redis学习
- redis-cli:是redis提供的命令行客户端
- redis-server:是redis的服务端启动脚本
- redis-sentinel:是redis的哨兵启动脚本

关于redis的选型问题:
https://www.cnblogs.com/54chensongxia/p/13815761.html
关于jedis连接池的八个参数:
1.maxTotal(最大连接数) - 这个参数设置的是连接池中最多可以有多少个连接。就像一个图书馆里最多能有多少本书一样,这里设置为8,就是说连接池里最多能有8个连接。
2.maxIdle(最大空闲连接数) - 这个参数表示连接池中最多可以有多少个空闲的连接。空闲连接就是暂时没人用,但还在连接池里待着的连接。这里也设置为8,意味着空闲的连接最多有8个。
3.minIdle(最小空闲连接数) - 这个参数是连接池中至少要保持多少个空闲连接。就像一个游泳池里至少要保持多少水一样,这里设置为0,就是说连接池里可以没有空闲连接,也可以有。
4.maxWaitMillis(最大等待时间) - 当连接池里的连接都被别人用完了,新的请求想要获取连接,就得等。这个参数就是设置最多能等多久。这里设置为1000毫秒,也就是1秒钟,如果1秒钟后还没等到连接,就会报错。
关于springdataredis的常见操作指令
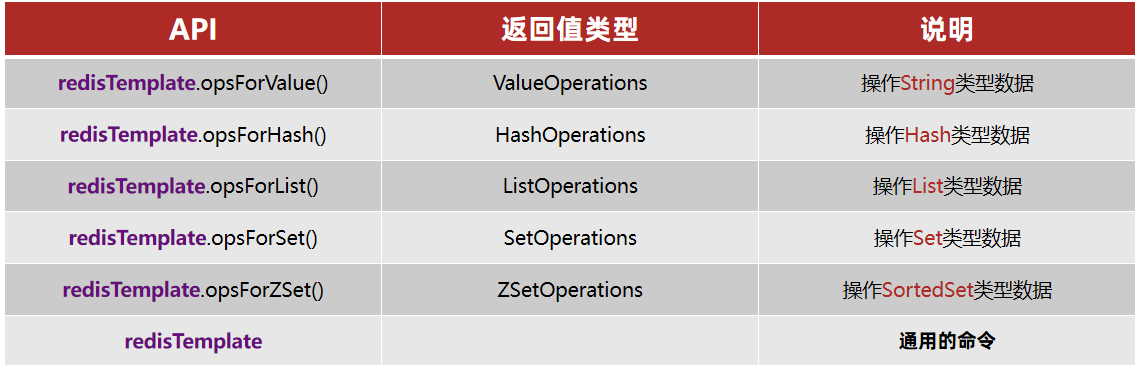
redis中的序列化:

关于tomcat的运行原理:
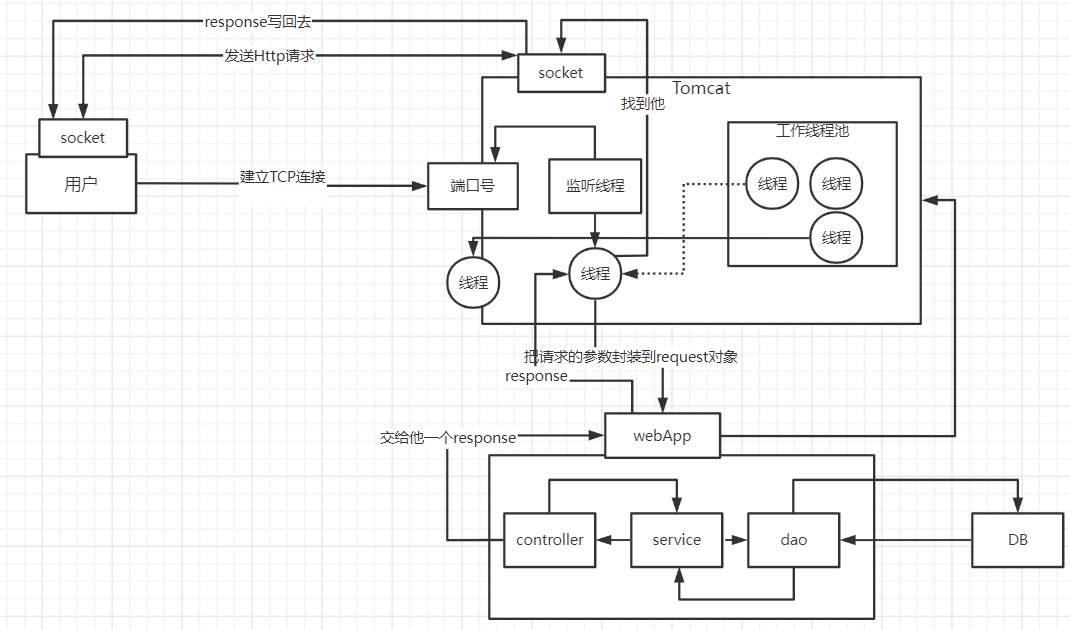
关于threadlocal的具体运行原理
https://blog.csdn.net/qq_37605486/article/details/137636878
关于redis缓存问题的额解决方案:
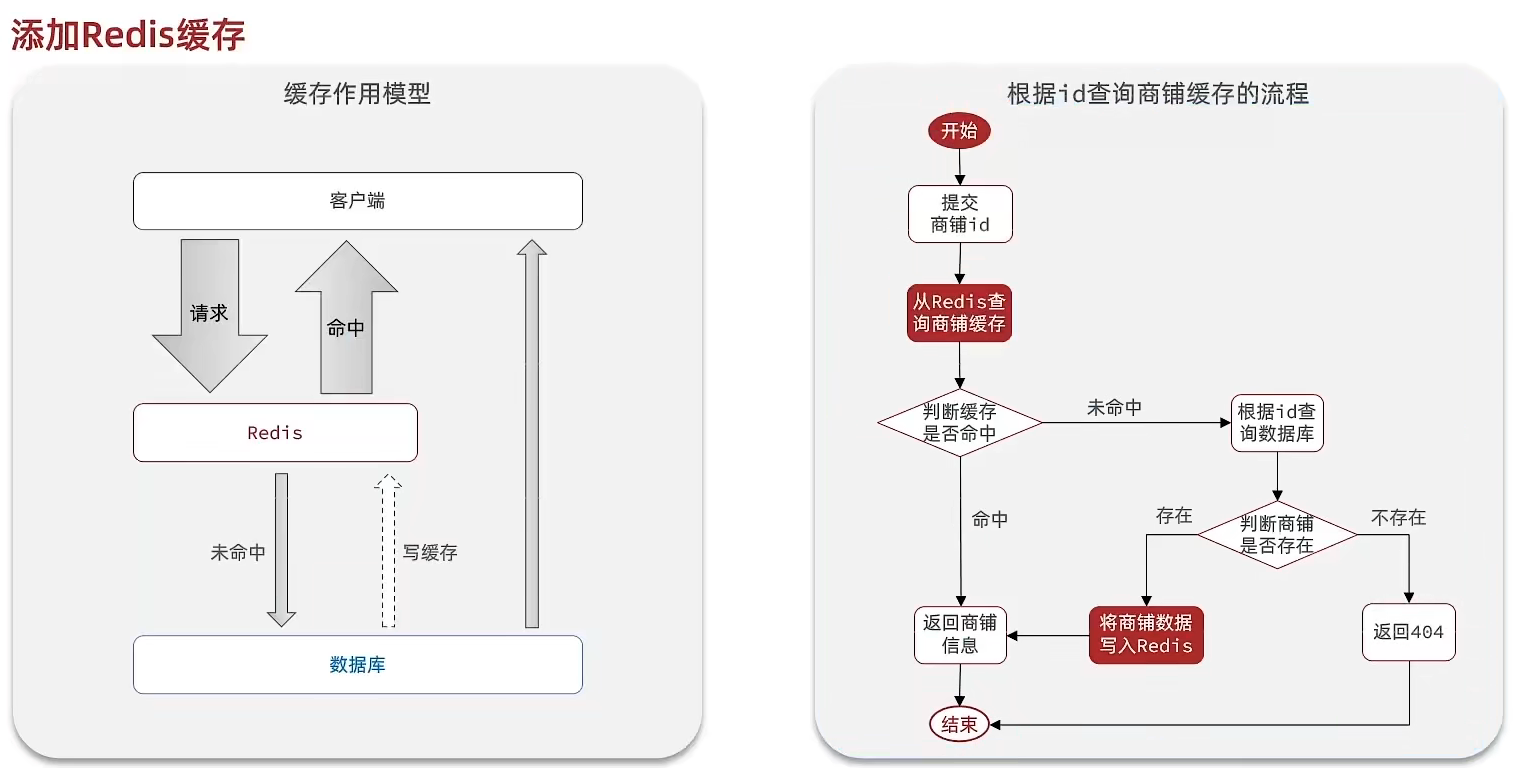
黑马程序员视频的经典问题:
以上两种方案都会有问题,但哪个出现的概率会高一点呢?
那就要比较是写数据库快,还是写缓存快?当然是写缓存快
在左边的例子中,我们删除完缓存向数据库写,这个时间相对较长,那么线程二的行为很容易发生
而在右边的例子中,我们向缓存中写的时间相对短,并且线程二中还要先操作数据库,这个时间长所以线程二出现的概率就更低
所以我们选择先操作数据库,再操作缓存
缓存穿透问题
关于布隆过滤器和返回空值的代码实现:
https://blog.csdn.net/m0_72853403/article/details/134998212
缓存击穿,缓存穿透,缓存雪崩三者之间的关系:
雪崩是多个,击穿是一个,区分与区别。
- 给不同的Key的TTL添加随机值
关于缓存击穿与缓存穿透问题的具体思考与解释:
中文确实不太好理解,你可以看看它们的英文名称:缓存穿透(cache penetration)和缓存击穿(cache breakdown)。Penetration 的意思是渗透,穿透,而breakdown 的意思是故障,崩溃,损坏。它们的区别就出来了,提炼一下关键字,一个是“透”,一个是“坏”。前者“透”的意思可以理解成查询不存在的值,那么查询是会从缓存穿透过去的。而后者“坏”的意思就可以理解成查询的值是存在的,但是它的缓存暂时“坏掉”了,也就是没有在缓存中。当然,我们平时可能还是和别人交流的时候用中文,穿透和击穿只有一个带“透”字的,没有带“坏”字的,记住这个“透”字,以后提到穿透和击穿的时候
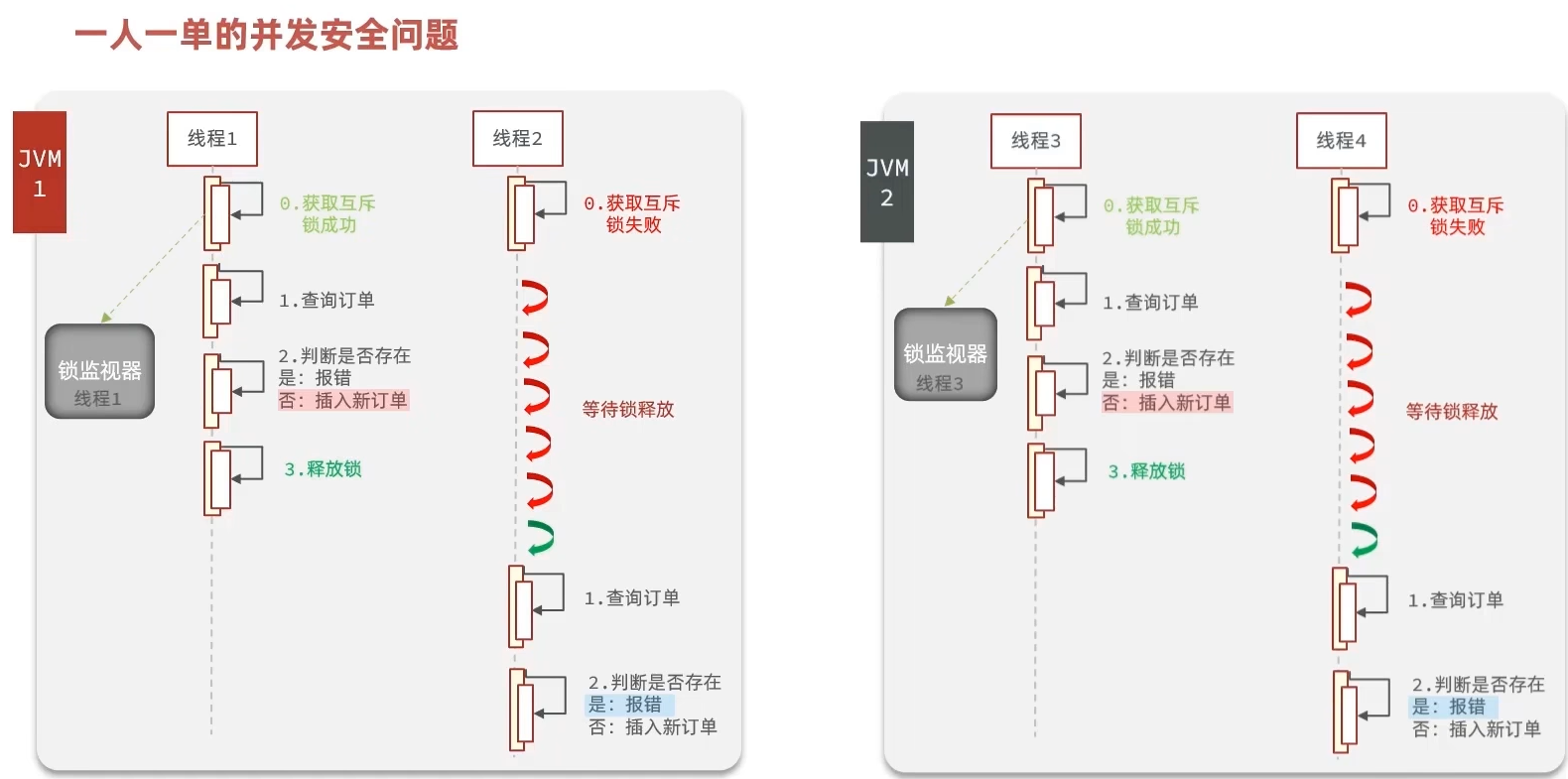
有锁就有死锁问题的发生!!!这个东西的思考。
封装redis工具这一部分严重看不懂!!!
关于下面的代码思考:加锁是具体的通过redis操作命令的setIfAbsent方法解决。
setIfAbsent方法就是setnx方法。
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
如何写出具体的逻辑过期方案与逻辑问题:这里是封装成redis工具
redis实现全局唯一ID:

关于mybatisplus这一点的思考:这一点的思考要思考的就是似乎秒杀并没有那么困难!!
boolean success = seckillVoucherService.update()
.setSql("stock= stock -1")
.eq("voucher_id", voucherId).update();
对于redis中的悲观锁与乐观锁的思考:
悲观锁:lock,synchronized
乐观锁:cas操作
关于cas问题的详细解释!!
CAS引发的ABA问题
ABA问题是指在CAS操作时,其他线程将变量值A改为了B,但是又被改回了A,等到本线程使用期望值A与当前变量进行比较时,发现变量A没有变,于是CAS就将A值进行了交换操作,但是实际上该值已经被其他线程改变过,这与乐观锁的设计思想不符合。ABA问题的解决思路是,每次变量更新的时候把变量的版本号加1,那么A-B-A就会变成A1-B2-A3,只要变量被某一线程修改过,改变量对应的版本号就会发生递增变化,从而解决了ABA问题。在JDK的java.util.concurrent.atomic包中提供了AtomicStampedReference来解决ABA问题,该类的compareAndSet是该类的核心方法。
关于intern问题的详细解释:
https://zhuanlan.zhihu.com/p/213707389
事务失效的几种原因需要仔细思以下就是关于redis中用id来锁的示例:
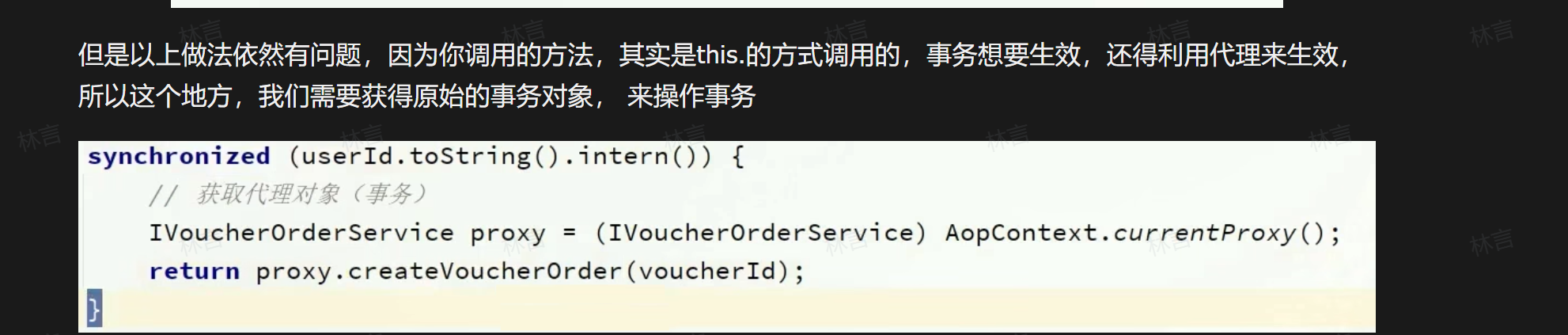
分布式锁的引入:
后面可以拓展的思路:利用zookeper实现分布式锁!
关于锁的误删问题:
关于lua脚本的动态性问题:
关于动态代理的子线程与主线程关系,绝了:
好的,我来更详细地解释一下为什么动态代理要在主线程中获取,然后在子线程中使用,以及ThreadLocal在其中的作用。
- ThreadLocal的作用
ThreadLocal是一个线程局部变量存储机制,它为每个线程提供了一个独立的变量副本。这意味着每个线程可以独立地读写自己的变量副本,而不会相互干扰。在Spring的事务管理中,事务信息是通过ThreadLocal来存储的。每个线程在执行带有@Transactional注解的方法时,Spring会将事务信息绑定到当前线程的ThreadLocal中。 - 为什么动态代理要在主线程中获取
在Spring中,当你在方法上加上@Transactional注解时,Spring会创建一个代理对象。这个代理对象在调用被注解的方法时,会自动处理事务的开始、提交和回滚等操作。这些事务操作是通过ThreadLocal变量来管理的。
主线程中的事务管理:
当你在主线程中调用一个带有@Transactional注解的方法时,Spring会创建一个事务,并将这个事务信息绑定到当前线程的ThreadLocal变量中。
这个事务信息包括事务的开始、提交和回滚等操作。
动态代理对象:
AopContext.currentProxy()方法用于获取当前类的代理对象。这个代理对象能够正确地使用当前线程的事务信息。
在主线程中调用AopContext.currentProxy()时,获取的代理对象会绑定当前线程的事务信息。 - 为什么子线程要使用主线程中的动态代理
子线程中的事务管理:
子线程是独立的线程,它有自己的ThreadLocal变量。因此,子线程无法直接访问主线程中的事务信息。
如果在子线程中直接调用带有@Transactional注解的方法,Spring会尝试在子线程的ThreadLocal中查找事务信息,但通常会找不到,从而导致事务管理失效。
使用主线程中的动态代理:
通过在主线程中获取代理对象,并将其传递给子线程,子线程可以使用这个代理对象来调用方法。
这个代理对象在调用方法时,会使用主线程中的事务信息,从而确保事务管理在子线程中仍然有效。 - 具体代码示例
java复制
// 主线程中获取代理对象
proxy = (IVoucherOrderService)AopContext.currentProxy();
// 子线程中使用代理对象
SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler());
主线程:
AopContext.currentProxy()获取当前类的代理对象,这个代理对象绑定了主线程的事务信息。
这个代理对象被存储在类的成员变量proxy中。
子线程:
VoucherOrderHandler内部类的run方法在子线程中运行。
子线程通过proxy.createVoucherOrder(voucherOrder)调用方法时,使用的是主线程中获取的代理对象。
这个代理对象在调用方法时,会使用主线程中的事务信息,确保事务管理在子线程中仍然有效。
5. 总结
ThreadLocal:为每个线程提供独立的变量副本,用于存储事务信息。
动态代理:在主线程中获取,绑定主线程的事务信息。
子线程:使用主线程中获取的代理对象,确保事务管理在子线程中仍然有效。
通过这种方式,代码能够确保在多线程环境下,事务管理仍然能够正确地工作,从而保证数据的一致性和完整性。希望这次解释更加清晰!
关于事务管理的内容:
https://blog.csdn.net/weixin_52850476/article/details/122734418?ops_request_misc=%257B%2522request%255Fid%2522%253A%25222553f2098bc17d0495c6b4f5506102ce%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=2553f2098bc17d0495c6b4f5506102ce&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-122734418-null-null.142v101pc_search_result_base7&utm_term=%E4%BA%8B%E5%8A%A1%E7%AE%A1%E7%90%86&spm=1018.2226.3001.4187
Redis的XREADGROUP命令的每一部分的具体作用和意义。
XREADGROUP命令
XREADGROUP命令用于从一个或多个流(stream)中读取消息,这些消息是通过消费者组(consumer group)来管理的。消费者组允许多个消费者(consumer)共同处理一个流中的消息,通常用于分布式任务处理或消息队列场景。
命令格式
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
每一部分的具体作用和意义
XREADGROUP:
这是命令的名称,表示从消费者组中读取消息。
GROUP group consumer:
GROUP:表示接下来的两个参数是消费者组的名称和消费者的名字。
group:消费者组的名称。消费者组是一个逻辑上的分组,多个消费者可以属于同一个消费者组,共同处理流中的消息。
consumer:当前消费者的名称。每个消费者在消费者组中有一个唯一的名称,用于区分不同的消费者。
[COUNT count]:
COUNT:表示接下来的参数是每次读取的最大消息数量。
count:每次读取的最大消息数量。例如,COUNT 10表示每次最多读取10条消息。这是一个可选参数,如果不指定,默认值通常是1。
[BLOCK milliseconds]:
BLOCK:表示接下来的参数是阻塞时间,单位是毫秒。
milliseconds:阻塞时间,单位是毫秒。如果流中没有消息,命令会阻塞指定的时间,直到有新消息到达或超时。这是一个可选参数,如果不指定,默认值通常是0,表示不阻塞。
[NOACK]:
NOACK:表示读取消息时不发送确认(acknowledgment)。通常在消费者组中,消费者需要显式地确认消息已经处理完毕。使用NOACK选项可以跳过这一步骤,但这样做可能会导致消息丢失。这是一个可选参数。
STREAMS key [key ...]:
STREAMS:表示接下来的参数是流的键名。
key:流的键名。可以指定一个或多个流的键名,例如STREAMS stream1 stream2表示从stream1和stream2两个流中读取消息。
ID [ID ...]:
ID:表示每个流的起始读取位置。
ID:每个流的起始读取位置。可以指定一个或多个ID,每个ID对应一个流。例如,ID 0 0表示从stream1和stream2的最开始位置读取消息。特殊值>表示从流的末尾开始读取新消息。
示例
假设有一个流stream1,我们想通过消费者组group1中的消费者consumer1读取消息,每次最多读取5条消息,如果流中没有消息则阻塞3000毫秒(3秒),从流的末尾开始读取新消息。命令如下:
plaintext复制
XREADGROUP GROUP group1 consumer1 COUNT 5 BLOCK 3000 STREAMS stream1 >
解释
XREADGROUP:命令名称,表示从消费者组中读取消息。
GROUP group1 consumer1:指定消费者组名称group1和消费者名称consumer1。
COUNT 5:每次最多读取5条消息。
BLOCK 3000:如果流中没有消息,命令会阻塞3000毫秒(3秒)。
STREAMS stream1:指定流的键名stream1。
:从流的末尾开始读取新消息。
总结
XREADGROUP命令用于从消费者组中读取消息,通过指定消费者组和消费者,可以灵活地管理多个消费者共同处理一个或多个流中的消息。通过COUNT、BLOCK和NOACK等选项,可以控制读取行为,确保消息处理的高效性和可靠性。
理解redis点赞功能的具体实现
@Override public Result likeBlog(Long id){ // 1.获取登录用户 Long userId = UserHolder.getUser().getId(); // 2.判断当前登录用户是否已经点赞 String key = BLOG_LIKED_KEY + id; Boolean isMember = stringRedisTemplate.opsForSet().isMember(key, userId.toString()); if(BooleanUtil.isFalse(isMember)){ //3.如果未点赞,可以点赞 //3.1 数据库点赞数+1 boolean isSuccess = update().setSql("liked = liked + 1").eq("id", id).update(); //3.2 保存用户到Redis的set集合 if(isSuccess){ stringRedisTemplate.opsForSet().add(key,userId.toString()); } }else{ //4.如果已点赞,取消点赞 //4.1 数据库点赞数-1 boolean isSuccess = update().setSql("liked = liked - 1").eq("id", id).update(); //4.2 把用户从Redis的set集合移除 if(isSuccess){ stringRedisTemplate.opsForSet().remove(key,userId.toString()); } }
这部分就是stream api的部分语法:
`这段代码主要使用了Java的几个重要语法和库的功能,包括Java 8的流(Stream)API、Lambdas表达式,以及一些常用的库方法。下面我将详细解释这些语法的使用。
- Java 8 流(Stream)API
Java 8 引入了流(Stream)API,它提供了一种高效的方法来处理集合。流可以进行各种操作,如过滤、排序、映射等。在这段代码中,流API被用来处理用户ID的集合。
java复制
Listids = top5.stream().map(Long::valueOf).collect(Collectors.toList());
stream():将集合转换为流。
map(Long::valueOf):将流中的每个元素(字符串)转换为Long类型。Long::valueOf是一个方法引用,等同于x -> Long.valueOf(x)。
collect(Collectors.toList()):将流中的元素收集到一个新的列表中。 - Lambdas表达式
Lambdas表达式是Java 8的一个重要特性,它允许你以更简洁的方式编写匿名内部类。在这段代码中,Lambdas表达式被用来转换用户对象。
java复制
.map(user -> BeanUtil.copyProperties(user, UserDTO.class))
user -> BeanUtil.copyProperties(user, UserDTO.class):这是一个Lambda表达式,它接受一个user对象,并返回一个新的UserDTO对象。BeanUtil.copyProperties是一个工具方法,用于将一个对象的属性复制到另一个对象中。 - Java 8 方法引用
方法引用是Lambdas表达式的一种特殊情况,它允许你直接引用已有的方法。在这段代码中,方法引用被用来调用Long.valueOf方法。
java复制
.map(Long::valueOf)
Long::valueOf:这是一个方法引用,等同于x -> Long.valueOf(x)。它表示调用Long类的静态方法valueOf。 - 字符串连接
StrUtil.join方法用于将一个集合中的元素连接成一个字符串,元素之间用指定的分隔符分隔。
java复制
String idStr = StrUtil.join(",", ids);
StrUtil.join(",", ids):将ids列表中的每个元素连接成一个字符串,元素之间用逗号分隔。StrUtil是cn.hutool.core.util.StrUtil类,是Hutool工具库中的一个工具类。 - SQL排序
在查询用户信息时,使用了SQL的ORDER BY FIELD语句来确保返回的用户列表的顺序与ids列表中的顺序一致。
java复制
.last("ORDER BY FIELD(id," + idStr + ")")
ORDER BY FIELD(id, 5, 1):这是一个SQL语句,用于按指定的顺序排序。FIELD(id, 5, 1)表示按id字段的值在5, 1中的顺序排序。 - 类型转换和集合操作
这段代码还涉及了一些基本的类型转换和集合操作,如将Set转换为List,以及使用Collections.emptyList()返回一个空列表。
java复制
if (top5 == null || top5.isEmpty()) {
return Result.ok(Collections.emptyList());``
}
Collections.emptyList():返回一个空的不可修改的列表。
总结
这段代码主要使用了Java 8的流API、Lambdas表达式、方法引用,以及一些常用的库方法(如Hutool的StrUtil)。这些语法和方法使得代码更加简洁、高效,并且易于理解和维护。希望这些解释能帮助你更好地理解这段代码的语法和功能。`
关于sql函数的漏缺
之前一直按照传统的字段进行分组,现在可以利用函数。
`@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3.非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 4.解析数据:blogId、minTime(时间戳)、offset
List
long minTime = 0; // 2
int os = 1; // 2
for (ZSetOperations.TypedTuple
// 4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
// 4.2.获取分数(时间戳)
long time = tuple.getScore().longValue();
if(time == minTime){
os++;
}else{
minTime = time;
os = 1;
}
}
os = minTime == max ? os : os + offset;
// 5.根据id查询blog
String idStr = StrUtil.join(",", ids);
List
for (Blog blog : blogs) {
// 5.1.查询blog有关的用户
queryBlogUser(blog);
// 5.2.查询blog是否被点赞
isBlogLiked(blog);
}
// 6.封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}`

 浙公网安备 33010602011771号
浙公网安备 33010602011771号