MASM汇编语言知识
练习心得
在汇编中 X DB 12H 和 X EQU 12H 的区别?
- X DB 12H:这表示将一个字节数据12H存储到变量X中。DB是"Define Byte"的缩写,用于定义一个字节长度的数据项。因此,X DB 12H可以看作是将一个字节大小的空间分配给变量X,并将值12H存储到这个空间中。
- X EQU 12H:这表示将符号常量X定义为12H。EQU是"Equation"的缩写,用于定义符号常量。符号常量不会在内存中分配空间,它们只是一个标签,用于在程序中代表一个固定的数值。因此,X EQU 12H可以看作是将符号常量X定义为12H,在程序中使用X时,会自动替换为12H。
即 EQU有点像C语言中的define
那么汇编中 = 与 EQU 的区别又是什么?
1、使用equ伪指令定义的符号名不能与其它符号名重名,符号名必须唯一,且不能被重新定义;
而使用等号伪指令"="定义的符号名可以重名,可以被重新定义,可被重新赋值。
2、使用equ伪指令定义的符号名不仅可以代表某个常数或常数表达式,还可以代表字符串、关键字、指令码、一串符号(如:word ptr),等等;
而使用等号伪指令"="定义的符号名仅仅用于代表数值表达式。
来看看$在汇编中的使用
汇编地址计数器用符号$表示,它用来记录正在被汇编程序翻译的语句的地址,即$的内容标示了汇编程序当前的工作位置。
在一个源程序中往往包含多个段。汇编程序在将该源程序翻译成目标程序时,每遇到一个新的段,就为该段分配一个初置为0的汇编地址计数器,
然后,再对该段中的语句汇编。在汇编过程中,对凡是需要申请分配存储单元的语句和产生目标代码的语句,汇编地址计数器则按该语句目标代码的长度增值。
(注意这段话说明$随着我们写汇编代码时,是会变的)
因此,段内定义的所有标号和变量的偏移地址就是翻译该语句时当前汇编地址计数器$的值。
字符串终止符
例如’i like myself$’,在上述字符串中对应于计算机语言中的\0,字符串的终止。
来理解一些 ? 在汇编中的使用
其一般用在初始化中
如初始化缓冲区:
BUF DB 81
DB ?
DB 80 DUP(0)
如初始化数组
BUF DB 80 DUP(?)
都表示将位置预留下来,代后面进行输入数据时 等 在填充上去
比如初始化缓冲区,第1个字节(从0开始的计数)要表示本次实际输入的字符个数
但是在定义时,我们是不知道要输入多少个字符的,所以首先用?代替
但输入完成,电脑自动添加
来理解一下 PTR 与 THIS 的区别
PTR与THIS都可以将其理解为指针
他们都可以建立一个指定类型的地址操作数
只是在使用上有点不同:
PTR使用如下:
ARRAY1 DB 100 DUP(?)
ARRAY2 EQU WORD PTR ARRAY1
这个操作使得 ARRAY1 与 ARRAY2 指向了同一个地址
但是ARRAY1是按照字节读写
ARRAY2是按照字读写
THIS使用如下
ARRAY2 EQU THIS WORD
ARRAY1 DB 100 DUP(?)
这个作用于上面相同
MOV ax,1234H 与 MOV ax,1234 的区别
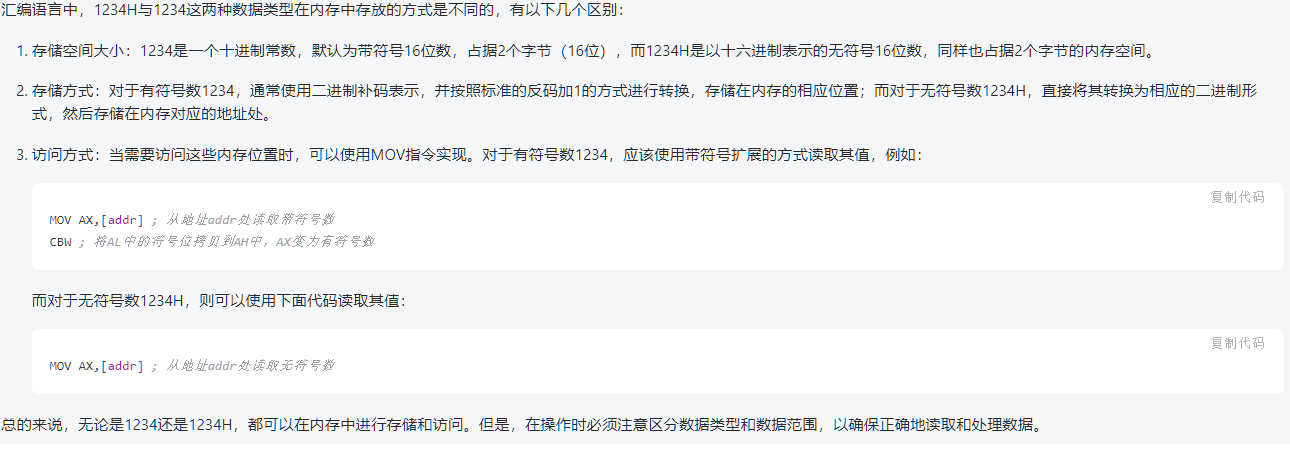
SEG OFFSET TYPE 数值返回运算符
MOV AX,SEG ARR
MOV BX,OFFSET BUF
MOV BX,TYPE ARR
遇到的坑
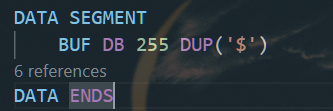
注意在写 $ 时,一定要加上‘’
否则会爆 constant expected 的错误,同时也会附带一些其他神奇的错误
MOV AX,BX 与 MOV AX,[BX] 的区别是什么?
前者是将BX中保存的值直接给AX
后者是通过BX中保存的值寻址后将找的地址中的内容 给AX
那么也就能够理解 MOV [AX],BX 与上述指令的区别了
这个是将BX中保存的值传给 通过AX值寻址后的地址中的内容
需要注意的是:
MOV BYTE PTR CL,[BUF+1]
这种行为是不允许的
同时MOV WORD PTR BX,AX
等这种行为都是不合法的
主要是因为寄存器的大小是固定的,即不能用 xxx PTR来修饰 寄存器
否则会喜提:

《c与masm汇编的对应》
//如何定义String,与cin,cout String?
STR DB 0DH,0AH,'STRING$'
//cin>>
BUF DB 81//定义缓冲区大小
DB ?//指明实际输入字符串的长度,?自动填充
DB 80 DUP('$')//需要注意字符串最后需要$,这里将缓冲区全部初始为$
LEA DX,BUF
MOV AH,10
INT 21H
//cout<<
LEA DX,STR
MOV AH,9
INT 21H
//如何定义Char/Int,与cin cout Char/Int?
CHAR DB 'a'
MOV AH,2
INT 21H
//cin>>
//从键盘中读入一个字符,保存到AL中
MOV AH,1
INT 21H
//cout<<
MOV DL,CHAR
MOV AH,2
INT 21H
//如何实现if = != > >= < <= go ?
CMP NUM1,NUM2
//=
JE
//!=
JNE
//>
JA//无符号数之间的比较
JG//有符合数之间的比较
//>=
JAE
JGE
//<
JNAE
JNGE
//<=
JNA
JNG
//go
JMP
//如何实现 + - * / % >> << ++ -- & | ^ ~
//++
INC NUM
//--
DEC NUM
//+
ADD NUM1,NUM2 //不带进位
ADC NUM1,NUM2 //带进位
//-
SUB NUM1,NUM2
SBB NUM1,NUM2
//*
//无符号乘
MUL NUM //当NUM为字节数据 AL * NUM -> AX
//当NUM为字数据 AX * NUM -> DX AX
//带符号乘
IMUL NUM
// /
//无符号除
DIV NUM//当NUM为字节数据 AX/NUM -> AL(商)AH(余数)
//当NUM为字数据(DX AX)/NUM -> AX(商)DX(余数)
//带符号除
IDIV NUM
// &
AND NUM1,NUM2
// |
OR NUM1,NUM2
// ^
XOR NUM1,NUM2
// ~
NOT NUM
// >>
SAR NUM,CL//算数,考虑符号位
SHR NUM,CL//逻辑
// <<
SAL NUM,CL
SHL NUM,CL
//如何实现for循环?
LOOP NEXT //CX-1!=0 是进行循环
//如何实现函数声明?
子程序名 PROC [NEAR/FAR]
.
.
.
子程序名 ENDP
//需要注意的是,在调用子程序时,父程序需要 CALL 子程序名
//在子程序返回时,需要 RET
//同时需要保存现场:即将父程序中用到的寄存器中的值保存下来,一般是保存到堆栈,然后子程序在RET之前再恢复现场
//具体来说如下:
TEST PROC
PUSH AX
PUSH BX
PUSH CX
PUSH DX
.
.
.
POP DX
POP CX
POP BX
POP AX
TEST ENDP
//如何让多个asm程序一起工作?
//这里有点像java了
当在一个asm程序中如果想能够其他asm程序使用其中的变量,函数,常量等,则需要在前标记上 PUBLIC
如果想要引入其他asm程序中的变量,函数,常量等,则需要再前标记上 EXTRN
变量的类型有 BYTE WORD DWORD
函数(标号)的类型有 NEAR FAR
常量的类型为 ABS
如下,现在有两个模块 MODE1.ASM MODE2.ASM
NAME MODE1.ASM
PUBLIC STR1,N,BUF
DATA1 SEGMENT
STR1 DB 'CILINMENGYE'
N EQU $-STR1 ; 用EQU相当于定义了一个常量
BUF DB 'With the proliferation of $'
DATA1 ENDS
.
.
.
NAME MODE2.ASM
EXTRN STR1:BYTE,N:ABS,BUF:BYTE
PUBLIC DISP
DATA2 SEGMENT
DATA2 ENDS
.
.
.
CODE SEGMENT
.
DISP PROC FAR
.
.
.
DISP ENDP
.
CODE ENDS
END
需要注意的是我们的一个字符串在定义
STR DB "...."后
其中的一个字符是一个字节
因为我们的一个字符在计算机中实际是用ASCII码保存的
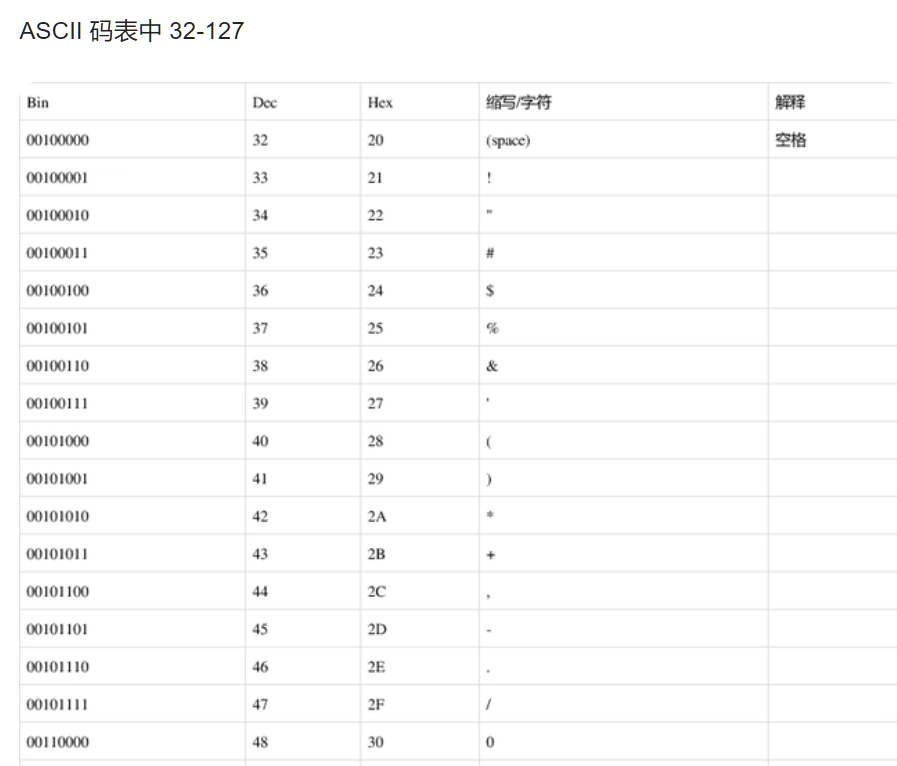
可以看到一个ASCII码8位,即一个字节大小
<汇编独有的特点>
特点一:利用标志位
AND AX,AX
JZ xxx
上述这条指令可以判断AX中的值是否为0
因为AND之后AX中的值不变,但是会改变标志位
如果AX中的标志位为0,那么标志位ZF=1,于是JZ就成立
JZ是条件转移符号,当ZF=1(即等于0)就转移
除了<< >> 操作可以影响CF
还有 ROL ,ROR (循环左移,右移)
还有RCL,RCR(带进位左移,右移)
可以影响
上述四条指令在对二进制下的数的某一位上的数进行操作十分好用
如:
XOR AX,AX
MOV BX,11
ROL BX,1
RCL AL,1
这样可以将BX中数(二进制下)的最高位移动到AX的第一位上中
同时还有JC 这个条件转移指令 当CF=1时 转移

 浙公网安备 33010602011771号
浙公网安备 33010602011771号