Redis缓存异常(击穿/穿透/雪崩)及解决方案
一、概述
Redis是一个完全开源的、遵守BSD协议的、高性能的key-value数据结构存储系统,它支持数据的持久化,可以将内存中的数据保存在磁盘中,而且不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储,功能十分强大,Redis还支持数据的备份,即master-slave模式的数据备份,从而提高可用性。当然最重要的还是读写速度快,作为我们平常开发中最常用的缓存方案被广泛应用。但在实际应用过程中,它会存在缓存雪崩、缓存击穿和缓存穿透等异常情况,如果忽视这些情况可能会带来灾难性的后果,下面主要对这些缓存异常和常见处理方案进行相应分析与总结。
缓存异常有四种类型
- 缓存击穿
- 缓存穿透
- 缓存雪崩
- 缓存和数据库的数据不一致
案例演示
以下是日常开发中常见的缓存查询代码,看似正常,实则隐藏了击穿、穿透等多重风险:
@Service
public class UserInfoServiceImpl implements UserInfoService {
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate<Long, String> redisTemplate;
@Override
public UserInfo findById(Long id) {
// 问题1:未做参数校验,允许无效id(如-1、0)穿透
// 问题2:RedisTemplate未配置序列化器,可能导致key乱码、反序列化失败
// 问题3:缓存未设置过期时间,可能导致缓存膨胀
String userInfoStr = redisTemplate.opsForValue().get(id);
//缓存未命中时直接查库,无锁控制
//1
if (StringUtils.isBlank(userInfoStr)) { // 问题4:isEmpty未处理"空对象"缓存,后续可能引发穿透
UserInfo userInfo = userMapper.findById(id);
//数据库中不存在
if (userInfo == null) {
return null; // 问题5:数据库无数据时未缓存,导致重复穿透
}
userInfoStr = JSON.toJSONString(userInfo);
//2
//放入缓存
redisTemplate.opsForValue().set(id, userInfoStr);// 问题6:无过期时间,热点数据长期占用内存
}
return JSON.parseObject(userInfoStr, UserInfo.class);
}
}
流程如下:
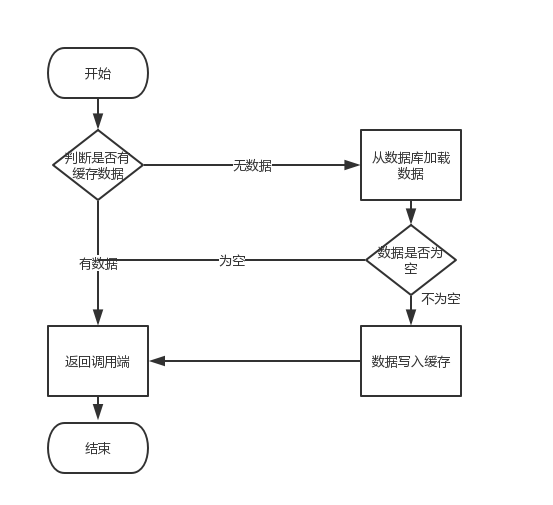
关键问题://1至//2之间的1.5秒窗口期,高并发请求会直接穿透至数据库(缓存击穿);若传入无效id(如-1),则会持续穿透(缓存穿透)。
二、缓存击穿
2.1 概念
缓存击穿是指缓存中单个热点key过期(或首次查询未缓存),此时大量并发请求同时查询该key,因缓存未命中,所有请求直接穿透至数据库,导致数据库瞬时压力骤增,甚至单表查询超时。
核心成因:热点key失效 + 无锁竞争 + 高并发访问
2.2 解决方案
2.2.1 同步锁
既然使用到锁,那么我们第一时间应该关心的是锁的粒度。如果我们放在方法findById上,那就是所有查询都会有锁的竞争,这里我相信大家都知道我们为什么不放在方法上。
@Service
public class UserInfoServiceImpl implements UserInfoService {
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate<Long, String> redisTemplate;
@Override
public UserInfo findById(Long id) {
// 1. 前置参数校验(拦截无效id,减少无效请求)
if (id == null || id <= 0) {
return null;
}
String cacheKey = "user:info:" + id;
//查询缓存
String userInfoStr = redisTemplate.opsForValue().get(id);
// 2. 第一次缓存校验
if (StringUtils.isEmpty(userInfoStr)) {
//优化:用cacheKey的intern()作为锁对象,实现key级锁(仅同一key竞争锁)
synchronized (cacheKey.intern()) {
// 3. 二次缓存校验(避免前一个线程已更新缓存)
userInfoStr = redisTemplate.opsForValue().get(cacheKey);
if (StringUtils.isBlank(userInfoStr)) {
UserInfo userInfo = userMapper.findById(id);
//数据库中不存在
if (userInfo == null) {
// 提前处理空数据,避免穿透(关联缓存穿透方案)
redisTemplate.opsForValue().set(cacheKey, "{}", 5, TimeUnit.MINUTES);
return null;
}
userInfoStr = JSON.toJSONString(userInfo);
// 4. 缓存设置过期时间(1小时),避免缓存膨胀
redisTemplate.opsForValue().set(id, userInfoStr, 3600, TimeUnit.SECONDS);
}
}
}
}
// 处理空对象缓存
return "{}".equals(userInfoStr) ? null : JSON.parseObject(userInfoStr, UserInfo.class);
}
关键优化点:
- 参数校验,拦截无效
id; - 缓存设置过期时间,避免内存溢出;
- 提前处理数据库空数据,关联缓存穿透防护。
2.2.2 分布式双重检查锁
代码实现和synchronized锁实现大致相同
@Service
public class UserInfoServiceImpl implements UserInfoService {
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate<String, String> redisTemplate;
@Resource
private RedissonClient redissonClient; // Redisson分布式锁客户端
// 锁参数配置(可通过Nacos动态调整)
private static final long WAIT_TIMEOUT = 3; // 获取锁的最大等待时间(秒)
private static final long LEASE_TIMEOUT = 10; // 锁持有时间(秒,需大于业务处理时间)
@Override
public UserInfo findById(Long id) {
// 1. 前置参数校验
if (id == null || id <= 0) {
return null;
}
String cacheKey = "user:info:" + id;
String userInfoStr = redisTemplate.opsForValue().get(cacheKey);
// 2. 第一次缓存校验(非空且非空对象)
if (StringUtils.isNotEmpty(userInfoStr)) {
return JSON.parseObject(userInfoStr, UserInfo.class);
}
// 3. 获取分布式锁(锁key与缓存key绑定,确保同一资源唯一锁)
RLock lock = redissonClient.getLock("lock:" + cacheKey);
try {
// 尝试获取锁:等待3秒,持有10秒,自动释放
boolean isLockAcquired = lock.tryLock(WAIT_TIMEOUT, LEASE_TIMEOUT, TimeUnit.SECONDS);
if (!isLockAcquired) {
// 获取锁失败:返回默认值或降级处理(避免用户等待)
log.warn("获取分布式锁失败,cacheKey:{}", cacheKey);
return new UserInfo(); // 或抛出友好异常
}
// 4. 第二次缓存校验(核心:防止前一个线程已更新缓存)
userInfoStr = redisTemplate.opsForValue().get(cacheKey);
if (StringUtils.isNotBlank(userInfoStr)) {
return JSON.parseObject(userInfoStr, UserInfo.class);
}
// 5. 查询数据库并更新缓存
UserInfo userInfo = userMapper.findById(id);
if (userInfo == null) {
// 缓存空对象(短期5分钟),避免穿透
redisTemplate.opsForValue().set(cacheKey, "{}", 300, TimeUnit.SECONDS);
return null;
}
userInfoStr = JSON.toJSONString(userInfo);
// 热点数据设置过期时间+随机值(避免雪崩)
long expireTime = 3600 + new Random().nextInt(600);
redisTemplate.opsForValue().set(cacheKey, userInfoStr, expireTime, TimeUnit.SECONDS);
return userInfo;
} catch (InterruptedException e) {
log.error("分布式锁操作异常", e);
Thread.currentThread().interrupt();
return null;
} finally {
// 确保锁释放(仅持有锁的线程可释放)
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
2.2.3 热点key永不过期(主动更新)
对于核心热点数据(如秒杀商品、首页Banner),可设置「永不过期」,通过后台定时任务主动更新缓存,避免过期触发击穿:
// 定时任务:每30分钟更新热点用户缓存(如VIP用户列表)
@Scheduled(cron = "0 0/30 * * * ?")
public void refreshHotUserCache() {
List<Long> hotUserIds = userMapper.selectVipUserIds(); // 查询热点用户ID
for (Long userId : hotUserIds) {
String cacheKey = "user:info:" + userId;
UserInfo userInfo = userMapper.findById(userId);
if (userInfo != null) {
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(userInfo));
}
}
log.info("热点用户缓存更新完成,共更新{}条数据", hotUserIds.size());
}
2.3 小结
缓存击穿的核心解决方案:锁竞争控制(本地锁/分布式锁)+ 双重缓存校验 + 热点数据特殊处理
- 单节点用「
key级本地锁」,集群用「Redisson分布式锁」; - 避免锁粒度过大,减少接口吞吐量损失;
- 热点数据优先采用「永不过期 + 定时更新」,从根源避免击穿。
三、缓存穿透
3.1 概念
缓存穿透是指缓存和数据库中均无对应数据(如恶意构造的负数id、随机字符串、超出业务范围的key),导致所有请求穿透缓存直接落到数据库。高并发场景下,海量无效请求会耗尽数据库连接池,最终导致数据库宕机。
3.2 解决方案
回顾上面的案例,在正常的情况下是没问题,但是一旦有人恶意攻击呢?比如说:入参id=-1,在数据库里并没有这个id,怎么办呢?
第一步、缓存中不存在
第二步、查询数据库
第三步、由于数据库中不存在,直接返回了,并没有操作缓存
第四步、再次执行第一步.....死循环了吧
3.2.1 接口层参数校验
用Spring Validation拦截无效参数,直接阻断请求进入服务层:
@RestController
@RequestMapping("/user")
public class UserController {
@Resource
private UserInfoService userInfoService;
@GetMapping("/{id}")
public Result<UserInfo> getUserById(
@PathVariable
@Min(value = 1, message = "用户ID必须为正整数") // 拦截负数、0
@Max(value = 1000000, message = "用户ID超出业务范围") // 拦截超大无效值
Long id) {
UserInfo userInfo = userInfoService.findById(id);
return Result.success(userInfo);
}
// 全局异常处理器:处理参数校验失败
@ExceptionHandler(MethodArgumentNotValidException.class)
public Result<Void> handleParamError(MethodArgumentNotValidException e) {
String message = e.getBindingResult().getFieldErrors().get(0).getDefaultMessage();
return Result.error(400, message);
}
}
3.2.2 缓存空对象
数据库查询无结果时,缓存「空对象」(如{})并设置短期过期时间(5-10分钟),避免同一无效key重复穿透:
// 核心代码片段(集成在分布式锁逻辑中)
if (userInfo == null) {
// 缓存空对象,设置5分钟过期(避免缓存膨胀)
redisTemplate.opsForValue().set(cacheKey, "{}", 300, TimeUnit.SECONDS);
return null;
}
回到上面的四步,就变成了。
比如说:入参id=-1,在数据库里并没有这个id,怎么办呢?
第一步、缓存中不存在
第二步、查询数据库
第三步、由于数据库中不存在,以id为key,空对象为value放入缓存中
第四步、执行第一步,此时,缓存就存在了,只是这时候只是一个空对象。
注意事项:
- 必须设置过期时间,否则无效
key会长期占用缓存; - 空对象需与有效数据区分(如用{}标记),避免反序列化失败。
3.2.3 布隆过滤器
具体请参考布隆过滤器
@Service
public class UserInfoServiceImpl implements UserInfoService {
@Resource
private RedissonClient redissonClient;
private BloomFilter<Long> userBloomFilter;
// 系统启动时初始化布隆过滤器(加载所有有效用户ID)
@PostConstruct
public void initBloomFilter() {
// 1. 获取分布式布隆过滤器(支持集群共享)
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter("bloom:filter:user:ids");
// 2. 初始化:预期数据量100万,误判率0.01(误判率越低,占用内存越大)
bloomFilter.tryInit(1000000, 0.01);
// 3. 分批次加载数据库中所有有效用户ID(避免OOM)
List<Long> allValidUserIds = userMapper.selectAllValidUserIds();
for (Long userId : allValidUserIds) {
bloomFilter.add(userId);
}
this.userBloomFilter = bloomFilter;
log.info("布隆过滤器初始化完成,加载有效用户ID{}条", allValidUserIds.size());
}
@Override
public UserInfo findById(Long id) {
// 1. 参数校验(第一层防护)
if (id == null || id <= 0 || id > 1000000) {
return null;
}
String cacheKey = "user:info:" + id;
String userInfoStr = redisTemplate.opsForValue().get(cacheKey);
// 2. 缓存校验(第二层防护)
if (StringUtils.isNotBlank(userInfoStr)) {
return JSON.parseObject(userInfoStr, UserInfo.class);
}
// 3. 布隆过滤器校验(第三层防护:不存在则直接返回)
if (!userBloomFilter.mightContain(id)) {
log.warn("布隆过滤器拦截无效ID:{}", id);
return null;
}
// 4. 分布式锁+查库(后续逻辑同缓存击穿方案)
// ...
}
}
3.3 小结
缓存穿透的防护核心:层层拦截,从源头阻断无效请求
- 中小规模系统:参数校验 + 空对象缓存(低成本、易落地);
- 大规模高并发系统:参数校验 + 布隆过滤器 + 空对象缓存(全方位防护);
- 布隆过滤器不支持删除操作,若数据有删除需求,需定期重建过滤器(如每天凌晨)。
四、缓存雪崩
4.1 概念
缓存雪崩是指缓存层大面积key同时过期或Redis集群宕机,导致所有请求瞬间穿透至数据库,数据库因承受不住海量请求而宕机。常见触发场景:
- 批量缓存设置相同过期时间(如秒杀活动结束后,所有商品缓存同时失效);
- Redis集群单点故障(无高可用配置);
- 系统上线初期未做缓存预热,大量用户请求直接查库。
4.2 解决方案
4.2.1 随机化过期时间(避免集体失效)
给每个缓存key的过期时间增加随机值(如0-10分钟),分散失效时间点:
// 基础过期时间1小时,随机增加0-10分钟(600秒)
long baseExpire = 3600;
long randomExpire = new Random().nextInt(600);
redisTemplate.opsForValue().set(cacheKey, userInfoStr, baseExpire + randomExpire, TimeUnit.SECONDS);
4.2.2 缓存标记 + 主动更新(避免过期穿透)
给缓存key设置「缓存标记」(单独的key),标记过期时间早于数据缓存,到期后主动更新数据缓存,而非直接失效:
@Override
public UserInfo findById(Long id) {
String dataKey = "user:info:" + id;
String flagKey = "user:info:flag:" + id; // 缓存标记key
String userInfoStr = redisTemplate.opsForValue().get(dataKey);
String flag = redisTemplate.opsForValue().get(flagKey);
// 缓存标记未过期:直接返回数据缓存
if (StringUtils.isNotBlank(flag)) {
return isValidCache(userInfoStr) ? JSON.parseObject(userInfoStr, UserInfo.class) : null;
}
// 缓存标记过期:加锁主动更新缓存
RLock lock = redissonClient.getLock("lock:" + dataKey);
try {
if (lock.tryLock(3, 10, TimeUnit.SECONDS)) {
// 二次校验标记
if (StringUtils.hasText(redisTemplate.opsForValue().get(flagKey))) {
return isValidCache(userInfoStr) ? JSON.parseObject(userInfoStr, UserInfo.class) : null;
}
// 查询数据库更新缓存
UserInfo userInfo = userMapper.findById(id);
if (userInfo != null) {
redisTemplate.opsForValue().set(dataKey, JSON.toJSONString(userInfo), 86400, TimeUnit.SECONDS); // 数据缓存1天
redisTemplate.opsForValue().set(flagKey, "1", 3600, TimeUnit.SECONDS); // 标记缓存1小时
}
return userInfo;
}
} catch (InterruptedException e) {
log.error("更新缓存异常", e);
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
return null;
}
4.2.3 Redis集群高可用(避免缓存不可用)
部署「主从复制 + 哨兵模式」或Redis Cluster,确保单个节点宕机后,从节点能自动切换为主节点,避免缓存服务整体不可用:
# Spring Boot配置Redis Cluster(生产环境示例)
spring:
redis:
cluster:
nodes: 192.168.1.101:6379,192.168.1.102:6379,192.168.1.103:6379
max-redirects: 3 # 最大重定向次数
timeout: 3000
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 2
4.2.4 缓存预热(系统上线前加载)
系统上线前主动加载热点数据到缓存,避免上线后大量用户请求查库:
@Component
public class CacheWarmer implements CommandLineRunner {
@Resource
private RedisTemplate<String, String> redisTemplate;
@Resource
private UserMapper userMapper;
@Override
public void run(String... args) throws Exception {
log.info("开始缓存预热...");
// 加载热点用户(如前1000名VIP用户)
List<UserInfo> hotUsers = userMapper.selectTopHotUsers(1000);
for (UserInfo user : hotUsers) {
String cacheKey = "user:info:" + user.getId();
long expireTime = 3600 + new Random().nextInt(600);
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(user), expireTime, TimeUnit.SECONDS);
}
log.info("缓存预热完成,加载热点用户{}条", hotUsers.size());
}
}
4.2.5 熔断降级(缓存不可用时兜底)
当 Redis 集群宕机或缓存命中率骤降时,通过熔断工具(Sentinel/Hystrix)拦截请求,返回默认值或降级页面,避免数据库压垮:
@Configuration
public class SentinelConfig {
@PostConstruct
public void initRules() {
// 1. 限流规则:每秒最多1000个请求
FlowRule flowRule = new FlowRule("getUserById")
.setGrade(RuleConstant.FLOW_GRADE_QPS)
.setCount(1000);
FlowRuleManager.loadRules(Collections.singletonList(flowRule));
// 2. 降级规则:Redis异常比例>50%时,降级5秒
DegradeRule degradeRule = new DegradeRule("getUserById")
.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO)
.setCount(0.5) // 异常比例阈值
.setTimeWindow(5); // 降级时间(秒)
DegradeRuleManager.loadRules(Collections.singletonList(degradeRule));
}
// 降级回调函数:返回默认用户信息
public UserInfo fallback(Long id) {
log.warn("缓存服务降级,id:{}", id);
UserInfo defaultUser = new UserInfo();
defaultUser.setId(-1L);
defaultUser.setName("系统繁忙,请稍后重试");
return defaultUser;
}
}
4.3 小结
缓存雪崩的防护核心:预防为主,兜底为辅
- 预防:随机TTL + 缓存标记 + Redis高可用 + 缓存预热;
- 兜底:熔断降级 + 数据库限流;
- 关键:实时监控Redis可用性、缓存命中率、数据库QPS,雪崩发生前及时预警。
五、缓存与数据库的数据一致性
缓存异常的处理离不开数据一致性 —— 若缓存与数据库数据不一致,再完善的异常防护也无意义。分布式系统中,强一致性难以实现且性能开销大,通常采用「最终一致性」方案。
5.1 问题本质
数据更新时,若先更缓存再更数据库,或先更数据库未删缓存,会导致:
- 线程 A:删缓存 → 线程 B:查缓存(无)→ 查数据库(旧数据)→ 写缓存 → 线程 A:更数据库(新数据);
- 结果:缓存存旧数据,数据库存新数据,数据不一致。
5.2 解决方案
5.2.1 延迟双删(核心方案)
流程:先更数据库 → 删缓存 → 延迟1秒后再次删缓存目的:确保线程 B 已完成「查库写缓存」后,再次删除缓存,避免旧数据残留。
@Override
public boolean updateUserInfo(UserInfo userInfo) {
// 1. 校验参数
if (userInfo == null || userInfo.getId() == null) {
return false;
}
// 2. 先更新数据库(确保数据库数据正确)
int rows = userMapper.updateById(userInfo);
if (rows <= 0) {
return false;
}
String cacheKey = "user:info:" + userInfo.getId();
// 3. 第一次删除缓存
redisTemplate.delete(cacheKey);
// 4. 延迟1秒后再次删除缓存(解决并发问题)
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(1000); // 延迟时间根据业务处理时间调整
redisTemplate.delete(cacheKey);
log.info("延迟双删缓存成功,cacheKey:{}", cacheKey);
} catch (InterruptedException e) {
log.error("延迟双删缓存异常", e);
Thread.currentThread().interrupt();
}
});
return true;
}
5.2.2 Canal同步binlog(高并发写场景)
延迟双删的延迟时间难以精准控制,高并发写场景下可通过 Canal 监听 MySQL binlog,异步更新缓存:
- Canal伪装成MySQL从节点,实时同步binlog日志;
- 解析binlog中的insert/update/delete操作;
- 异步更新或删除Redis对应的缓存key。
核心优势:无业务代码侵入,一致性更可靠,支持高并发写。
六、其他
6.1 热点数据和冷数据
热点数据,缓存才有价值
对于冷数据而言,大部分数据可能还没有再次访问到就已经被挤出内存,不仅占用内存,而且价值不大。频繁修改的数据,看情况考虑使用缓存
对于热点数据,比如我们的某IM产品,生日祝福模块,当天的寿星列表,缓存以后可能读取数十万次。再举个例子,某导航产品,我们将导航信息,缓存以后可能读取数百万次。
数据更新前至少读取两次,缓存才有意义。这个是最基本的策略,如果缓存还没有起作用就失效了,那就没有太大价值了。
那存不存在,修改频率很高,但是又不得不考虑缓存的场景呢?有!比如,这个读取接口对数据库的压力很大,但是又是热点数据,这个时候就需要考虑通过缓存手段,减少数据库的压力,比如我们的某助手产品的,点赞数,收藏数,分享数等是非常典型的热点数据,但是又不断变化,此时就需要将数据同步保存到Redis缓存,减少数据库压力。
6.2 缓存热点key
缓存中的一个Key(比如一个促销商品),在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询
七、总结
- 缓存击穿:使用双重检查锁的方式来解决,看到双重检查锁,大家肯定第一印象就会想到单例模式,这里也算是给大家复习一把双重检查锁的使用。
- 缓存穿透:将空对象放入缓存中、布隆过滤器、使用锁的时候注意锁的力度,建议换成分布式锁(
Redis或者Zookeeper实现),多个节点时可用Redisson提供的分布式锁! - 缓存雪崩:数据预热、分散缓存失效时间、数据永不过期。
缓存治理黄金法则
| 问题类型 | 推荐方案 | 工具推荐 |
|---|---|---|
| 缓存穿透 | 空值缓存 + 布隆过滤器 | Redisson BloomFilter |
| 缓存雪崩 | 随机TTL + 熔断降级 | Hystrix/Sentinel |
| 缓存击穿 | 互斥锁 + 热点预加载 | Redisson Lock |
| 数据一致性 | 延迟双删 + 最终一致性 | Canal+RocketMQ |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号