系统稳定性—StackOverFlowError常见原因及解决方法
每一个JVM线程都拥有一个私有的JVM线程栈,用于存放当前线程的JVM栈帧(包括被调用函数的参数、局部变量和返回地址等)。如果某个线程的线程栈空间被耗尽,没有足够资源分配给新创建的栈帧,就会抛出java.lang.StackOverflowError错误。
一、线程栈运行过程
首先给出一个简单的程序调用代码示例,如下所示:
public class SimpleExample {
public static void main(String args[]) {
a();
}
public static void a() {
int x = 0;
b();
}
public static void b() {
Car y = new Car();
c();
}
public static void c() {
float z = 0f;
}
}
当main()方法被调用后,执行线程按照代码执行顺序,将它正在执行的方法、基本数据类型、对象指针和返回值包装在栈帧中,逐一压入其私有的调用栈,整体执行过程如下图所示:
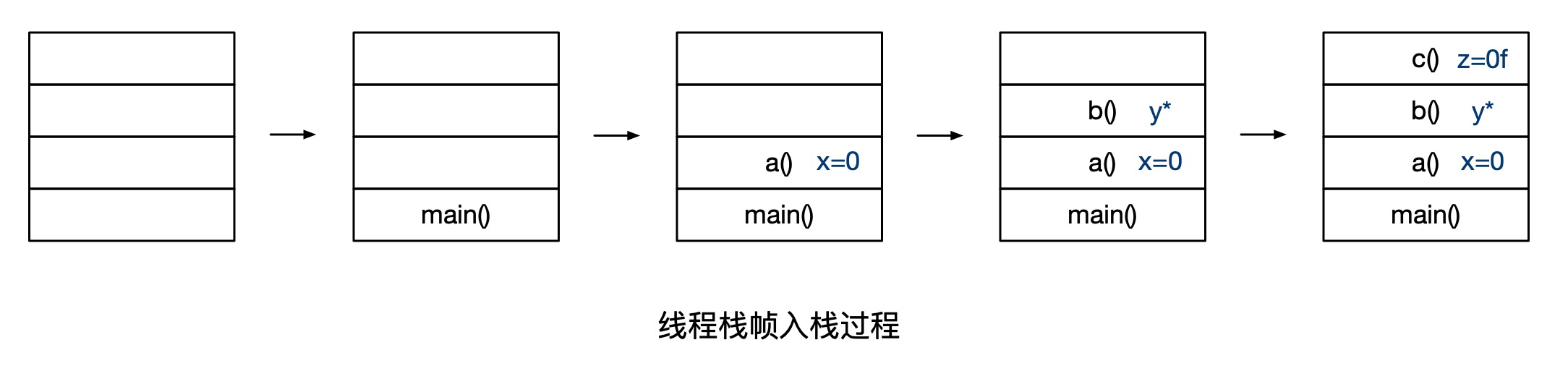
- 首先,程序启动后,
main()方法入栈。 - 然后,
a()方法入栈,变量x被声明为int类型,初始化赋值为0。注意,无论是x还是0都被包含在栈帧中。 - 接着,
b()方法入栈,创建了一个Car对象,并被赋给变量y。请注意,实际的Car对象是在Java堆内存中创建的,而不是线程栈中,只有Car对象的引用以及变量y被包含在栈帧里。 - 最后,
c()方法入栈,变量z被声明为float类型,初始化赋值为0f。同理,z还是0f都被包含在栈帧里。
当方法执行完成后,所有的线程栈帧将按照后进先出的顺序逐一出栈,直至栈空为止。
二、产生原因
如上所述,JVM线程栈存储了方法的执行过程、基本数据类型、局部变量、对象指针和返回值等信息,这些都需要消耗内存。一旦线程栈的大小增长超过了允许的内存限制,就会抛出java.lang.StackOverflowError错误。
2.1 无限递归调用(最常见)
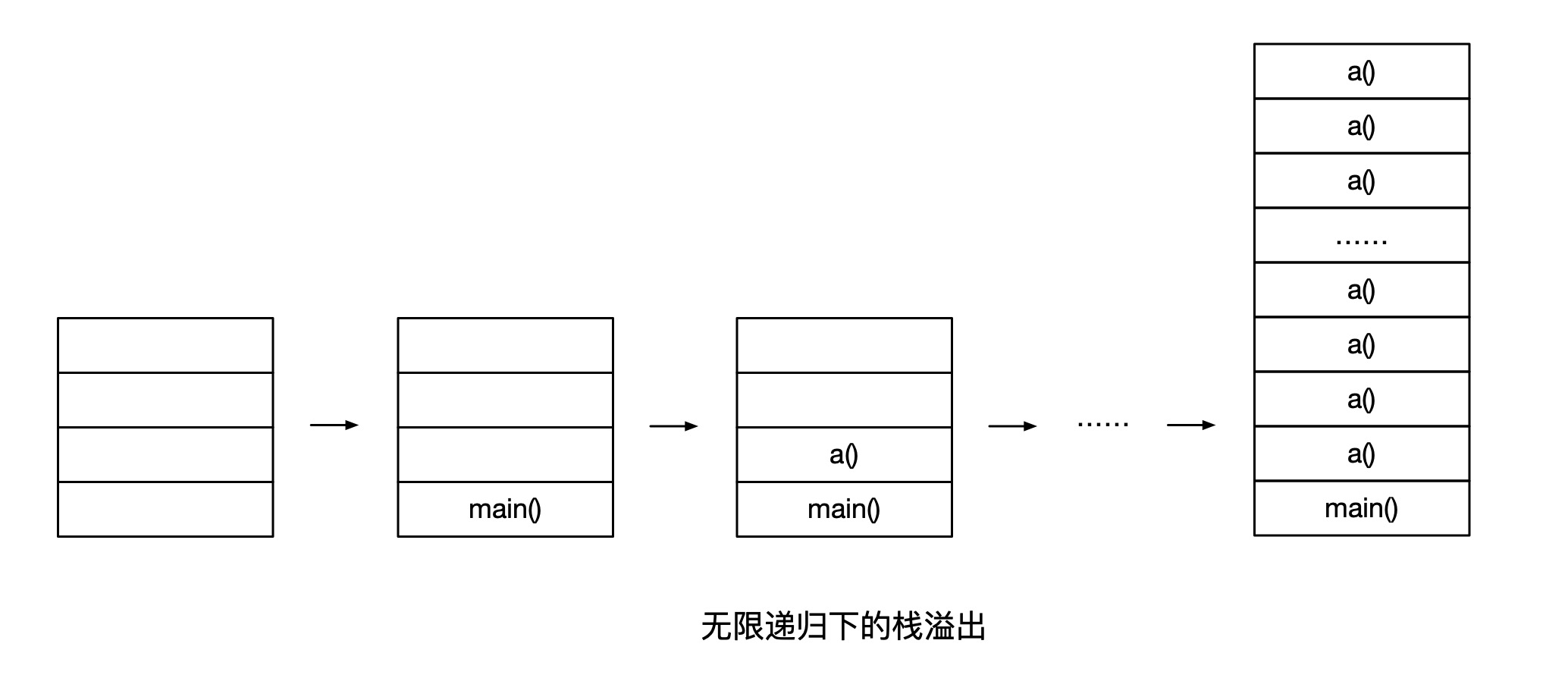
下面这段代码通过无限递归调用最终引发了java.lang.StackOverflowError错误。
public class StackOverflowErrorExample {
public static void main(String args[]) {
a();
}
public static void a() {
a();
}
}
在这种情况下,a()方法将无限入栈,直至栈溢出,耗尽线程栈空间,如下图所示。
Exception in thread "main" java.lang.StackOverflowError
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
at StackOverflowErrorExample.a(StackOverflowErrorExample.java:10)
2.2 方法嵌套调用过深
非递归方法中,多个方法相互调用导致调用链过长。
public void methodA() { methodB(); }
public void methodB() { methodA(); } // 互相调用形成死循环
2.3 Spring循环依赖
Spring Bean之间存在循环依赖,且某些情况下无法通过代理解决。
@Service
public class ServiceA {
@Autowired
private ServiceB serviceB;
}
@Service
public class ServiceB {
@Autowired
private ServiceA serviceA; // 循环依赖
}
2.4 大对象的方法调用
处理复杂数据结构(如深度嵌套的JSON、XML)时,解析方法调用层次过深。
2.5 线程栈内存不足
线程栈大小(通过-Xss设置)过小,无法支持正常调用深度。
- 执行了大量方法,导致线程栈空间耗尽。
- 方法内声明了海量的局部变量。
native代码有栈上分配的逻辑,并且要求的内存还不小,比如java.net.SocketInputStream.read0会在栈上要求分配一个64KB的缓存(64位Linux)
除了程序抛出StackOverflowError错误以外,还有两种定位栈溢出的方法:
- 进程突然消失,但是留下了
crash日志,可以检查crash日志里当前线程的stack范围,以及RSP寄存器的值。如果RSP寄存器的值超出这个stack范围,那就说明是栈溢出了。 - 如果没有
crash日志,那只能通过coredump进行分析。在进程运行前,先执行ulimit -c unlimited,当进程挂掉之后,会产生一个core.[pid]的文件,然后再通过jstack $JAVA_HOME/bin/java core.[pid]来看输出的栈。如果正常输出了,那就可以看是否存在很长的调用栈的线程,当然还有可能没有正常输出的,因为jstack的这条从core文件抓栈的命令其实是基于Serviceability Agent实现的,而SA在某些版本里有Bug。
三、排查步骤
3.1 查看错误日志
从日志中获取完整的错误堆栈信息,找到触发StackOverflowError的具体方法调用链。
示例日志:
java.lang.StackOverflowError
at com.example.MyService.recursiveMethod(MyService.java:10)
at com.example.MyService.recursiveMethod(MyService.java:10) // 重复调用
3.2 分析线程调用栈
通过线程堆栈信息定位问题代码:
- 直接分析日志:日志中会重复显示同一方法的调用路径。
- 使用
Arthas在线诊断:通过Arthas的thread命令查看线程栈。
# 查看所有线程状态
thread
# 查看指定线程的堆栈
thread <线程ID>
3.3 检查递归和循环调用
- 人工检查代码:找到日志中重复出现的方法,检查是否存在未终止的递归或相互调用。
- 静态代码分析工具:使用
SonarQube、IDEA的代码检查工具,发现潜在的递归风险。
3.4 排查Spring循环依赖
- Spring启动日志:Spring会在启动时警告循环依赖:
The dependencies of some of the beans in the application context form a cycle:
┌─────┐
| serviceA (field private com.example.ServiceB com.example.ServiceA.serviceB)
↑ ↓
| serviceB (field private com.example.ServiceA com.example.ServiceB.serviceA)
└─────┘
- 使用@Lazy注解:延迟加载可能解决部分循环依赖问题。
3.5 复现问题
- 本地复现:在本地环境中模拟线上场景,尝试触发
StackOverflowError。 - 单元测试:为可疑方法编写单元测试,验证递归终止条件。
四、解决
4.1 修复无限递归或循环调用
添加递归终止条件:
public void recursiveMethod(int count) {
if (count <= 0) return; // 终止条件
recursiveMethod(count - 1);
}
重构相互调用的方法:打破方法间的循环调用链。
4.2 解决Spring循环依赖
- 重构代码:通过设计模式(如事件驱动、依赖注入)解耦Bean。
- 使用@Lazy延迟加载:
@Service
public class ServiceA {
@Autowired
@Lazy // 延迟注入
private ServiceB serviceB;
}
- 避免字段注入:改用构造函数注入(Spring 4.3+ 支持隐式构造函数注入)。
4.3 增加线程栈大小
在JVM启动参数中调整线程栈大小(默认值通常为1MB):
java -Xss2m -jar your-spring-boot-app.jar
谨慎调整:过大的栈大小可能导致内存浪费。
线程栈的默认大小依赖于操作系统、JVM版本和供应商,常见的默认配置如下表所示:
| JVM版本 | 线程栈默认大小 |
|---|---|
| Sparc 32-bit JVM | 512 kb |
| Sparc 64-bit JVM | 1024 kb |
| x86 Solaris/Linux 32-bit JVM | 320 kb |
| x86 Solaris/Linux 64-bit JVM | 1024 kb |
| Windows 32-bit JVM | 320 kb |
| Windows 64-bit JVM | 1024 kb |
4.4 优化复杂数据解析
- 分治处理:将大对象拆分为小段处理,减少单次方法调用深度。
- 使用迭代代替递归:将递归算法改写为迭代。
// 递归写法(可能导致栈溢出)
public int factorial(int n) {
if (n == 1) return 1;
return n * factorial(n - 1);
}
// 迭代写法(安全)
public int factorial(int n) {
int result = 1;
for (int i = 1; i <= n; i++) {
result *= i;
}
return result;
}
五、预防
5.1 代码审查
- 递归检查:确保所有递归方法都有明确的终止条件。
- 依赖关系检查:避免
Spring Bean的循环依赖。
5.2 静态代码分析
使用工具:集成SonarQube、Checkstyle到CI/CD流程,检测潜在问题。
5.3 压力测试
模拟深度调用:在测试环境中构造极端场景(如深度为10,000的调用链),验证系统稳定性。
5.4 监控与告警
- 线程栈监控:通过APM工具(如SkyWalking、Prometheus)监控线程栈深度。
- 日志告警:配置日志监控,及时发现StackOverflowError。
提示: 实际生产系统中,可以对程序日志中的StackOverFlowError配置关键字告警,一经发现,立即处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号