教育大营销平台day3 具体抽奖算法设计
抽奖算法的改进
解决序列化办法1:
解决序列化办法2:
解决redission存放java对象列表转型问题
-抛出问题:
在infrastructure层中,StrategyRepository实现queryStrategyAwardList(Long strategyId)方法时会出现redis前后存值取值类型转换问题,具体问题如下。
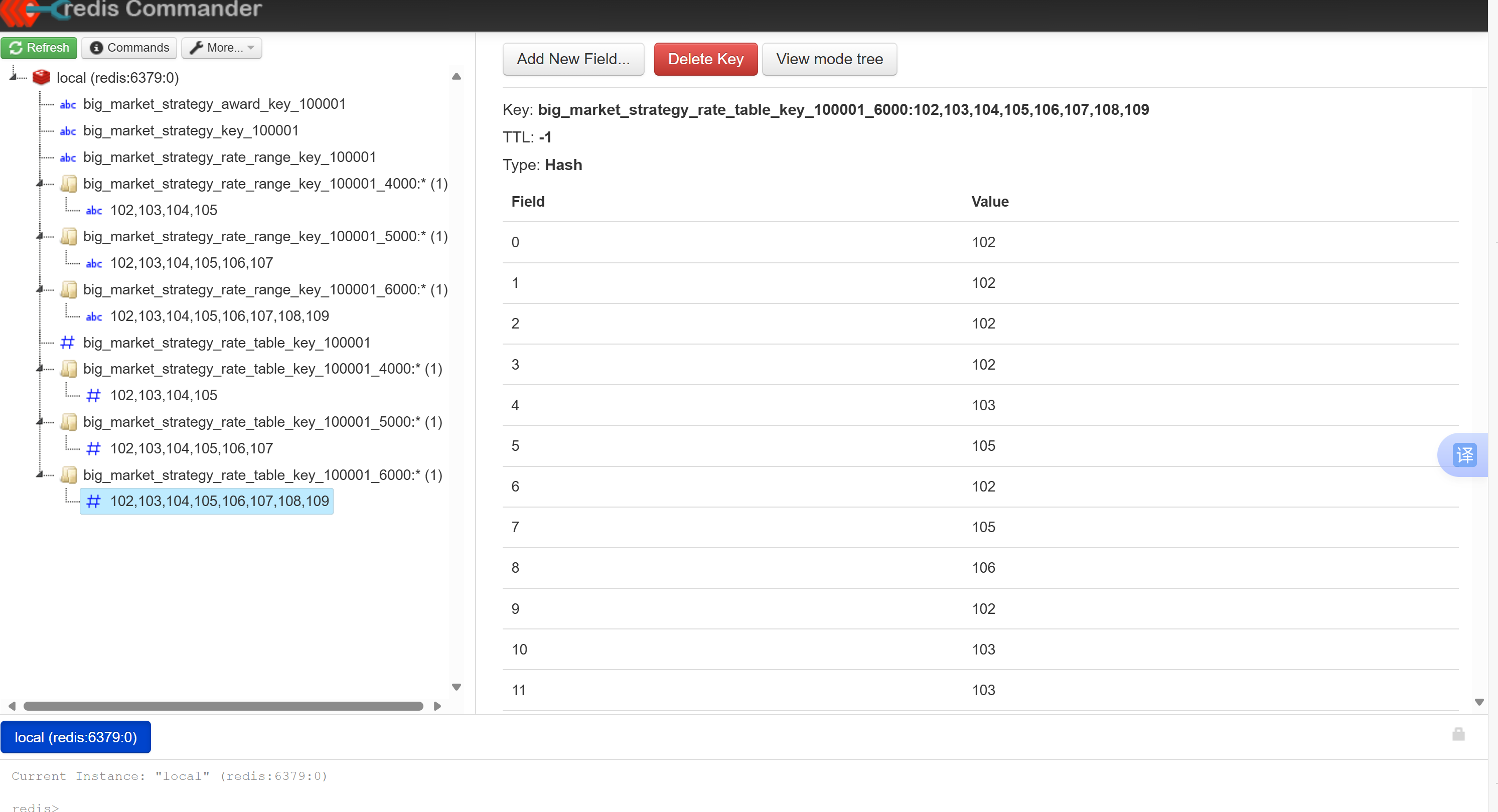
-优化前代码:对于这行strategyAwardEntities.add(strategyAwardEntity);我们存值存到redis中是字符串类型(查看redis图),而不是StrategyAwardEntity对象列表类型,因此在后续取值的时候,List
redis图(第一张)
异常图(第二张)
// 优先从缓存获取
String cacheKey = Constants.RedisKey.STRATEGY_AWARD_KEY + strategyId;
List
if (null != strategyAwardEntities && !strategyAwardEntities.isEmpty()) return strategyAwardEntities;
// 从库中获取数据
List
strategyAwardEntities = new ArrayList<>(strategyAwards.size());
for (StrategyAward strategyAward : strategyAwards) {
StrategyAwardEntity strategyAwardEntity = StrategyAwardEntity.builder()
.strategyId(strategyAward.getStrategyId())
.awardId(strategyAward.getAwardId())
.awardCount(strategyAward.getAwardCount())
.awardCountSurplus(strategyAward.getAwardCountSurplus())
.awardRate(strategyAward.getAwardRate())
.build();
strategyAwardEntities.add(strategyAwardEntity);
}
redisService.setValue(cacheKey, strategyAwardEntities);
return strategyAwardEntities;
}
-解决思路:
1.在IRedisService和RedissonService层中分别添加getList() 方法,这个方法返回的对象是一个代理对象,因此下面操作代理对象会同步到redis中,所以,代码上没有大幅度的改变,但是redis中存储对象的结构发生变化(如下图)
redis图(第三张)
2.但还没完,这样只是为后续解析操作提供便利。因为value值经过debug你会发现,他还是String类型,所以我目前没有太好的办法直接进行存储对象,因此我采用性能低的方法,就是解析字符串。在types层中加一个Utils包,然后自定义一个StringUtils类(如下)
public class StringUtils {
public static List<String> splitStr(String str){
String[] split = str.split("[\\\\(\\\\)]");
System.out.println(split[1]);
String[] splitTotal = split[1].split(",");
List<String> sArr = new ArrayList<>();
for(String s : splitTotal){
String[] filedArr = s.split("=");
sArr.add(filedArr[1]);
}
return sArr;
}
}
这个方法返回一个list
因此,问题到这就结束啦
@Override
public List
//1.通过策略ID去缓存中获取策略奖品集合
String cacheKey = Constants.RedisKey.STRATEGY_AWARD_KEY + strategyId;
List<StrategyAwardEntity> strategyAwardEntitiesTemp = new ArrayList<>();
//List<StrategyAwardEntity> strategyAwardEntities = redisService.getValue(cacheKey);
//从缓存中获取结果有转型问题都是String,因此需要解析一下重新放到队列中
List<String> strategyAwardEntities = redisService.getList(cacheKey);
if(null != strategyAwardEntities && !strategyAwardEntities.isEmpty()){
for(String str : strategyAwardEntities){
int i = 0;
//解析每一行数据
List<String> sArrList = StringUtils.splitStr(str);
StrategyAwardEntity strategyAwardEntity = StrategyAwardEntity.builder()
.strategyId(Long.parseLong(sArrList.get(i++)))
.awardId(Integer.parseInt(sArrList.get(i++)))
.awardCount(Integer.parseInt(sArrList.get(i++)))
.awardCountSurplus(Integer.parseInt(sArrList.get(i++)))
.awardRate(BigDecimal.valueOf(Double.parseDouble(sArrList.get(i))))
.build();
strategyAwardEntitiesTemp.add(strategyAwardEntity);
}
return strategyAwardEntitiesTemp;
}
//2.如缓存中无数据,就去数据库中获取数据
List<StrategyAward> strategyAwards = strategyAwardDao.queryStrategyAwardListByStrategyId(strategyId);
strategyAwardEntitiesTemp = new ArrayList<>(strategyAwards.size());
//3.把数据中的数据保存到缓存中去
for(StrategyAward strategyAward : strategyAwards){
StrategyAwardEntity strategyAwardEntity = StrategyAwardEntity.builder()
.strategyId(strategyAward.getStrategyId())
.awardId(strategyAward.getAwardId())
.awardCount(strategyAward.getAwardCount())
.awardCountSurplus(strategyAward.getAwardCountSurplus())
.awardRate(strategyAward.getAwardRate())
.build();
strategyAwardEntities.add(String.valueOf(strategyAwardEntity));
strategyAwardEntitiesTemp.add(strategyAwardEntity);
}
//redisService.setValue(cacheKey, strategyAwardEntities);
return strategyAwardEntitiesTemp;
}
这个方法可以保证业务顺利进行下去,但是代码量变大
关于这个序列化的处理的其他方法:
Redisson 常见的编解码器
基于你提供的代码上下文,Redisson 提供了多种编解码器(codec)用于处理数据的序列化和反序列化:
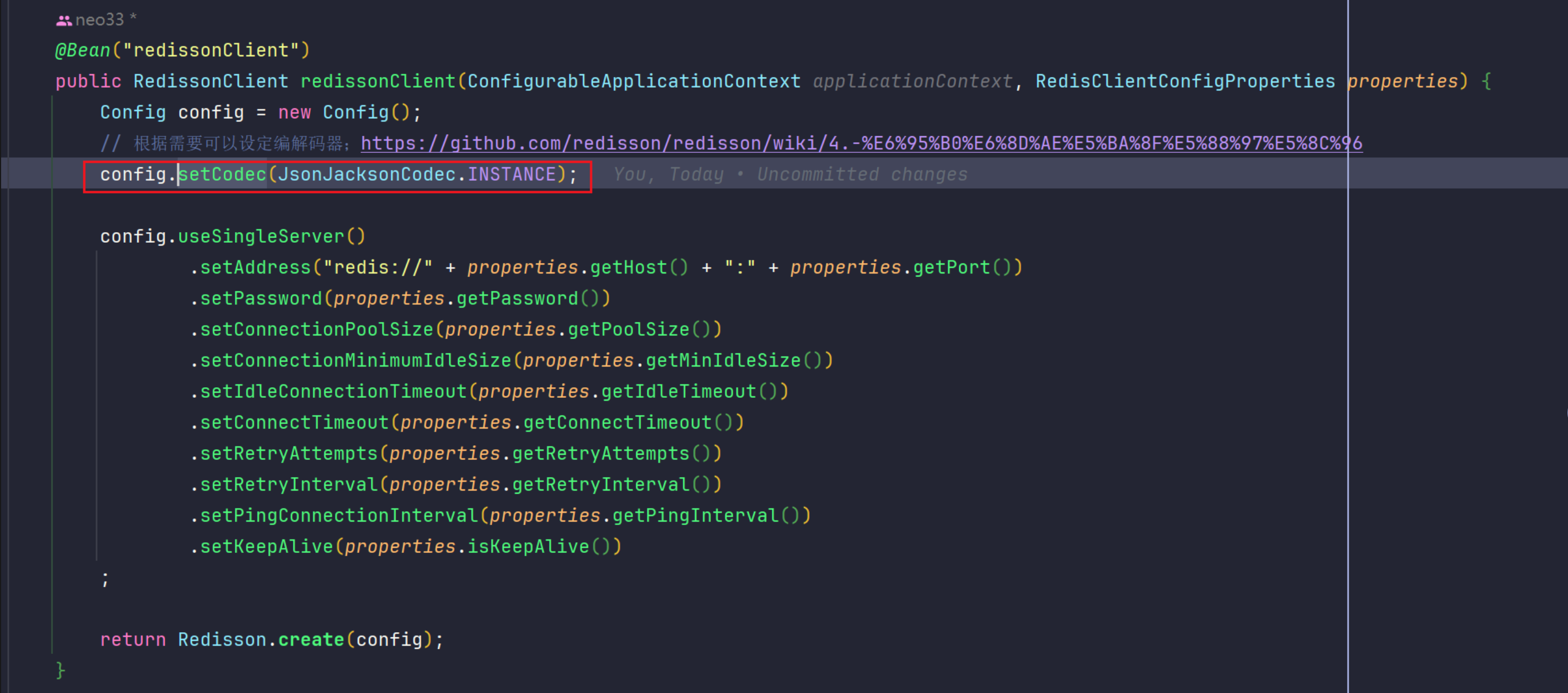
1. JsonJacksonCodec
config.setCodec(JsonJacksonCodec.INSTANCE);
- 使用 Jackson 库进行 JSON 序列化
- 数据以 JSON 格式存储,可读性好,通用性强
2. FSTCodec
config.setCodec(new FSTCodec());
- 使用 FST(Fast Serialization) 进行序列化
- 性能较高,序列化后的数据相对较小
3. KryoCodec
config.setCodec(new KryoCodec());
- 使用 Kryo 序列化框架
- 高性能,序列化速度快,数据体积小
4. SerializationCodec
config.setCodec(new SerializationCodec());
- 使用 Java 原生序列化
- 兼容性好,但性能相对较低,数据体积较大
5. LZ4Codec
config.setCodec(new LZ4Codec());
- 使用 LZ4 压缩算法进行序列化
- 数据压缩率高,适合存储大量数据
6. SnappyCodec
config.setCodec(new SnappyCodec());
- 使用 Snappy 压缩算法
- 压缩和解压缩速度快
7. AvroJacksonCodec
config.setCodec(new AvroJacksonCodec());
- 结合 Avro 和 Jackson
- 适合需要 Schema 管理的场景
自定义编解码器
如代码中的 [RedisCodec](file://C:\Users\ruofengcy\Downloads\big-market-231231-xfg-strategy-armory-rule-weight\big-market-231231-xfg-strategy-armory-rule-weight\big-market-app\src\main\java\cn\bugstack\config\RedisClientConfig.java#L53-L82) 类所示,你也可以自定义编解码器来满足特殊需求。
选择建议
- 开发调试阶段:推荐
JsonJacksonCodec,数据可读性好 - 生产环境:推荐
KryoCodec或FSTCodec,性能更好 - 存储空间敏感:推荐
LZ4Codec或SnappyCodec

 浙公网安备 33010602011771号
浙公网安备 33010602011771号