从零开始的nes模拟器-[4] PPU渲染背景
PPU 背景渲染
渲染原理
我们之前了解过,PPU VRAM 一共 4KB,每 1KB 就控制着一张图像,也就是说,另外 3KB 图像始终是不会输出到屏幕上的。同时这 4 张图像以田字格的形式组合,再结合 PPU 的滚动功能,就能实现背景画面的上下左右移动
下面针对每一帧图像(每一块 VRAM),看看 PPU 是如何渲染的:
NES 以 8 x 8 像素为单位,将图片分成了 32 x 30 个小块,每一个小块称为一个瓦片(tile),同时,每 16 个 tile 组成一个大块,如下图:
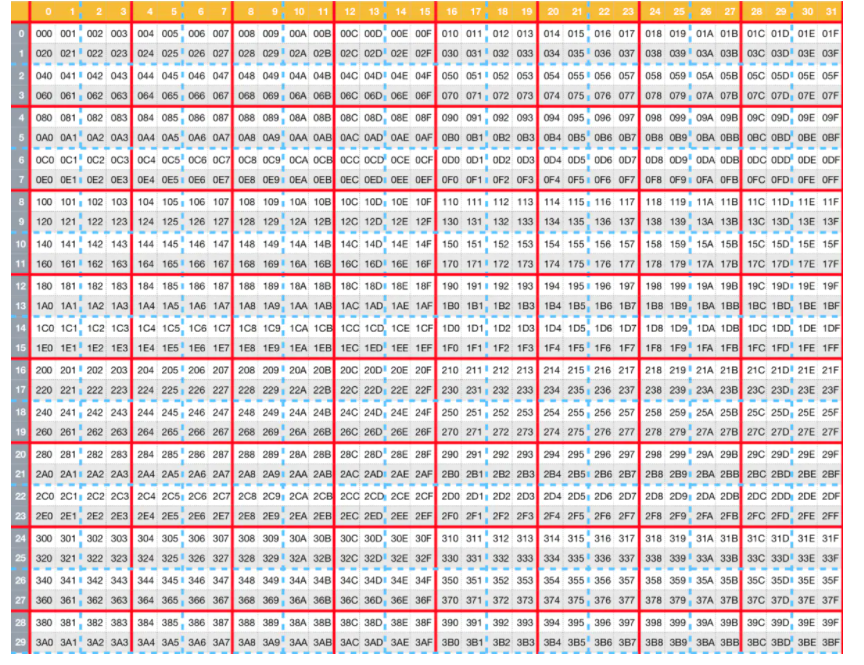
每一个 tile 在 vram 中用一个 byte 表示,该字节表示了当前 tile 在 pattern table 中的偏移量,也就表示像素的数据。
pattern table 以 16 bytes 为单位,每 16 bytes 中,有分前 8 bytes 和后 8 bytes。前后每 8 bytes 表示 tile 中每一行的 像素所处 palette 的低 2 bit,前 8 bytes 为 bit 0,后 8 bytes 为 bit 1
颜色高 2bit 由 attribute table 表示,attribute table 中每一个字节能管理 16 个 tile 的颜色,如上图中红色的大块。16 个 tile 中,每 4 个 tile 整合到一起,再和另外 12 个 tile 组成田字形格局,分别为 左上,右上,左下,右下。每个占 2 bit,刚好 8 bit
这里也能看到 NES 画面表现力不足,即每 4 个 tile 组成的部分田字格中,他们只能有 4 种不同的颜色,因为高 2 bit 固定了,剩下可变了只有低 2 bit
现在总结一下:图像分成了 32 x 30 = 960 个 tile,每个 tile 在 name table 占前 960 字节。同时 tile 在 vram 中表示 pattern table 0 - 255 的偏移量,pattern table 又以 16 bytes 为一个单位,那么总共需要 256 * 16 = 4KB 大小的 pattern table。前面讲过,pattern table 一共 8KB,可分为两个 4KB 分别给 background 或者 sprite 使用,是不是刚刚好?另外 16 个 tile 组成的大的 tile 中,每个由 attribute table 的一个字节表示,一共需要 8 x 8 = 64 bytes。加上 name table 的 960,刚好 64 + 960 = 1024 字节,即 1KB VRAM
图像的滚动
之前介绍的都是静态的情况,实际上游戏过程中画面都是运动的,这就靠 PPU 滚动来完成
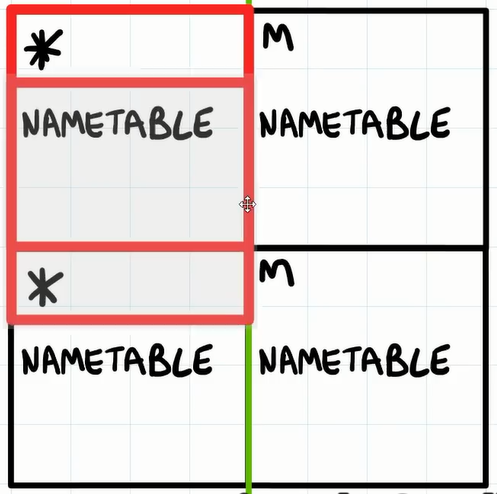
之前说过,PPU 一共 4 个 1KB 的 VRAM,他们组成田字布局,把屏幕想像成窗口,PPU 滚动的时候就相当于窗口在田字格上滑动,类似于这种效果:

以 NTFS 为例,图像刷新率为 60fps,PPU 会在 1s 内产生 60 次中断告知 CPU 刷新图像(这对应了之前介绍的垂直消隐), CPU 会设置 PPU相关的寄存器以更新图像位置,一次达到图像运动的目的。
最常见的窗口滚动分为垂直滚动和水平滚动。(由卡带决定)
如果窗口在某个方向上滚动超出了所有的NameTable,那么会出现一个叫 Wrapped (环绕)的现象。

垂直滚动
这里的M是Mirror映射的意思。换句话说,改写带 * ( M ) 的NameTable 会伴随着 更改对应的带 M ( * )的NameTable 。
水平滚动
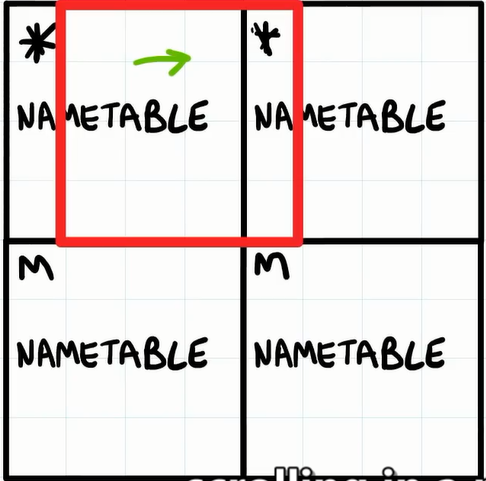
其它滚动方式
一般垂直滚动和水平滚动就能应付大部分游戏了,但是有的游戏居然还支持 "沿对角线滚动" 。 但是游戏通常不会沿对角线滚动,因为它会因为名字表镜像而在屏幕边缘产生伪影。
每个游戏的盒式磁带包含硬件,允许配置名称表镜像。

有些游戏不需要改变镜像,因此它们的盒式磁带硬连线到水平或垂直镜像。 (硬件决定了)
其他游戏需要在两种模式之间动态切换,因此它们的盒式磁带可以通过软件进行配置,水平或垂直镜像。
塞尔达的传说属于这个类别。最后,有些真正的花哨的游戏在盒式筒中有额外的视频内存,这意味着它们根本不需要镜像,并且可以同时滚动水平和垂直,没有任何可见复制。
完善 Mapper 类 和 Cartridge 类
游戏画面在NameTable的滚动方式是由卡带决定的。每个游戏的墨盒包含允许名称表镜像配置的硬件。我们要在Cartridge类里 和 Mapper类里面加上相关的信息。
在Mapper增加滚动类型
Mapper 关于滚动的类型
// 镜像模式的枚举
enum MIRROR
{
HARDWARE,
HORIZONTAL,
VERTICAL,
ONESCREEN_LO, // 这种情况适用于 Mapper1 ( MMC1 ) , 后面有专门讲 Mapper 的章节会介绍这些
ONESCREEN_HI,
};
// 获取镜像模式的方法
// Get Mirror mode if mapper is in control
virtual MIRROR mirror();
在Cartridge增加接口
// 即时获取Mirror模式
MIRROR Cartridge::Mirror()
{
// 有的游戏的mirror模式是动态变化的(比如 Mapper_001 ),有的游戏的mirror模式是固定的
// 不同类型的mappper有不同的模式,但接口是一样的
// 调用 mapper 的接口
MIRROR m = pMapper->mirror();
if (m == MIRROR::HARDWARE)
{
// 镜像配置已定义 , 通过焊接在硬件中 ( 写死了 )
return hw_mirror;
}
else
{
// 镜像配置即可 , 通过映射器动态设置
return m;
}
}
scroll寄存器
游戏通过写入PPUSCROLL寄存器来改变滚动的位置,PPUSCROLL寄存器被映射到地址0x2005。对PPUSCROLL的第一个写入设置滚动位置的X组件,第二个写入设置Y组件。写作继续以这种方式交替进行。
表示滚动位置的寄存器( v , t , x , w )
PPU内部维护了几个寄存器v、t、x、w, 用来记录名称表的偏移信息 (但是这些寄存器并不映射到CPU的内存布局)。参考:PPU scrolling
- v: 当前的VRAM地址。(15 bit )
- t: 临时的VRAM地址,也可以被看作是屏幕窗口左上角的地址。 (15 bit )
- x: 精准x滚动(3bit)。
- w: 第一次或第二次写时触发(1bit)。
CPU使用主内存的0x2007 ( 对应 scroll register ,下面会看到)读写数据时,PPU使用的就是当前的VRAM地址,它也被用来获取名称表的数据以绘制到屏幕上。
v 寄存器 , t 寄存器的结构是一样的 ,是一个15位的寄存器,用作当前vram的访问地址和后台滚动配置。
在对scroll写数据时,实际上对 t 寄存器写东西 (详见下面对寄存器的归纳) , 渲染的时候,会把t寄存器的内容赋值给v寄存器
当将这个值作为地址处理时,第14位被忽略 (因为PPU的内存布局中的地址最大也就是 0x3FFF ),0-13位被视为显存中的地址。
根据该表,当将寄存器作为滚动配置时,其内容的不同部分具有不同的含义。

Name Table Select is a value from 0 to 3, and selects the name table currently being drawn from. (名称表的ID)
Coarse X Scroll and Coarse Y Scroll give the coordinate of a tile within the selected name table. This is the tile currently being drawn. ( 刚好是5位 , 能表示 0 ~ 32 )
Fine Y Scroll contains a value from 0 to 7, and specifies the current vertical offset of the row of pixels within the current tile. Tiles are 8 pixels square. ( 简单来说就是表示 tile 内部的 y 值 )
Fine X Scroll is absent from this register. There is a separate register which just contains the horizontal offset of the current pixel, but it won’t be relevant( 相关 ) for explaining how The Legend of Zelda performs vertical scrolling. ( fine x 独立于v,t 寄存器 )
该寄存器的代码定义
// 滚动寄存器
union loopy_register
{
struct
{
uint16_t coarse_x : 5;
uint16_t coarse_y : 5;
uint16_t nametable_x : 1;
uint16_t nametable_y : 1;
uint16_t fine_y : 3;
uint16_t unused : 1;
};
uint16_t reg = 0x0000;
};
更新 v 寄存器
// 传输临时存储的水平nametable访问信息
// 进入“指针”。请注意,精细x滚动不是“指针”的一部分
// 寻址机制
auto TransferAddressX = [&]() {
// Ony if rendering is enabled
if (mask.render_background || mask.render_sprites)
{
vram_addr.nametable_x = tram_addr.nametable_x;
vram_addr.coarse_x = tram_addr.coarse_x;
}
};
// 传输临时存储的垂直名称表访问信息
// 进入“指针”。请注意,精细的y形滚动是“指针”的一部分
// 寻址机制
auto TransferAddressY = [&]() {
// Ony if rendering is enabled
if (mask.render_background || mask.render_sprites)
{
vram_addr.fine_y = tram_addr.fine_y;
vram_addr.nametable_y = tram_addr.nametable_y;
vram_addr.coarse_y = tram_addr.coarse_y;
}
};
向右滚动
// 将背景平铺“指针”水平增加一个平铺/列
auto IncrementScrollX = [&]() {
// Note: pixel perfect scrolling horizontally is handled by the data
// shifters. Here we are operating in the spatial domain of tiles, 8x8
// pixel blocks. 注:像素完美水平滚动由数据移位器处理。
// 在这里,我们在瓦片的空间域中操作,即8x8像素块。
// 如果绘制
if (mask.render_background || mask.render_sprites)
{
// A single name table is 32x30 tiles. As we increment horizontally
// we may cross into a neighbouring nametable, or wrap around to
// a neighbouring nametable
// 单个名称表为32x30平铺。当我们水平增加时
// 我们可能会跨进相邻的一张姓名表,或者绕到另一张姓名表上
if (vram_addr.coarse_x == 31)
{
// Leaving nametable so wrap address round
// 离开nametable,将地址环绕
vram_addr.coarse_x = 0;
// Flip target nametable bit
// 翻转目标命名表位
vram_addr.nametable_x = ~vram_addr.nametable_x;
}
else
{
// 依然在当前名称表中,所以只需增加coarse_x
vram_addr.coarse_x++;
}
}
};
向下滚动
// ==============================================================================
auto IncrementScrollY = [&]() {
// 垂直递增更为复杂。可见名称表
// 是32x30瓷砖,但内存中有足够的空间容纳32x32瓷砖。
// 底部的两排瓷砖实际上根本不是瓷砖,它们
// 包含整个表的“属性”信息。这是
// 描述用于不同应用程序的选项板的信息
// 名称表的区域。
// 此外,网元不会以8像素的块垂直滚动
// 即瓷砖的高度,它可以通过使用
// 寄存器的精细部分。这意味着Y的增量
// 首先调整精细偏移,但可能需要调整整个偏移
// 行偏移,因为fine_y是一个0到7的值,一行高8像素
if (mask.render_background || mask.render_sprites)
{
// If possible, just increment the fine y offset
if (vram_addr.fine_y < 7)
{
vram_addr.fine_y++;
}
else
{
// 如果我们已经超过了一排的高度,我们需要
// 增加行数,可能会换行到相邻行中
// 垂直名称表。不过,别忘了下面两排
// 不包含平铺信息。使用粗略的y偏移
// 确定我们想要的名称表的哪一行,以及
// y偏移是特定的“扫描线”
// find_y是title内的像素y坐标扫描线
vram_addr.fine_y = 0;
// coarse_y记录的是名称表内的y扫描线
if (vram_addr.coarse_y == 29)
{
vram_addr.coarse_y = 0;
vram_addr.nametable_y = ~vram_addr.nametable_y;
}
else if (vram_addr.coarse_y == 31) // 感觉删了也没影响
{
// 进入名称表的属性范围边界
vram_addr.coarse_y = 0;
}
else
{
vram_addr.coarse_y++;
}
}
}
};
时序
概览
在理解时序之前要先了解以前的显示器的成像原理: CRT显示器
简单来说就是,Nes 屏幕大小是 256 * 240 , 但是实际上绘制一帧需要的扫描线有 260 条,并且每条扫描线有 340 个像素点, ,而每一个PPU的时钟周期,绘制一个像素点。
时序图是统筹渲染的时间表,要读懂时序,才能写出有效的代码。
下面这个是完整的时序图

图像解读
时序:
- PPU 时钟为 CPU 的 3 倍,每一个 PPU 时钟扫描一个点,每一帧一共扫描 262 行,每一行扫描 341 个点,并且只有在扫描线 0 - 239 的 1 - 256 点可见
- 除了(0, 0)以外,每行第一个点不做任何事情,(0,0)会在使能背景显示并且在奇数帧时跳过
像素读取:
图中的黄色部分每 8 个点看作一个单位( **8个circle 用来准备未来要绘制的tile , 这些准备的数据会保存在 “ 移位寄存器 ” 里 ** ):
- 时钟 0 - 1 取 Name table 数据 (实际上是 tile 的索引)
- 时钟 2 - 3 取 Attribute table 数据 ( 实际上是 palette 的索引 )
- 时钟 5 - 6 读取 tile 低 8 位 (LSB)
- 时钟 7 - 8 读取 tile 高 8 位 (HSB)
读取的数据会进入锁存器,然后每一个时钟进入移位寄存器 (后面会涉及),以提供绘图使用,数据读取方法和锁存器在 NESDEV 上已经提供了伪代码了,这里不再重复,参考:
http://wiki.nesdev.com/w/index.php/PPU_scrolling
http://wiki.nesdev.com/w/index.php/PPU_rendering每一个可见的时钟都会从移位寄存器取出 palette index,进行绘图。图中一些不可见的时钟也存在取数据的操作(比如 321 - 340),这是因为需要预先将移位寄存器塞满
中断:
在
scanline 240 cycle 1时,有一个set VBlank flag的操作 这时候会将 PPU 状态寄存器中的
VBlank标志置位 并且如果 PPU 使能(enable)了中断 (这个要看PPU控制寄存器),会向 CPU 触发一个 NMI 中断提醒 CPU 进行绘图更新
最后会在
scanline 261 cycle 1时清除Blank
利用滚动寄存器渲染
滚动寄存器配套使用的内部数据有
// 背景像素渲染信息
// 要配合上面面的时序理解这个变量
uint8_t bg_next_tile_id = 0x00; //时钟 0~1 修改这个值
uint8_t bg_next_tile_attrib = 0x00; // 时序 2~3修改这个值
uint8_t bg_next_tile_lsb = 0x00; // 时序 4~5 修改这个值,当前渲染的像素,所在的lsb对应行的信息
uint8_t bg_next_tile_msb = 0x00; // 时序 6~7 修改这个值, 当前渲染的像素,所在的msb对应行的信息
// 移位寄存器,根据这些移位寄存器来渲染信息,这些移位寄存器是通过上面的
// 预准备的数据存在低8位 (也就是说存在低8位的信息是留给下一个 "8周期" 使用的)
// 当前渲染用到的数据存在高8位,所以每次跨越tile的时候,这些寄存器都要移位
uint16_t bg_shifter_pattern_lo = 0x0000;
uint16_t bg_shifter_pattern_hi = 0x0000;
uint16_t bg_shifter_attrib_lo = 0x0000;
uint16_t bg_shifter_attrib_hi = 0x0000;
利用滚动寄存器渲染的原理
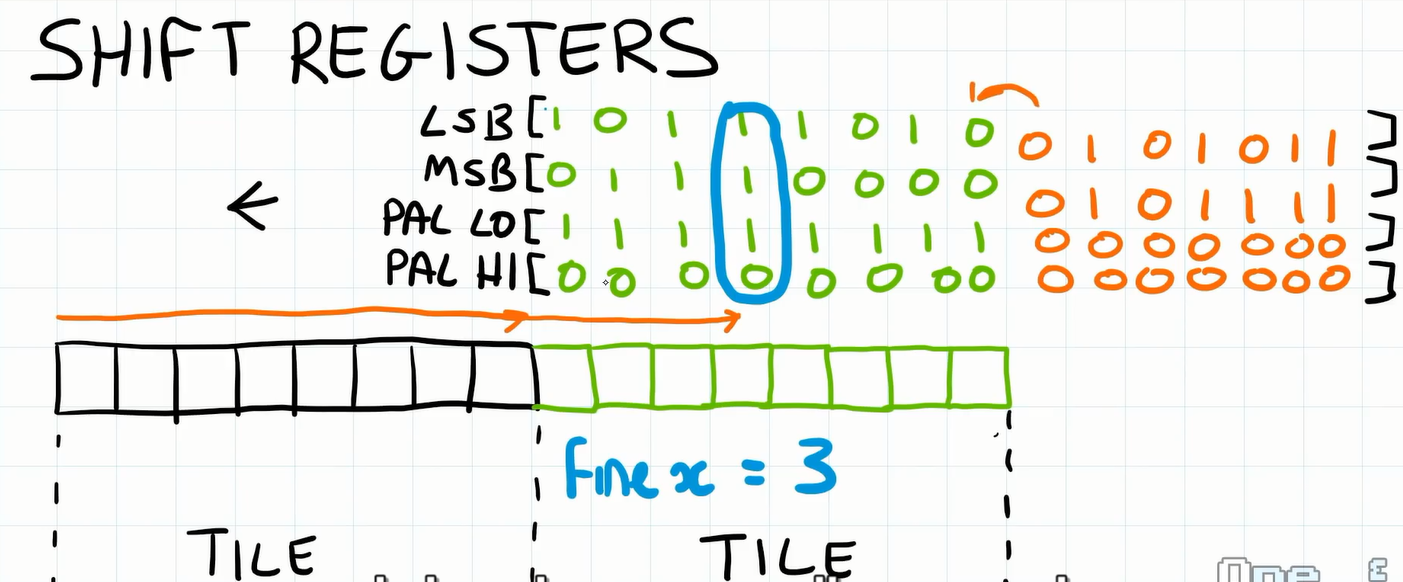
uint16_t bg_shifter_pattern_lo = 0x0000; // 对应 LSB uint16_t bg_shifter_pattern_hi = 0x0000; // 对应 MSB uint16_t bg_shifter_attrib_lo = 0x0000; // 对应 PAL Lo uint16_t bg_shifter_attrib_hi = 0x0000; // 对应 PAL HI
更新滚动寄存器的代码
// 每个周期,存储模式和属性信息的移位器移位
// 它们的内容是1位的。这是因为每一个周期,输出都在进行
// 1像素。这意味着换档杆的状态相对而言是同步的
// 为扫描线的8像素部分绘制像素。
auto UpdateShifters = [&]() {
if (mask.render_background)
{
// Shifting background tile pattern row
bg_shifter_pattern_lo <<= 1;
bg_shifter_pattern_hi <<= 1;
// Shifting palette attributes by 1
bg_shifter_attrib_lo <<= 1;
bg_shifter_attrib_hi <<= 1;
}
if (mask.render_sprites && cycle >= 1 && cycle < 258)
{
for (int i = 0; i < sprite_count; i++)
{
if (spriteScanline[i].x > 0)
{
spriteScanline[i].x--;
}
else
{
sprite_shifter_pattern_lo[i] <<= 1;
sprite_shifter_pattern_hi[i] <<= 1;
}
}
}
};
载入滚动寄存器代码
// 为“有效”背景平铺移位器加上底漆,以便下一步输出
// 扫描线为8像素。
auto LoadBackgroundShifters = [&]() {
// 每次PPU更新我们计算一个像素。这些移位器沿方向移位1位
// 向像素合成器提供所需的二进制信息。它的
// 16位宽,因为前8位是当前正在绘制的8个像素
// 底部的8位是接下来要绘制的8个像素。当然这意味着
// 所需位始终是移位器的MSB。但是,“精细x”滚动
// 这也起了一定作用,后面会看到,所以事实上我们可以选择
// 前8位中的任意一位。
bg_shifter_pattern_lo = (bg_shifter_pattern_lo & 0xFF00) | bg_next_tile_lsb;
bg_shifter_pattern_hi = (bg_shifter_pattern_hi & 0xFF00) | bg_next_tile_msb;
bg_shifter_attrib_lo = (bg_shifter_attrib_lo & 0xFF00) | ((bg_next_tile_attrib & 0b01) ? 0xFF : 0x00);
bg_shifter_attrib_hi = (bg_shifter_attrib_hi & 0xFF00) | ((bg_next_tile_attrib & 0b10) ? 0xFF : 0x00);
};
渲染对应代码
// 此时已经获得了所有的前景(精灵)和背景的像素信息,此时需要做合成了
// 其中,背景像素块的信息中颜色信息,每8个bit需要改变一次
uint8_t bg_pixel = 0x00; // The 2-bit pixel to be rendered
uint8_t bg_palette = 0x00; // The 3-bit index of the palette the pixel indexes
//如果启用了 PPU,我们只会渲染背景。注意如果
// 背景渲染被禁用,像素和调色板结合
// 形成 0x00。这将通过颜色表产生
// 当前生效的背景颜色
if (mask.render_background)
{
// 通过选择相关位来处理像素选择
// 取决于精细 x scolling。
// 这具有以下效果 :
// 将所有背景渲染偏移一个设定的数字像素,允许平滑滚动
uint16_t bit_mux = 0x8000 >> fine_x;
uint8_t p0_pixel = (bg_shifter_pattern_lo & bit_mux) > 0;
uint8_t p1_pixel = (bg_shifter_pattern_hi & bit_mux) > 0;
bg_pixel = (p1_pixel << 1) | p0_pixel;
uint8_t bg_pal0 = (bg_shifter_attrib_lo & bit_mux) > 0;
uint8_t bg_pal1 = (bg_shifter_attrib_hi & bit_mux) > 0;
bg_palette = (bg_pal1 << 1) | bg_pal0;
}
这里已经得到了
bg_palette和bg_pixel, 用两个量已经可以确定对应像素点颜色了。
划分时序区间
下面是时序图的简化形式,这样设计时序是为了让电子枪在绘制 screen 以外的区域(这些区域不会被显示)的时候,cpu能够利用这些时间间隙来和ppu通讯。
+--------+ 0 ----+
| | |
| | |
| Screen | +-- (0-239) 256x240 on-screen results
| | |
| | |
+--------+ 240 --+
| ?? | +-- (240-242) Unknown
+--------+ 243 --+
| | |
| VBlank | +-- (243-262) VBlank
| | |
+--------+ 262 --+
扫描线和时钟计数
void clock() {
.......
cycle++;
if (cycle >= 341)
{
cycle = 0;
scanline++;
if (scanline >= 261)
{
scanline = -1;
// 标记这个背景帧是不是完成
frame_complete = true;
// 奇数帧 <-> 偶数帧
odd_frame = !odd_frame;
}
}
.......
}
这里把第262条 scanline 设置为-1, 方便标识。
划分区间
// 除第 1 条 ( 准确来说是 scanline == -1 )之外的所有 secanlines 对用户都是可见的。
// 在 -1 处的预渲染扫描线,用于配置第一条可见扫描线的“移位寄存器”
// scanline 在 [-1 , 240 ) 是可见区间
// 内部还会划分各种时钟周期
if (scanline >= -1 && scanline < 240)
{
// 这里的scanline 指的是行数 ,渲染的行数为 0 - 239
// cycle 指的是 Pixel 列数
// 如果是基础
if (scanline == 0 && cycle == 0 && odd_frame)
{
// "Odd Frame" cycle skip
cycle = 1;
}
// 预处理
if (scanline == -1 && cycle == 1)
{
// Effectively start of new frame, so clear vertical blank flag
...
}
// 执行动作的时钟区间
if ((cycle >= 2 && cycle < 258) || (cycle >= 321 && cycle < 338))
{
//在这些cycle中,我们收集和处理可见数据
//“移位器”已经在前一个扫描线的末尾与该扫描线开始的数据预加载。
switch ((cycle - 1) % 8)
{
case 0:
...
break;
case 2:
...
break;
case 4:
...
break;
case 6:
...
break;
case 7:
...
break;
}
}
// End of a visible scanline, so increment downwards...
if (cycle == 256)
{
....
}
//...and reset the x position
if (cycle == 257)
{
...
}
// Superfluous reads of tile id at end of scanline
if (cycle == 338 || cycle == 340)
{
...
}
if (scanline == -1 && cycle >= 280 && cycle < 305)
{
...
}
}
// 下面是不可见的扫描线区间
if (scanline == 240)
{
// Post Render Scanline - Do Nothing!
}
// 最后的要准备的扫描线区间
if (scanline >= 241 && scanline < 261)
{
if (scanline == 241 && cycle == 1)
{
......
}
}
// 进行渲染
....
这个是时序实现的框架。 接下来按照时序来探讨各部分实现
1.不可视期: 禁止中断,跳出vblank
if (scanline == -1 && cycle == 1)
{
// Effectively start of new frame, so clear vertical blank flag
status.vertical_blank = 0;
}
2 . 可视期 : 常规操作
if ((cycle >= 2 && cycle < 258) || (cycle >= 321 && cycle < 338))
{
UpdateShifters();
// 在这些周期中,我们收集和处理可见数据
// “换档杆”已在上一节结束时预加载
// 带有此扫描线起点数据的扫描线。一旦我们
// 离开可见区域,我们进入休眠状态,直到移位器被移除
// 为下一条扫描线预加载。
// 幸运的是,对于背景渲染,我们经历了一个相当复杂的过程
// 可重复的事件序列,每2个时钟周期。
switch ((cycle - 1) % 8)
{
case 0:
// Load the current background tile pattern and attributes into the
// "shifter" 这个是背景,所有的x坐标开始都是 8 的整数倍
LoadBackgroundShifters();
// Fetch the next background tile ID
// "(vram_addr.reg & 0x0FFF)" : Mask to 12 bits that are relevant
// "| 0x2000" : Offset into nametable space on PPU
// address bus 获取下一个背景title的ID号(名称表中)
bg_next_tile_id = ppuRead(0x2000 | (vram_addr.reg & 0x0FFF));
// 说明:
// 循环寄存器的底部12位提供到的索引
// 这4个名称表,与名称表镜像配置无关。
// 名称表_y(1)名称表_x(1)粗略_y(5)粗略_x(5)
//
// 考虑单个可指定的是32×32数组,并且我们有四个数组。
// 0 1
// 0 +----------------+----------------+
// | | |
// | | |
// | (32x32) | (32x32) |
// | | |
// | | |
// 1 +----------------+----------------+
// | | |
// | | |
// | (32x32) | (32x32) |
// | | |
// | | |
// +----------------+----------------+
//
// This means there are 4096 potential locations in this array, which
// just so happens to be 2^12!
// 这意味着此阵列中有4096个潜在位置
// 正好是2^12!
break;
case 2:
// 获取下一个背景平铺属性。好的,所以这个有点
// 更多参与:P
// 回想一下,每个nametable都有两行不是平铺的单元格
// 信息,而是表示
// 指示将哪些选项板应用于屏幕上的哪个区域。
// 重要的是(令人沮丧的是)没有1:1的对应关系
// 在背景平铺和调色板之间。两行磁贴数据保持不变
// 64个属性。因此,我们可以假设属性会影响
// 屏幕上该名称表的8x8区域。给出了一个工作决议
// 对于256x240,我们可以进一步假设每个区域为32x32像素
// 在屏幕空间或4x4平铺中。分配了四个系统选项板
// 要进行背景渲染,只需使用
// 2位。因此,属性字节可以指定4个不同的选项板。
// 因此,我们甚至可以进一步假设一个调色板是
// 应用于4x4瓷砖区域的2x2瓷砖组合。事实本身
// 背景瓷砖在本地“共享”调色板就是原因
// 在一些游戏中,你会看到屏幕边缘颜色的失真。
// 与前面一样,在选择磁贴ID时,我们可以使用
// 循环寄存器,但我们需要使实现“更粗糙”
// 因为我们需要的是属性字节,而不是特定的磁贴
// 一组4x4瓷砖,或者换句话说,我们划分32x32地址
// 乘以4,得到一个等效的8x8地址,我们将该地址偏移
// 进入目标名称表的属性部分。
// 将12位循环地址重新构造为
// 属性存储器
// "(vram_addr.coarse_x >> 2)" : integer divide coarse x by 4,
// from 5 bits to 3 bits
// "((vram_addr.coarse_y >> 2) << 3)" : integer divide coarse y by 4,
// from 5 bits to 3 bits,
// shift to make room for coarse
// x
// Result so far: YX00 00yy yxxx
// 名称表中的所有属性内存从0x03C0开始,so或with
// 结果以选择目标名称表和属性字节偏移量。最后
// 或使用0x2000偏移到PPU总线上的nametable地址空间。
bg_next_tile_attrib = ppuRead(0x23C0 | (vram_addr.nametable_y << 11) | (vram_addr.nametable_x << 10) |
((vram_addr.coarse_y >> 2) << 3) | (vram_addr.coarse_x >> 2));
// 我们已经读取了指定地址的正确属性字节,
// 但是字节本身被进一步分解为2x2平铺组
// 在4x4属性区域中。
// 属性字节是这样组合的:BR(76)BL(54)TR(32)TL(10)
//
// +----+----+ +----+----+
// | TL | TR | | ID | ID |
// +----+----+ where TL = +----+----+
// | BL | BR | | ID | ID |
// +----+----+ +----+----+
//
// 因为我们知道可以直接从12位地址访问磁贴,所以我们
// 可以分析粗坐标的底部位,为我们提供
// 将正确的偏移量转换为8位字,以产生所需的2位
// 实际感兴趣的是指定2x2组
// 瓷砖。我们知道如果“粗y%4”<2,我们在上半部分,否则在下半部分。
// 同样,如果“粗略x%4”小于2,则我们位于左半部分,否则位于右半部分。
// 最终,我们希望属性词的底部两位是
// 选择调色板。所以按要求换班。。。
if (vram_addr.coarse_y & 0x02)
bg_next_tile_attrib >>= 4;
if (vram_addr.coarse_x & 0x02)
bg_next_tile_attrib >>= 2;
bg_next_tile_attrib &= 0x03;
break;
// Compared to the last two, the next two are the easy ones... :P
case 4:
// 从模式内存中获取下一个背景平铺LSB位平面
// 已从名称表中读取磁贴ID。我们将使用此id
// 索引到模式内存中以找到正确的精灵(假设
// 精灵位于内存中的8x8像素边界上,它们就是这样做的
// 即使存在8x16精灵,因为背景平铺始终为8x8)。
//
// 由于精灵实际上是1位深,但8像素宽,我们
// 可以将整个sprite行表示为单个字节,因此偏移
// 进入模式记忆很容易。总共有8KB,所以我们需要一个
// 13位地址。
// "(control.pattern_background << 12)" : the pattern memory selector
// from control register,
// either 0K or 4K offset
// "((uint16_t)bg_next_tile_id << 4)" : the tile id multiplied by
// 16, as
// 2 lots of 8 rows of 8 bit
// pixels
// "(vram_addr.fine_y)" : Offset into which row based
// on
// vertical scroll offset
// "+ 0" : Mental clarity for plane
// offset Note: No PPU address bus offset required as it starts at
// 0x0000
bg_next_tile_lsb = ppuRead((control.pattern_background << 12) + ((uint16_t)bg_next_tile_id << 4) +
(vram_addr.fine_y) + 0);
break;
case 6:
// Fetch the next background tile MSB bit plane from the pattern
// memory This is the same as above, but has a +8 offset to select the
// next bit plane
bg_next_tile_msb = ppuRead((control.pattern_background << 12) + ((uint16_t)bg_next_tile_id << 4) +
(vram_addr.fine_y) + 8);
break;
case 7:
// Increment the background tile "pointer" to the next tile
// horizontally in the nametable memory. Note this may cross nametable
// boundaries which is a little complex, but essential to implement
// scrolling
IncrementScrollX();
break;
}
}
3. 可视期:设置滚动寄存器
// End of a visible scanline, so increment downwards...
if (cycle == 256)
{
IncrementScrollY();
}
//...and reset the x position
if (cycle == 257)
{
LoadBackgroundShifters();
TransferAddressX();
}
// Superfluous reads of tile id at end of scanline
if (cycle == 338 || cycle == 340)
{
bg_next_tile_id = ppuRead(0x2000 | (vram_addr.reg & 0x0FFF));
}
if (scanline == -1 && cycle >= 280 && cycle < 305)
{
// End of vertical blank period so reset the Y address ready for rendering
TransferAddressY();
} // End of a visible scanline, so increment downwards...
4. 不可视期:允许中断
进入 unkonow 区域时,设置 vblank 。意味着CPU在这个时刻可以设置CPU的信息。
if (scanline >= 241 && scanline < 261)
{
if (scanline == 241 && cycle == 1)
{
// 设置垂直空白标志
status.vertical_blank = 1;
// 此时控制寄存器允许cpu进行nmi中断
if (control.enable_nmi)
nmi = true;
}
}
可以这样理解,nmi中断相当于是告知cpu, ppu已经把图绘制好了,现在cpu可以为绘制下一帧做准备了。
在主时钟上,可以这样协调组织两者。 (实际的主时钟函数没有那么简单,这个代码的意义在于把关键动作框架勾勒出来)
void clock() { //运行频率由调用此函数的任何函数控制。因此,这里我们根据需要“划分”时钟,并在正确的时间调用外围设备clock()函数。 //Nes系统中最快的时钟即是PPU时钟。 //所以PPU的频率和nes系统的时钟频率是一样的。 ppu.clock(); // CPU运行速度比PPU慢3倍 if (nSystemClockCounter % 3 == 0) { cpu.clock(); } // PPU的中断通常发生在vertical blanking period // 此时cpu需要进行下一帧的名称表的准备 // 不可能在绘制的时间进行准备,只能等到绘制结束,否则会产生很多问题 // 唯一的机会就是在垂直消隐期间进行 if (ppu.nmi) { ppu.nmi = false; cpu.nmi(); } // 用一个全局计数器来计数主时钟。 nSystemClockCounter++; }
CPU和PPU的通信 - PPU的寄存器
图像滚动依赖于CPU向PPU写入滚动信息。 所以PPU要向CPU暴露写信息的接口。
PPU和CPU之间通过9个寄存器来互通信息。

这是CPU的内存布局中和通信相关的区域,CPU通过访问这里的地址来写PPU的寄存器,进而改写PPU的状态。
这些是和滚动相关的寄存器 ,下面会陆续提及
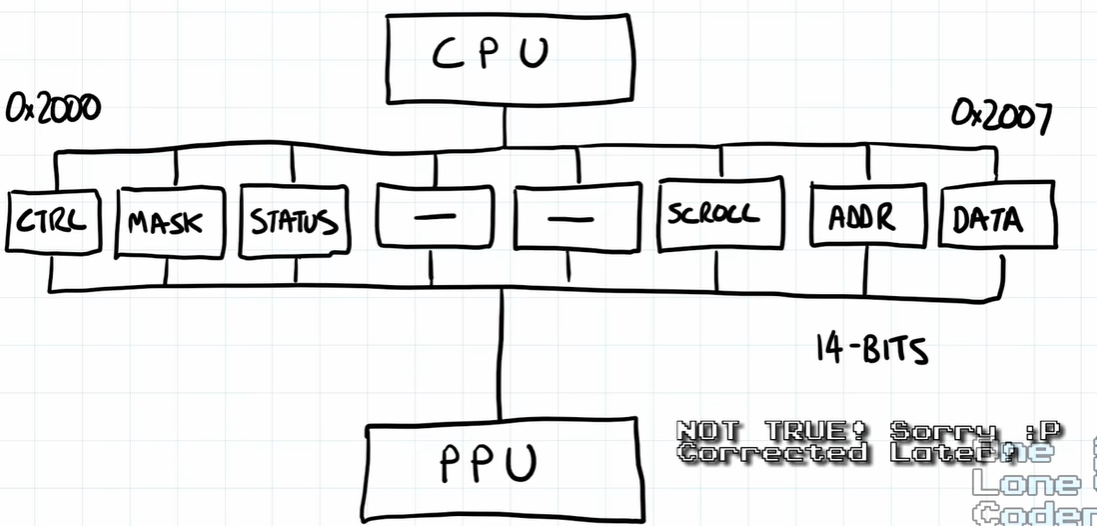
CTRL : 负责设置PPU的参数,以切换渲染方式
MASK : 相当于一个开关,决定是渲染 background 还是
Spririt ,以及决定一些 “屏幕” 边缘的渲染动作
STATUS : 负责告知CPU/PPU,安全渲染/准备的时机。
SCROLL : 和图像滚动信息有关
ADDR : 显存指针,只读的
DATA : 读写显存
下面着重解释一下 ADDR 和 DATA
PPUADDR 寄存器,用于设置当前渲染的vram的地址。例如,当游戏想要改变nameTable的一个tile时,它首先将tile 的vram地址写入PPUADDR 寄存器,然后将tile的新值写入PPUDATA 寄存器
在非vblank 期间写入PPUADDR 寄存器 (例如:正在绘制画面时) 会导致图形伪像( graphical artefacts)。这是因为PPU在从vram中检索tile以绘制tile时,PPU也会直接操纵写入PPUADDR的PPU电路 (( 言下之意是两者会冲突 )。
随着绘图从屏幕的顶部到底部进行,并且在每个像素行中从左到右进行,PPU有效地将PPUADDR设置为包含当前正在绘制的像素的tile的地址。当绘图从一个tile移动到另一个tile时,通过增加其当前值来改变PPUADDR。
因此,对ppaddr的中间帧的写入可以改变PPU在当前帧期间从内存中获取的tile。
控制寄存器
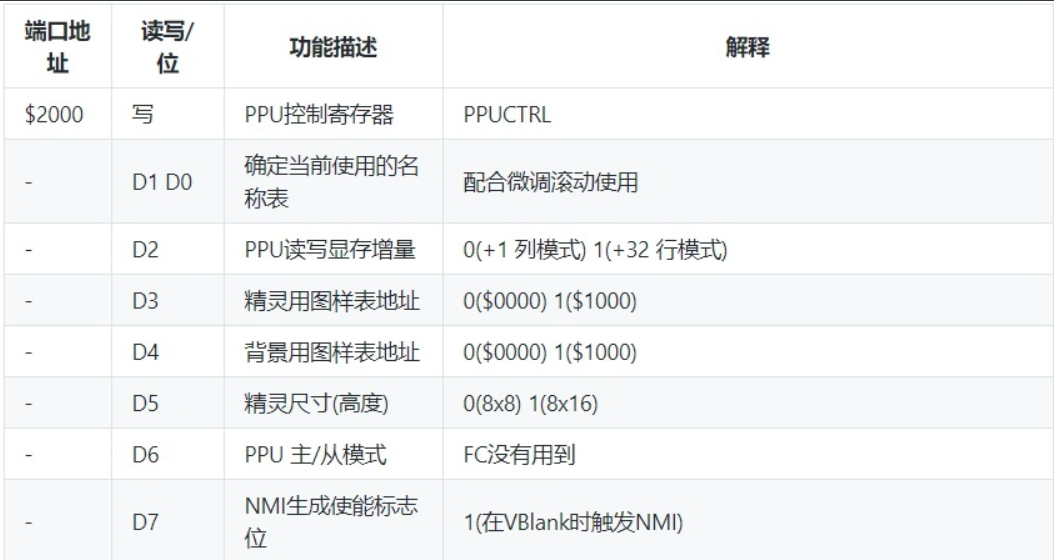
定义
union PPUCTRL {
struct
{
uint8_t nametable_x : 1;
uint8_t nametable_y : 1;
uint8_t increment_mode : 1;
uint8_t pattern_sprite : 1;
uint8_t pattern_background : 1;
uint8_t sprite_size : 1;
uint8_t slave_mode : 1; // unused
uint8_t enable_nmi : 1;
};
uint8_t reg;
} control; // 控制寄存器
cpu读操作
// 没有写权限
cpu写操作
control.reg = data;
// 临时存储要在不同时间“转移”到“指针”中的信息
// 后面会解释变量 tram_addr 的含义
tram_addr.nametable_x = control.nametable_x;
tram_addr.nametable_y = control.nametable_y;
掩码寄存器
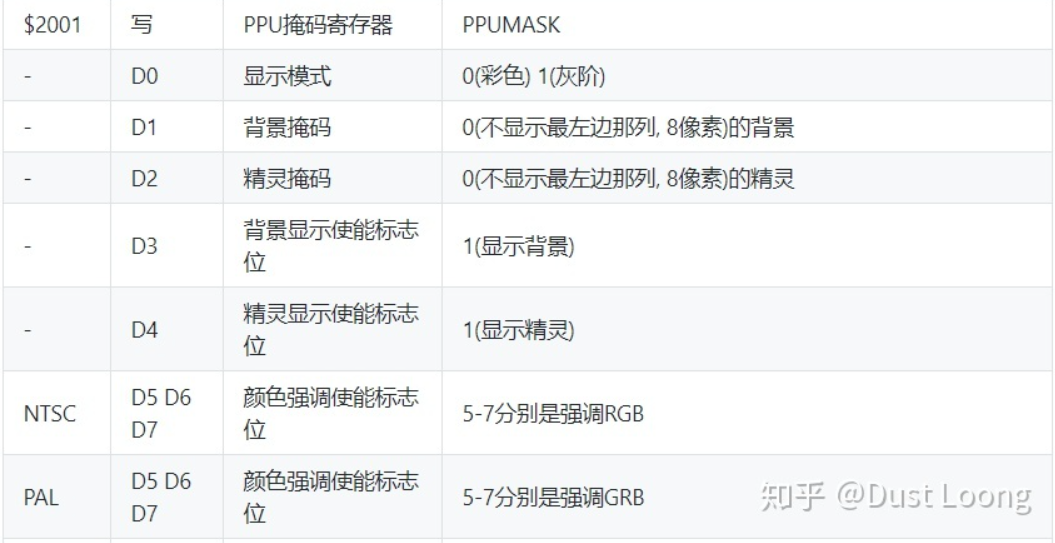
可以看成是一系列开关
union {
struct
{
uint8_t grayscale : 1;
uint8_t render_background_left : 1;
uint8_t render_sprites_left : 1;
uint8_t render_background : 1;
uint8_t render_sprites : 1;
uint8_t enhance_red : 1;
uint8_t enhance_green : 1;
uint8_t enhance_blue : 1;
};
uint8_t reg;
} mask; // 掩码寄存器
cpu读操作
// 没有写权限
cpu写操作
mask.reg = data;
ADDR (显存指针)

定义
union loopy_register
{
// Credit to Loopy for working this out :D
struct
{
uint16_t coarse_x : 5;
uint16_t coarse_y : 5;
uint16_t nametable_x : 1;
uint16_t nametable_y : 1;
uint16_t fine_y : 3;
uint16_t unused : 1;
};
uint16_t reg = 0x0000;
};
// 指向 nametable 地址的指针v
loopy_register vram_addr;
// 将要保存到指针v指向的地址的临时信息,信息记录的是滚动位置
loopy_register tram_addr;
cpu读操作
// 没有权限
cpu写操作
// PPU Address
// ppu地址是一个16字节地址,所以分两次传输
// 第一次传输高8字节
// 第二次传输底8字节
// 两个周期
if (address_latch == 0)
{
// CPU可通过ADDR和DATA访问PPU地址总线寄存器
// 第一次写入该寄存器将锁存高字节
// 在地址中,第二个是低字节。
// tram_addr.reg=(uint16_t)((data&0x3F)<<8)|(tram_addr.reg&0x00FF);
tram_addr.reg = (uint16_t)((data & 0x3F) << 8); // fix something
address_latch = 1;
}
else
{
// 写入整个地址后,内部vram地址
// 缓冲区已更新。在渲染期间不能写入PPU
// 因为PPU将自动维护vram地址,同时更新
// 渲染扫描线位置。
tram_addr.reg = (tram_addr.reg & 0xFF00) | data;
vram_addr = tram_addr;
address_latch = 0;
}
address_latch(地址锁存器), 是控制写低位/高位的变量。
DATA (显存数据)

cpu读操作
// https://wiki.nesdev.com/w/index.php?title=PPU_programmer_reference#Data_.28.242007.29_.3C.3E_read.2Fwrite
// 从 NameTable ram 读取会延迟一个周期,
// 所以输出缓冲区包含来自之前的读请求
data = ppu_data_buffer;
// CPU 读取并获取内部缓冲区的内容后
// PPU 会立即使用当前 VRAM 地址处的字节更新内部缓冲区 (为下一次读做准备)
ppu_data_buffer = ppuRead(vram_addr.reg);
//但是,如果地址在调色板范围内,则数据没有延迟,所以立即返回
if (vram_addr.reg >= 0x3F00)
data = ppu_data_buffer;
// 根据控制寄存器中设置的模式,
// 所有从 PPU 数据读取的数据都会自动递增命名表地址。
// 如果设置为垂直模式,则增量为 32,因此跳过一整行名称表;
// 在水平模式下它只是增加 1,移动到下一列
vram_addr.reg += (control.increment_mode ? 32 : 1);
cpu写操作
// PPU Data
// 调用PPU的接口
ppuWrite(vram_addr.reg, data);
// 根据控制寄存器中设置的模式,所有从 PPU
// 数据写入的数据都会自动递增命名表地址。
// 如果设置为垂直模式,则增量为 32,
// 因此跳过一整行名称表;
// 在水平模式下它只是增加 1,移动到下一列
vram_addr.reg += (control.increment_mode ? 32 : 1);
状态寄存器
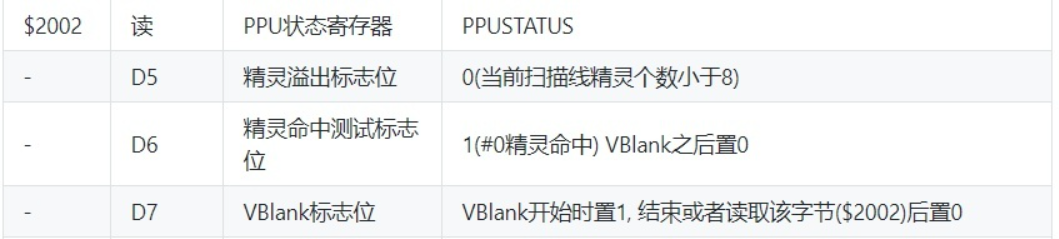
定义
union {
struct
{
uint8_t unused : 5;
uint8_t sprite_overflow : 1;
uint8_t sprite_zero_hit : 1;
uint8_t vertical_blank : 1;
};
uint8_t reg;
} status; // 状态寄存器
cpu读操作
// 读操作也会改变内部的信息
// 只有后三位存有有效信息
// https://wiki.nesdev.com/w/index.php?title=PPU_programmer_reference#Status_.28.242002.29_.3C_read
// 0xE0 = 0b11100000 0x1F = 0b00011111
// ppu_data_buffer 之前写入 PPU 寄存器的最低有效位
data = (status.reg & 0xE0) | (ppu_data_buffer & 0x1F); // 后面这个 (ppu_data_buffer & 0x1F) 其实是不必要的
// Clear the vertical blanking flag
status.vertical_blank = 0;
// Reset Loopy's Address latch flag
address_latch = 0;
.....
// 返回数据
return data;
cpu写操作
// 没有权限
SCROLL 寄存器

我的实现省略了这个寄存器,实际上直接把数据保存到t寄存器就足够了,因为整个渲染过程主要依靠内部寄存器,SCROLL寄存器根本就不会被更改。
cpu读操作t
// 没有权限
cpu写操作
// 滚动功能实现寄存器
// 通过address_latch 判断是水平滚动还是垂直滚动
// 这个scroll执行两次,先执行x 后执行 y
if (address_latch == 0)
{
// 首次写入滚动寄存器包含像素空间中的X偏移量
// 我们将其分为粗x值和细x值
// 细x值保存的是像素x偏移
// 粗x值保存名称表的偏移
fine_x = data & 0x07;
tram_addr.coarse_x = data >> 3;
address_latch = 1;
}
else
{
// 首次写入滚动寄存器包含像素空间中的Y偏移量
// 我们将其分为粗y值和细y值
// 细y值保存的是像素y偏移
// 粗y值保存名称表的偏
tram_addr.fine_y = data & 0x07;
tram_addr.coarse_y = data >> 3;
address_latch = 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号