java学习笔记大全
快速开发指南和八股细分:
1.启动包:
源码下载百度网盘链接: https://pan.baidu.com/s/12haXVFytMxtbrLr51Vopfw 提取码: h4pi
2.Maven仓库:
Maven Repository: Search/Browse/Explore
3.redius启动常用指南:
启动redis服务:redis-server.exe ./redis.windows.conf
redis的Maven依赖:
4.ES安装指南
elasticsearch.bat
安装常见报错问题
kibana安装后生成可视化界面:
常见报错:
常用软件类库的下载包:
软件:常用软件类库安装包_免费高速下载|百度网盘-分享无限制
密码;dimv
5.Nacos配置依赖:
MYbatisplus3使用指南
上述图片中只能二选一: lombok和toString/hashcode
读取excel 的一些示例代码:
``
public static String excelToCsv(MultipartFile multipartFile) {
File file = null;
try {
file = ResourceUtils.getFile("classpath:网站数据.xlsx");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
// 读取数据
List<Map<Integer, String>> list = (List<Map<Integer, String>>) EasyExcel.read(file);
try {
list = EasyExcel.read(multipartFile.getInputStream())
.excelType(ExcelTypeEnum.XLSX)
.sheet()
.headRowNumber(0)
.doReadSync();
} catch (IOException e) {
log.error("表格处理错误", e);
}
if (CollUtil.isEmpty(list)) {
return "";
}
System.out.println(list);
sql注入
关于redis配置:常见的关于redis配置的问题
Swagger2文档和Swagger3文档:
下面只是swagger2
下面是swagger3
关于swagger配置:Swagger(全) SpringBoot整合与使用_springboot swagger-CSDN博客
rabbitmq启动指南:
rabbitmq-plugins.bat enable rabbitmq_management
rabbitmq-service.bat stop
rabbitmq-service.bat install
rabbitmq-service.bat start
6.consule:
下载地址:https://developer.hashicorp.com/consul/install
下载对应的版本【adm64版本的就是x86_64版本的,386就是x86_32版本的】
windows使用下面的命令启动,然后缩放到最小化就行
consul agent -dev
访问8500端口,进入ui界面
localhost:8500
启动类加上@EnableDiscoveryClient注解,开启服务发现功能【有人说可以不加这个注解了】
@EnableDiscoveryClient
八股细分:
并发编程-原理部分:
AQS:
下述通知相邻node采用的都是park,unpark;
AQS实现锁:

tryAcquire:尝试独占获取资源,成功返回 true,失败返回 false。
tryRelease:尝试释放独占获取的资源,成功返回 true,失败返回 false。
tryAcquireShared:尝试共享获取资源,成功返回正数,失败返回 false。
tryReleaseShared:尝试释放共享获取的资源,成功返回 true,失败返回 false。
isHeldExclusively:检查资源是否被独占持有,是返回 true,否则返回 false。

waitStatus:
0:表示节点处于默认状态,没有特殊等待。
1:表示节点正在等待获取锁。
-1:表示节点被阻塞,等待被唤醒。
-2:表示节点正在等待某个条件变量
不可重入锁的实现:
自定义同步器,自定义锁,结合线程启动。
关于上述不可重入锁的人各个参数的设置:
ReentrantLock锁:
CAS 操作是一种无锁的线程安全操作。
改进:
AQS 的 enq 方法相比于 CLH 队列的改进主要体现在以下几个方面:
使用虚拟头节点和尾节点,简化队列操作,避免空指针异常。
使用 CAS 操作,确保线程安全,避免显式锁的使用。
自旋循环,确保节点能够成功加入队列,提高并发性能。
双向链表,方便节点的插入、删除和遍历操作。
这些改进使得 AQS 的同步队列更加高效和稳定,能够更好地应对高并发场景。
下图中黄色标记对应了waitstatus的状态:
黄色标记的作用是表示Node节点的waitStatus状态,0表示节点处于默认状态,1表示节点正在等待获取锁。
0:表示节点处于默认状态,没有特殊等待。
1:表示节点正在等待获取锁。
-1:表示节点被阻塞,等待被唤醒。
-2:表示节点正在等待某个条件变量。
ReentrantLock非公平锁:
1.竞争锁的策略:
2.竞争锁失败后逐个阻塞
3.释放锁后:
4.重新争夺锁以及非公平争夺的体现
两个原理:
可重入原理:
可打断原理:
打断模式与不可打断模式:
打断模式原理:
尝试获取锁,如果失败,将当前线程加入 AQS 队列中等待。
在等待过程中,如果线程被中断,会设置中断标记。
如果线程被唤醒并成功获取锁,返回中断状态。
如果线程在获取锁过程中被中断,重新设置中断标记,确保中断状态被正确处理。
不可打断模式原理:
ReentrantLock公平锁:
与非公平锁实现的区别关键
带条件变量的锁实现原理:
创建条件变量 ------释放锁--------阻塞条件变量------------signal重新移入队列
关于node队列:
Node.SIGNAL:表示前驱节点正在等待当前线程被唤醒。
Node.WAITING:表示前驱节点正在等待某个条件。
Node.TIMED_WAITING:表示前驱节点正在等待某个条件,但有时间限制。
Node.CANCELLED:表示前驱节点已经取消等待。
读写锁实现原理:
备注:释放锁时必须为独占锁,是为了确保线程安全、避免死锁和资源泄露,以及维护锁的状态一致性。这是锁机制设计中的一个重要原则,确保多个线程在访问共享资源时能够正确同步。检查方法:
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
0.写锁优先比读锁生效了
1.持有锁,不释放:
2.释放t1锁后,持续唤醒sharde类型锁,然后加读锁,然后将下一节点位置设置成头节点:
读锁和写锁的各自释放流程:
信号量工具:
用seamphore改造数据库连接池
stampedlock加锁原理:
LinkedBlockingQueue:

h:临时指针,用于指向链表的头节点(head),方便操作。
first:指针,用于指向链表中的第一个实际节点(head.next),方便出队操作。
ConcurrentLinkedQueue 原理
ConcurrentHashMap:
jdk1.7:
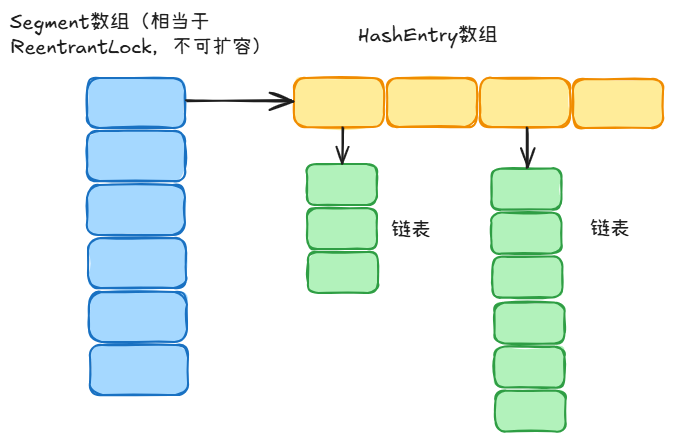
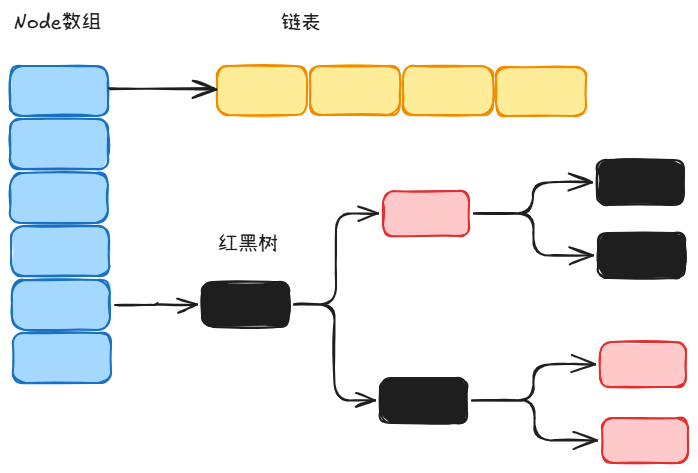
jdk1.8:
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表.
HashMap和currenthashmap全解
HashMap1.7:
resize方法主要是进行扩容
HashMap1.8:
环形链表:
若查询一个不存在的key就会导致........
currentHashMap1.7:
currentHashMap1.8:
常见面试内容::
HashMap
1. HashMap 是什么?
HashMap 是 Java 中的一个散列表,它存储键值对(key-value pairs),并使用键的哈希值来确定存储位置。HashMap 允许存储 null 键和 null 值,但键必须唯一。
2. HashMap 的 get 和 put 过程
2.1 put 过程
- 计算哈希值:根据键(key)计算哈希值,确定存储位置。
- 检查冲突:如果哈希值相同,检查键是否相同。如果相同,更新值;如果不同,处理冲突。
- 存储节点:将键值对存储在计算出的位置。如果发生冲突,使用链表或红黑树存储。
2.2 get 过程
- 计算哈希值:根据键(key)计算哈希值,确定查找位置。
- 查找节点:在计算出的位置查找键值对。如果发生冲突,遍历链表或红黑树查找。
3. Java 1.8 的优化
3.1 优化内容
- 链表转红黑树:当链表长度超过 8 时,将链表转换为红黑树,提高查找效率。
- 红黑树转链表:当链表长度小于 6 时,将红黑树转换回链表,减少内存开销。
- 同步优化:在
ConcurrentHashMap中,使用更细粒度的锁,提高并发性能。
4. HashMap 是线程安全的吗?
不是。HashMap 在多线程环境下不是线程安全的。如果多个线程同时对 HashMap 进行修改操作,可能会导致数据不一致、死循环等问题。
5. 不安全会导致哪些问题?
- 数据不一致:多个线程同时修改 HashMap,可能导致数据丢失或覆盖。
- 死循环:在扩容过程中,如果多个线程同时操作,可能会形成环形链表,导致死循环。
- 并发修改异常:在遍历 HashMap 时,如果其他线程修改了 HashMap,可能会抛出
ConcurrentModificationException。
6. 如何解决?
- 使用同步:在操作 HashMap 时使用
synchronized关键字或ReentrantLock进行同步。 - 使用线程安全的容器:使用
ConcurrentHashMap或Collections.synchronizedMap()方法创建线程安全的 Map。
7. 有没有线程安全的并发容器?
有。Java 提供了多种线程安全的并发容器,如 ConcurrentHashMap、CopyOnWriteArrayList、CopyOnWriteArraySet 等。
8. ConcurrentHashMap 是如何实现的?
8.1 Java 1.7 实现
- 分段锁:
ConcurrentHashMap使用分段锁(Segment)来实现线程安全。每个 Segment 是一个独立的锁,多个线程可以同时操作不同的 Segment。 - 链表存储:每个 Segment 内部使用链表存储键值对。
8.2 Java 1.8 实现
- 取消分段锁:
ConcurrentHashMap取消了分段锁,改为使用Node数组和CAS操作来实现线程安全。 - 链表转红黑树:当链表长度超过 8 时,将链表转换为红黑树,提高查找效率。
- 红黑树转链表:当链表长度小于 6 时,将红黑树转换回链表,减少内存开销。
9. 为什么这么做?
- 提高并发性能:通过取消分段锁,使用更细粒度的锁和
CAS操作,ConcurrentHashMap在高并发环境下具有更高的性能。 - 减少内存开销:链表转红黑树和红黑树转链表的优化,减少了内存开销,提高了内存利用率。
- 简化实现:取消分段锁后,
ConcurrentHashMap的实现更加简洁,减少了复杂度。
总结
- HashMap 是一个散列表,存储键值对,但不是线程安全的。
- get 和 put 过程涉及哈希值计算、冲突处理和节点存储。
- Java 1.8 对 HashMap 和 ConcurrentHashMap 进行了优化,提高了性能和内存利用率。
- 线程安全问题 可以通过同步或使用线程安全的容器来解决。
- ConcurrentHashMap 在 Java 1.7 和 1.8 中有不同的实现,1.8 版本更加高效和简洁。
Spring5:
常见包:
获取Bean的n种方法:
1.普通bean的读入
2.set方法读入
3.构造函数读入
4.p名称空间注入:
5.注入bean的特殊值:
引入外部bean
注入集合属性:
集合中设置对象属性值与引入集合:
提取集合注入部分:
Aop编程完整代码:
正常配置方法:
使用的就是
示例代码:
`java
复制
@Component
@Aspect
public class LogAspect {
// 定义一个切入点,匹配 User 类的 add 方法
@Pointcut("execution(* com.atguigu.spring5.aopanno.User.add(..))")
public void pointcut() {}
// 前置通知
@Before("pointcut()")
public void before() {
System.out.println("Before the method is executed...");
}
// 后置通知
@AfterReturning("pointcut()")
public void afterReturning() {
System.out.println("After the method is executed successfully...");
}
// 异常通知
@AfterThrowing("pointcut()")
public void afterThrowing() {
System.out.println("After the method throws an exception...");
}
// 最终通知
@After("pointcut()")
public void after() {
System.out.println("After the method is executed, regardless of success or failure...");
}
// 环绕通知
@Around("pointcut()")
public void around(ProceedingJoinPoint pjp) throws Throwable {
System.out.println("Before the method is executed (around)...");
pjp.proceed(); // 执行目标方法
System.out.println("After the method is executed (around)...");
}
}
-
定义被增强类
java
复制
@Component
public class User {
public void add() {
System.out.println("Adding a user...");
}
} -
配置类
java
复制
@Configuration
@ComponentScan(basePackages = {"com.atguigu.spring5.aopanno"})
@EnableAspectJAutoProxy
public class AppConfig {
} -
主类
java
复制
public class MainApp {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
User user = context.getBean("user", User.class);
user.add();
}
} -
Spring 配置文件 (applicationContext.xml)
xml
复制<context:component-scan base-package="com.atguigu.spring5.aopanno" />
<aop:aspectj-autoproxy />
-
运行结果
复制
Before the method is executed...
Before the method is executed (around)...
Adding a user...
After the method is executed (around)...
After the method is executed successfully...
After the method is executed, regardless of success or failure...`
配置事务:
下面有两种方法:
声明式:
事务管理器+数据库连接池+jdbctemplate
xml式:
函数式注册风格:
@Test:标记测试方法。
GenericApplicationContext:Spring 5 的核心容器,支持函数式风格的 Bean 管理。
context.refresh():初始化 Spring 容器。
context.registerBean():以函数式风格注册 Bean。
context.getBean():从容器中获取 Bean。
System.out.println():打印对象,验证获取结果。

webflux形式的思考:
经典的stream方法:
Stream
注解大全:
1.@PathVariable
@PathVariable 是 Spring MVC 中用于将 URL 模板变量绑定到你控制器处理器方法参数上的注解。这个注解使你能够访问 URI 模板变量,这些变量是在请求 URL 中定义的。通过这种方式,你可以将 URL 中的一部分动态地映射到你的控制器方法中,而不需要将这些部分作为查询参数(query parameters)或路径参数(path parameters,但这里特指 URL 路径中的动态部分)来处理。
具体意思
当你定义一个 URL 模板时,可以在其中包含变量。这些变量被大括号 {} 包围。例如,在 /user/{userId} 这个 URL 模板中,userId 就是一个变量。在控制器的方法中,你可以使用 @PathVariable 注解来指定一个方法参数应该绑定到这个 URL 模板变量上。
作用
- 绑定 URL 模板变量:如上所述,
@PathVariable用于将 URL 模板中的变量绑定到控制器方法的参数上。这使得你可以根据 URL 的不同部分来动态地处理请求。 - 简化 URL 设计:通过使用
@PathVariable,你可以设计出更加简洁和直观的 URL,这些 URL 直接反映了资源的结构,而不是依赖于查询参数来传递必要的信息。 - 增强 RESTful 服务的可读性:在构建 RESTful Web 服务时,使用
@PathVariable可以让你的服务接口更加符合 REST 风格,使得接口的设计更加直观和易于理解。
示例
在这个例子中,/users/{userId} 是一个 URL 模板,其中 {userId} 是一个变量。当请求匹配这个模板时(例如,/users/123),@PathVariable("userId") 会将 123 这个值绑定到 getUserById 方法的 userId 参数上。然后,控制器方法可以使用这个值来执行相应的业务逻辑。注意,如果 @PathVariable 的 value 属性(在这个例子中是 "userId")与 URL 模板中的变量名相同,则可以省略 value 属性,直接写 @PathVariable Long userId。
以下是初步理解
2.@Slf4j
3.@restcontroller层
4.一个主要的注解类:@RequestMapping
一个完整的请求路径,应该是类上@RequestMapping的value属性 + 方法上的 @RequestMapping的value属性
5.@param
@param的基本用法,主要是关于参数的提取与应用。
https://blog.csdn.net/Sunshineoe/article/details/114697944?ydreferer=aHR0cHM6Ly9jbi5iaW5nLmNvbS8%3D
6.@requestparam
这个注解也可以处理和人表单项不一致的情况;
7.@datetimeformat
8.@value
9.@value属性
10。@ConfigurationProperties
12.@bean
@Repository注解的作用和用法,以及和@Mapper的区别
13.@Repository
1、@Repository的作用
@Repository是属于Spring的注解。它用来标注访问层的类(Dao层),它表示一个仓库,主要用于封装对于数据库的访问。其实现方式与@Component注解相同,只是为了明确类的作用而设立。
即@Repository是@Component注解的一个派生品,与@Service和@Controller都可以理解为@Component注解的扩展。他们的作用都是在类上实例化bean,并把当前类对象的实现类交给spring容器进行管理。
换句话说,@Repository注解修饰哪个类表明这个类具有对数据库CRUD的功能,用在持久层的接口上。
另外,作为spring的注解,他还能把所标注的类中抛出的数据访问异常封装为spring的数据访问异常类型。
2、@Repository与@Service和@Component有什么区别?
@Repository作用如上所说。
@Service注解用来标注服务层中的类,用于处理业务逻辑。在使用@Service注解标记的类中,通常会注入@Reposity的类。
@Component注解是通用的注解,用来标记所有被spring容器管理的组件。在使用@Component注解标记的类中,通常会注入@Service和@Repository标记的类。
本质上都是把实例化对象交给spring管理。
3、@Repository和@Mapper的异同
@Mapper是属于mybatis的注解。在程序中,mybatis需要找到对应的mapper,在编译时候动态生成代理类,实现数据库查询功能。
@Mapper和@Repository注解的使用方式一样,都是在持久层的接口上添加注解。
但是如果只是单独的使用@Mapper注解的话,在idea中进行自动装配的时候,会出现警告,提示找不到这个bean。但是这个不影响程序运行,可以直接忽略。
想要不出现这个警告,可以在idea设置中对这种警告进行忽略,也可以在使用@Mapper的地方同时使用
@Repository注解。这样spring会扫描@Repository并识别这个bean,就不会出现这个警告。
正常情况下的使用,我们都是使用@Mapper居多,而不使用@Repository注解。
不使用@Repository注解,而实现注入这个接口的实现类主要有以下3种方法:
1、在spring的配置文件中,配置了MapperScannerConfigure这个bean,他会扫描持久层接口创建实现类交给spring来管理。
2、接口使用@Mapper注解。
3、springboot的启动类上使用@MapperScan注解,和MapperScannerConfigure的作用一样。
4、正确的单独使用@Repository
@Repository注解是用于标记数据访问层的组件的注解,它会被spring扫描并注入到ioc容器中。即使没有使用@MapperScan注解或MapperScannerConfigurer,只要@Repository注解标记的组件与Mybatis的mapper接口实现相同,它也可以生效。
但是,在mybatis中使用@Repository注解可能会有一些问题。当使用@Repository注解时,spring会将其视为spring的组件,即为该类创建一个代理对象并在ioc容器进行管理。但是,mybatis中的mapper接口实现并不是spring的组件,他们是由mybatis创建的代理对象。使用@Repository注解可能会导致mybatis创建的代理对象被spring重新创建代理,进而出现问题。
因此,建议在mybatis中使用@MapperScan注解或者MapperScannerConfigurer来扫描mapper接口实现,并将他们注入到ioc容器中,而不是使用@Repository注解。
5、总结:
1、@Repository是spring的注解,@Mapper是mybatis的注解。
2、@Repository与@Mapper都可以使用,二者可以同时出现,也可以单一使用。
3、单独使用@Repository,需要配合使用MapperScannerConfigurer或者@MapperScan注解。
4、单独使用@Mapper时,可能会在编辑器出现警告,不影响程序运行。可以配合使用@Repository消除警告。(也可以在编辑器中设置忽略这种警告)
14.@componentScan
15.@EnableXXXX
16.datetimeformat类的问题
17.@return注解的具体使用
@Builder
@postmappping @pathvarable作用
占位符
扫描部分:
18.关于aop的注解
18.data注解的具体作用:
-
这里是requestmapping的具体作用
- @ requestparam
20.关于传递的不同实体类。
21.@exceptionhandler
@ExceptionHandler 的作用和意义
作用
@ExceptionHandler 是 Spring MVC 中的一个注解,用于处理控制器方法中抛出的异常。具体来说,当控制器方法中抛出一个异常时,@ExceptionHandler 注解的方法会被调用,用于处理该异常并返回一个响应给客户端。
意义
- 集中处理异常:通过
@ExceptionHandler,可以将异常处理逻辑集中在一个地方,而不是分散在各个控制器方法中,从而提高代码的可维护性和可读性。 - 统一异常处理:可以统一处理特定类型的异常,返回统一的错误响应,提高用户体验。
- 简化代码:避免在每个控制器方法中都编写异常处理逻辑,简化代码结构。
示例
假设有一个控制器方法可能会抛出 UserNotFoundException 异常,可以使用 @ExceptionHandler 注解来处理该异常:
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(UserNotFoundException.class)
public ResponseEntity<String> handleUserNotFoundException(UserNotFoundException ex) {
return new ResponseEntity<>("User not found: " + ex.getMessage(), HttpStatus.NOT_FOUND);
}
}
- 解释:
@ControllerAdvice:表示这是一个全局的异常处理器,可以处理所有控制器方法中抛出的异常。@ExceptionHandler(UserNotFoundException.class):表示这个方法专门处理UserNotFoundException异常。handleUserNotFoundException方法:当UserNotFoundException异常被抛出时,这个方法会被调用,返回一个包含错误信息和状态码的响应。
总结
@ExceptionHandler的作用:处理控制器方法中抛出的异常,返回一个响应给客户端。- 意义:集中处理异常,统一异常处理逻辑,简化代码结构,提高代码的可维护性和可读性。
REQUIRED:有事务则复用,无事务则创建。
REQUIRED_NEW:总是创建新事务,挂起原有事务。
SUPPORTS:有事务则运行在事务中,无事务则不运行在事务中。
NOT_SUPPORTED:不运行在事务中,有事务则挂起。
MANDATORY:必须运行在事务中,无事务则抛出异常。
NEVER:不运行在事务中,有事务则抛出异常。
NESTED:有事务则嵌套运行,无事务则创建新事务。
@requestbody:
作用
@RequestBody 是 Spring MVC 中的一个注解,用于将客户端发送的请求体(通常是一个 JSON 或 XML 格式的字符串)转换为 Java 对象。具体来说,它会将请求体中的数据自动绑定到方法参数中指定的 Java 对象上。
意义
- 简化数据接收:通过
@RequestBody,开发者不需要手动解析请求体中的数据,Spring MVC 会自动完成数据的绑定和转换。 - 支持多种数据格式:
@RequestBody支持多种数据格式(如 JSON、XML 等),并可以与消息转换器(如 Jackson、Gson 等)配合使用,自动将请求体中的数据转换为 Java 对象。 - 提高开发效率:开发者可以直接在方法参数中使用 Java 对象来接收请求数据,而不需要手动解析请求体,从而提高开发效率。
示例
假设有一个用户注册的接口,客户端发送一个 JSON 格式的请求体:
{
"name": "John",
"age": 25
}
在 Spring MVC 控制器中,可以使用 @RequestBody 注解来接收这个请求体:
@RestController
public class UserController {
@PostMapping("/register")
public String registerUser(@RequestBody User user) {
System.out.println("Name: " + user.getName());
System.out.println("Age: " + user.getAge());
return "User registered successfully!";
}
}
- 解释:
@RequestBody User user表示将请求体中的数据自动绑定到User对象上。Spring MVC 会使用消息转换器(如 Jackson)将 JSON 数据转换为User对象。
总结
@RequestBody的作用:将客户端发送的请求体数据自动转换为 Java 对象。- 意义:简化数据接收过程,支持多种数据格式,提高开发效率。
@requestmapping注解:
浏览器的核心解析:
thymeleaf使用@{}填写路径,且自带tomcat中设置的默认文本路径
使用()填写请求参数
作用:顾名思义,@RequestMapping`注解的作用就是将请求和处理请求的控制器方法关联起来,建立映射关系。SpringMVC 接收到指定的请求,就会来找到在映射关系中对应的控制器方法来处理这个请求。
位置
@RequestMapping标识一个类:设置请求路径的初始信息,作为类里所有控制器方法映射路径的的公共前缀部分
@RequestMapping标识一个方法:设置映射请求请求路径的具体信息
@RequestMapping注解
作用:顾名思义,@RequestMapping`注解的作用就是将请求和处理请求的控制器方法关联起来,建立映射关系。SpringMVC 接收到指定的请求,就会来找到在映射关系中对应的控制器方法来处理这个请求。
value,method属性:
@RequestMapping( value = {"/testRequestMapping", "/test"}, method = {RequestMethod.GET, RequestMethod.POST} ) public String testRequestMapping(){ return "success"; }
params属性:
Header属性:
`“header”:要求请求映射所匹配的请求必须携带header请求头信息
“!header”:要求请求映射所匹配的请求必须不能携带header请求头信息
“header=value”:要求请求映射所匹配的请求必须携带header请求头信息且header=value
“header!=value”:要求请求映射所匹配的请求必须携带header请求头信息且header!=value
若当前请求满足@RequestMapping注解的value和method属性,但是不满足headers属性,此时页面显示404错误,即资源未找到`
检测路径占位符:
获取请求参数:
解决请求参数乱码问题:
获取请求参数体:
@Requestparam注解
@RequestHeader
@RequestMapping("/header")
public String testHeader(@RequestHeader(value = "Host") String host,
@RequestHeader(value = "Accept-Encoding") String code){
System.out.println(host+"**"+code);
return "target";
}
@cookievalue:
`@CookieValue
@CookieValue是将cookie数据和控制器方法的形参创建映射关系
@CookieValue注解一共有三个属性:value、required、defaultValue,用法同@RequestParam
session依赖于cookie,cookie在第一次请求时由服务器创建,通过响应头返回给浏览器并保存在浏览器中,cookie默认在浏览器关闭后自动清除`
简单解释
@CookieValue 是一个注解(Annotation),用于在 Spring MVC 控制器中将 HTTP 请求中的 Cookie 数据 映射到方法的参数上。简单来说,它可以让控制器方法直接获取客户端发送的 Cookie 数据。
作用
- 获取 Cookie 数据:通过
@CookieValue,可以直接从请求中提取指定的 Cookie 值,并将其作为方法参数传递给控制器方法。 - 简化代码:不需要手动从
HttpServletRequest中获取 Cookie 数据,@CookieValue会自动完成这些工作。
属性说明
value:指定要获取的 Cookie 的名称(必填)。required:指定该 Cookie 是否必须存在(默认为true)。如果设置为true,但请求中没有对应的 Cookie,会抛出异常;如果设置为false,则不会抛出异常。defaultValue:指定当 Cookie 不存在时的默认值(只有在required = false时有效)。
示例代码
1. 获取一个必需的 Cookie 值
import org.springframework.web.bind.annotation.CookieValue;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class CookieController {
@GetMapping("/get-cookie")
public String getCookie(@CookieValue("username") String username) {
return "Welcome, " + username + "!";
}
}
- 解释:
- 当客户端访问
/get-cookie时,Spring 会尝试从请求的 Cookie 中获取名为username的值。 - 如果
username存在,返回欢迎信息;如果不存在,会抛出异常(因为required默认为true)。
- 当客户端访问
2. 获取一个非必需的 Cookie 值
@GetMapping("/get-cookie-optional")
public String getCookieOptional(@CookieValue(value = "username", required = false) String username) {
return username != null ? "Welcome, " + username + "!" : "Welcome, Guest!";
}
- 解释:
- 如果
username存在,返回欢迎信息;如果不存在,返回默认的 "Welcome, Guest!"。
- 如果
3. 设置默认值
@GetMapping("/get-cookie-default")
public String getCookieWithDefaultValue(@CookieValue(value = "username", defaultValue = "Guest") String username) {
return "Welcome, " + username + "!";
}
- 解释:
- 如果
username存在,使用实际值;如果不存在,使用默认值Guest。
- 如果
总结
@CookieValue用于从请求的 Cookie 中提取数据。- 它的用法和
@RequestParam类似,但专门用于处理 Cookie 数据。 - 通过
required和defaultValue属性,可以灵活地处理 Cookie 是否存在的情况。
例子
假设客户端发送了一个请求,Cookie 中包含以下数据:
username=John
访问 /get-cookie 时,返回:
Welcome, John!
如果 Cookie 中没有 username,访问 /get-cookie 会抛出异常,而访问 /get-cookie-optional 或 /get-cookie-default 会返回默认值。
@EnableAspectJAutoProxy
注解,开启aspect aop注解支持
@ComponentScan("com.atguigu.service")
注解,进行业务组件扫描
@transactionManager(DataSource dataSource)
方法,指定具体的事务管理器
@PropertySource注解
@PropertySource 是 Spring 框架中的一个注解,用于指定一个外部的属性文件(如 .properties 文件)作为配置源。通过这个注解,可以将外部属性文件中的属性加载到 Spring 的 Environment 对象中,从而可以在应用程序中使用这些属性。
意思
指定配置源:告诉 Spring 从哪个外部文件中加载配置属性。
加载属性文件:将指定的属性文件中的属性加载到 Spring 的 Environment 对象中。
示例
假设你有一个外部的属性文件 application.properties,内容如下:
properties
app.name=MyApp
app.version=1.0
你可以在 Spring 配置类中使用
@PropertySource 注解来加载这个文件:
@Configuration
@PropertySource("classpath:application.properties")
public class AppConfig {
}
解释:
@PropertySource("classpath:application.properties") 表示从类路径(classpath)下的 application.properties 文件中加载配置属性。
这些属性会被加载到 Spring 的 Environment 对象中,可以在应用程序中通过 @Value 注解或 Environment 对象获取这些属性。
总结
作用:指定一个外部的属性文件作为配置源,将文件中的属性加载到 Spring 的 Environment 对象中。
意思:告诉 Spring 从哪个文件中加载配置属性。
@resultType:
自动映射,用于属性名和表中字段名一致的情况
@resultMap:
自定义映射,用于一对多或多对一或字段名和属性名不一致的情况
@requestparam
@GetMapping("/search")
public String search(@RequestParam(value = "q", defaultValue = "java") String query) {
System.out.println("Query: " + query);
return "search";
}
处理与参数名字不一致的情况
@param
public interface UserMapper {
List<User> selectUsers(@Param("username") String userName, @Param("age") int userAge);
}
@Options(useGeneratedKeys = true, keyProperty = "id"):
useGeneratedKeys = true:表示使用数据库自动生成的主键。
keyProperty = "id":指定 User 对象的 id 属性用于接收自动生成的主键值。
@Data注解
作用的具体实现
四个域对象:
1.Restful案例
Servlet:处理请求并返回响应。
JSP:生成动态网页内容。
DispatcherServlet:在 Spring MVC 中负责请求的分发和路由。
关于资源:HTML/XML/JSON/纯文本/图片/视频/音频
它们分别对应四种基本操作:GET 用来获取资源,POST 用来新建资源,PUT 用来更新资源,DELETE 用来删除资源
在 Spring MVC 的控制器方法中,当你使用 Model、ModelMap 或 Map 作为参数时,Spring MVC 会自动将这些参数转换为 BindingAwareModelMap 类型。这样做的原因是:
统一处理:Spring MVC 需要一个统一的方式来处理模型数据,包括数据绑定和验证等。
功能增强:BindingAwareModelMap 提供了一些额外的功能,比如数据绑定和验证的支持,而这些功能在普通的 Model 或 Map 中是没有的。
HiddenHttpMethodFilter 过滤器的作用是将 POST 请求转换为 PUT 或 DELETE 请求,从而解决浏览器不支持 PUT 和 DELETE 请求的问题。
配置时需要注意过滤器的注册顺序,确保字符集设置在获取请求参数之前完成
在 web.xml 文件中注册 HiddenHttpMethodFilter 过滤器:
xml
复制
reaquestbody和responsebodyde的区别要注意:
经典写法
Stream的经典语句写法:
List
List
.map(n -> n + 1)
.collect(Collectors.toList());
userMapper.selectList(null).forEach(System.out::println);
JSONObject jsonObject = JSON.parseObject(string);
集合如何获取流:
import java.util.*;
import java.util.stream.Stream;
public class Demo04GetStream {
public static void main(String[] args) {
// 集合获取流
// Collection接口中的方法: default Stream<E> stream() 获取流
List<String> list = new ArrayList<>();
// ...
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<>();
// ...
Stream<String> stream2 = set.stream();
Vector<String> vector = new Vector<>();
// ...
Stream<String> stream3 = vector.stream();
}
}
map获取流:
import java.util.stream.Stream;
public class Demo06GetStream {
public static void main(String[] args) {
// Stream中的静态方法: static Stream of(T... values)
Stream<String> stream6 = Stream.of("aa", "bb", "cc");
String[] arr = {"aa", "bb", "cc"};
Stream<String> stream7 = Stream.of(arr);
Integer[] arr2 = {11, 22, 33};
Stream<Integer> stream8 = Stream.of(arr2);
// 注意:基本数据类型的数组不行
int[] arr3 = {11, 22, 33};
Stream<int[]> stream9 = Stream.of(arr3);
}
}
@Test
public void testCount() {
List<String> one = new ArrayList<>();
Collections.addAll(one, "迪丽热巴", "宋远桥", "苏星河", "老子", "庄子", "孙子");
System.out.println(one.stream().count());
}
Optional<User> user = findUser(userId);
if (user.isPresent()) {
System.out.println("用户找到了:" + user.get().getName());
} else {
System.out.println("没有找到用户");
}
拦截器与过滤器:
结合图理解拦截器:
添加拦截器常用方法:
@EnableWebMvc //json数据处理,必须使用此注解,因为他会加入json处理器
@Configuration
@ComponentScan(basePackages = {"com.atguigu.controller","com.atguigu.exceptionhandler"}) //TODO: 进行controller扫描
//WebMvcConfigurer springMvc进行组件配置的规范,配置组件,提供各种方法! 前期可以实现
public class SpringMvcConfig implements WebMvcConfigurer {
//配置jsp对应的视图解析器
@Override
public void configureViewResolvers(ViewResolverRegistry registry) {
//快速配置jsp模板语言对应的
registry.jsp("/WEB-INF/views/",".jsp");
}
//开启静态资源处理 <mvc:default-servlet-handler/>
@Override
public void configureDefaultServletHandling(DefaultServletHandlerConfigurer configurer) {
configurer.enable();
}
//添加拦截器
@Override
public void addInterceptors(InterceptorRegistry registry) {
//将拦截器添加到Springmvc环境,默认拦截所有Springmvc分发的请求
registry.addInterceptor(new Process01Interceptor());
}
}
拦截器的添加和过滤配置:
//添加拦截器
@Override
public void addInterceptors(InterceptorRegistry registry) {
//将拦截器添加到Springmvc环境,默认拦截所有Springmvc分发的请求
registry.addInterceptor(new Process01Interceptor());
//精准匹配,设置拦截器处理指定请求 路径可以设置一个或者多个,为项目下路径即可
//addPathPatterns("/common/request/one") 添加拦截路径
registry.addInterceptor(new Process01Interceptor()).addPathPatterns("/common/request/one","/common/request/tow");
//排除匹配,排除应该在匹配的范围内排除
//addPathPatterns("/common/request/one") 添加拦截路径
//excludePathPatterns("/common/request/tow"); 排除路径,排除应该在拦截的范围内
registry.addInterceptor(new Process01Interceptor())
.addPathPatterns("/common/request/one","/common/request/tow")
.excludePathPatterns("/common/request/tow");
}
多个拦截器执行顺序
- preHandle() 方法:SpringMVC 会把所有拦截器收集到一起,然后按照配置顺序调用各个 preHandle() 方法。
- postHandle() 方法:SpringMVC 会把所有拦截器收集到一起,然后按照配置相反的顺序调用各个 postHandle() 方法。
- afterCompletion() 方法:SpringMVC 会把所有拦截器收集到一起,然后按照配置相反的顺序调用各个 afterCompletion() 方法。
| springmvc框架 | 主要作用、核心组件、调用流程 |
| 简化参数接收 | 路径设计、参数接收、请求头接收、cookie接收 |
| 简化数据响应 | 模板页面、转发和重定向、JSON数据、静态资源 |
| restful风格设计 | 主要作用、具体规范、请求方式和请求参数选择 |
| 功能扩展 | 全局异常处理、拦截器、参数校验注解 |
-
@NotNull (包装类型不为null)
@NotNull 注解是 JSR 303 规范中定义的注解,当被标注的字段值为 null 时,会认为校验失败而抛出异常。该注解不能用于字符串类型的校验,若要对字符串进行校验,应该使用 @NotBlank 或 @NotEmpty 注解。
-
@NotEmpty (集合类型长度大于0)
@NotEmpty 注解同样是 JSR 303 规范中定义的注解,对于 CharSequence、Collection、Map 或者数组对象类型的属性进行校验,校验时会检查该属性是否为 Null 或者 size()==0,如果是的话就会校验失败。但是对于其他类型的属性,该注解无效。需要注意的是只校验空格前后的字符串,如果该字符串中间只有空格,不会被认为是空字符串,校验不会失败。
-
@NotBlank (字符串,不为null,切不为" "字符串)
@NotBlank 注解是 Hibernate Validator 附加的注解,对于字符串类型的属性进行校验,校验时会检查该属性是否为 Null 或 “” 或者只包含空格,如果是的话就会校验失败。需要注意的是,@NotBlank 注解只能用于字符串类型的校验。
SpringMVC:
SSM整合:
maven:
Springboot:
-
简化依赖管理:Spring Boot Starter通过捆绑和管理一组相关的依赖项,减少了手动解析和配置依赖项的工作。只需引入一个相关的Starter依赖,即可获取应用程序所需的全部依赖。
-
自动配置:Spring Boot Starter在应用程序启动时自动配置所需的组件和功能。通过根据类路径和其他设置的自动检测,Starter可以自动配置Spring Bean、数据源、消息传递等常见组件,从而使应用程序的配置变得简单和维护成本降低。
-
提供约定优于配置:Spring Boot Starter遵循“约定优于配置”的原则,通过提供一组默认设置和约定,减少了手动配置的需要。它定义了标准的配置文件命名约定、默认属性值、日志配置等,使得开发者可以更专注于业务逻辑而不是繁琐的配置细节。
-
快速启动和开发应用程序:Spring Boot Starter使得从零开始构建一个完整的Spring Boot应用程序变得容易。它提供了主要领域(如Web开发、数据访问、安全性、消息传递等)的Starter,帮助开发者快速搭建一个具备特定功能的应用程序原型。
-
模块化和可扩展性:Spring Boot Starter的组织结构使得应用程序的不同模块可以进行分离和解耦。每个模块可以有自己的Starter和依赖项,使得应用程序的不同部分可以按需进行开发和扩展。
- 如果同时存在application.properties | application.yml(.yaml) , properties的优先级更高。
从配置文件中读入并且配置:
package com.atguigu.properties;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;@Component
public class DataSourceProperties {@Value("${spring.jdbc.datasource.driverClassName}") private String driverClassName; @Value("${spring.jdbc.datasource.url}") private String url; @Value("${spring.jdbc.datasource.username}") private String username; @Value("${spring.jdbc.datasource.password}") private String password; // 生成get set 和 toString方法 public String getDriverClassName() { return driverClassName; } public void setDriverClassName(String driverClassName) { this.driverClassName = driverClassName; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } @Override public String toString() { return "DataSourceProperties{" + "driverClassName='" + driverClassName + '\'' + ", url='" + url + '\'' + ", username='" + username + '\'' + ", password='" + password + '\'' + '}'; }}
多环境配置问题:
配置文件的5个参数:
当涉及Spring Boot的Web应用程序配置时,以下是五个重要的配置参数:
server.port: 指定应用程序的HTTP服务器端口号。默认情况下,Spring Boot使用8080作为默认端口。您可以通过在配置文件中设置server.port来更改端口号。server.servlet.context-path: 设置应用程序的上下文路径。这是应用程序在URL中的基本路径。默认情况下,上下文路径为空。您可以通过在配置文件中设置server.servlet.context-path属性来指定自定义的上下文路径。spring.mvc.view.prefix和spring.mvc.view.suffix: 这两个属性用于配置视图解析器的前缀和后缀。视图解析器用于解析控制器返回的视图名称,并将其映射到实际的视图页面。spring.mvc.view.prefix定义视图的前缀,spring.mvc.view.suffix定义视图的后缀。spring.resources.static-locations: 配置静态资源的位置。静态资源可以是CSS、JavaScript、图像等。默认情况下,Spring Boot会将静态资源放在classpath:/static目录下。您可以通过在配置文件中设置spring.resources.static-locations属性来自定义静态资源的位置。spring.http.encoding.charset和spring.http.encoding.enabled: 这两个属性用于配置HTTP请求和响应的字符编码。spring.http.encoding.charset定义字符编码的名称(例如UTF-8),spring.http.encoding.enabled用于启用或禁用字符编码的自动配置。
这些是在Spring Boot的配置文件中与Web应用程序相关的一些重要配置参数。根据您的需求,您可以在配置文件中设置这些参数来定制和配置您的Web应用程序
默认的静态资源路径为:
· classpath:/META-INF/resources/
· classpath:/resources/
· classpath:/static/
· classpath:/public/
我们只要静态资源放在这些目录中任何一个,SpringMVC都会帮我们处理。 我们习惯会把静态资源放在classpath:/static/ 目录下。在resources目录下创建index.html文件默认的资源路径:
JDBCTemplate:
1.经典的jdbc处理方法
@Slf4j
@Controller
@RequestMapping("/user")
public class UserController {
@Autowired
private JdbcTemplate jdbcTemplate;
@GetMapping("/getUser")
@ResponseBody
public User getUser(){
String sql = "select * from users where id = ? ; ";
User user = jdbcTemplate.queryForObject(sql, new BeanPropertyRowMapper<>(User.class), 1);
log.info("查询的user数据为:{}",user.toString());
return user;
}
数据库连接池:
指定数据库连接池的配置文件:
数据库连接池的配置关系:
配置前后关系:
四、SpringBoot3整合Druid数据源
1. 创建程序
2. 引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.5</version>
</parent>
<groupId>com.atguigu</groupId>
<artifactId>springboot-starter-druid-04</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- web开发的场景启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 数据库相关配置启动器 jdbctemplate 事务相关-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- druid启动器的依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-3-starter</artifactId>
<version>1.2.18</version>
</dependency>
<!-- 驱动类-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.28</version>
</dependency>
</dependencies>
<!-- SpringBoot应用打包插件-->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3. 启动类
@SpringBootApplication
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class,args);
}
}
4. 配置文件编写
> 添加druid连接池的基本配置
spring:
datasource:
# 连接池类型
type: com.alibaba.druid.pool.DruidDataSource
# Druid的其他属性配置 springboot3整合情况下,数据库连接信息必须在Druid属性下!
druid:
url: jdbc:mysql://localhost:3306/day01
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
# 初始化时建立物理连接的个数
initial-size: 5
# 连接池的最小空闲数量
min-idle: 5
# 连接池最大连接数量
max-active: 20
# 获取连接时最大等待时间,单位毫秒
max-wait: 60000
# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
test-while-idle: true
# 既作为检测的间隔时间又作为testWhileIdel执行的依据
time-between-eviction-runs-millis: 60000
# 销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接(配置连接在池中的最小生存时间)
min-evictable-idle-time-millis: 30000
# 用来检测数据库连接是否有效的sql 必须是一个查询语句(oracle中为 select 1 from dual)
validation-query: select 1
# 申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-borrow: false
# 归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为true
test-on-return: false
# 是否缓存preparedStatement, 也就是PSCache,PSCache对支持游标的数据库性能提升巨大,比如说oracle,在mysql下建议关闭。
pool-prepared-statements: false
# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
max-pool-prepared-statement-per-connection-size: -1
# 合并多个DruidDataSource的监控数据
use-global-data-source-stat: true
logging:
level:
root: debug
5. 编写Controller
@Slf4j
@Controller
@RequestMapping("/user")
public class UserController {
@Autowired
private JdbcTemplate jdbcTemplate;
@GetMapping("/getUser")
@ResponseBody
public User getUser(){
String sql = "select * from users where id = ? ; ";
User user = jdbcTemplate.queryForObject(sql, new BeanPropertyRowMapper<>(User.class), 1);
log.info("查询的user数据为:{}",user.toString());
return user;
}
}
6. 启动测试
7. 问题解决
通过源码分析,druid-spring-boot-3-starter目前最新版本是1.2.18,虽然适配了SpringBoot3,但缺少自动装配的配置文件,需要手动在resources目录下创建META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports,文件内容如下!
com.alibaba.druid.spring.boot3.autoconfigure.DruidDataSourceAutoConfigure

配置解释
1. spring.datasource
- 作用:配置数据源的相关信息。
- 意义:用于连接数据库,提供数据库连接池的配置。
2. type: com.alibaba.druid.pool.DruidDataSource
- 作用:指定使用的连接池类型。
- 意义:这里使用的是 Druid 连接池。
3. druid.url: jdbc:mysql://localhost:3306/day01
- 作用:指定数据库的连接 URL。
- 意义:连接到本地的 MySQL 数据库,数据库名为
day01。
4. druid.username: root
- 作用:指定数据库的用户名。
- 意义:使用
root用户连接数据库。
5. druid.password: root
- 作用:指定数据库的密码。
- 意义:使用
root作为密码连接数据库。
6. druid.driver-class-name: com.mysql.cj.jdbc.Driver
- 作用:指定数据库驱动类。
- 意义:使用 MySQL 的驱动类
com.mysql.cj.jdbc.Driver。
7. druid.initial-size: 5
- 作用:初始化时建立的物理连接个数。
- 意义:启动时创建 5 个初始连接。
8. druid.min-idle: 5
- 作用:连接池的最小空闲连接数。
- 意义:连接池中至少保持 5 个空闲连接。
9. druid.max-active: 20
- 作用:连接池的最大连接数。
- 意义:连接池中最多允许 20 个连接。
10. druid.max-wait: 60000
- 作用:获取连接时的最大等待时间(单位:毫秒)。
- 意义:等待 60 秒后,如果仍然无法获取连接,则抛出异常。
11. druid.test-while-idle: true
- 作用:申请连接时检测空闲连接的有效性。
- 意义:如果空闲时间大于
time-between-eviction-runs-millis,则执行validation-query检测连接是否有效。
12. druid.time-between-eviction-runs-millis: 60000
- 作用:检测空闲连接的间隔时间(单位:毫秒)。
- 意义:每 60 秒检测一次空闲连接。
13. druid.min-evictable-idle-time-millis: 30000
- 作用:连接在池中的最小生存时间(单位:毫秒)。
- 意义:连接在池中至少存活 30 秒后,才可能被销毁。
14. druid.validation-query: select 1
- 作用:检测数据库连接是否有效的 SQL 语句。
- 意义:执行
select 1来检测连接是否有效。
15. druid.test-on-borrow: false
- 作用:申请连接时是否执行
validation-query。 - 意义:不执行
validation-query,以提高性能。
16. druid.test-on-return: false
- 作用:归还连接时是否执行
validation-query。 - 意义:不执行
validation-query,以提高性能。
17. druid.pool-prepared-statements: false
- 作用:是否缓存
PreparedStatement。 - 意义:不缓存
PreparedStatement,以避免内存占用过多。
18. druid.max-pool-prepared-statement-per-connection-size: -1
- 作用:每个连接中缓存的
PreparedStatement的最大数量。 - 意义:设置为 -1,表示不缓存
PreparedStatement。
19. druid.use-global-data-source-stat: true
- 作用:是否合并多个
DruidDataSource的监控数据。 - 意义:开启全局监控数据合并。
2. logging.level
- 作用:配置日志的级别。
- 意义:控制日志的输出级别,
debug级别会输出所有日志信息。
总结
- 数据源配置:用于连接数据库,提供数据库连接池的详细配置。
- 日志配置:用于控制日志的输出级别,
debug级别会输出所有日志信息。
声明式事务整合配置:
依赖导入:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency>
注:SpringBoot项目会自动配置一个 DataSourceTransactionManager,所以我们只需在方法(或者类)加上 @Transactional 注解,就自动纳入 Spring 的事务管理了
@Transactional public void update()
{ User user = new User();
user.setId(1);
user.setPassword("test2");
user.setAccount("test2");
userMapper.update(user); }`
AOp整合配置:
依赖导入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
直接使用aop注解即可:
@Component
@Aspect
public class LogAdvice {
@Before("execution(* com..service.*.*(..))")
public void before(JoinPoint joinPoint){
System.out.println("LogAdvice.before");
System.out.println("joinPoint = " + joinPoint);
}
}
线程池配置:
java打包命令:
java -jar命令用于在Java环境中执行可执行的JAR文件。下面是关于java -jar命令的说明:
命令格式:java -jar [选项] [参数] <jar文件名>
-D<name>=<value>:设置系统属性,可以通过System.getProperty()方法在应用程序中获取该属性值。例如:java -jar -Dserver.port=8080 myapp.jar。-X:设置JVM参数,例如内存大小、垃圾回收策略等。常用的选项包括:-Xmx<size>:设置JVM的最大堆内存大小,例如-Xmx512m表示设置最大堆内存为512MB。-Xms<size>:设置JVM的初始堆内存大小,例如-Xms256m表示设置初始堆内存为256MB。
-Dspring.profiles.active=<profile>:指定Spring Boot的激活配置文件,可以通过application-<profile>.properties或application-<profile>.yml文件来加载相应的配置。例如:java -jar -Dspring.profiles.active=dev myapp.jar。
启动和测试:

SSM:
1.2.1 第一问:SSM整合需要几个IoC容器?
两个容器
本质上说,整合就是将三层架构和框架核心API组件交给SpringIoC容器管理!
一个容器可能就够了,但是我们常见的操作是创建两个IoC容器(web容器和root容器),组件分类管理!
这种做法有以下好处和目的:
1. 分离关注点:通过初始化两个容器,可以将各个层次的关注点进行分离。这种分离使得各个层次的组件能够更好地聚焦于各自的责任和功能。
2. 解耦合:各个层次组件分离装配不同的IoC容器,这样可以进行解耦。这种解耦合使得各个模块可以独立操作和测试,提高了代码的可维护性和可测试性。
3. 灵活配置:通过使用两个容器,可以为每个容器提供各自的配置,以满足不同层次和组件的特定需求。每个配置文件也更加清晰和灵活。
总的来说,初始化两个容器在SSM整合中可以实现关注点分离、解耦合、灵活配置等好处。它们各自负责不同的层次和功能,并通过合适的集成方式协同工作,提供一个高效、可维护和可扩展的应用程序架构!
1.2.2 第二问:每个IoC容器对应哪些类型组件?
图解:

总结:
| 容器名 | 盛放组件 |
| web容器 | web相关组件(controller,springmvc核心组件) |
| root容器 | 业务和持久层相关组件(service,aop,tx,dataSource,mybatis,mapper等) |
1.2.3 第三问:IoC容器之间关系和调用方向?
情况1:两个无关联IoC容器之间的组件无法注入!

情况2:子IoC容器可以单向的注入父IoC容器的组件!

结论:web容器是root容器的子容器,父子容器关系。
- 父容器:root容器,盛放service、mapper、mybatis等相关组件
- 子容器:web容器,盛放controller、web相关组件
源码体现:
FrameworkServlet 655行!
protected WebApplicationContext createWebApplicationContext(@Nullable ApplicationContext parent) {
Class<?> contextClass = getContextClass();
if (!ConfigurableWebApplicationContext.class.isAssignableFrom(contextClass)) {
throw new ApplicationContextException(
"Fatal initialization error in servlet with name '" + getServletName() +
"': custom WebApplicationContext class [" + contextClass.getName() +
"] is not of type ConfigurableWebApplicationContext");
}
ConfigurableWebApplicationContext wac =
(ConfigurableWebApplicationContext) BeanUtils.instantiateClass(contextClass);
wac.setEnvironment(getEnvironment());
//wac 就是web ioc容器
//parent 就是root ioc容器
//web容器设置root容器为父容器,所以web容器可以引用root容器
wac.setParent(parent);
String configLocation = getContextConfigLocation();
if (configLocation != null) {
wac.setConfigLocation(configLocation);
}
configureAndRefreshWebApplicationContext(wac);
return wac;
}
调用流程图解:

1.2.4 第四问:具体多少配置类以及对应容器关系?
配置类的数量不是固定的,但是至少要两个,为了方便编写,我们可以三层架构每层对应一个配置类,分别指定两个容器加载即可!

建议配置文件:
| 配置名 | 对应内容 | 对应容器 |
| WebJavaConfig | controller,springmvc相关 | web容器 |
| ServiceJavaConfig | service,aop,tx相关 | root容器 |
| MapperJavaConfig | mapper,datasource,mybatis相关 | root容器 |
1.2.5 第五问:IoC初始化方式和配置位置?
在web项目下,我们可以选择web.xml和配置类方式进行ioc配置,推荐配置类。
对于使用基于 web 的 Spring 配置的应用程序,建议这样做,如以下示例所示:
public class MyWebAppInitializer extends AbstractAnnotationConfigDispatcherServletInitializer {
//指定root容器对应的配置类
//root容器的配置类
@Override
protected Class<?>[] getRootConfigClasses() {
return new Class<?>[] { ServiceJavaConfig.class,MapperJavaConfig.class };
}
//指定web容器对应的配置类 webioc容器的配置类
@Override
protected Class<?>[] getServletConfigClasses() {
return new Class<?>[] { WebJavaConfig.class };
}
//指定dispatcherServlet处理路径,通常为 /
@Override
protected String[] getServletMappings() {
return new String[] { "/" };
}
}
图解配置类和容器配置:

日志技术:
<!-- 设置全局日志级别。日志级别按顺序分别是:TRACE、DEBUG、INFO、WARN、ERROR -->
TRACE:记录最详细的执行过程,用于开发和调试。
DEBUG:记录调试信息,用于开发和调试。
INFO:记录程序的正常运行状态,用于日常监控。
WARN:记录可能影响程序运行的警告信息,提醒开发者注意。
ERROR:记录严重的错误,需要立即处理。
<!-- 指定任何一个日志级别都只打印当前级别和后面级别的日志。 -->
<root level="DEBUG">
<!-- 指定打印日志的appender,这里通过“STDOUT”引用了前面配置的appender -->
<appender-ref ref="STDOUT" />
</root>
<!-- 根据特殊需求指定局部日志级别,可也是包名或全类名。 -->
<logger name="com.atguigu.mybatis" level="DEBUG" />
开启静态资源:
主要配置controller,springmvc相关组件配置
位置:WebJavaConfig.java(命名随意)
/**
* projectName: com.atguigu.config
*
* 1.实现Springmvc组件声明标准化接口WebMvcConfigurer 提供了各种组件对应的方法
* 2.添加配置类注解@Configuration
* 3.添加mvc复合功能开关@EnableWebMvc
* 4.添加controller层扫描注解
* 5.开启默认处理器,支持静态资源处理
*/
@Configuration
@EnableWebMvc
@ComponentScan("com.atguigu.controller")
public class WebJavaConfig implements WebMvcConfigurer {
//开启静态资源
@Override
public void configureDefaultServletHandling(DefaultServletHandlerConfigurer configurer) {
configurer.enable();
}
}
Mybatis配置:
从包中可以看出来核心的一个方法就是sqlsession
以下是核心API:
//1.读取外部配置文件
InputStream ips = Resources.getResourceAsStream("mybatis-config.xml");
//2.创建sqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(ips);
//3.创建sqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
//4.获取mapper代理对象
EmpMapper empMapper = sqlSession.getMapper(EmpMapper.class);
//5.数据库方法调用
int rows = empMapper.deleteEmpById(1);
System.out.println("rows = " + rows);
//6.提交和回滚
sqlSession.commit();
sqlSession.close();
关于注入IOC容器管理的东西:
-
SqlSessionFactoryBuilder
这个类可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。
因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。 无需ioc容器管理! -
SqlSessionFactory
一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例。 使用 SqlSessionFactory 的最佳实践是在应用运行期间不要重复创建多次,因此 SqlSessionFactory 的最佳作用域是应用作用域。 需要ioc容器管理!
-
SqlSession
每个线程都应该有它自己的 SqlSession 实例。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。 无需ioc容器管理!
-
Mapper映射器实例
映射器是一些绑定映射语句的接口。映射器接口的实例是从 SqlSession 中获得的。虽然从技术层面上来讲,任何映射器实例的最大作用域与请求它们的 SqlSession 相同。但方法作用域才是映射器实例的最合适的作用域。
从作用域的角度来说,映射器实例不应该交给ioc容器管理!
但是从使用的角度来说,业务类(service)需要注入mapper接口,所以mapper应该交给ioc容器管理!

-
总结
- 将SqlSessionFactory实例存储到IoC容器
- 将Mapper实例存储到IoC容器
关于前端工程化:
Node.js 是前端程序运行的服务器,类似Java程序运行的服务器Tomcat
Npm 是前端依赖包管理工具,类似maven依赖管理工具软件
运行vscod前端文件的经典命令:
npm install //安装依赖
npm run dev //运行测试
mybatisplius内容:
基于BaseMapper的单表CRUD:
通用service:
条件构造器:
常用注解:
Mybatis快速生成代码:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.31</version>
</dependency>
public class FastAutoGeneratorTest {
public static void main(String[] args) {
FastAutoGenerator.create("jdbc:mysql://127.0.0.1:3306/mybatis_plus?
characterEncoding=utf-8&userSSL=false", "root", "123456")
.globalConfig(builder -> {
builder.author("atguigu") // 设置作者
//.enableSwagger() // 开启 swagger 模式
.fileOverride() // 覆盖已生成文件
.outputDir("D://mybatis_plus"); // 指定输出目录
})
.packageConfig(builder -> {
builder.parent("com.atguigu") // 设置父包名
.moduleName("mybatisplus") // 设置父包模块名
.pathInfo(Collections.singletonMap(OutputFile.mapperXml, "D://mybatis_plus"));
// 设置mapperXml生成路径
})
.strategyConfig(builder -> {
builder.addInclude("t_user") // 设置需要生成的表名
.addTablePrefix("t_", "c_"); // 设置过滤表前缀
})
.templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker
引擎模板,默认的是Velocity引擎模板
.execute();
}
}
模拟数据源的配置:
spring:
# 配置数据源信息
datasource:
dynamic:
# 设置默认的数据源或者数据源组,默认值即为master
primary: master
# 严格匹配数据源,默认false.true未匹配到指定数据源时抛异常,false使用默认数据源
strict: false
datasource:
master:
url: jdbc:mysql://localhost:3306/mybatis_plus?characterEncoding=utf-
8&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
slave_1:
url: jdbc:mysql://localhost:3306/mybatis_plus_1?characterEncoding=utf-
8&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
将操作的类名与数据库表名建立一一对应关系:
配置固定前缀:
mybatis-plus:
configuration:
配置MyBatis日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
配置MyBatis-Plus操作表的默认前缀
table-prefix: t_
wapper全系列:
实现子查询:
@Test
public void test06() {
//查询id小于等于3的用户信息
//SELECT id,username AS name,age,email,is_deleted FROM t_user WHERE (id IN
(select id from t_user where id <= 3))
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.inSql("id", "select id from t_user where id <= 3");
List<User> list = userMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
updatemapper中必须要创建user对象:
@Test
public void test07() {
//将(年龄大于20或邮箱为null)并且用户名中包含有a的用户信息修改
//组装set子句以及修改条件
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
//lambda表达式内的逻辑优先运算
updateWrapper
.set("age", 18)
.set("email", "user@atguigu.com")
.like("username", "a")
.and(i -> i.gt("age", 20).or().isNull("email"));
//这里必须要创建User对象,否则无法应用自动填充。如果没有自动填充,可以设置为null
//UPDATE t_user SET username=?, age=?,email=? WHERE (username LIKE ? AND
(age > ? OR email IS NULL))
//User user = new User();
//user.setName("张三");
更多Java –大数据 – 前端 – UI/UE - Android - 人工智能资料下载,可访问百度:尚硅谷官网(www.atguigu.com)
4、condition
在真正开发的过程中,组装条件是常见的功能,而这些条件数据来源于用户输入,是可选的,因
此我们在组装这些条件时,必须先判断用户是否选择了这些条件,若选择则需要组装该条件,若
没有选择则一定不能组装,以免影响SQL执行的结果
思路一:
思路二:
上面的实现方案没有问题,但是代码比较复杂,我们可以使用带condition参数的重载方法构建查
询条件,简化代码的编写
//int result = userMapper.update(user, updateWrapper);
//UPDATE t_user SET age=?,email=? WHERE (username LIKE ? AND (age > ? OR
email IS NULL))
int result = userMapper.update(null, updateWrapper);
System.out.println(result);
}
mybatis内容:
配置属性:
FATAL(致命)>ERROR(错误)>WARN(警告)>INFO(信息)>DEBUG(调试)
sql文件的生成:
逆向工程:
代码生成:
SqlSession:代表Java程序和数据库之间的会话。(HttpSession是Java程序和浏览器之间的
会话)
SqlSessionFactory:是“生产”SqlSession的“工厂”。
工厂模式:如果创建某一个对象,使用的过程基本固定,那么我们就可以把创建这个对象的
相关代码封装到一个“工厂类”中,以后都使用这个工厂类来“生产”我们需要的对象。
Mybatis的重要语法:
MyBatis获取参数值的两种方式:${}和#{}
${}的本质就是字符串拼接,#{}的本质就是占位符赋值
${}使用字符串拼接的方式拼接sql,若为字符串类型或日期类型的字段进行赋值时,需要手动加单引
号;但是#{}使用占位符赋值的方式拼接sql,此时为字符串类型或日期类型的字段进行赋值时,可以自
动添加单引号
Maven内容:
Insert的代替就是 select,update,delete
下面是经典的jdbc代码:
import org.apache.ibatis.session.SqlSession;
import com.example.mapper.UserMapper;
import com.example.pojo.User;
public class MyBatisTest {
public static void main(String[] args) {
// 获取 SqlSession
SqlSession sqlSession = MyBatisUtil.getSqlSession();
try {
// 获取 UserMapper
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 调用方法,传入参数
String username = "John";
int age = 25;
List<User> users = userMapper.selectUsers(username, age);
// 输出结果
for (User user : users) {
System.out.println("ID: " + user.getId() + ", Name: " + user.getName() + ", Age: " + user.getAge());
}
} finally {
// 关闭 SqlSession
sqlSession.close();
}
}
}
如何处理这种情况!!!
Map 集合类型的参数
示例代码
假设我们有一个 UserMapper 接口,需要根据多个参数查询用户信息。我们可以使用 Map 集合来传递这些参数。
1. Mapper 接口 UserMapper
java
import org.apache.ibatis.annotations.Param;
import java.util.List;
import java.util.Map;
public interface UserMapper {
List<User> selectUsers(Map<String, Object> params);
}
2. 对应的 XML 文件 UserMapper.xml
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper">
<!-- 使用 #{key} 访问 map 集合中的参数 -->
<select id="selectUsers" resultType="com.example.pojo.User">
SELECT * FROM users
WHERE username = #{username} AND age = #{age}
</select>
</mapper>
3. 调用示例
java
import org.apache.ibatis.session.SqlSession;
import com.example.mapper.UserMapper;
import com.example.pojo.User;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class MyBatisTest {
public static void main(String[] args) {
// 获取 SqlSession
SqlSession sqlSession = MyBatisUtil.getSqlSession();
try {
// 获取 UserMapper
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 创建 Map 集合,添加参数
Map<String, Object> params = new HashMap<>();
params.put("username", "John");
params.put("age", 25);
// 调用方法,传入 Map 集合
List<User> users = userMapper.selectUsers(params);
// 输出结果
for (User user : users) {
System.out.println("ID: " + user.getId() + ", Name: " + user.getName() + ", Age: " + user.getAge());
}
} finally {
// 关闭 SqlSession
sqlSession.close();
}
}
}
多个参数的另外一种写法:
1. Mapper 接口 UserMapper
import java.util.List;
public interface UserMapper {
List<User> selectUsers(int id, String name);
}
2. 对应的 XML 文件 UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper">
<!-- 使用 #{paramName} 访问参数 -->
<select id="selectUsers" resultType="com.example.pojo.User">
SELECT * FROM users
WHERE id = #{arg0} AND name = #{arg1}
</select>
</mapper>
单个数据的删除和查改:
主要是resultmap的书写情况:
特殊的sql类查询:
多对一的映射关系的处理方法:
级联映射:
<resultMap id="empDeptMap" type="Emp">
<id column="eid" property="eid"></id>
<result column="ename" property="ename"></result>
<result column="age" property="age"></result>
<result column="sex" property="sex"></result>
<result column="did" property="dept.did"></result>
<result column="dname" property="dept.dname"></result>
</resultMap>
<!--Emp getEmpAndDeptByEid(@Param("eid") int eid);-->
<select id="getEmpAndDeptByEid" resultMap="empDeptMap">
select emp.*,dept.* from t_emp emp left join t_dept dept on emp.did =
dept.did where emp.eid = #{eid}
</select>
*association映射:
<resultMap id="empDeptMap" type="Emp">
<id column="eid" property="eid"></id>
<result column="ename" property="ename"></result>
<result column="age" property="age"></result>
<result column="sex" property="sex"></result>
<association property="dept" javaType="Dept">
<id column="did" property="did"></id>
<result column="dname" property="dname"></result>
</association>
</resultMap>
<!--Emp getEmpAndDeptByEid(@Param("eid") int eid);-->
<select id="getEmpAndDeptByEid" resultMap="empDeptMap">
select emp.*,dept.* from t_emp emp left join t_dept dept on emp.did =
dept.did where emp.eid = #{eid}
</select>
一对多的映射以及分布查询功能的解决问题:
分步查询的优点:可以实现延迟加载,但是必须在核心配置文件中设置全局配置信息:
lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载
aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。 否则,每个
属性会按需加载
此时就可以实现按需加载,获取的数据是什么,就只会执行相应的sql。此时可通过association和
collection中的fetchType属性设置当前的分步查询是否使用延迟加载,fetchType="lazy(延迟加
载)|eager(立即加载)
操作符:
if where trim choose、when、otherwise
关于以上操作符的模板思考:
select if
<!--List<Emp> getEmpListByMoreTJ(Emp emp);-->
<select id="getEmpListByMoreTJ" resultType="Emp">
select * from t_emp where 1=1
<if test="ename != '' and ename != null">
and ename = #{ename}
</if>
<if test="age != '' and age != null">
and age = #{age}
</if>
<if test="sex != '' and sex != null">
and sex = #{sex}
</if>
</select>
select where if
<select id="getEmpListByMoreTJ2" resultType="Emp">
select * from t_emp
<where>
<if test="ename != '' and ename != null">
ename = #{ename}
</if>
<if test="age != '' and age != null">
and age = #{age}
</if>
<if test="sex != '' and sex != null">
and sex = #{sex}
</if>
</where>
</select>
<select id="getEmpListByMoreTJ" resultType="Emp">
select * from t_emp
<trim prefix="where" suffixOverrides="and">
<if test="ename != '' and ename != null">
ename = #{ename} and
</if>
<if test="age != '' and age != null">
age = #{age} and
</if>
<if test="sex != '' and sex != null">
sex = #{sex}
</if>
</trim>
</select>
trim用于去掉或添加标签中的内容
常用属性:
prefix:在trim标签中的内容的前面添加某些内容
prefixOverrides:在trim标签中的内容的前面去掉某些内容
suffix:在trim标签中的内容的后面添加某些内容
suffixOverrides:在trim标签中的内容的后面去掉某些内容
公共sql语句与操作:
<sql id="empColumns">
eid,ename,age,sex,did
</sql>
select <include refid="empColumns"></include> from t_emp
1. Maven安装和配置
https://maven.apache.org/docs/history.html
选用版本:
| 发布时间 | maven版本 | jdk最低版本 |
|---|---|---|
| **2019 - 11 - **25 | 3.6.3 | Java 7 |
-
安装
安装条件:maven需要本机安装java环境、必需包含java_home环境变量!
软件安装:右键解压即可(绿色免安装)
软件结构:

-
环境变量
环境变量:配置maven_home 和 path


-
命令测试
mvn -v
# 输出版本信息即可,如果错误,请仔细检查环境变量即可!
# 友好提示,如果此处错误,绝大部分原因都是java_home变量的事,请仔细检查!!
-
配置文件
我们需要需改maven/conf/settings.xml配置文件,来修改maven的一些默认配置。我们主要休要修改的有三个配置:1.依赖本地缓存位置(本地仓库位置)2.maven下载镜像3.maven选用编译项目的jdk版本!
- 配置本地仓库地址
<!-- localRepository
| The path to the local repository maven will use to store artifacts.
|
| Default: ${user.home}/.m2/repository
<localRepository>/path/to/local/repo</localRepository>
-->
<!-- conf/settings.xml 55行 -->
<localRepository>D:\repository</localRepository>
2. 配置国内阿里镜像
<!--在mirrors节点(标签)下添加中央仓库镜像 160行附近-->
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
3. 配置jdk17版本项目构建
<!--在profiles节点(标签)下添加jdk编译版本 268行附近-->
<profile>
<id>jdk-17</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>17</jdk>
</activation>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<maven.compiler.compilerVersion>17</maven.compiler.compilerVersion>
</properties>
</profile>
-
idea配置本地maven
我们需要将配置好的maven软件,配置到idea开发工具中即可! 注意:idea工具默认自带maven配置软件,但是因为没有修改配置,建议替换成本地配置好的maven!
-
打开idea配置文件,构建工具配置
依次点击
file / settings / build / build tool / maven
-
选中本地maven软件

-
测试是否配置成功
注意:如果本地仓库地址不变化,只有一个原因,就是maven/conf/settings.xml配置文件编写错误!仔细检查即可!

-
2.关于Maven的属性问题:
GAV遵循一下规则:
1) GroupID 格式:com.{公司/BU }.业务线.[子业务线],最多 4 级。
说明:{公司/BU} 例如:alibaba/taobao/tmall/aliexpress 等 BU 一级;子业务线可选。
正例:com.taobao.tddl 或 com.alibaba.sourcing.multilang com.atguigu.java
2) ArtifactID 格式:产品线名-模块名。语义不重复不遗漏,先到仓库中心去查证一下。
正例:tc-client / uic-api / tair-tool / bookstore
3) Version版本号格式推荐:主版本号.次版本号.修订号 1.0.0
1) 主版本号:当做了不兼容的 API 修改,或者增加了能改变产品方向的新功能。
2) 次版本号:当做了向下兼容的功能性新增(新增类、接口等)。
3) 修订号:修复 bug,没有修改方法签名的功能加强,保持 API 兼容性。
例如: 初始→1.0.0 修改bug → 1.0.1 功能调整 → 1.1.1等
3.Packaging定义规则:
指示将项目打包为什么类型的文件,idea根据packaging值,识别maven项目类型!
packaging 属性为 jar(默认值),代表普通的Java工程,打包以后是.jar结尾的文件。
packaging 属性为 war,代表Java的web工程,打包以后.war结尾的文件。
packaging 属性为 pom,代表不会打包,用来做继承的父工程。
<!--
通过编写依赖jar包的gav必要属性,引入第三方依赖!
scope属性是可选的,可以指定依赖生效范围!
依赖信息查询方式:
1. maven仓库信息官网 https://mvnrepository.com/
2. mavensearch插件搜索
-->
<dependencies>
<!-- 引入具体的依赖包 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<!--
生效范围
- compile :main目录 test目录 打包打包 [默认]
- provided:main目录 test目录 Servlet
- runtime: 打包运行 MySQL
- test: test目录 junit
-->
<scope>runtime</scope>
</dependency>
</dependencies>
关于jackson依赖
依赖传递演示:
项目中,需要导入jackson相关的依赖,通过之前导入经验,jackson需要导入三个依赖,分别为:

通过查看网站介绍的依赖传递特性:data-bind中,依赖其他两个依赖

最佳导入:直接可以导入data-bind,自动依赖传递需要的依赖
```XML
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.0</version>
</dependency>
```
自动选择原则
- 短路优先原则(第一原则)
A—>B—>C—>D—>E—>X(version 0.0.1)
A—>F—>X(version 0.0.2)
则A依赖于X(version 0.0.2)。
- 依赖路径长度相同情况下,则“先声明优先”(第二原则)
A—>E—>X(version 0.0.1)
A—>F—>X(version 0.0.2)
在<depencies></depencies>中,先声明的,路径相同,会优先选择!
4.清理maven错误配置:
脚本使用:
使用记事本打开
set REPOSITORY_PATH=D:\repository 改成你本地仓库地址即可!
点击运行脚本,即可自动清理本地错误缓存文件!!
| 命令 | 描述 |
|---|---|
| mvn clean | 清理编译或打包后的项目结构,删除target文件夹 |
| mvn compile | 编译项目,生成target文件 |
| mvn test | 执行测试源码 (测试) |
| mvn site | 生成一个项目依赖信息的展示页面 |
| mvn package | 打包项目,生成war / jar 文件 |
| mvn install | 打包后上传到maven本地仓库(本地部署) |
| mvn deploy | 只打包,上传到maven私服仓库(私服部署) |
构建maven工程架构:
分页功能:pagehelper 实现分页查询功能
<plugins>
<!--设置分页插件-->
<plugin interceptor="com.github.pagehelper.PageInterceptor"></plugin>
</plugins>
<!-- https://mvnrepository.com/artifact/com.github.pagehelper/pagehelper -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
配置乐观组件:
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//添加分页插件
interceptor.addInnerInterceptor(new
PaginationInnerInterceptor(DbType.MYSQL));
//添加乐观锁插件
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
自定义resultmap:
<resultMap id="userMap" type="User">
<id property="id" column="id"></id>
<result property="userName" column="user_name"></result>
<result property="password" column="password"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
</resultMap>
<!--List<User> testMohu(@Param("mohu") String mohu);-->
<select id="testMohu" resultMap="userMap">
<!--select * from t_user where username like '%${mohu}%'-->
select id,user_name,password,age,sex from t_user where user_name like
concat('%',#{mohu},'%')
</select>
关于驼峰映射:
若字段名和实体类中的属性名不一致,但是字段名符合数据库的规则(使用_),实体类中的属性
名符合Java的规则(使用驼峰)
此时也可通过以下两种方式处理字段名和实体类中的属性的映射关系
a>可以通过为字段起别名的方式,保证和实体类中的属性名保持一致
b>可以在MyBatis的核心配置文件中设置一个全局配置信息mapUnderscoreToCamelCase,可
以在查询表中数据时,自动将_类型的字段名转换为驼峰
例如:字段名user_name,设置了mapUnderscoreToCamelCase,此时字段名就会转换为
userName
多级缓存:
二级缓存配置:
Springcloud:
尚硅谷2025最新SpringCloud速通-操作步骤(详细)_雷丰阳python速通课-CSDN博客
完美诠释了springcloud和springcloudalibab的区别:
编辑微服务的服务模块:
服务发现的作用是:服务间的远程调用通过nacos发现对方的服务,然后进行调用,后续不用手动调,这里只要加上注解,两个API作为了解。
远程调用是需要注册中心的:
负载均衡的思考:
上述转换驼峰命名的方法需要思考和注意:
监听配置文件的变化:
导入默认值配置:
nacos导入配置文件的生效方式
一套注解两套逻辑:
响应式编程:
JDK新特性:
Jdk8之后的新增的默认方法,静态方法,抽象方法。
Mapper4的思考:
SpringBoot集成MyBatis通用Mapper4-阿里云开发者社区
SWagger2和SWagger3区别:
Spring Boot 下的Swagger 3.0 与 Swagger 2.0 的详细对比_swagger3 和swagger2注解对比-CSDN博客
官网保存地址:
APIfox:[Apifox - API 文档、调试、Mock、测试一体化协作平台。拥有接口文档管理、接口调试、Mock、自动化测试等功能,接口开发、测试、联调效率,提升 10 倍。最好用的接口文档管理工具,接口自动化测试工具。](https://apifox.com/?utm_source=bing&utm_medium=sem&utm_campaign=竞品词-Swagger&utm_content=Swagger-核心&utm_term=swagger 作用&search_term=swagger3,swagger2 &msclkid=1e3008526e2b17fe90646f931c7e5799)
优化时间格式的两种方式:
发起客户端请求的工具:
在ApplicationContext初始化前,通过BootstrapContext创建一些组件实例(需要的话),等ApplicationContext初始化后,再将BootstrapContext创建创建的实例注册到ApplicationContext中作为常规的bean供项目使用。
@FeignClient("cloud-payment-service")
public interface PayFeignApi {
//方法上的注解就是被调用方法的请求类型和地址
//这样他就合成了http://cloud-payment-service/pay/getall
@GetMapping("/pay/getall")
//这里的返回值需要和被调用接口的返回值一致
ResultData getOrders();
}
关于resttemplate的使用:
//1.get请求【两个方法任选一个】
//两个方法的参数一样:①url请求地址 ②请求参数【可以省略】 ③返回值接收对象类型
//只接受返回对象用这个:restTemplate.getForObject("请求地址",参数,返回值对象类型)
Result result = restTemplate.getForObject("http://localhost:8080/order/getPayResult", Result.class);
//全部响应体用这个:restTemplate.getForEntity("请求地址",参数,返回值对象类型)
ResponseEntity<Result> forEntity = restTemplate.getForEntity("http://localhost:8001/pay/get/all", Result.class);
//2.post请求【两个方法任选一个】
//两个方法的参数一样:①url请求地址 ②请求参数 ③返回值接收对象类型
//只接受返回对象用这个:restTemplate.postForObject("请求地址",参数,返回值对象类型)
Result result = restTemplate.postForObject("http://localhost:8080/order/getPayResult",pay,Result.class);
//全部响应体用这个:restTemplate.postForEntity("请求地址",参数,返回值对象类型)
ResponseEntity<String> stringResponseEntity = restTemplate.postForEntity("http://localhost:8080/order/getPayResult",pay,String.class);
//3.delete请求
//方法的参数:①url请求地址
restTemplate.delete("http://localhost:8080/order/getPayResult");
//4.put请求
//方法的参数:①url请求地址 ②请求参数
restTemplate.put("http://localhost:8080/order/getPayResult", pay);
spring:
cloud:
openfeign:
client:
config:
#这里将default换成微服务的名称
cloud-payment-service:
#指定超时时间最大:3S
read-timeout: 3000
#指定连接时间最大:3S
connect-timeout: 3000
上述表格中的client是随便写的,注意注意。
用contextID进行命名才是王道。
配置超时时间:
上述中的重试机制是这样的,需要先配置retryer到容器里面才行!!1
JDK新特性与ES:
sharding_sphere:
-
Snowflake:即使用 Snowflake 算法生成唯一 ID。
-
UUID:使用 UUID 算法生成全局唯一的主键。
-
Next Value For:依赖于数据库的序列或者自定义生成器。
-
Other Custom:通过实现 ShardingSphere 提供的 Key Generator 接口,自定义生成策略。
-
@RunWith是 JUnit 中的一个注解,它的主要作用是指定一个运行器(Runner)。运行器是用来运行测试用例的类,它决定了测试用例的运行方式。运行测试样例的东西!!
Mysql详细解释:
binlog的三种日志关系:
- Statement 格式:记录 SQL 语句,日志文件小,但可能有数据一致性问题。
- Row 格式:记录每一行数据的变化,日志文件大,但数据一致性好。
- Mixed 格式:根据具体情况选择记录
Statement或Row,日志文件大小适中,数据一致性较好。
负载均衡类型,目前的取值有4 种:
(1)balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
(2)balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从
模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3)balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
(4)balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
指令细分:
mysql -h 主机名 -P 端口号 -u 用户名 -p密码
show variables like 'character_%';
show variables like 'collation_%';
show variables like 'character_%';
show variables like 'collation_%'; 用最简单的语言解释清楚上面这个collation_%具体有什么意义以及作用
着重号区分情况:
固定常数值查询:
SELECT '尚硅谷' AS corporation, last_name FROM employees;
关于springMVC的匹配方法与匹配策略:
在 Spring Framework 中,mvc.pathmatch.matching-strategy: ant_path_matcher 这个配置项用于指定 Spring MVC 中 URL 路径匹配策略的类型。具体来说,它是配置 Spring MVC 如何匹配请求的 URL 路径和控制器方法之间的映射关系。
解释配置项:
mvc:这是 Spring MVC 的相关配置部分,控制如何处理 HTTP 请求和响应。
pathmatch:用于配置路径匹配策略,即如何根据 URL 路径选择相应的处理器(控制器)。
matching-strategy:这个属性定义了路径匹配的策略方式。常见的匹配策略包括:
ant_path_matcher:使用 Ant 风格的路径匹配规则。
regex_path_matcher:使用正则表达式来进行路径匹配。
ant_path_matcher 匹配策略:
ant_path_matcher 是 Spring 默认的路径匹配策略,它允许你使用 Ant 风格的路径模式来匹配 URL。Ant 风格的路径模式具有如下特性:
*:匹配任意字符串(不包括路径分隔符)。
**:匹配任意路径(包括路径分隔符)。
?:匹配单个字符。
{variable}:匹配路径参数(类似于路径中的占位符)。
示例:
假设你有以下控制器方法:
@RequestMapping("/users/*")
public String handleUserRequests() {
return "user";
}
这里的路径 /users/* 会匹配以 /users/ 开头的任何路径,但是它只能匹配单个路径段(* 表示匹配任何单个路径段,但不包括 /)。
regex_path_matcher 匹配策略:
如果你将 matching-strategy 设置为 regex_path_matcher,Spring 会使用正则表达式来匹配 URL 路径。例如:
@RequestMapping("/users/{id:\\d+}")
public String handleUserById(@PathVariable String id) {
return "user" + id;
}
这会匹配 /users/123,但不会匹配 /users/abc,因为路径中 {id} 必须是一个数字(正则表达式 \\d+)。
总结:
mvc.pathmatch.matching-strategy: ant_path_matcher 是告诉 Spring MVC 使用 Ant 风格的路径匹配规则来匹配 URL 路径和控制器方法。
这种配置适合于那些需要灵活路径匹配的场景(如使用 *、** 等路径通配符)。
如果你需要更复杂的路径匹配规则,也可以选择 regex_path_matcher 来使用正则表达式进行匹配。
配置其中的逻辑删除字段,对逻辑删除字段的思考。
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted
关于链式存储:
在 Spring Boot 项目中,@Accessors(chain = true) 是 Lombok 提供的一个注解,用于简化 Java 类的 getter 和 setter 方法生成规则。以下是对其作用和意义的详细解释:
1. 作用
@Accessors(chain = true) 的主要作用是生成链式 setter 方法。也就是说,当为类中的字段生成 setter 方法时,这些方法会返回当前对象(this)而非 void。这样就可以在调用 setter 方法时,将其链接起来,实现链式调用。
2. 意义
代码简洁性:通过链式调用,可以将多个 setter 方法的调用写成一行代码,使代码更加简洁、易读。例如,原本需要这样写:
java
复制
PageQuery query = new PageQuery();
query.setPageNo(2);
query.setPageSize(10);
query.setIsAsc(false);
query.setSortBy("createdDate");
使用链式调用后,可以简化为:
java
复制
PageQuery query = new PageQuery().setPageNo(2).setPageSize(10).setIsAsc(false).setSortBy("createdDate");
可读性:链式调用使代码的逻辑更加流畅,一眼就能看出是对同一对象的多个属性进行设置,增强了代码的可读性。
代码风格一致性:在一些需要大量创建和配置对象的场景中,链式调用可以使代码风格更加一致,便于维护。
3. 相关代码片段示例
java
复制
@Data
@Accessors(chain = true)
public class PageQuery {
private Integer pageNo;
private Integer pageSize;
private Boolean isAsc;
private String sortBy;
}
在以上代码中,@Data 会自动生成 getter 和 setter 方法,而 @Accessors(chain = true) 会为 setter 方法生成类似以下形式的代码:
java
复制
public PageQuery setPageNo(Integer pageNo) {
this.pageNo = pageNo;
return this;
}
这样就可以实现链式调用。
总结
@Accessors(chain = true) 是 Lombok 提供的一个注解,用于生成链式 setter 方法,使代码更加简洁、易读,同时也增强了代码的可维护性。
数据库的设计情况:
以下是用通俗易懂的语言解释每行代码的具体意义和作用:
### 表名
```sql
CREATE TABLE learning_lesson
```
- **作用**:创建一个名为 `learning_lesson` 的表。
- **意义**:这个表将存储学生的课程学习信息,比如学习状态、学习计划、学习进度等。
### 字段定义
#### 1. `id`
```sql
id bigint NOT NULL COMMENT '主键'
```
- **作用**:定义一个名为 `id` 的字段,数据类型为 `bigint`(大整数),不允许为空。
- **意义**:作为表的唯一标识符,用于唯一地标识表中的每一行记录。
#### 2. `user_id`
```sql
user_id bigint NOT NULL COMMENT '学员id'
```
- **作用**:定义一个名为 `user_id` 的字段,数据类型为 `bigint`,不允许为空。
- **意义**:标识学员在系统中的唯一的身份标识,用于关联学员信息。
#### 3. `course_id`
```sql
course_id bigint NOT NULL COMMENT '课程id'
```
- **作用**:定义一个名为 `course_id` 的字段,数据类型为 `bigint`,不允许为空。
- **意义**:标识课程在系统中的唯一的身份标识,用于关联课程信息。
#### 4. `status`
```sql
status tinyint DEFAULT '0' COMMENT '课程状态,0-未学习,1-学习中,2-已学完,3-已失效'
```
- **作用**:定义一个名为 `status` 的字段,数据类型为 `tinyint`(小整数),默认值为 `0`。
- **意义**:表示学员学习课程的状态,`0` 表示未学习,`1` 表示学习中,`2` 表示已学完,`3` 表示已失效。
#### 5. `week_freq`
```sql
week_freq tinyint DEFAULT NULL COMMENT '每周学习频率,每周3天,每天2节,则频率为6'
```
- **作用**:定义一个名为 `week_freq` 的字段,数据类型为 `tinyint`,允许为空。
- **意义**:表示学员每周学习的频率,例如每周 3 天,每天 2 节课,则频率为 6。
#### 6. `plan_status`
```sql
plan_status tinyint NOT NULL DEFAULT '0' COMMENT '学习计划状态,0-没有计划,1-计划进行中'
```
- **作用**:定义一个名为 `plan_status` 的字段,数据类型为 `tinyint`,默认值为 `0`。
- **意义**:表示学员的学习计划状态,`0` 表示没有计划,`1` 表示计划进行中。
#### 7. `learned_sections`
```sql
learned_sections int NOT NULL DEFAULT '0' COMMENT '已学习小节数量'
```
- **作用**:定义一个名为 `learned_sections` 的字段,数据类型为 `int`(整数),默认值为 `0`。
- **意义**:表示学员已学习的小节数量。
#### 8. `latest_section_id`
```sql
latest_section_id bigint DEFAULT NULL COMMENT '最近一次学习的小节id'
```
- **作用**:定义一个名为 `latest_section_id` 的字段,数据类型为 `bigint`,允许为空。
- **意义**:表示学员最近一次学习的小节的唯一标识。
#### 9. `latest_learn_time`
```sql
latest_learn_time datetime DEFAULT NULL COMMENT '最近一次学习的时间'
```
- **作用**:定义一个名为 `latest_learn_time` 的字段,数据类型为 `datetime`(日期时间),允许为空。
- **意义**:记录学员最近一次学习的具体时间。
#### 10. `create_time`
```sql
create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
```
- **作用**:定义一个名为 `create_time` 的字段,数据类型为 `datetime`,默认值为当前时间戳。
- **意义**:记录该记录的创建时间。
#### 11. `expire_time`
```sql
expire_time datetime NOT NULL COMMENT '过期时间'
```
- **作用**:定义一个名为 `expire_time` 的字段,数据类型为 `datetime`,不允许为空。
- **意义**:表示该记录的过期时间。
#### 12. `update_time`
```sql
update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
```
- **作用**:定义一个名为 `update_time` 的字段,数据类型为 `datetime`,默认值为当前时间戳,并且在每次更新记录时自动更新为当前时间。
- **意义**:记录该记录的最后更新时间。
### 索引
```sql
PRIMARY KEY (id),
UNIQUE KEY idx_user_id (user_id,course_id) USING BTREE
```
- **作用**:
- `PRIMARY KEY (id)`:定义 `id` 为主键,用于唯一标识表中的每一行记录。
- `UNIQUE KEY idx_user_id (user_id,course_id) USING BTREE`:创建一个唯一性索引,确保 `user_id` 和 `course_id` 的组合是唯一的。
- **意义**:
- 主键用于快速定位记录,唯一性索引用于确保学员和课程的关联关系是唯一的,避免重复记录。
### 表选项
```sql
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生课表';
```
- **作用**:
- `ENGINE=InnoDB`:指定表的存储引擎为 InnoDB。
- `DEFAULT CHARSET=utf8mb4`:指定表的默认字符集为 UTF-8。
- `COLLATE=utf8mb4_0900_ai_ci`:指定字符集的排序规则。
- `COMMENT='学生课表'`:为表添加注释,描述表的用途。
- **意义**:
- InnoDB 是 MySQL 的一种存储引擎,支持事务和外键等特性,能够保证数据的一致性和完整性。
- UTF-8 是一种常见的字符集,支持多种语言的字符,包括中文。
- 表注释用于方便开发人员和 DBA 理解表的用途,方便后续的维护和管理。
关于CURRENT_TMIESTAMP
`CURRENT_TIMESTAMP` 是 SQL 中的一个函数,用于表示当前的日期和时间。以下是用最简单的语言解释其具体作用和意义:
### 作用:
1. **自动生成时间戳**:
- 在插入或更新表中的记录时,可以使用 `CURRENT_TIMESTAMP` 来自动设置一个时间戳字段为当前的日期和时间。
- 例如,如果你在创建一条记录时,有一个字段用于记录创建时间,你可以将该字段的默认值设置为 `CURRENT_TIMESTAMP`,这样该字段会自动填充为记录被创建时的当前时间。
2. **表示动态时间**:
- `CURRENT_TIMESTAMP` 返回的是数据库服务器所在时区的当前日期和时间,而不是某个固定的时间值。
- 每次查询或使用这个函数时,它都会返回一个新的时间值,反映了数据库服务器上当前的时刻。
### 意义:
1. **记录事件的时间点**:
- 在数据库中,时间戳字段通常用于记录事件发生的具体时间,如记录的创建时间、修改时间或其他重要事件的时间。
- 通过使用 `CURRENT_TIMESTAMP`,可以确保这些时间戳字段总是包含最新、最准确的时间信息,而不是依赖手动输入或其他不准确的来源。
2. **用于审计和日志记录**:
- 在需要追踪数据变更或用户行为的场景中,时间戳字段是非常重要的。
- 例如,通过记录用户的登录时间、操作时间等,可以方便地进行数据分析、审计和问题排查。
3. **简化开发工作**:
- 使用 `CURRENT_TIMESTAMP` 可以避免开发人员手动获取当前时间并将其插入到数据库中,从而简化了代码的编写和维护工作。
- 这也减少了因手动操作可能导致的错误,确保了时间记录的准确性和一致性。
总结:
`CURRENT_TIMESTAMP` 提供了一种方便且可靠的方式来记录当前的日期和时间,广泛应用于数据库开发中,以满足各种需要时间戳的应用场景。
@RequiredArgsConstructor 是 Lombok 提供的一个注解,用于生成一个包含所有 final 或 @NonNull 注解字段的构造方法。以下是其具体的作用和意义:
关于执行流程:
2. 请求处理流程
Spring 系统的请求处理流程如下:
网关过滤器:请求首先到达网关服务,经过网关过滤器(如认证、权限校验等)。
后端服务:网关服务将请求转发到后端服务。
拦截器:后端服务接收到请求后,Spring MVC 的拦截器开始处理(如记录日志、用户校验等)。
控制器:请求进入控制器方法,处理业务逻辑。
以下是对图片中各个注解的简单解释:
1. `@FeignClient`
- **作用**:定义一个 Feign 客户端接口,用于调用其他服务的接口。
- **属性**:
- `contextId`:指定上下文 ID,用于区分不同的 Feign 客户端。
- `value`:指定要调用的服务名称。
- `path`:指定服务的路径。
2. `@GetMapping`
- **作用**:映射 HTTP GET 请求到指定的方法。
- **属性**:
- `"/batchQuery"`:指定请求的路径为 `/batchQuery`。
3. `@RequestParam`
- **作用**:将请求参数绑定到方法参数。
- **属性**:
- `"ids"`:指定请求参数的名称为 `ids`。
- `Iterable<Long> ids`:指定方法参数的类型为 `Iterable<Long>`,表示可以接收多个 `Long` 类型的参数。
示例解释
java
@GetMapping("/batchQuery")
List<CataSimpleInfoDTO> batchQueryCatalogue(@RequestParam("ids") Iterable<Long> ids);
作用:定义一个 GET 请求方法,用于根据目录 ID 列表查询目录信息。
参数:
@RequestParam("ids") Iterable<Long> ids`:表示方法接收一个名为 `ids` 的请求参数,类型为 `Iterable<Long>`,即可以接收多个 `Long` 类型的目录 ID。
返回值:返回一个 `List<CataSimpleInfoDTO>` 类型的列表,表示查询到的目录基础信息列表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号