性能分析 | Memory Bound

基于LMbench测试LLC
工具与术语
-
LLC延迟(Last Level Cache Latency) 是指处理器访问最后一级缓存(通常是L3缓存)中的数据所需的时间延迟。
-
LMbench
LMbench是Intel旗下的内存测试工具,其主要功能有:- 带宽测评(读取缓存文件、拷贝内存、读/写内存、管道、TCP)
- 延时测评(上下文切换、网络、文件系统的建立和删除、进程创建、信号处理、上层系统调用、内存读入反应时间)等功能。
LMbench包含子测试lat_mem_rd,可用于测试在指定数据集和步长下的内存读取延迟:
./bin/lat_mem_rd [-P <parallelism>] [-W <warmup>] [-N <repetitions>] [-t] len [stride...]
理论
基于CSAPP中的知识, 我们知道内存与缓存L3之前,L3与L2,L2与L1...这些不同层次之间都是基于块为单位进行数据交流
在内存与缓存之间,这里的块即是我们的cache line,缓存行:
- 在计算机缓存层级(L1、L2、L3)之间,每次数据传输的最小单位是缓存行(Cache Line)
- 现代主流CPU(如x86、ARM)的缓存行大小通常为 64字节(部分场景可能为128字节或32字节,但64字节最常见)。
实践
如下为CSAPP中测试出存储器上的代码:
long data[MAXELEMS]; /* The global array we'll be traversing */
/* test - Iterate over first "elems" elements of array "data" with
* stride of "stride", using 4 x 4 loop unrolling.
*/
int test(int elems, int stride)
{
long i, sx2 = stride*2, sx3 = stride*3, sx4 = stride*4;
long acc0 = 0, acc1 = 0, acc2 = 0, acc3 = 0;
long length = elems;
long limit = length - sx4;
/* Combine 4 elements at a time */
for (i = 0; i < limit; i += sx4) {
acc0 = acc0 + data[i];
acc1 = acc1 + data[i+stride];
acc2 = acc2 + data[i+sx2];
acc3 = acc3 + data[i+sx3];
}
/* Finish any remaining elements */
for (; i < length; i+=stride) {
acc0 = acc0 + data[i];
}
return ((acc0 + acc1) + (acc2 + acc3));
}
/* run - Run test(elems, stride) and return read throughput (MB/s).
* "size" is in bytes, "stride" is in array elements, and Mhz is
* CPU clock frequency in Mhz.
*/
double run(int size, int stride, double Mhz)
{
double cycles;
int elems = size / sizeof(double);
test(elems, stride); /* Warm up the cache */
cycles = fcyc2(test, elems, stride, 0); /* Call test(elems,stride) */
return (size / stride) / (cycles / Mhz); /* Convert cycles to MB/s */
}
- test函数所做的事情为以stride的步长将大小为size的data数组的相应元素求和,其中的细节为:
- 第一个循环采用4x4循环展开加速求和
- 第二个循环将剩余元素累加到变量acc0中
- stride的单位为8字节
- run函数所做的事件为调用test函数进行读吞吐量测试,其中细节为:
- 先调用test进行Warm up让缓存先充满元素
- 后再调用test开始真正的测试
在L1 cache size = 32KB, L2 cache size = 256KB, L3 cache size = 8MB, cache line restore size = 64B情况下,结果为:
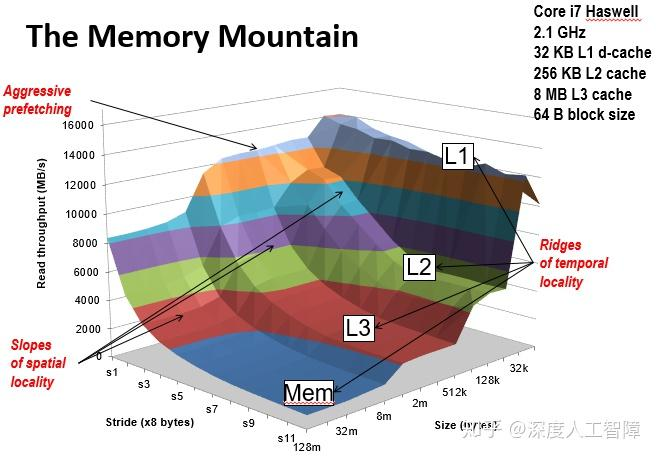
以LLC延迟为例,取极限情况,当size == L3 cache size, 即8MB时。即使步长为1,运行时也会不可避免地到L3 cache中多次取数据。
当stride == L2 cache size / 8,即262144时。即使size = 256KB,必然L1,L2均无法命中,会到L3 cache中取数据。
所以假设cache硬件情况与如上相同,可以设置size大小为L3 cache size,stride为256KB,用lat_mem_rd测试出LLC延迟(需要设置-W参数用于Warm up)
优化内存访问
显示内存预取
主要功能和目的:降低缓存未命中惩罚,预先将可能数据内存位置引入缓存
实现的底层机制:
- 硬件预取。硬件预取器通过对重复内存访问模式发起预取请求来帮助隐藏内存访问延迟。
- 当数据访问模式太复杂无法预测时,硬件预取器就会失败。软件开发人员对此无能为力
- OOO 执行(Out of Order 乱序执行)。OOO 引擎向前看 N 条指令,并提前发出加载指令,以允许平滑执行未来将需要此数据的指令。
- 它成功的唯一衡量标准是它通过提前调度加载隐藏了多少延迟。
for (int i = 0; i < N; ++i) {
size_t idx = random_distribution(generator);
int x = arr[idx]; // cache miss
doSomeExtensiveComputation(x);
}
- 硬件预取器不可能预测,因为每次加载都进入内存中一个完全新的位置。
- 从知道内存位置的地址(从函数 random_distribution 返回)到需要该内存位置的值(调用 doSomeExtensiveComputation)的时间间隔称为 预取窗口。在这个例子中,由于预取窗口非常小,OOO 引擎没有机会提前发出加载指令。
为了隐藏缓存未命中延迟,我们需要将其与 doSomeExtensiveComputation 的执行重叠。如果我们管道化(流水线华)随机数生成并在下一次迭代中开始预取内存位置,就可以实现这一点。
size_t idx = random_distribution(generator);
for (int i = 0; i < N; ++i) {
int x = arr[idx];
idx = random_distribution(generator);
// prefetch the element for the next iteration
__builtin_prefetch(&arr[idx]);
doSomeExtensiveComputation(x);
}
__builtin_prefetch() 是 GCC 提供的一个内置函数,它向 CPU 发出预取指令,提示硬件提前将指定地址的数据加载到缓存中。这是一种性能优化手段,主要用于隐藏内存访问延迟
- 当你调用 __builtin_prefetch(&arr[idx]) 时,程序不会立刻使用返回值或阻塞等待数据到达,而是向 CPU 提供一个“提示”. 当后续真的访问这个数据时(例如 int x = arr[idx]),数据很可能已经在缓存中,从而降低内存访问延迟,提升性能。
- 预取指令是一条非阻塞的提示,不会中断当前的执行流,也不会等待数据加载完成。它允许 CPU 在后台异步加载数据,利用执行过程中其它指令的空闲时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号