Dfs
《dfs的连通块模型》
这种题目大多是既可以用bfs也可以用dfs来解决的,其实在图的内部进行搜索遍历,对于dfs来说
这种模型不用恢复现场(即回溯)
《dfs的状态转移模型》
这种题目一般是一次变换之后,以整个图的状态为单位进行转换,这时就要恢复现场、
《dfs之搜索顺序》
这种题目即要找到一种搜索顺序使可以在爆搜的情况下能遍历到全部的状态
1 1117. 单词接龙
2
3 单词接龙是一个与我们经常玩的成语接龙相类似的游戏。
4
5 现在我们已知一组单词,且给定一个开头的字母,要求出以这个字母开头的最长的“龙”,每个单词最多被使用两次。
6
7 在两个单词相连时,其重合部分合为一部分,例如 beast 和 astonish ,如果接成一条龙则变为 beastonish。
8
9 我们可以任意选择重合部分的长度,但其长度必须大于等于1,且严格小于两个串的长度,例如 at 和 atide 间不能相连。
10
11 输入格式
12 输入的第一行为一个单独的整数 n 表示单词数,以下 n 行每行有一个单词(只含有大写或小写字母,长度不超过20),输入的最后一行为一个单个字符,表示“龙”开头的字母。
13
14 你可以假定以此字母开头的“龙”一定存在。
15
16 输出格式
17 只需输出以此字母开头的最长的“龙”的长度。
18
19 数据范围
20 n≤20
21 输入样例:
22 5
23 at
24 touch
25 cheat
26 choose
27 tact
28 a
29 输出样例:
30 23
31 提示
32 连成的“龙”为 atoucheatactactouchoose。
注意点:
1.每个单词最多被使用两次,说明单词可以重复,这时以前传统的 bool st[]数组要改成,int used[],用来记录使用次数
2、为了最长那么重合的地方取最小,而且计算最小重合长度肯定要预处理,不能放在dfs中再一个一个求;
1 #include <iostream>
2 #include <algorithm>
3 #include <cstring>
4 using namespace std;
5 const int N = 21;
6 string words[N];
7 int used[N], g[N][N];
8 int n, ans;
9 char start;
10 void dfs(string dargon, int x)
11 {
12 if (ans < dargon.size())
13 ans = dargon.size();
14 used[x]++;
15 for (int i = 0; i < n; i++)
16 {
17 if (g[x][i] && used[i] < 2)
18 {
19 /*dargon=dargon + words[i].substr(g[x][i]);//我代码这里是错误的
//因为如果我这样写dargon在下面也要恢复现场,很麻烦,所以这里要写成:
20 dfs(dargon, i);*/
dfs(dragon + word[i].substr(g[x][i]), i);
21 }
22 }
23 used[x]--;
24 }
25 int main()
26 {
27 cin >> n;
28 for (int i = 0; i < n; i++)
29 cin >> words[i];
30 cin >> start;
31 //预处理一下两个单词最小的可连接长度
32 for (int i = 0; i < n; i++)
33 {
34 for (int j = 0; j < n; j++)
35 {
36 string a = words[i], b = words[j];
37 for (int k = 1; k < min(a.size(), b.size()); k++)
38 {
39 if (a.substr(a.size() - k, k) == b.substr(0, k))
40 {
41 g[i][j] = k;
42 break;
43 }
44 }
45 }
46 }
47 for (int i = 0; i < n; i++)
48 {
49 if (words[i][0] == start)
50 dfs(words[i], i);
51 }
52 cout << ans;
53 return 0;
54 }

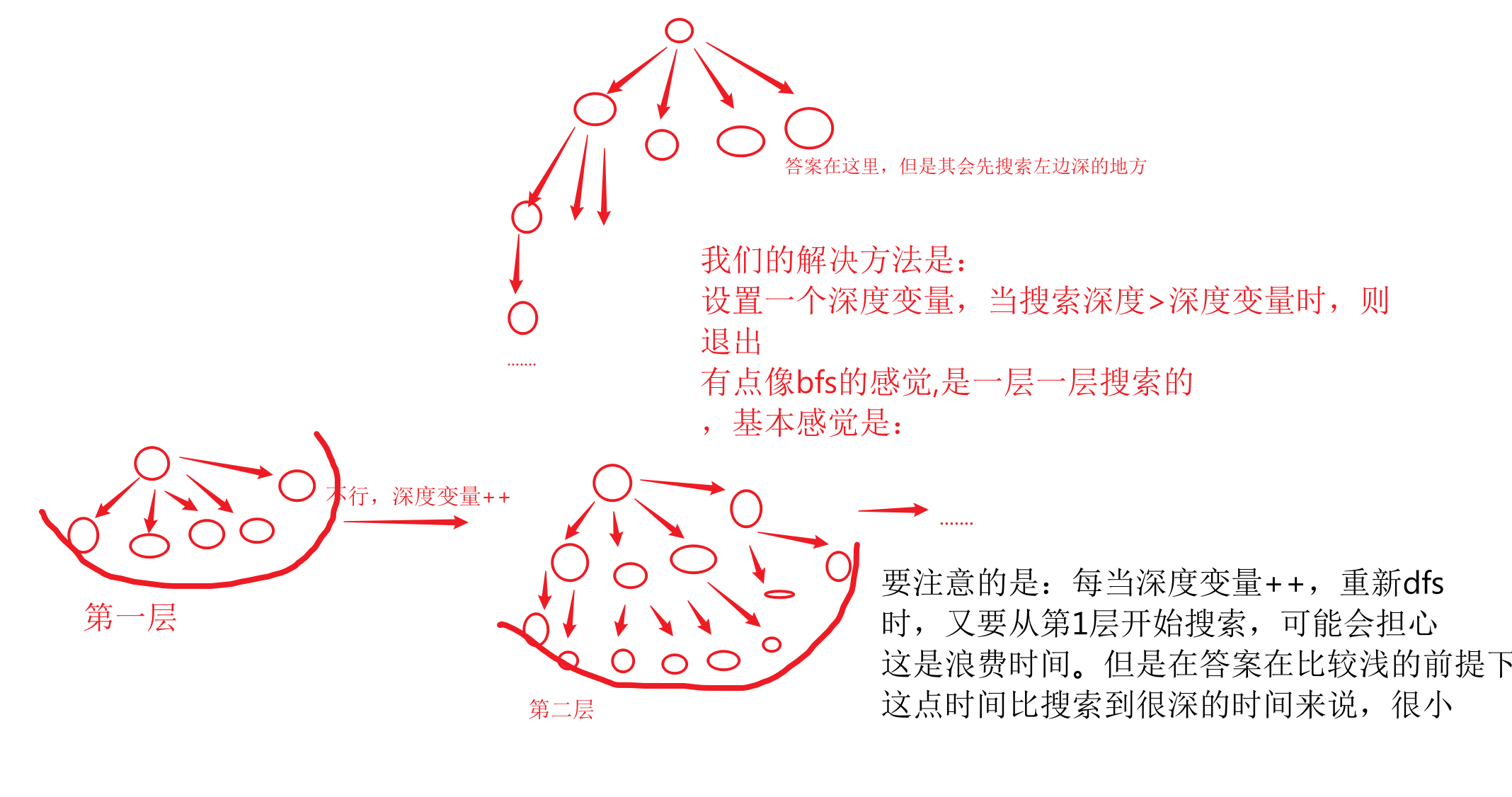
《dfs的搜索原理与精髓》
1.dfs首先要想到一个搜索方式,能够将全部的情况都不漏地搜索到(可以重复,当然越少重复越好)
尽量让决策的分支少
2.然后画出dfs的搜索顺序的搜索树,根据树进行递归写代码,逻辑更加清晰(其实递归的搜索顺序与这颗数的前序遍历是一样的)
如何建树?技巧是:只要决策了,就进行递归一层
3.尽量优化(剪枝)
《递归实现指数型枚举》
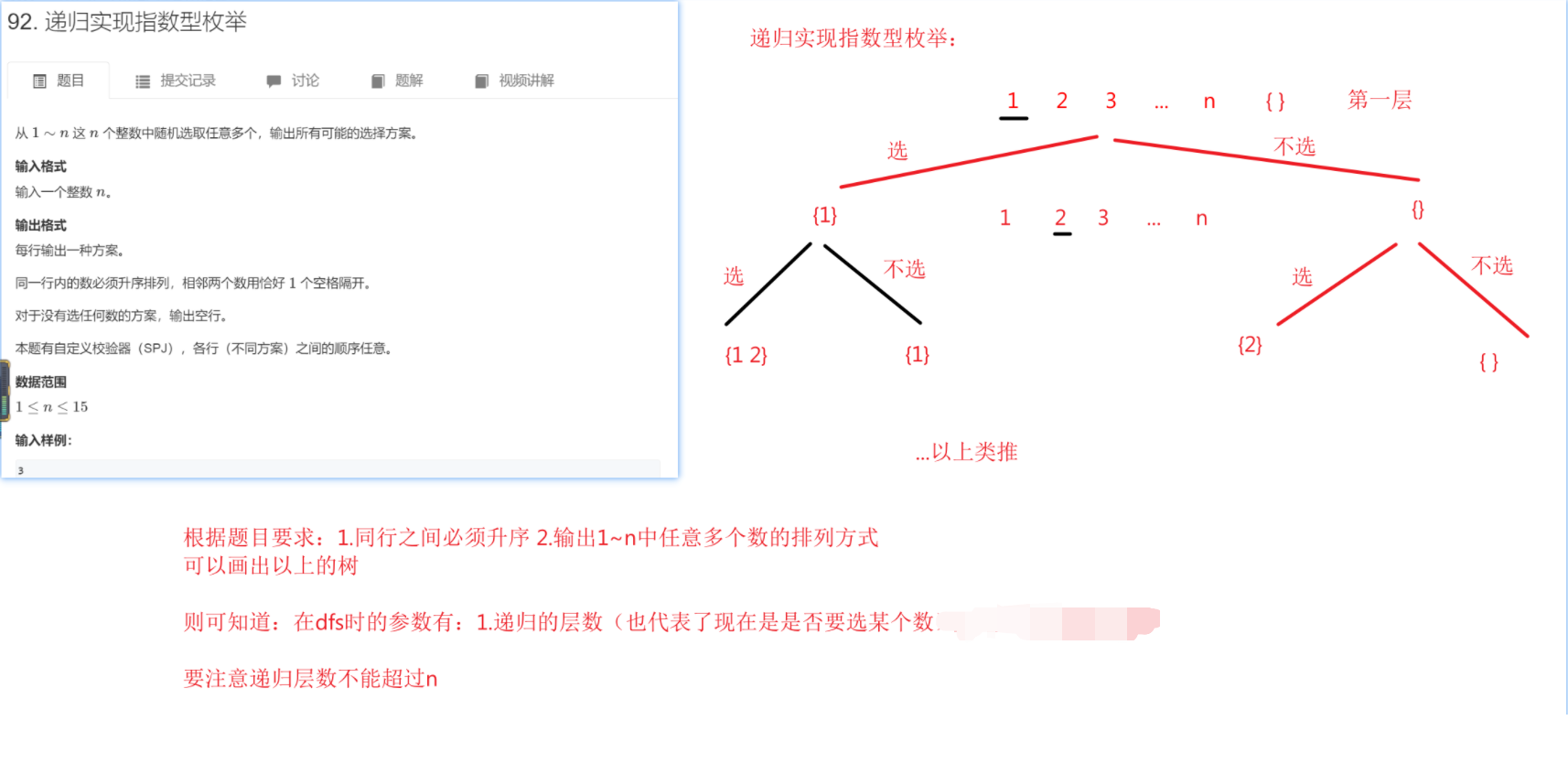
1 #include <iostream> 2 #include <cstring> 3 #include <algorithm> 4 using namespace std; 5 const int N = 16; 6 int n; 7 bool st[N]; 8 void dfs(int cnt) 9 { 10 if (cnt > n) 11 { 12 for (int i = 1; i <= n; i++) 13 if (st[i]) 14 cout << i << " "; 15 cout << endl; 16 return ; 17 } 18 st[cnt] = true; 19 dfs(cnt + 1); 20 st[cnt] = false; 21 dfs(cnt + 1); 22 } 23 int main() 24 { 25 cin >> n; 26 dfs(1); 27 return 0; 28 }
《递归实现组合型枚举》
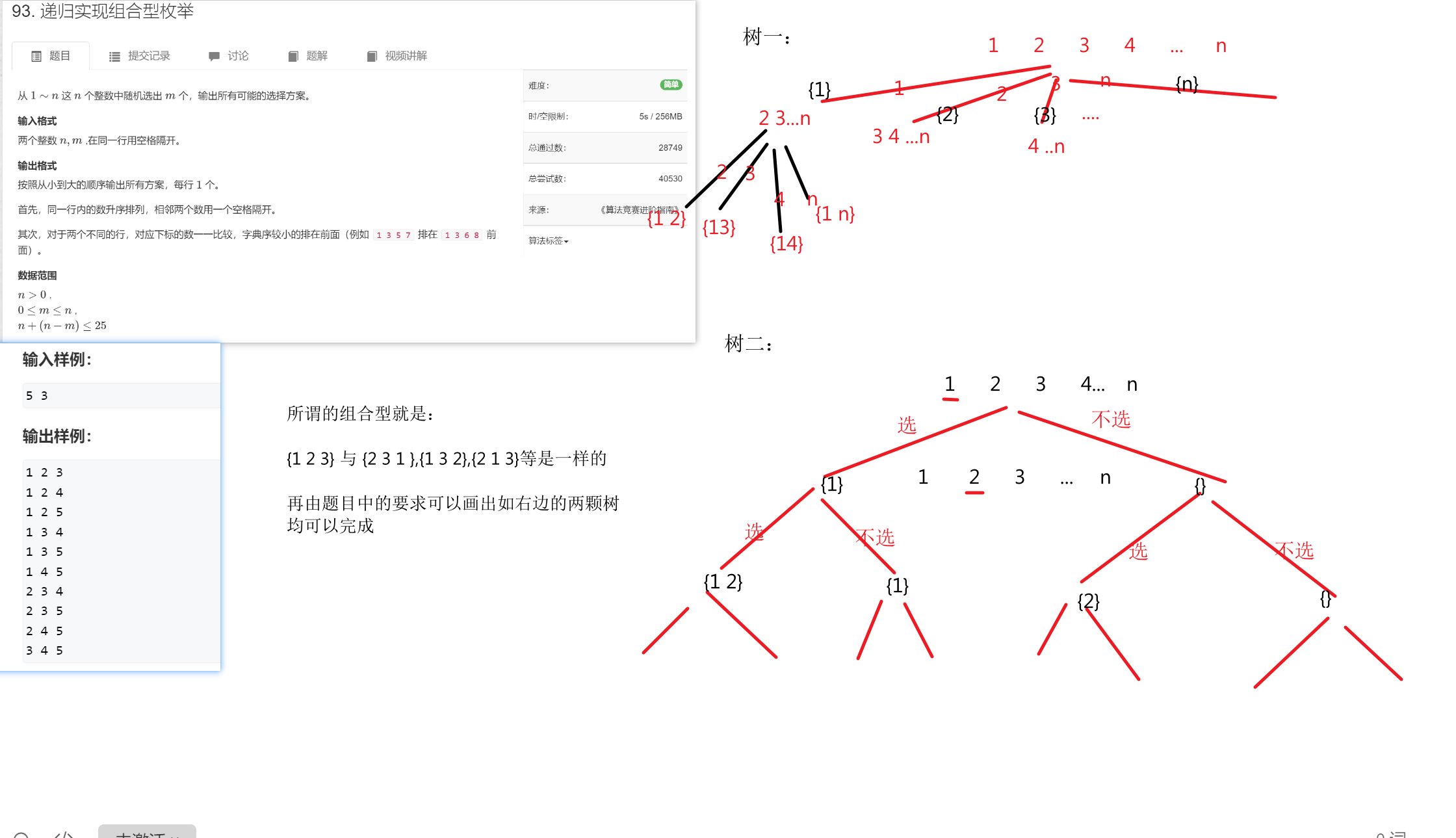
树二代码:
1 #include <iostream>
2 #include <algorithm>
3 #include <cstring>
4 using namespace std;
5 const int N = 25;
6 int n, m;
7 bool st[N];
8 void dfs(int u, int cnt)//u表示层数,cnt表示现在集合中元素的个数
9 {
10 if (u>=n+1 && cnt < m) return ;//注意这里要处理一下边界条件
11 if (cnt >= m)
12 {
13 for (int i = 1; i <= n; i++)
14 if (st[i])
15 cout << i << " ";
16 cout << endl;
17 return;
18 }
19 st[u] = true;
20 dfs(u + 1, cnt + 1);
21 st[u] = false;
22 dfs(u + 1, cnt);
23 }
24
25 int main()
26 {
27 cin >> n >> m;
28 dfs(1, 0);
29 return 0;
30 }
中 树一代码:
1 #include <iostream>
2 #include <algorithm>
3 #include <cstring>
4 using namespace std;
5 const int N = 25;
6 int n, m;
7 int path[N];
8 void dfs(int u, int start)//u表示层数(层数也代表了现在集合的元素个数),start表示现在分支的从那个数开始枚举
9 {
10 if (u > m)
11 {
12 for (int i = 1; i <= m; i++)
13 {
14 cout << path[i] << " ";
15 }
16 cout << endl;
17 return;
18 }
19 for (int i=start;i<=n;i++)
20 {
21 path[u]=i;
22 dfs(u+1,i+1);
23 }
24 }
25
26 int main()
27 {
28 cin >> n >> m;
29 dfs(1, 1);
30 return 0;
31 }
《递归实现排列型枚举》 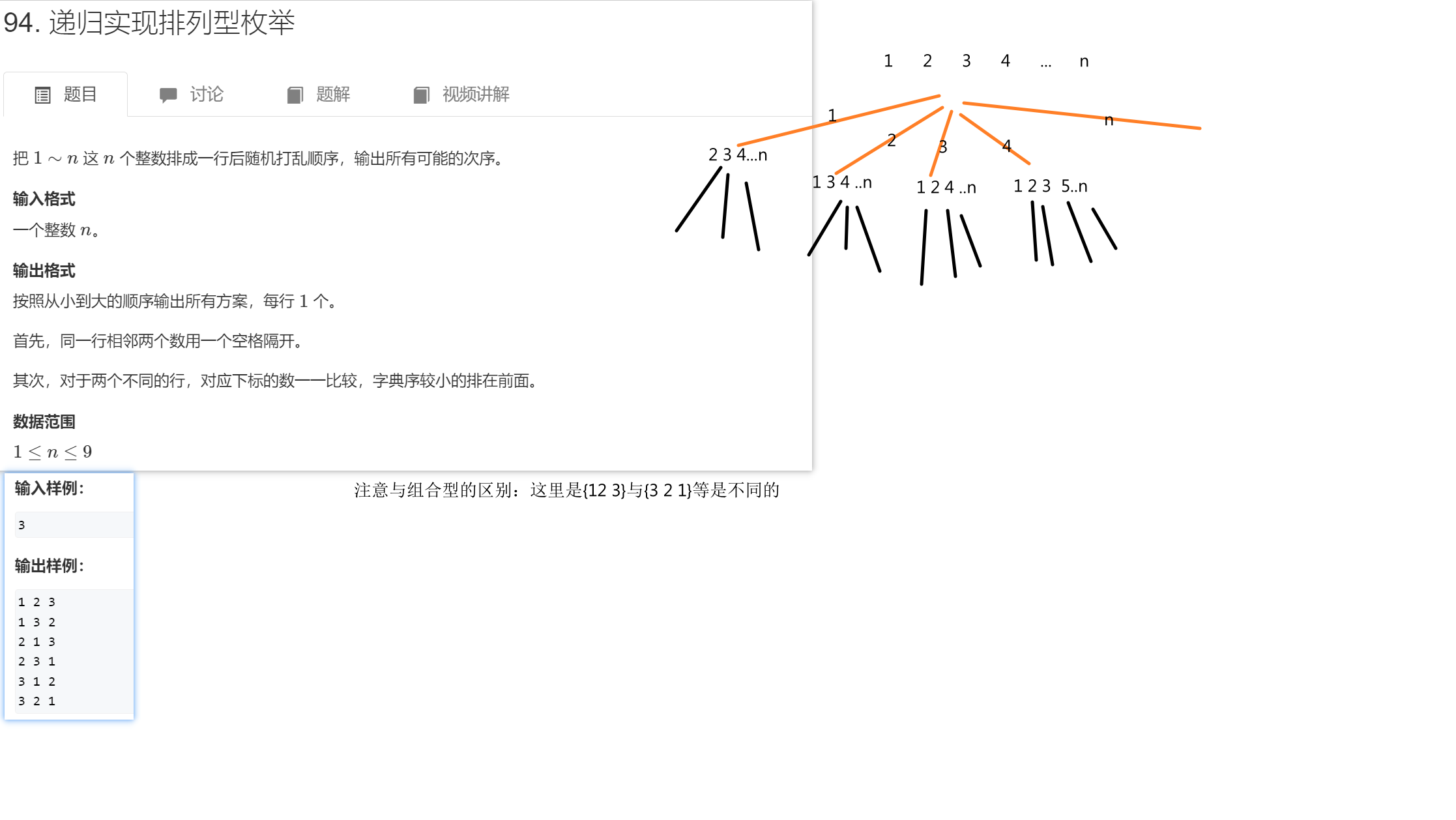
1 #include <iostream>
2 #include <cstring>
3 #include <algorithm>
4 using namespace std;
5 const int N = 10;
6 int n, path[N];
7 bool st[N];
8 void dfs(int u)
9 {
10 if (u>n){
11 for (int i=1;i<=n;i++)
12 {
13 cout<<path[i]<<" ";
14 }
15 cout<<endl;
16 return ;
17 }
18 for (int i=1;i<=n;i++)
19 {
20 if (!st[i]){
21 st[i]=true;
22 path[u]=i;
23 dfs(u+1);
24 st[i]=false;
25 }
26 }
27 }
28 int main()
29 {
30 cin >> n;
31 dfs(1);
32 return 0;
33 }
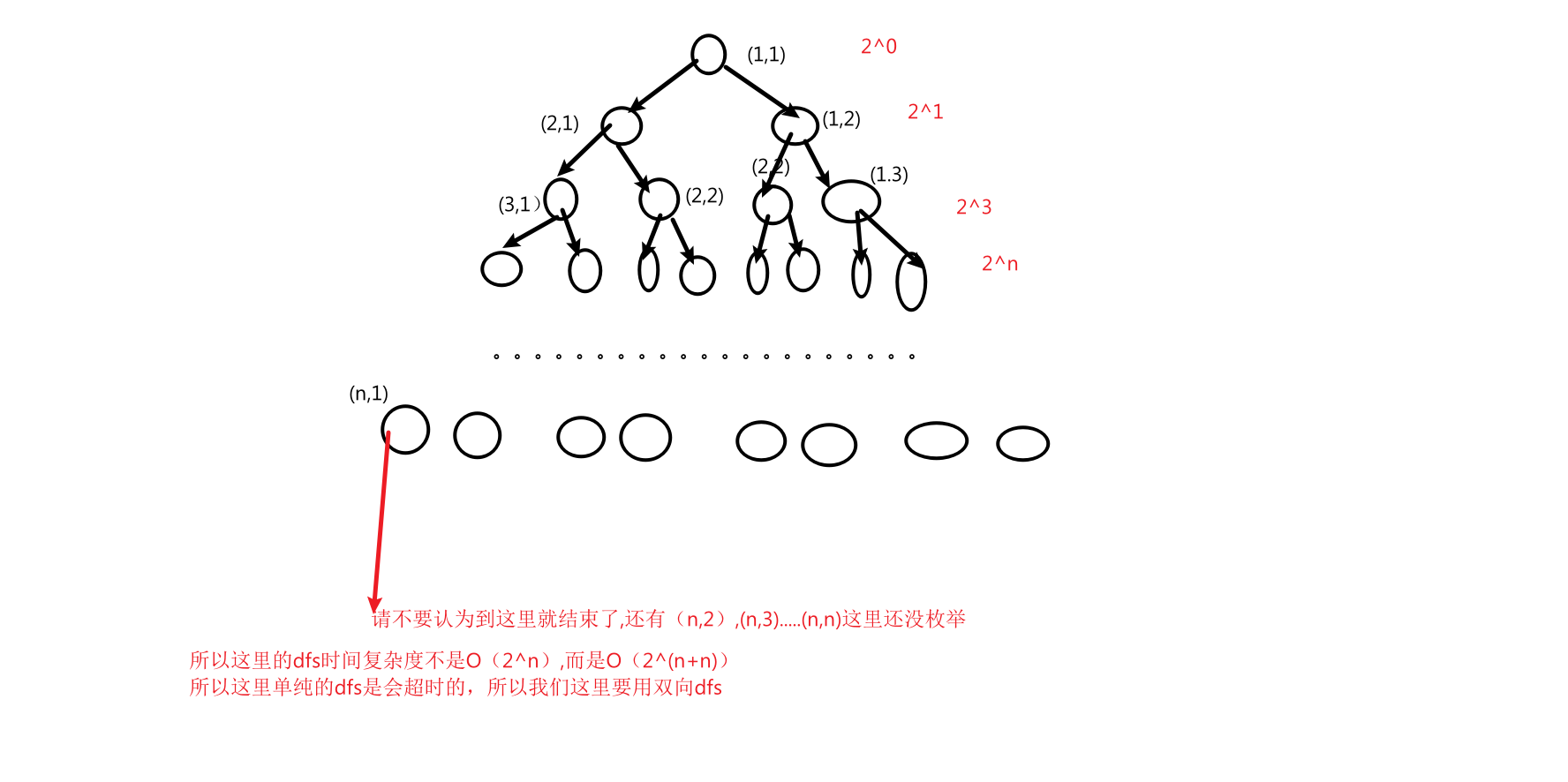
《分成互质组》

1 #include <iostream>
2 #include <algorithm>
3 #include <cstring>
4 using namespace std;
5 const int N = 12;
6 int g[N][N], n, nums[N];
7 bool st[N], ifPrime[N][N];
8 int ans;
9 int gcd(int a, int b)
10 {
11 return b ? gcd(b, a % b) : a;
12 }
13 bool check(int a, int gg[], int c)
14 {
15 for (int i = 0; i < c; i++)
16 {
17 if (!ifPrime[a][gg[i]])
18 return false;
19 }
20 return true;
21 }
22 void dfs(int index, int u, int c, int sum)
23 {
24 if (u >= ans)//剪枝
25 return;
26 if (sum >= n)
27 ans = u;
28 bool flag = true;//这一次dfs的决策要不就是添加到最后一组,要不就是开个新组。这里flag是判断要不要开新组
29 for (int i = index; i <= n; i++)
30 {
31 if (!st[i] && check(i, g[u], c))
32 {
33 flag = false;//能进这里就说明有元素可以添加到最后一组,也就是不用开新组
34
35 st[i] = true;
36 g[u][c] = i;
37 dfs(i + 1, u, c + 1, sum + 1);
38 st[i] = false;
39 }
40 }
41 if (flag)
42 dfs(1, u + 1, 0, sum); //每一次新开一个组就要刷新一下,组内元素各数以及都是从1下标重新开始遍历数了;
43 }
44 int main()
45 {
46 cin >> n;
47 ans = n;
48 for (int i = 1; i <= n; i++)
49 cin >> nums[i];
50 for (int i = 1; i <= n; i++)
51 {
52 for (int j = 1; j <= n; j++)
53 {
54 if (gcd(nums[i], nums[j]) <= 1)
55 ifPrime[i][j] = ifPrime[j][i] = true;
56 else
57 ifPrime[i][j] = ifPrime[j][i] = false;
58 }
59 }
60 //现在搜索到的是下标为...,现在搜到的是第...组,现在这个组的下标是...
61 //现在总共搜索了...个数
62 dfs(1, 1, 0, 0);
63 cout<<ans;
64 return 0;
65 }
《dfs的剪枝优化》
《小猫爬山》
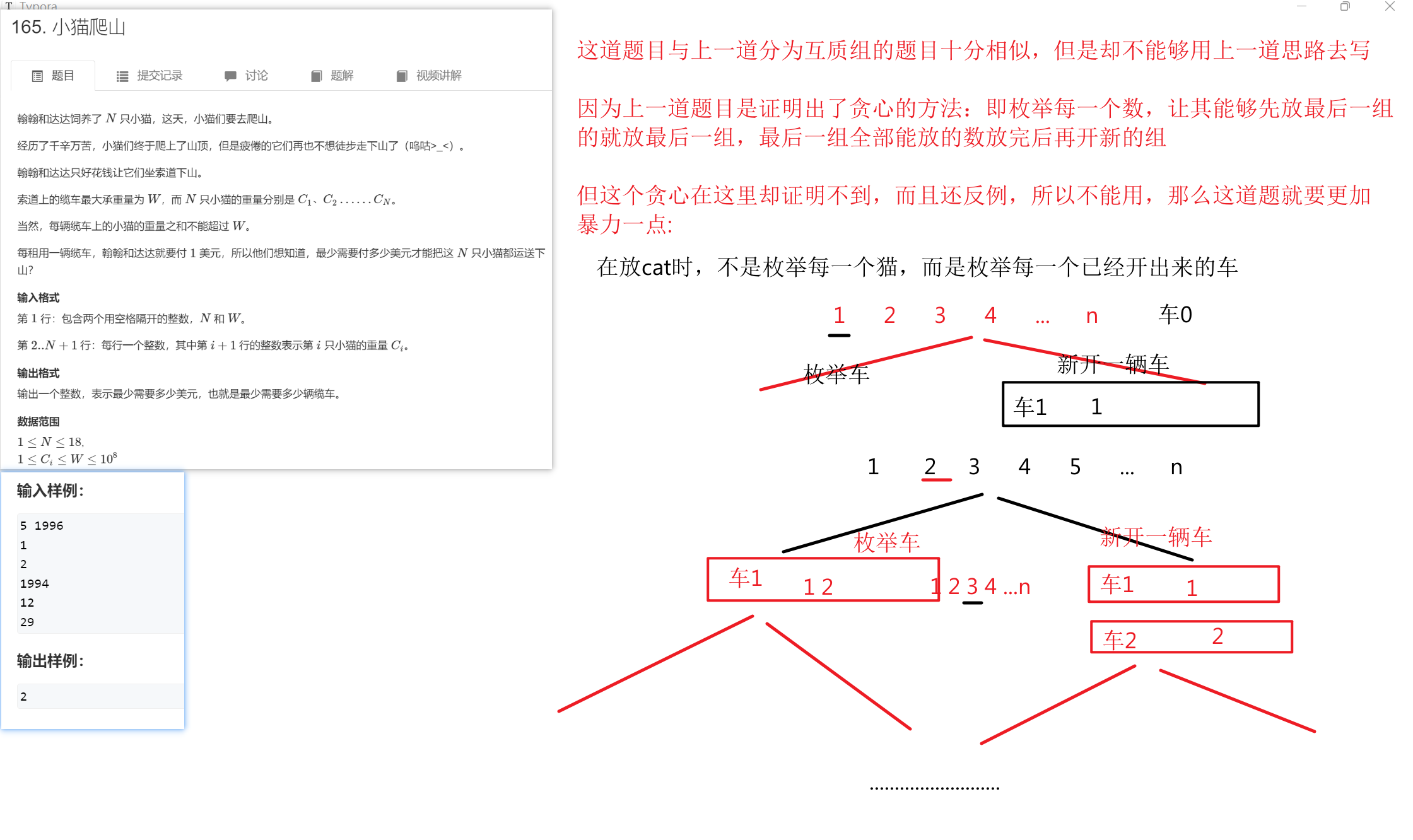
1 #include <iostream> 2 #include <algorithm> 3 #include <cstring> 4 using namespace std; 5 const int N = 20; 6 int n, w; 7 int g[N], cars[N], cnt; 8 int ans; 9 bool rule(int a, int b) 10 { 11 return a > b; 12 } 13 void dfs(int u, int k)//第一个参数是现在开了第...个车,第二个参数是先枚举到了第...层(第...个猫) 14 { 15 if (u >= ans)//最优化剪枝 16 return; 17 if (k > n) 18 { 19 ans = u; 20 return; 21 } 22 for (int i = 1; i <= u; i++) 23 { 24 if (cars[i] + g[k] <= w)//可行性剪枝 25 { 26 cars[i] += g[k]; 27 dfs(u, k + 1); 28 cars[i] -= g[k]; 29 } 30 } 31 cars[u + 1] = g[k]; 32 dfs(u + 1, k + 1); 33 cars[u + 1] = 0; 34 } 35 int main() 36 { 37 cin >> n >> w; 38 ans = n; 39 for (int i = 1; i <= n; i++) 40 cin >> g[i]; 41 sort(g + 1, g + n + 1, rule);//优化搜索顺序(从最大的猫开始枚举可以大大减少分支) 42 dfs(1, 1);//同时我这里用了组合型递归,减少了冗余项 43 cout << ans; 44 return 0; 45 }






 浙公网安备 33010602011771号
浙公网安备 33010602011771号