NEMU PA2 - 补充内容

基础设施(2)
bug诊断的利器 - 踪迹
函数调用的踪迹 - ftrace

-
在我们执行
make ARCH=$ISA-nemu ALL=xxx run时,通过查看Makefile可以发现Makefile帮我们实现了传入ELF文件到NEMU,具体表现为Makefile最终的执行程序命令为:/home/cilinmengye/ics2023/nemu/build/riscv32-nemu-interpreter -l /home/cilinmengye/ics2023/am-kernels/tests/am-tests/build/nemu-log.txt -b -e /home/cilinmengye/ics2023/am-kernels/tests/am-tests/build/amtest-riscv32-nemu.elf /home/cilinmengye/ics2023/am-kernels/tests/am-tests/build/amtest-riscv32-nemu.bin可以看到-e后的参数就是elf文件的地址了,我们只要1.在
parse_args()处识别-e选项,接收elf文件地址 2.打开elf文件准备解析elf文件 -
根据翻阅RISCV手册,可以先保持KISS原则,认为:
-
所有写回
x1(ra)的JAL/JALR都是“函数调用”(伪指令 call)。即JAL/JALR指令的目的寄存器都是ra(rd == ra)


-
ret指令有固定的格式,即
opcode == jalr && imm == 0 && rs1 == ra/x1 && rd == x0
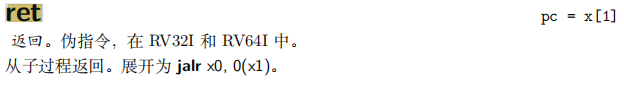
-
知道如何识别call和ret指令后就很好做了,我们接下来只要到/home/cilinmengye/ics2023/nemu/src/isa/riscv32/inst.c下(即NEMU识别指令的C文件)插入相关对call和ret的识别代码即可
识别到call和ret指令后我们需要什么相关信息?
- 对call指令我们需要知道1.指令地址 2.跳转地址 3.跳转到的地址对应函数的名称
- 对ret指令我们需要知道1.指令地址 2.返回时是从哪个函数返回的,这个函数的名称是什么(即执行ret指令时指令地址是属于哪个函数的)
对于上面的问题其实都很好解决:
- 执行call指令的指令地址就是当前的PC值,通过访问PC寄存器我们很容易得到
- 执行call指令时要跳转到的地址可以很容易依据指令
jal/jalr的行为计算出来 - 跳转到的地址对应函数的名称得到方法为依据计算出来的跳转地址,通过解析ELF文件,查找跳转地址在ELF符号表中哪个符号的地址范围,再通过查找字符串表找到这个符号的字符串
- 执行ret指令的指令地址就是当前的PC值,依据指令地址去解析ELF文件查找指令地址是属于哪个函数,步骤与上述相同
依据提供的地址,解析ELF文件返回所述函数的字符串实现
# ics2023/nemu/src/utils/trace.c
char* find_symbol_by_addr(Elf* elf, vaddr_t addr) {
char* ret = NULL;
Elf_Scn *scn = NULL; // 当前遍历到的节 (Section)
Elf_Data *sym_data = NULL; // 指向符号表数据的指针
Elf_Data *str_data = NULL; // 指向符号名字符串表数据的指针
GElf_Shdr sym_shdr; // 用于保存当前符号表节头
size_t sym_count = 0; // 符号表中总的符号数量
// 遍历所有节,寻找符号表节
while ((scn = elf_nextscn(elf, scn)) != NULL) {
// 读取当前节的节头信息到 sym_shdr
if (gelf_getshdr(scn, &sym_shdr) == NULL) Assert(0, "gelf_getshdr failed");
// 判断是否为符号表节
if (sym_shdr.sh_type == SHT_SYMTAB) {
// 获取符号表本身的数据指针
sym_data = elf_getdata(scn, NULL);
Assert(sym_data != NULL, "Get symbol table fail");
// 获取字符串表,关联的字符串表位于节索引 sym_shdr.sh_link
Elf_Scn *str_scn = elf_getscn(elf, sym_shdr.sh_link);
Assert(str_scn != NULL, "Failed to get string table section");
str_data = elf_getdata(str_scn, NULL);
break;
}
}
if (sym_data == NULL) Assert(0, "No symbol table found in ELF file");
if (str_data == NULL) Assert(0, "No string table found in ELF file");
// 计算符号条目数量 = 节大小 / 每条目大小
sym_count = sym_shdr.sh_size / sym_shdr.sh_entsize;
// 因为有可能这个地址并非是函数符号地址,所以需要记录下
// 在符号表条目中查找地址最接近且不大于 addr 的函数符号
for (size_t i = 0; i < sym_count; i++) {
GElf_Sym sym;
gelf_getsym(sym_data, i, &sym);
// 只关注函数类型的符号
if (GELF_ST_TYPE(sym.st_info) != STT_FUNC) continue;
vaddr_t start = (vaddr_t)sym.st_value;
vaddr_t end = (vaddr_t)(start + sym.st_size);
if (addr >= start && addr < end) {
// 获取其在字符串表中的地址
ret = (char*)str_data->d_buf + sym.st_name;
return ret;
}
}
return ret;
}
然后我们需要思考的问题是:我们要如何输出格式,以及应该输出到哪?
- 对于输出格式,我将模仿讲义中的实现
- 对于输出到哪,我将输出到nemu的日志文件中,可以通过nemu提供的API
log_write函数实现
# ics2023/nemu/src/utils/trace.c
#ifdef CONFIG_FTRACE
int formBlank = 1;
char elfbuf[512];
void ftraceInst_get(char* type, vaddr_t instAddr, vaddr_t toAddr) {
if (strcmp(type, "ret") == 0) formBlank--;
char *sym_name = find_symbol_by_addr(elf, toAddr);
if (sym_name == NULL) sym_name = "???";
// 然后将内容输出到log_file中
char* p = elfbuf;
// 先输出指令地址
p += snprintf(p, sizeof(elfbuf), FMT_WORD ":", instAddr);
// 再输出层次空格
for (int i = 0; i < formBlank; i++) p += snprintf(p, sizeof(elfbuf), " ");
// 再输出主体内容
p += snprintf(p, sizeof(elfbuf), "%s [%s@0x%08x]\n", type, sym_name, toAddr);
Assert((p - elfbuf ) <= 512, "Ftrace elfbuf overflow");
// 然后将p中的内容输出到log_file中
log_write("%s", elfbuf);
if (strcmp(type, "call") == 0) formBlank++;
}
/*
* 需要初始化一下elf文件
*/
void init_ftrace(const char *elf_file) {
Assert(elf_file != NULL, "ELF file can't be NULL");
Assert(elf_version(EV_CURRENT) != EV_NONE, "ELF library initialization failed");
int elf_fp = open(elf_file, O_RDONLY);
Assert(elf_fp >= 0, "Failed to open ELF file");
Log("ELF file path is %s", elf_file);
elf = elf_begin(elf_fp, ELF_C_READ, NULL);
Assert(elf != NULL, "elf_begin failed");
snprintf(elfbuf, sizeof(elfbuf), "[Starting Ftrace]\n");
log_write("%s", elfbuf);
}
#endif
当然为了开启Ftrace的配置我们需要到ics2023/nemu/Kconfig文件中更改下加上Ftrace选项:
config FTRACE
bool "Enable ftrace"
default n
然后输出的部分结果为,以make ARCH=$ISA-nemu ALL=recursion run为例:
0x8000000c: call [_trm_init@0x80000254]
0x80000264: call [main@0x800001c8]
0x800001e8: call [f0@0x80000010]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000058: ret [f0@0x80000058]
0x80000100: ret [f2@0x80000100]
0x80000180: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000058: ret [f0@0x80000058]
0x80000100: ret [f2@0x80000100]
0x800001a8: ret [f3@0x800001a8]
0x80000100: ret [f2@0x80000100]
0x80000180: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000058: ret [f0@0x80000058]
0x80000100: ret [f2@0x80000100]
0x80000180: call [f2@0x800000a4]
0x800000f0: call [f1@0x8000005c]
0x80000058: ret [f0@0x80000058]
0x80000100: ret [f2@0x80000100]
0x800001a8: ret [f3@0x800001a8]
0x80000100: ret [f2@0x80000100]
0x800001a8: ret [f3@0x800001a8]
0x80000100: ret [f2@0x80000100]
...
尾调用问题
0x8000000c: call [_trm_init@0x80000260]
0x80000270: call [main@0x800001d4]
0x800001f8: call [f0@0x80000010]
0x8000016c: call [f2@0x800000a4]
0x800000e8: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000e8: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000e8: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000e8: call [f1@0x8000005c]
0x8000016c: call [f2@0x800000a4]
0x800000e8: call [f1@0x8000005c]
0x80000058: ret [f0] # 注释(2)
0x800000fc: ret [f2] # 注释(1)
0x80000180: call [f2@0x800000a4]
0x800000e8: call [f1@0x8000005c]
0x80000058: ret [f0]
0x800000fc: ret [f2]
0x800001b0: ret [f3] # 注释(3)

尾调用(Tail Call)指的是:一个函数在它返回前的最后一步是调用另一个函数,而且它本身不会再做任何工作。当编译器发现函数的“最后一步”是尾调用,就可以做优化:
- 不用保存返回地址(不用再留出一层栈帧)
- 直接跳转到被调用函数
- 共享当前栈帧,不会造成栈增长
例如下面这个代码:
int f1(int x) {
return f0(x); // 尾调用 f0,调用后就直接返回 f0 的返回值
}
从汇编角度指令如下:
jalr x0, f0 // 尾调用 f0,不保存返回地址(x0)!
所以这条指令在我的实现中并不能被识别出为call指令,因为我的实现call指令的目的寄存器rd == ra,这里其rd == x0即没有保存返回地址(在RISCV中ra寄存器是用到暂存函数返回地址的)

发生尾调用时栈中的变化可以如下图理解:
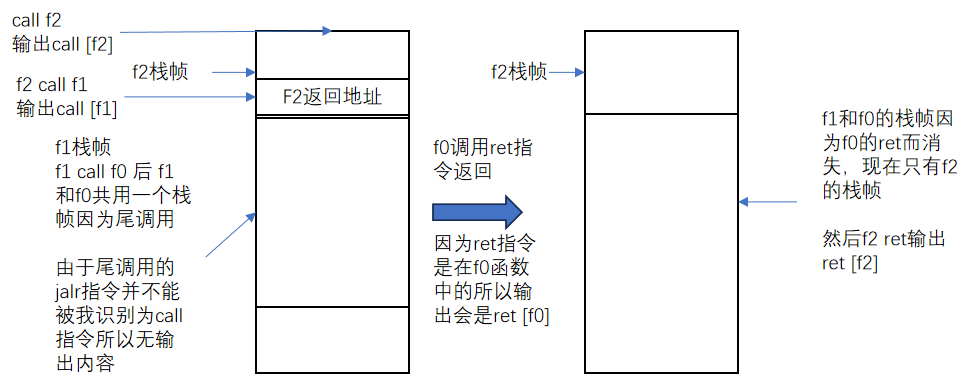
梳理下所以上述的输出为:
call [f2]
call [f1]
ret [f0]
ret [f2]
Differential Testing
问题: 我们在编写NEMU和AM时,因为我们同时编写了硬件(NEMU)和软件(AM), 当发生错误时我们并不知道到底是硬件出错误了还是软件出错误了
控制变量,保证其中一方一定是正确的,测试不一定正确的一方
测试软件
当测试软件AM时,我们可以使用make ARCH=native run进行构建项目,目的是让我们编写的软件AM运行在一定正确的硬件--真机上
运行在真机上需要主要编写可移植的程序

进行测试当然需要测试程序,在NEMU项目中测试程序在ics2023/am-kernels, 其中测试am库的测试程序在ics2023/am-kernels/tests/am-tests
讲义介绍了编写测试程序的方法,即依据程序的特性进行编写测试。
以memset为例,该函数作用可以看做是对数组中的一段连续区间进行写入
考虑如下初始化一个数组:
void reset() {
int i;
for (i = 0; i < N; i ++) {
data[i] = i + 1;
}
}
当我们调用memset对数组一段区间进行写时,验证memset实现是否正确则把预期的输出分成三段来检查:
- 第一段是函数写入区间的左侧, 这一段区间没有被写入, 因此应该有
assert(data[i] == i + 1) - 第二段是函数写入的区间本身, 这一段区间的预期结果和函数的具体行为有关
- 第三段是函数写入区间的右侧, 这一段区间没有被写入, 因此应该有
assert(data[i] == i + 1)
那么我们就可以写一个测试程序,遍历区间[l, r]是数组data要被memset写入的区间,然后依据上述的方法检查三段区间[0, l), [l, r], (r, dataLen]是否都合理
这样问题变成了一个编程题目了,ACMer的强项地方了:
void test_memset() {
int l, r;
for (l = 0; l < N; l ++) {
for (r = l + 1; r <= N; r ++) {
reset();
uint8_t val = (l + r) / 2;
memset(data + l, val, r - l);
check_seq(0, l, 1);
check_eq(l, r, val);
check_seq(r, N, r + 1);
}
}
}
am-kernels下并没有测试klib库的代码,为此讲义要求我们为其编写程序:

测试硬件
基本思想为:找一个实现好的正确的模拟器/真机与nemu一样,在初始时将状态(通用寄存器和PC)设置与nemu相同,执行相同的指令,并对比状态的不同
若状态不同则说明nemu某些地方实现出问题了.
这实际上是一种非常奏效的测试方法, 在软件测试领域称为differential testing(后续简称DiffTest). 通常来说, 进行DiffTest需要提供一个和DUT(Design Under Test, 测试对象) 功能相同但实现方式不同的REF(Reference, 参考实现), 然后让它们接受相同的有定义的输入, 观测它们的行为是否相同.
这里DUT为nemu,REF为spike
Spike是RISC-V社区的一款全系统模拟器
Spike模拟器在哪?
先看Makefile
nemu/tools/difftest.mk中已经设置了相应的规则和参数, 会自动进入nemu/tools/下的相应子目录(kvm-diff, qemu-diff或spike-diff)编译动态库, 并把其作为NEMU的--diff选项的参数传入.
nemu/include/generated/autoconf.h, 阅读C代码时使用nemu/include/config/auto.conf, 阅读Makefile时使用
发现:
CONFIG_DIFFTEST_REF_PATH="tools/spike-diff"
ics2023/nemu/src/monitor/monitor.c-->依据参数-d设置diff_so_file文件路径,difftest_port,调用init_difftest(diff_so_file, img_size, difftest_port)
在ics2023/nemu/tools/spike-diff/Makefile下git clone spike模拟器的代码
在make menuconfig后在nemu目录下执行make ARCH=$ISA-nemu run会执行make -s -C /home/cilinmengye/ics2023/nemu/tools/spike-diff GUEST_ISA=riscv32 SHARE=1 ENGINE=interpreter
g++
-std=c++17
-O2
-shared
-fPIC
-fvisibility=hidden
-Irepo
-Irepo/fesvr
-Irepo/riscv
-Irepo/disasm
-Irepo/customext
-Irepo/fdt
-Irepo/softfloat
-Irepo/spike_main
-Irepo/spike_dasm
-Irepo/build
-I/home/cilinmengye/ics2023/nemu/include
difftest.cc
repo/build/libspike_main.a
repo/build/libriscv.a
repo/build/libdisasm.a
repo/build/libsoftfloat.a
repo/build/libfesvr.a
repo/build/libfdt.a
-o
build/riscv32-spike-so
/home/cilinmengye/ics2023/nemu/build/riscv32-nemu-interpreter --log=/home/cilinmengye/ics2023/nemu/build/nemu-log.txt --diff=/home/cilinmengye/ics2023/nemu/tools/spike-diff/build/riscv32-spike-so
-
让NEMU和Spike模拟器状态相同
- diff_so_file文件是动态库文件,由
ics2023/nemu/tools/spike-diff中的C文件编译动态库, 并把其作为NEMU的--diff选项的参数传入 - 打开DiffTest后,
nemu/src/cpu/difftest/dut.c中的init_difftest()会额外进行以下初始化工作:- 打开传入的动态库文件
ref_so_file. - 通过动态链接对动态库中的上述API符号进行符号解析和重定位, 返回它们的地址.
- 对REF的DIffTest功能进行初始化, 具体行为因REF而异.
- 将DUT的guest memory拷贝到REF中.
- 将DUT的寄存器状态拷贝到REF中.
- 打开传入的动态库文件
- diff_so_file文件是动态库文件,由
-
在NEMU中执行完一条指令后, 就在difftest_step()中让REF执行相同的指令,然后读出REF中的寄存器, 并进行对比.
ics2023/nemu/src/cpu/difftest/dut.c属于nemu,所以这份代码会运行在真机上# difftest_step()代码在不考虑校准的指令的情况下,代码简化为: void difftest_step(vaddr_t pc, vaddr_t npc) { CPU_state ref_r; ref_difftest_exec(1); ref_difftest_regcpy(&ref_r, DIFFTEST_TO_DUT); checkregs(&ref_r, pc); }ref_difftest_exec(1); ref_difftest_regcpy(&ref_r, DIFFTEST_TO_DUT);会调用被编译链接成动态库/home/cilinmengye/ics2023/nemu/tools/spike-diff/build/riscv32-spike-so中的代码
共享库的加载方法
在 Linux 下,我们确实有两种常见的“使用共享库(.so)”的方法:
-
链接时动态链接(隐式加载)
g++ main.o -o myapp -L/path/to/lib -lfoo- -L/path/to/mylibs:把 /path/to/mylibs 加入到链接器搜索路径
- -lfoo:链接 libfoo.so 或 libfoo.a
- 编译/链接阶段就把
libfoo.so的符号(函数、变量)解析进来,生成的可执行文件在运行时会自动去加载这个库。 - 运行时不需要再写任何代码,所有共享库依赖都已经记录在可执行文件中。
-
运行时动态加载(显式加载)
void *h = dlopen("libfoo.so", RTLD_LAZY); auto fn = (foo_t)dlsym(h, "foo"); fn();- 编译时只需加
-ldl,不提libfoo.so。
gcc main.c -o myapp -ldl- 这里的 -ldl 是针对 动态加载库 libdl.so 本身的,而 不是 你后面要动态加载的那个 .so 文件。
- 程序运行到
dlopen那一行时,才去加载你指定路径下的库,并用dlsym拿到符号地址,最后调用。
- 编译时只需加
输入输出
冯诺依曼计算机系统 -- PA2 必答题
编译与链接

Q1
-
去掉static
- 并没有报错
-
去掉inline
- 也没有报错
-
两者都去掉,报错了
+ CC src/engine/interpreter/hostcall.c + CC src/isa/riscv32/inst.c + LD /home/cilinmengye/ics2023/nemu/build/riscv32-nemu-interpreter /usr/bin/ld: /home/cilinmengye/ics2023/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/inst.o: in function `inst_fetch': /home/cilinmengye/ics2023/nemu/include/cpu/ifetch.h:20: multiple definition of `inst_fetch'; /home/cilinmengye/ics2023/nemu/build/obj-riscv32-nemu-interpreter/src/engine/interpreter/hostcall.o:/home/cilinmengye/ics2023/nemu/include/cpu/ifetch.h:20: first defined here collect2: error: ld returned 1 exit status make: *** [/home/cilinmengye/ics2023/nemu/scripts/build.mk:54: /home/cilinmengye/ics2023/nemu/build/riscv32-nemu-interpreter] Error 1
原因如下:
在 C(尤其是 GCC 的 GNU inline)里,static 和 inline 这两个关键字都会影响函数的“链接属性”(linkage),也就是说它们决定了编译器和链接器如何对待在多个翻译单元(.c/.h 文件)中出现的同名函数定义。
1. static inline 放在头文件:
// cpu/ifetch.h
static inline uint32_t inst_fetch(vaddr_t *pc, int len) {
// …
}
static:给函数一个内部链接(internal linkage),也就是每个包含这个头文件的.c文件都会得到自己独立的一份inst_fetch,它们的符号不会泄漏到整个可执行文件中。inline:告诉编译器 “尽量把它当作内联函数展开”,并且在 GNU C 下,inline定义的函数会被当作弱符号(weak symbol)对待;即使真的生成了一个函数体,也会被标记为弱符号,允许多个同名弱符号同时存在,链接器会去重。
所以 static inline 的组合最常用于头文件——你既拿到了内联展开的效率,又不会因为每个翻译单元都有一个同名函数而产生符号冲突。
2. 只去掉 static,保留 inline:
// cpu/ifetch.h
inline uint32_t inst_fetch(vaddr_t *pc, int len) { … }
- 无
static⇒ 外部链接(external linkage) - 保留
inline⇒ 弱符号
多个翻译单元都包含这个头文件,各自生产一个弱符号版本的 inst_fetch,链接器允许对弱符号“去重”——最终只保留一个,因此不报重复定义错误。
3. 只去掉 inline,保留 static:
// cpu/ifetch.h
static uint32_t inst_fetch(vaddr_t *pc, int len) { … }
static⇒ 内部链接- 无
inline⇒ 仍旧是每个翻译单元有一份,但都是私有的
内部链接的符号互不冲突,链接时根本不会把它们当成重复定义,所以也不会报错。
4. 同时去掉 static 和 inline:
// cpu/ifetch.h
uint32_t inst_fetch(vaddr_t *pc, int len) { … }
- 无
static⇒ 外部链接 - 无
inline⇒ 强符号(strong symbol)
这时每个包含了头文件的 .c 文件都会定义一个强符号 inst_fetch,链接器看到多个同名强符号,就会报 “multiple definition of inst_fetch” 的错误。
如何正确放置一个非内联、非静态的函数定义?
如果你确实想要一个全局可见(external linkage)、又不希望把它写成 inline 或 static,就应该把函数 声明 放在头文件,把 定义 放到一个单独的 .c(或者 .cpp)文件里:
// cpu/ifetch.h
#ifndef CPU_IFETCH_H
#define CPU_IFETCH_H
#include <stdint.h>
uint32_t inst_fetch(vaddr_t *pc, int len); // 只有声明
#endif
// cpu/ifetch.c
#include "cpu/ifetch.h"
uint32_t inst_fetch(vaddr_t *pc, int len) { // 唯一的一份定义
// …
}
这样,无论多少翻译单元 #include "cpu/ifetch.h",都只会有一个 inst_fetch 的定义,链接就不会报错了。
总结:
static inline(头文件里最常用)→ 内部链接 + 弱符号,不冲突,可内联。inline(无static)→ 外部弱符号,可多次定义但去重。static(无inline)→ 内部强符号,各自独立不冲突。- 无
static、无inline→ 外部强符号,多个定义冲突。
链接错误的根本原因在于,当你把 static 和 inline 都去掉以后,inst_fetch 就变成了一个在头文件中被“定义”的、具有外部链接(external linkage)的强符号(strong symbol)。
-
你在
cpu/ifetch.h里写了uint32_t inst_fetch(vaddr_t *pc, int len) { … } -
又在两个不同的
.c文件(一个编译成inst.o,一个编译成hostcall.o)里都#include了这个头文件。 -
结果这两个 .o 文件里各自都有一份对外可见的、同名的强符号
inst_fetch。 -
链接器发现同一个可执行或库里出现了两个同名强符号,按照 C/C++ 规则这是不允许的,就报 “multiple definition of
inst_fetch” 错误了。
我们可以通过readelf -s查看符号表证明:
你关心的那些“static/inline 导致的符号属性”其实都能在 ELF 可执行文件(或者静态/动态库)里的符号表里看得到,主要体现在符号绑定(binding)字段上。
ELF 符号的 binding(绑定类型)主要有三种,你会看到对应的宏(STB_*)或者在 nm/readelf 中的字母表示:
| Binding 类型 | ELF 宏 | nm/readelf -s 中的字母 |
含义 |
|---|---|---|---|
| 本地(Local) | STB_LOCAL |
t 或 d(小写) |
符号只在本翻译单元可见(static) |
| 弱(Weak) | STB_WEAK |
W 或 V(大写) |
弱符号,允许多重定义,链接时去重(inline 导致的弱符号) |
| 全局(Global) | STB_GLOBAL |
T 或 D(大写) |
强符号,且对所有翻译单元可见(无 static、无 inline) |
static inline放头文件:如果真的产生了符号,它会是STB_LOCAL(static)和STB_WEAK(inline混用时弱化)的混合,但实践中对静态内联函数常常只做内联展开,不留符号。- 仅
inline:符号变成弱符号 →STB_WEAK→W。 - 仅
static:符号变成本地强符号 →STB_LOCAL→t。 - 既无
static也无inline:符号是全局强符号 →STB_GLOBAL→T。
在我这里真实的情况为:
-
static inline两者都去掉
inst.o符号表显示:
182: 000000000000140a 31 FUNC GLOBAL DEFAULT 70 inst_fetch -
两者都没去掉:
直接在符号表里没了,可能是因为inline把函数体给去掉了 -
inline去掉
3: 0000000000000000 27 FUNC LOCAL DEFAULT 70 inst_fetch
主要Binding字段变成LOCAL了 -
static 去掉
inst_fetch直接在符号表里没了,果然是因为inline把函数体给去掉了
Q2
-
readelf -s /home/cilinmengye/ics2023/nemu/build/riscv32-nemu-interpreter | awk 'NR>2 && $NF=="dummy"' | wc -l输出34,应该是引入了
nemu/include/common.h的.c文件个数,因为voliate可以防止编译器优化掉dummy, static可以让其变成本地强符号 -
在
nemu/include/debug.h中添加一行volatile static int dummy;加上后
readelf -s /home/cilinmengye/ics2023/nemu/build/riscv32-nemu-interpreter | awk 'NR>2 && $NF=="dummy"' | wc -l
还是输出34,这是因为在nemu/include/debug.h中其引入了common.h, 然后相当于在同一个.c文件中写了多个volatile static int dummy;
等同于:#include<stdlib.h> #include<stdio.h> volatile static int dummy; volatile static int dummy; int main() { printf("hello"); return 0; }诶?为什么不会报错?
C 语言允许重复声明,只要:- 是在相同作用域;
- 声明的类型完全一致;
- 只有一次是定义(allocation)。
-
按其所说后会报错:
In file included from /home/cilinmengye/ics2023/nemu/include/common.h:49, from src/nemu-main.c:16: /home/cilinmengye/ics2023/nemu/include/debug.h:19:21: error: redefinition of ‘dummy’ 19 | volatile static int dummy = 0; | ^~~~~ In file included from src/nemu-main.c:16: /home/cilinmengye/ics2023/nemu/include/common.h:19:21: note: previous definition of ‘dummy’ with type ‘int’ 19 | volatile static int dummy = 0; | ^~~~~这是因为重复定义了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号