Pandas

Pandas
Creating, Reading and Writing
pandas中有两类实体类: the DataFrame and the Series.
-
DataFrame
A DataFrame is a table.
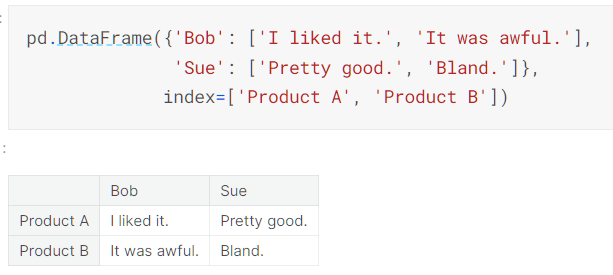
-
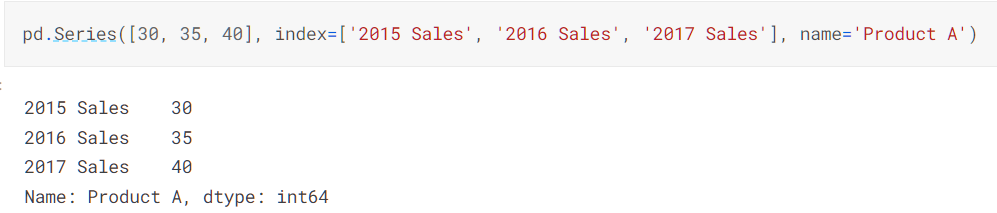
Series
A Series, by contrast, is a sequence of data values.
一般我们在读取的时候都是用DataFrame类进行装载数据

index_col=0这个参数表示我们用读到的数据第一列作为下标(pandas读取数据时会自动为每行设定从0开始不断累加的下标)
我们还可以通过set_index()函数指定某列作为下标使用:
pandas 中的 set_index() 方法用于设置DataFrame中的一个或多个列作为索引列。它的语法如下:
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数说明:
keys: 用于设置为索引的列名或列名的列表。drop: 默认为True,如果将要设置为索引的列也保留在DataFrame中,可以将其设置为False。append: 默认为False,如果要将多个索引列附加到现有索引上,可以将其设置为True。inplace: 默认为False,如果设置为True,将修改原始DataFrame,否则将返回一个新的DataFrame。verify_integrity: 默认为False,如果设置为True,则在设置索引时检查新索引的唯一性。
示例:
import pandas as pd
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 将列'A'设置为索引
df.set_index('A', inplace=True)
# 如果要将多个列设置为索引,可以传入列名的列表
df.set_index(['A', 'B'], inplace=True)
# 如果要在现有索引的基础上添加一个新的索引列,可以使用append参数
df.set_index('C', append=True, inplace=True)
上述示例演示了如何使用set_index()方法在pandas中设置索引列。根据需要,你可以根据列的名称或名称的列表来设置索引,并根据其他参数来调整设置的方式。
读取DataFrame中的列标签:
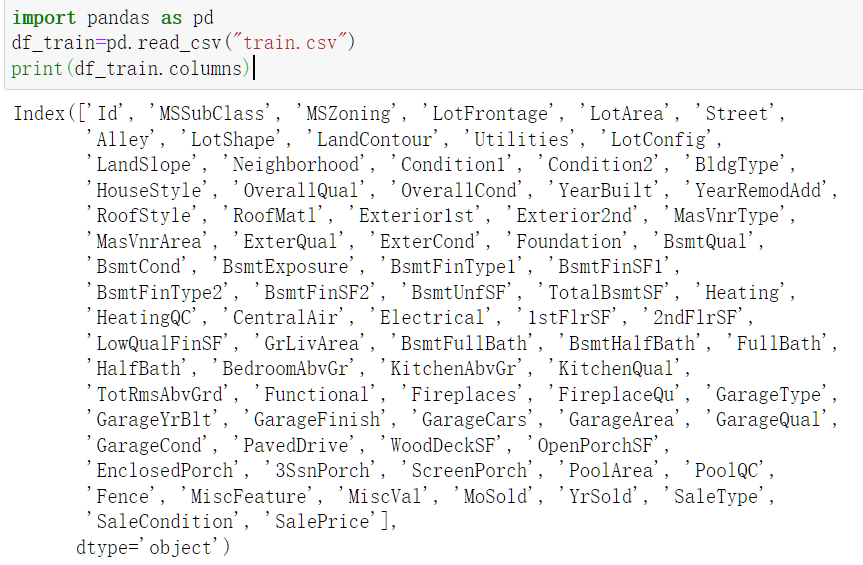
Indexing, Selecting & Assigning
我们能够通过DataFrame中的"attribute"(即可以看出每一列的key值),来访问一整列:
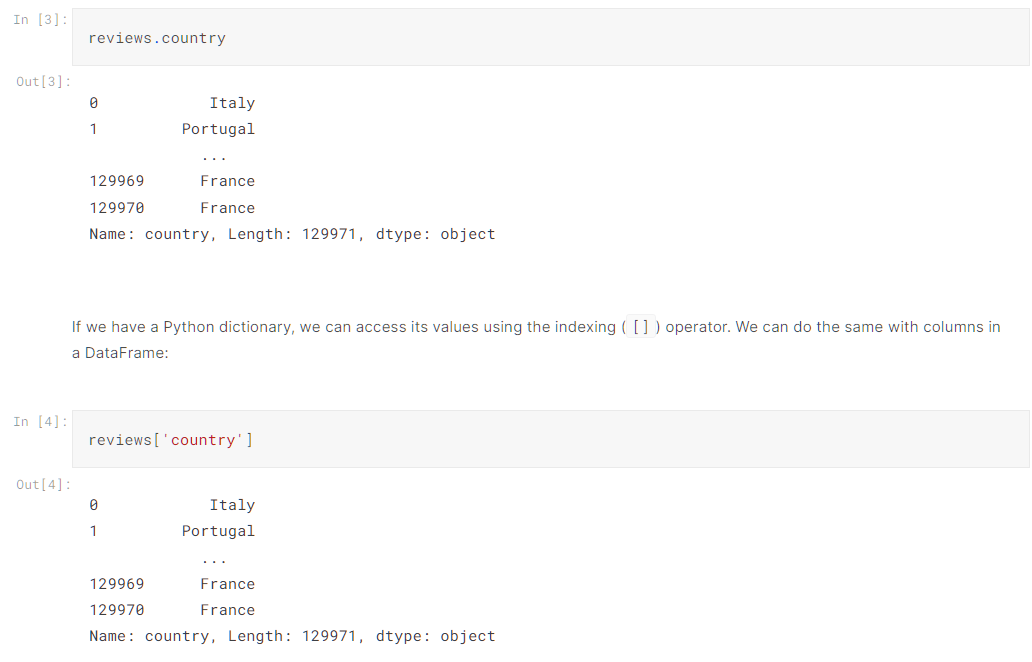
Indexing in pandas
通过iloc函数可以实现利用数值下标进行访问数据
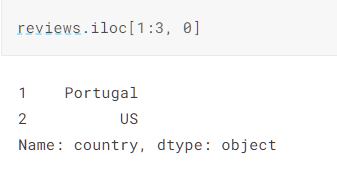
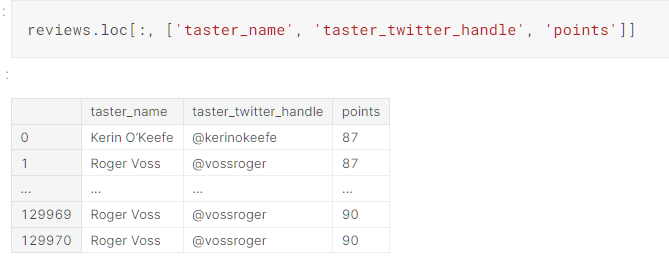
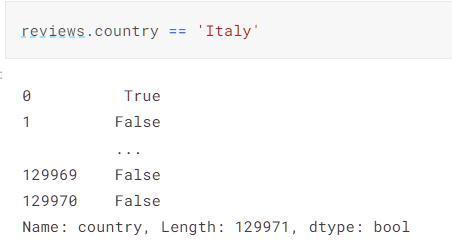
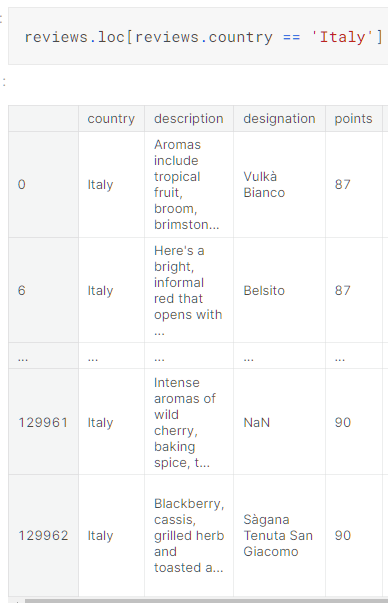
通过loc函数可以实现利用attribute和条件进行访问数据
df.points.idxmax(),idxmax()函数可以查找处值最大的索引是什么
Assigning data
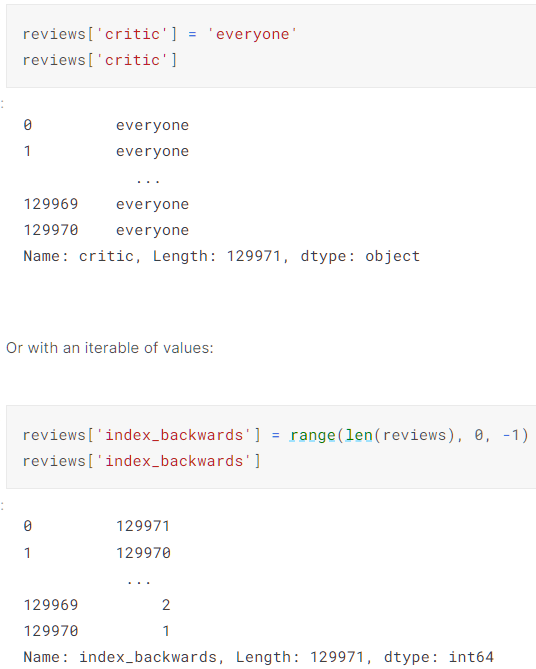
我们可以通过赋值单个数值进行整列自动赋值
也可以给出列表进行每行赋值
Summary Functions and Maps
Summary functions
我们可以使用describe()函数查看属性的描述性统计
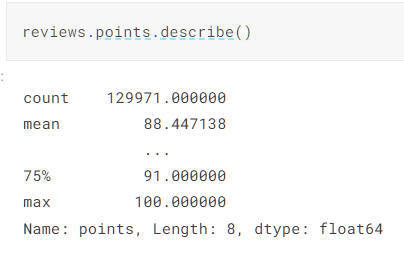
当然上述describe()的值我们也可以单个拿出来,如:reviews.points.mean()
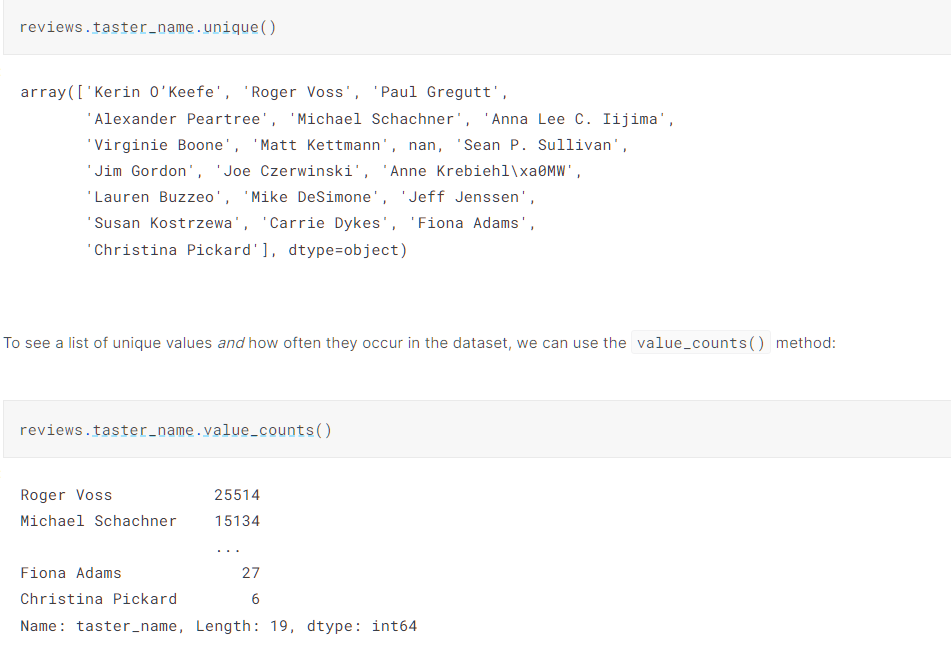
对数据进行统计展示:
Maps
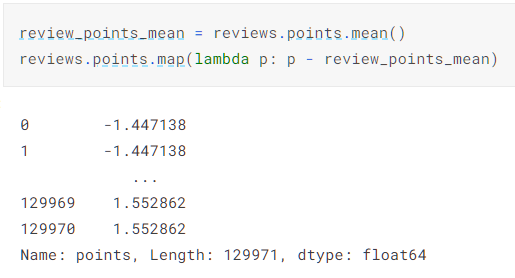
map()函数可以对Series实体对象中的值按照给出的函数进行处理
而apply()函数则是对DataFrame实体对象的值按照给出的函数进行处理
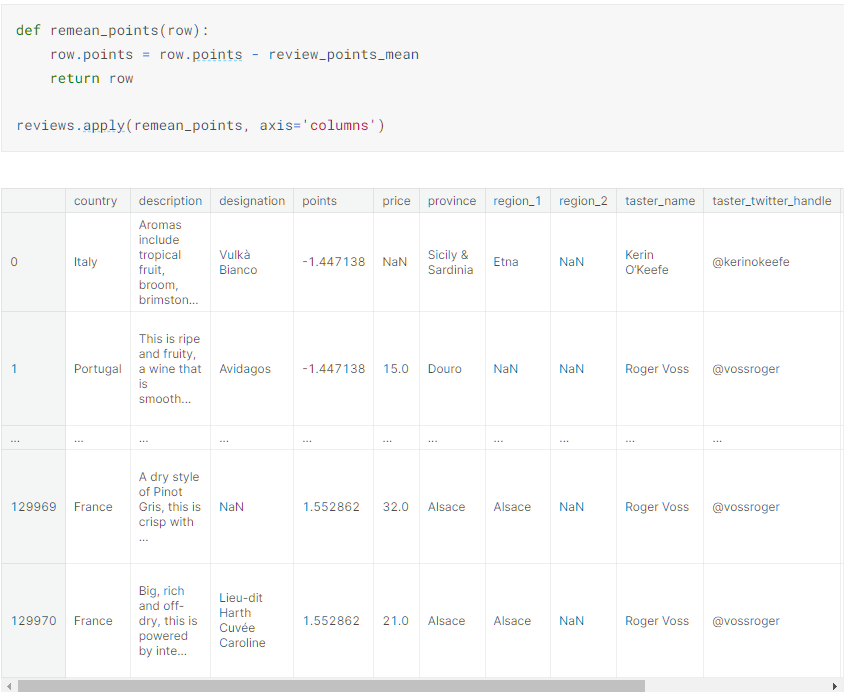
需要注意的是上述操作并不改变原值,而是只是返回处理完后的新值而已
Grouping and Sorting
Groupwise analysis
groupby()函数有点像数据库中的group by,能够根据给定的属性进行分组,然后可以对每组进行集中操作,并给出各组处理后的结果
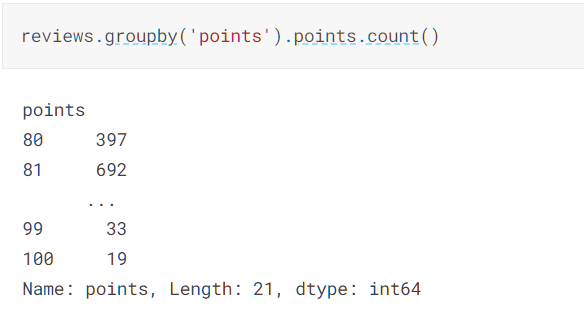
如上,首先就是对原始的DataFrame对象根据points进行分组(注意分完组后DataFrame对象被分成了points不同的DataFrame对象),然后对各个组进行取points属性的操作,再进行统计
分组可以简单理解为原来DataFrame中的行,只要符合points属于某个值就被分到某个组中去
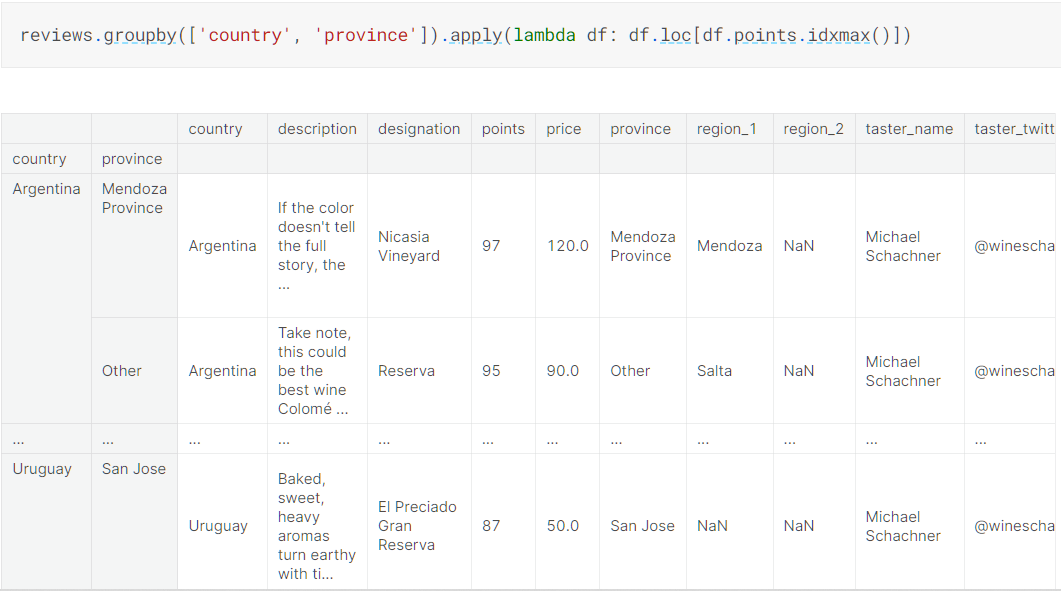
还可以对组进行apply()
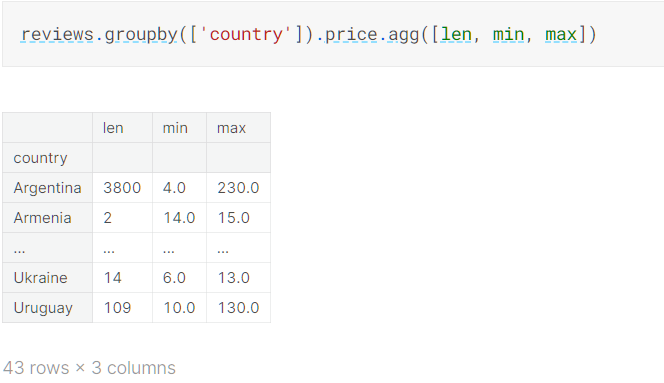
可以对组进行执行多个函数:
Multi-indexes
在进行分组后输出的DataFrame中的下标并不是我们之前见过的数值下标了:
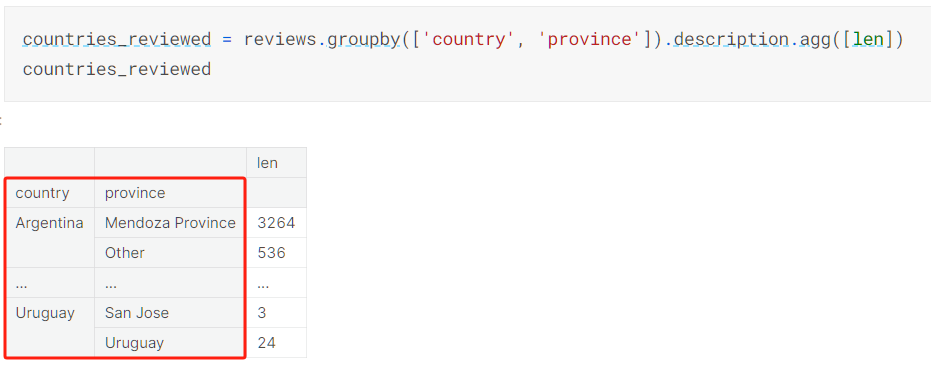
仔细看红框中的内容,发现其将我们分组的数据作为下标了
打印出下标的类型
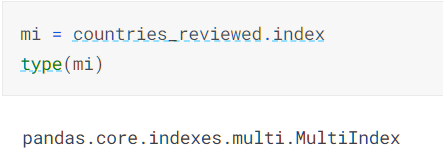
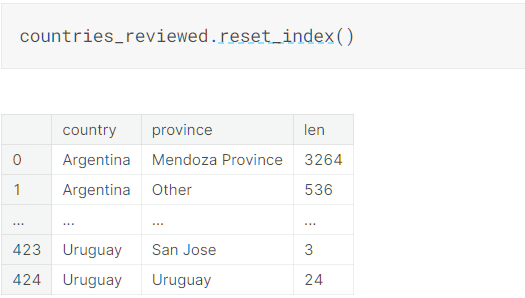
当然我最常使用的还是希望分组后,最为分组依据的数据还在,而且下标也是常见的数值下标
可以通过reset_index()函数,其返回一个新的DataFrame对象
Sorting
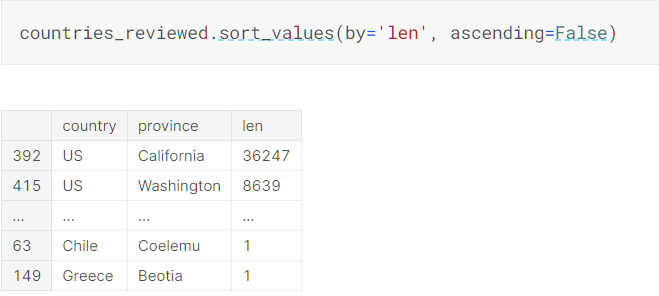
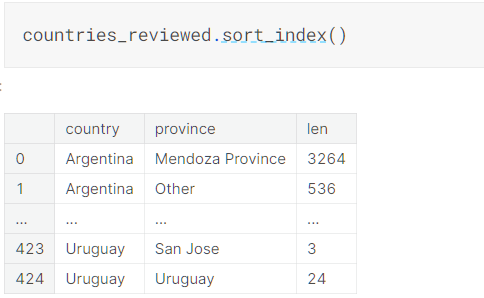
默认升序排序
sort_index()根据下标排序
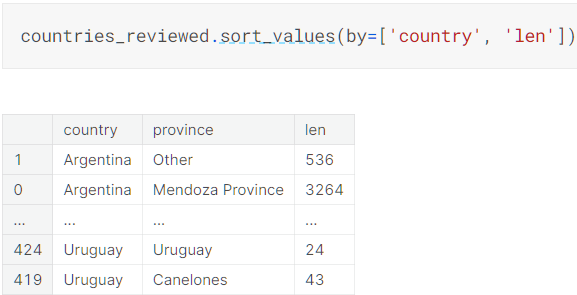
多指标排序
Data Types and Missing Values
Dtypes

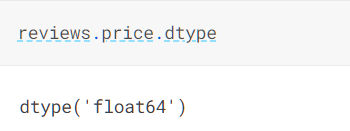
我们可以通过atype()函数更改数据类型
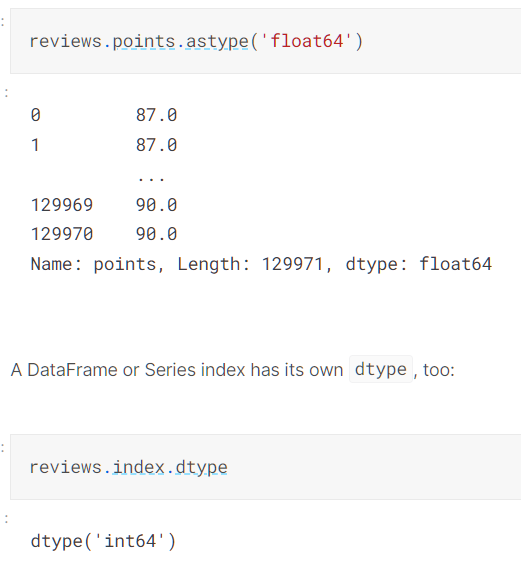
Missing data

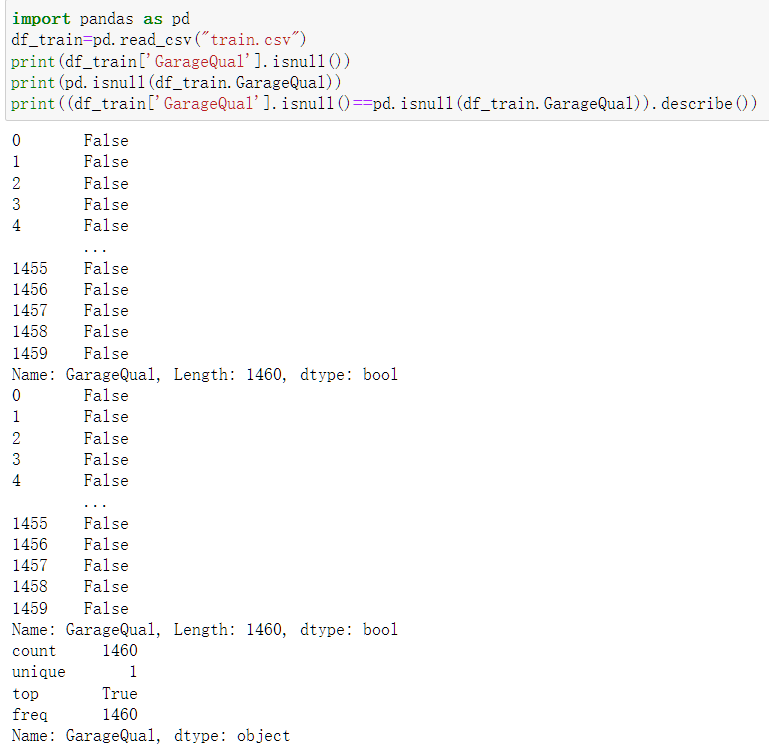
可以看到判断是否是null()有多种不同写法,我们还可以用notnull()进行判断
同时我们可以通过一些方法替换掉NaN值
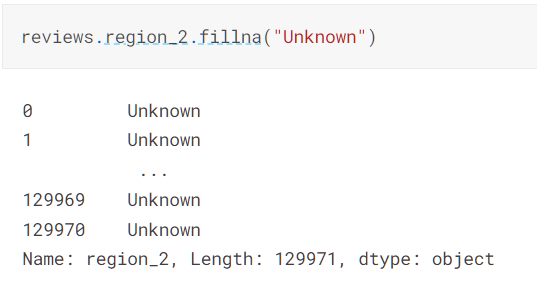
- fillna()
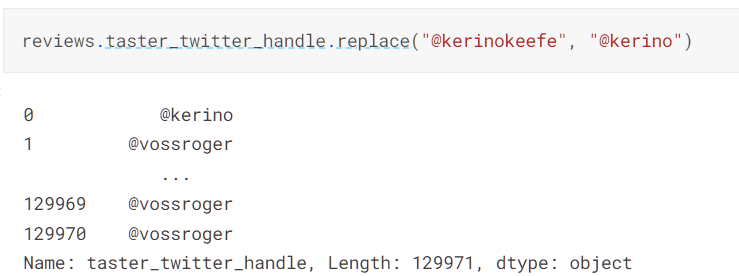
- replace()
Renaming and Combining
Renaming
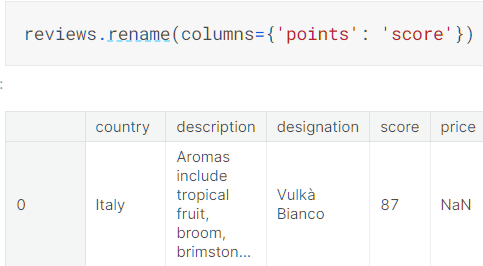
rename()函数可以帮助我们改变原先数据集中不合理的列名称
rename_axis()同时我们还可以为index设置名称

还可以为下标的值设置名称:
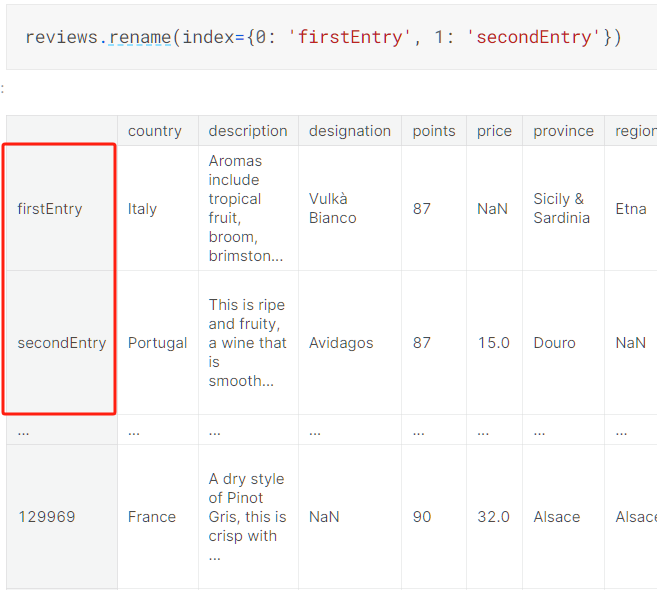
Combining
- concat()
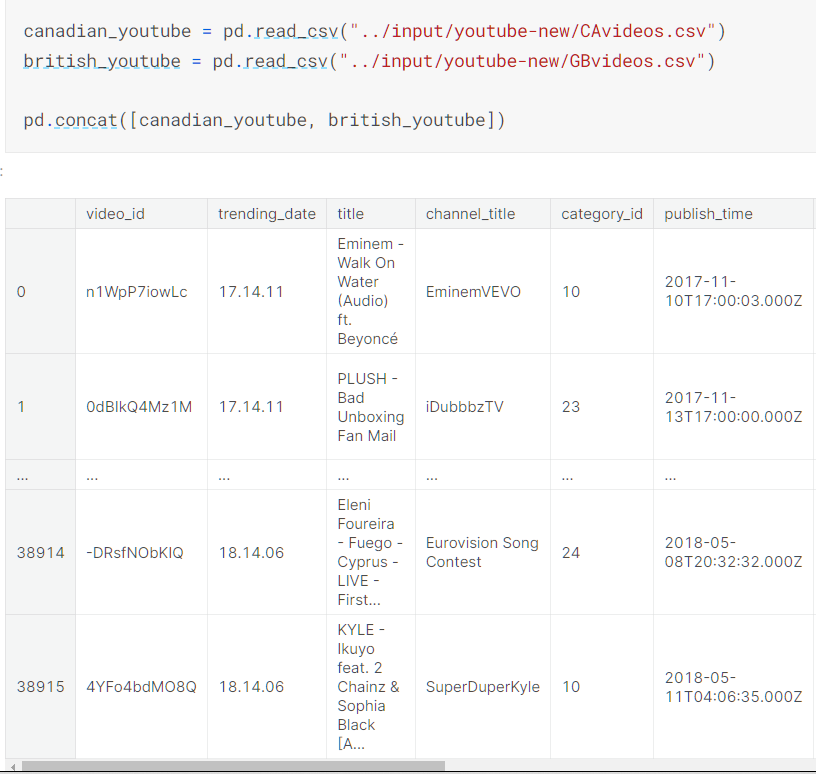
默认是按照axis=0进行连接,即按照0轴大小变化的方向进行连接
(其实你reshape会看到如(3,4)这样的输出,其中从左到右依次为0,1....轴,按照0轴大小变化的方向,其实就是要改变3这个数)
- join()
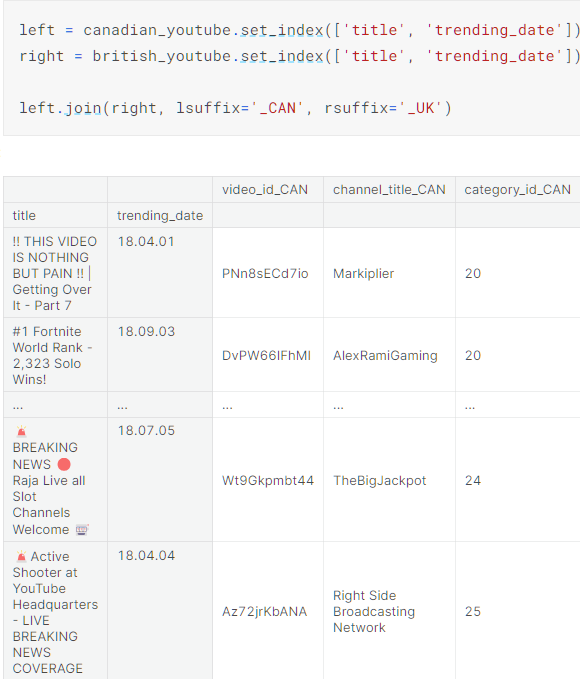
join() lets you combine different DataFrame objects which have an index in common.
即join是按照下标相同的行进行拼接
这个过程可以想象成一个DataFrame for循环他所有的行,然后每次拿出这个行的下标与另一个DataFrame的每行的下标进行对比,相同则进行行拼接

如何给pd的DataFrame添加一行数据
-
通过loc

-
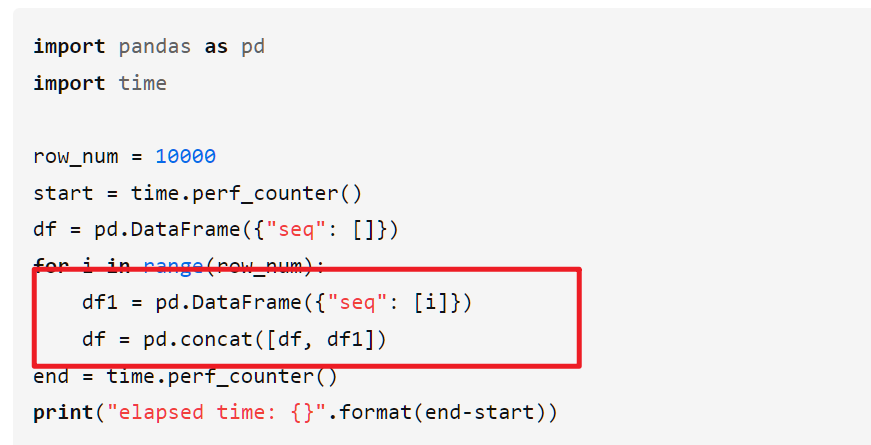
通过concat

 浙公网安备 33010602011771号
浙公网安备 33010602011771号