并行计算架构和编程 | 缓存一致性

资料
基础知识
注意点
- 内存一致性的粒度为某个内存位置(如一个变量或一个字大小的数据)
- 缓存一致性的粒度为缓存行(cache line),所以这就有真共享和伪共享的性能问题了
内存一致性(memory consistency)
内存一致性模型(memory consistency model)是对多线程/多处理器系统中,针对不同地址的读(loads)和写(stores)操作在时间与顺序上的可允许行为所做的规范,它回答了以下两个关键问题:
- 可见性(Visibility):某个线程的写操作何时对其它线程可见?
- 顺序性(Ordering):针对同一或不同地址的多次读写,哪些操作必须保持程序中给定的先后顺序,哪些可以重排执行以换取性能?
换言之,在硬件或编译器重排序、缓存延迟与乱序执行的复杂环境下,一致性模型提供了一套契约(contract),让程序员能够预测并推理并行程序的执行结果。
缓存一致性是内存一致性的一部分、一个最基本的要求;内存一致性则更进一步,在此基础上规范多个地址之间的操作顺序与跨线程可见性
什么叫做 对多线程/多处理器系统中 针对不同地址的读(loads)和写(stores)操作?
以双重检查锁定伪代码,展示没有合适一致性模型时,程序如何出现“难以察觉”的并发错误。
// 假设 flag = false, data 变量未初始化
// 线程 A:
1: if (flag == false) {
2: data = new Object(...); // 写操作 W1
3: flag = true; // 写操作 W2
}
// 线程 B:
4: if (flag == true) { // 读操作 R1
5: use(data); // 读操作 R2
}
按直观顺序应有的行为
- A 线程先在步骤 2 完成对 data 的构造与写入(W1),再在步骤 3 将 flag 置为 true(W2)。
- B 线程在 R1 处读到 flag == true 之后,再去 R2 读取 data,应当看到已初始化的对象。
若系统遵守顺序一致性(Sequential Consistency, SC),所有操作都按某个全局串行化顺序执行,且每个线程内部按程序顺序。
在此模型下,B 不可能在看见 W2 (flag = true) 之前看到 W1 (data = new ...) 之后的任何写;也就不会出现 use(data) 读取到未初始化的 data。
在弱一致性模型或无一致性屏障时的问题
现代多核处理器和编译器为了性能,经常对不同地址的操作做重排序和乱序执行:
- 硬件重排序(StoreLoad Reordering)
- 处理器可能将对 flag 的写 (W2) 提前执行到对 data 的写 (W1) 之前,因为它们是不同地址的写。
- 这样在总线上先出现 W2,再出现 W1,但程序在 A 线程依然感知到正确顺序,因为乱序对同一线程是透明的。
- 可见性延迟
- 即使按程序顺序在处理器内部执行了 W1→W2,data 的更新可能在某些缓存或写缓冲区中滞留,尚未被另一个线程看到;而对 flag 的写,则可能迅速刷新到可见域,使 B 在线程 B 的 R1 读到 true。
如果没有内存屏障(memory barrier)或volatile/atomic操作来强制 W1→W2 的顺序和可见性,B 线程就可能在读取到 flag == true 后,立即执行 use(data),却看到 data 仍是未初始化或部分构造的状态。
什么是内存屏障(memory barrier)?
内存屏障(也称 fence、membar)是一种指令或操作,它要求 CPU 或编译器保证:凡是在屏障之前发出的内存操作,必须在屏障之后的操作之前完成;同理,屏障之后的操作不能移到屏障之前执行
现代 CPU 为了性能,会对加载(load)和存储(store)指令进行乱序执行;编译器也会对源代码的读写进行优化性重排。这种优化在单线程场景下“看不见”副作用,但在多线程或设备驱动中,会导致可见性和执行顺序出现意料之外的结果
通过插入内存屏障,可以在关键点(如锁的获取与释放、双重检查锁定、驱动对硬件寄存器的访问等)显式地划分“有序边界”,保证各线程按预期顺序看到读/写。
缓存一致性(cache coherence)
缓存一致性指在多处理器系统中,各核私有缓存对于同一内存位置的数据副本要保持统一性,即一旦某核写入更新,其他核不能再读到旧值
核心原则
- 写操作可见性:任一核对某行的写,最终必须使其它所有缓存或待访问该行的核看到更新后值
- 单一复制顺序:对同一地址的所有写操作,对所有核都应出现同样的全局顺序
写策略和分配策略
- Write-through 与 Write-back 关注的是写操作何时以及如何更新主存;
- Write-allocate 与 No-write-allocate 则规定了写未命中(write miss)时是否先将对应缓存行装载到缓存。
Write-through(写直达)
每次写操作既更新缓存,又立即写回主存或广播到下一级存储,保证主存与缓存同步。
Write-back(写回)
写操作只首先更新缓存,并将该行标记为“脏”(dirty),仅在该缓存行被替换(evict)或显式回写时,才统一写回主存。
Write-allocate(写分配)
在写未命中时,先从主存(或更低级缓存)加载整个缓存行到本地缓存,再在缓存中执行写操作。
No-write-allocate(写不分配)
在写未命中时,不将缓存行加载到缓存,而是直接写回主存或下一级存储。
缓存一致性
大多数笔记内容这位大佬已经写好了:并行计算(三):缓存一致性
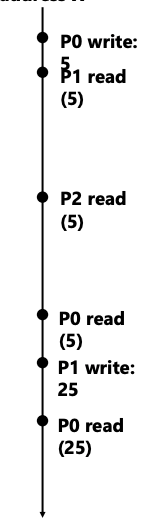
例如不遵守缓存一致性会出现什么问题?
我再其基础上再增加一些内容,使得更好理解。
内存系统一致性定理(通常也称为顺序一致性定理)指出,只要针对每个内存位置都能找到一个使得所有处理器操作满足以下三个条件的全局串行顺序,那么该系统即满足顺序一致性(Sequential Consistency, SC):
对于任意并行执行,如果存在一个全局操作序列 S,使得
- S 中的操作在每个处理器内遵循其程序顺序;
处理器P对地址X的读,在P对地址X的写之后,应该返回P的写的值(假设在这之间没有其他处理器对X写)。
- S 给出对每个单独内存位置的总序(即每地址的所有读写在 S 中可比较);
在假设的全局串行序列 S 中,针对每一个地址的所有读写操作都能排成一条线性序列——也就是任意两次对同一地址的访问,在 S 里都有确定的先后关系。
- 每次读操作返回在 S 中紧邻它之前的最近一次写入的值
即对同一地址的写是串行化的:任何两个处理器对地址X的两个写都被所有处理器以相同的顺序观察。(例如:如果数值1然后2被写到地址X,处理器观察不到X在数值1之前有数值2),这被称为写入序列化
上述定理可被证明
目前我想要介绍的是基于Snooping(总线监听)的一致性实现,利用共享总线或互连广播机制,让每个缓存控制器实时“监听”总线上所有读写事务,并对感兴趣的地址执行失效或更新操作,以保证所有缓存对同一地址都能看到一致的数据副本
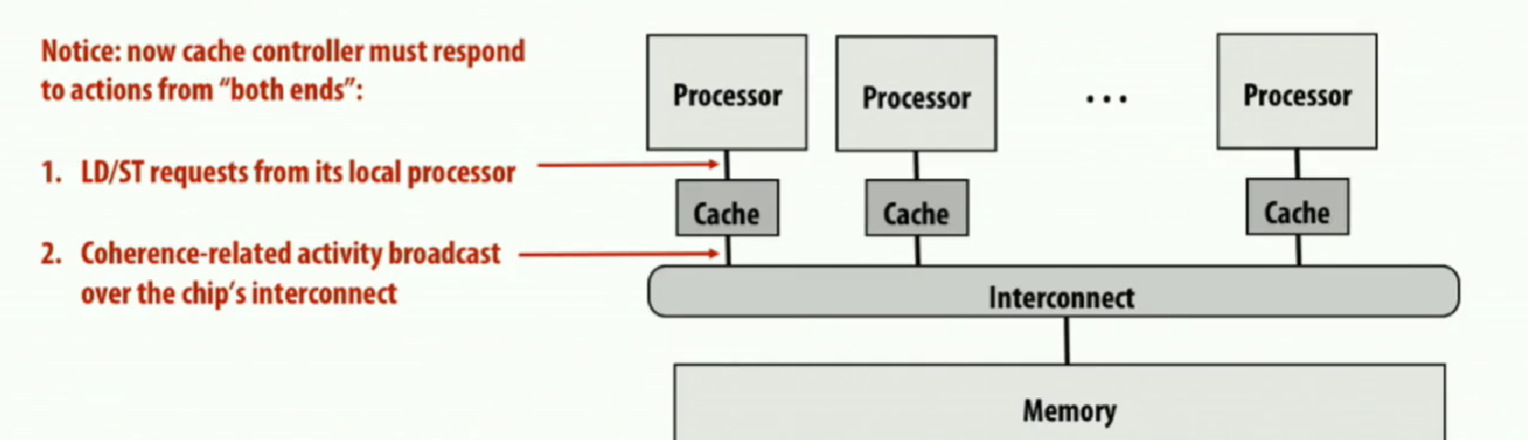
每个缓存都包含一个“侦听器”(snooper),该逻辑会监控总线上的所有事务(读 Miss、读取独占、写 Miss 等)
当出现针对某缓存行的总线事务时,所有缓存根据自己该行的状态(如 Modified/Shared/Invalid)采取相应动作:要么提供数据并降级,要么将行失效(invalidate),要么更新该行
基于“写直达 + 无写分配”(write‐through & no‐write‐allocate)的两态缓存一致性协议
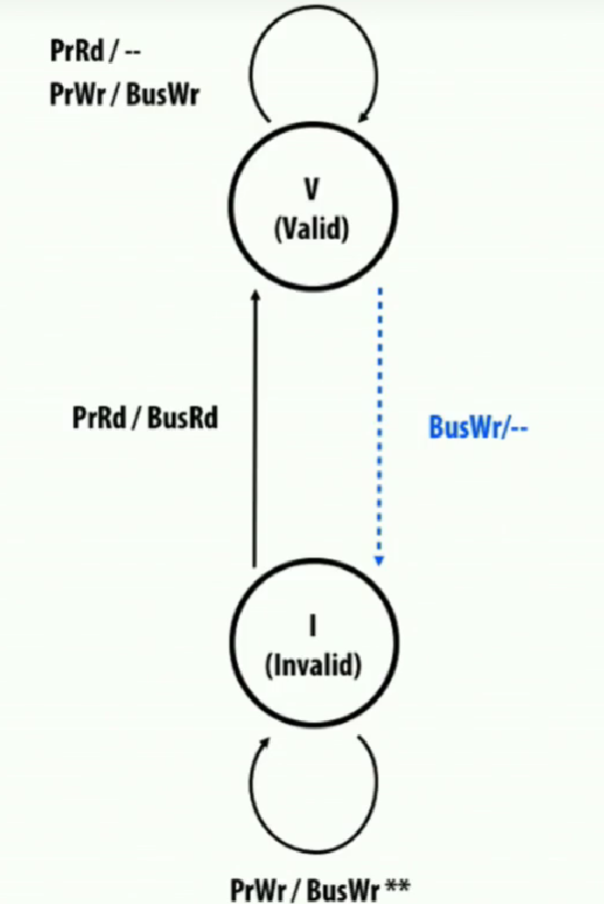
上图为某地址在缓存行的状态转换图:
-
节点状态
- V (Valid):本地缓存中有且只有最新的(或至少是合法的)拷贝。
- I (Invalid):本地缓存中该行无效,不可直接读/写。
-
驱动
- X/Y 表示if X then Y
- PrRd = 处理器发起读请求, PrWr = 处理器发起写请求
- BusRd = 在总线上广播读请求(向其他缓存或内存取数据), BusWr = 在总线上广播写请求(写回/更新内存或通知其他缓存失效)
- 某一列是 “–”,代表这个操作不需要走总线,比如读命中时就不发 BusRd。
- 蓝线表示因其他处理器而传递过来的信息
需要注意I节点上的循环,PrWr / BusWr 即写未命中,由于 “无写分配” 策略,不把数据调入缓存;处理器直接通过 BusWr 更新主存/广播写,仍然是 Invalid。
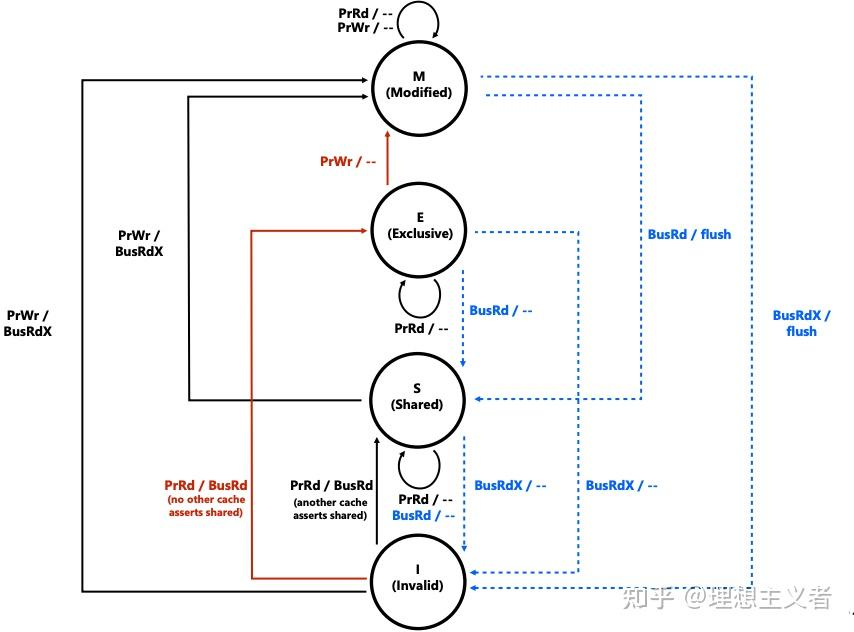
MSI 协议
MSI(Modified–Shared–Invalid)协议是最基本的缓存一致性协议之一,广泛用于对称多处理器(SMP)系统中,它通过定义三种状态来管理每个缓存行的读写权限和一致性:
- Modified(修改)/ Exclusive(独占):缓存行在本地被修改过,与主存数据不一致,且是唯一持有者。
- Shared(共享):缓存行未被修改,可存在于多个缓存中,且与主存一致。
- Invalid(无效):缓存行不可用,必须重新从主存或其他缓存获取。
A line in the ‘exclusive’ state can be modified without notifying the other caches
独占态(E 或者 M)意味着你是这条缓存行的唯一持有者,其他缓存都没有这行的有效拷贝。
因此,你可以在本地直接修改它(写回缓存或写回主存),而不必每次写都在总线上广播失效或更新消息。
Processor can only write to lines in the exclusive state
为了防止多个缓存同时悄悄写同一行造成冲突,一致性协议规定:只有当本地缓存行处于独占态,处理器才能对它执行写操作。
如果是 Shared(共享)态或 Invalid(无效)态,你先得把它升级到独占态才能写。
So they need a way to tell other caches that they want exclusive access to the line, When cache controller snoops a request for exclusive access to line it contains — It must invalidate the line in its own cache
当本地处理器要写某行但该行尚未在本地处于独占态时,就要发一个总线请求(通常是 BusRdX / BusUpgr)。
这个请求会告诉所有其他缓存:“我想要这行的独占权限,请你们把你们的拷贝失效(invalidate)。”
当某个缓存控制器监听到别的核发来的“独占访问请求”(BusRdX/BusUpgr)针对自己也拥有的那条行,就必须把该行从 Shared(或 Exclusive)降级到 Invalid,交出独占权。
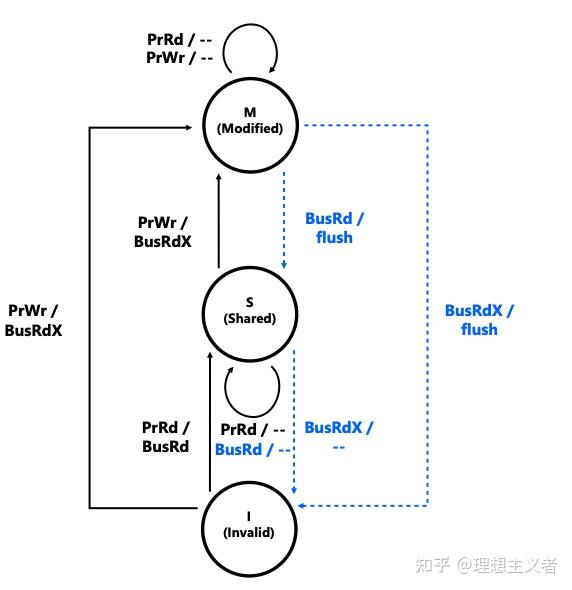
-
BusRd(Bus Read)是在处理器本地读未命中(PrRd miss)时发起的总线广播,请求从其他缓存或主存获取该缓存行的数据
-
BusRdX(Bus Read Exclusive,又称 Read-For-Ownership, RFO)是在处理器本地写未命中(PrWr miss)时发起的总线请求,它不仅获取缓存行数据,还使其它所有缓存失效,以便本核取得独占写权限
发送 BusRdX 时,所有监听到该事务的缓存若持有该行(Shared 或 Modified),都必须Invalidate(置 Invalid)自己的副本;若持有 Modified,还需先执行 Flush,将脏数据写回/转发给请求者。
请求者接收到数据后,将该行装入本地缓存并置为 Modified 状态。
- Flush(或 FlushOpt)是指将缓存中 Modified 状态的行写回或转发到总线的操作,用于满足他核的 BusRd 或 BusRdX 请求,并使主存或请求者获得最新数据
当某缓存处于 Modified 状态并 snoop 到他核的 BusRd,需先 Flush 数据到总线,再将自身状态由 Modified 降级为 Shared。
当 snoop 到他核的 BusRdX,则需 Flush 数据并降级为 Invalid。
NESI 协议
在 MSI 协议下,对于我们最常见的“先读再写”这一访问模式,往往要经过两次总线事务才能把缓存行状态从无到可写,带来不必要的开销
为什么“先读后写”很常见?
- 初始化或累加:程序里常常先读取一个变量的旧值,再在此基础上做加减修改,然后写回。
- 读取-修改-写回(RMW)操作:像 x = x + 1、x *= 2、x |= mask 这些,都属于先读后写。
- 编译器生成的代码:很多赋值、累加、结构体字段更新,底层都翻译成 Load(读)后跟 Store(写)。
MSI 下的两次事务
-
事务 1:BusRd (I → S)
缓存最开始是 Invalid 状态,处理器第一次读 miss,就要发一条 BusRd 把数据从内存(或其他缓存)拉到本地,并把状态置为 Shared。 -
事务 2:BusRdX (S → M)
随后处理器要写这条数据,发现它只是 Shared(或甚至还是 S),就得发一条 BusRdX(读并获取独占权限),让其他缓存失效,然后才能改成 Modified 并真正写入。
→ 两次总线往返,才能完成一个“先读再写”操作。
即使没有跨核共享也会发生
了解决这一问题可以增加额外的状态E(exclusive clean):
- 唯一拥有:在 E 状态下,该缓存行不在系统中任何其他缓存中存在(即它是“独占”的)。
- 未修改(Clean):缓存行内容与主存一致,因此无需写回主存即可释放或再次共享
- 本地写无总线事务:当本地处理器在 E 状态行上执行写操作时,它可直接将状态切换到 M(Modified)并更新缓存,不需要发送 BusRdX 或 BusUpgr 请求

 浙公网安备 33010602011771号
浙公网安备 33010602011771号