pages have been accessed.- args:
- the starting virtual address of the first user page to check.
- the number of pages to check.
- user address to a buffer to store the results into a bitmask
- args:
TODO
Lab: traps
RISC-V assembly
Which registers contain arguments to functions? For example, which register holds 13 in main's call to
printf?
printf("%d %d\n", f(8)+1, 13);
24: 4635 li a2,13
26: 45b1 li a1,12
28: 00000517 auipc a0,0x0
2c: 7b850513 addi a0,a0,1976 # 7e0 <malloc+0xe6>
30: 00000097 auipc ra,0x0
34: 612080e7 jalr 1554(ra) # 642 <printf>
a2
Where is the call to function
fin the assembly code for main? Where is the call tog? (Hint: the compiler may inline functions.)
内联了,直接把值计算出来了
At what address is the function
printflocated?
0000000000000642 <printf>:
What value is in the register
rajust after thejalrtoprintfinmain?
ra 返回地址
s0 或者叫fp帧指针
void main(void) {
1c: 1141 addi sp,sp,-16 // 创建main函数的栈帧
1e: e406 sd ra,8(sp) // 保存调用者函数的返回地址
20: e022 sd s0,0(sp) // 保存调用者函数的帧指针
22: 0800 addi s0,sp,16 // 设置新的帧指针
printf("%d %d\n", f(8)+1, 13);
24: 4635 li a2,13
26: 45b1 li a1,12
28: 00000517 auipc a0,0x0
2c: 7b850513 addi a0,a0,1976 # 7e0 <malloc+0xe6>
30: 00000097 auipc ra,0x0 // aupic PC加高位立即数
34: 612080e7 jalr 1554(ra) # 642 <printf>
exit(0);
38: 4501 li a0,0
3a: 00000097 auipc ra,0x0
3e: 28e080e7 jalr 654(ra) # 2c8 <exit>
jalr rd, offset(rs1) t=pc+4; pc=(x[rs1]+sext(offset))&∼1; x[rd]=t
执行jalr时,PC = 0x34, 之后ra = PC + 4 = 0x38
What is the output? Here's an ASCII table that maps bytes to characters.
The output depends on that fact that the RISC-V is little-endian. If the RISC-V were instead big-endian what would you set
ito in order to yield the same output? Would you need to change57616to a different value?
output: HE110 World
因为小端模式,unsigned int i = 0x00646c72;放到内存(从小地址到大地址)的感觉就是72 6c 64 00
如果是大端模式,i 需要在内存中也是72 6c 64 00,因为大端模式是先存储最高位,所以unsigned int i = 0x726c6400
但是57616不需要变,因为系统在处理数值型的输出时会处理
In the following code, what is going to be printed after
'y='? (note: the answer is not a specific value.) Why does this happen?printf("x=%d y=%d", 3);printrf
printf中是通过va_list ap; 和 va_arg(ap, uint64);来获取参数的
RISC-V PSABI 把 va_list 表示为与 void * 相同(即“指针”),并要求:
va_start将该指针初始化为“第一个可变参在函数入口可能出现的地址”;如果有些可变参会经由寄存器传递,函数需要在入口处构造一个 varargs save area(把寄存器中的入参复制到栈的保存区),然后把va_list指向该保存区(这样后续统一从这个区域/后续栈位置顺序读取)。
所以y=%d的值会读取随机的残留在a1寄存器上的值
Backtrace
- Each stack frame consists of the return address and a "frame pointer" to the caller's(调用者) stack frame.
- Your
backtraceshould use the frame pointers to walk up the stack and print the saved return address in each stack frame. 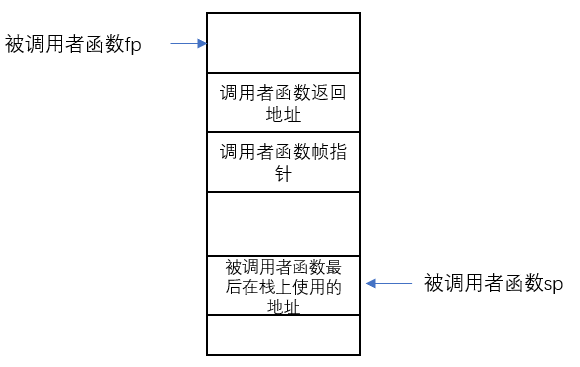
- The GCC compiler stores the frame pointer of the currently executing function in the register
s0. - the return address lives at a fixed offset (-8) from the frame pointer of a stackframe
- the saved frame pointer lives at fixed offset (-16) from the frame pointer.
那么最初的调用者函数返回地址是什么?即我们如何判断到了最后的栈帧?
我们处理异常是从trampoline.S开始的,其中切换到的内核栈来自p->trapframe->kernel_sp = p->kstack + PGSIZE; // process's kernel stack (kernel/trap.c:106)
也就是说一切的开始都是在这个栈上,我们来看看进程创建p->kstack是如何来的:
// map kernel stacks beneath the trampoline,
// each surrounded by invalid guard pages.
// kernel/memlayout.h: 56
#define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE) //
// kernel/proc.c: 54
for(p = proc; p < &proc[NPROC]; p++) {
initlock(&p->lock, "proc");
p->state = UNUSED;
p->kstack = KSTACK((int) (p - proc)); // (int) (p - proc) 计算出来的是元素差
}
所以我们只要判断下fp是否来到了栈的最高点p->kstack + PGSIZE即可
但是想想好像又没有这么麻烦,因为栈就只有一个PGSIZE的大小,我们只要判断fp是否在这个页上即可,用PGROUNDDOWN(fp) == PGROUNDDOWN(p->kstack) 判断即可
Alarm
periodically alerts a process as it uses CPU time
- add a new
sigalarm(interval, handler)system callcalls sigalarm(n, fn)- after every
n"ticks" of CPU time that the program consumes, the kernel should cause application functionfnto be called. - When
fnreturns, the application should resume where it left off.
- after every
- A tick is a fairly arbitrary unit of time in xv6, determined by how often a hardware timer generates interrupts.
- If an application calls
sigalarm(0, 0), the kernel should stop generating periodic alarm calls.
Get started by modifying the kernel to jump to the alarm handler in user space, which will cause test0 to print "alarm!".
我在proc.h中添加如下元素:
// Labs: trap
int maxTick; // 触发阈值
int tickCnt; // 计数器
uint64 alarmHandler; // 处理函数
struct trapframe alarmContext;
其中alarmContext是用来保存原用户程序的状态
我在trap.c的usertrap中识别到是定时器中断后并且发现计数器到达阀值后就保存原用户程序的上下文(因为没有所谓的调用者和被调用者,线程全部的32个通用寄存器全部要保存)切换下一次用户线程执行的内容:
if (p->maxTick != 0) {
p->tickCnt++;
if (p->tickCnt == p->maxTick) {
p->alarmContext = *(p->trapframe);
p->trapframe->epc = p->alarmHandler;
}
}
同时在sys_sigreturn(void)中恢复原用户程序的上下文
uint64
sys_sigreturn(void)
{
struct proc *p = myproc();
if (p->maxTick != 0 && p->tickCnt == p->maxTick) {
*(p->trapframe) = p->alarmContext;
p->tickCnt = 0;
}
return 0;
}
为了判别是否通过sigalarm(0,0) 取消了alarm,我添加了p->maxTick != 0判断
为了防止重入sys_sigreturn 我添加了p->tickCnt == p->maxTick判断
这个题目只要记住:
一个线程不会并行地执行在多个CPU上,其同一时间只会执行在一个CPU上
且不同的线程之前alarm独立,用户程序和内核处理程序并不是并行的
Lab: Copy-on-Write Fork for xv6
-
static struct proc* allocproc(void)只是初始化一些进程必要的内存如页目录和trapframe,所以其API我们不需要更改 -
int mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)其做的事情就是将起始虚拟地址 va 映射到 起始物理地址 pa, va 和 pa 的大小相同都是size大小(size 一般为PGSIZE);这个过程mapages会递归地查看修改pagetable 并最终将leaf PTE的标志设置成perm -
uint64 walkaddr(pagetable_t pagetable, uint64 va)将 va --> pa -
pte_t *walk(pagetable_t pagetable, uint64 va, int alloc)将va--> PTE
相关硬件异常处理
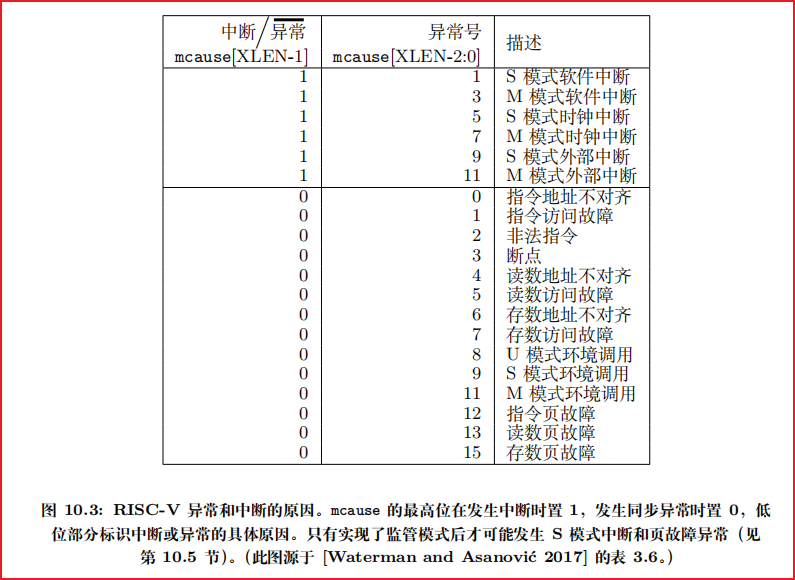
Instruction page fault:指令取值时的页错误。scause 编号 12(0xC)。
Load page fault:执行一次 load 指令时的页错误。scause 编号 13(0xD)。
Store / AMO page fault:执行 store 或 AMO 指令时的页错误(写/原子写相关)。scause 编号 15(0xF)。
COW 在写时会遇到的那种 page fault 会是“Store/AMO page fault”——异常码为 15(十进制),即 0xF

硬件会在异常时把“出错的虚拟地址”保存到寄存器 stval(在 S-mode 下是 stval,M-mode 对应 mtval);但不会给出对应的物理地址。
通常把 RSW 的其中一位当作 “COW 标志位”(设为 1 表示该 PTE 是 copy-on-write 映射);
#define PTE_COW (1L << 8) /* 也有人用 (1L<<9) 或把两位当一个字段,取决于实现 */
a "reference count" of the number of user page tables that refer to that page.
- Set a page's reference count to one when
kalloc()allocates it. - Increment a page's reference count when fork causes a child to share the page
- decrement a page's count each time any process drops the page from its page table.
kfree()should only place a page back on the free list if its reference count is zero.
所以COW fork实现的整体思路为:
在fork时,普通实现下我们会copy父进程物理内存到子进程的物理内存(子进程会申请新的物理内存)
COW fork下子进程只copy父进程的页表内容,并将其中带有PTE_W权限的标识去除,换成PTE_COW
当然父进程的pte标识也要如上改动
当子进程/父进程一方要写入PTE_COW标识的PTE代表的物理地址时,那一方只要创建出新的物理地址,然后将旧物理地址中的内容copy到新物理地址,然后去除PTE_COW的标识,添加PTE_W的标识,然后再写入新内容到新地址,然后free掉旧地址。
你可能会疑问,那另一方呢?其标识我们要如何改到?例如:
当父进程遇到要写入PTE_COW标识的PTE代表的物理地址时,父进程完成了上述改动;然后子进程遇到了上述情况,照样完成上述改动
其中有一点要注意的是free掉旧地址,现在我们要为物理地址添加一些额外信息例如cnt数组,表示当前物理地址被多少个进程的虚拟地址给映射了,当进程虚拟地址映射的物理地址数大于1时,我们就还不能释放物理地址。
- 为了实现这点,我们有两个重要的函数
mappages和uvmunmap - 我认为应该在
mappages上实现cnt++操作 - 应该在
uvmunmap上实现cnt--操作 - 在
kalloc时初始化cnt数组对应物理地址为0
(我的实现可能和讲义给的建议不太一样)
DEBUG
BUG1
表面上的报错为:panic: init exiting
我发现是因为在exec函数中执行出错返回了-1
int ret = exec(path, argv); (kernel/sysfile.c:464)
然后产生了exit系统调用,随后就是如下一系列过程:

在追溯下发现问题发生在exec中的copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1)
后来发现是我在copyout中相关权限判断不对
Lab: Multithreading
Uthread: switching between threads
**You will need to add code to thread_create() and thread_schedule() in user/uthread.c, and thread_switch in user/uthread_switch.S. **
- One goal is ensure that when
thread_schedule()runs a given thread for the first time, the thread executes the function passed tothread_create(), on its own stack. - Another goal is to ensure that
thread_switchsaves the registers of the thread being switched away from, restores the registers of the thread being switched to, and returns to the point in the latter thread's instructions where it last left off. - You will have to decide where to save/restore registers; modifying
struct threadto hold registers is a good plan. - You'll need to add a call to
thread_switchinthread_schedule; you can pass whatever arguments you need tothread_switch, but the intent(目的) is to switch from threadttonext_thread.
调用者保存寄存器和被调用者保存寄存器
thread_switchneeds to save/restore only the callee-save registers. Why?
这关乎我们的实现:
struct context {
uint64 ra;
uint64 sp;
// 被调用者保存寄存器
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context context;
};
我们首先要搞清楚调用者和被调用者,以及调用者保存寄存器和被调用者保存寄存器
int bar(void) {
return 42; // leaf 函数,不再调用其它函数
}
int foo(int x) {
int y = bar(); // foo 会调用 bar —— 这是嵌套调用
return x + y;
}
int main(void) {
return foo(1);
}
对应的简化 RISC-V 汇编:
# ---------- main ----------
main:
addi sp, sp, -16 # 分配栈帧(保持 16 字节对齐)
sw ra, 12(sp) # 保存调用main的函数的ra
li a0, 1 # 参数 a0 = 1
jal ra, foo # call foo ; ra <- addr_after_call (在 main 中)
# 返回到这里,a0 中是 foo 的返回值
lw ra, 12(sp)
addi sp, sp, 16
ret
# ---------- foo ----------
# foo 会调用 bar,所以必须保存原来的 ra(它返回给 main 的地址)
foo:
addi sp, sp, -16 # 分配栈帧(16 字节对齐)
sw ra, 12(sp) # 保存进入 foo 时的 ra(即 main 的返回地址)
# (如果使用 s0/fp,也会在这里保存并设置 s0)
# 现在调用 bar:
jal ra, bar # call bar ; 这条指令会把返回地址写入 ra —— 覆盖了之前的 ra 寄存器
# bar 返回,返回值在 a0
lw ra, 12(sp) # 恢复 foo 原来的 ra(也就是 main 的返回地址)
addi sp, sp, 16
ret # 使用恢复后的 ra 返回到 main
# ---------- bar ----------
bar:
li a0, 42
ret # leaf 函数,没调用别的函数,不需要保存 ra
foo 既是被调用者(callee)相对于 main,又是调用者(caller)相对于 bar。因为 foo 要去调用 bar,它必须保证调用 bar 时不会丢失那个回到 main 的地址。(因为jal bar时会写ra寄存器,若不保存会丢失原信息)
bar 自身不调用其他函数,所以它不需要保存 ra(ra 的当前值就是返回到 foo 的地址,且 bar 不会覆盖 ra)。
这样我们就能够理解ra是调用者保存(caller-save)寄存器了,因为编译器其遵守着调用约定,其经常会把保存ra的操作提前到函数指令的开始,所以我们经常能够看到如下一番操作:
1c: 1141 addi sp,sp,-16 // 创建main函数的栈帧
1e: e406 sd ra,8(sp) // 保存调用者函数的返回地址
20: e022 sd s0,0(sp) // 保存调用者函数的帧指针
22: 0800 addi s0,sp,16 // 设置新的帧指针
也经常看到如下图:
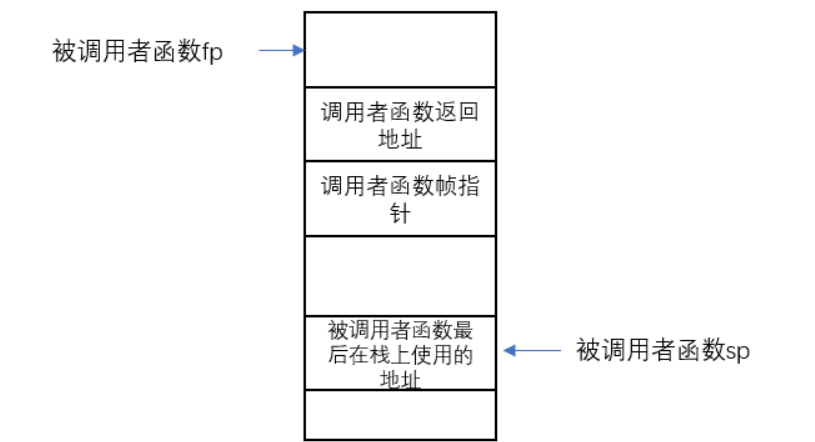
线程切换时,在我们的实验是在同model(即都是在User model)下实现的切换
- 若如果上下文切换是由中断/异常触发(随时发生,程序在任意指令处被打断),中断处理程序必须保存全部(或至少更多)寄存器
- 因为调用约定不对“中断发生时寄存器的期望”作任何保证。
- 中断发生时可能有任意寄存器在使用中(caller-saved 也可能正被活跃使用),所以中断处理的入口/出口要保存足够多的状态来完全恢复被中断线程。
但是我们这种是协作式,即由线程代码显式调用switch,此时调用switch的函数会承担调用者的责任保存调用者保护寄存器在其栈上,switch只要保存被调用者保存寄存器即可然后恢复另一个线程的状态
我们会在switch中保存ra寄存器,可以从两个角度进行理解:
-
假设我们线程A --> 线程B,线程A中调用函数
switch切换到线程B,线程B执行必然会使用到ra,线程A的switch函数要承担调用者的责任 -
thread_switch干的事不是普通函数调用,而是:- 保存“当前线程”的上下文(包括 sp, callee-saved 寄存器, ra 等等);
- 恢复“另一个线程”的上下文,并跳转到它“上次停下的地方”。
这里的关键是:线程切换之后,当前线程不会马上回来!
- 线程 A 调用
thread_switch时,它的ra寄存器里存的是 “调用点的返回地址”。 - 如果不保存这个
ra,当 A 将来再次被调度恢复时,就不知道应该“从哪里继续执行”了。
所以对调度器来说,
ra已经不只是“caller-saved”,而是线程上下文的一部分
DEBUG
我发现只有thread_c在运行,其他的线程不运行了,使用gdb调试的过程为:
// 加载程序的二进制文件,本来gdb上只有内核文件,只能调试内核程序,现在可以通过此方法调试用户程序
file user/_uthread
b thread_schedule
b thread_switch
然后逐步调试
发现all_thread[2].state在我没有显示地写入其时,其自己就会改动数值
通过watch all_thread[2].state, 发现printf调用时改动的,这很奇怪
后来发现是因为初始化线程没有写对:t->context.sp = (uint64)((uint64)t->stack + STACK_SIZE);
我错误地写成了t->context.sp = (uint64)t->stack;
这导致printf在使用栈的时候,将栈的内容写到了t->state中去了。
Barrier
UXIN pthread threading library如下两个API很像XV6中sleep和wakeup的实现:
-
pthread_cond_wait(&cond, &mutex);andpthread_cond_broadcast(&cond); -
struct barrier { pthread_mutex_t barrier_mutex; pthread_cond_t barrier_cond; int nthread; // Number of threads that have reached this round of the barrier int round; // Barrier round } bstate;
在xv6中:
void sleep(void *chan, struct spinlock *lk);
void wakeup(void *chan);
实现思路是一样的,&cond用于指定睡眠事件,即是因为cond才睡眠的,这将pthread_cond_wait和pthread_cond_broadcast联系了起来,等下pthread_cond_broadcast会唤醒因cond而睡眠的线程
&mutex即是条件锁了
XV6启动过程
从entry.S开始
// 做的事情就是sp = ($mhartid + 1) * 4096
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
其中stack0来自start.c是一个char类型的数组,每个CPU应该对应一个stack0,其属于内核的.data/.bss段中的内容
我们称这个最开始在每个CPU上使用stack0作为栈的第一个运行的线程为调度器线程
我通过make CPUS=1 qemu-geb来调试,所以我只有一个CPU,此时mhartid = 0
call start然后来到了start, 接下来做的事情就是为了设置定时器中断,委托中断给S Model, 配置寄存器使得调用mret可以执行到main.c并且处于S Model,具体内容可以查看初始化定时器中断
此时sp = 0x8001ac50 <stack0+4096>
执行start的时候其汇编代码如下:
start:
addi sp,sp,-16
sd ra,8(sp)
sd s0,0(sp)
addi s0,sp,16
...
mret
也就是说其使用stack0的空间后,直接mret了,并没有恢复所使用的栈空间
执行mret到达main后:
main:
addi sp,sp,-16
sd ra,8(sp)
sd s0,0(sp)
addi s0,sp,16
...
执行完后栈为sp = 0x8001ac30 <stack0 + 4064>, 注意其使用的还是stack0的栈
main中会调用cpuid() == 0来决定CPU_0进程一系列初始化操作,其他CPU等待CPU_0初始化完成(通过锁,其锁的实现请见锁相关章节):
CPU_0
- free memory链表初始化,链表管理free memory
kinit() - 分配内核的页目录,并设置CPU satp寄存器为内核页目录
kvminit(); kvminithart(); - 设置
struct proc proc[NPROC]中的每个进程状态为UNUSED,并设置为他们分配内核栈的虚拟地址procinit() - 设置中断处理程序为
kenerlvectrapinithart() - 中断和设备初始化
- 初始化第一个用户进程
userinit- 分配pid, 设置状态为USED,分配进程页目录,分配进程trapframe, 分配进程切换的context,调度器线程初始化
allocproc initproc = 此进程- 为运行
initcode加载其代码和数据并设置p->trapframe,为了后续内核线程-->用户线程时运行的是initcode程序 - 设置状态为RUNNABLE
- 分配pid, 设置状态为USED,分配进程页目录,分配进程trapframe, 分配进程切换的context,调度器线程初始化
scheduler()- 调度器线程被换下,上述初始化完的内核线程换上来执行
- 后续一切进程都是在用户进程下通过
fork系统调用来增加的
其他CPU:
- 设置CPU satp寄存器为内核页目录
kvminithart(); - 设置中断处理程序为
kenerlvectrapinithart() - ask PLIC for device interrupts
plicinithart() scheduler();- 这些CPU的调度器线程会不断询问是否有RUNNABLE的线程出现并切换到其执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号