JDBC---初识
《基本介绍》

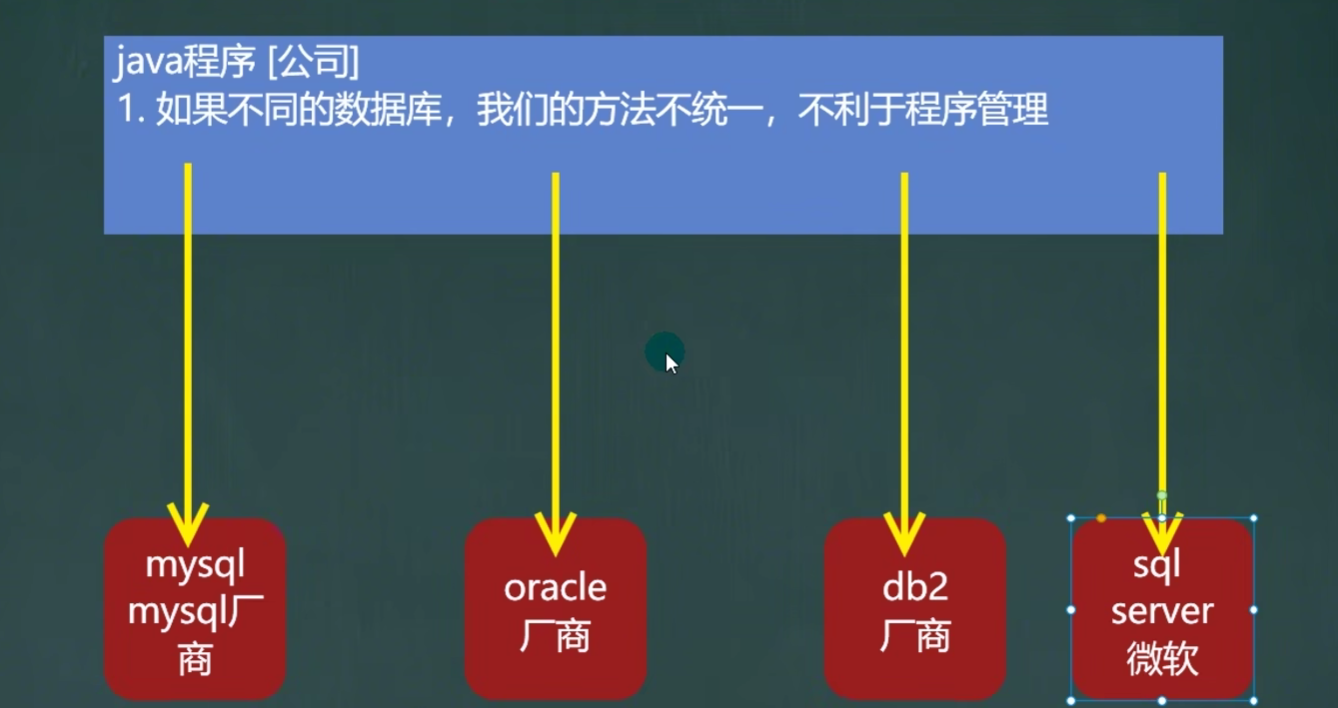
《需求》
当面对不同的数据库,如果直接用java操作数据库会使得对于不同的数据库有不同的方法,不统一
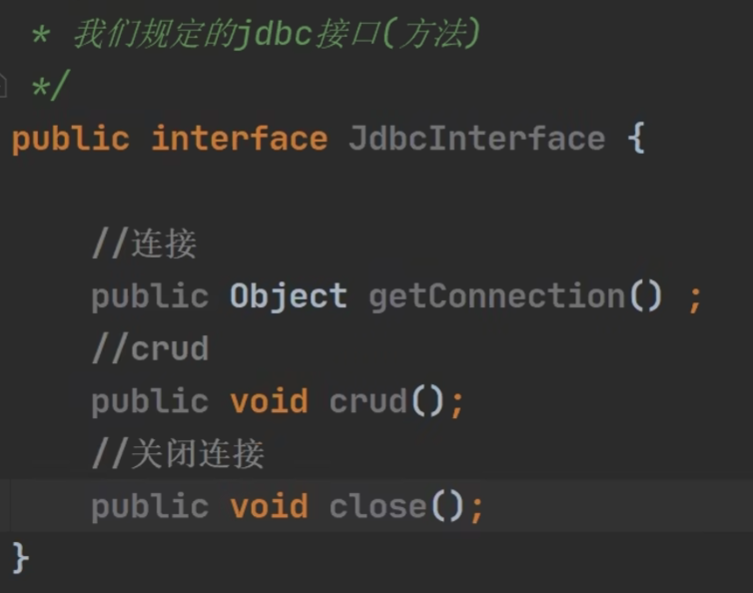
《解决》
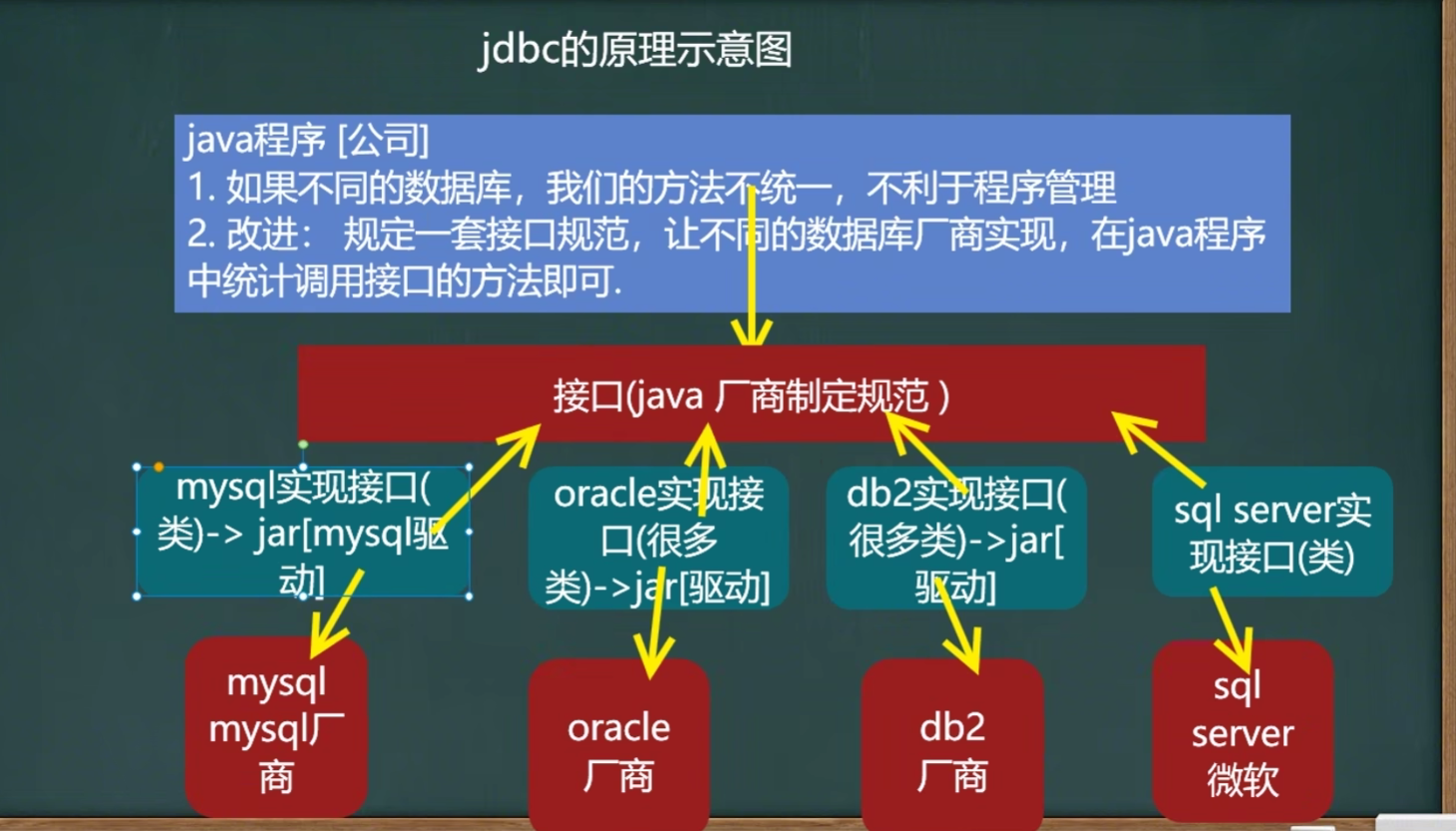
java厂商实现jdbc接口
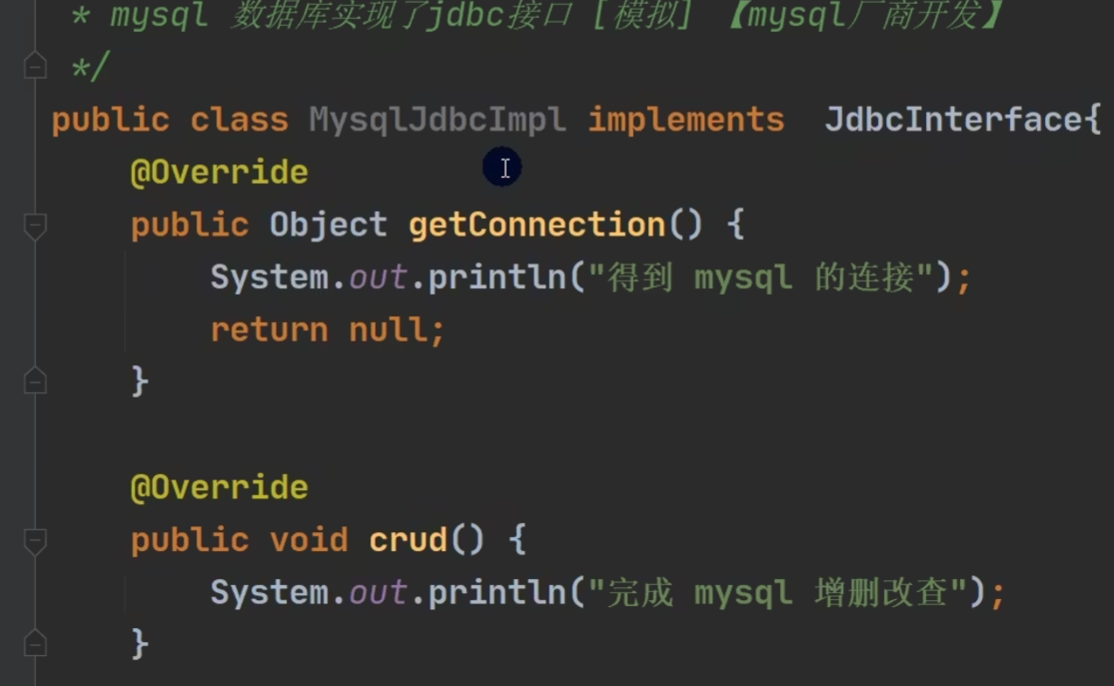
数据库厂商实现接口
程序员实现
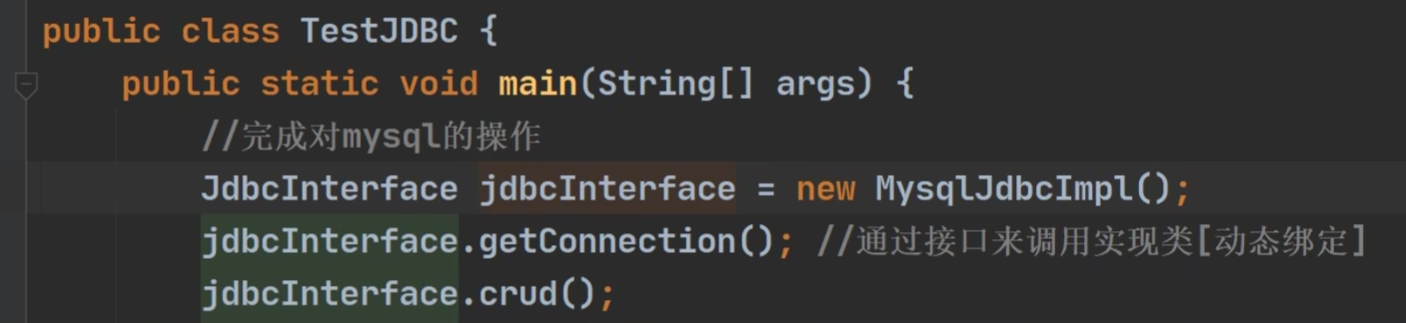
《JDBC》
《连接数据库》


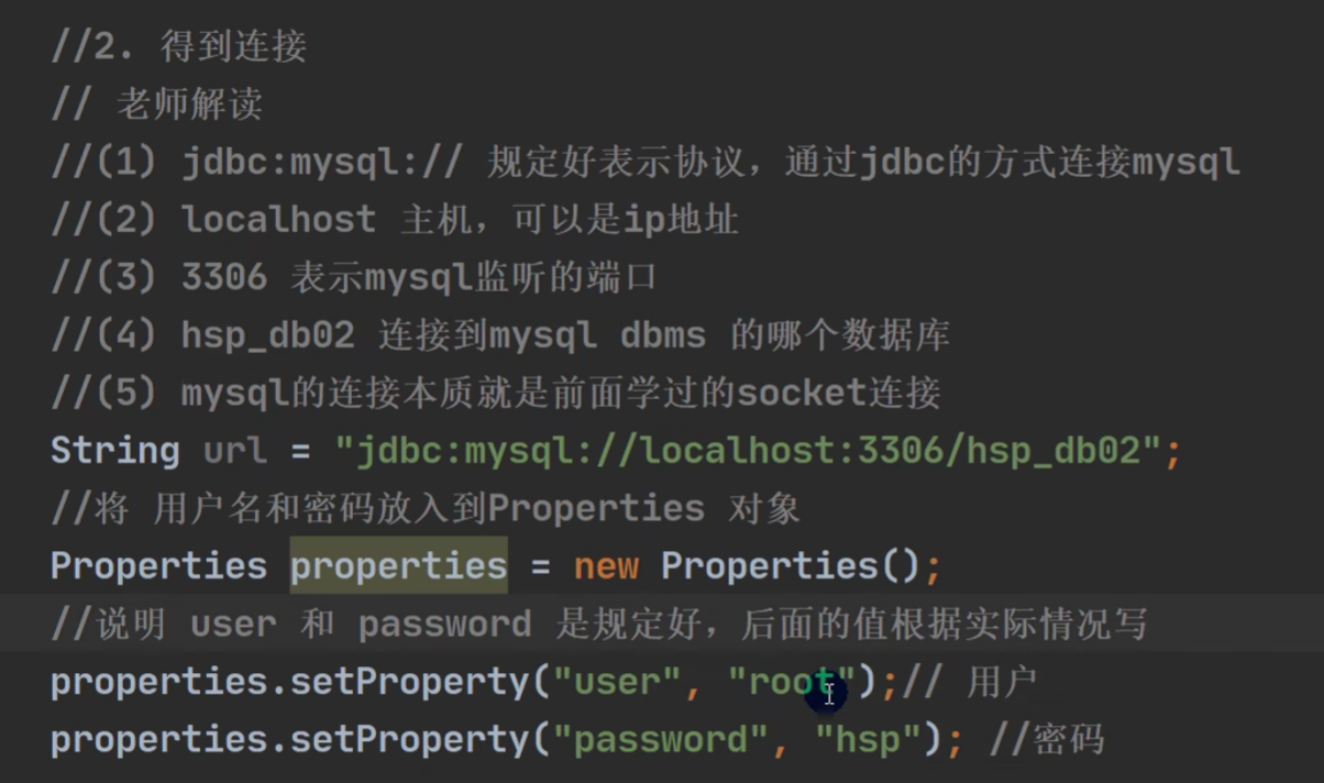



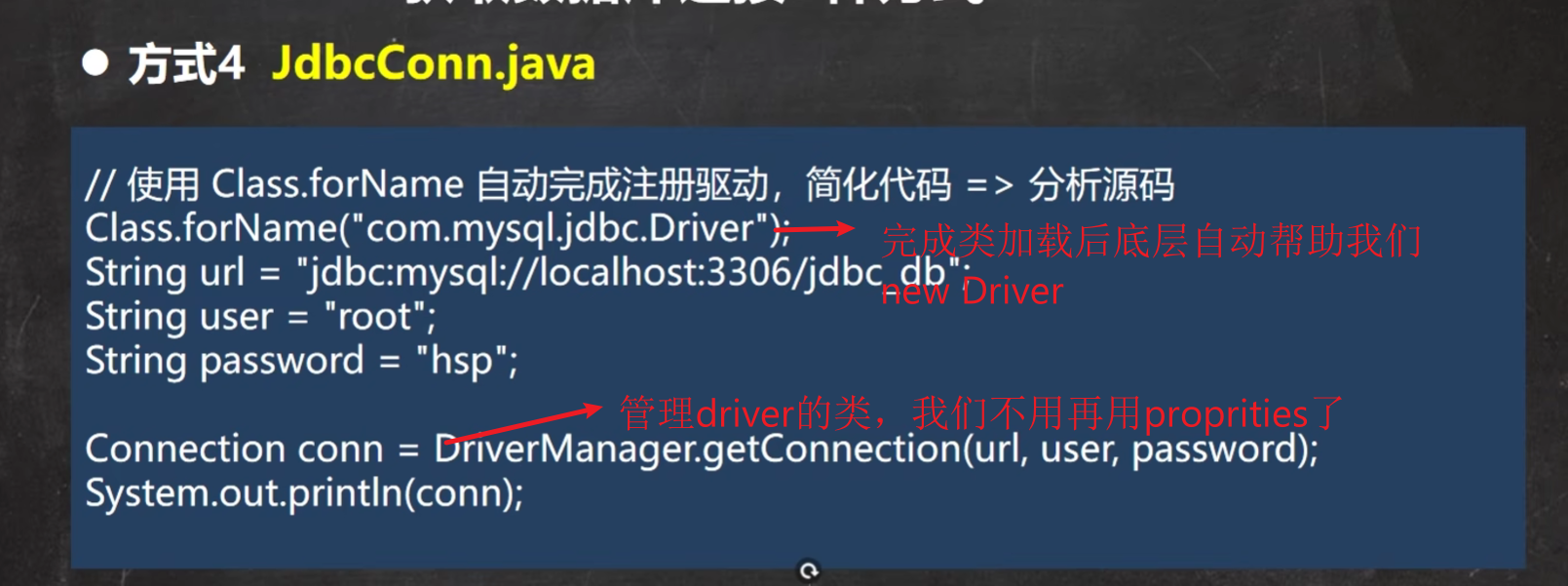
《用反射优化依赖性》

再一种连接方式:
《ResultSet》

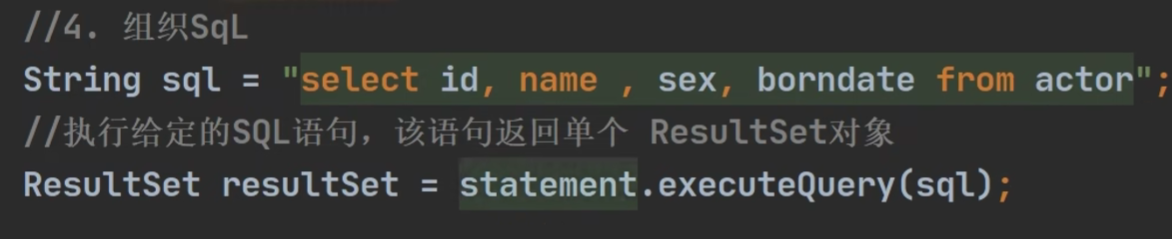
ResultSet这个类可以得到数据库返回的数据表
假设数据表如下(通过select sql语句来看):
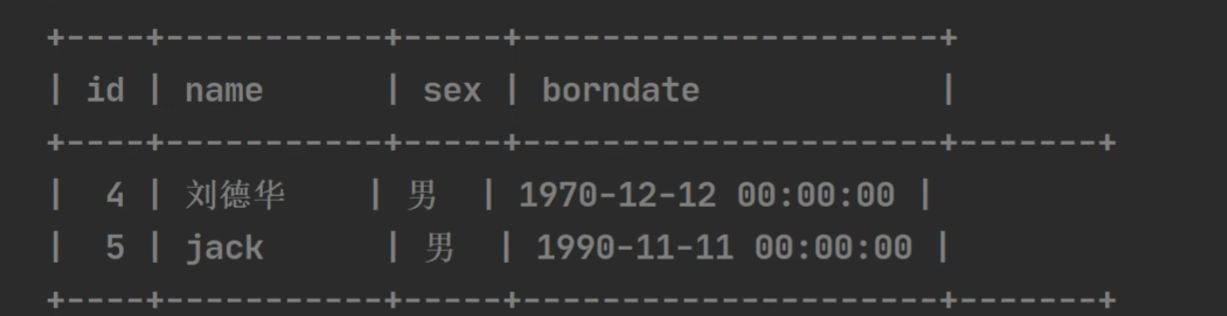
通过, 然后显示数据:
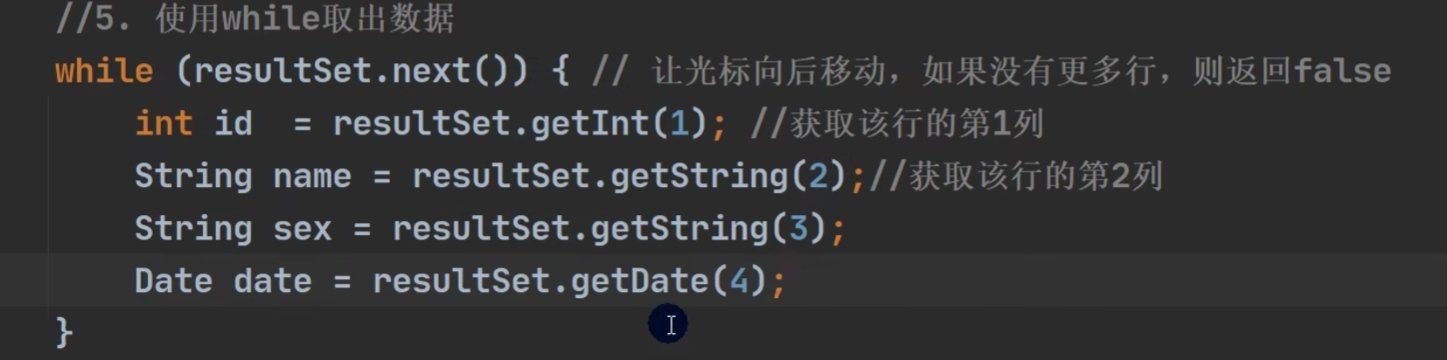
resultSet.getInt()等API也可以通过()里面写列名(`name`等)来查询

注意:resultSet.close
《SQL注入的风险与PreStatement的解决》

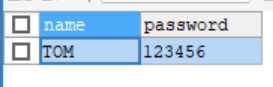
假设我有这一个表
我想通过输入正确的name与password能够显示相应的信息:
但是,通过一些手段可以输入不正确的信息也能够通过:

输入name='1' or,password=' or 1=1,可以使where 永久为true;
代码体现即为使用了字符串拼接的不安全性
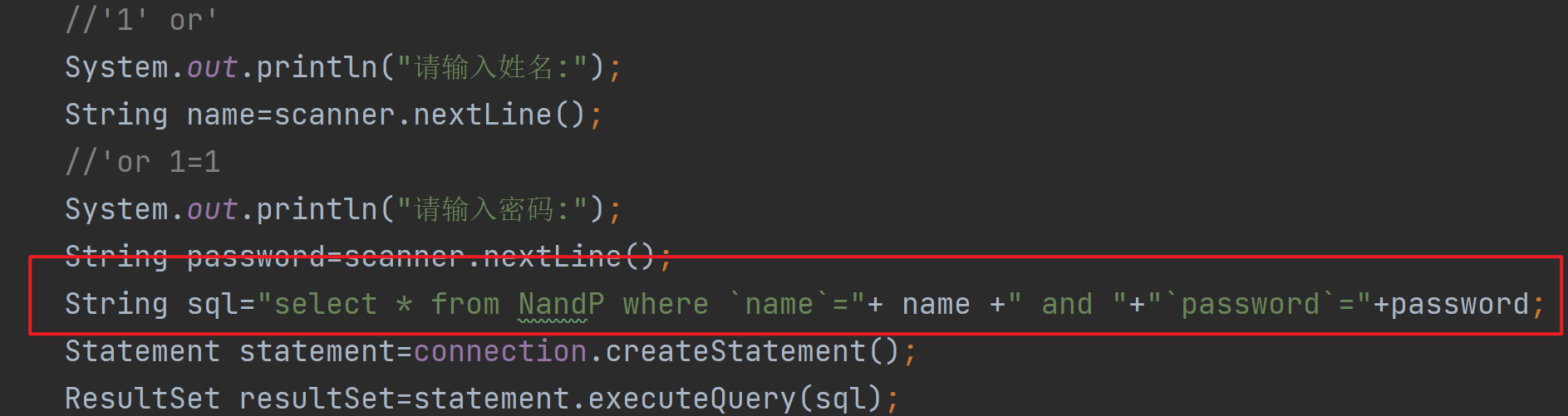
《解决》
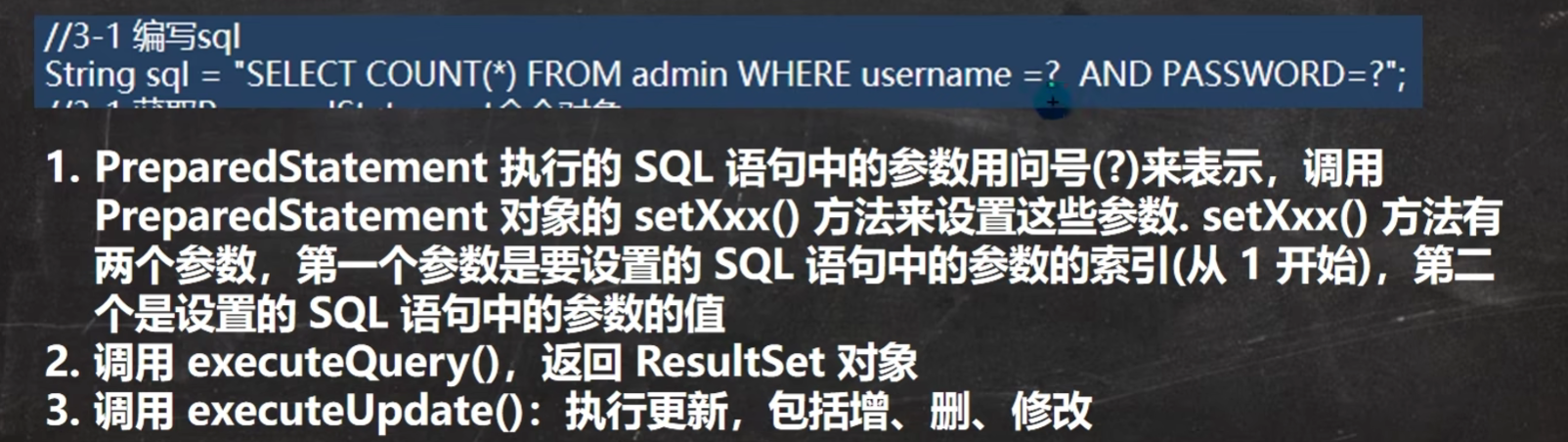

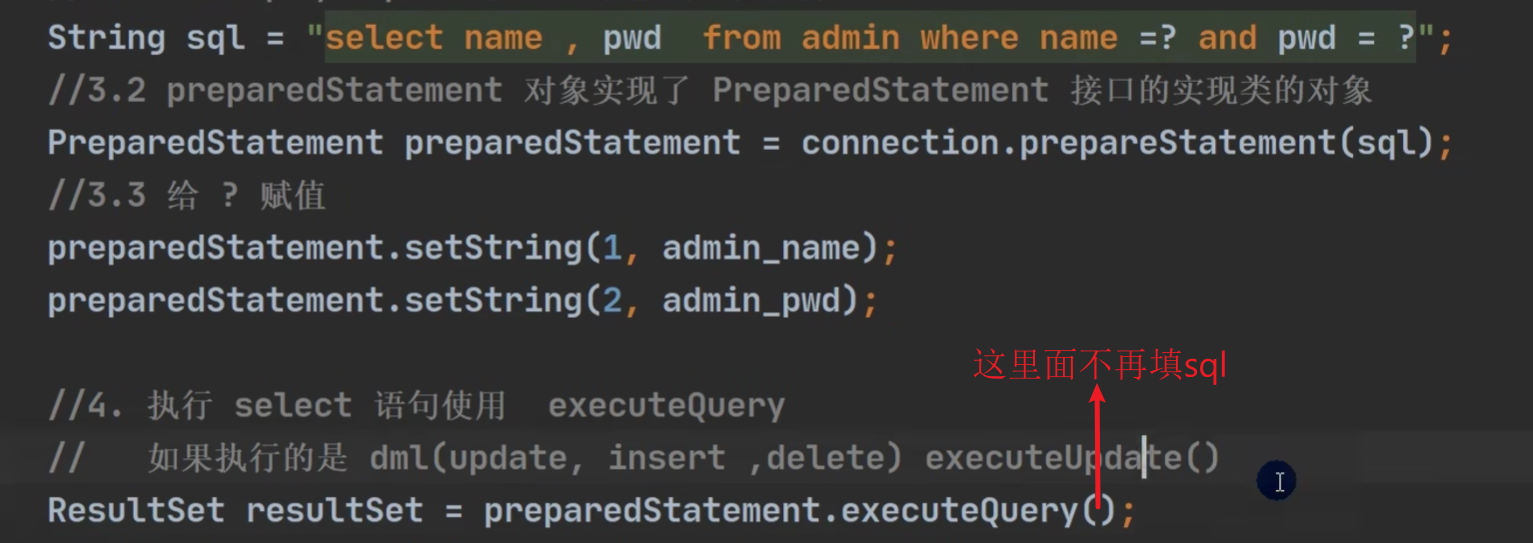

《事务》

1 class ConnectWay02 {
2 public static void main(String[] args) {
3 Connection connection = null;
4 PreparedStatement preparedStatement = null;
5 try {
6 connection = JdbcUtil.getConnection();
7 //相当于开启了一个事务
8 connection.setAutoCommit(false);
9
10 String sql1 = null;
11 preparedStatement = connection.prepareStatement(sql1);
12 preparedStatement.executeUpdate();
13 String sql2 = null;
14 preparedStatement = connection.prepareStatement(sql2);
15 preparedStatement.executeUpdate();
16
17 //到这里还没有异常,则提交
18 connection.commit();
19 } catch (SQLException e) {
20 //一旦发生了错误,可以在异常中捕获,实现回滚
21 //默认回滚到事务开始的地方
22 try {
23 connection.rollback();
24 } catch (SQLException ex) {
25 throw new RuntimeException(ex);
26 }
27 throw new RuntimeException(e);
28 } finally {
29 JdbcUtil.getClose(preparedStatement, connection, null);
30 }
31 }
32 }
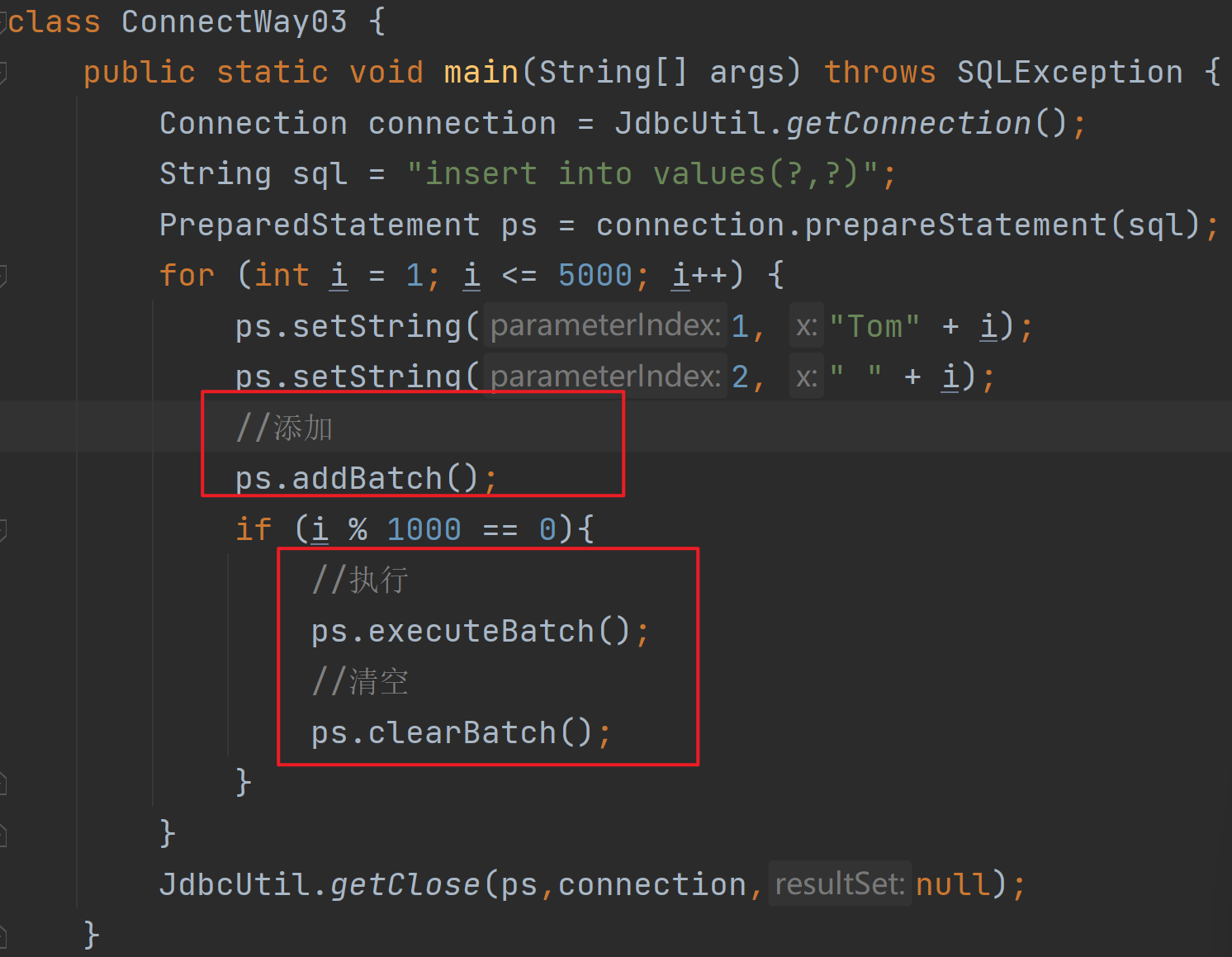
《批处理》


配置文件:

代码:
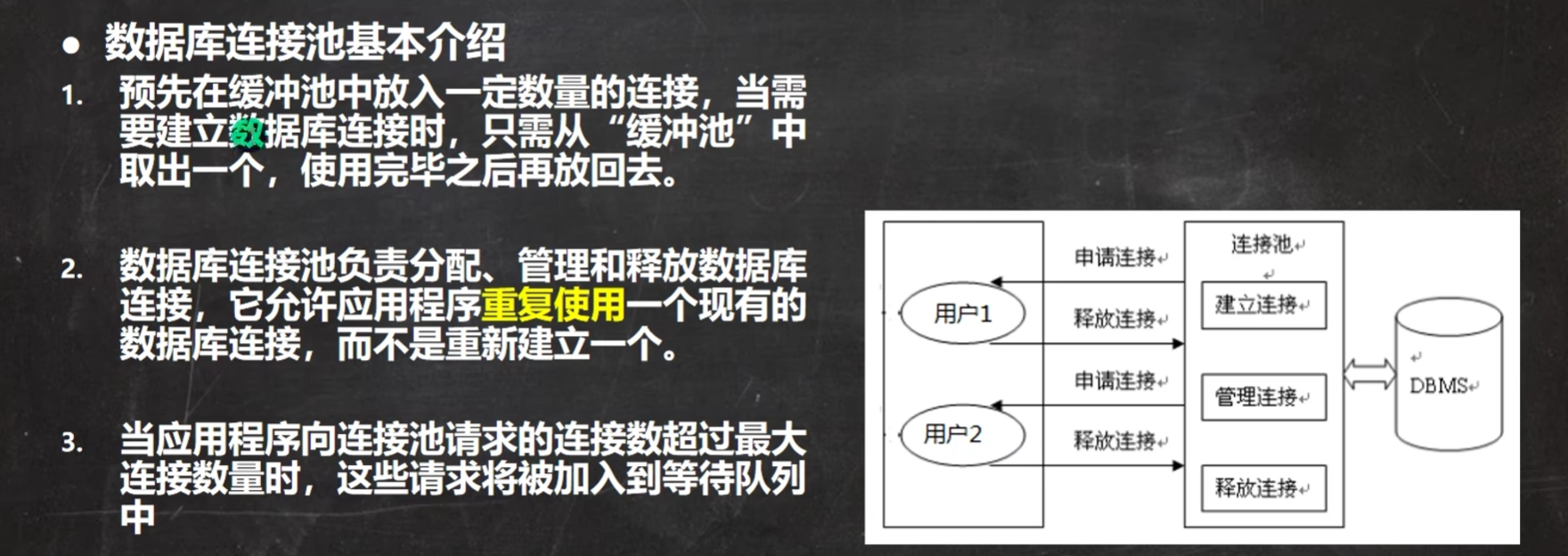
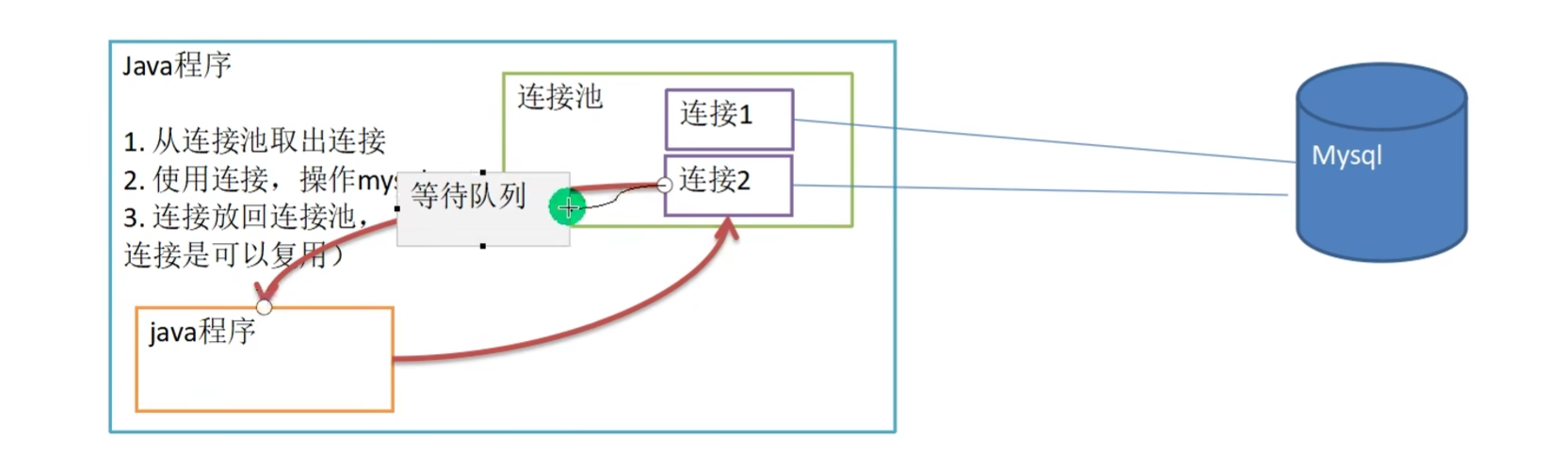
《数据库连接池》
《为什么要数据库连接池》

《数据库连接池原理》
《使用druid连接池》
1.安装.jar包
2.配置好文件
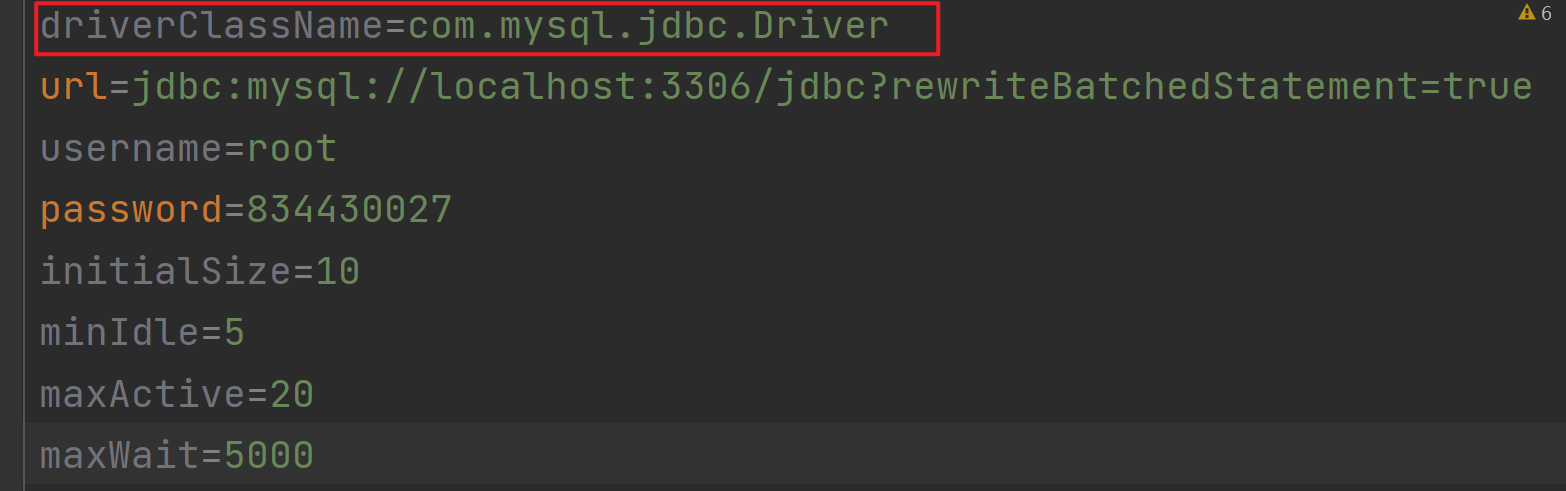
3.使用(我写了用druid连接池的连接工具包)
1 public class Druid_JdbcUtil {
2 static DataSource dataSource;
3
4 static {
5 Properties properties = new Properties();
6 try {
7 properties.load(new FileInputStream("src:\\druid.properties"));
8 dataSource = DruidDataSourceFactory.createDataSource(properties);
9 } catch (Exception e) {
10 throw new RuntimeException(e);
11 }
12 }
13
14 public static Connection getConnection() {
15 try {
16 return dataSource.getConnection();
17 } catch (SQLException e) {
18 throw new RuntimeException(e);
19 }
20 }
21
22 public static void getCLose(Connection connection, Statement statement, ResultSet resultSet) {
23 try {
24 connection.close();
25 statement.close();
26 resultSet.close();
27 } catch (SQLException e) {
28 throw new RuntimeException(e);
29 }
30 }
31 }
《解决resultSet结果集相关问题》
《问题》

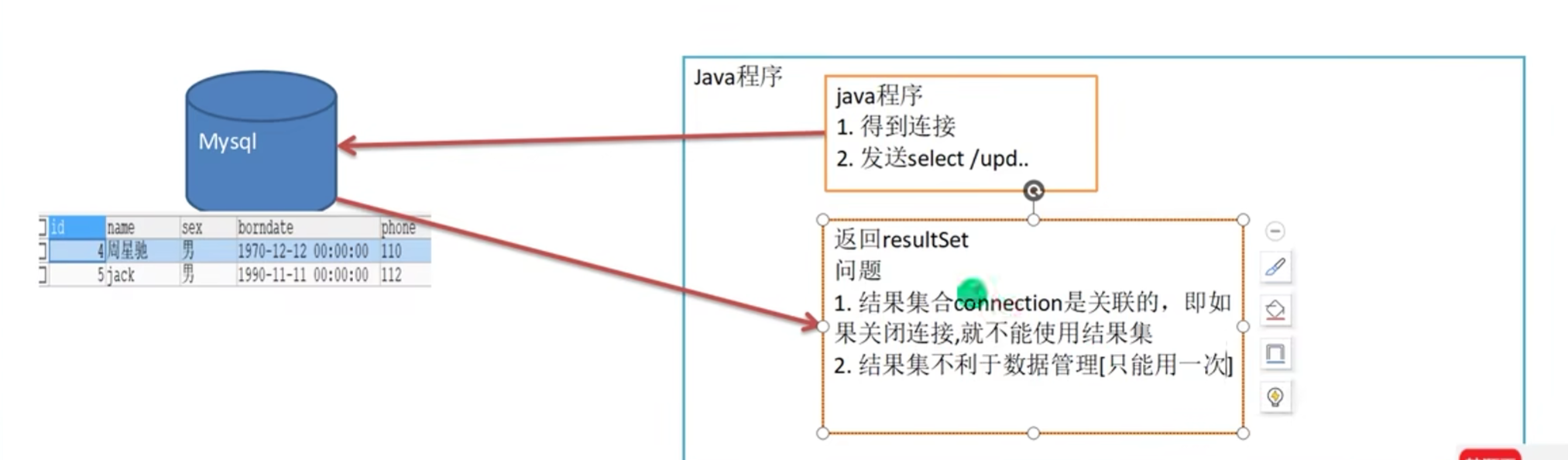
为什么说只能用一次?因为当查询完了后connection总是要有关闭的一天,但是这个数据我想长久的保存下来使用
但是一旦connection关闭了,resultSet就不能使用了
《解决方法》
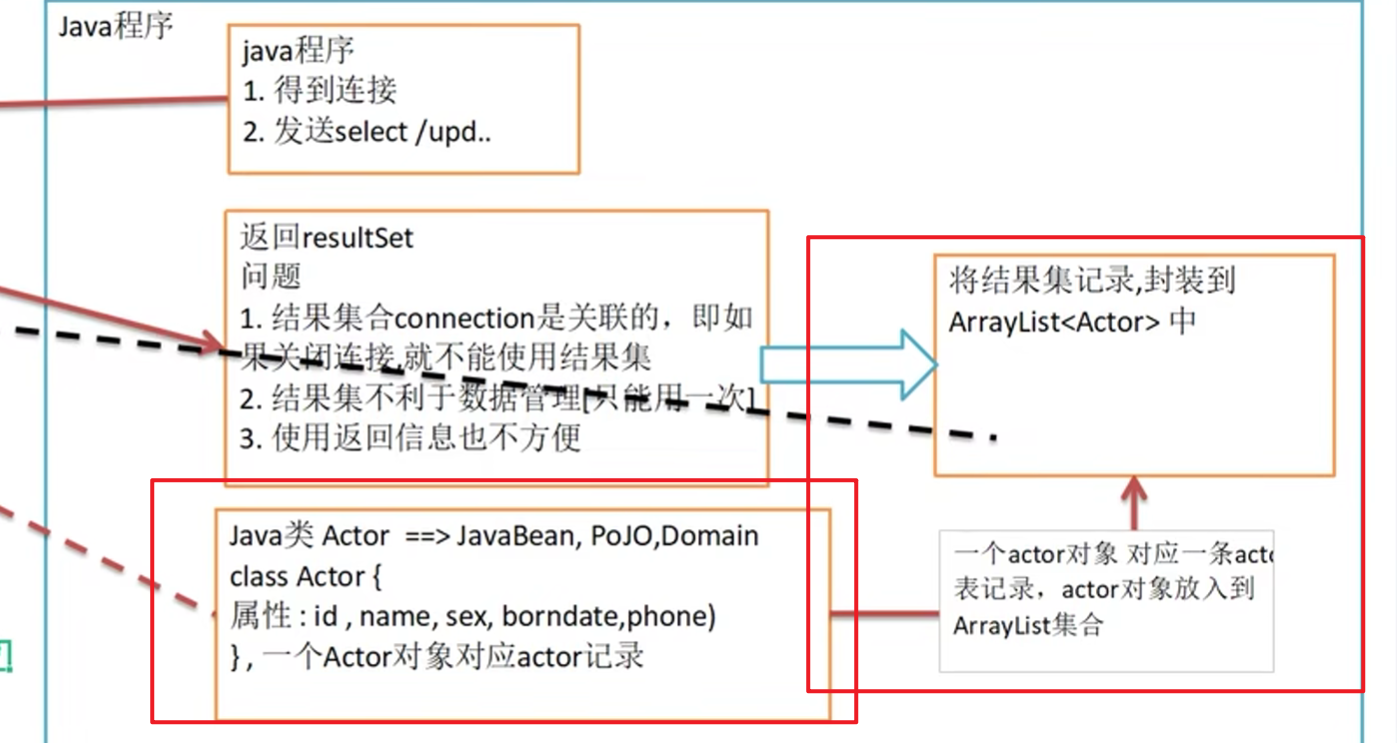
《工具》
我们自己也可以写个工具,封装List与类对象(javaBean)来实现解决这个问题
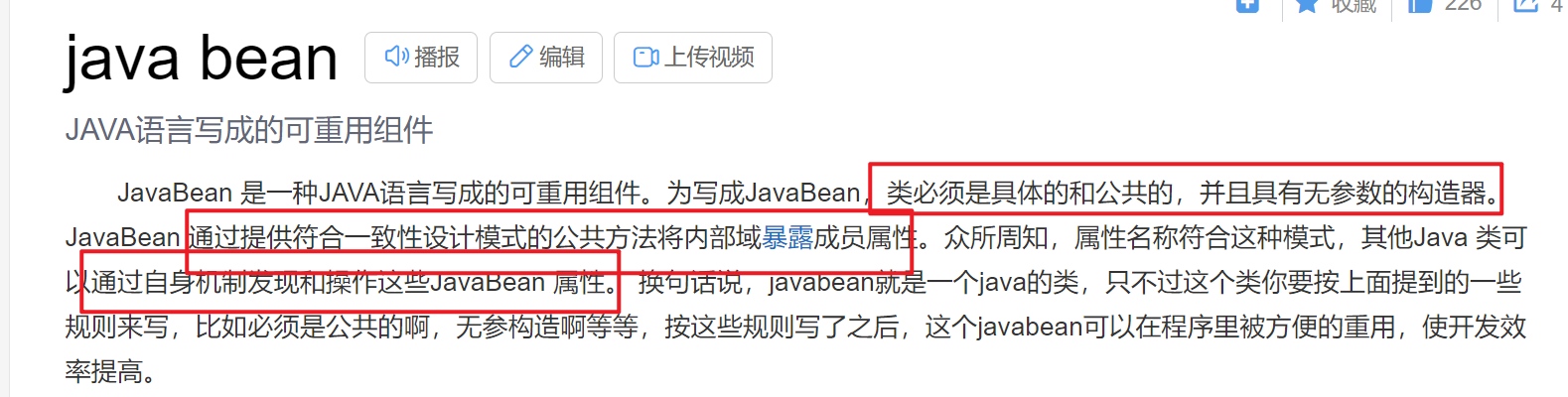
关于javaBean中数据类型的一下规范:
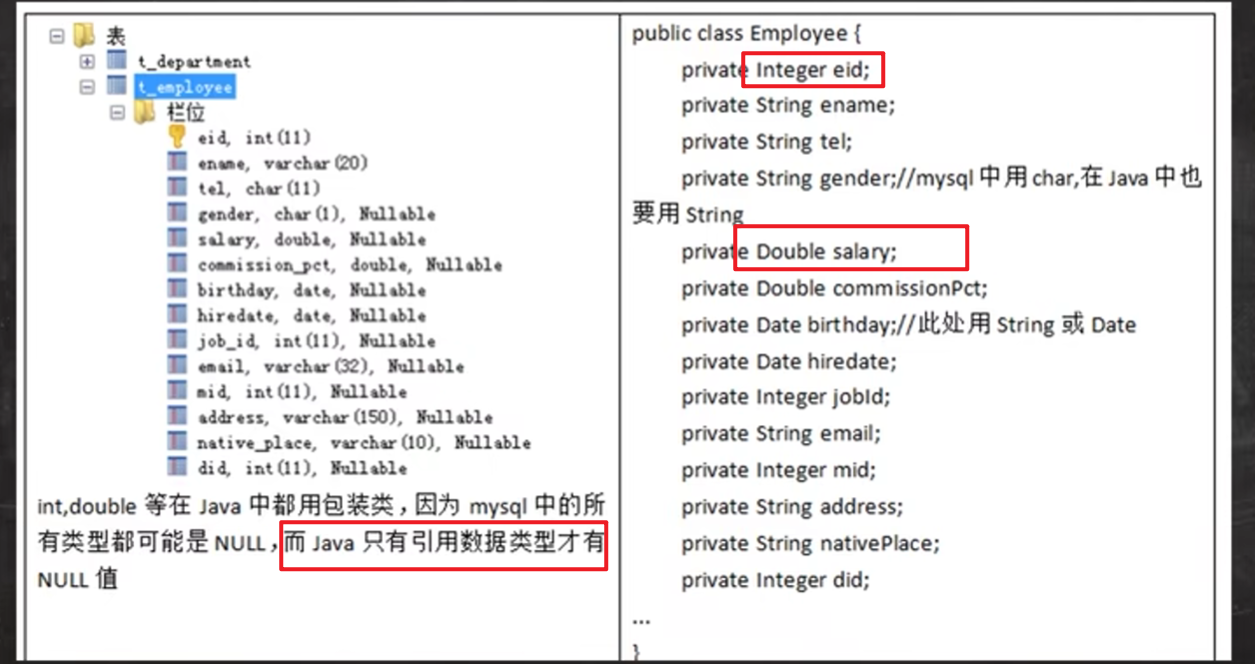
即要使用引用类型
首先这个javaBean如这样:
package Jdbc;
public class StructClass {
private String name;
private String password;
private int id;
//一定要无参有构造器,反射时有用,而且这个构造器是public的
public StructClass() {
}
public StructClass(String name, String password, int id) {
this.name = name;
this.password = password;
this.id = id;
}
//一定要配置getter与setter
//正如我们从类对象时可以调用这些方法来访问属性
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String toString() {
return "StructClass" +
"(" + name + "," + password + "," + id + ")";
}
}
第三方的jar包中封装了List

1.引入相应jar包
2.使用
1 public static void main(String[] args) throws SQLException {
2 //这里使用我自己写的Druid_jdbcUtil
3 String sql = "select * from nandp where id > ?";
4 //得到连接
5 Connection connection = Druid_JdbcUtiler.getConnection();
6 //用dbutils来得到QueryRunner对象
7 QueryRunner queryRunner = new QueryRunner();
8 //得到List类的结果集
9 List<StructClass> list =
10 queryRunner.query(connection, sql,
11 new BeanListHandler<>(StructClass.class),
12 1);
13 for (StructClass structClass : list) {
14 System.out.println(structClass);
15 }
16 }
注意一下还要关闭一下connect,prestatement与resultSet工具包会自己关我们不用管
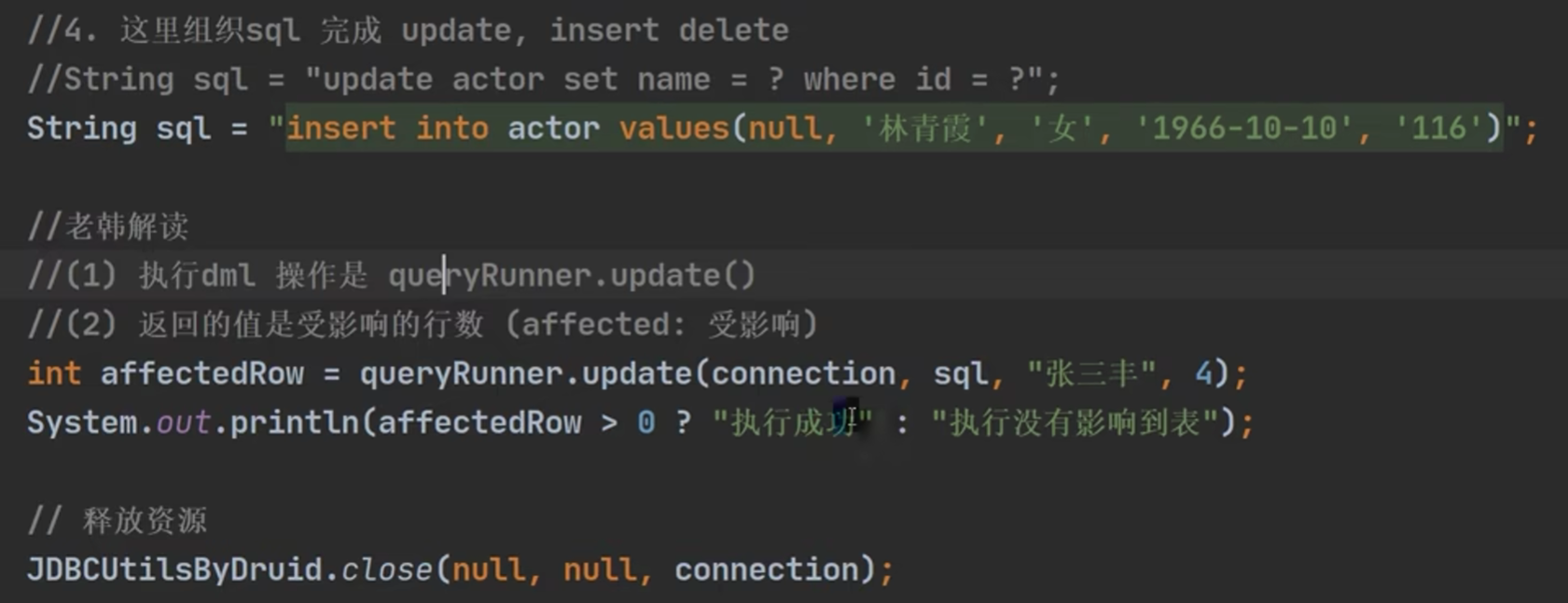
这个工具还能实现增删改查:


《java操作数据库详细规划》
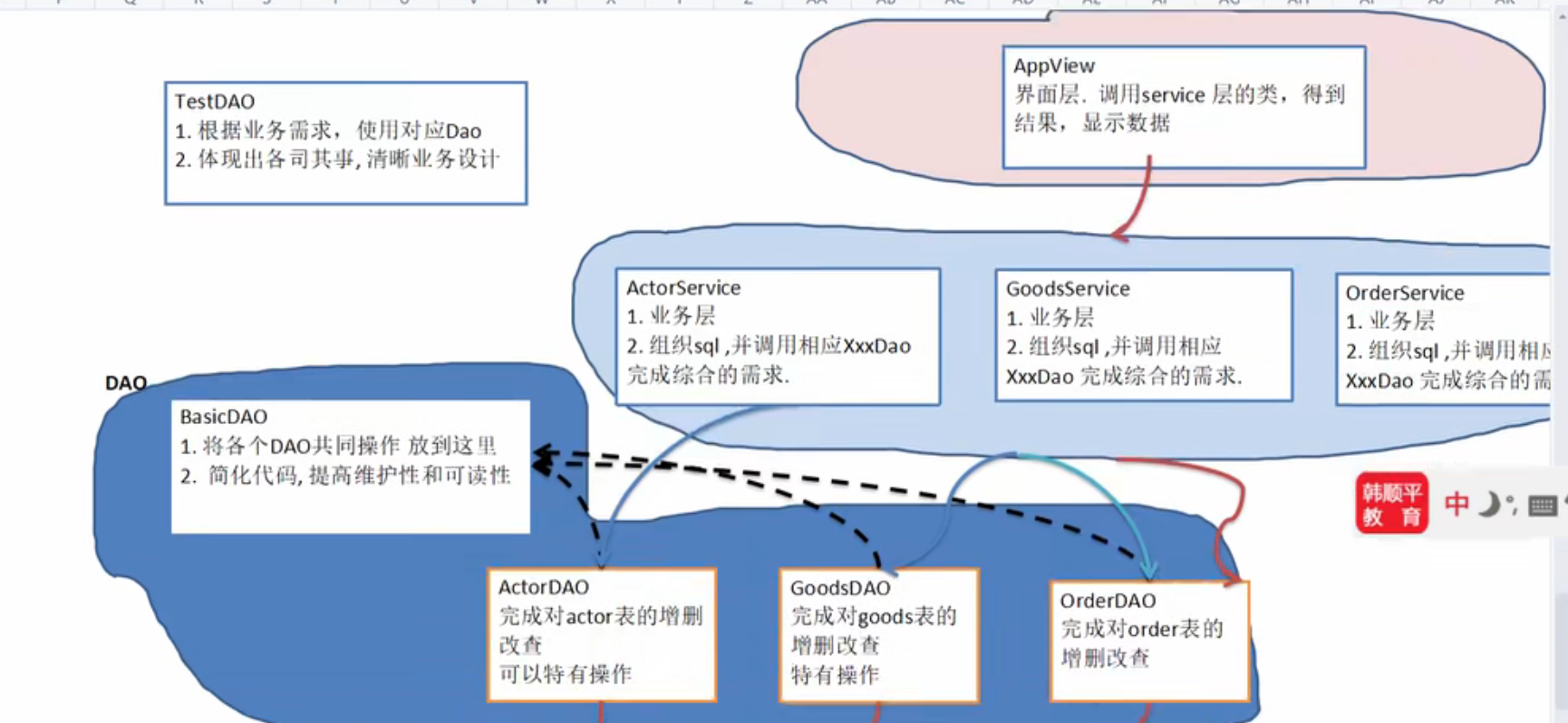
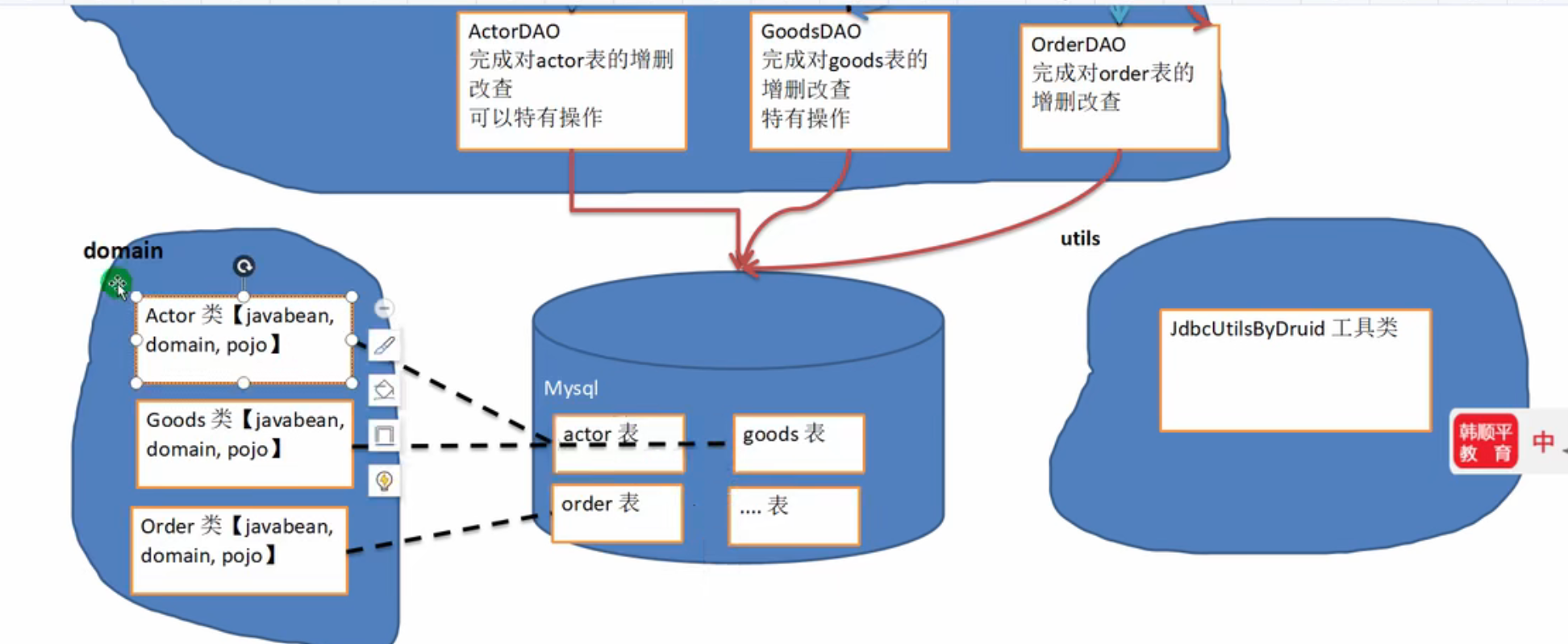
总之是首先写好工具包(将重复的连接数据库的内容封装到底层)
将要展示的数据封装成一个类,然后利用工具包从数据库获得ResultSet
每一个类对应着一个操作的类XXX_Dao,其专门与复杂的数据库的数据操作打交道
在来一个XXX_Service是View专门操作的类
然后展示
详细操作见这个博客:https://blog.csdn.net/weixin_42469070/article/details/122665902

 浙公网安备 33010602011771号
浙公网安备 33010602011771号