CSAPP | 优化程序性能

优化程序性能
- 消除不必要的工作
- 循环不变式外提
- 减少循环函数调用
- 减少循环访存
- 理解编译器的能力和局限性
- 编译器只对程序进行保守的,安全的优化
- 编译器会假设最坏的情况,若优化在此种情况下可能导致程序结果改变,编译器不会执行优化
- 如指针,指针可能同时指向同一个地址
- 在超标量乱序执行的背景下并行优化程序
- 在超标量乱序执行的背景下,针对循环,我们普通地改进代码就可以做到指令级的并行
- 理解CPU模型和CPE(Cycles per Element)指标
- 利用图形数据流理解处理器对指令的执行形象化,预测程序性能; 确认关键路径,即在循环反复执行过程中形成的数据相关链
表示程序性能
CSAPP P345
处理器活动的顺序是由时钟控制的,时钟提供了某个频率的规律信号,“4GHZ”表示处理器运行时钟运行频率为每秒\(4*10^9\)个周期。 用时钟周期来表示,度量值表示的是执行了多少条指令,而不是时钟运行得有多快。
引入度量标准每元素的周期数(CPE),其对执行重复计算的程序来说是很合适的,帮助我们在更加细节的级别上帮助迭代程序的循环性能。
CSAPP P359
对于Intel Core i7 Haswell参考机有8个功能单元,编号为0~7
0. Integer arithmetic, floating-point multiplication,
integer and floating-point division, branches
1. Integer arithmetic, integer multiplication,
floating-point addition, floating-point multiplication
2. Load, address computation 3. Load, address computation
4. Store 5. Integer arithmetic
6. Integer arithmetic, branches 7. Store address computation

左侧为整数运算,右侧为浮点数运算
Latency表明执行时间运行所需的时钟周期总数
Issue表明两次运算之前间隔的最小周期数
Capacity表明同时能发射多少个这样的操作
- Capacity>1 是因为有多个功能单元
- 发射时间为1的功能单元被称为完全流水化的:每个时钟周期可以开始一个新的运算。
- 表达发射时间的一种更常见的方式是指明这个功能单元的最大吞吐量,定义为发射时间的倒数,对于一个容量为C,发射时间为I的操作老说,处理器可能获得的吞吐量为每时钟周期\(C/I\)
依据CPE指标,以延迟和吞吐量两个角度分析,得到如下性能:

- 延迟界线给出了任何必须按照严格顺序完成合并运算的函数所需的最小CPE值
- 吞如量界限给出了CPE的最小界限
对于整数加分吞吐量CPE,按照定义本应该是\(1/4=0.25\), 但是两个加载单元限制了处理器每个时钟周期最多读取两个数据值,从而使得吞吐量界限为0.50
循环的数据流图和关键路径
除了书中复杂的,要依据汇编代码生成数据流图查看关键路径外,我想要用一种习题中出现的简单方法(习题解答P397 5.8)说明数据流图和关键路径。
关键路径,即在循环反复执行过程中形成的数据相关链;非关键路径可以在超标量乱序执行的背景下提前执行
书中P365和P366习题5.5和5.6(注意在分析数据流图中我们着重查看对数据运行操作,忽略掉了load,store,分支等):
double poly(double a[], double x, long degree)
{
long i;
double result = a[0];
double xpwr = x;
for (i = 1; i <= degree; i++) {
result += a[i] * xpwr;
xpwr = x * xpwr;
}
return result;
}
double poly2(double a[], double x, long degree)
{
long i;
double result = a[degree];
for (i = degree - 1; i >= 0; i--)
result = a[i] + x * result;
return result;
}
poly函数CPE为5.0,poly2函数的CPE为8.0,要求我们结合迭代中的数据相关分析原因:
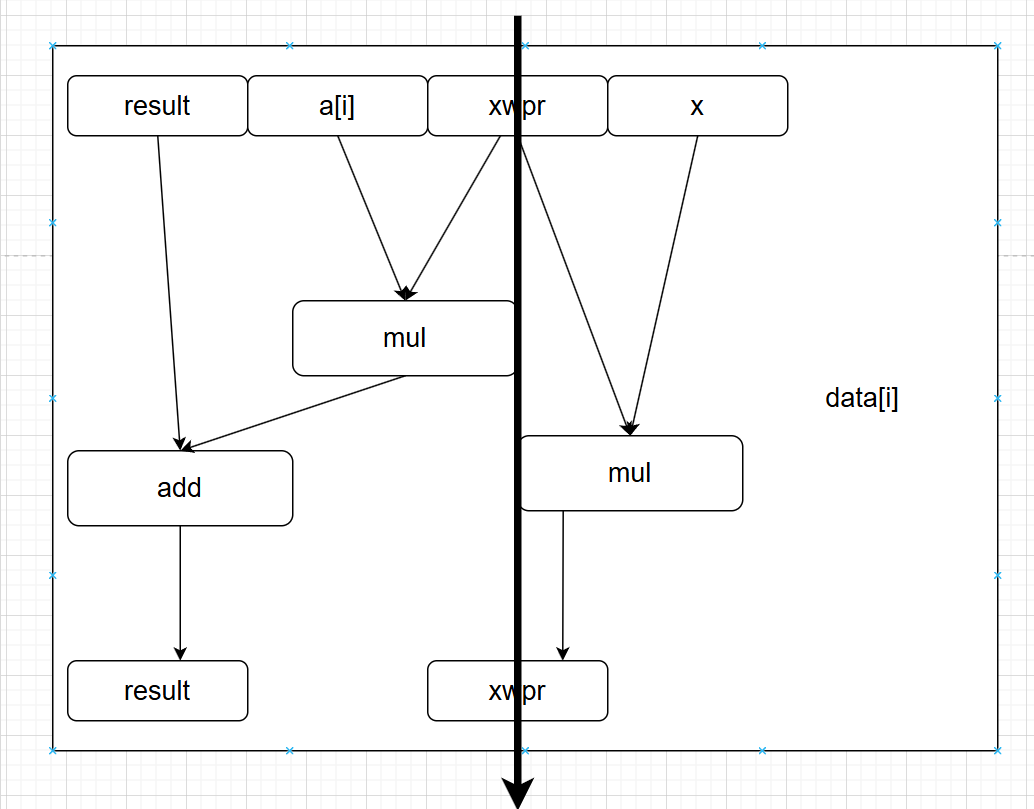
对于形成循环的代码片段,我们可以将访问到的寄存器分为四类:
- 只读:这些寄存器只用作源值。如上图的a[i]和x
- 只写:这些寄存器作为数据传送操作的目的。
- 局部:这些寄存器在循环内部被修改和使用,迭代与迭代之间不相关。
- 循环:对于循环来说这些寄存器既作为源值,又作为目的,一次迭代中产生的值会在另外一次迭代中使用。如上图的result和xwpr
上图中xwpr形成关键路径,其mul延迟为5个cycles.
为啥不是result形成关键路径,那边不是在执行add之前还要等待mul完成吗?
因为只要xwpr那里路径完成就可以开始下一个data计算,注意我们是超标量乱序执行,我们无需等待其余路径上计算完成才开始下一个数据的计算。
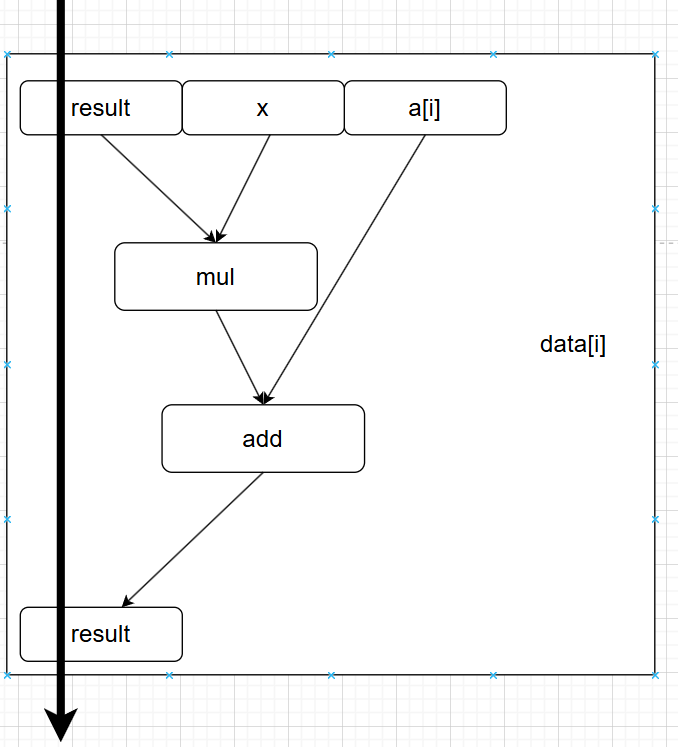
可以看到对于这条result是唯一的路径,也是关键路径,需要mul和add,即8个时钟周期才能处理一个data
循环展开
- 减少计算无关(如循环对于分支的判断,循环内的索引等)
- 减少关键路径中循环次数。
-
对于\(k*1\)循环展开本质上是将k个data在一次循环中处理;
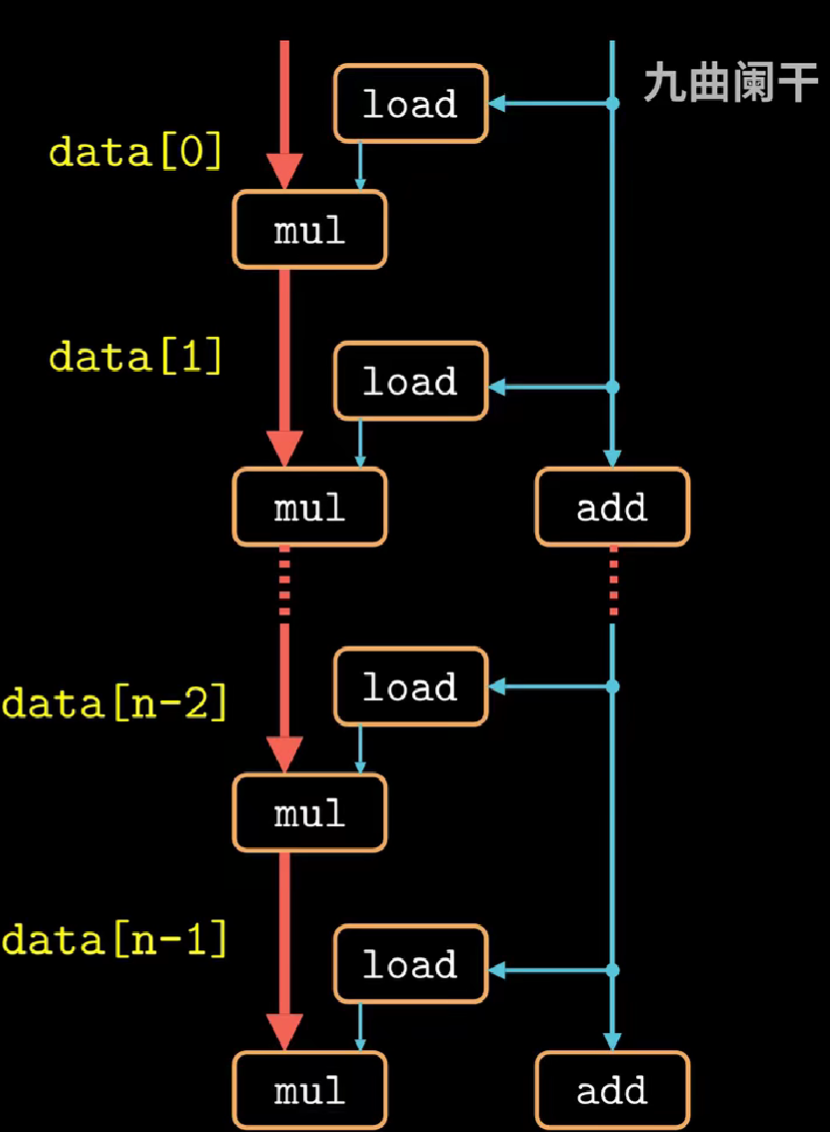
-
对于\(k*k\)循环展开本质上是将k个data在一次循环中处理,同时利用多处理单元,形成k条关键路径并行处理数据。
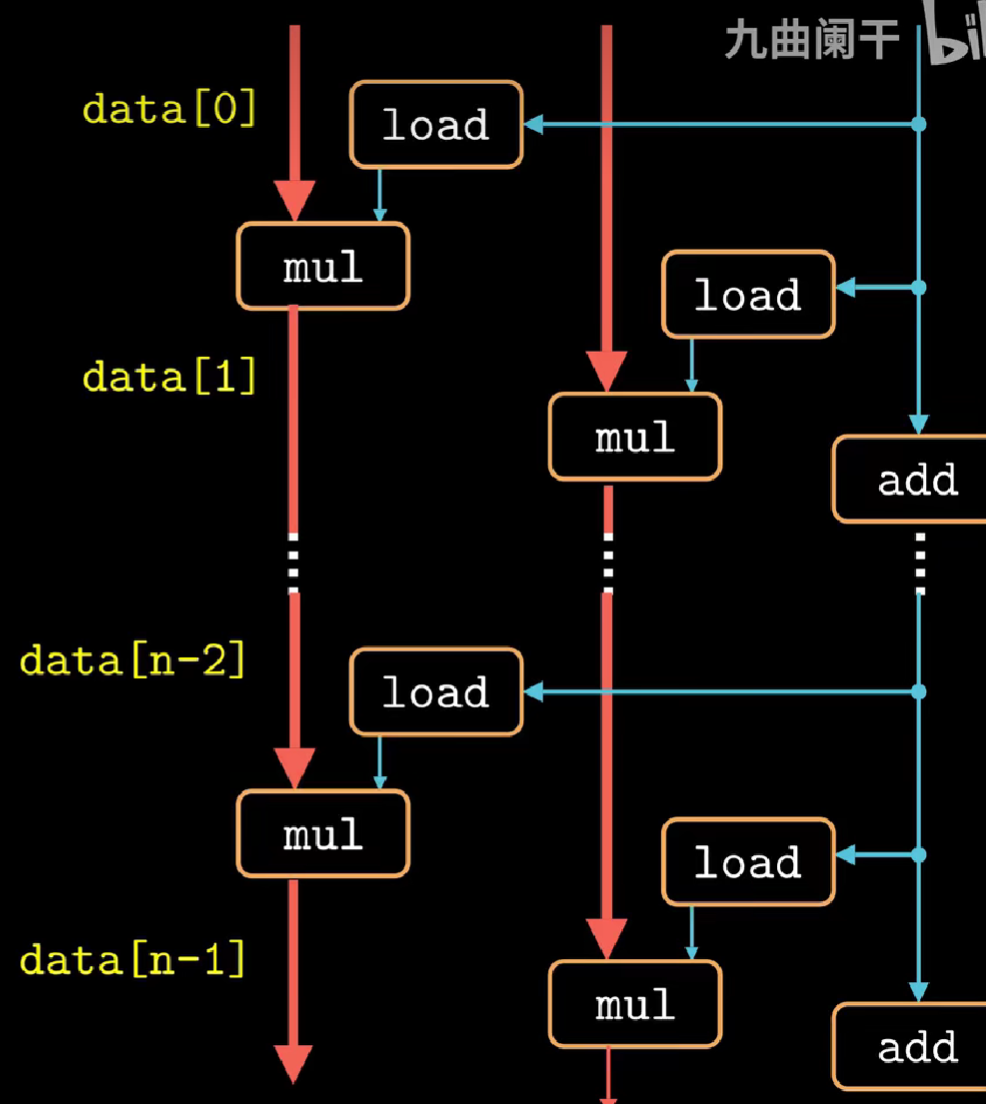
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号