py tips

Python Bases
Python Data Types
格式化输出
在 Python 中,格式化浮点数通常使用 f 或 g 类型说明符:
- f:表示定点数格式,始终以小数点表示。例如,{value:.6f} 会将 value 格式化为小数点后 6 位的浮点数。
- g:表示通用格式,根据数值的大小自动选择定点数格式或科学计数法。例如,{value:.6g} 会将 value 格式化为 6 位有效数字,并根据需要选择最合适的表示方式。(如 123.456)或科学计数法(如 1.23456e+02)。
String and Methords
range and list and dict
dict = {'a':1, 'b':2, 'c':3, 'd':1}
values = dict.values()
print(values)
output: dict_values([1, 2, 3, 1])
返回dict_values对象,其是一个可迭代对象,同时可通过list(values)得到列表
tips:
list()是一个内置函数,任何可迭代对象(iterable)可以通过list()转换为列表。
more detail
了解上述知识后就很好理解如下常见代码:
for i in range(5):
print(i)
range 是一个内建的函数,返回的是一个 range 对象, range为可迭代对象。
所有可迭代对象均可如上使用for进行循环迭代。
上述dict.values()是获得字典中value的方法,那有没有什么方法可以获得key呢?
dict = {'a':1, 'b':2, 'c':3, 'd':1}
keys = dict.keys()
print(keys)
output: dict_keys(['a', 'b', 'c', 'd'])
python中同样可以使用dict[a] dict[a] = 2访问和修改dict
tips: 在 Python 中,如果你在一个类中实现了 getitem 和 setitem 方法,你的类将支持索引操作和项赋值操作。这意味着你可以使用方括号([])来获取和设置对象的属性.
class MyDict:
def __init__(self):
self.data = {}
def __getitem__(self, key):
print(f"Getting value for key: {key}")
return self.data[key] # 获取字典中的值
def __setitem__(self, key, value):
print(f"Setting value for key: {key} to {value}")
self.data[key] = value # 设置字典中的值
__getitem__ 方法定义了如何通过索引来访问对象中的元素。当你使用 obj[key] 语法时,Python 会调用 obj.__getitem__(key) 方法。
__setitem__ 方法定义了如何通过索引来修改对象中的元素。当你使用 obj[key] = value 语法时,Python 会调用 obj.__setitem__(key, value) 方法。
列表推导式(List Comprehension): 创建列表的语法糖, 基本结构如下:
#[expression for item in iterable if condition]
nodes_values = [
{
"func_name": x.func_name,
"module_name": x.module_name,
"cycles": x.get_cycles(),
}
for x in graph.nodes()
]
expression通常为一个对象,这里为一个字典对象。
for x in graph.nodes()即for item in iterable
生成表达式
生成器表达式是一种惰性计算的语法结构,用于按需生成值,而不是一次性生成所有值。它的语法与列表推导式(List Comprehension)非常相似,但使用圆括号 () 而不是方括号 []。
(表达式 for 变量 in 可迭代对象 if 条件)
示例
# 生成器表达式
gen = (x * 2 for x in range(5) if x % 2 == 0)
# 输出
for value in gen:
print(value)
输出:
0
4
8
生成器表达式是迭代器
生成器表达式返回的是一个生成器对象,而生成器对象是 Python 中的一种迭代器。因此,生成器表达式具有迭代器的所有特性:
迭代器的特性:
- 惰性计算:值是按需生成的,而不是一次性生成所有值。
- 只能遍历一次:生成器对象在遍历完后会被耗尽,无法再次使用。
- 支持
next()函数:可以通过next()逐个获取值。
gen = (x for x in range(3))
# 使用 next() 逐个获取值
print(next(gen)) # 输出 0
print(next(gen)) # 输出 1
print(next(gen)) # 输出 2
print(next(gen)) # 抛出 StopIteration 异常
Python Iterators
可迭代对象(Iterable objects)是一个容器,我们使用iter()方法可得到迭代器(Iterator)。Lists, tuples, dictionaries, and sets这些数据类型都是可迭代对象。
在 Python 中,要使一个类成为可迭代对象(Iterable),需要在类中实现 __iter__ 方法,且这个方法应该返回一个迭代器,迭代器本身必须实现 __next__ 方法。
迭代器是一个包含
__iter__方法和__next__方法的对象。
__iter__进行初始化操作最终返回一个迭代器
__next__最终返回下一个元素
class MyIterable:
def __init__(self, start, end):
self.start = start
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.start >= self.end:
raise StopIteration
self.start += 1
return self.start - 1
上述例子中,我定义了一个类MyIterable,在__iter__其返回了一个迭代器即自身(因为MyIterable也实现了__next__所以MyIterable也算迭代器)。所以实现了MyIterable为一个可迭代对象。
class NodeTable:
def __init__(self, nodes: Dict[str, Node] | None = None):
self._nodes: Dict[str, Node] = node if nodes else {}
def __iter__(self):
return iter(self._nodes)
上述例子中__iter__中因为dictionaries本身就是可迭代对象,通过iter()得到字典的迭代器并返回,所以使得NodeTable成功实现为了可迭代对象
可迭代对象使用迭代器能够通过next函数访问元素:
mytuple = ("apple", "banana", "cherry")
myit = iter(mytuple)
print(next(myit))
print(next(myit))
print(next(myit))
Python lamba表达式
df["semantics"] = df["symbol"].map(
lambda x: next((k for k, v in semantics_mapping.items() if x in v), None)
)
这段代码的作用是为 DataFrame 的 symbol 列创建一个新列 semantics,其值基于 semantics_mapping 字典的映射。我将用通俗易懂的方式逐步解释每个语法元素,并提供具体示例帮助你理解。
lambda 表达式:
lambda是 Python 中定义匿名函数的关键字,用于快速创建小型临时函数。- 语法:
lambda 参数: 表达式 - 特点:没有函数名,只能包含单行表达式,自动返回结果。
lambda x: next((k for k, v in semantics_mapping.items() if x in v), None)
- 参数:
x是输入值(即 DataFrame 中symbol列的每个值)。 - 表达式:
next(...)是返回值。
next() 函数:
next(iterator, default)用于从迭代器中获取下一个元素。- 参数:
iterator:可迭代对象(如生成器、列表等)。default(可选):当迭代器耗尽时返回的默认值。
生成器表达式 (k for ...):
- 生成器表达式用于惰性生成值,逐个产生结果,节省内存。
- 语法:
(表达式 for 变量 in 可迭代对象 if 条件)
代码中的生成器:
(k for k, v in semantics_mapping.items() if x in v)
- 遍历:
semantics_mapping.items()的每个键值对(k, v)。 - 条件:如果当前
x(symbol的值)在v(字典值的列表)中。 - 返回值:符合条件的键
k。
Python Built-in functions
len
- 输入:可迭代对象
- 输出:可迭代对象元素个数
list = [1,2,3,4]
print(f"len: {len(list)}")
df = pd.read_csv(file)
print(f"rownum: {len(df)}")
map
- 输入:可迭代对象
- 输出:迭代器
- 作用:对一个可迭代对象(例如列表、元组、字符串等)中的每个元素应用一个指定的函数,并返回一个迭代器,其每个元素都是函数作用后的结果。
list = [1,2,3,4]
list_2 = list(map(lamba x: x*x, list))
join
separator.join(iterable)
- separator:分隔符字符串。这个字符串将插入到每个被连接的字符串之间。
- iterable:一个可迭代对象,其中的每个元素都应当是字符串。如果其中有非字符串类型,会抛出异常。
- 输出:字符串
function = ['add', 'sub','mul']
pattern = '|'.join(function)
Python Pandas
Pandas Basics
Pandas Series and DataFrames
Series对象就像表格中的一列:
| index | value |
|---|---|
| x | 1 |
| y | 7 |
| z | 2 |
values = [1, 7, 2]
myseries = pd.Series(values, index = ["x", "y", "z"])
若去除index,即myseries = pd.Series(values)那么下标默认为1,2,3...
除了list可以转换为series,dict同样可以转换:
dict = {"x":1, "y":7, "z":2}
myseries = pd.Series(dict)
Note: The keys of the dictionary become the labels(index).即上述代码效果和上述表格一致
按照上述思路,DataFrame就像表格:
| index | Name | Age | Salary |
|---|---|---|---|
| 0 | Alice | 25 | 500 |
| 1 | Bob | 30 | 600 |
| 2 | Charlie | 35 | 700 |
列表和字典同样可以转换为DataFrame:
data1 = [
["Alice", 25, 500],
["Bob", 30, 600],
["Charlie", 35, 700]
]
df = pd.DataFrame(data1, columns=["Name", "Age", "Salary"], index=[1,2,3])
data2 = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"Salary": [500, 600, 700],
}
df = pd.DataFrame(data2, index=[1,2,3])
simple info
df.head(n) # 表头数据
df.tail(n) # 表尾巴数据
df.info() # 总结各列数据信息
# output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 3 non-null object
1 Age 3 non-null int64
2 Salary 3 non-null int64
dtypes: int64(2), object(1)
memory usage: 204.0+ bytes
None
Pandas 寻找子集
.isin
.isin() 用于检查 DataFrame 或 Series 中的每个元素是否属于给定的序列(例如列表、集合、Series 等)中的某个值。
import pandas as pd
data = {'symbol': ['AAPL', 'GOOG', 'MSFT', 'AMZN'],
'price': [150, 2800, 300, 3500]}
symbols_to_keep = ['AAPL', 'MSFT']
filtered_df = df[df['symbol'].isin(symbols_to_keep)]
print(filtered_df)
.str.contains
.str.contains() 用于判断 Series 中每个字符串是否包含指定的子串或正则表达式模式。
import pandas as pd
data = {'symbol': ['AAPL_Inc', 'Google LLC', 'MSFT_Corporation', 'Amazon.com']}
pattern = 'LLC|Corporation'
filtered_df = df[df['symbol'].str.contains(pattern, regex=True, na=False)]
print(filtered_df)
Python Numpy
对于一个 1000 万个元素的数组(成为向量或矢量)乘法操作,NumPy 使用方法跟单个值(称为标量)完全一致。
即对于Numpy不管是x = np.arange(10000000)还是x = np.array([1]),都可以使用x * 2直接对全部元素乘2
这种高效且简易操作的 NumPy 数组其正式对象名为 ndarray
ndarray
创建ndarray
其实从DataFrame或Serial中通过.values得到的也是ndarray:
df = pd.read_csv['xxx']
lab1 = df['lab1'].value()
print(type(lab1))
# 输出
<class 'numpy.ndarray'>
Python Matplotlib
对数分箱和对数轴
对数轴
在此对数能够很好地处理跨越多个数量级、且在低值或高值段分布不均的数据,使得数据图在各个数量级上都能清晰展示数据分布情况。
例如:
from matplotlib import pyplot
a = [ pow(10,i) for i in range(10) ]
pyplot.subplot(2,1,1)
pyplot.plot(a, color='blue', lw=2)
pyplot.show()
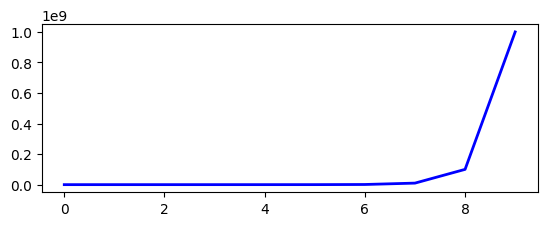
对于a数据集[1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000, 1000000000],大部分数据都在1~1000000,但是上述图因为y轴数据范围的问题,缺失掉了大部分数据信息
加上pyplot.yscale('log')可解决这个问题:
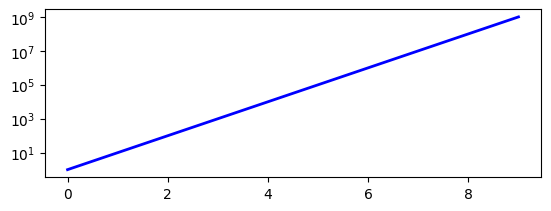
The relevant function is pyplot.yscale(). If you use the object-oriented version, replace it by the method Axes.set_yscale(). Remember that you can also change the scale of X axis, using pyplot.xscale() (or Axes.set_xscale()).
stackover flow Plot logarithmic axes
对数分箱
同样对于低值或高值段分布不均的数据,例如我想要统计这些数据在不同区间上的Count并用直方图显示出来,应该如何办?
第一步需要考虑如下划分区间:
stack overflow: How to have logarithmic bins in a Python histogram
首先可以考虑下numpy中的自动分箱技术:numpy.histogram(a, bins='auto', range=None)
- a: 输入数据(一维数组)
- bins: 分箱策略(支持字符串如 'auto', 'fd', 'sturges', 'sqrt' 等)
- range: 数据范围(默认为数据的最小/最大值)
- numpy.histogram 的返回值是一个包含两个数组的元组:直方图频数(hist)和分箱边界(bin_edges)
import numpy as np
data = [1, 2, 3, 4]
hist, bin_edges = np.histogram(data, bins=2)
假设输入数据为 data = [1, 2, 3, 4],分箱策略为 bins=2:
-
hist = [2, 2]
分箱1(1.0 到 2.5):包含数据点 1 和 2 → 计数值为 2。
分箱2(2.5 到 4.0):包含数据点 3 和 4 → 计数值为 2。 -
bin_edges = [1.0, 2.5, 4.0]
分箱边界:共 3 个值(2 个分箱需要 3 个边界)。
可用这个直接画出直方图:
import matplotlib.pyplot as plt
data = np.random.randn(1000)
hist, bin_edges = np.histogram(data, bins='auto')
# 绘制直方图
plt.bar(bin_edges[:-1], hist, width=np.diff(bin_edges), edgecolor='black')
plt.title("Histogram with Auto Bins")
plt.show()
若考虑到对数问题,则可以手动在数据上进行log10
import numpy as np
import matplotlib.pyplot as plt
data = 10**np.random.normal(size=500)
_, bins = np.histogram(np.log10(data + 1), bins='auto')
plt.hist(data, bins=10**bins);
plt.gca().set_xscale("log")
data + 1是为了避免数据出现==0的数据
也可以通过np.logspace实现,np.logspace 是 NumPy 提供的生成对数刻度数组的函数,其核心功能是“在对数空间内等距、在原始空间内等比”地生成一系列数值。
numpy.logspace(start, # 对数刻度起点(指数)
stop, # 对数刻度终点(指数)
num=50, # 生成样本数量
endpoint=True, # 是否包含 stop 指数对应的值
base=10.0, # 对数底,默认 10
dtype=None,
axis=0)
import numpy as np
# 例:生成从 10^1 到 10^3 的 3 个对数等距点
log_bins = np.logspace(1, 3, num=3)
print(log_bins) # 输出 [ 10. 100. 1000.]
# 验证等比关系
ratios = log_bins[1:] / log_bins[:-1]
print(ratios) # 输出 [10. 10.] 公比恒定为 10
- 返回值类型:numpy.ndarray,长度为 num,元素为浮点数
- start, stop:通常取 log10(min_value) 和 log10(max_value);
- 缺点是需要手动指定num:所需分箱边界数(通常等于分箱数或分箱数+1);
np.logspace和np.联动
bins = np.logspace(np.log10(runtime.min()), np.log10(runtime.max()), num=20)
counts, bin_edges = np.histogram(runtime, bins=bins)
或者选择使用plt.hist直接画出来:
import pylab as pl
import numpy as np
data = np.random.normal(size=10000) # 一个一维ndarray数组
pl.hist(data, bins=np.logspace(np.log10(0.1),np.log10(1.0), 50))
pl.gca().set_xscale("log")
pl.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号