CPU性能分析方法论

前置知识
指令流水线与分支预测
指令流水线(英语:Instruction pipeline)是为了让计算机和其它数字电子设备能够加速指令的通过速度(单位时间内被执行的指令数量)而设计的技术。
流水线在处理器的内部被组织成层级,各个层级的流水线能半独立地单独运作。每一个层级都被管理并且链接到一条“链”,因而每个层级的输出被送到其它层级直至任务完成。
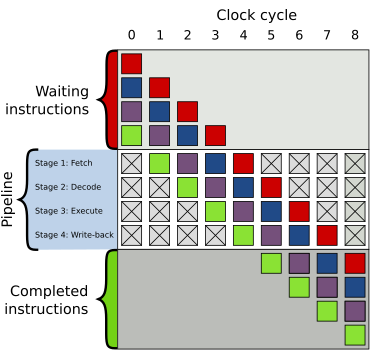
上述说的流水线级数在此图上为4。
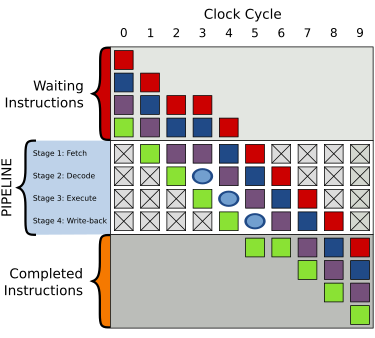
条件分支指令通常具有两路后续执行分支。即不采取(not taken)跳转,顺序执行后面紧挨JMP的指令;以及采取(taken)跳转到另一块程序内存去执行那里的指令。是否条件跳转,只有在该分支指令在指令流水线中通过了执行阶段(execution stage)才能确定下来。
如果后来发现分支预测错误,那么流水线中推测执行的那些中间结果全部放弃,重新获取正确的分支路线上的指令开始执行。在分支预测失败时浪费的时间是从取指令到执行完指令(但还没有写回结果)的流水线的级数。
分支预测不同于“分支目标预测”(Branch target predictor)。后者是指对指令高速缓存中的内容,检测出其中的条件跳转指令与无条件跳转指令,然后为指令高速缓存预装入(prefetch)相应的跳转目标代码块。
即分支预测投机的指令是真正会执行的。
NUMA(Non-Uniform Memory Access)
上述资料讲解了UMA(Uniform Memory Architecture)的特点与不足,从而引出NUMA。
同时讲解了CPU上socket,core,thread,node重要概念。
lscpu命令查看socket,core,thread,nod相关信息
numactl -H命令查看NUMA相关信息(数量,布局等)
博客2用实验证明了NUMA绑核及其重要性
博客2,3 解释到像如top(1)这样的性能分析工具中显示的%CPU指标当其值较高时,并不能代表处理器达到了瓶颈,而是表明处理器已经在各尽所能了。
正如博客3中的这张图,有可能CPU是被阻塞等待内存I/O:
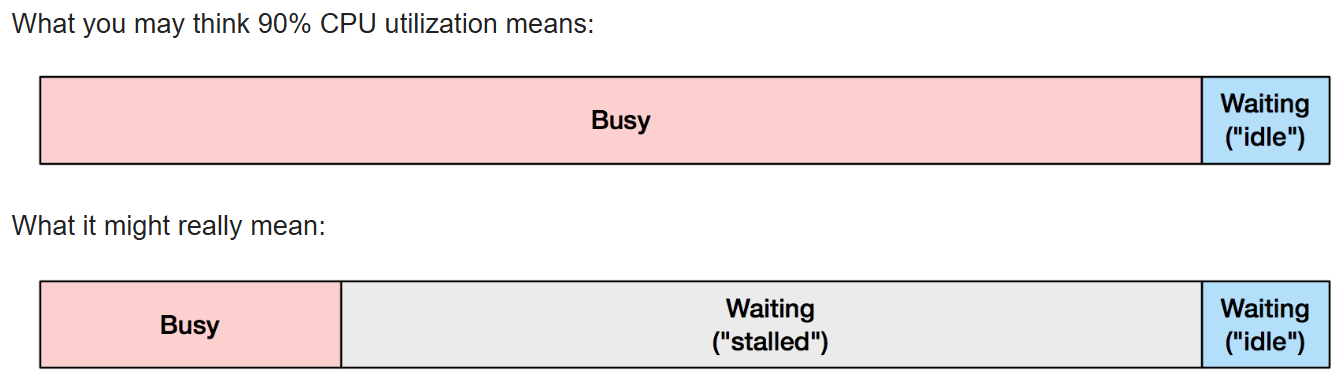
我们若真正想要看到处理器是否达到极限,应该去看IPC(instructions per cycle )这个指标。perf stat命令可以做到这一点。
现代处理器一般最高速度是 IPC 为 4.0。这也称为 4 宽,指的是指令提取/解码路径。这意味着,CPU 可以在每个时钟周期退出(完成)四条指令。
如果使用perf stat观察到如下内容,则说明CPU在运行某程序上只使用了它0.78 ÷ 4 × 100% = 19.5%的"力气":
1,118,336,816,068 instructions # 0.78 insns per cycle (75.01%)
TMA基本概念
TMA是什么?
Top-down Microarchitecture Analysis,是对CPU性能瓶颈进行分析和优化的方法论。
-
Top-down是基于事件指标的层次组织。
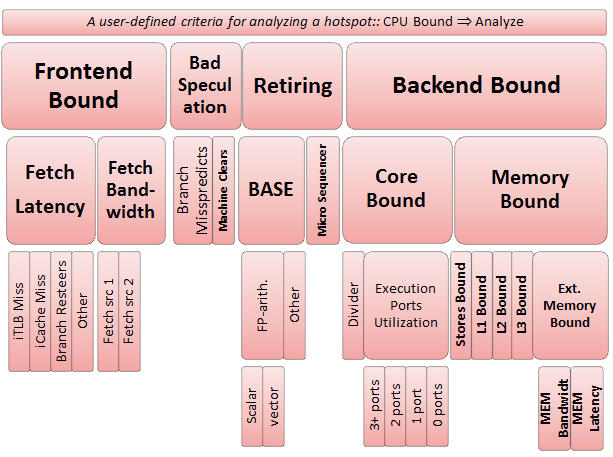
从上图可以初步窥见,所谓事件是像缓存未命中事件、分支预测失败等影响CPU性能的事情。
-
这套方法论的计算基于流水线资源,通过计算占据流水线资源的百分比来评定事件的性能。
数据来源来自PMUs(片上性能监控单元),PMUs 是 CPU 内核中的专用逻辑块,用于记录计算系统上发生的特定硬件事件。 这些事件可能是缓存遗漏或分支错误预测。 我们可以观察到这些事件,并将它们组合起来创建有用的高级指标,如 CPI 。
基础概念:
-
前端和后端(the Front-end and the Back-end)
-
the Front-end:前端负责获取架构指令中表示的程序代码,并将其解码为一个或多个称为微操作(micro-ops (uOps)),uOps 在称为分配(Allocation)的过程中被馈送到后端。
-
the Back-end: 分配后,后端负责监视 uOp 的数据操作数何时可用,并在可用的执行单元中执行 uOp。
-
-
retire
uOp执行完成称为退休(retirement),此时 uOp 的结果被提交到架构状态(CPU 寄存器或写回内存)。
若发生了分支预测错误,因为分支预测投机的指令最多到达执行阶段,不会提交,所以这种特殊情况就不叫做retirement了。 -
pipeline slot(流水线槽)
一个流水线槽代表处理一个uOp所需的硬件资源。
TMA分析原理
总体思路大纲:
TMA解决的问题就是如何求得CPU瓶颈。
首先看CPU流水线总体上有多少时间没有真正在处理计算任务(流水线利用率)。
继而观察没有处理计算任务是因为各方面没有协调好导致流水线空转(Stalled),还是虽然没有空转(Non-stalled)但却没有进行实际的计算。
然后针对空转,看看是前端的原因还是后端的原因。然后再具体看是前/后端哪一个具体事件导致的空转。
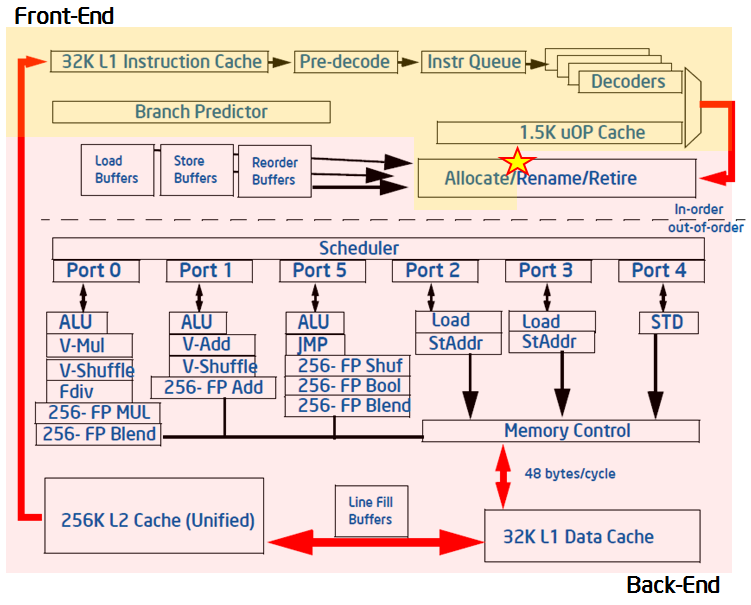
上述流水线视图的虚线划分依据为是否顺序执行。黄色区域表示前端,粉红区域表示后端。
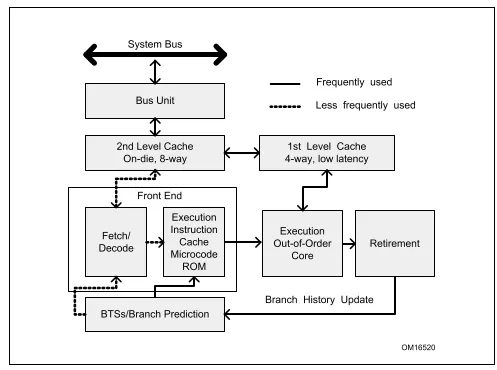
或许下面的图更简洁一些:
在最近的Intel微架构中,流水线的前端每个周期可以分配4个uOps,而后端每个周期可以执行完成4个uOps。
假设对于每个CPU内核,在每个时钟周期上,有四个流水线槽可用。
在任何周期中,流水线槽可能是空闲的,也可能是被用uOp使用的。如果一个槽位在一个时钟周期内是空闲的,这种现象被归于停滞(stall)。
流水线槽的状态(如是否空闲)在分配点(在上图中用星号标记)处获取,这里uOps离开前端并到达后端。
下一步需要对流水线槽进行分类,确定是流水线的前端部分还是后端部分造成了停滞。
-
Front-End Bound slot: 如果停滞是由于前端无法用uOp填充槽造成的,那么在此周期它将被归类为前端绑定槽(Front-End Bound slot),这意味着性能受到前端绑定类别下的某些瓶颈的限制。
-
Back-End Bound:如果前端已准备好uOp,但由于后端尚未准备好处理它而因此无法交付它,则空流水线槽将被分类为后端绑定(Back-End Bound)。 后端停滞(backend stalls)通常是由后端耗尽某些资源(例如,负载缓冲区)造成的。
但是,如果前端和后端都停止了,那么插槽将被归类为后端。 这是因为,在这种情况下,修复前端的停滞很可能对应用程序的性能没有帮助。 后端的瓶颈是限制性的,它需要在修复前端的问题前先被移除。
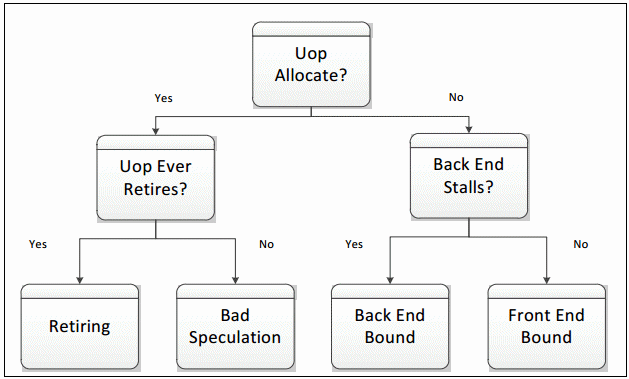
上述内容可以这么想象:
在一个流水线工厂中,一个CPU Core相当于一台流水线机器+一个工人。
一个CPU Core中有n个执行单元,相当于一个工人有n双手。
在每次CPU时钟周期,老板会派发4个任务(uOp)给工人。
工人每次CPU时钟周期也需要完成4个任务(uOp)。
工人完成任务需要资源部件(pipeline slot),所以每次CPU时钟周期流水线机器都会出现4个资源部件(pipeline slot)给工人完成任务用,哪个资源部件(pipeline slot)用于哪个任务(uOp)是老板指定的。
资源部件(pipeline slot)在工人的工作下转化为了成果,当然还有没有转化为成果的现象,我们称这种现象为停滞(stall)。
出现这种现象的原因有:老板的问题(Front-End Bound slot for this cycle),工人的问题(backend stalls)。老板的问题出在没有发出任务与资源部件对应。工人的问题出在工人未能将资源部件(pipeline slot)转化为成果
TMA 指标和计算原理
指标就是占用pipeline slot的百分比(流水线资源利用率)
如何判断性能瓶颈?
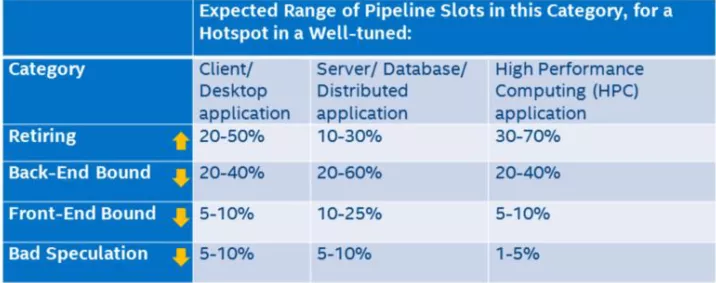
若超过上述指标范围的则需要注意
优化指导
hotport(热点),所谓热点即是占用CPU时间周期较长的程序/函数/指令/...
可参考此博客
优化后端
大多数未调优的应用程序都是后端瓶颈的。 解决后端问题通常与解决延迟源有关,延迟源会导致执行完成所需的时间超过必要时间。
后端停滞可以再细分为两类:内存瓶颈和内核瓶颈子指标。
-
内存瓶颈类别中的停滞有与内存子系统相关的原因。 例如,缓存未命中和内存访问可能导致内存瓶颈的停滞。
-
内核瓶颈停滞是由于在每个周期中对CPU中可用执行单元的使用没有达到最佳状态造成的。槽只有在它们被停止并且没有未完成的内存访问时才被归类为内核瓶颈
大多数后端瓶颈问题都属于内存瓶颈类别。核心瓶颈在后端瓶颈中通常不太常见。
内存瓶颈类别下的大多数指标确定了从L1缓存到内存的内存层次结构的那个级别是瓶颈。一旦后端停止,指标将尝试将负载的停止归因于特定级别的缓存或正在运行的存储。如果热点瓶颈在给定的级别,这意味着它的大部分数据都是从该缓存或内存级别检索的。
优化前端
流水线的前端部分成为应用程序的瓶颈并不常见。 然而,在某些情况下,前端可以在很大程度上造成机器停滞。
提高前端性能通常与代码布局和编译器技术有关。分支代码或占用空间大的代码(代码的footprint大)很可能导致前端停滞
将前端停滞可以再细分为两类:前端延迟和前端带宽。
-
前端延迟报告一个周期的范围内前端没有处理uOps,而后端已经准备好使用它们的周期。
-
前端带宽报告处理数量小于4个uOps的周期,这意味着对前端能力的低效率使用。
Bad Speculation类别调优
实践工具
参考博客
On-CPU and Off-CPU Performance Bottleneck Analysis
基础知识
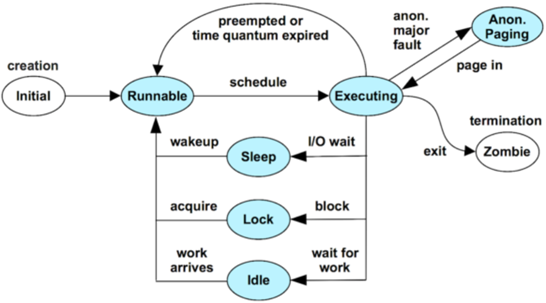
what is on-CPU and what is off-CPU?
-
on-CPU: 线程正在真正占用 CPU 核心执行指令的时间。包括用户态和内核态下执行 CPU 指令的所有时间。
-
off-CPU: 线程没有占用 CPU,而是在等待某些事件或资源的时间,包括:
- I/O 等待:磁盘、网络、数据库操作等
- 锁等待:互斥锁、读写锁、条件变量等同步原语
- 调度延迟:线程被抢占或阻塞在调度队列上
- 睡眠/延时:调用 sleep、nanosleep、定时器等
Linux perf, sysstat, perf-tools这些性能分析工具的区别是什么?
下面简要说明 sysstat、Brendan Gregg 的 perf-tools(通常指其开源脚本集)与 Linux 自带的 perf 工具集三者的定位、原理和使用场景差异与关联。
1. sysstat
-
组成
- 常见命令:
sar、iostat、mpstat、pidstat、dstat(虽不是 sysstat 包的一部分,但用途相似)等。
- 常见命令:
-
原理
- 基于
/proc、/sys等接口定期采样系统统计数据,比如 CPU 利用率、IO 统计、内存、上下文切换、进程级指标等。 - 不依赖 CPU 硬件性能计数器(PMU),主要统计操作系统层面的资源使用。
- 基于
-
特点
- 长时间/历史数据:可以通过
sar将系统运行期间的数据定期采集并保存至文件,用于后续趋势分析。 - 低门槛:无需特殊硬件支持,普遍适用于大多数 Linux 发行版。
- 粒度有限:多为秒级或更粗粒度采样,不适合对单个函数或指令级热点定位。
- 长时间/历史数据:可以通过
2. Linux perf(perf_events)
-
组成
- 自带于较新内核的
perf工具集,子命令如perf stat、perf record、perf top、perf trace等。
- 自带于较新内核的
-
原理
- 利用 Linux 内核的
perf_events子系统,能访问 CPU 的硬件性能计数器(PMU),也能跟踪软件事件(如上下文切换、缓存丢失、分支预测失败、调度事件、系统调用等)。 - 支持采样(sampling)、计数(counting)以及事件跟踪。
- 利用 Linux 内核的
-
特点
- 细粒度:可定位到函数级、指令级热点;配合火焰图(Flame Graph)可直观展现调用路径。
- 硬件依赖:需要 CPU 支持的 PMU,但主流 x86/ARM 服务器一般都有。
- 在线与离线分析:既可对正在运行的进程采样,也可对命令行启动的程序进行分析。
-
典型用法
perf stat ./app:统计整个程序运行期间的硬件/软件事件总量,用于初步扫描瓶颈。perf record -F 99 -g ./app+perf script+ Flame Graph:热点定位。perf top:实时查看当前系统最热函数。
3. perf-tools(Brendan Gregg 等人的脚本集合)
-
组成
- 一系列基于 BPF 或 perf_events 的脚本/工具,如
offcputime,cpudist,cachegrind(并非 Valgrind 的 cachegrind,而是统计缓存延迟的脚本)、execsnoop、filelife、biosnoop等。多数以 BPFtrace 或 bcc 为基础,也有老版直接用 perf_events + Python/awk 等实现。
- 一系列基于 BPF 或 perf_events 的脚本/工具,如
-
原理
- 利用 Linux 提供的 eBPF、perf_events 接口,对内核和用户态事件进行高度定制化跟踪。
- 可以捕获更复杂的场景,例如线程的 off-CPU 时间归因、特定 syscall 的延迟分布、锁竞争分析、延迟路径跟踪等。
-
特点
- 用途专一:每个脚本针对某种场景(如 off-CPU 分析、I/O 延迟、调度延迟、网络探针等)。
- 灵活可扩展:借助 BPF,可以在线插桩,开销相对较低。
- 深度诊断:通常在发现性能问题后,用于深入剖析具体原因。
-
与 perf 的关系
- 底层依赖内核提供的 perf_events 或 BPF 功能;某些脚本也会调用
perf采样接口。 - perf-tools 脚本往往是在
perf stat/record等粗略扫描之后,用来做更细致的跟踪。
- 底层依赖内核提供的 perf_events 或 BPF 功能;某些脚本也会调用
4. 三者的对比与关联
| 维度 | sysstat | Linux perf | perf-tools (Brendan Gregg) |
|---|---|---|---|
| 采集接口 | /proc、/sys 系统统计接口 | perf_events(PMU + 软件事件) | perf_events / eBPF |
| 关注层面 | 系统级资源使用、历史趋势 | 硬件/内核/应用热点定位 | 特定场景(off-CPU、锁竞争、I/O 延迟等) |
| 粒度 | 粗(秒级或更长) | 细(函数、指令、调用路径) | 很细(调用链、事件分布、归因) |
| 典型场景 | 长期监控、容量规划、容量分析 | 初步性能扫描、热点定位 | 深度性能剖析、问题根因定位 |
| 依赖 | 无需 PMU | 需要 PMU 支持 | 需要 perf_events / eBPF 支持 |
| 开销 | 低 | 低到中(视采样频率) | 低到中(视探针复杂度) |
Github地址:
sysstat常见命令:sar、iostat、mpstat、pidstat、dstat(虽不是 sysstat 包的一部分,但用途相似)等。
/proc和/sys都是虚拟文件系统接口:内核维护一系列全局或 per-CPU 的统计数据结构。这些结构会在事件发生时(如时钟中断、调度切换、I/O 完成、中断处理等)更新累加。/proc//sys 只是将这些累积值在用户读取时“映射”输出。
sar -A 命令会显示出许多指标,下图我只截出CPU的指标:
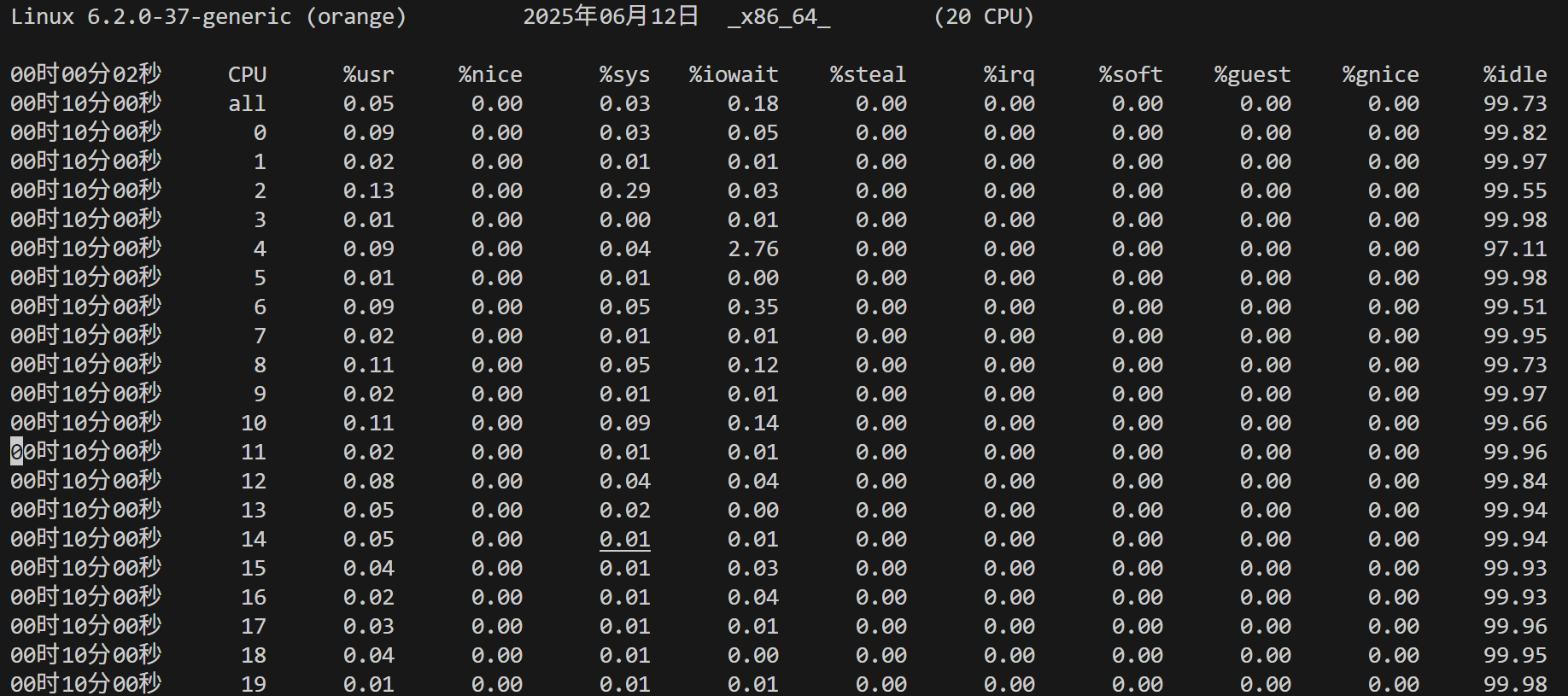
这些CPU指标数据来源于/proc/stat, cat /proc/stat:
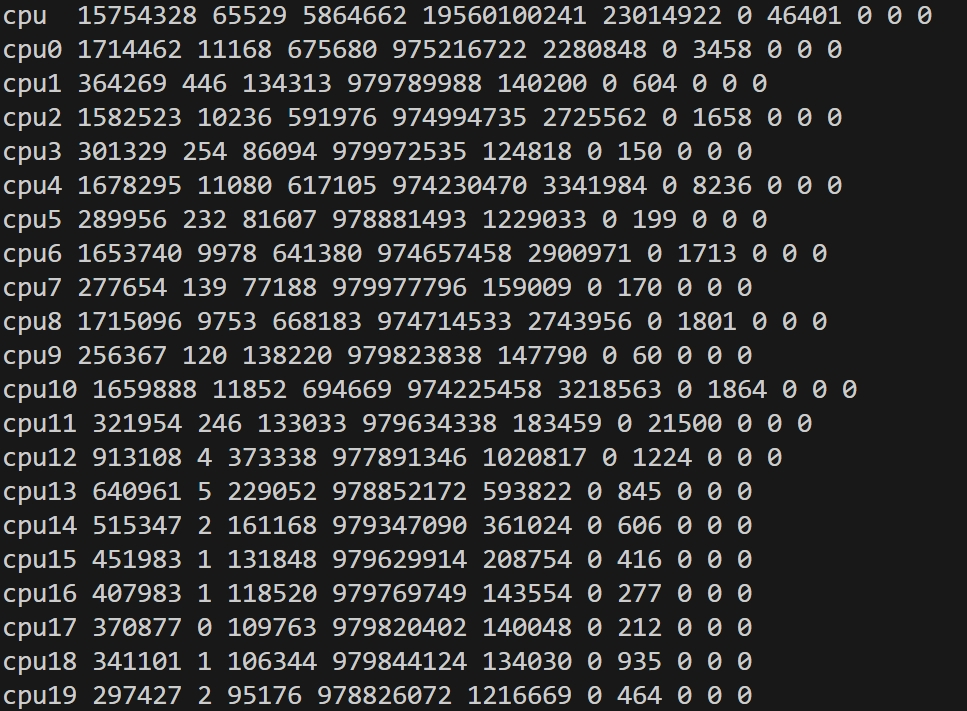
这里各字段依次表示自系统启动以来,各类别 CPU 时间的“jiffies”累积值:
- user:在用户态执行的时间(不包含 nice 进程)
- nice:在用户态执行的低优先级(nice > 0)进程的时间
- system:在内核态(system)执行的时间
- idle:空闲时间(不含 iowait)
- iowait:等待 I/O 完成的时间(注意并非严格算 CPU 占用,但常被当作“非忙”时间处理)
- irq:处理中断的时间
- softirq:处理软中断的时间
- steal:虚拟化环境下,被其他 VM “窃取”的时间
- guest、guest_nice:在虚拟机中运行客户操作系统时消耗的时间(通常不单独计入宿主 CPU 利用率)
- 以上字段都是累积值,内核在相应事件或时钟中断时将消耗时间累加到对应字段。
jiffies 是 Linux 内核中用于记录系统从启动以来所经过“时钟滴答”(tick)次数的全局变量。内核在启动时将 jiffies 置为初始值(通常接近于 0),然后在每次时钟中断(timer interrupt)发生时将其加一,因此 jiffies 的值与系统运行时间密切相关:若内核配置为每秒 HZ 次时钟中断,则每秒 jiffies 增加 HZ 次,系统启动后的运行秒数大致为 jiffies/HZ
- 在每次时钟中断(tick)或运行时长记录点,内核会记录当前进程的执行模式(user/system/idle 等),并累加到相应的 per-CPU 计数器。
- 在处理 I/O 等待、软中断、中断处理等场景,内核也会更新对应累积字段。
- 这些累积值存放在内核内部数据结构(如
kernel/sched/或架构相关代码中维护的 per-CPU 变量),供/proc读取接口直接访问。
我们可以利用以上数据计算出CPU利用率:
-
核心思路:利用累积值在两个时间点之间的增量来衡量该期间各类别的时间分布,从而计算利用率。
-
示例公式:
-
读取时刻 \(t_1\) 时的各字段累积值,求和得到总累积:
\[ \text{total}_1 = \sum_{\text{所有字段}} \text{value}_{i}(t_1). \]其中也可选择忽略 guest/guest_nice,或将其合并进 user。
-
读取时刻 \(t_2\) 时再次读取同样字段,计算:
\[ \Delta_\text{total} = \text{total}_2 - \text{total}_1,\quad \Delta_\text{idle} = \bigl(\text{idle}_2 + \text{iowait}_2\bigr) - \bigl(\text{idle}_1 + \text{iowait}_1\bigr). \] -
则在区间 \([t_1, t_2]\) 内,总“忙”时间为 \(\Delta_\text{busy} = \Delta_\text{total} - \Delta_\text{idle}\)。
-
CPU 利用率(百分比)可定义为:
\[ \text{CPU\_util} = \frac{\Delta_\text{busy}}{\Delta_\text{total}} \times 100\%. \] -
例如常见脚本:先读取
/proc/stat,等待固定间隔(如 1 秒),再读取,计算增量并得出利用率. -
注意事项:
- 不同工具对 iowait 是否计入“忙”有不同处理,需根据实际意义决定;
- 多核情况下
/proc/stat的第一行“cpu”是所有 CPU 的累积,通常直接用上述方法;也可读取每行 “cpu0”、“cpu1” 单独计算 per-CPU 利用率; - jiffy 单位与时间间隔需匹配:差值的单位是“jiffies”,但比值中 jiffies 单位可互相抵消,无需显式转换为秒;如果需要时间值,可用 jiffies 除以 USER_HZ 得到秒数。
-
Linux perf(perf_events)子命令如 perf stat、perf record、perf top、perf trace 等。
利用 Linux 内核的 perf_events 子系统,能访问 CPU 的硬件性能计数器(PMU),也能跟踪软件事件(如上下文切换、缓存丢失、分支预测失败、调度事件、系统调用等)。
Linux 内核中的 perf_events(Performance Counters for Linux, PCL)子系统是内核层对硬件性能计数器(PMU, Performance Monitoring Unit)和软件/tracepoint 事件的统一管理框架,用于收集、统计、监控系统和应用的性能数据。
即Linux perf 是基于PMU实现的,需要扫描PMU。
perf-tools(Brendan Gregg 等人的脚本集合)一系列基于 BPF 或 perf_events 的脚本/工具,如 offcputime, cpudist, cachegrind(并非 Valgrind 的 cachegrind,而是统计缓存延迟的脚本)、execsnoop、filelife、biosnoop 等。多数以 BPFtrace 或 bcc 为基础:
- 每个脚本针对某种场景(如 off-CPU 分析、I/O 延迟、调度延迟、网络探针等)。
- 借助 BPF,可以在线插桩,开销相对较低。
Analysis
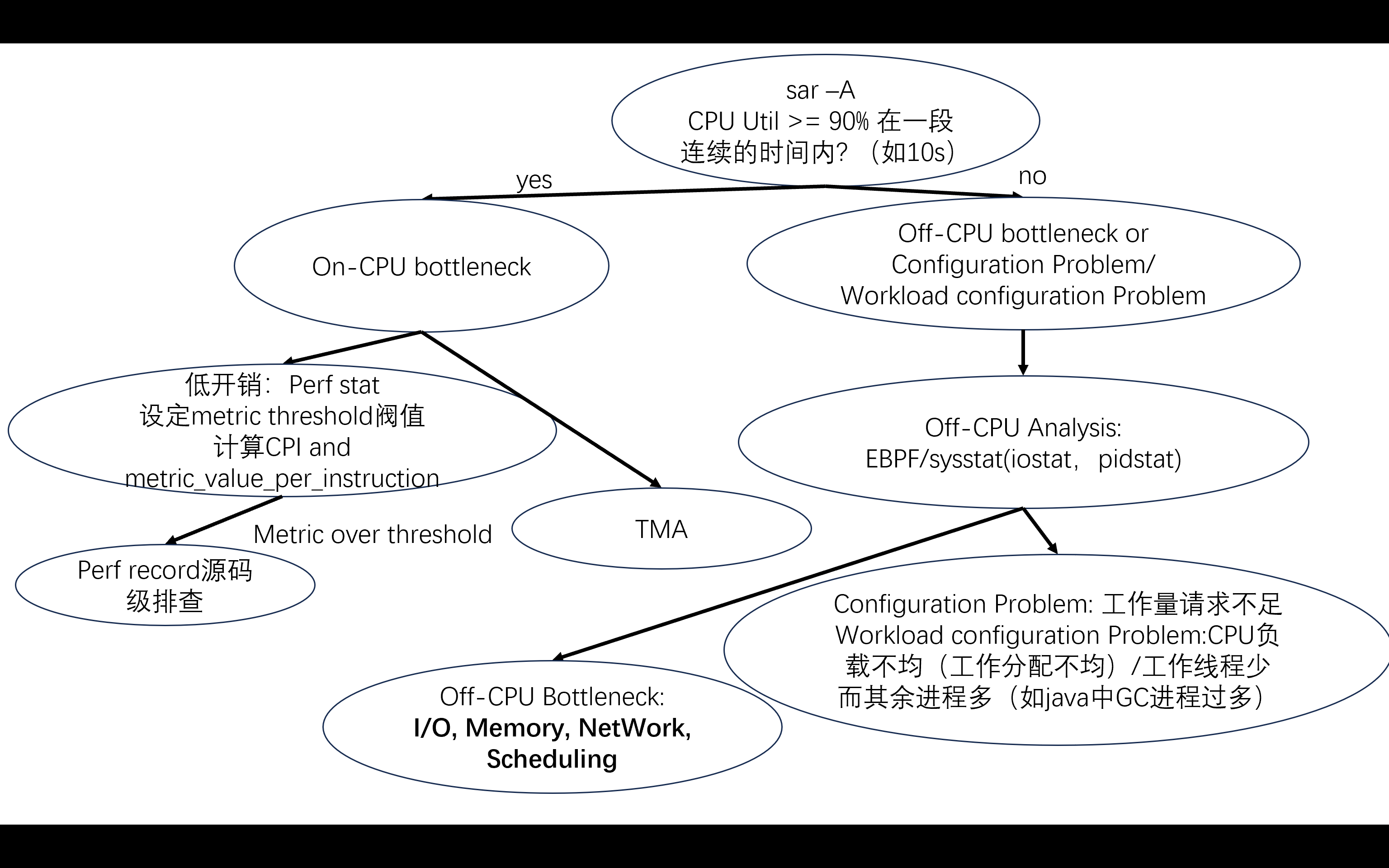
perf stat和TMA均为低开销方法,能够帮助我们在不知道瓶颈原因时从两个角度分别寻找出线索。
我们能够通过perf stat收集到许多指标:cycles, instructions, read, write cache misses (3 levels), instruction, data TLB misses (2 levels)...
一般我们都会在上述指标中除以instructions变成新指标metric_value_per_instruction
- 一般若CPI > 1, 则可能是Memory Access Latency, Branch Misprediction, Resource Contention(竞争),Instruction Pipeline Stalls(可能是数据依赖,控制依赖导致的);
- 若CPI <= 1,说明我们的CPU在高效的运行,但是还是需要考虑软件上的性能问题:是否写了高复杂度的算法?是否有计算冗余?是否是自旋锁导致了高开销?
这些问题我们可以通过perf record这种开销比较大的方法进行进一步的源码级探索
perf stat因为是基于PMU实现的,其与扫描PMC中记录的数据,但是我们知道我们有很多events,但是PMC却很少,我们只能选择部分events进行测量
TMA 提供了一种更加细致的角度,在不看源码的情况下帮助我们辨别瓶颈的原因:
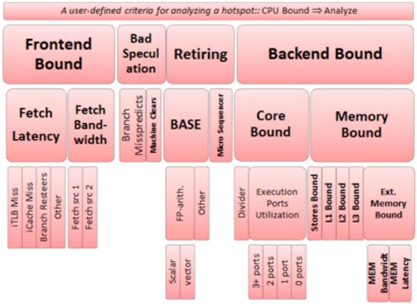
一般我们设置阀值:
● front-end 0.2
● back-end 0.2
● bad speculation 0.1
● retiring 0.7
- front-end bound:一般是不能立刻得到指令地址,如instruction cache miss/(Instruction Translation Lookaside Buffer)ITLB miss
Note instruction addresses are sequential. Thus cache misses should be very low.
- back-end bound: 一般是资源受限,如data cache miss/DTLB miss/memory bandwidth limit/依赖关系
对于指令地址,因为其是静态的,且代码段空间较小,一般比较少发生miss, 但是对于数据地址,其是动态的,即在运行时可能地址会改动,其数据段空间较大,大多数cache miss发生在data上
- Bad-Speculation
目前分支预测错误占比应该很小,因为代码一般经过很好的调优在这一方面
若是出现了属于Backend_Bound.Memory_Bound瓶颈,可以通过:
perf c2c recordperf c2c report
这两条命令更加深入地查看问题原因,因为TMA方法虽然好,但是有时不能很直接地让我们看出问题所在,因为TMA的一个指标是由许多性能事件计算出来的,我们有时面对如此多的性能事件并不能查找到问题所在。
实践
消除 伪共享(false sharing)性能问题
- source code
- 问题原因:请记住缓存一致性的单位是cache line
基础
阅读Intel TMA Metric表
截止2025.6.21,TMA Metric.xlsx表长这样:
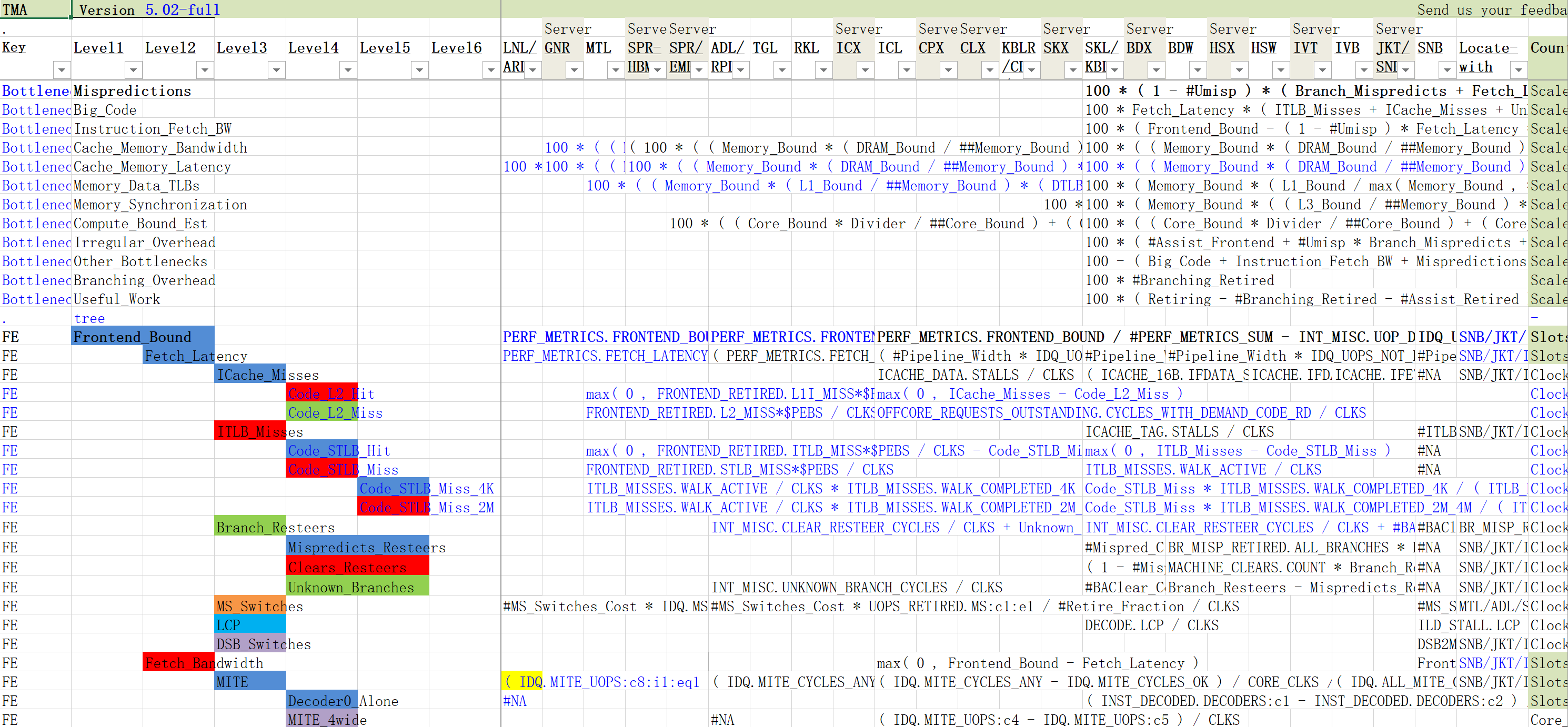
其中左侧内容很好理解,为TMA各个层级下的指标; 我们需要清楚指标是通过事件计数数据计算出来的
右侧内容有一些难以理解的单词缩写,其是CPU 微架构名称缩写,我们可以在附表ManyCounters 工作表中找到更详细的内容:
-
Multi Group Metrics: 该架构下属于多个性能指标组的指标列表,以分号分隔。即列出一组指标名称,这些指标在 TMA 分析中涉及多个类别(属于多重分类)。此信息可指导工具在同一计数器可用于计算多个度量时的处理。
-
SNB:Sandy Bridge(客户端或服务器版)
-
JKT/SNB-EP:Jupiter/Sandy Bridge-EP(Sandy Bridge-Enterprise/Server)
-
IVT:Ivy Bridge(客户端)
-
IVB:Ivy Bridge(服务器/Enterprise)
-
HSW:Haswell(客户端)
-
HSX:Haswell-EP(服务器)
-
BDW:Broadwell(客户端)
-
BDX:Broadwell-EP/EX(服务器)
-
SKL/KBL:Skylake / Kaby Lake(客户端)
-
SKX:Skylake-EP(服务器)
-
KBLR/CFL/CML:Kaby Lake Refresh / Coffee Lake / Coffee Lake Refresh(客户端演进系列)
-
CLX:Cascade Lake(服务器)
-
CPX:Cooper Lake(服务器)
-
ICL:Ice Lake(客户端)
-
ICX:Ice Lake Xeon(服务器)
-
RKL:Rocket Lake(客户端)
-
TGL:Tiger Lake(客户端)
-
ADL/RPL:Alder Lake / Raptor Lake(客户端)
-
SPR/EMR:Sapphire Rapids / Emerald Rapids(服务器,下一代 Xeon)
-
SPR-HBM:Sapphire Rapids 带 HBM 支持的变种
-
MTL:Meteor Lake(客户端未来架构)
-
GNR:Granite Rapids(未来/预期服务器架构)
-
LNL/ARL:Lunar Lake / Arrow Lake(更远未来客户端架构)
通过cpuid -1 | grep "\(synth\)"查看本地微架构为何
有一个列称为Locate-with列:告知分析工具或用户,需要使用哪些硬件计数器来采集原始计数,再结合其他数据计算出该 TMA 指标。
有时我们可以看到在微架构对应的指标下计算公式空缺了,可能是如下几种情况:
-
locate-with列的条件表达式覆盖所有情况,无需单独列:有时表中以一种条件表达式(如 SNB ? A : IVB/IVT/JKT ? B : HSW/HSX/... ? C : DEFAULT)来覆盖多个架构,表格头部又分别有 SNB、IVB、HSW 等列,此时可能只在“公式列”中写了一个整体条件表达式,而在各单独架构列未填内容,因为该表达式已包含所有架构分支逻辑。架构列因此留空表示“不在此列单独定义”,而是在同一表达式里一次性处理。
-
通过继承规则处理:有些架构若未在本列给出显式事件名称或公式,工具会查 “inheritance_rules” 表,看看该架构是否继承自某前代架构,间接使用前代事件。如若继承链上某代支持,就使用继承事件;如果都不支持,则该指标在本架构不采集、或需报错/跳过。
-
不支持或晚期才支持:如果某个微架构并不支持直接计算该指标,或在该架构必须使用特殊事件、但表中未提供(可能通过继承或外部文档补充),则该单元格留空。例如:Sandy Bridge(SNB)较早期可能没有专门的 DRAM_Bound 计算事件,或者需要用更复杂的前代事件组合,此时表中可能留空或交由脚本查“inheritance_rules”再决定。
往下翻会发下如下内容,其中metric记录的是上图中一些公式中以 # 出现的指标。
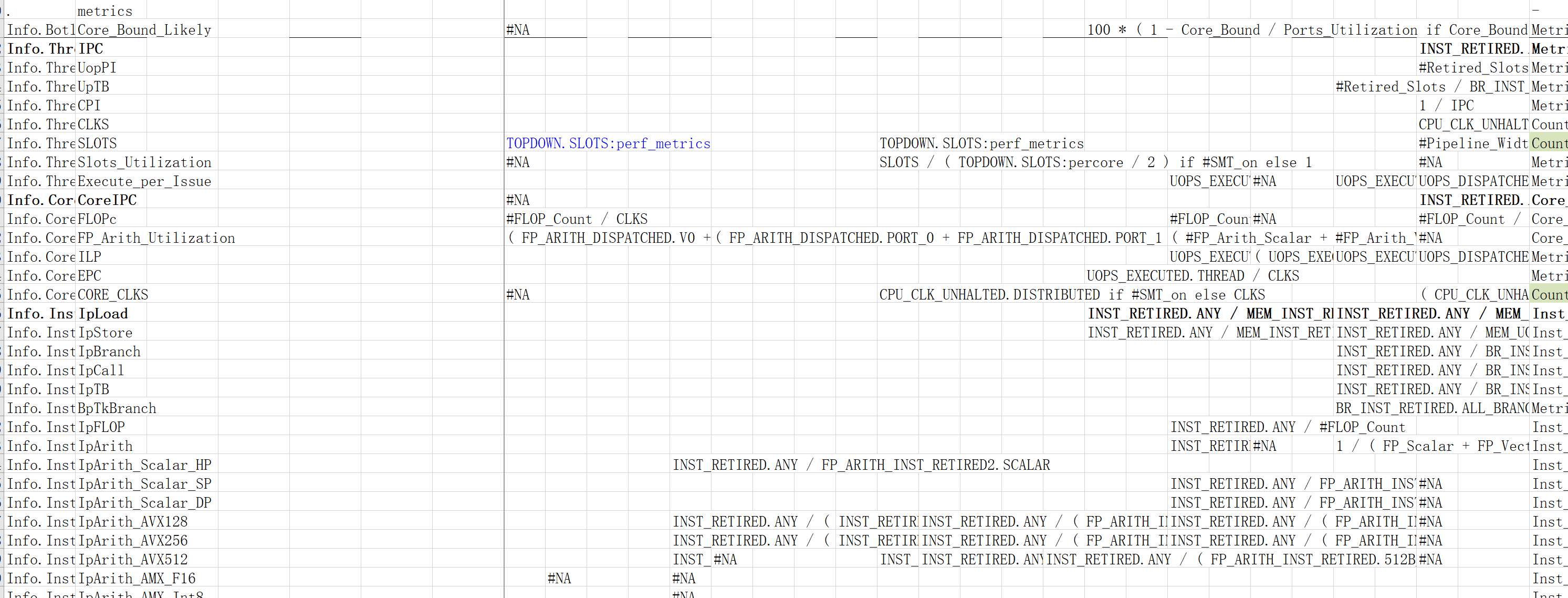
如DRAM_BOUND在SKL/KBL架构下为#MEM_Bound_Ratio,其中MEM_Bound_Ratio就可以在这张表中找到
在公式中出现的事件,我们一般可以通过perf list | grep -i event_name来查看当前机器上是否支持该事件的计数,然后通过perf stat -e event_name来观察数值
perf-ninja项目构建和对比
如何在具体lab下编译构建程序?
cmake -E make_directory build
cd build
cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_C_FLAGS="-g" -DCMAKE_CXX_FLAGS="-g" ..
cmake --build . --config Release --parallel 8
cmake --build . --target validateLab
cmake --build . --target benchmarkLab
如何对比修改前的baseline程序和修改后的solution程序?
# 1. Benchmark the baseline and save the score into a JSON file
./lab --benchmark_min_time=1 --benchmark_out_format=json --benchmark_out=baseline.json
# 2. Change the code
# 3. Benchmark your solution and save the score into a JSON file
./lab --benchmark_min_time=1 --benchmark_out_format=json --benchmark_out=solution.json
# 4. Compare solution.json against baseline.json
/path/to/benchmark/tools/compare.py benchmarks baseline.json solution.json
perf-ninja项目使用到的 Google benchmark 项目
Google Benchmark 是 Google 开源的一个 C++ 基准测试(microbenchmark)框架,旨在方便开发者对代码片段或函数进行精确的性能测量与比较。
头文件:
#include <benchmark/benchmark.h>
基准函数与主函数:
static void BM_MyFunction(benchmark::State& state) {
for (auto _ : state) {
// 要测量的代码片段
MyFunction();
}
}
BENCHMARK(BM_MyFunction)->Iterations(1000);
BENCHMARK_MAIN();
过程
on-CPU 还是 off-CPU?
sar -a 固然是总好方法,但是其是针对于全局来说,当我想要查看某特定进程的CPU使用率又应该如何呢?
pidstat
./lab &
PID=$!
pidstat -u -p $PID 1
需要注意的是pidstat每次最少间隔1s, 如果程序运行的很快甚至pidstat没有输出,可以让程序多迭代几轮
15时17分03秒 UID PID %usr %system %guest %wait %CPU CPU Command
15时17分04秒 1024 549050 786.00 0.00 0.00 0.00 786.00 10 lab
15时17分05秒 1024 549050 820.00 1.00 0.00 0.00 821.00 2 lab
15时17分06秒 1024 549050 823.00 1.00 0.00 0.00 824.00 14 lab
15时17分07秒 1024 549050 824.00 0.00 0.00 0.00 824.00 19 lab
15时17分08秒 1024 549050 836.00 3.00 0.00 0.00 839.00 2 lab
15时17分09秒 1024 549050 835.00 1.00 0.00 0.00 836.00 10 lab
15时17分10秒 1024 549050 826.00 2.00 0.00 0.00 828.00 8 lab
15时17分11秒 1024 549050 824.00 1.00 0.00 1.00 825.00 8 lab
15时17分12秒 1024 549050 806.00 0.00 0.00 1.00 806.00 4 lab
15时17分13秒 1024 549050 803.00 1.00 0.00 0.00 804.00 14 lab
15时17分14秒 1024 549050 815.00 2.00 0.00 0.00 817.00 15 lab
15时17分15秒 1024 549050 825.00 2.00 0.00 0.00 827.00 4 lab
15时17分16秒 1024 549050 834.00 1.00 0.00 0.00 835.00 3 lab
15时17分17秒 1024 549050 825.00 0.00 0.00 0.00 825.00 6 lab
15时17分18秒 1024 549050 826.00 1.00 0.00 0.00 827.00 7 lab
15时17分19秒 1024 549050 827.00 1.00 0.00 0.00 828.00 13 lab
15时17分19秒 UID PID %usr %system %guest %wait %CPU CPU Command
15时17分20秒 1024 549050 814.00 0.00 0.00 0.00 814.00 13 lab
15时17分21秒 1024 549050 808.00 3.00 0.00 0.00 811.00 4 lab
15时17分22秒 1024 549050 824.00 8.00 0.00 0.00 832.00 19 lab
pidstat 报告的是进程(或线程)在所有 CPU 核心上的累积使用率,所以当进程是多线程并且并行地在多个核心上运行时,%usr(用户态 CPU 使用率)就可能远超 100%。你看到的 ~800% 说明你的程序在那个时刻几乎占满了约 8 个核在做用户态工作。
CPU 列(最后 “CPU” 字段):表示采样时该任务(或线程)所在的具体 CPU 核编号,只是显示在哪个核心上发生了度量,并不影响 %usr 的累积意义。 由于线程会被调度到不同核心,所以你看到不同的 CPU 编号。
总之看到如上结果,我们可以确定是ON-CPU的性能问题。
P核还是E核?
我们知道程序运行在P核还是E核也会影响到性能, lscpu -e 查看第4列Core可以知道是P核还是E核
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ MHZ
0 0 0 0 0:0:0:0 yes 5100.0000 800.0000 1069.1470
1 0 0 0 0:0:0:0 yes 5100.0000 800.0000 3500.0000
2 0 0 1 4:4:1:0 yes 5100.0000 800.0000 3500.0000
3 0 0 1 4:4:1:0 yes 5100.0000 800.0000 3500.0000
4 0 0 2 8:8:2:0 yes 5100.0000 800.0000 1100.0240
5 0 0 2 8:8:2:0 yes 5100.0000 800.0000 3500.0000
6 0 0 3 12:12:3:0 yes 5100.0000 800.0000 1092.4000
7 0 0 3 12:12:3:0 yes 5100.0000 800.0000 3500.0000
8 0 0 4 16:16:4:0 yes 5100.0000 800.0000 1100.0470
9 0 0 4 16:16:4:0 yes 5100.0000 800.0000 3500.0000
10 0 0 5 20:20:5:0 yes 5100.0000 800.0000 1100.4990
11 0 0 5 20:20:5:0 yes 5100.0000 800.0000 1100.3101
12 0 0 6 24:24:6:0 yes 3900.0000 800.0000 3500.0000
13 0 0 7 25:25:6:0 yes 3900.0000 800.0000 3500.0000
14 0 0 8 26:26:6:0 yes 3900.0000 800.0000 3500.0000
15 0 0 9 27:27:6:0 yes 3900.0000 800.0000 3500.0000
16 0 0 10 28:28:7:0 yes 3900.0000 800.0000 800.0680
17 0 0 11 29:29:7:0 yes 3900.0000 800.0000 799.8420
18 0 0 12 30:30:7:0 yes 3900.0000 800.0000 3500.0000
19 0 0 13 31:31:7:0 yes 3900.0000 800.0000 3500.0000
因为只有P核才能超线程,才能有两个线程出现在同一个core上
识别瓶颈
perf stat
./lab &
PID=$!
perf stat -p $PID
Performance counter stats for process id '555633':
161,968.78 msec task-clock # 8.090 CPUs utilized
62,289 context-switches # 384.574 /sec
11,696 cpu-migrations # 72.211 /sec
2,816 page-faults # 17.386 /sec
738,317,657,397 cpu_core/cycles/ # 4.558 G/sec (62.53%)
505,729,550,502 cpu_atom/cycles/ # 3.122 G/sec (53.63%)
43,185,548,222 cpu_core/instructions/ # 266.629 M/sec (62.53%)
21,906,442,058 cpu_atom/instructions/ # 135.251 M/sec (53.63%)
2,525,733,181 cpu_core/branches/ # 15.594 M/sec (62.53%)
1,320,408,748 cpu_atom/branches/ # 8.152 M/sec (53.63%)
13,863,059 cpu_core/branch-misses/ # 85.591 K/sec (62.53%)
12,286,593 cpu_atom/branch-misses/ # 75.858 K/sec (53.63%)
3,620,704,751,734 cpu_core/slots/ # 22.354 G/sec (62.53%)
79,025,259,633 cpu_core/topdown-retiring/ # 2.2% Retiring (62.53%)
22,270,537 cpu_core/topdown-bad-spec/ # 0.0% Bad Speculation (62.53%)
3,081,713,475 cpu_core/topdown-fe-bound/ # 0.1% Frontend Bound (62.53%)
3,537,624,936,980 cpu_core/topdown-be-bound/ # 97.7% Backend Bound (62.53%)
35,000,831,305 cpu_core/topdown-heavy-ops/ # 1.0% Heavy Operations # 1.2% Light Operations (62.53%)
20,583,159 cpu_core/topdown-br-mispredict/ # 0.0% Branch Mispredict # 0.0% Machine Clears (62.53%)
2,694,698,103 cpu_core/topdown-fetch-lat/ # 0.1% Fetch Latency # 0.0% Fetch Bandwidth (62.53%)
3,369,746,198,046 cpu_core/topdown-mem-bound/ # 93.1% Memory Bound # 4.6% Core Bound (62.53%)
20.020009434 seconds time elapsed
perf stat的TMA初步指明是Backend Bound的问题。
pmu-tool的TMA具体识别瓶颈
~/pmu-tools/toplev.py -l2 -v --no-desc ./lab
-
-l2: 设定 Top-Down 决策树分析的层级(level 2)。更高层级(-l3、-l4)可进一步深入,但会使用更多 PMU 事件,可能触发更频繁的多路复用(multiplexing),影响精度。- 或者可以去掉
-l2,我们直接使用--drilldown, 用于在初步 Top-Down 分析识别出主要瓶颈类别后,自动针对该瓶颈节点重新运行更深层级的度量,只显示并聚焦在该瓶颈路径下的子指标。这样可以减少一次性采样过多事件带来的多路复用误差,并快速给出针对主要瓶颈的细化信息。
- 或者可以去掉
-
-v: 打印所有测量到的指标,而不仅仅是超过阈值或关注度高的那些,从而获得更全面的信息。 -
--no-desc: 不打印每个度量指标的文本描述,只输出核心字段(标签、分类、数值等),以节省屏幕空间,让输出更紧凑。
# 5.01-full-perf, 4 on 13th Gen Intel(R) Core(TM) i5-13600K [adl]
C0-T0-core FE Frontend_Bound % Slots 0.8 <
C0-T0-core BAD Bad_Speculation % Slots 0.0 <
C0-T0-core BE Backend_Bound % Slots 95.7
C0-T0-core RET Retiring % Slots 3.5 <
C0-T0-core FE Frontend_Bound.Fetch_Latency % Slots 0.8 <
C0-T0-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.0 <
C0-T0-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C0-T0-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C0-T0-core BE/Mem Backend_Bound.Memory_Bound % Slots 89.0 <==
C0-T0-core BE/Core Backend_Bound.Core_Bound % Slots 6.7 <
C0-T0-core RET Retiring.Light_Operations % Slots 2.0 <
C0-T0-core RET Retiring.Heavy_Operations % Slots 1.6 <
C0-T0-core MUX % 100.00
C0-T1-core FE Frontend_Bound % Slots 0.8 <
C0-T1-core BAD Bad_Speculation % Slots 0.0 <
C0-T1-core BE Backend_Bound % Slots 95.7
C0-T1-core RET Retiring % Slots 3.5 <
C0-T1-core FE Frontend_Bound.Fetch_Latency % Slots 0.8 <
C0-T1-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.0 <
C0-T1-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C0-T1-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C0-T1-core BE/Mem Backend_Bound.Memory_Bound % Slots 90.6 <==
C0-T1-core BE/Core Backend_Bound.Core_Bound % Slots 5.1 <
C0-T1-core RET Retiring.Light_Operations % Slots 2.4 <
C0-T1-core RET Retiring.Heavy_Operations % Slots 1.2 <
C0-T1-core MUX % 100.00
C4-T0-core FE Frontend_Bound % Slots 0.4 <
C4-T0-core BAD Bad_Speculation % Slots 0.0 <
C4-T0-core BE Backend_Bound % Slots 96.5
C4-T0-core RET Retiring % Slots 3.1 <
C4-T0-core FE Frontend_Bound.Fetch_Latency % Slots 0.4 <
C4-T0-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.0 <
C4-T0-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C4-T0-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C4-T0-core BE/Mem Backend_Bound.Memory_Bound % Slots 90.6 <==
C4-T0-core BE/Core Backend_Bound.Core_Bound % Slots 5.9 <
C4-T0-core RET Retiring.Light_Operations % Slots 2.0 <
C4-T0-core RET Retiring.Heavy_Operations % Slots 1.2 <
C4-T0-core MUX % 100.00
C4-T1-core FE Frontend_Bound % Slots 0.8 <
C4-T1-core BAD Bad_Speculation % Slots 0.0 <
C4-T1-core BE Backend_Bound % Slots 96.1
C4-T1-core RET Retiring % Slots 3.1 <
C4-T1-core FE Frontend_Bound.Fetch_Latency % Slots 0.8 <
C4-T1-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.0 <
C4-T1-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C4-T1-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C4-T1-core BE/Mem Backend_Bound.Memory_Bound % Slots 91.8 <==
C4-T1-core BE/Core Backend_Bound.Core_Bound % Slots 4.3 <
C4-T1-core RET Retiring.Light_Operations % Slots 2.0 <
C4-T1-core RET Retiring.Heavy_Operations % Slots 1.2 <
C4-T1-core MUX % 100.00
C8-T0-core FE Frontend_Bound % Slots 0.4 <
C8-T0-core BAD Bad_Speculation % Slots 0.0 <
C8-T0-core BE Backend_Bound % Slots 96.5
C8-T0-core RET Retiring % Slots 3.1 <
C8-T0-core FE Frontend_Bound.Fetch_Latency % Slots 0.4 <
C8-T0-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.0 <
C8-T0-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C8-T0-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C8-T0-core BE/Mem Backend_Bound.Memory_Bound % Slots 90.6 <==
C8-T0-core BE/Core Backend_Bound.Core_Bound % Slots 5.9 <
C8-T0-core RET Retiring.Light_Operations % Slots 2.0 <
C8-T0-core RET Retiring.Heavy_Operations % Slots 1.2 <
C8-T0-core MUX % 100.00
C8-T1-core FE Frontend_Bound % Slots 0.8 <
C8-T1-core BAD Bad_Speculation % Slots 0.0 <
C8-T1-core BE Backend_Bound % Slots 96.5
C8-T1-core RET Retiring % Slots 2.7 <
C8-T1-core FE Frontend_Bound.Fetch_Latency % Slots 0.8 <
C8-T1-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.0 <
C8-T1-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C8-T1-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C8-T1-core BE/Mem Backend_Bound.Memory_Bound % Slots 92.2 <==
C8-T1-core BE/Core Backend_Bound.Core_Bound % Slots 4.3 <
C8-T1-core RET Retiring.Light_Operations % Slots 1.6 <
C8-T1-core RET Retiring.Heavy_Operations % Slots 1.2 <
C8-T1-core MUX % 100.00
C12-T0-core FE Frontend_Bound % Slots 0.8 <
C12-T0-core BAD Bad_Speculation % Slots 0.0 <
C12-T0-core BE Backend_Bound % Slots 96.1
C12-T0-core RET Retiring % Slots 3.1 <
C12-T0-core FE Frontend_Bound.Fetch_Latency % Slots 0.4 <
C12-T0-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.4 <
C12-T0-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C12-T0-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C12-T0-core BE/Mem Backend_Bound.Memory_Bound % Slots 90.2 <==
C12-T0-core BE/Core Backend_Bound.Core_Bound % Slots 5.9 <
C12-T0-core RET Retiring.Light_Operations % Slots 2.0 <
C12-T0-core RET Retiring.Heavy_Operations % Slots 1.2 <
C12-T0-core MUX % 100.00
C12-T1-core FE Frontend_Bound % Slots 0.8 <
C12-T1-core BAD Bad_Speculation % Slots 0.0 <
C12-T1-core BE Backend_Bound % Slots 96.1
C12-T1-core RET Retiring % Slots 3.1 <
C12-T1-core FE Frontend_Bound.Fetch_Latency % Slots 0.8 <
C12-T1-core FE Frontend_Bound.Fetch_Bandwidth % Slots 0.0 <
C12-T1-core BAD Bad_Speculation.Branch_Mispredicts % Slots 0.0 <
C12-T1-core BAD Bad_Speculation.Machine_Clears % Slots 0.0 <
C12-T1-core BE/Mem Backend_Bound.Memory_Bound % Slots 91.8 <==
C12-T1-core BE/Core Backend_Bound.Core_Bound % Slots 4.3 <
C12-T1-core RET Retiring.Light_Operations % Slots 2.0 <
C12-T1-core RET Retiring.Heavy_Operations % Slots 1.2 <
C12-T1-core MUX % 100.00
- C0-T1-core表示在core 0 thread 1上采集的数据
- “MUX” 指多路复用(multiplexing)相关的指标汇总行,显示全部计数周期的累积百分比或多路复用利用情况。
- 通常会显示为 “100.00%”,表示在整个测量期间,所有采样时间段都在某种事件分组下被采样(即无时段完全跳过事件采集)。
- 若显示小于 100%,可能意味着部分时间段并未采样到指定事件,或者因采样组管理出现遗漏。
当然接下来可以通过-l3之类的参数查看更深层的原因,关键是在使用命令后会提示:
Run toplev --describe Memory_Bound^ L1_Bound^ to get more information on bottlenecks for core
这样我们能够看到关于性能瓶颈事件的详细说明:
Backend_Bound.Memory_Bound
This metric represents fraction of slots the Memory
subsystem within the Backend was a bottleneck. Memory Bound
estimates fraction of slots where pipeline is likely stalled
due to demand load or store instructions. This accounts
mainly for (1) non-completed in-flight memory demand loads
which coincides with execution units starvation; in addition
to (2) cases where stores could impose backpressure on the
pipeline when many of them get buffered at the same time
(less common out of the two).
Backend_Bound.Memory_Bound.L1_Bound
This metric estimates how often the CPU was stalled without
loads missing the L1 Data (L1D) cache. The L1D cache
typically has the shortest latency. However; in certain
cases like loads blocked on older stores; a load might
suffer due to high latency even though it is being satisfied
by the L1D. Another example is loads who miss in the TLB.
These cases are characterized by execution unit stalls;
while some non-completed demand load lives in the machine
without having that demand load missing the L1 cache.
L1_Bound
Counts the number of cycles that the oldest load of the load
buffer is stalled at retirement due to a pipeline block
定位瓶颈代码
或者可以通过加上--show-sample参数,~/pmu-tools/toplev.py -l3 --no-desc --show-sample ./lab
可以给出其建议的采样命令:
perf record -g -e '
{cpu_core/event=0xa6,umask=0x2,name=Ports_Utilized_1_EXE_ACTIVITY_1_PORTS_UTIL,period=2000003/,
cpu_core/event=0xc6,umask=0x1,frontend=0x8,name=MS_Switches_FRONTEND_RETIRED_MS_FLOWS,period=100007/,
cpu_core/event=0xad,umask=0x80,name=Clears_Resteers_INT_MISC_CLEAR_RESTEER_CYCLES,period=500009/,
cpu_core/event=0xc3,umask=0x1,edge=1,cmask=1,name=Machine_Clears_MACHINE_CLEARS_COUNT,period=100003/,
cpu_core/event=0xd0,umask=0x21,name=Lock_Latency_MEM_INST_RETIRED_LOCK_LOADS:pp,period=100007/,
cpu_core/event=0xd2,umask=0x4,name=Contested_Accesses_MEM_LOAD_L3_HIT_RETIRED_XSNP_FWD:pp,period=20011/,
cpu_core/event=0xd2,umask=0x1,name=Contested_Accesses_MEM_LOAD_L3_HIT_RETIRED_XSNP_MISS:pp,period=20011/,
cpu_core/event=0xd2,umask=0x2,name=Data_Sharing_MEM_LOAD_L3_HIT_RETIRED_XSNP_NO_FWD:pp,period=20011/},
{cpu_core/event=0xd1,umask=0x1,name=L1_Bound_MEM_LOAD_RETIRED_L1_HIT:pp,period=1000003/,
cpu_core/event=0xd1,umask=0x4,name=L3_Bound_MEM_LOAD_RETIRED_L3_HIT:pp,period=100021/,
cpu_core/event=0x2a,umask=0x1,offcore_rsp=0x10003c0002,name=False_Sharing_OCR_DEMAND_RFO_L3_HIT_SNOOP_HITM:pp,period=100003/,
cpu_core/event=0x2a,umask=0x1,offcore_rsp=0x10800,name=Streaming_Stores_OCR_STREAMING_WR_ANY_RESPONSE:pp,period=100003/,
cpu_core/event=0xa2,umask=0x2,name=Serializing_Operation_RESOURCE_STALLS_SCOREBOARD:pp,period=100003/,
cpu_core/event=0xa4,umask=0x2,name=Backend_Bound_TOPDOWN_BACKEND_BOUND_SLOTS:pp,period=10000003/,
cpu_core/event=0xc2,umask=0x4,frontend=0x8,name=Microcode_Sequencer_UOPS_RETIRED_MS:pp,period=2000003/,
cycles:pp}' -o perf.data -a ./lab
-n-n 或 --show-nr-samples:在输出中显示每个符号或条目的样本数(number of samples)。--stdio:使用纯文本(stdio)界面输出,而非交互式 TUI(基于 curses 的界面)。
此时我们可以精确定位到某个函数导致性能事件了
perf annotate --stdio -M intel solution
-M以intel汇编风格展示solution为定位到的函数名称
此时我们可以查看汇编代码,看看是哪条指令导致的性能事件,但是此方法有时并不好用,甚至会误导,因为采样一直会有event skip问题导致并非能够精确指出是哪条指令导致的,甚至很可能出现误报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号